一、说在前面
现代软件系统因体量越来越大,一般所拥有的数据量也越大,并且往往系统间存在着诸多依赖关系,其中数据依赖是一个比较典型的业务场景。
笔者日常处理数据依赖的工作内容比较多,所以下面分享两个典型数据依赖案例及相应处理方案。
二、具体案例
案例一:依赖其他业务系统的数据表数据
初始方案
在将内部大数据数仓中的数据同步到业务系统时,最初的技术方案是这样的。
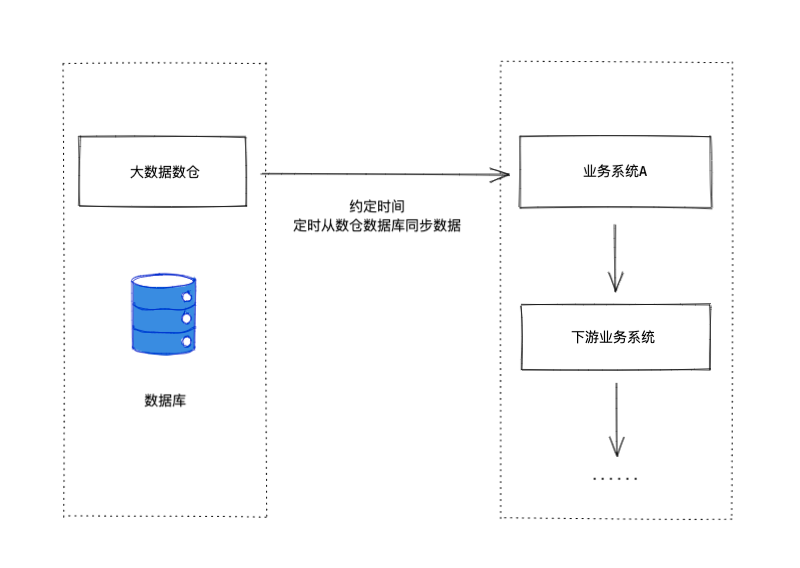
大数据数仓和业务系统商量好,每天数仓提供的数据大约会在几点给出来,然后业务系统这边定时去将数仓中的数据同步过来。
看起来没有什么大问题,只要每天数仓提供的数据能按时给出来,业务系统这边就基本能正常运行。
然后就这样上线观察运行了几天也没出问题,处理数据速度也蛮快的。
问题
但是就这样运行了一段时间后,某一天大数据数仓处理数据出了问题,原本应提供给下游的数据没有提供出来,业务系统无法从上游同步数据,导致业务系统及其下游业务系统异常。
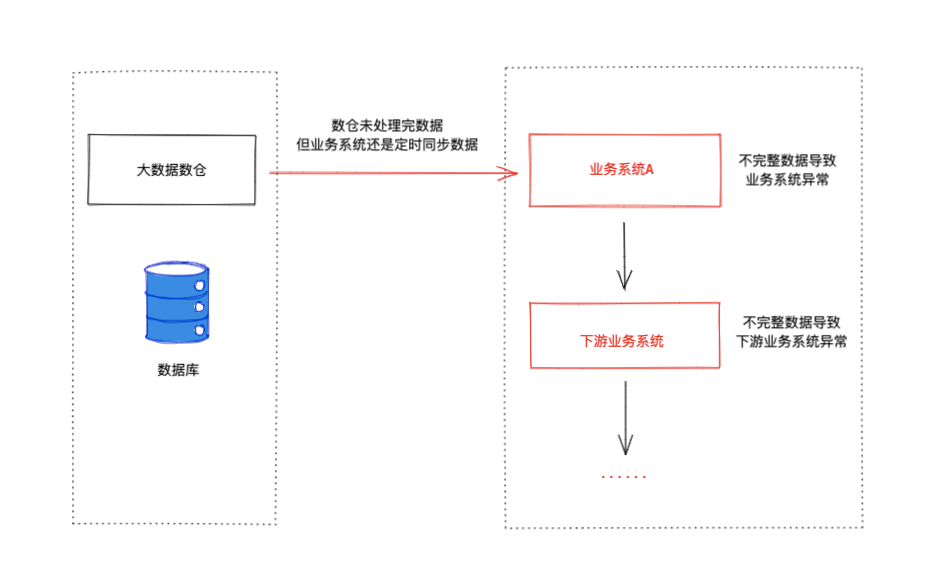
然后就是火急火燎的通知上游大数据数仓数据出现了问题,让他们修复问题补数据,业务系统再从数仓同步数据,最后下游业务系统再重新处理数据。整个流程处理起来太费时间,满足不了系统长时间稳定运行的诉求。
并且随着数据量每日不断的增加,大数据数仓处理数据的时间自然而然就会变长,提供给下游数据的时间节点就越来越滞后,但是下游业务系统又需要尽快处理数据,以便每天能在业务运营人员早上上班之前能及时提供分析数据。
所以靠约定在某个时间点定时去从数仓同步数据的做法显然是行不通的,需要更快更稳定的方案。
优化方案
针对上述问题,我们与大数据数仓协调沟通得出了如下方案。
增加任务处理表,由大数据数仓维护,当每个数据任务处理完后,会往任务表中插入一条任务记录。我方业务系统则只需监听任务处理表是否有相应任务处理完成,然后再做进一步的数据同步处理。
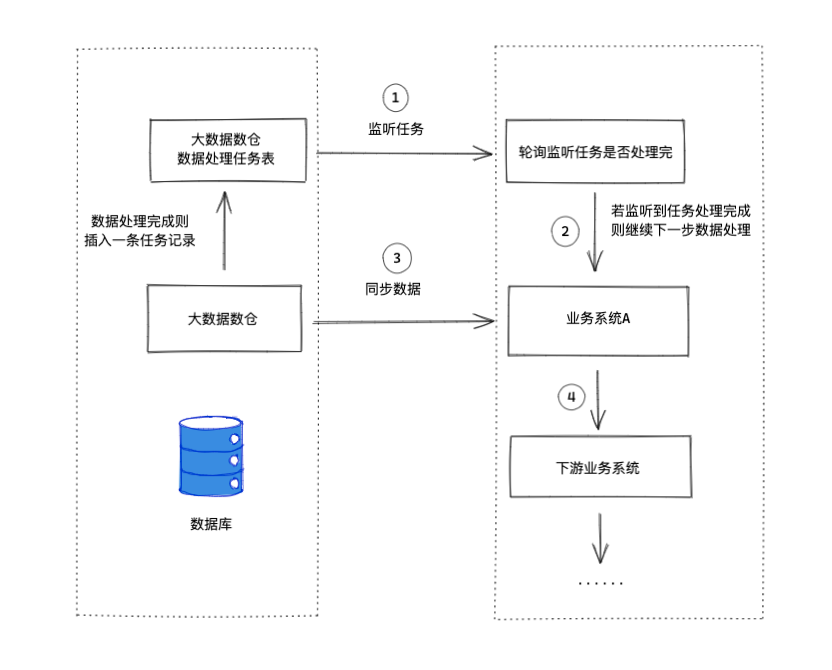
下面是具体技术实现
1.设计任务表,每当数仓处理完某一任务数据后,写入一条任务记录到此表(由大数据数仓维护)
下面是任务表结构及示例数据
CREATE TABLE `task_record` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`data_date` char(10) NOT NULL DEFAULT '' COMMENT '日期',
`task_name` varchar(128) NOT NULL DEFAULT '' COMMENT '任务名',
`create_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
id,data_date,task_name,create_time
1,2021-11-10,data_task1,2021-11-11 03:38:28
2,2021-11-10,data_task2,2021-11-11 03:52:35
3,2021-11-09,data_task1,2021-11-10 03:39:44
4,2021-11-09,data_task2,2021-11-10 03:52:35
2.业务系统这边使用 redis hash 结构来记录任务的处理状态(由业务系统方维护)
下面是任务的hash结构示例
{
"id": "1",
"data_date": "2021-11-10",
"task_name": "data_task1",
"create_time": "2021-11-11 03:38:28",
"status":"doing" // doing or done
}
3.下面是业务系统程序处理逻辑(程序执行机制为定时轮询执行,例如每十分钟执行一次)
// 查询任务数据表间隔时间内指定任务的最新一条记录
taskData = GetLatestTaskData(custom_listen_task_name)
// 查询指定任务缓存状态
oldTaskData = hget task-redis-key taskData.task_name
if oldTaskData.status == "doing" {
exit "doing"
}
if oldTaskData.status == "done" {
if taskData.id == oldTaskData.id {
exit "already done"
} else {
// 任务状态初始化设置
hset task-redis-key id taskData.id
hset task-redis-key data_date taskData.data_date
hset task-redis-key create_time taskData.create_time
hset task-redis-key status "doing"
// data sync handle start
...
// data sync handle end
// 任务处理完成同步修改状态
hset task-redis-key taskData.task_name status "done"
}
}
逻辑优化了后,数据同步再也没有出现异常情况,像之前每次出现问题都火急火燎补数据的难忘经历也就此划上了句号。不过为了以防不测,我们也是加上数据指标异常监测提醒逻辑,应对未来可能出现未知的数据异常问题,以便能及时响应处理。
更好的处理方案?
当然身为开发人员的我们不应止于此,只满足基本的业务优化诉求,我们还可以在任务调度细节方面做进一步优化处理,致力于寻找更好的实践方案。但这里局限于篇幅我们就不做过多赘述了。
案例二:依赖API调用获取第三方数据
初始方案
同案例一的问题有些类似,案例二的问题也是在将数据同步到业务系统出现的,下图是案例二最初实现的方案。
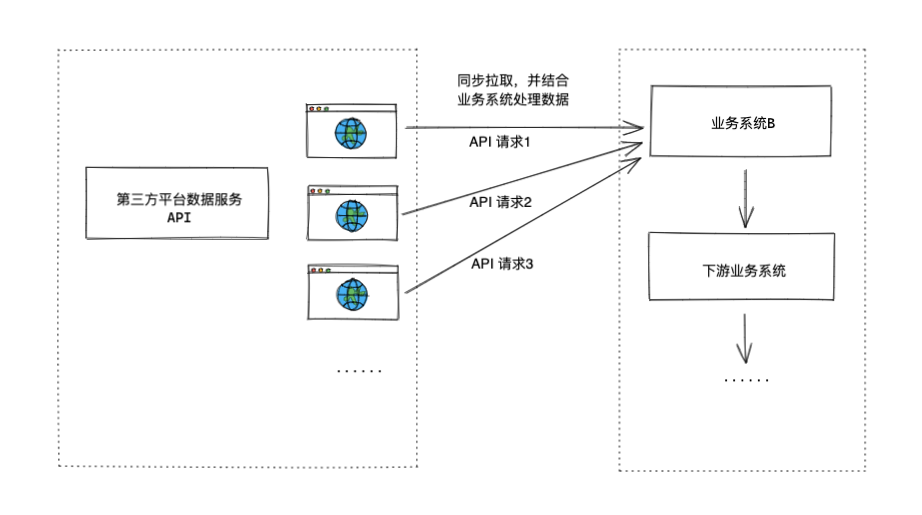
业务系统对接多个第三方平台数据,每天定时请求不同的 API 服务,获取相应数据同步到业务系统。
问题
在业务开发上线初期,经常会有第三方平台数据服务时不时数据提供的晚了,或是数据有异常,这时依赖第三方数据的业务系统就经常会出现问题,而且还很难排查。
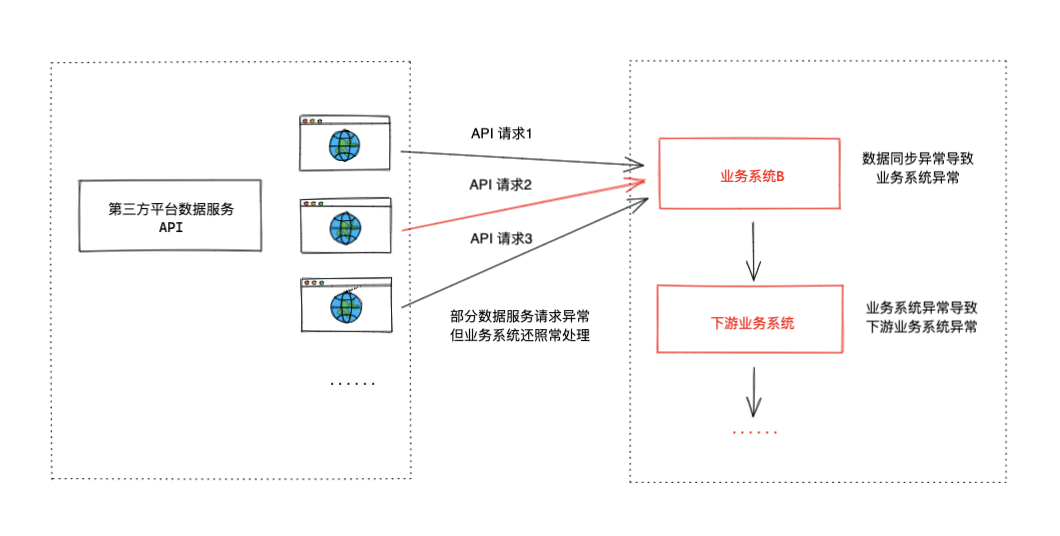
最后解决问题的方案一般都是通知第三方平台修复问题,然后己方业务系统再重新请求 API 补数据来解决问题,整个流程沟通成本很高,难以满足基本的业务诉求。
思考
读者可能会想,这里案例二的问题不是和案例一的问题有点类似吗。其实不是,这里对接的第三方数据是公司外部的,而且不止一个,会有多个。所以这里的问题解决方案就不能按照案例一中的解决方案那样,让所有的第三方平台配合本方业务进行技术调整。
如此分析下来旧的技术实现方案就显得很单薄,且在定位问题、处理问题及修复数据的时候对开发人员就显得很不友好,并且也非常影响数据的准确性和及时修复数据的效率。
优化方案
针对上述问题,我们在对接第三方数据平台的数据服务时,重新设计了如下新的业务架构。
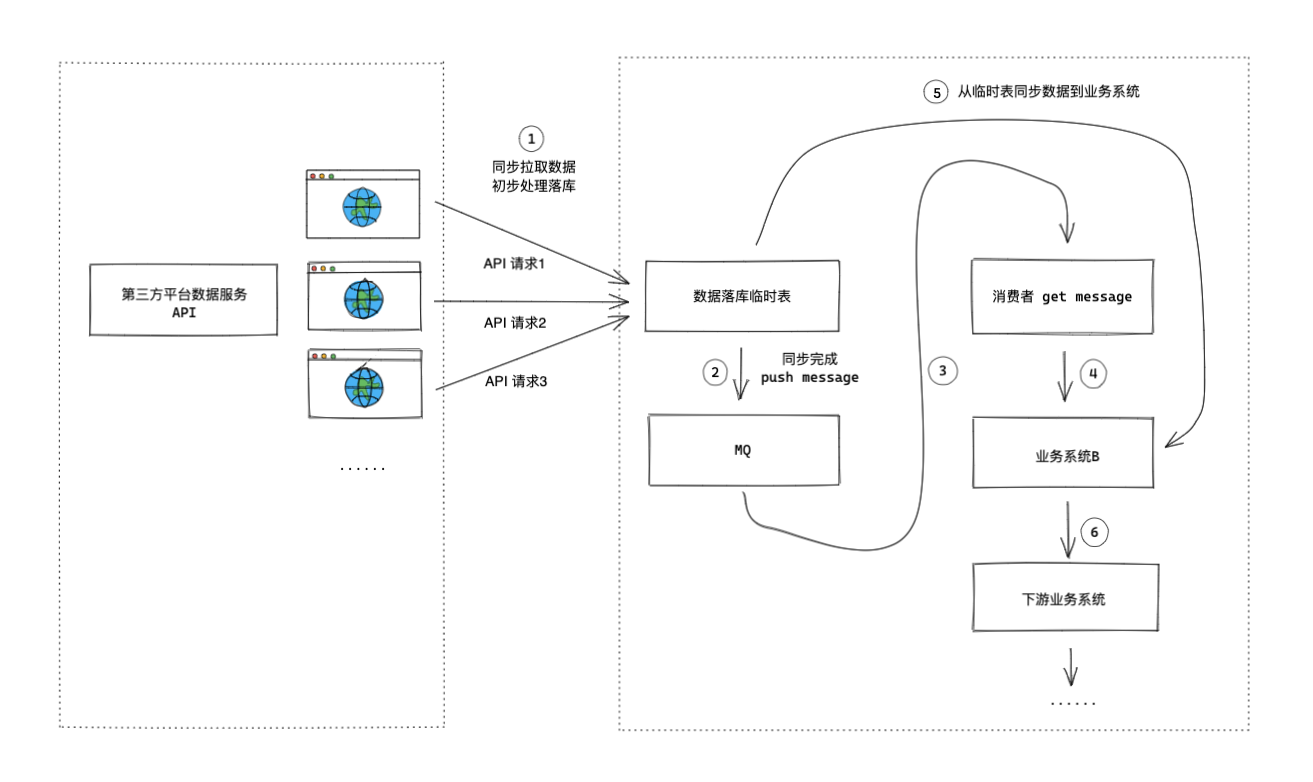
新的技术实现方案如下:
- 增加临时表来存储第三方数据
对接外部第三方平台进行数据同步的时候,首先初步简单处理后就将数据落库。
在一些业务场景中,拿到外部数据后不是直接进行处理,而是先将数据落库是一个比较好的处理方法,方便后续数据出现问题的定位及修复。 - 引入MQ,将业务系统和数据同步操作解耦
这里案例二原技术实现方案中的业务系统和数据同步操作耦合度太高,当数据同步操作出现问题时,业务系统一般都会受到影响。
所以这里引入MQ,当某一维度的数据同步完成后,往MQ发送一条消息,通知消费者该维度数据已处理完成,使业务系统不直接与数据同步操作相关联。 - 消费者及业务系统
消费者从MQ拿到指定维度数据处理完成的信号,通知业务系统再从临时表中找到指定维度下的数据,将其同步到业务系统,并做进一步数据处理操作。
案例二这里具体的技术实现细节限于文章篇幅,就不做过多赘述了。其实所做的技术优化也比较简单,即针对耦合度太高的两个模块引入MQ做了解耦,读者看完业务流程图后应该就能理解了。
三、思考及总结
本文介绍了两个典型的数据依赖案例,及相应问题的优化处理。最后下面列了几点个人的思考总结
- 当我们做需求分析的时候,应该提前考虑到数据增量可能带来的问题,比如数据量短时间快速增加或长时间缓慢增加背后可能隐藏的问题。
- 当己方核心业务需要依赖上游服务的时候,做好上游服务出现问题时的提醒及快速恢复机制。
- 当对接第三方服务的时候,注意做好服务请求及获取到响应数据的记录,以便后期出现问题时能够快速定位、追踪问题。