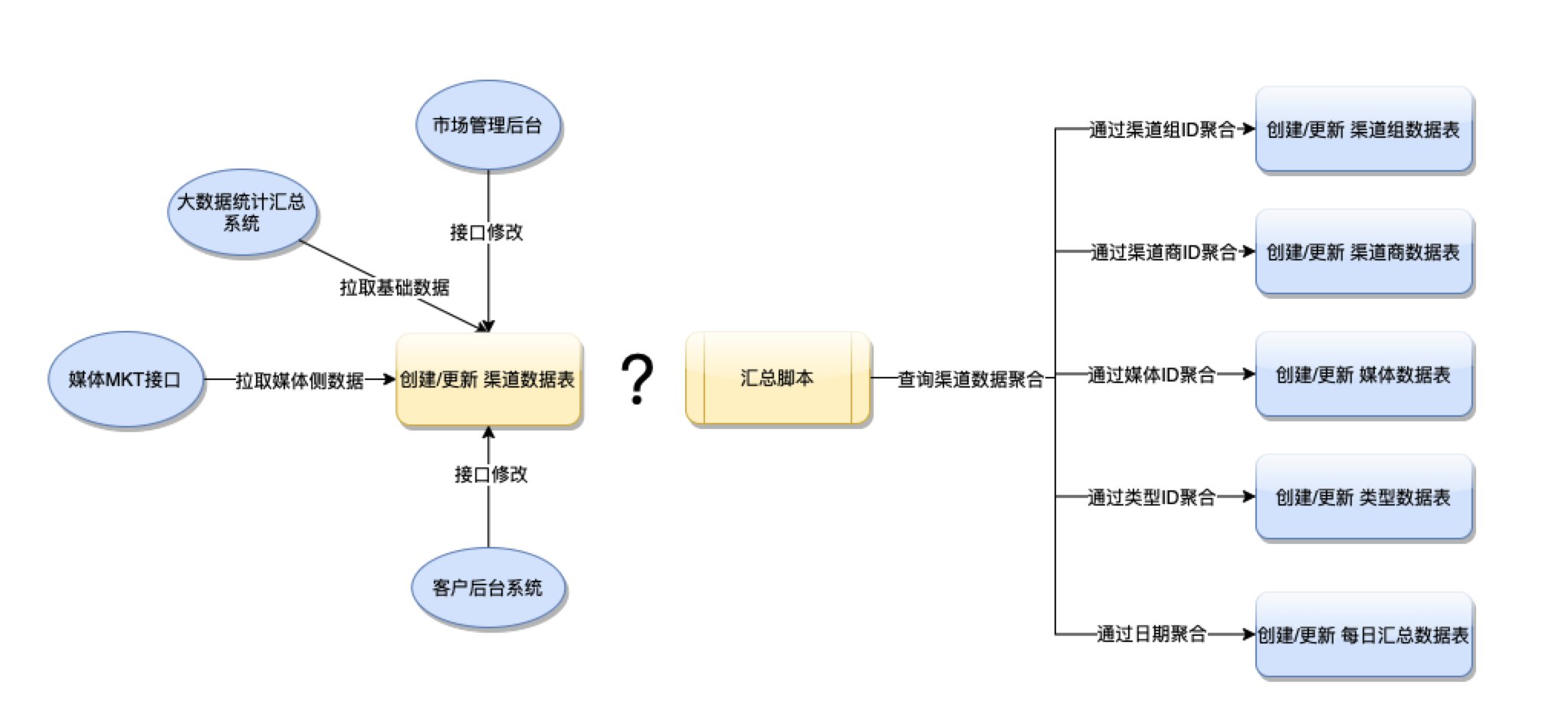
导读:在市场推广业务中,广告主需要评估推广活动的效果。通常,在媒体广告后台中会展示广告计划或者广告创意对应的转化效果数据,主要包括新增、活跃、转化率等指标,然而广告主也会自己定义维度来评估转化效果,七猫市场推广的效果转化记录以及评估由最低的渠道维度,往上的渠道商、渠道组、媒体、类型以及每日汇总维度组成。
问题描述:
渠道的基础数据会在次日从大数据系统汇总数据中获取,但渠道部分数据指标还需要依赖媒体MKT接口拉取获得,由于不同维度上的统计指标不完全统一,例如:媒体维度上增加了LTV指标;每日汇总维度中过滤了部分渠道的部分指标数据。而且渠道数据量每日约6百万,总数据量已超过3亿。因此,各个维度的汇总数据不能实时查询渠道数据聚合汇总完成,而是脚本查询从库表(我们应用了AnalyticDB作为从库)聚合后写入对应的维度记录表中,后台查询对应的汇总表展示数据。在实际的业务中,我们遇到了渠道数据更新后,往上的维度何时去汇总的问题。
业务逻辑图示:
方法思路及问题分析
一 实时触发汇总:代码耦合,触发频率高,资源浪费
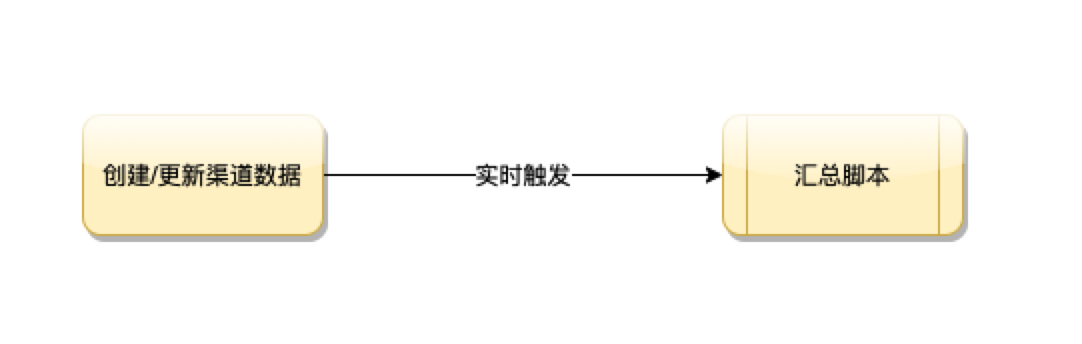
在渠道数据修改的逻辑中同步调用汇总的逻辑,显然是不可行的。一:部分修改是前端接口请求修改,实时触发汇总会请求超时;二:渠道数据的更新在次日会持续一天。在这种架构设计下,汇总脚本会在次日频繁的触发,由于数据维度以及指标较多,造成资源浪费;三:如果有新的业务逻辑更新渠道数据,也要耦合调用汇总的方法。
二 异步定时触发汇总:实时性差
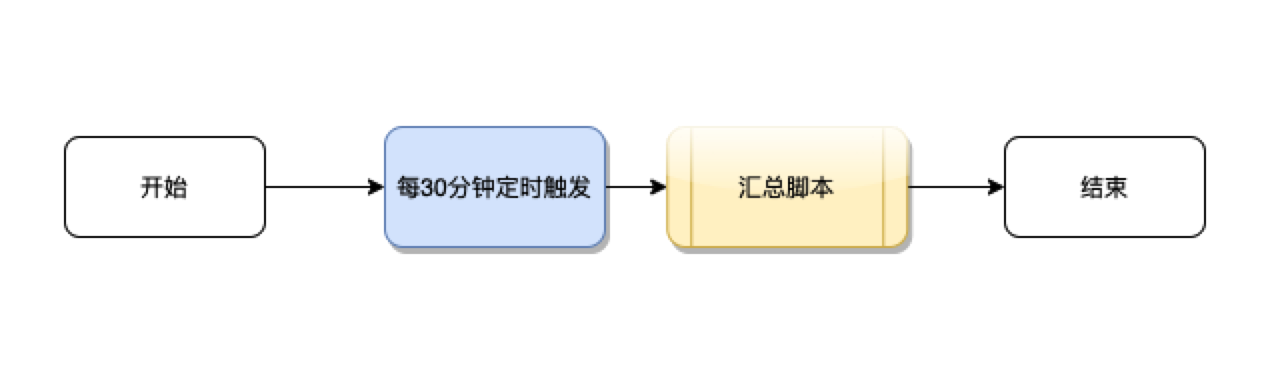
在与产品沟通确认后,我们采用异步定时汇总的方式,定时脚本每30分钟执行一次汇总,由于在汇总脚本中存在清零操作(将汇总数据重置为0)后再更新数据,在实际业务中,运营人员多次反馈数据突然没有了。由于30分钟的时间间隔,汇总数据与渠道的汇总数据也经常不一致。此外,历史的渠道数据也会发生更新,因此汇总的周期也很难设置,设置周期越长,影响的数据越多,脚本效率越差;设置周期较短,历史的汇总数据与渠道汇总数据又不一致。
三 异步定时触发优化:时间周期参数不好设置
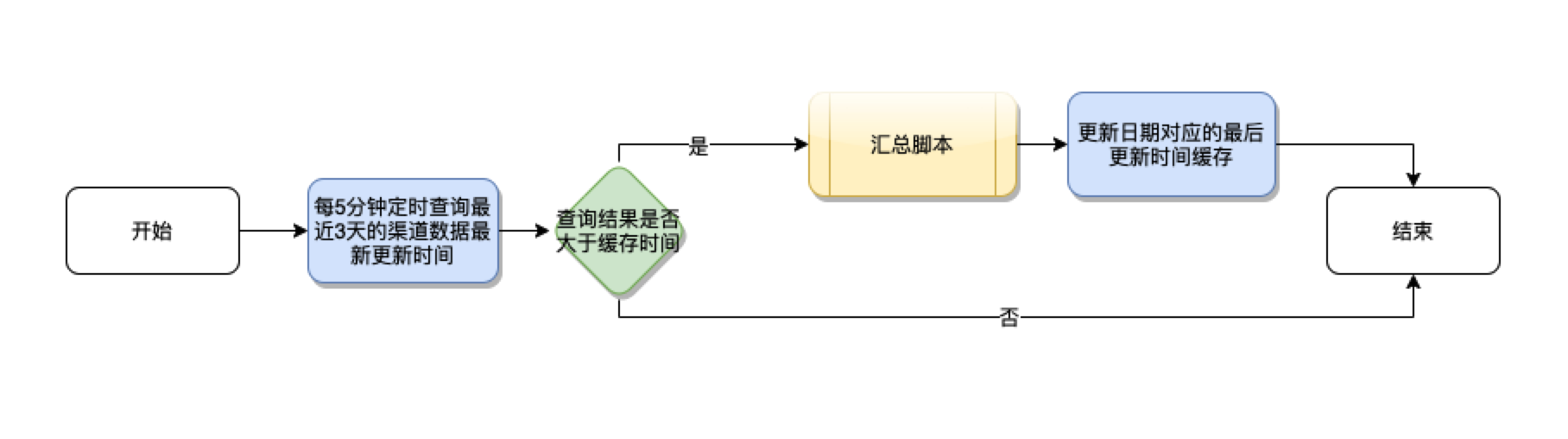
继续采用异步定时触发的设计,减少无效汇总更新的次数。一开始,我们采用定时查询渠道最后更新时间判断数据是否有更新来触发汇总逻辑,然后缓存最后更新时间,对于最近一天的数据,这种方式很高效,但随着业务的发展,越来越多的业务导致历史的渠道数据会发生变化,比如次日留存数据,七日留存数据,三十日留存数据等,因此,如果要满足业务需求,异步的脚本中,每一次执行至少需要遍历查询近三十天数据的最后更新时间。在与产品沟通后,异步频率设置为5分钟一次,遍历查询最近3天渠道数据的最后更新时间并判断是否触发汇总脚本。同时,在凌晨设置定时脚本,查询遍历最近一个月的最后更新时间对比触发汇总脚本。然而,在实际的业务中,产品还是经常提任务让我们更新一个月前某一天的汇总数据,或者手动执行某一天的汇总脚本。这种方式还是不能完全解决问题。
四 应用Canal:简单,高效
在对我们遇到的问题仔细分析后,我们希望有一个中间件,能够订阅渠道数据的更新,然后消费更新数据,重点是获取到更新数据的日期,定时去重后执行汇总。在一次我们研发中心内部组织的技术分享交流中,我们其他小组开发人员介绍到了Canal,它能够实现 MySQL 数据库增量日志解析,提供增量数据订阅和消费,正好我们的渠道数据主库是MySQL,场景也很符合。因此我们基于Canal设计了最终的方案。
具体方案
流程图
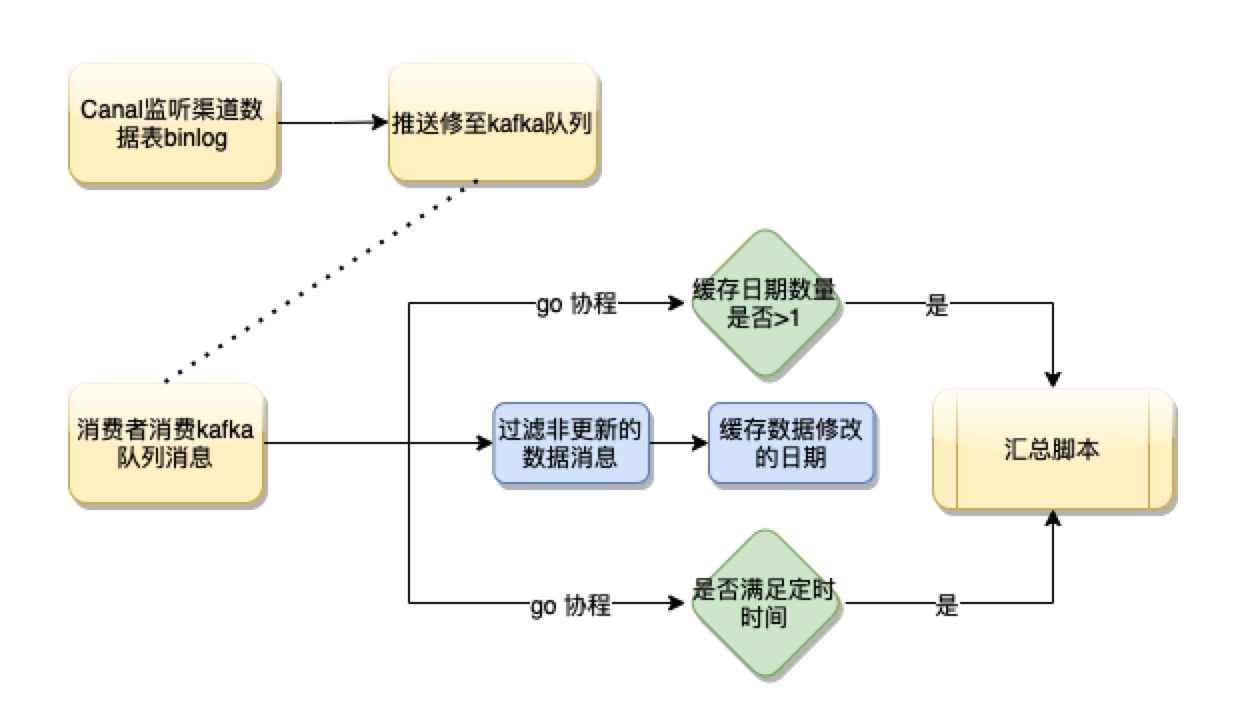
在Canal中配置监听渠道数据表binary log日志,将更新数据推送至kafka队列中,异步消费者消费消息,过滤非更新操作数据(渠道数据不存在删除),解析消息中的日期并缓存,然后定时5分钟触发汇总脚本,或者缓存日期数量大于1(表示有历史数据更新)时触发汇总脚本。设置缓存日期数量大于1就触发汇总脚本是因为历史日期的渠道数据修改量和频率通常较小,运营人员对汇总的实时性要求高。
对比之前的方案,应用Canal能够更加准确高效的触发汇总,解决之前方案的所有缺点
优化:
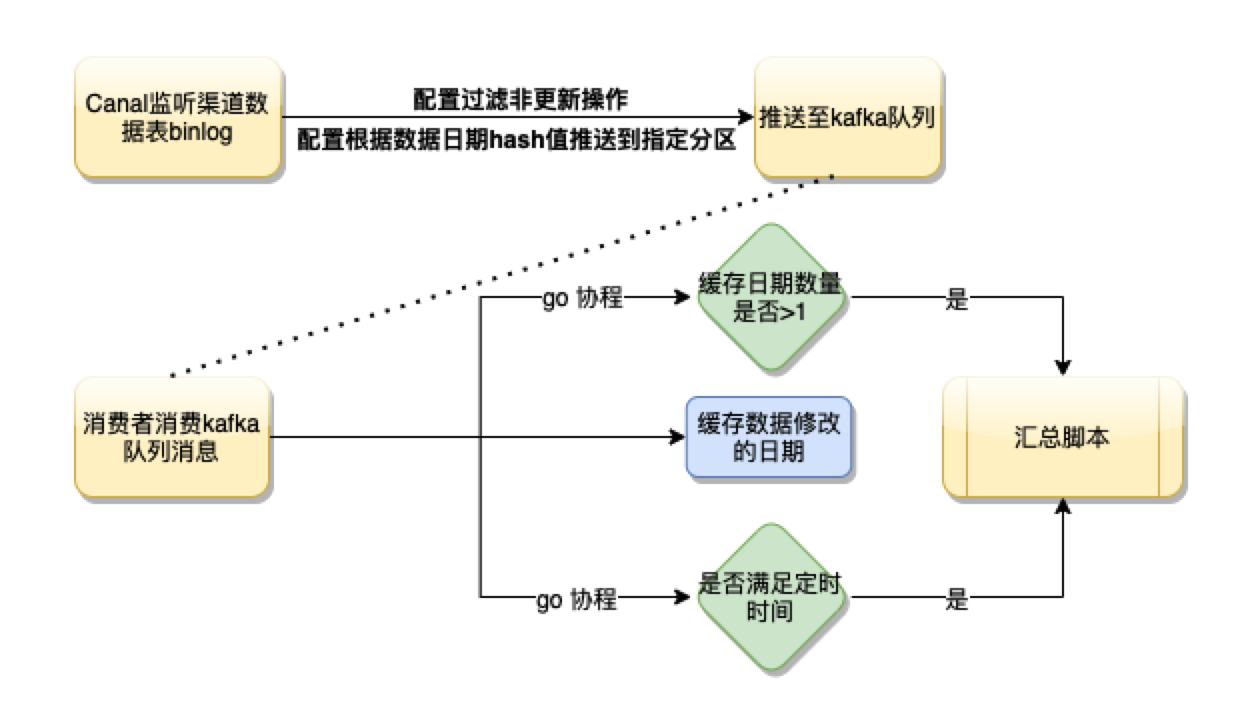
一 基于Canal的方案上线后,我们发现消息数量特别大,凌晨还会有少量的数据堆积,经过分析后,我们发现凌晨有大量的数据插入,但我们的汇总不关心数据的插入,Canal的配置正好也提供数据变更类型的过滤。因此,我们优化了Canal的配置,直接忽略了渠道数据表insert,delete操作日志,kafka消息数量明显下降,消费效率也有提升

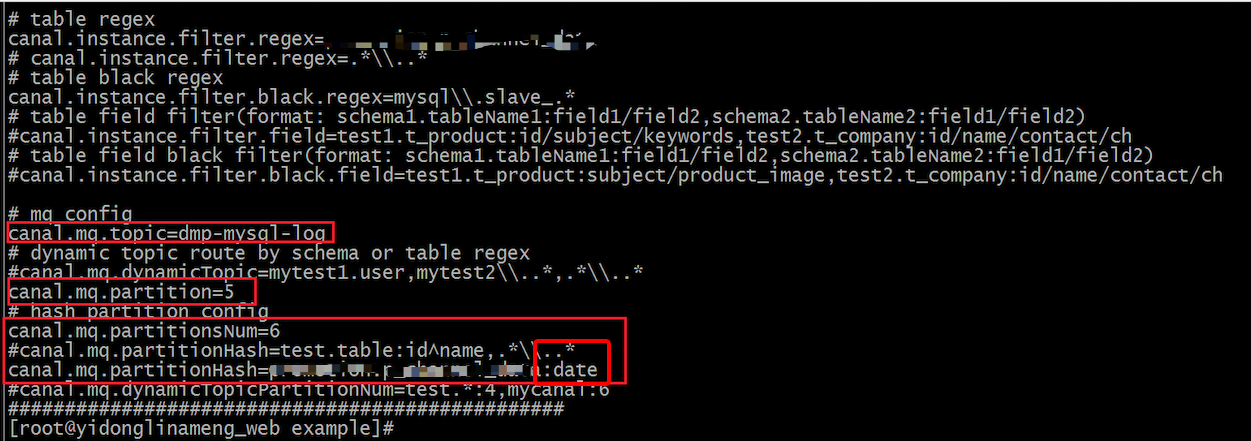
二 随着汇总逻辑中指标的增加以及业务逻辑的增加,队列消费经常出现消息堆积。经过对消费日志的分析,发现如果更新的数据中穿插着不同的日期,就会导致我们的脚本一直在更新,因为在不断的触发缓存更新日期数量大于1的逻辑,近似回到了第一种方案的情景。分析消费的逻辑,结合kafka分区的特性,如果同一个分区中的消息日期是一致的,那么只有定时的逻辑才会被触发,消费的效率就会很高,查看Canal中kafka topic的配置项,能根据表以及字段等信息的hash值来设置分区,因此,我们设置根据渠道表日期字段的hash值来确定分区,这样,相同日期的更新数据保证在相同的分区上,消费者就会触发定时器更新的逻辑,消费效率更加高效
总结
Canal的工作原理就是把自己伪装成MySQL slave,模拟MySQL slave的交互协议向MySQL Mater发送 dump协议,MySQL mater收到Canal发送过来的dump请求,开始推送binary log给Canal,然后Canal解析binary log,再发送到存储目的地,比如MySQL,kafka,Elastic Search等等,它的特性使得我们可以简单的应用它通过数据库表数据状态来解耦业务,一方面,通过简单的配置就能实现数据源发布订阅模型,操作简单;另一方面,订阅数据的存储支持多种方式,可满足不同的业务类型,例如:通过kafka可以实现多个业务同时订阅一个数据源,各自独立实现业务逻辑;通过redis实现业务cache的刷新等。在有相似的场景下,应用Canal能够快速解耦业务,方便扩展,设计出更加高效的架构。