本文是“Agent 工程化实践”系列第一篇,侧重点是知识与代码底座:如何把业务文档、多仓库代码和历史经验整理成 Agent 可查询、可引用、可验证的上下文层。本文面向外部技术分享,已去除具体公司、业务、人员、内部系统地址、截图链接和生产数据细节。
系列说明
Agent 工程化不是单点工具接入,而是一组围绕上下文、运行时、权限、观测和治理展开的系统工程。本文聚焦其中的上下文基础设施:如何组织业务文档、代码仓库与历史经验,让 Agent 的回答和行动建立在可检索、可追溯、可验证的依据之上。
1. 背景:AI 真正缺的不是更多文档,而是可靠上下文
很多团队在引入 AI 编程助手或研发 Agent 后,很快会遇到同一个问题:模型能力并不是唯一瓶颈,真正影响效果的是上下文质量。
业务规则散落在协作文档、历史需求、复盘记录、会议纪要和聊天记录里;代码分布在多个仓库中,模块边界、调用链和历史决策往往只存在于资深同学的经验里。AI 能帮忙写代码、整理方案、生成测试用例,但如果它拿不到稳定、可信、可追溯的上下文,就会出现三类典型问题:
现象 | 根因 | 后果 |
|---|---|---|
同一个问题每次答案不一致 | 检索到的材料版本、口径和权威性不同 | 团队不敢信任 AI 结论 |
文档里有资料但 AI 找不到 | 标题、术语、目录和用户提问不一致 | 知识沉淀无法转化为生产力 |
文档答案和代码实现不一致 | 文档滞后或缺少代码校验 | 排障、设计和测试判断被误导 |
因此,知识与代码底座的目标不是“把所有资料喂给模型”,而是把文档、代码和历史经验整理成 AI 能查询、验证、引用和持续更新的上下文系统。
2. 本篇主线:两条知识线并行
实践中,我们把知识与代码底座拆成两条线:
知识线 | 解决的问题 | 典型材料 | 使用方式 |
|---|---|---|---|
LLM-Wiki | 让业务文档、规范、复盘、流程变成可追溯的主干知识 | 协作文档、需求、技术方案、复盘记录 | 回答“规则是什么、流程怎么走、历史为什么这么定” |
GitNexus 代码知识库 | 让 AI 能快速理解多仓库代码结构和实现位置 | 源码、目录结构、接口、调用链、变更记录 | 回答“代码在哪、如何实现、改动影响哪里” |
两条线不是互相替代,而是互相校验:文档提供背景和业务语义,代码提供最终实现依据。对于研发排障和技术方案,原则始终是:
文档有明确定义时,仍需代码验证;文档没有精确匹配时,直接下钻代码,禁止拼凑结论。
3. LLM-Wiki:把原始资料编译成主干知识
普通文档库适合人阅读,但不一定适合 Agent 使用。普通 RAG 可以检索原文,但每次问答都要重新从原文里综合,很容易受旧文档、弱相关材料和口径冲突影响。LLM-Wiki 的做法是增加一层“可维护知识层”:先把原始资料整理为证据笔记,再把稳定、可复用、可追溯的结论沉淀为主干页面。

这一层的关键不是摘要,而是分层治理:
层级 | 负责什么 | Agent 怎么用 |
|---|---|---|
原始事实层 | 保留原文、附件、同步缓存和更新时间 | 发生争议或冲突时回查 |
提取层 | 提取文本、节点清单、索引和增量差异 | 支撑检索、重建和质量检查 |
证据笔记层 | 按来源或主题整理候选事实 | 补充来源、边界条件和上下文 |
主干结论层 | 承载当前稳定口径 | 回答时优先引用 |
一个有效的知识库不应该追求页面越多越好,而应该追求少量主干页能覆盖高频问题,并能回到证据和原文。
4. 新资料如何进入知识库
新文档进入知识库时,不应该只生成一篇摘要。更好的做法是按信息类型拆分:
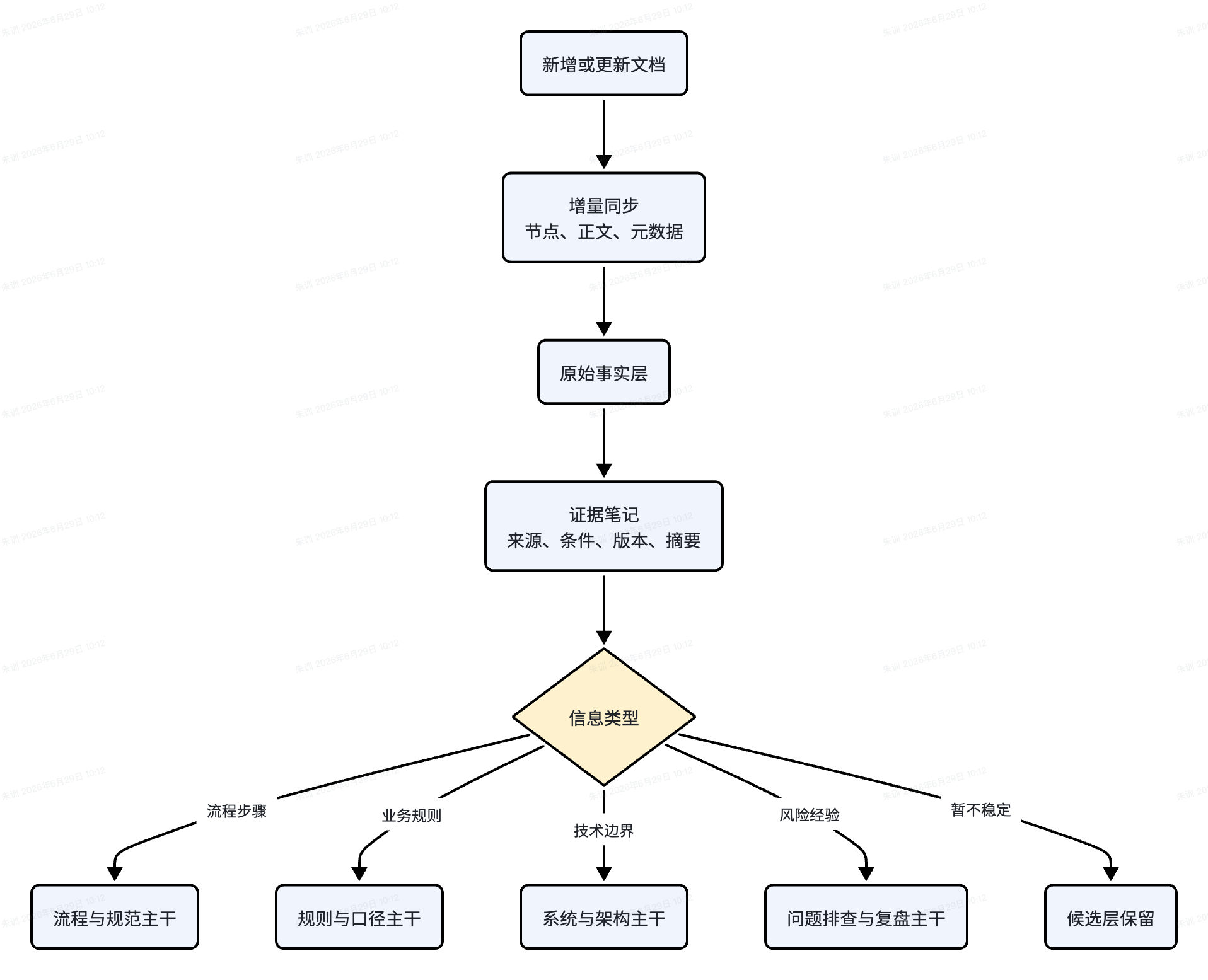
这能避免两个常见问题:
- 一篇长文只有一个摘要,导致里面的规则、流程、风险点无法被精确复用。
- 多篇历史文档互相冲突,Agent 在回答时被迫“投票”,无法判断当前口径。
5. Agent 如何查询知识库
这里的“Agent 查询”只讨论知识访问路径,不讨论角色调度和执行权限。知识库查询不是一次性把大量文档塞给模型,而是先定位范围,再读取少量高质量材料。推荐路径如下:
步骤 | 做法 | 避免什么 |
|---|---|---|
找范围 | 用关键词、标题、标签、元数据、少量同义词和全文检索 fallback 定位候选页面 | 让模型从超长目录里猜 |
读主干 | 优先读取流程、架构、规则、复盘等主干页 | 直接读取大量原始资料 |
查证据 | 对关键结论补充证据笔记和来源 | 无来源判断 |
回原文 | 冲突、不确定或高风险结论回查原文 | 旧口径被自信引用 |
一个好的回答应包含:当前口径、来源依据、适用边界和不确定性说明。
6. GitNexus 代码知识库:让 AI 能找到代码
业务知识解决“为什么”,代码知识库解决“在哪里”和“怎么实现”。在多仓库研发环境中,Agent 直接搜索源码会遇到几个问题:
- 仓库太多,先看哪个仓库就很难判断。
- 目录、类名、接口、路由、任务、消费者之间关系复杂。
- 单纯关键词搜索召回弱,语义问题需要上层推理补足。
- 代码会持续变化,知识库必须跟着增量更新。
代码知识库采用 GitNexus 的思路:基于 Git 历史、目录结构和代码依赖,增量生成结构化 Markdown Wiki,再用关键词检索和 Agent 推理结合。这里保留 GitNexus 这个技术名词,因为它是方案可复用性的关键,不属于业务敏感信息。
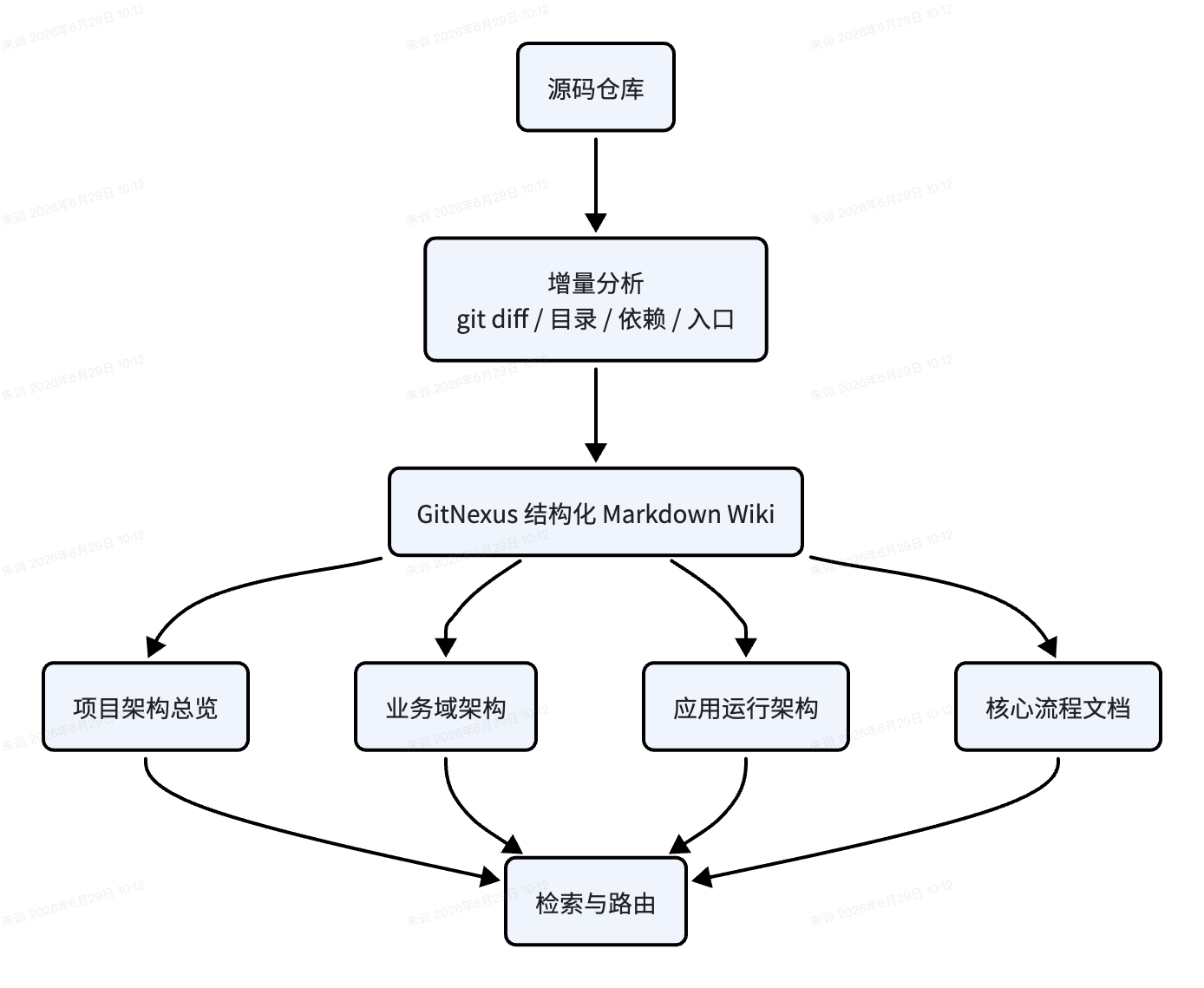
代码知识库的文档结构建议保持稳定:
文档 | 作用 |
|---|---|
项目架构总览 | 技术栈、目录结构、核心模块、外部依赖 |
业务域架构 | 这个仓库负责什么,核心实体和边界是什么 |
应用运行架构 | 接入层、服务层、基础设施、外部依赖如何协作 |
核心流程文档 | 关键业务链路、状态流转、异步任务、异常处理 |
这类文档不是替代源码,而是帮助 Agent 快速定位源码。
6.1 为什么选择 GitNexus 这类结构化代码 Wiki
直接让 Agent 读源码虽然准确,但成本高、入口不稳定,尤其在多仓库场景中,Agent 常常先卡在“该看哪个仓库、哪个模块、哪条链路”。GitNexus 的价值在于先把代码库编译成一层人和 AI 都能读的导航层。
选型点 | 说明 | 带来的收益 |
|---|---|---|
Markdown 产物 | 生成物是普通文本,可审计、可 diff、可人工修订 | 不被黑盒索引绑定,方便进入 Git 流程 |
增量驱动 | 基于 git diff 处理变更文件,而不是每次全量重建 | 更新成本可控,适合多仓库周期刷新 |
结构化分层 | 固定生成架构、领域、应用、流程等文档 | Agent 有稳定阅读顺序 |
与业务知识融合 | 代码 Wiki 可以和 LLM-Wiki 一起检索 | 回答同时具备业务背景和实现依据 |
语义短板上移 | BM25 负责精确召回,模糊意图由 Agent 拆关键词 | 不必一开始就引入复杂向量系统 |
6.2 GitNexus 文档如何被 Agent 使用
Agent 进入一个陌生仓库时,不应该先盲扫所有源码,而是按“总览到专题,再到源码”的顺序读取:
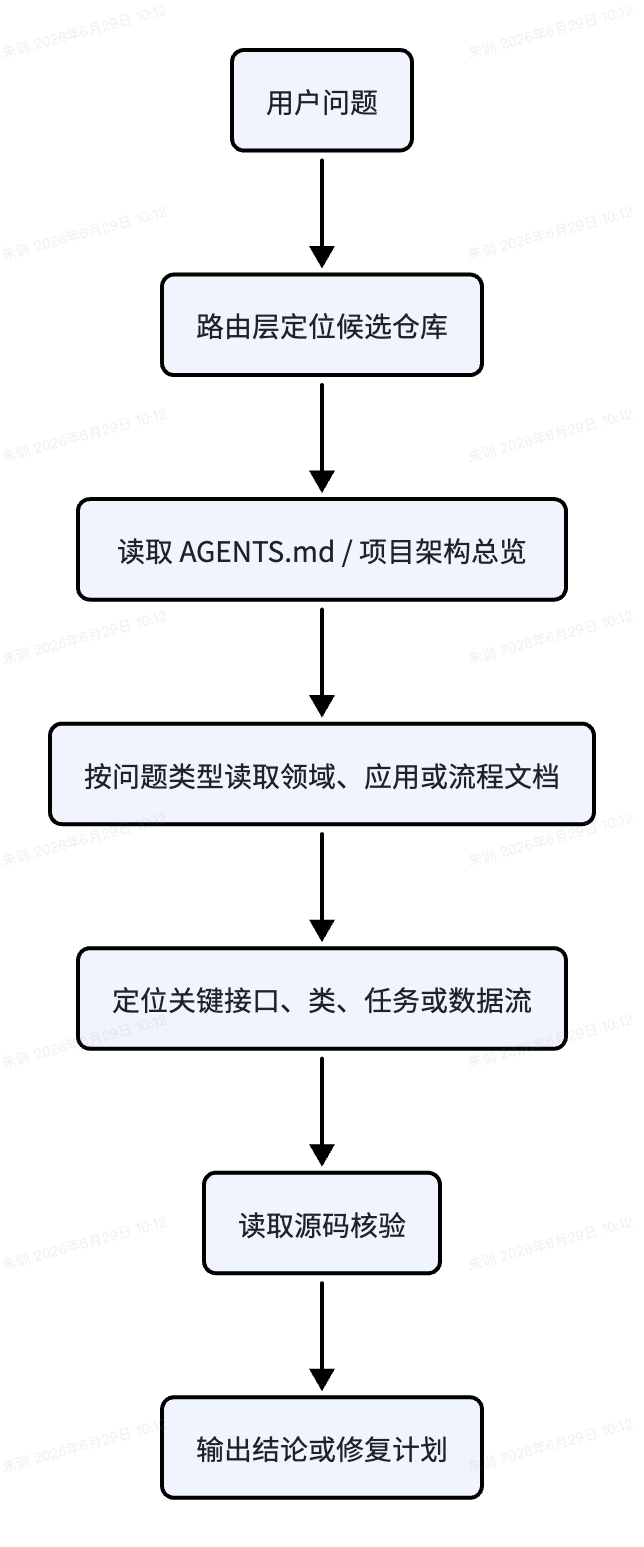
这种顺序有两个好处:一是减少无效源码搜索,二是强制最终结论回到代码核验,避免“文档看起来合理但实现不是这样”的问题。
6.3 自动刷新流水线
代码知识库需要随着代码变化持续更新。一个典型流水线可以拆成四步:

实践中可以只对有新提交的仓库触发生成。对几十个仓库的团队来说,这比全量扫描更容易稳定运行。
7. 检索架构:路由、召回、融合
实践中,代码知识库和业务知识库可以采用双轨检索。工具层可以通过 MCP Server 暴露为 kb_search、kb_answer、kb_read_page 等能力,让 Agent 以工具调用方式访问知识库,而不是直接扫描文件系统。

其中,路由层非常重要。它帮助 Agent 从模糊描述定位到目标模块或仓库,例如:
- 根据域名、接口、页面路由或任务名映射到仓库。
- 根据业务总览图判断模块边界。
- 根据工具说明选择业务检索、代码检索还是直接读文件。
检索层可以先采用 BM25、分词、标题标签和全文搜索 fallback。向量检索不是起点必需品,只有当高频语义召回确实不足时,再补充 embedding 索引会更稳。
7.1 MCP 化:把知识库变成工具,而不是一堆文件
MCP Server 的作用是把知识库包装成稳定 API。这样 IDE、群聊 Agent、CLI Agent、定时任务都可以复用同一套检索和读取逻辑。
工具类型 | 示例能力 | 作用 |
|---|---|---|
检索与回答 | kb_search、kb_answer、kb_read_page | 查找页面、合成回答、读取原文 |
变更与状态 | kb_recent_changes、kb_sync_status | 判断知识库是否新鲜、是否同步异常 |
统计与观测 | kb_cache_stats、kb_query_stats | 查看缓存、命中率、查询趋势 |
7.2 BM25+jieba 与 fallback
一个轻量但有效的检索链路如下:
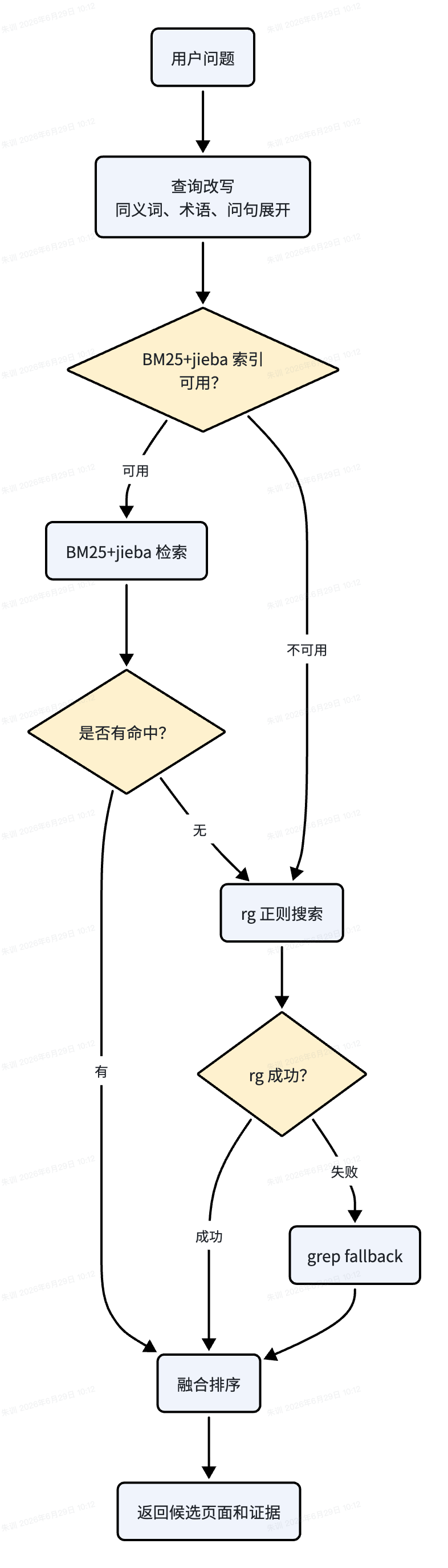
排序时可以综合路径权重、层级权重、标题命中、BM25 分数和来源新鲜度。业务主干页、代码架构页、source-note、raw 原文不应该一视同仁;它们在回答中的角色不同。
8. 质量治理:知识库也会老化
知识库上线后,真正的挑战是持续可信。常见风险包括:
风险 | 表现 | 治理方式 |
|---|---|---|
漂移 | 主干结论和原文逐渐不一致 | 抽样回查原文和证据 |
孤岛 | 证据笔记没人引用 | 回挂到主干页或归档 |
旧口径 | 历史材料被当成当前规则 | 主干优先,历史材料降级为证据 |
断链 | 引用页面不存在或来源失效 | 链接检查和修复 |
零结果 | 用户问法无法命中材料 | 补标题、标签、别名或少量同义词 |
治理流水线可以分为三类:
类型 | 作用 |
|---|---|
质量检查 | 检查冲突、过时、断链、孤岛、漂移 |
固定问题集评测 | 验证高频问题能否命中正确页面 |
真实问题回流 | 从群聊、IDE、Agent 查询中发现零结果和错误答案 |
高风险口径必须保留人工确认。AI 可以做整理、摘要、回挂和初步评测,但不能自动把未经确认的结论推进最终主干。
9. 知识与代码底座在研发流程中的价值
知识与代码底座建好后,可以支撑多个场景:
场景 | 知识库怎么发挥作用 |
|---|---|
需求理解 | 从历史规则、流程和架构中补齐背景 |
技术方案 | 根据代码结构和历史决策识别影响范围 |
问题排查 | 先查业务背景,再定位实现和调用链 |
测试用例 | 结合需求、现有实现和历史缺陷生成检查清单 |
新人上手 | 从主干页和代码 Wiki 快速建立系统认知 |
特别是在测试用例生成和代码 review 中,三源融合效果明显:需求文档提供验收标准,代码知识库提供实现路径,业务知识库提供历史风险和边界条件。
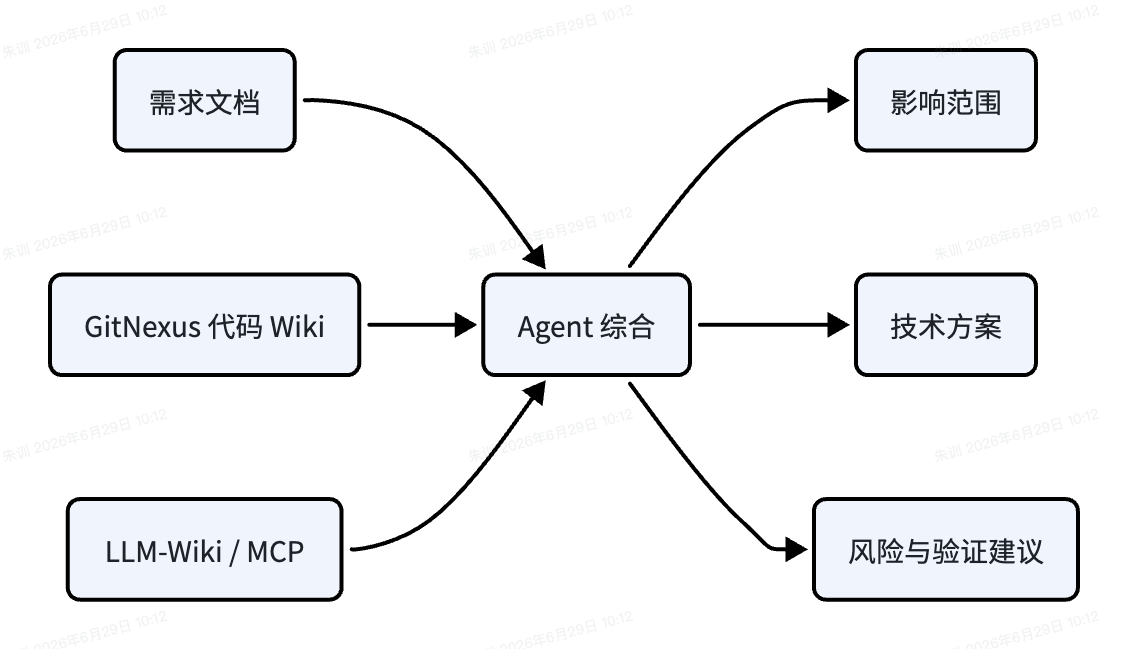
9.1 基于知识库的开发文档生成
技术方案或开发文档不应只靠需求描述生成。更稳的输入是三源合并:
输入 | 提供什么 |
|---|---|
需求文档 | 业务目标、验收条件、功能边界 |
GitNexus 代码知识库 | 当前模块结构、接口定义、调用链、数据模型 |
LLM-Wiki / MCP | 历史设计决策、规则口径、已知风险 |
生成流程可以是:
9.2 基于知识库的测试用例生成
测试用例生成也可以用类似三源融合:
来源 | 用途 |
|---|---|
需求文档 | 提取验收条件、适用对象、状态机、页面和数据结果 |
GitNexus / 当前实现 | 提取方法签名、入参校验、调用链、已有测试模式 |
LLM-Wiki / 历史复盘 | 补充历史缺陷、边界场景、回归风险 |
生成时建议覆盖五类用例:主路径、边界条件、异常路径、分支覆盖、回归防护。生成结果应作为检查清单和 review 输入,而不是宣称完全替代人工测试。
9.3 边界与局限
知识与代码底座能显著降低“找不到上下文”的成本,但它不等于自动正确。对外分享时需要把边界讲清楚:
局限 | 表现 | 应对方式 |
|---|---|---|
文档准确性 | 历史文档可能和当前实现不一致 | 文档只作背景,关键结论回到源码核验 |
代码知识库滞后 | 大重构或跨仓库改动后,GitNexus 产物可能未及时刷新 | 变更后触发增量生成,必要时手动全量重建 |
BM25 弱语义 | 用户问法和文档术语差异大时可能漏召回 | 补标题、标签、别名和少量同义词;高频场景再考虑向量检索 |
测试用例不完整 | Agent 只能覆盖显性路径,隐性业务规则仍可能遗漏 | 将用例作为检查清单,人工补充领域知识 |
自动治理风险 | AI 自动合并主干口径可能引入错误结论 | 高风险口径必须人审确认 |
因此,知识与代码底座的目标不是替代研发判断,而是让判断有更好的上下文、更清楚的来源和更低的检索成本。
10. 本篇落地建议
可以按三阶段推进:
阶段 | 目标 | 关键动作 |
|---|---|---|
P0 可用 | 让 Agent 能查到高频知识 | 建主干页、同步原文、接入基础检索 |
P1 可信 | 让回答可追溯、可验证 | 建证据笔记、来源引用、固定问题集 |
P2 可持续 | 让知识库能自我更新和治理 | 增量同步、质量检查、真实问题回流 |
最小可行版本不需要大而全,只需要做好五件事:
- 保留原文和来源,不丢证据。
- 把稳定口径沉淀到少量主干页。
- 让 Agent 优先读主干,再按需查证据和原文。
- 为代码仓库生成结构化导航文档。
- 用固定问题集和真实问题反馈持续修正。
11. 总结
知识与代码底座的本质,是把“认识这个系统”的资料、代码和经验组织成 AI 可以调用、可以验证、可以更新的形式。
LLM-Wiki 解决业务和流程知识的可信组织;GitNexus 代码知识库解决多仓库实现的快速定位;MCP 和 BM25+jieba 检索让这些知识成为 Agent 可调用的工具。它不是一次性文档整理项目,而是一套面向 Agent 时代的上下文基础设施。