一、背景
内容生态是平台核心护城河,优质新书冷启、生态培育与爆款孵化,直接决定平台长期内容竞争力与商业化天花板,对于七猫原创优质小说,推荐系统会通过扶持系数提高书籍的曝光,助力优质内容前期成长;扶持总流量有限,如何高效的利用有限流量扶持尽可能多的书籍,是扶持策略需要解决的重点问题。
七猫生态扶持策略经过长期迭代,升级多个版本,从V1基础扶持策略,到V2PID控制策略, 到目前的V3强化学习策略版本,依托时序强化学习全局序列决策能力,可实现扶持权重智能动态调配,兼顾短期分发指标与长期内容生态价值,构建更精细化、长效化的智能内容扶持体系。
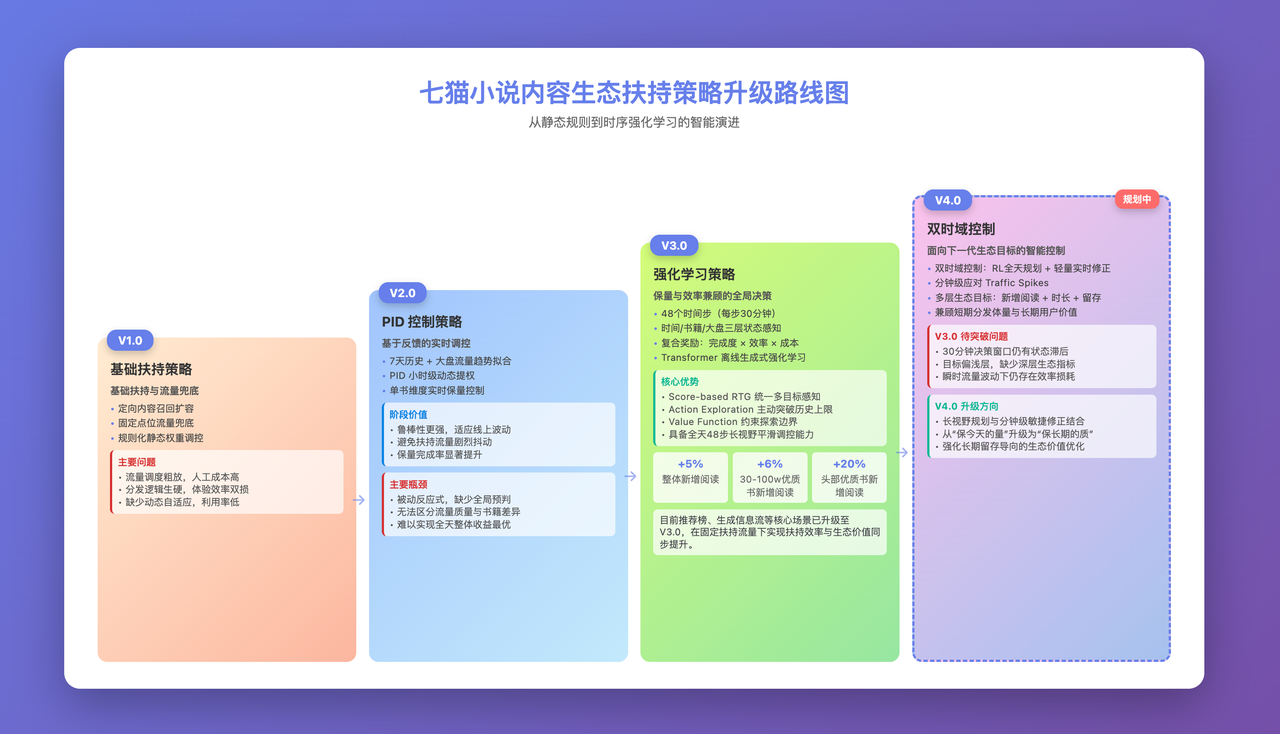
本文重点讲述基于生成式强化学习的动态调权策略。在总扶持流量受限的前提下,策略将内容扶持力度建模为时序序列优化问题,通过价值函数引导探索,利用Transformer架构对全天48个时间步的全局状态进行建模,生成适配不同书籍的最优扶持系数序列。设计的复合奖励函数确保模型在提升新增阅读量的同时,兼顾转化效率与扶持系数约束。
实验表明,该策略在固定流量下显著提升了书籍曝光效率,尤其在30-100万字的优质连载书中效果突出,为内容平台的资源分配提供了新的技术范式。
二、强化学习与生成式强化学习核心介绍
强化学习(Reinforcement Learning, RL)是机器学习的重要分支,核心是通过智能体(Agent)与环境(Environment)的持续交互,学习最优的序列决策策略,以最大化长期累积奖励。
强化学习与监督学习、无监督学习是机器学习的三大范式:
| 学习方式 | 类比 | 典型应用 |
| 监督学习 | 做题册+标准答案,反复练习,参加考试 | 图像识别、语音识别 |
| 无监督学习 | 没有答案,自己归纳规律 | 大模型预训练、聚类 |
| 强化学习 | 写作文,老师打分,自己总结哪里好哪里差 | 游戏AI、机器人 |
与监督学习依赖标注数据、无监督学习侧重数据聚类不同,强化学习无需提前提供“正确答案”,而是通过“试错”机制,让智能体在动态环境中不断调整动作,逐步掌握适配场景的决策逻辑,其核心特征是“时序性”与“目标导向性”。
强化学习的核心框架由状态(State)、动作(Action)、奖励(Reward)三大要素构成:状态是智能体感知到的环境信息,动作是智能体做出的决策行为,奖励是环境对动作的反馈信号,智能体的核心目标就是通过调整动作序列,实现长期奖励的最大化。近年来,强化学习的应用已从游戏领域(如AlphaGo击败人类棋手),蔓延到所有需要序列决策的行业,包括内容分发、广告出价、机器人控制、金融交易等,成为解决动态环境下多目标优化问题的核心技术。
强化学习的几个关键概念,用"出租车司机开车"来理解:
- 状态(State):当前所在位置、油量、时间——即"当下处境"
- 动作(Action):往左走、往右走、等待——即"可以做什么"
- 奖励(Reward):送到乘客得到车费,走错路扣时间——即"这次做得好不好"
- 策略(Policy):司机的驾驶经验——即"在什么情况下做什么"
- 价值函数:评估"当前这条路长远来看能不能多赚钱"——即"这个决策的长期价值"强化学习要解决的问题就是:如何让司机通过不断跑单,总结出一套"长期总收入最大化"的接单、行驶策略。
生成式强化学习(Generative Reinforcement Learning)是强化学习与生成式模型的结合体,是当前RL领域的前沿方向。它在传统强化学习的基础上,融入了生成式模型(如Transformer、GAN等)的序列生成能力,打破了传统RL对动作空间的限制,能够生成更具灵活性、多样性的最优动作序列,同时具备更强的全局视野和探索能力。
与传统强化学习相比,生成式强化学习的核心优势体现在两方面:
- 序列生成能力,能够基于历史轨迹数据,生成适配全局场景的连续动作序列,而非单一时间步的局部最优动作.
- 探索-利用的平衡能力,通过生成式模型的引导,既能够利用历史经验保证决策的稳定性,又能主动探索未出现过的更优策略,突破历史数据的局限.
其中,基于决策Transformer(DT)的生成式RL模型最为典型,它将“状态-动作-奖励”序列视为文本序列,通过Transformer架构预测下一个最优动作,类似大模型生成文本的逻辑,兼具稳定性与灵活性。
传统强化学习多适用于简单、静态的决策场景,而生成式强化学习则更适配复杂、动态、多目标的工业场景,能够有效解决传统RL在长时序决策、动作空间复杂、多目标平衡等方面的短板,为工业级序列决策问题提供了更高效的解决方案。
三、强化学习在七猫内容扶持的实践应用
在七猫小说的内容分发场景中,优质新内容的启动扶持是核心业务痛点,而这一场景恰好是强化学习(尤其是生成式强化学习)的核心应用场景。七猫的内容扶持策略,本质是在总曝光流量有限的前提下,给特定书籍叠加扶持系数,提升其展示竞争力,进而实现新增阅读量、转化效率、扶持成本的多目标优化,这是一个典型的多目标、长时序、动态环境的序列决策问题,与强化学习的核心适配度极高。
七猫内容扶持的核心难点有:
- 预算有限:总曝光流量固定
- 扶持系数需控制:避免干扰整体推荐效果
- 流量时变性强:早晚高峰流量价值差异大
- 书籍转化能力不均:不同书籍的曝光-新增阅读转化效率差异显著
传统规则系统通过“打补丁”的方式平衡多目标,易出现策略冲突、效果不稳定等问题,而强化学习的全局决策能力能够有效解决这一痛点。
针对上述核心痛点,我们自主研发了基于生成式强化学习的自适应时序调权框架,突破传统规则系统在内容分发场景的适配瓶颈,实现扶持策略的全流程自主优化。
3.1 七猫内容扶持业务的强化学习建模
在系统设计上,我们构造七猫内容扶持业务场景的强化学习三要素:
🕐 时间切分
将一天划分为 48 个时间步(每步30分钟),模型在每个时间步输出每本扶持书的扶持系数。
📊 状态(State):模型"看到"什么?
每个时间步,模型能看到的信息包含三个层次:
- 时间维度:当前是第几个时间步(感知"时间紧迫感")
- 书籍维度:
a 当天已累计的PV、展现、点击、新增阅读数
b 近3个时间步的滑动窗口特征(短期趋势)
c 扶持目标:今天这本书要拉多少新读者(目标感知)
d 书籍静态特征:类别、字数、评级等
- 大盘维度:整体平台的实时流量和转化情况
🎮 动作(Action):模型"做"什么?
模型输出的是一个连续数值——当前时间步的扶持权重系数。
🏆 奖励(Reward):如何衡量"做得好不好"?
这是整个设计最核心也最难的部分。单一奖励无法覆盖多目标,我们设计了一个乘积形式的复合奖励:
最终得分 = 新增阅读完成度 × 效率惩罚系数 × 扶持系数惩罚系数
| 奖励分量 | 含义 | 效果 |
| 新增阅读完成度 | 当前完成了多少比例的拉新目标 | 驱动模型"必须完成任务" |
| 效率惩罚 | 如果转化率低于底线,进行非线性惩罚(可配置惩罚强度) | 防止模型"花大钱办小事" |
| 扶持系数惩罚系数 | 扶持系数越高,惩罚越大 | 防止模型出太高扶持系数干扰大盘 |
为什么用乘积而不是加权求和?
乘积的含义是:任何一个维度接近0,总分就接近0。这迫使模型必须同时把三个维度都做好,而不是用某一个高分来掩盖另一个的失败。类比:一个员工绩效 = 工作量完成度 × 质量达标系数 × 成本控制系数。任何一项不及格,综合绩效都会大幅下滑。
至此,我们将内容扶持业务建模为强化学习模型, 三要素状态、动作、奖励中,状态层面创新性融入书籍语义特征嵌入模块,将书籍类别、字数、评级等静态特征与实时流量反馈特征深度融合,解决了传统模型“重时序、轻内容”的弊端,让调权策略更贴合书籍本身的转化潜力;动作层面,设计连续型动态调权输出机制,结合书籍转化潜力动态调整扶持系数的波动范围,避免单一系数过高或过低导致的效果失衡;奖励层面,采用乘积式复合奖励函数,确保扶持调权既兼顾量、效率、成本三大目标,又能贴合用户阅读偏好,进一步提升转化质量;
3.2 模型结构及如何学习
模型采用离线生成式强化学习模型
离线强化学习:为何选取离线强化学习? 在线的强化学习需要在真实环境中不断“试错”,在真实生产系统中风险极高,会造成大量流量损失和用户体验下降;离线强化学习接从历史日志数据(轨迹数据)中学习,安全性极高;
扶持轨迹数据:就是扶持书籍历史的状态、动作、奖励三元组序列,序列长度是48,对应每一天的48个时间步;如:(目标奖励-r1, 状态-s1,扶持系数-a1,目标奖励-r2, 状态-s2,扶持系数-a2,...,目标奖励-r48, 扶持系数-a48,奖励-r48)
奖励我们使用 RTG (Reward-to-Go):它不是告诉模型“你现在得到了多少奖励”,而是告诉模型“为了达成全天目标,你接下来还需要获得多少奖励” ,模型从“被动响应”到“目标驱动”;
生成式强化学习:以决策Transformer为基础架构,我们知道Transformer是大模型的基础结构,输入一段文字,模型自动生成后续的文字;DT(Decision Transformer)是把文字替换为"状态-动作-奖励"序列, 即如上的扶持轨迹数据
模型结构:
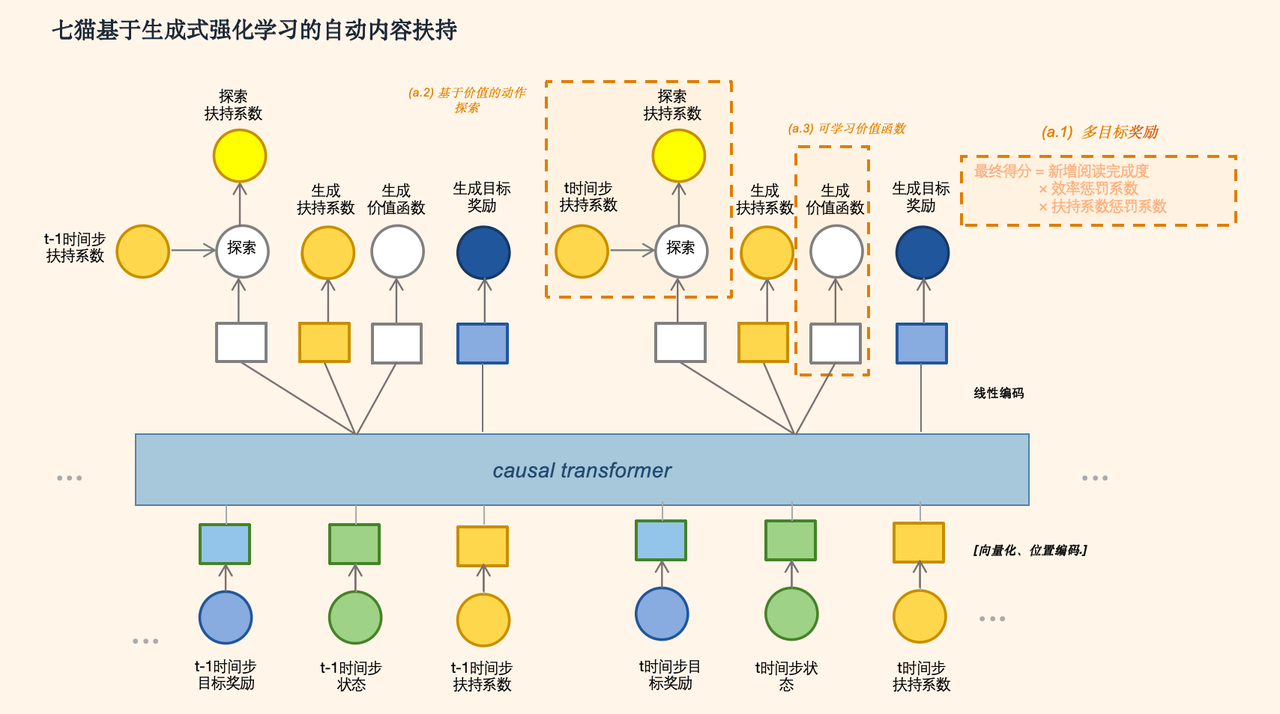
- 目标奖励、状态、扶持系数经过向量层后依次进入transformer结构中;
- t时间步状态之前的轨迹输入模型后, 生成模型预估的扶持系数、当前状态的价值;
- t时间步扶持系数之前轨迹输入模型后,生成模型预估的目标奖励;引入基于状态价值的探索,让模型有机会尝试历史数据中未出现过的探索扶持系数
- 根据模型生成的扶持系数、价值函数、目标奖励、探索扶持系数和真实的扶持系数、目标奖励、价值函数等差异训练模型
模型优点:
- 设计了可定制的综合评分作为目标奖励,同时兼顾扶持完成度、效率约束、扶持系数约束,三个目标权重可按需调整.
- 模型的动作选择上引入受控的探索,让模型有机会尝试历史数据中未出现过的更优扶持策略.
- 价值函数约束探索边界:探索不能漫无目的,训练的价值函数来评估"这次探索方向是否有价值";高价值方向:继续探索;低价值方向(可能带来亏损):拒绝.
- 普通算法只看"现在",Transformer 架构可以看到整天 48 个时间步的全局视野, 全天整体规划扶持策略.
- 高安全性,可直接工业落地, 基于历史数据训练,比在线试错的崩溃风险低得多.
- 动态响应运营干预,运营人员临时修改某本书的扶持目标,模型能通过 State 中的目标参数自动感知并调整策略,无需重新训练
3.3、策略效果
目前推荐榜、生成信息流主要场景已升级为强化学习扶持策略,对比之前策略,在固定扶持流量下,扶持书整体新增阅读增加5%,30-100w四五星原创连载书新增阅读增加6%,头部优质扶持书新增阅读增加20%;