目录
- 摘要
1.1 关键词 - 背景与问题
- 技术设计
3.1 旧版方案
3.2 优化方案
3.3 效果
3.3.1 离线可行性验证
3.3.2 线上实验 - 结论与展望
- 致谢
摘要
为保证推荐结果的新颖性,本文提出了一种新的策略,通过在推荐流程中的精排阶段引入交互特征(指用户、书籍间的曝光、点击交互数据),在保证不降低推荐精度,甚至略有提升的同时,降低过滤的复杂度,其中总存储由400GB降低为200GB(降低的曝光打压存储,新增的交互特征存储),提升推荐引擎性能, 同时模型更容易维护。
关键词
曝光打压、过滤、新颖性、精排
背景与问题
个性化的推荐算法被广泛应用于互联网产品中,通过从大量的信息中有效地过滤掉用户不关心的内容,生成个性化的推荐列表。从用户角度来说,提高了单位时间的信息价值,减少了噪声的干扰,得到了更好的信息体验;从应用角度来说,可以精准地定位到不同的用户,提高了单位成本下的推广效果,减少了用户流失的可能性。
七猫推荐系统在对用户进行书籍推荐时,总共会经历5个阶段:
- 召回:根据用户喜好,从书籍库筛选几千本书籍。
- 过滤:根据业务规则,过滤掉一些书籍。
- 粗排:根据特定算法逻辑,将书籍候选集【千本级别】,快速排序,取topN,剩余200~300本。
- 精排:根据深度学习算法模型,将粗排候选集,进行精排。
- 重排:根据业务需要,对精排后的某些书籍,进行加权或降权。
推荐系统面临着一个问题:
- 推荐位有限。如果每次推荐结果都相同,新颖性不够,影响用户体验;同时,书的分发效率也有一定影响。
- 如何在保证推荐精度不下降的同时,提升新颖性;同时,整个系统又不能太复杂。
在早期推荐系统刚上线的时候,过滤阶段还没有曝光打压策略,当时终章页推荐场景,随着时间的推移,有效点击率会呈现缓慢的下降。
经过排查之后,我们发现,推荐系统会反复推荐给用户一些书,哪怕这些书前几天已经被推荐过了。此时我们意识到,系统缺少了一个机制,需要对用户推荐过的书籍进行一定程度的打压,由此诞生了曝光打压策略。
七猫推荐系统过滤阶段由多个过滤策略组成,本文重点介绍其中的曝光打压策略优化前和优化后的对比。
技术设计
旧版方案
曝光打压策略
- 策略目的:七猫小说app在对某个用户进行内容推荐时,用户已经曝光过或点击过的书籍,需要进行一定程度的打压,以避免重复推荐相同的书籍给用户,提高用户推荐书籍的新颖度。
- 策略逻辑:近30天内,用户在某个场景下,曝光过和点击过的书籍,需要进行不同力度的打压过滤,且点击过的书籍打压力度>只曝光不点击的书籍打压力度。【由此,引入了曝光打压权重和点击打压权重系数来控制】
由于逻辑较为复杂,这里不过多阐述,简单总结一下曝光打压策略的整体思路:
以曝光打压为例,通过权重系数的设置,使得用户第1天曝光过的书籍,第2天不可以曝光,第3天可以曝光;若第3天此书籍又曝光了,则第4,第5,乃至第6天不可以曝光,第7天又可以曝光...
诸如逻辑,它变成一个阶梯式的打压,曝光次数越多,打压越狠。点击的打压逻辑类似,只是力度比曝光更大。
要想实现这个策略,需要完成两个方面:
- 将用户近30天内,每一天曝光和点击过的书籍进行存储,且需要实时统计。
- 设置合理的打压力度,即打压权重,使得用户曝光或点击过的书籍不至于打压过轻或过重,保持在一个合理值。
对于第一个方面,由大数据flink任务实时计算后存储在redis中,且需要比较多的redis存储.
对于第二个方面,打压权重的设置,较难把控,为了得到一个合理的值,由此我们设置了多组参数,通过AB实验,来进行效果验证。如图所示:
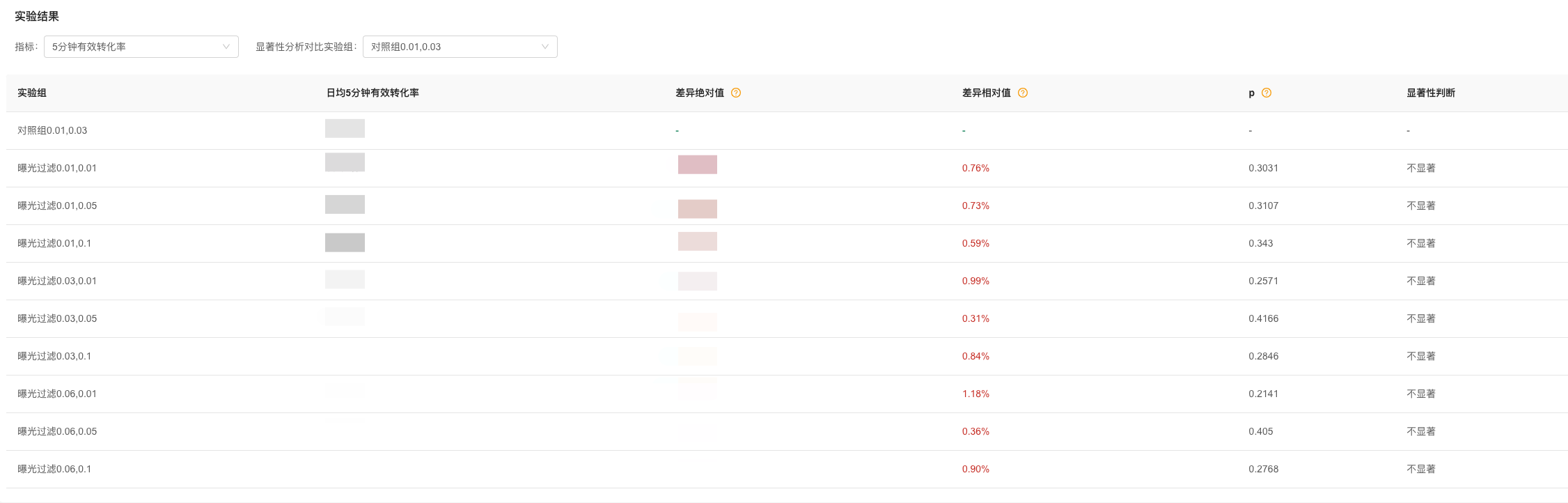
上图,是我们在七猫书城信息流场景的14天实验情况,由实验结果,我们选出了一组较为合理的权重。
虽然,我们能通过实验来筛选出一组曝光与点击的打压权重,但是这里面依然有一些不足,如下:
- 实验成本较高,且不同场景的打压权重需要独立的实验来验证,即打压力度无法全场景适用,需要定制化设置。
- 打压权重的设置,存在盲区,因为无法穷举权重进行实验,所以只能找出实验中的相对合理值。
优化方案
由于整个曝光打压策略,是基于人工的权重设置来控制,存在一定的缺陷。那么我们就会想到,能否让算法模型自行学习这个规则,然后进行打压降权呢?
而这个想法的可行性,是基于这么一个底层逻辑:
用户重复曝光或点击过的书籍,他的兴趣度是会下降的,即点击概率变低了。而对于算法模型来说,本身就是预测书籍点击率的,那么理论来说,精排模型对此类书籍应该会排的比较靠后,即被打压降权了。
那么要想实现这么一个目的,在精排阶段,我们就需要告诉算法模型用户和书籍的交互特征,即待精排的200~300本书籍,用户近30天内,分别曝光和点击过多少次,让其自行打压。
效果
离线可行性验证
要想让模型能够自主打压,首先需要让其从海量样本中学习到这个经验,即规律。
我们选了详情页场景的精排阶段算法模型,在此基础上,添加了6个特征进行模型的训练:
| 特征名称 | 特征说明 |
|---|---|
| userbook_show_count_30 | 用户该书30内书籍曝光次数 |
| userbook_show_count_14 | 用户该书14内书籍曝光次数 |
| userbook_show_count_7 | 用户该书7内书籍曝光次数 |
| userbook_click_count_30 | 用户该书30内书籍点击次数 |
| userbook_click_count_14 | 用户该书14内书籍点击次数 |
| userbook_click_count_7 | 用户该书7内书籍点击次数 |
由于要对曝光打压策略进行可行性验证,在模型训练后,我们选取了 30,14,7日 的书籍曝光次数这三个特征来验证。
以某个用户的某次访问详情页请求为例,我们选取了3本书,初始曝光次数均为1,经过精排模型打分后,结果分别为:
| 书名 | 精排分数 |
|---|---|
| 天降七个神仙姐姐 | 0.16410595271736383 |
| 极品美女军团 | 0.1607327749952674 |
| 我的七个妹妹国色天香 | 0.15821188711561263 |
当3本书的书籍曝光特征即userbook_show_count_30、userbook_show_count_14、 userbook_show_count_7 曝光次数分别+1之后:
| 书名 | 精排分数 |
|---|---|
| 天降七个神仙姐姐 | 0.16226203786209226 |
| 极品美女军团 | 0.16175024607218802 |
| 我的七个妹妹国色天香 | 0.15163698163814843 |
曝光次数 +2之后,结果如下:
| 书名 | 精排分数 |
|---|---|
| 天降七个神仙姐姐 | 0.1554027097299695 |
| 极品美女军团 | 0.1541137108579278 |
| 我的七个妹妹国色天香 | 0.14864090736955404 |
曝光次数 +3之后,结果如下:
| 书名 | 精排分数 |
|---|---|
| 极品美女军团 | 0.1526818098500371 |
| 天降七个神仙姐姐 | 0.15063489973545074 |
| 我的七个妹妹国色天香 | 0.1470978984143585 |
如图所示:
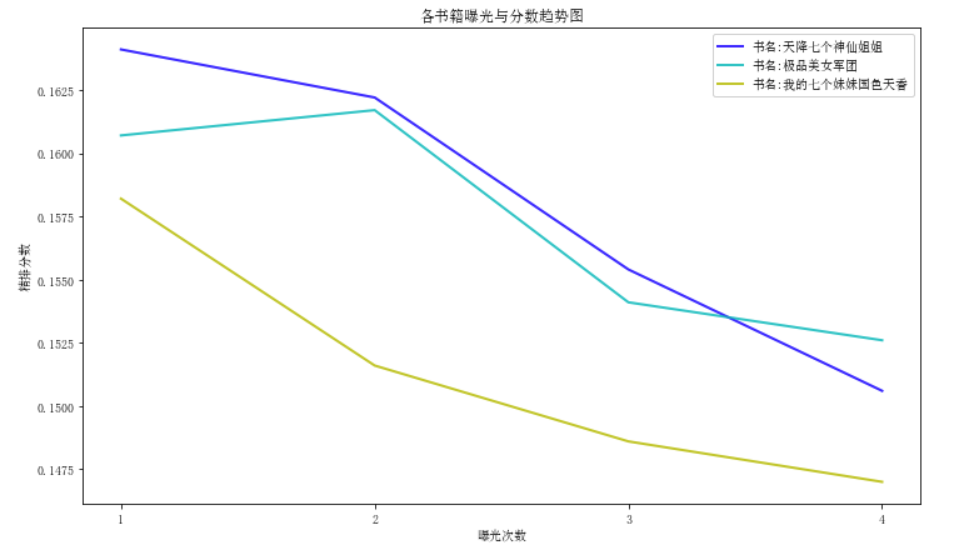
通过以上的验证,可以发现,除了当曝光次数为2时,即曝光次数+1,极品美女军团这本书的分数有所上升之外,其余的情况,当书籍曝光数加的越多,分数下降的就越厉害,即被打压的越狠了。
该方案从整体数据表现上看,曝光次数越多,分数就越低,达到了预期目的。但对于类似《极品美女军团》这本书曝光+1后,分数反而变高的少量特殊情况,我们还在持续探索其更深层次的原因。
线上实验
由于添加的6个用户书籍交互特征是离线T+1更新的,若把现有的曝光打压策略全部剔除,则就会出现,用户当日内重复访问某一场景,推荐的结果就会不变。
故而,用户当日内推荐的书籍,还是要曝光打压过滤掉,第二天的时候,特征已经更新了,此时算法再推荐昨天曝光过的书籍时,自动会打压降权。
以下是在书城推荐榜进行的14天实验情况:

注1:正常曝光打压实验组指的是过滤阶段基于原人工30日内曝光打压策略。
注2:仅当天曝光打压实验组指的是过滤阶段只有当天曝光和点击的书籍会被过滤掉。
注3:仅3天曝光打压实验组指的是过滤阶段由原来的人工30日内曝光打压策略缩短至3天曝光打压策略。
注4:以上3个实验组的精排模型为同一个算法模型,都添加了6个用户书籍交互特征,他们只是过滤阶段的曝光打压策略周期不一样。
注5:本实验重点关注仅当天曝光打压实验组,其余实验组顺手做的。
本实验只要有效点击率p值不负向显著即可,从图中可以看到,仅当天曝光打压策略,甚至还略有提升。
推测可能原因:书城推荐榜的无效曝光较多,使得一些好书用户根本就没认真看,就被系统认为是曝光过了,从而被曝光打压规则过滤掉,如下图:
- 注:用户启动七猫app,默认进入书城页面,此时展示8本推荐榜书籍,用户平均一天启动app 10次,即总共一天曝光了80本书,而这些书,又是推荐系统认为适合用户的书
而采用【过滤阶段当天曝光打压 + 精排阶段的算法模型自学习打压】这种组合方式,当天被曝光过的书籍,第二天依然有可能再次被曝光。至于如何抉择,取决于算法模型,这也正是采用这种方式的好处之一,由算法模型自学习打压而得到的结果,比人工硬规则打压,盲区更少,效果更佳。
【过滤阶段当天曝光打压 + 精排阶段的算法模型自学习打压】 比 【过滤阶段基于人工规则的30日内曝光打压】方式相比,有以下优势:
- 降低人工权重配置带来的复杂度 ,减少盲区,且效果也能得到保证。
- 曝光打压redis存储可减少,原先需要存储近30天内,每个用户每天曝光和点击过的书籍以及次数,redis内存使用400GB左右。现在理论只要存储当天的曝光和点击书籍即可,当然精排模型新引入的6个特征也需要额外的的存储开销,约200GB,总体来说redis使用量降低约一半。
- 推荐引擎的性能也能够得到一定的提升,原先在过滤阶段,引擎需要将用户30天内的每一天书籍曝光和点击数据进行查询、计算和过滤,性能消耗大;而现在只要查询当日的数据,进行过滤即可,响应更快。

结论与展望
结论:
- 算法智能曝光打压的优化方案,在保证精度不降低,甚至略有提升的同时,降低了曝光打压策略的复杂度,已经经过AB测试,并应用到七猫app各个推荐场景。
思考:
- 运营规则和算法结合的好处。运营规则可解释性强、但维护困难,且容易存在盲区;算法解释性差,但自动学习,更智能化,两者结合,才是上策。如何将这种以算法为主,运营为辅的组合方式运用在更多的方面,减少人工业务规则的使用,是后面需要进一步思考的。
后续可能的探索方向:
- 探索实时特征对交互特征的影响,看是否能进一步降低过滤复杂度。
- 探索更多的交互行为, 提升精度。
致谢
在曝光打压策略的迭代优化过程中,产品冯雨昕,推荐引擎魏小亮同样给出了很多宝贵的意见,这里特别感谢一下。