如果不从事软件开发相关工作可能很少会听到“解耦”这个词,其实,在我们日常的工作中到处能见到“解耦”的应用,工作任务的分配、目标和关键结果的拆解、部门和小组的划分等都需要通过“解耦”来实现。
在软件开发领域,解耦虽然不是单独的软件设计原则,但是几乎所有的设计原则中都能找到它的影子,如果你仔细观察就会发现软件技术的进化史也正是一部软件开发解耦的历史:
- 1984 年图灵奖获得者、著名计算机科学家尼古拉斯·沃斯(Niklaus Wirth)提出 程序=数据结构+算法 的概念,将数据的组织和处理过程解耦,降低了我们学习和编写程序的难度;
- 面向过程的编程方式通过函数将不同的逻辑块封装起来,解耦复用不同的运算逻辑,使我们能够开放更加复杂的软件系统;
- 面向对象的编程方式将数据和方法封装到类中,让具有相同行为的对象之间解耦,使我们能够更好的模拟真实的世界;
- Kubernetes采用“声明式API”,将期望状态和具体实现解耦,迅速成为了云原生时代的王者;
- 无状态应用将程序的运行与数据进行解耦,使应用程序可以快速的伸缩;
- 将单体服务解耦拆分为微服务提高了应用的可扩展性、可用性和部署效率,不同微服务也不再需要统一的技术栈;
- 为了更好的落地微服务,早在2003年就提出的领域驱动设计成为了当前程序员们最向往的技术圣地;
- ...
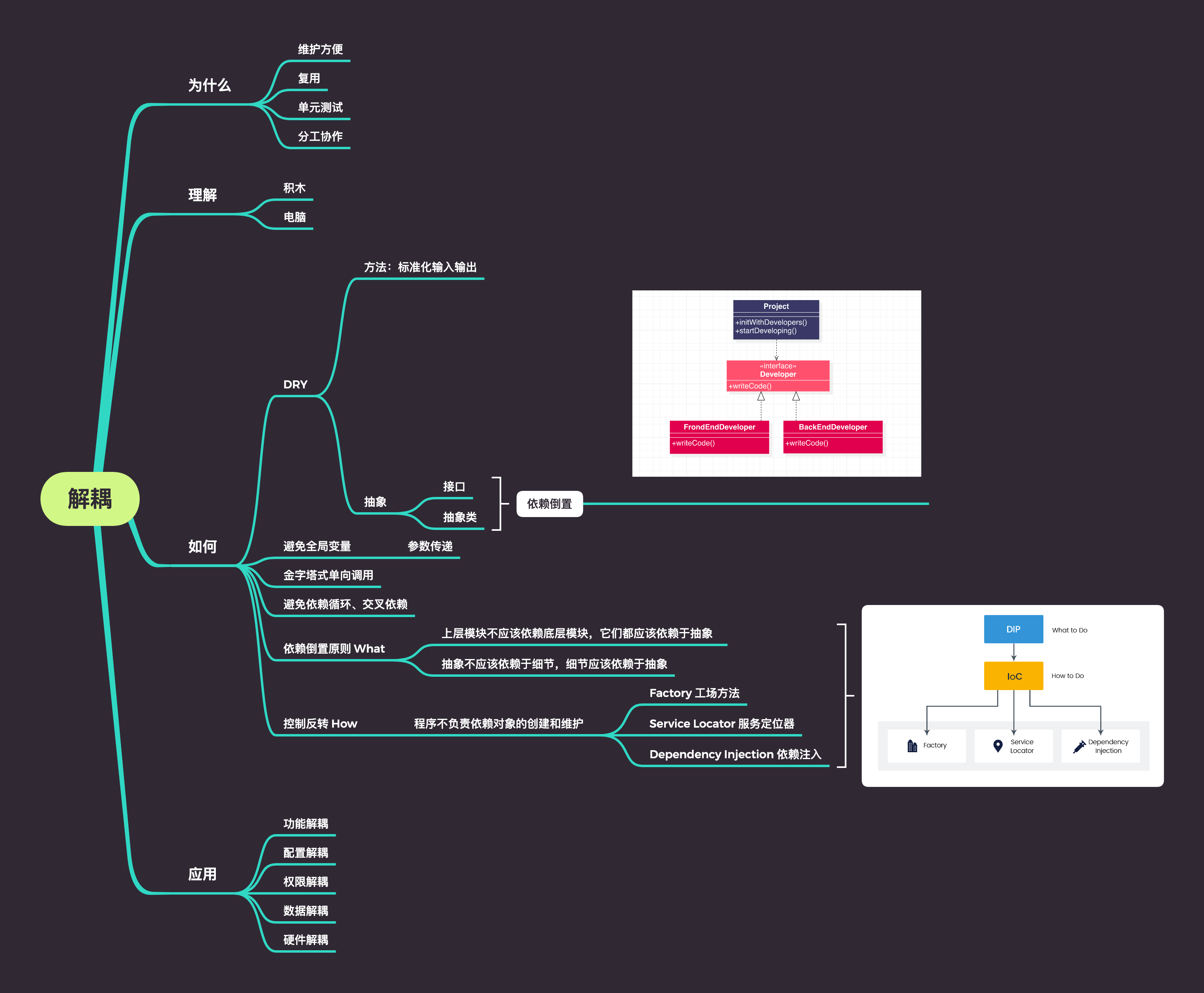
为什么要解耦?
人类大脑的容量有限,只能处理有限的复杂性,我们唯一能做的就是把复杂的事情变简单。
人类探索世界的过程也是将复杂问题拆分为简单问题的过程,而软件设计、软件开发需要创造一个虚拟的世界,是人类从事的最复杂的工作之一,这项工作也同样受到我们大脑容量的限制。

因此,如何处理系统的复杂度就成为了软件设计、软件开发过程中最核心的问题。
同时,软件设计也是一门关注长期变化的学问,耦合度过高是造成系统可用性、可扩展性、可维护性等诸多问题的根源,这些问题的积累让我们难以关注长期变化,甚至连短期的需求实现都变得异常困难,一个微小的改动就可能导致意想不到的bug,造成整个系统的崩溃。
将问题、需求、代码和模块拆分为互不影响的单元能够帮助我们降低系统的复杂度,提高我们解决问题和工作的效率,是我们处理系统复杂性的有效手段。
这个过程在软件开发中就叫做解耦。
解耦不仅让我们的代码维护更方便,易于复用,可以方便的进行单元测,更重要的是让我们能够更好的分工协作。

什么是解耦?
在软件开发中解耦可以理解为功能模块的正交分解,通俗地讲就是将两个原来相互影响的功能拆分出来,让它们独立发展,每个功能模块只负责一件事情,这样我们就可以复用这些模块的功能而不用担心影响其他的功能。
经过正交分解的模块可以像拼积木、组装电脑一样组合、复用不同的模块,每个模块内部的逻辑也相对简单,易于理解、优化。
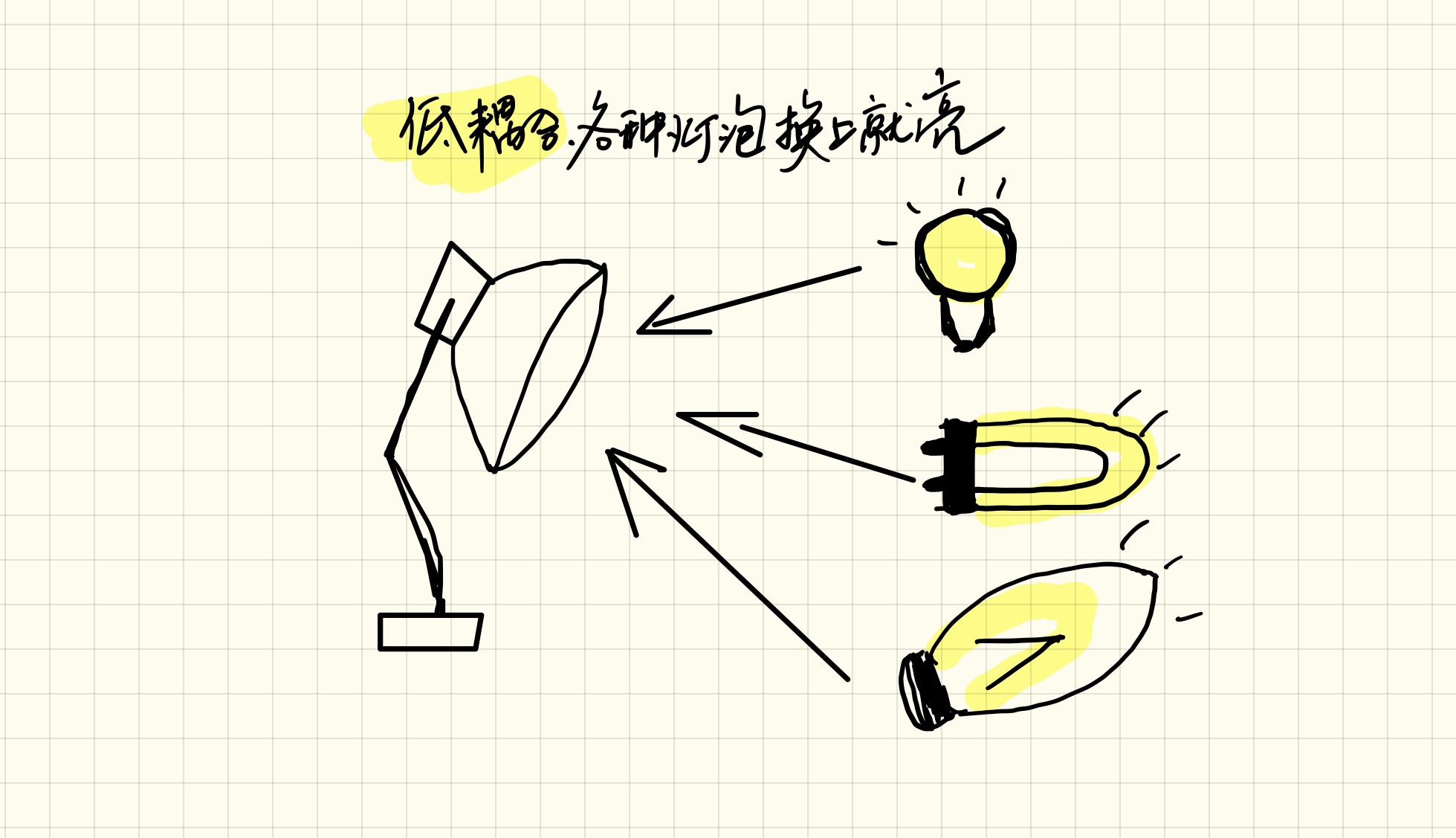
这里“正交分解”中的“正交”一词是借鉴了AB实验设计的“流量正交”概念,用在这里指的是拆分出来的功能模块必须互不影响。
如何解耦?
前面我们讲过,软件设计是一门关注长期变化的学问,而解耦的关键是要找到一个长期不变的支点,这个支点可以是一个ID、一个名称、一种数据格式、一个接口定义、一种设计原则等,只要能事先约定并且长期不变的东西都可以作为解耦的支点。
编写代码时我们可以通过减少全局变量、避免循环和交叉依赖、标准化输入输出、依赖注入等方式对代码进行解耦,但是解耦不仅仅局限在编码领域,软件设计、团队协作的时候也可以应用解耦的思想。
在推荐引擎的日常工作中也经常需要进行解耦的设计,下面简单分享几个解耦的案例,供大家参考。
通过ID解耦
我们在设计数据库表时通常会增加一个主键,主键不能重复,用来唯一标识一条记录,通过ID将不同的数据记录解耦。
实际工作中,推荐引擎需要支持算法、产品同学进行快速的AB实验,一开始我们直接在AB实验平台配置不同的参数,然后推荐引擎实现各个实验参数的逻辑,每次做不同的实验时都必须开发相应的实验逻辑,不仅工作量大,代码不能复用,而且各种参数很容易配错,推荐引擎和AB实验平台不可避免的耦合在了一起。
通过团队的共同努力我们设计并实现了一套推荐流程管理系统,向算法、产品同学提供一个了召回、过滤、粗排、精排等各业务阶段能够自由组合策略的推荐管理平台。
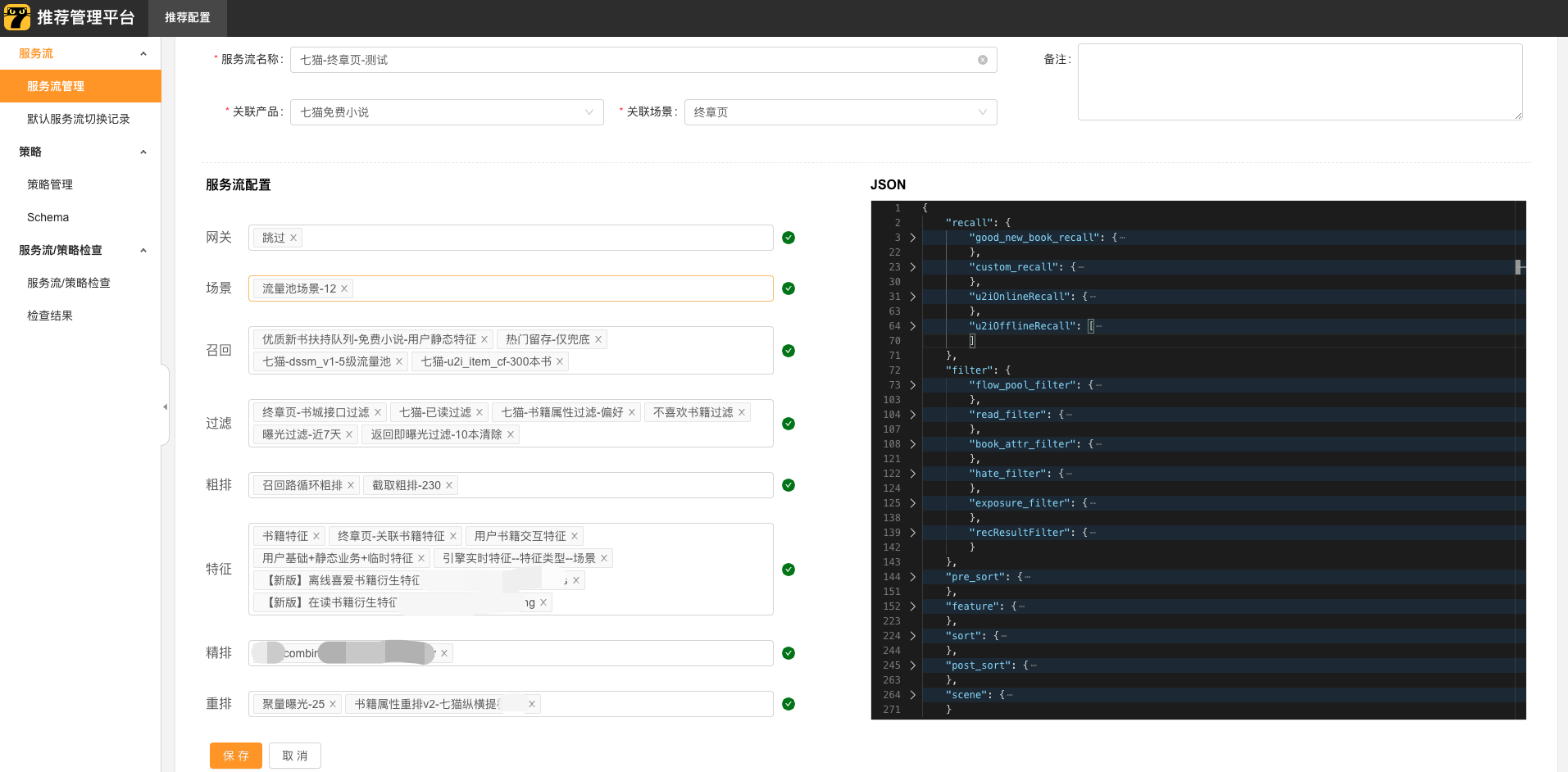
为了将推荐引擎、推荐管理平台和AB实验平台串联起来,我们给每个配置好的推荐流程增加了一个随机生成的字符串ID,算法、产品同学配置AB实验时只需要填写推荐流程ID即可,推荐引擎从推荐管理平台获取到这个推荐流程中各阶段策略的详细配置,再按照配置执行对应的逻辑,完成整个推荐流程。
这个长期不变推荐流程ID就是解耦这3个系统的核心支点,推荐引擎负责推荐策略的执行,推荐管理平台负责快速组装所需的推荐流程,而AB管理平台也只需要负责流量分配的工作。
通过名称解耦
一位先哲说过,当一个东西有了自己的名字,就拥有了生命。人类探索世界的过程,也是不断对新事物命名的过程。有了名称就可以将不同的事物区分开来,同时也可以将一个事物的特性封装到这个名称中去,这似乎是我们大脑了解世界的基本方式。
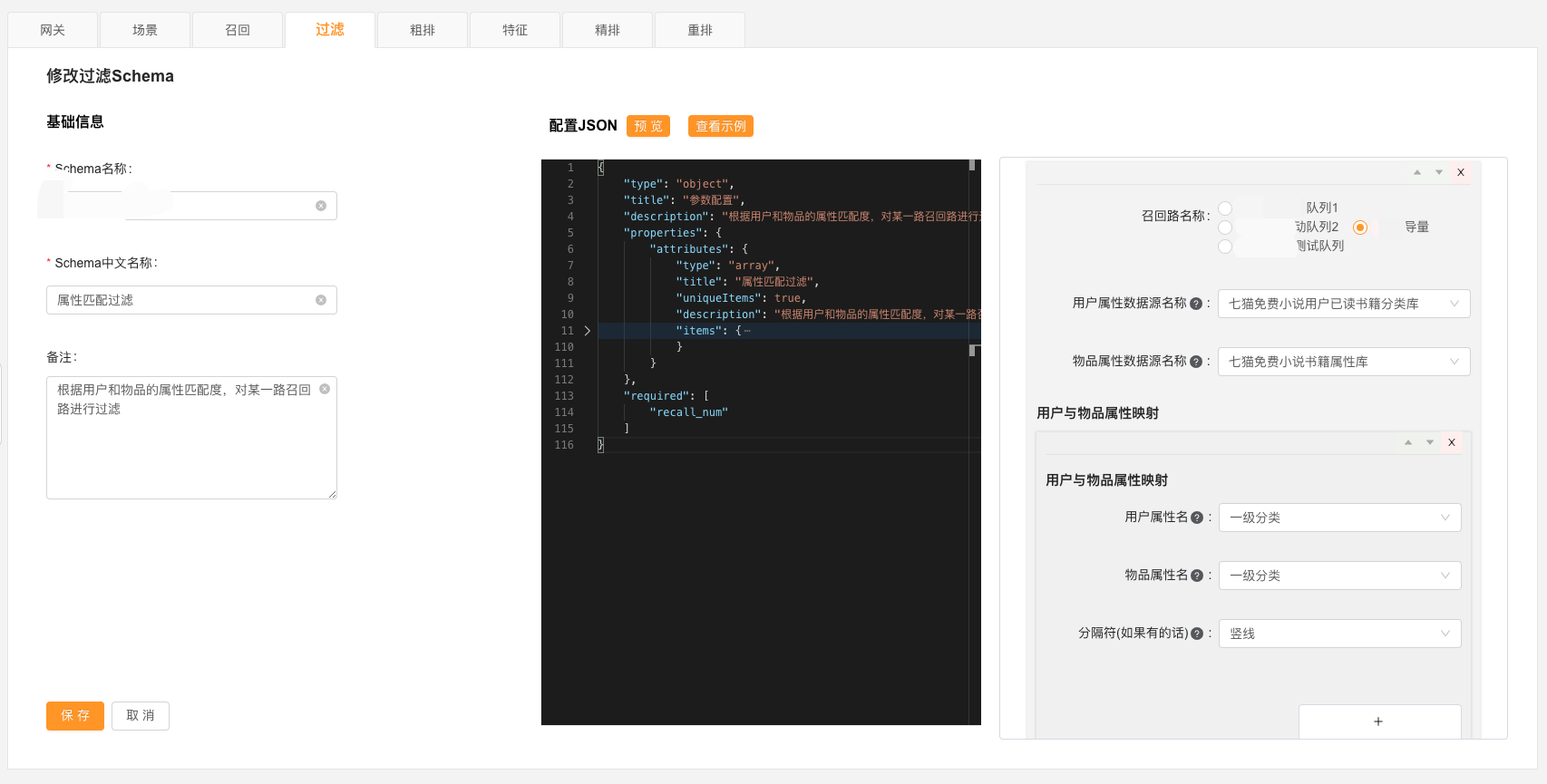
最近推荐引擎收到一个召回策略的开发需求,需要将一个优质书单强制召回,并且跟用户阅读过的书籍的一级分类匹配,如果能匹配上就将这些匹配上的优质书籍插入到指定的位置,实现基于用户偏好扶持优质书籍的目的。
之前我们开发过类似的召回策略,当时是把召回书籍的属性和用户属性匹配的逻辑封装到同一个召回策略中的,这次的需求由于召回的逻辑不一样如果还按照上次的设计去实现的话就需要新增一个召回策略把一模一样的属性匹配逻辑复制一遍。
经过讨论我们决定新增一个属性匹配过滤策略,通过不变的召回路名称解耦召回策略,这样不仅这两个召回路可以使用属性匹配过滤的策略,其他的召回路也都可以使用。通过召回路名称解耦的方式不仅降低了代码的冗余,提高了系统的可维护性,还能策略复用,应对将来其他召回路需要属性匹配过滤的需求。
通过数据格式解耦
推荐引擎的策略经常需要跟算法、大数据的同学配合完成开发,各种召回路的书单、模型需要的特征等数据的变动频率非常高,如果每次变动都需要引擎、算法、大数据一起修改才能实现的话需求的沟通成本将会很高,上线周期将难以保证。
讨论过后我们决定通过约定不变的数据格式进行解耦,我们先约定好各个策略的数据格式,然后将数据库抽为策略中的一个参数,只要算法、大数据的同学按照约定的格式将数据存入到某个数据库中,再在推荐管理平台加上这个数据库的参数就可以在推荐流程中配置相应的策略了。
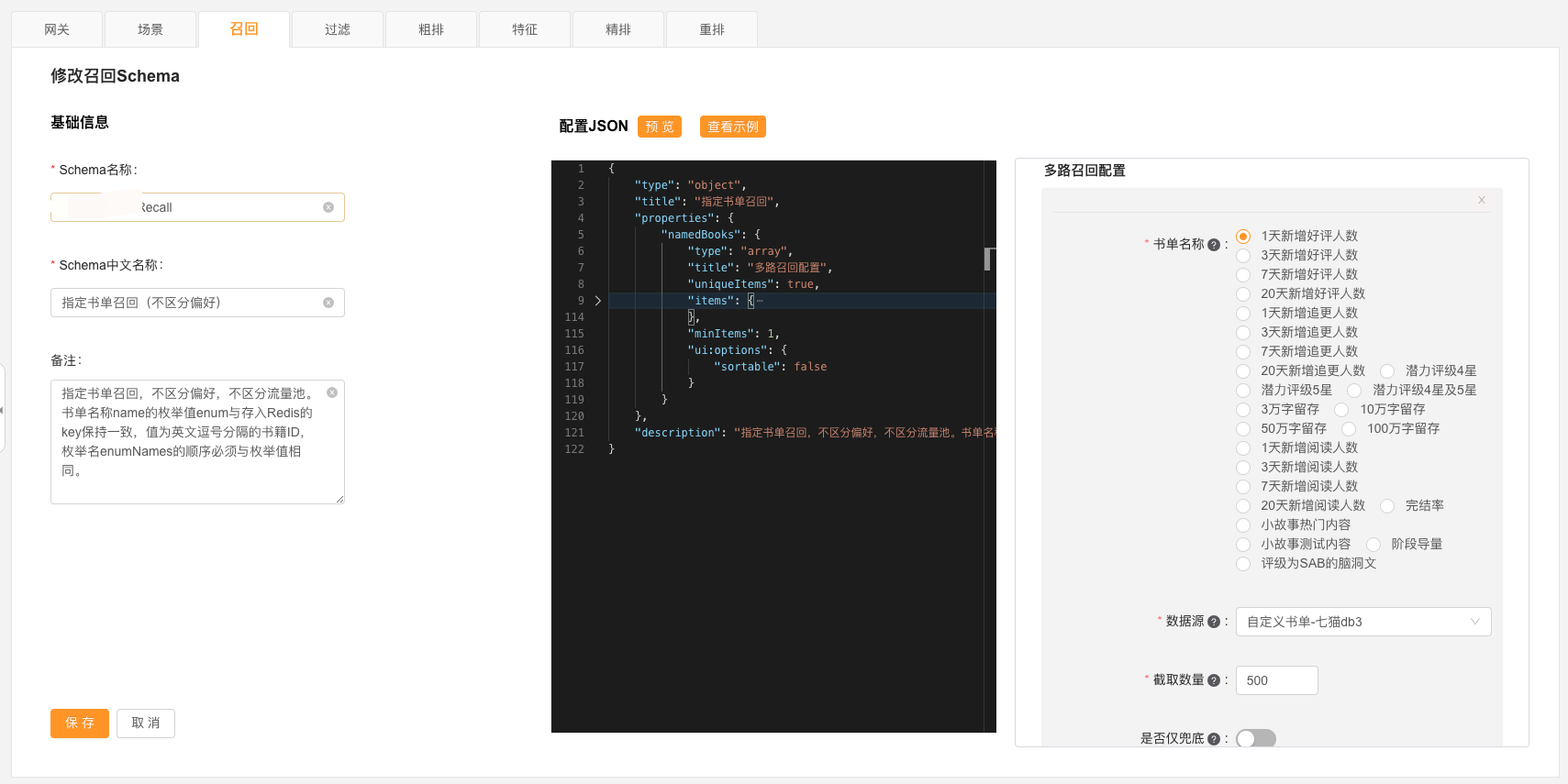
这样推荐引擎就不需要关心召回的书单是协同过滤算法产生的还是运营策略的强制扶持的,只要跟约定好的数据格式保持一致推荐引擎就不需要改动代码,不仅节省了推荐引擎的工作量,也提升了算法、大数据同学的开发效率。
通过接口定义解耦
最近数据服务收到一个设备评分接口的开发需求,需要根据设备的品牌、型号、CPU数量等信息返回一个固定的分数。
推荐引擎维护的数据服务是面向服务端的微服务,没有直接跟客户端对接过,正好基础平台的小伙伴正在开发面向客户端的接口网关统一处理鉴权、负载均衡等问题,于是我们愉快的将双方合作变成了三方合作,由基础平台的网关服务将请求中转到数据服务的接口上。
可现在问题来了,变成三方合作之后如果接口有变就需要三个地方同时改动,接口维护、更新的难度大大增加了。
组织讨论时我们得知接口请求的QPS、设备数量和评分的更新频率都很低,于是我们决定将所有的请求参数转为JSON封装到一个不变的字符串参数中,这样当我们增加、删除设备匹配参数时基础平台的转发接口不需要任何改动,直接将数据透传过来即可。
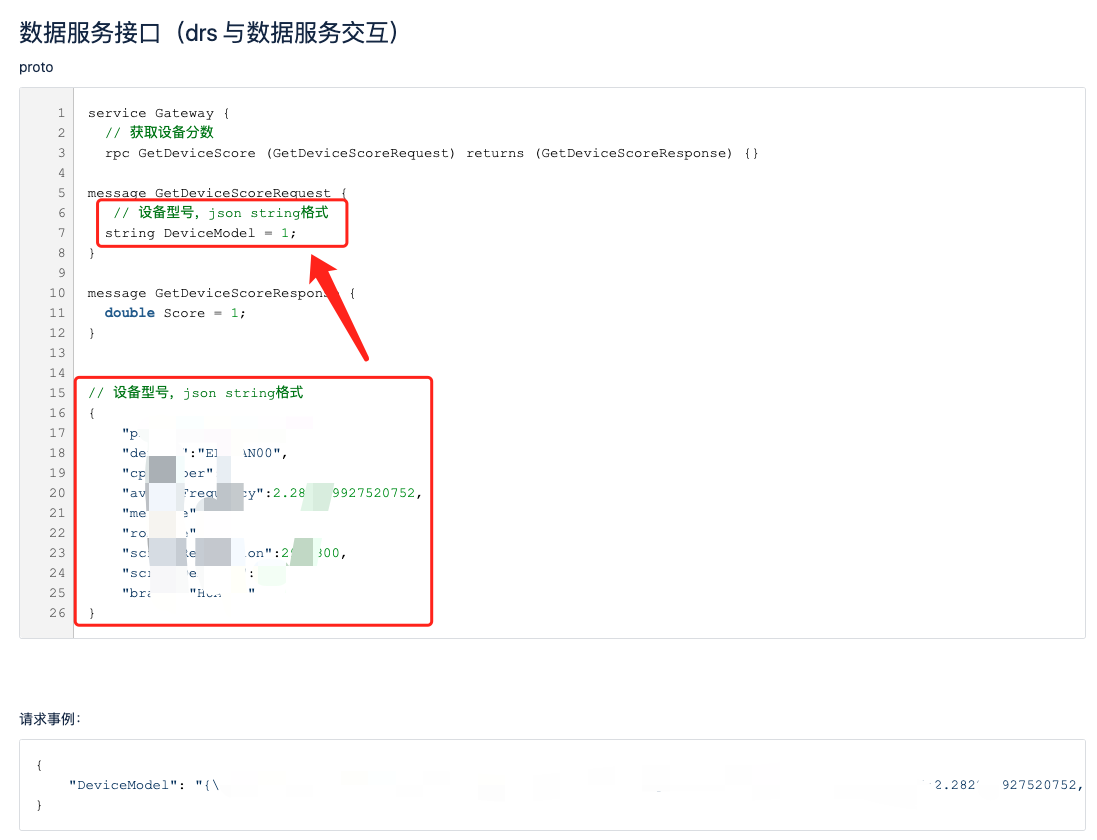
通过这种方式我们既复用了基础平台的鉴权功能还将可能的业务变动跟转发网关进行了解耦,当接口变动时再也不用担心打扰基础平台的小伙伴了。
通过依赖倒置原则解耦
开发软件时我们经常会采用分层的设计,将不同层次的模块关系梳理清楚。设计分层方案时如果不进行适当的解耦,低层模块的改动将会影响到高层模块的逻辑,不必要的改动将会沿着依赖关系逐层向上传递,导至软件维护的过程异常困难。
为了让高层模块能够复用,不受低层模块的影响,软件大师Robert C.Martin提出了依赖倒置原则:
- 高层模块不应依赖于低层模块,二者都应该依赖于抽象
- 抽象不应依赖于细节,细节应该依赖于抽象
这里的抽象通常是一个面向对象编程语言中的接口定义,是一个长期不变的约定,使高层模块和低层模块之间相互解耦,通过依赖注入的方式可以很方便的替换掉低层模块。
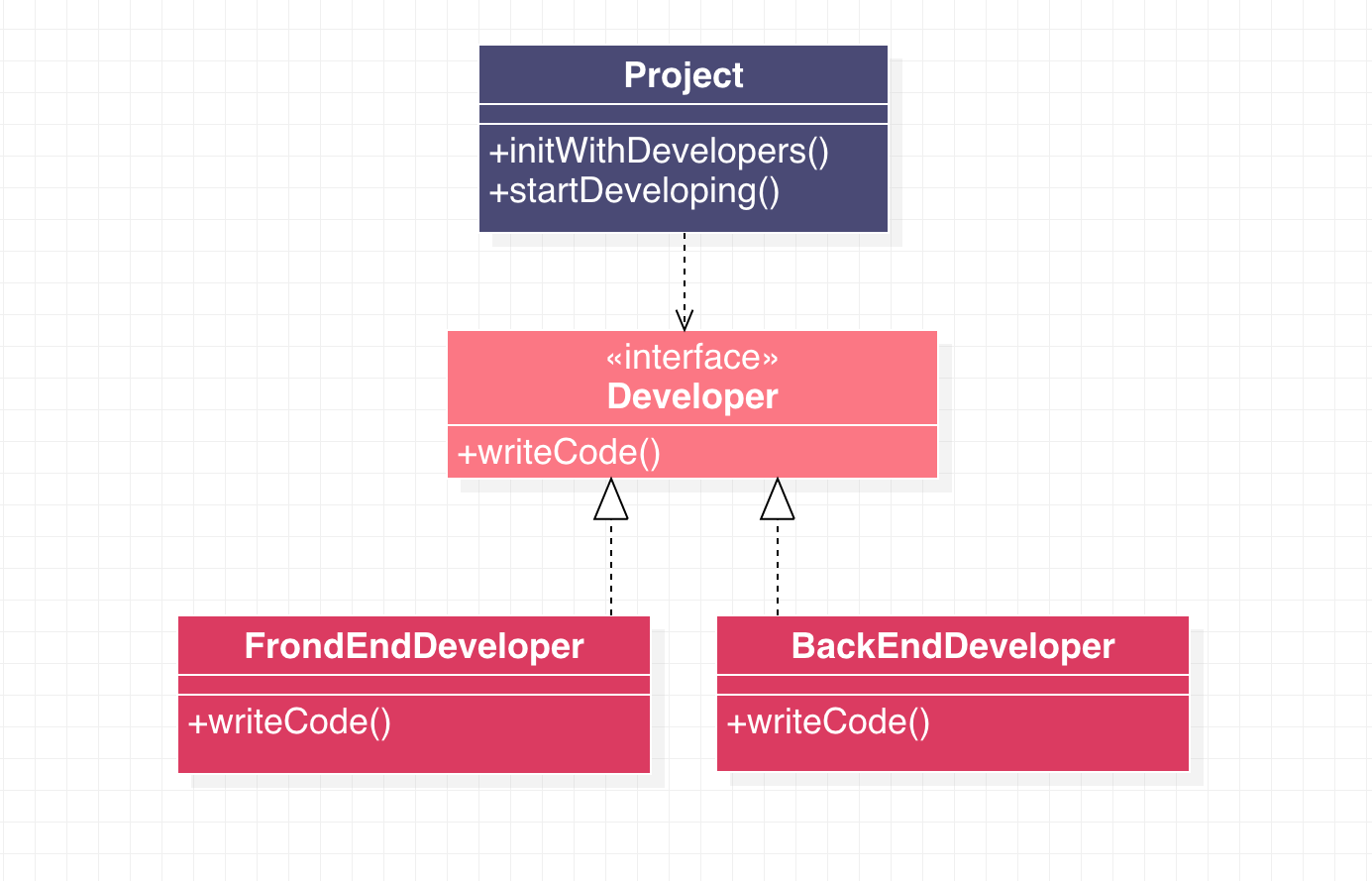
推荐引擎的每个阶段都有各种不同的策略,策略的增减和更新非常频繁,为了应对需求的频繁变动我们通过依赖注入工具wire将上层调用逻辑对各个子策略的依赖进行了倒置,只要实现上层调用逻辑定义的接口就可以快速的新增、更新策略,而调用逻辑不需要进行任何改动。
总结
如果你细心观察会发现解耦无处不在,它的应用也不局限于软件开发领域,任何复杂的事物都可以进行解耦,关键是我们要找到那个长期不变的支点,通过这个长期不变的支点将复杂的事物拆分为相对简单的事物。
我们常说解决问题的能力是一个人的核心竞争力,解耦就是我们提升解决问题能力的关键工具,让我们面对复杂问题、复杂项目和复杂任务时能够从容不迫,化繁为简,逐步解决遇到的任何难题。
最后,附上刚入职七猫时整理的“浅谈解耦”思维导图,希望解耦的思想能帮助到你。文章写的比较随意、发散,但却是我最想分享的内容,如果有写的不对的地方还请大家多多指教。