起因
关于连接池,想必大家耳熟能详。从其定义上来说,连接池是创建和管理一个连接的缓冲池的技术,这些连接准备好被任何需要它们的线程使用。简单点来说,就是当我们的程序在运行时,将数据库的连接进行实例化,每个连接当成对象存储在内存中,并且用一个数量大小的池子将其管理起来,当后续需要与数据库进行网络通信的时候再从池子中取出已有且正常的连接对象进行复用即可。因此,其所带来的好处显而易见,比如:1.减少连接的创建时间;2.提高资源的复用性减少资源浪费;3.精简编程模式简化开发模型等 .....
在刚入职从事后端开发的时候,就听前辈们说过我们的项目使用了数据库的连接池模型,而当时也一直没有深入的去理解和研究连接池底层的原理以及实现,而就在上周,突然发现服务器的日志上,多了一条redis连接池的报错日志,其内容如下图所示:

当然,首先看到的问题就是不应该把非业务的错误代码直接暴露给用户,因此在以迅雷不及掩耳的速度解决了错误返回的问题后,就开始冥思苦想这个奇奇怪怪的redis报错的字样是如何产生的,于是乎,我打开了golandIDE,全文搜索了一下错误源头发生的代码,发现这是一个项目内使用的go-redis的源码库预声明的变量即:
// 代码位置:go-redis/internal/pool/pool.go
var ErrPoolTimeout = errors.New("redis: connection pool timeout")
于是乎我查看了调用这个错误变量的方法,是一个挂载在ConnPool的名叫waitTurn的方法,在一头雾水继续深入的看了一下其调用链,似乎好像是在获取连接池连接的时候抛出的错误,那么问题来了,究竟是什么原因导致的这个问题,为了一探究竟,我选择探究一下go-redis连接池的源码,彻头彻尾的理解其原理和设计哲学,进而在来排查一下错误产生的原因。话不多说,从源码开始撸起
redis 连接池源码探究
why
在探究 go-redis 连接池源码之前,从服务发起端和 redis 端的角度来说,让我们先来看看一条最简单的 redis 的 get 命令是如何被执行的:
- redis启动,监听指定端口(默认6379)
- 用户服务端发起一个redis连接,经过redis端确认,成功连接(这里redis的连接主要有两种,一种是基于tcp的连接,一种是基于unix的socket连接),我们把它表示为一个redis的client
- 用户使用这个已经连接到redis的client,并执行一个get请求命令(向网络buffer中写入对应的字节流),发送至redis端并等待其结果响应
- redis监听到了这个连接对应的请求,经过对指令的解析后,把对应key的value写回到redis网络buffer中并发送给用户端
- 用户端收到了响应,经过解析后拿到了想要的结果,经过服务端的组装处理,可以返回给app端或者web前端。
这里就可以看出,如果我们服务的并发访问很高,那么每一个用户请求都需要建立一个redis的连接,而我们的服务端对redis的连接是tcp的,这里的耗时往往相对redis对请求的逻辑处理来说要高的多(想想三次握手),因此在请求连接处就浪费了好多的时间和资源;同时,如果在某一个高峰期时刻请求量过大,因为需要同时突然建立很多的redis连接,而导致超出了redis的最大连接数限制,既会对reids造成潜在的压力问题和风险,也会对用户造成一些错误的体验。所以也正是处于这几个主要的原因,才引入了所谓的连接池的组件。
go-redis,一次get请求都经历了哪些模块和步骤
若想深入探究出一个简单的 redis 命令在 go-redis 中到底经历了哪些流程,那么首先要完成的是 redis client 的建立,源码如下所示:
func NewClient(opt *Options) *Client {
// 初始化配置
opt.init()
// 初始化baseclient
c := Client{
baseClient: newBaseClient(opt, newConnPool(opt)),
ctx: context.Background(),
}
// process很重要
c.cmdable = c.Process
return &c
}
这里的代码比较清晰,主要分为两大块,1是对配置的初始化,2是对baseclient的初始化;我们按着顺序详细的去描述这两个模块
- 到底初始化了哪些配置
主要分为两块,如下图所示
type Options struct {
// 关于client和net层网络的配置
Network string // 连接方式,默认tcp
Addr string // 连接地址
// 很重要,每一次连接的net层的拨号具体方法
Dialer func(ctx context.Context, network, addr string) (net.Conn, error)
OnConnect func(*Conn) error
Username string
Password string
DB int
MaxRetries int // 针对网络层连接的最大重试次数
MinRetryBackoff time.Duration
MaxRetryBackoff time.Duration
DialTimeout time.Duration // 连接时候的超时时间阈值
ReadTimeout time.Duration // 网络buffer中读数据的超时时间
WriteTimeout time.Duration // 网络buffer中写数据的超时时间
// 关于连接池的参数配置
PoolSize int
MinIdleConns int
MaxConnAge time.Duration
PoolTimeout time.Duration
IdleTimeout time.Duration
IdleCheckFrequency time.Duration
}
首先是对于每一个redis连接的管理配置,比如连接协议的选择(tcp),用户名密码的验证参数,以及dialer的具体实现方法,还有就是一些重试次数和超时次数;之后就是关于连接池的参数配置,这里先暂时不对其进行展开描述,不过可以明确的一点就是,go-redis默认支持连接池,因此在初始化一个redis client时候,这些参数也都被赋予给了其对应的连接池属性上。
- redis client到底是什么?
其实redis client的类型就是包含了一个baseclient之外再加上一些process的方法,而关于baseClient的定义和初始化如下,很简单,代码如下所示
type baseClient struct {
opt *Options // 基本参数
connPool pool.Pooler // 一个连接池
onClose func() error // hook called when client is closed
}
func newBaseClient(opt *Options, connPool pool.Pooler) *baseClient {
return &baseClient{
opt: opt,
connPool: connPool,
}
}
可以看出无非就是对baseClient的两个参数进行赋值,这里对于connPool连接池的初始化先不提及,之后会做详细的解释。
接下来就是很重要的一个步骤,”c.cmdable = c.Process“,也就是初始化挂载了一个对redis的命令处理的方法,这里其实就是实现了一个,当我们在执行一个redis命令如 get set等等 的时候, 我们对命令的一个统一处理的一个方法,包括形如对redis请求的重试和网络超时的处理模块均在process的底层方法中所编写,源码如下所示:
func (c *baseClient) _process(ctx context.Context, cmd Cmder) error {
var lastErr error
//
for attempt := 0; attempt <= c.opt.MaxRetries; attempt++ {
if attempt > 0 {
if err := internal.Sleep(ctx, c.retryBackoff(attempt)); err != nil {
return err
}
}
retryTimeout := true
// 在获取到连接的基础上进行后续操作(注意,获取连接的方法被封装成了withConn)
lastErr = c.withConn(ctx, func(ctx context.Context, cn *pool.Conn) error {
// 向网络连接buffer中写入数据
err := cn.WithWriter(ctx, c.opt.WriteTimeout, func(wr *proto.Writer) error {
return writeCmd(wr, cmd)
})
if err != nil {
return err
}
// 向网络连接buffer中读出数据(接收redis的响应结果,阻塞等待,超时报错退出)
err = cn.WithReader(ctx, c.cmdTimeout(cmd), cmd.readReply)
if err != nil {
retryTimeout = cmd.readTimeout() == nil
return err
}
return nil
})
// 错误处理
if lastErr == nil || !isRetryableError(lastErr, retryTimeout) {
return lastErr
}
}
return lastErr
}
// withConn方法包装了getConn即连接的获取和释放
func (c *baseClient) withConn(
ctx context.Context, fn func(context.Context, *pool.Conn) error,
) error {
// 获取连接
cn, err := c.getConn(ctx)
if err != nil {
return err
}
// 释放连接
defer func() {
c.releaseConn(cn, err)
}()
// 处理错误
err = fn(ctx, cn)
return err
}
// 网络连接层读数据方法
func (cn *Conn) WithReader(ctx context.Context, timeout time.Duration, fn func(rd *proto.Reader) error) error {
// 对连接进行阻塞等待并读出数据
err := cn.netConn.SetReadDeadline(cn.deadline(ctx, timeout))
if err != nil {
return err
}
return fn(cn.rd)
}
上述关于process源码的注释很清晰,这里再度简单描述一下,也就是当我们想要使用已经初始化的redis client进行具体的set key 或者get key 执行命令时,首先对redis client的连接进行获取,这里也增加了重试的机制了;其次就是将我们执行的redis命令写入到redis网络连接buffer中并发出,在超时时间内,读出redis服务端的响应结果(当然也是从网络连接的buffer中读了);而后对错误进行处理并关闭连接,由此完成了一个简单的redis命令了。以上的代码,我绘制了一份流程图如下,为了更直观的理解,如下:
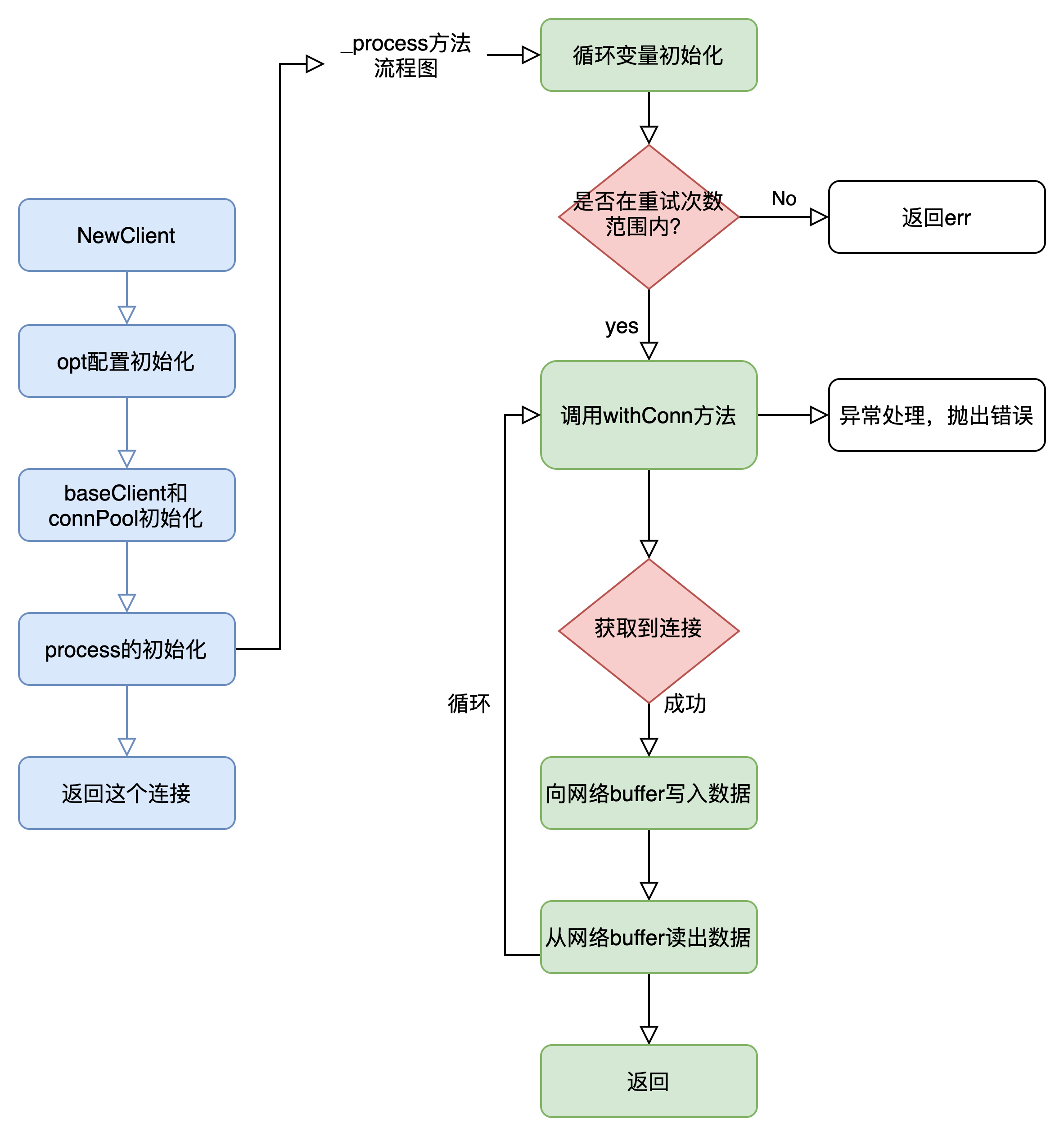
是不是觉得有点复杂?明明就是在键盘上敲几个字母的东西,居然在服务端中经历了如此复杂的流程和封装。其实细心的小伙伴也发现了,在上述process的连接获取的讲解,也就是getConn的执行,我没有细说,其实这里就是涉及到从连接池中获取一个连接的流程了,那么接下来就一起看一看,连接池是什么,以及如何从连接池中获取,使用和归还或消除连接的?
go-redis连接池,是如何实现和应用的?
同样的,为了深入探究go-redis到底是如何工作的,我们也按着上面的思路,一步一步从声明到实现再到使用的。我们先来看看go-redis对连接池的建立与管理
- 连接池的结构
连接池的结构体中主要包括如下代码所示,由上至下分别为opt配置,这里就不过多描述;其次是dialErrorsNum,其代表的含义为在建立连接(就是每当建立redis连接,想象一下dial拨号的感觉)的时候的错误数量;比较重要的是queue,这里用了一个golang的通道实现了一个令牌桶,其实令牌桶的作用起到了限流作用,不过值得注意的一点就是其chan内的数据类型为空的struct,这样写的好处就是不需要占用额外空间,性能也十分高效;接下来就是连接池内的连接模块了,使用切片来存放正常的连接和空闲连接,并用poolSize来定义连接池的大小容量(其实也是queue的容量);go-redis连接池提供了stat属性,也提供了对应的获取其状态的方法,可以用于做一些连接池的监控和调优;最后就是和关闭连接池相关的一些标识变量了,具体的代码如下所示。
type ConnPool struct {
opt *Options // redis client 的配置
dialErrorsNum uint32 // atomic 记录dial连接的时候出现的错误数量(建立连接的时候比如tcp连接)
lastDialErrorMu sync.RWMutex
lastDialError error // 最后一个连接错误的记录
queue chan struct{} // 很重要的一个令牌通道
connsMu sync.Mutex // 从conns 中取出和放回连接的时候加锁
conns []*Conn // 连接的存放切片
idleConns []*Conn // 空闲连接的切片
poolSize int // 连接池的大小,其实也是queue的大小,以及同时存在使用连接的数量的最大值
idleConnsLen int // 空闲连接的长度
stats Stats // 连接池的状态相关参数
_closed uint32 // atomic // 关闭
closedCh chan struct{}
}
- 连接池的初始化:何时何处?
可能刚看到上述源码的人会觉得有点困惑,毕竟密密麻麻的参数和定义,着实不好一下子理解和消化。本着学知识由浅入深的原则,我们就从一个连接池的建立开始,到使用再到关闭来深入理解go-redis的代码和实现原理。那么请看如下的初始化源码:
func NewConnPool(opt *Options) *ConnPool {
// 初始化一些基本属性,从make的参数就可以看出poolsize的意义
// 以及closeCh为无缓冲通道
p := &ConnPool{
opt: opt,
queue: make(chan struct{}, opt.PoolSize),
conns: make([]*Conn, 0, opt.PoolSize),
idleConns: make([]*Conn, 0, opt.PoolSize),
closedCh: make(chan struct{}),
}
// 进行空闲连接的检测(比较当前的poolsize和设定好的poolsize以及比较是否在最小空闲连接参数阈值内)
// 以决定是否向连接池中放入空闲连接
p.connsMu.Lock()
p.checkMinIdleConns()
p.connsMu.Unlock()
// 对坏的连接进行收集并关闭(reap原意就是收割的意思,很形象)
if opt.IdleTimeout > 0 && opt.IdleCheckFrequency > 0 {
// 用一个后台协程去不断的轮询(定时器),内部运用了伪随机策略对关闭状态进行检测与关闭
// 防止执行了一个关闭的坏的连接
go p.reaper(opt.IdleCheckFrequency)
}
return p
}
可以看到,虽然在初始化connpool对象的时候,连接存放的切片是空的(没有可用空闲连接),但是一旦设置了MinIdleConns,那么在经过checkMinIdleConns后,池子内会放入MinIdleConns个已建立的可用的连接的。由于这个初始化的方法很简单,则不过多赘述
3. 连接池如何对连接进行管理
如此一来,我们就建立好了一个连接池,并且也对这个连接池进行连接的管理制订了最基本的规则。那么连接池究竟是如何管理连接的呢?我们此时回想一下上个问题到的一个非常重要的Process方法,其中有一个withconn的子方法的底层中,实现了一个_getConn的方法,代码如下,我们发现原来当一个redis客户端想要执行一个cmd命令时,其实必须经过的一个步骤就是从connPool也就是连接池中Get到一个连接,因此我们接下来将主要探究一下连接池的Get方法是如何实现的。
- 连接池连接的获取
代码如下:
// baseClient的获取连接,实际上就是要从已经初始化的连接池中Get到一个连接
func (c * baseClient) _getConn(ctx context.Context) (*pool.Conn, error) {
// 从连接池中获取一个连接
cn, err := c.connPool.Get(ctx)
if err != nil {
return nil, err
}
// 初始化这个连接
err = c.initConn(ctx, cn)
if err != nil {
c.connPool.Remove(cn, err)
if err := internal.Unwrap(err); err != nil {
return nil, err
}
return nil, err
}
return cn, nil
}
下面就是Get方法的核心源码,其实流程很简单,检测连接池是否关闭,--> 获取turn的机会(就是看看能不能向令牌桶中插入令牌)--> 尝试获取空闲连接的可用链接 --> 如果获取不到则将missed计数加一 --> 新建一个连接成功则将hit(命中)计数加一 ,源码中也加入注释便于理解
func (p * ConnPool) Get(ctx context.Context) (*Conn, error) {
// 连接池关闭信号为真则返回错误
if p.closed() {
return nil, ErrClosed
}
// 等待机会,其实所等待的就是是否可以向queue令牌桶中传入一个空struc
// 进而判断是否可以拿到连接,或者建立新连接在或者就是报错
err := p.waitTurn(ctx)
if err != nil {
return nil, err
}
// 试图从已经存在的空闲连接中获取可用连接
for {
p.connsMu.Lock()
cn := p.popIdle()
p.connsMu.Unlock()
if cn == nil {
break
}
if p.isStaleConn(cn) {
_ = p.CloseConn(cn)
continue
}
atomic.AddUint32(&p.stats.Hits, 1)
return cn, nil
}
// missed计数加一,表示一次从连接池中未命中连接的次数
atomic.AddUint32(&p.stats.Misses, 1)
// 拿不到空闲可用连接则进行新链接的建立,也就是newConn
newcn, err := p.newConn(ctx, true)
if err != nil {
p.freeTurn()
return nil, err
}
return newcn, nil
}
这里有两个子函数值得注意,一个是waitTurn,用来获取到机会令牌(获取到才能进行下面操作如空闲连接的获取或者新连接的建立);另一个是newConn方法,也就是新的连接的建立。我们可以进入里面看看其实现方式,如下:
func (p *ConnPool) waitTurn(ctx context.Context) error {
// 判断ctx是否超时
select {
case <-ctx.Done():
return ctx.Err()
default:
}
// 判断是否能向queue(连接池队列的大小)中写入数据,如果能说明有空闲连接,则返回正常(nil)
select {
case p.queue <- struct{}{}:
return nil
default:
}
timer := timers.Get().(*time.Timer)
timer.Reset(p.opt.PoolTimeout)
// 还是要先判断ctx的超时情况
// 不能写入queue,等待pooltimeout时间,如果在这个时间之前能从p的queue中写入数据则正常进行下一环节(要么从可用连接离取,要么新建连接),即;
// 如果超过这个时间会报redis:connection pool err
select {
case <-ctx.Done():
if !timer.Stop() {
<-timer.C
}
timers.Put(timer)
return ctx.Err()
case p.queue <- struct{}{}:
if !timer.Stop() {
<-timer.C
}
timers.Put(timer)
return nil
case <-timer.C:
timers.Put(timer)
atomic.AddUint32(&p.stats.Timeouts, 1)
return ErrPoolTimeout
}
}
func (p * ConnPool) newConn(ctx context.Context, pooled bool) (*Conn, error) {
// 熟悉的拨号方式获取到dialer中的连接,默认就是tcp的连接
cn, err := p.dialConn(ctx, pooled)
if err != nil {
return nil, err
}
p.connsMu.Lock()
p.conns = append(p.conns, cn)
// pooled为真表明该连接可以放回到连接池中
if pooled {
// 如果池子已经满,则不放回
if p.poolSize >= p.opt.PoolSize {
cn.pooled = false
} else {
p.poolSize++
}
}
p.connsMu.Unlock()
return cn, nil
}
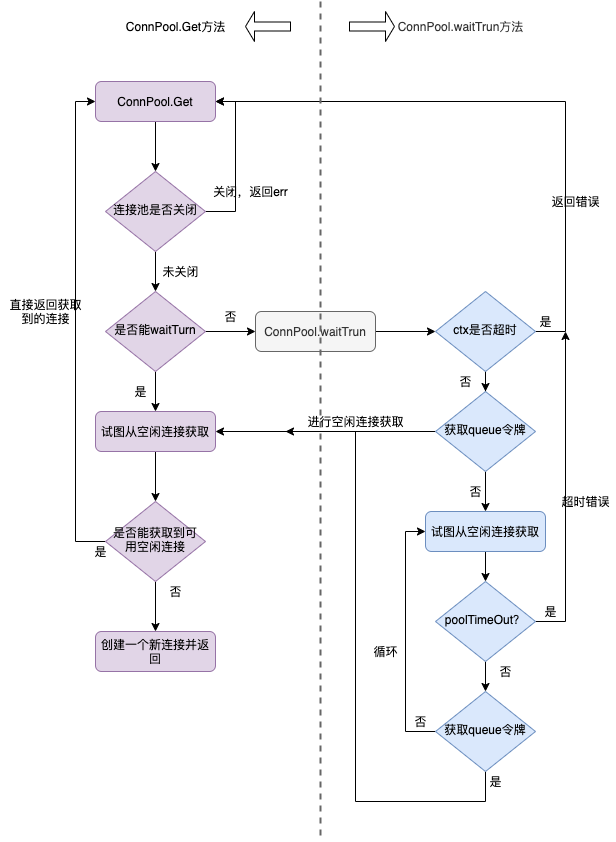
上述waitTurn源码中,正常情况下,我们只是判断一下ctx上下文是否超时,以及是否可以向令牌queue中投入令牌,如果以上均满足,则表名该协程拿到了”机会“,否则,就进入一个select选择条件判断中,这里看似逻辑复杂晦涩难懂,其实很简单:首先还是要判断一下这里的ctx是否超时,若正常,则向queue尝试投入令牌(插入空的struct),如果一旦插入成功就意味着拿到了机会,则会正常的返回,否则的话,一旦超过了一定的时间,也就是PoolTimeout,那么就会抛出redis pool的timeout超时异常,并返回给客户端,值得注意的是这里的timeout并不是用户端和redis服务端通信的超时,而是该协程对全局redis连接池中连接获取的超时,这里要注意不要看到timeout就混淆。
由于此处相对有点绕,故放出对应方法的流程图帮助理解:
- 连接池连接的放回or释放
我们再度把思维放回到withConn方法中,可以看到defer后执行的方法,包括了一个releaseConn,而这里千万不要被名称迷惑(释放连接),对于连接池,释放既可以指连接真正的断开,也可以指把不用的连接放回到连接池中,代码逻辑十分清晰简单,就不赘述了,源码如下:
func (c *baseClient) releaseConn(cn *pool.Conn, err error) {
if c.opt.Limiter != nil {
c.opt.Limiter.ReportResult(err)
}
if isBadConn(err, false) {
c.connPool.Remove(cn, err)
} else {
c.connPool.Put(cn)
}
}
其实如果稍微对net包和网络模型有所了解的伙伴们就知道,remove所做的一定就是吧net包中的conn关闭掉,而我们点到下层函数逐一查看,也确实是这样的;而Put函数所执行的,顾名思义就是把连接放回到conn切片中进行保存,这里也就不对加锁和一些原子等避免并发问题的操作进行赘述了。到这里,go-redis的源码基本已经掌握,那么接下来,我们一起探究一下线上错误的原因。
从原理到实践的探究
由于报错的源码位置已经明确,就是在用户协程的获取连接池中连接的时候,当执行到waitTurn的时候,获取令牌超时所导致的。所以,从这个角度出发,应该是在某一个时间段内,很多网络请求同时长时间占用了这个连接池子的连接所导致,于是我突发奇想的想要模拟一下单纯从连接池里获取连接,即ConnPool的Get操作,来验证一下我们对源码的探究。由于go-redis没有对外暴露从baseClient的接口(或者说并没有暴露一个client的连接池接口),因此我手动修改了一下源码将get方法暴露,并在test1方法中调用,我的测试代码如下:
// 测试一,暴露连接的底层池子,后台起个协程时时观测
func test1() {
// 这里的client设置了poolSize=20
client, clean, err := newRedisClient()
defer clean()
if err != nil {
return
}
log.Println("查看一下底层连接池对象",client.GetPool())
go func() {
// 定时器,每隔500ms查看一下连接池中的连接数量
t:=time.NewTicker(500*time.Millisecond)
defer t.Stop()
for {
<-t.C
fmt.Println("每500ms查看一下池中连接的的数量,当前数量:",client.GetPool().Len())
}
}()
// 每隔一秒,从连接池中获取连接,并
for {
cnn,err := client.GetPool().Get(context.Background())
if err != nil {
log.Println("获取池子的连接失败:err,",err) // 主要就是想看一下报错是否是我们期望的 connection pool timeout
}
log.Println("当前连接为:",cnn)
time.Sleep(1 * time.Second)
}
}
果然,当我运行了上述代码,结果完全在意料之中。在起初的20秒,由于poolSize为20,因此连接池稳定的在增长连接,并没有任何问题,打印的日志如下:
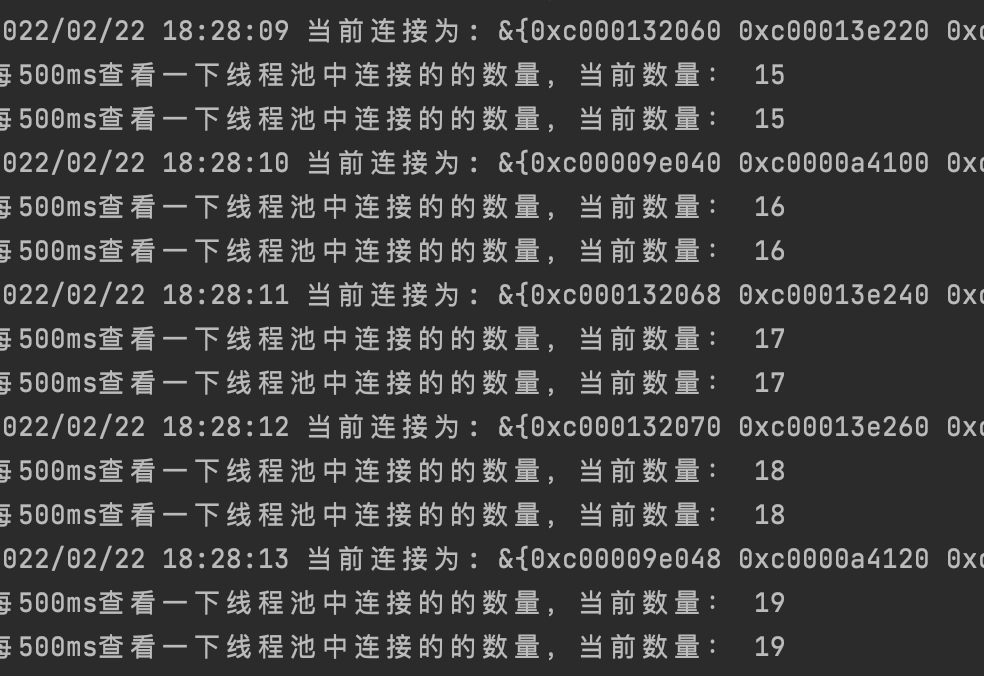
而当20秒之后,我发现日志开始变得不同:
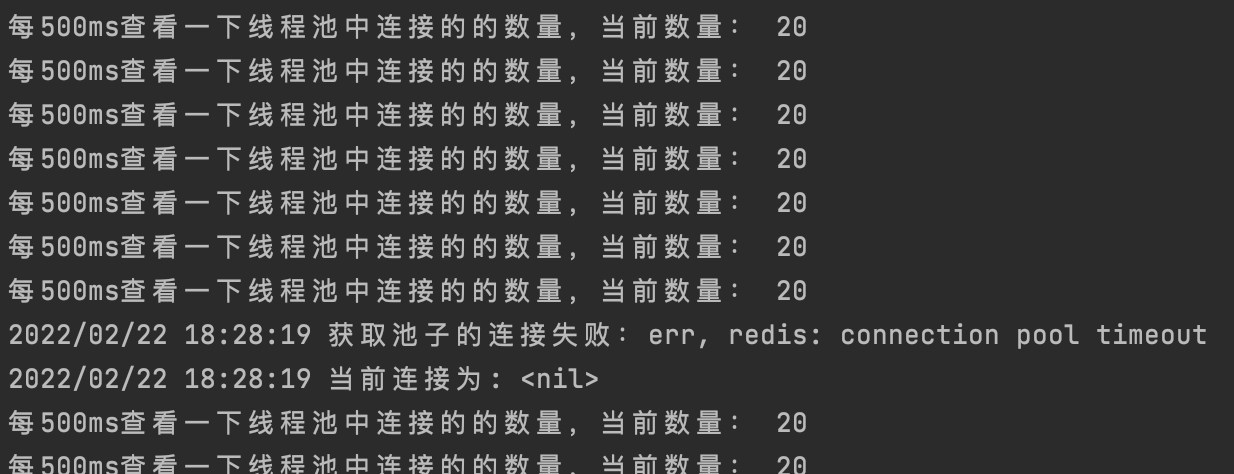
而令我开心的是,我成功的复现了这个”connection pool timeout”的报错字样,而且恰恰和我所分析源码的思路一样,得到了很好的验证,也就是说当我们的被占用的连接数超过poolSize时,因为其他的请求goroutine无法获得queue的令牌机会,而导致最终超过了PoolTimeout的时间而被connPool抛出了err。而解决test1代码err的方法很简单,我get完之后,再把它put回池子里就可以了,因此我将代码“client.GetPool().Put(cnn)”加入到“time.Sleep(1 * time.Second)”,就完美的解决了这个错误,你也可以run一下验证,修改完的代码如下所示:
func test1() {
// .....
for {
cnn,err := client.GetPool().Get(context.Background())
if err != nil {
log.Println("获取池子的连接失败:err,",err) // 主要就是想看一下报错是否是我们期望的 connection pool timeout
}
log.Println("当前连接为:",cnn)
time.Sleep(1 * time.Second)
client.GetPool().Put(cnn) // 将连接放回池子中
}
}
如果你感觉上述例子不够清晰,我们看一下下面的例子,其实就是首先定义一个poolsize大小为10的连接,在client获取到redis连接后,我们强制sleep一下这个获取到的conn(本质底层是一个net包的conn对象),并且我尝试用10个goroutine打满这个连接池,而后再用额外的10个goroutine执行自定义的ping(实际上就是get key的redis操作),同时同样起了一个后台goroutine监听这个连接池的状态,当10s过后(conn被放开),我们又起了一个goroutine尝试执行get key的操作,并在主goroutine用select阻塞程序,代码如下:
func test4() {
client := redis.NewClient(&redis.Options{
MaxRetries: 0,
// 自定义一个dialer,延迟10s返回给client
Dialer: func(ctx context.Context, network, addr string) (net.Conn, error) {
log.Print("Dialer called")
conn, err := net.Dial(network, addr)
log.Printf("打印一下conn,连接为:", conn)
time.Sleep(10 * time.Second)
return conn, err
},
PoolSize: 10,
})
// 自定义一个ping
ping := func() {
res, err := client.Get("key").Result()
if err != nil {
log.Print(err)
return
}
log.Println(res)
}
// 占满连接池
for i := 0; i < 10; i++ {
time.Sleep(200 * time.Millisecond)
go ping()
}
// 超过poolsize后再度获取连接
for i := 0; i < 10; i++ {
time.Sleep(500 * time.Millisecond)
go ping()
}
go func() {
for {
t := time.NewTicker(1 * time.Second)
<-t.C
log.Println("循环打印连接的情况:", client.PoolStats())
}
}()
time.Sleep(10 * time.Second)
go func() {
_res, err := client.Get("key").Result()
if err != nil {
log.Println("err:", err)
return
}
log.Println("十秒后正常读取数据 ", _res)
}()
// 阻塞主goroutine
select {}
}
结果呢,不出所料,在前十个goroutine请求的时候,会等待10s当conn获取到redispool中后,成功执行并取到了redis的key的结果,而后10个goroutine,触发了redis pool timeout的报错,10s之后的goroutine也同样正常执行了get key 的操作,并获取到了其结果。debug的结果如下:
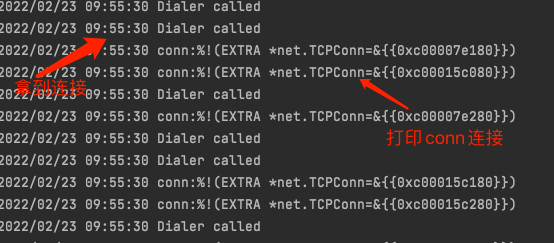
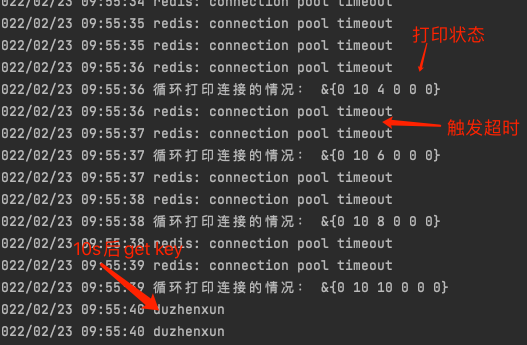
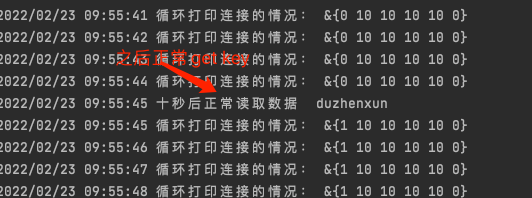
其实从上述的图中,细心的小伙伴也会发现,在最后的"正常获取数据"日志之后。“循环打印连接的状态”显示,连接池stat的第一个属性从0变成了1,而我们通过查看stat对应的源码可知,这是hits变量,是命中了一次连接池的连接(证明了连接池起到了作用)。这里多说一嘴,其实Stat方法还是很有必要研究一下的,尤其是涉及到redispool的监控和调优,有着重要的意义,
源码为了方便阅读,直接贴了出来:
func (p *ConnPool) Stats() *Stats {
idleLen := p.IdleLen()
return &Stats{
Hits: atomic.LoadUint32(&p.stats.Hits),
Misses: atomic.LoadUint32(&p.stats.Misses),
Timeouts: atomic.LoadUint32(&p.stats.Timeouts),
TotalConns: uint32(p.Len()),
IdleConns: uint32(idleLen),
StaleConns: atomic.LoadUint32(&p.stats.StaleConns),
}
}
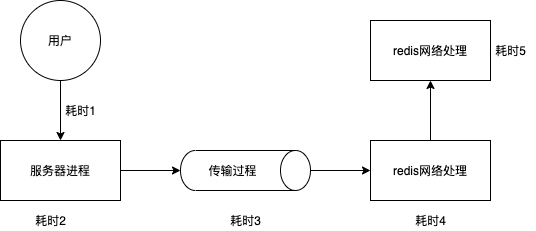
其实上面两个例子的本质不大一样,但也有相似之处,我尝试简单的画出了一个从用户端到redis端的一个请求的主要流程,并标注了如下几个耗时的点,比如test1内部我模拟的是服务器进程内获取redispool的连接过多且每个goroutine占用连接过长的现象;而test2模拟的是当我们获取到了一个redisconn,但是一直未能投入使用(强制占用),其实是可以理解为图中耗时3的情况(但并不一样,因为当耗时3处过久,redis服务端会抛出自身的timeout且记录这个错误的),具体参考下图:
线上监控中的线索
当然,具体是什么原因还是要从多方面的监控数据来确定,于是乎我从几个维度去查看了一下整个功能流程的监控,按流程顺序大致分为 1)envoy服务大盘监控 2)服务容器pod监控 3)redis集群监控 4)其他业务涉及实例的监控等。
envoy 大盘监控
- 首先是网络服务请求qps的监控图
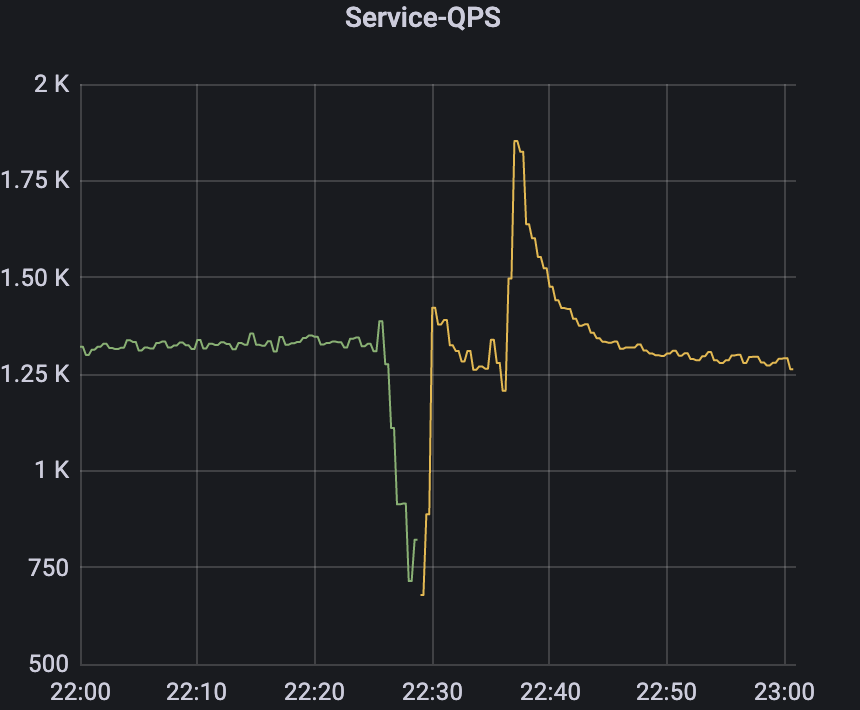
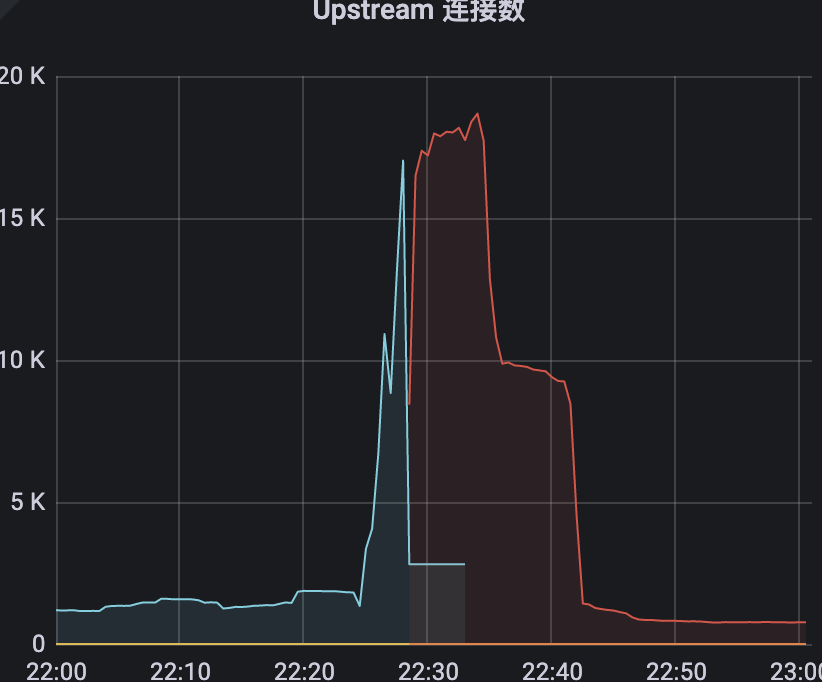
2)其次是上游upstream连接数
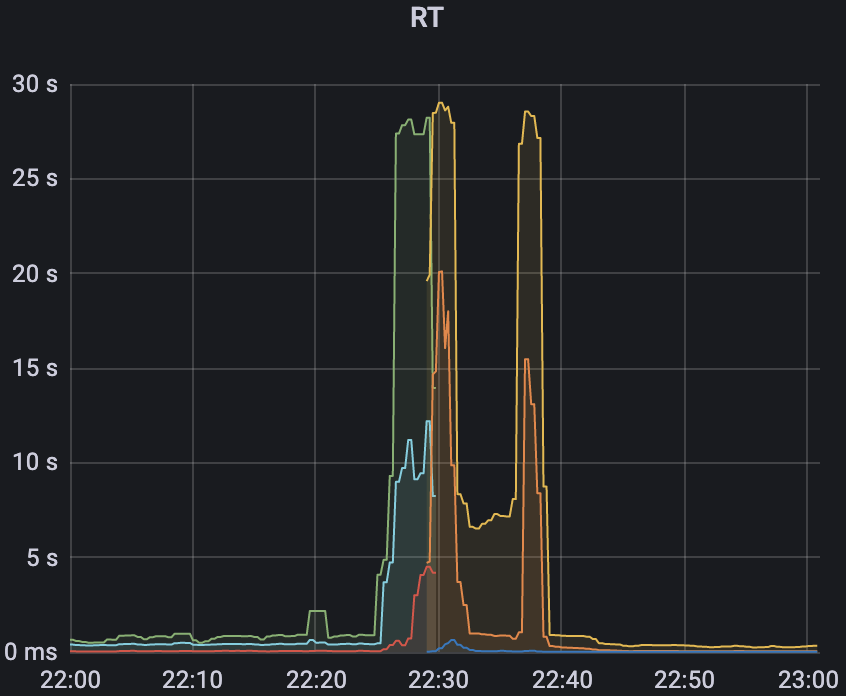
3)最后是看pod请求的RT耗时
我们对比一下正常的服务的日志(我选择了后一天的,因为后一天的量更大一点)
4)后一天的监控图对比
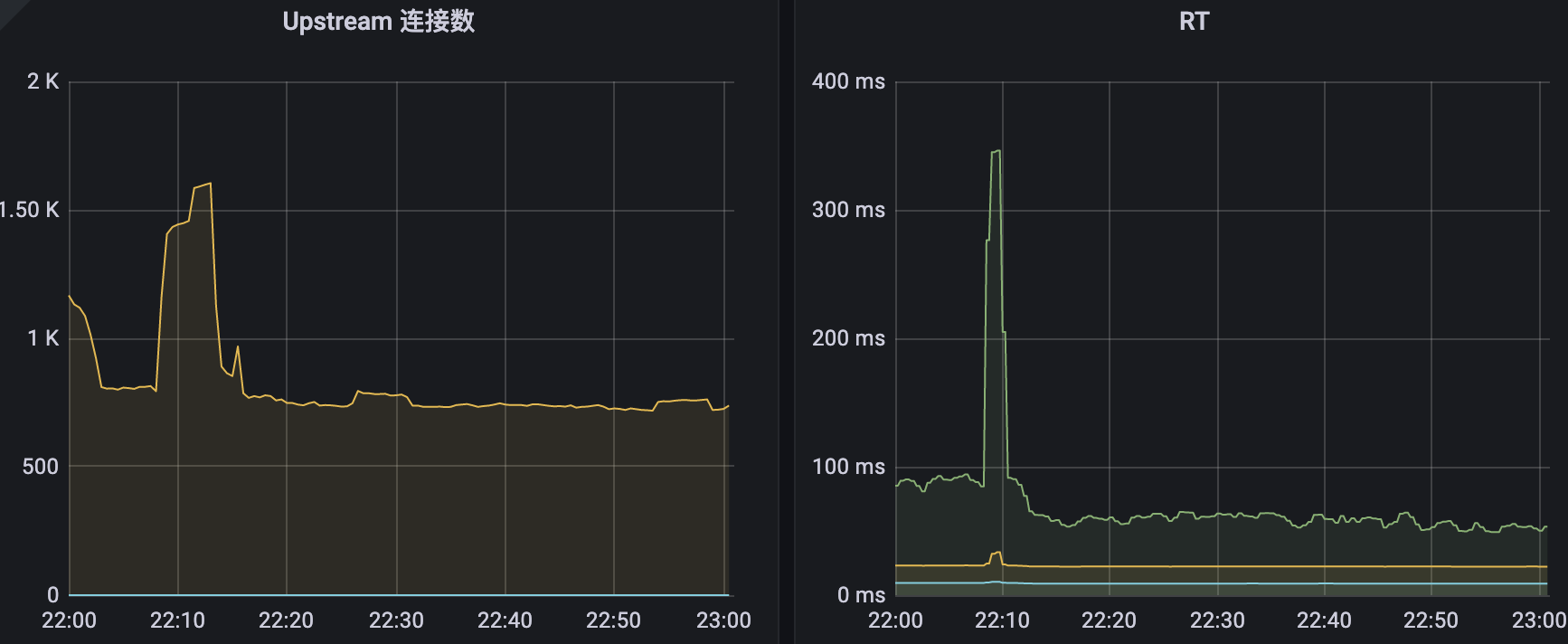
很明显的可以看出,在22点20分的时候,进入了服务请求的高峰期,但是不知道出了某种原因,导致请求量骤减,而此刻对应的上游连接数却不断的骤增从千级别一直涨到近18k,而且RT居然在这一区间内达到了惊人的27s(不要慌,这个只是pod的RT,线上用户早就会被请求超时所截断,并不会给用户造成卡死的体验),而对比了后一天的正常情况的监控来看,请求量并没有达到瓶颈。因此仅仅从k8s的监控情况来看,无法断定是哪里出了问题,于是我又开始看redis集群监控。
k8s和容器监控
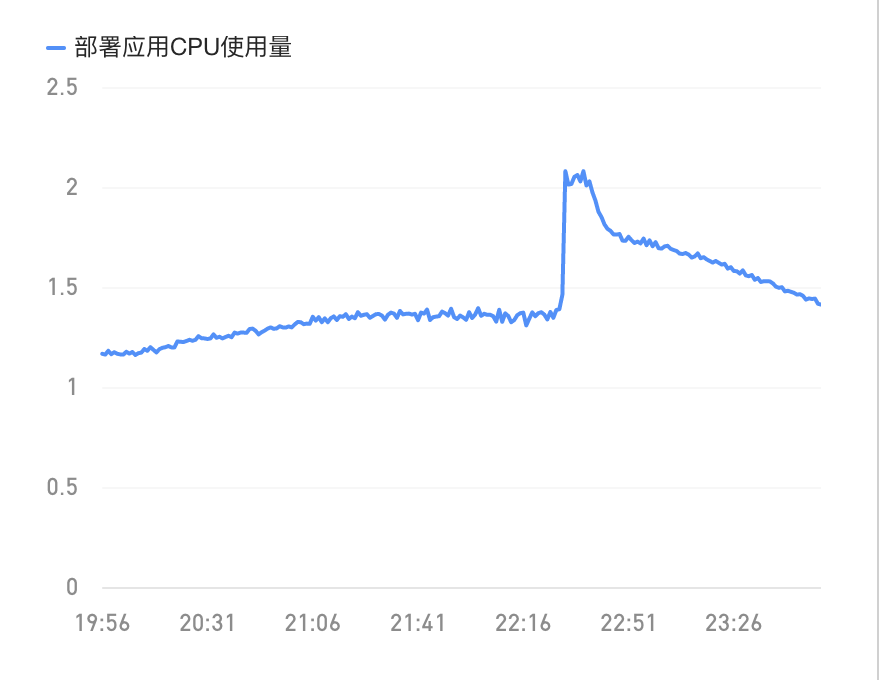
1)容器组的cpu资源监控
2)容器组的内存使用监控
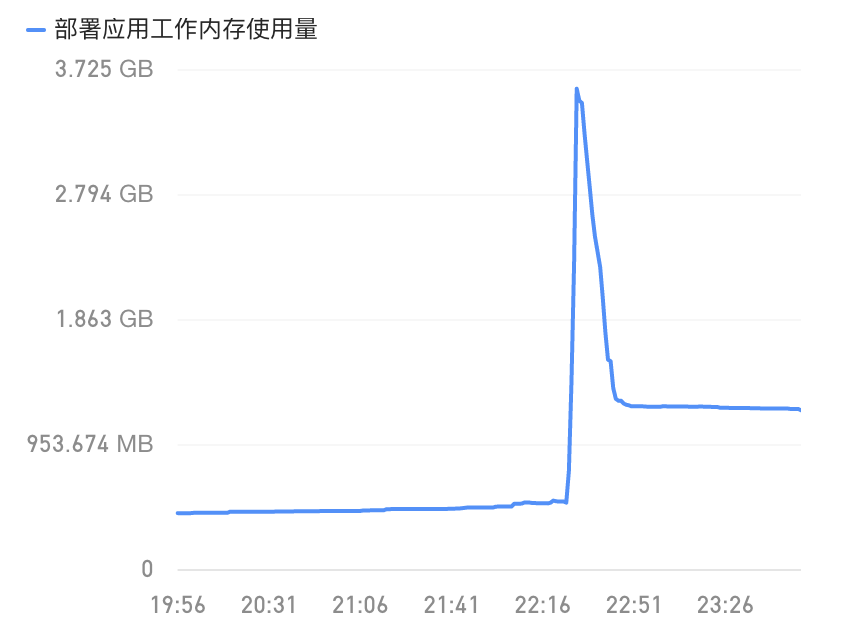
依然很明显,对于段评服务的pod组来说,在这个时间点,cpu和内存的使用飙高,虽然服务cpu和内存使用率突然升高可能有很多原因导致,但是结合envoy的监控我们可以初步怀疑是在这一个时间点,流入pod的请求量突然升高,导致cpu需要去管理这些网络io从而升高资源占用;与此同时,由于某些原因,容器内的服务可能由于处理过慢而造成了goroutine堆积从而导致了oom的趋势(没有oom类的报错,容器也没有自动扩容)。
redis集群监控
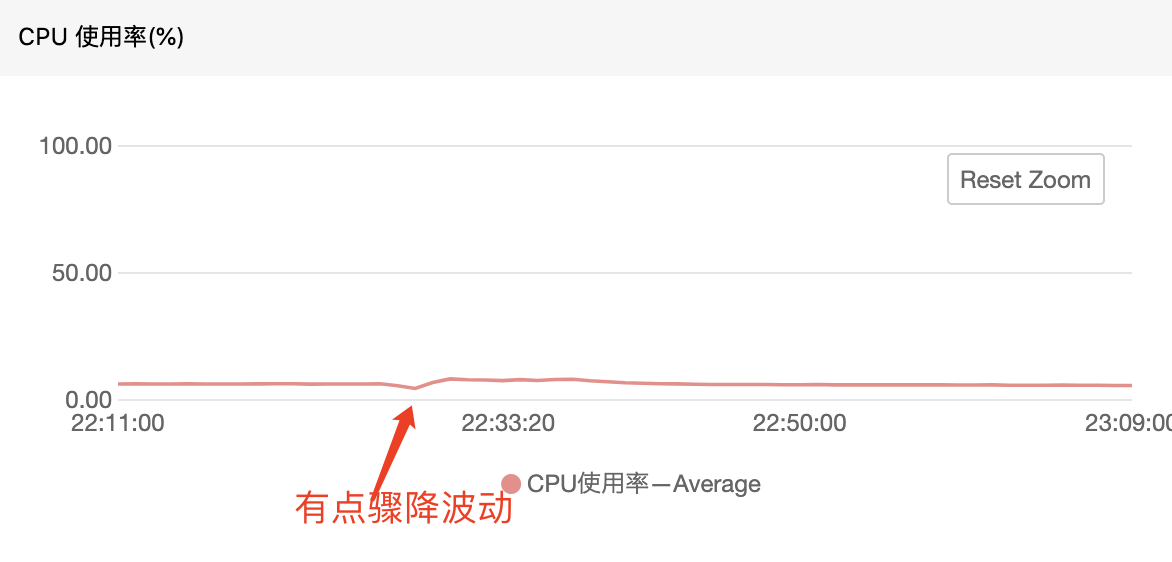
1)redis线上集群的cpu监控
2)redis线上集群的内存监控
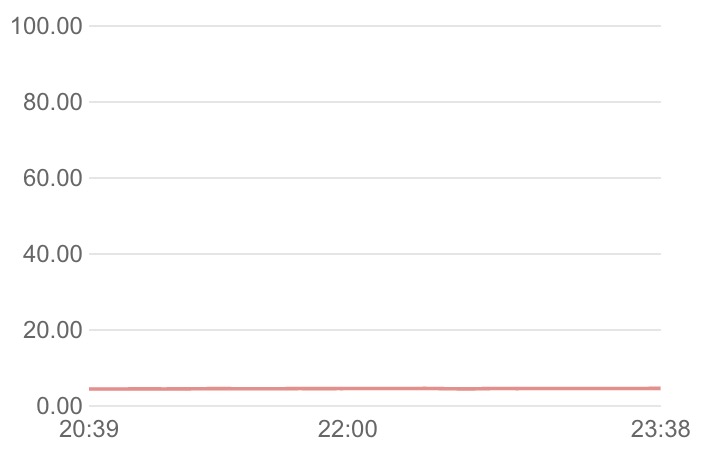
这里可以看出,redis整体的集群资源还是处于稳定空置的状态,cpu的使用率在5%左右,而内存也仅仅只有4%,所以可以排除是redis集群的问题了(当然不是,因为上面redis-pool的源码已经说明了是服务的进程内的问题了)。这里有必要提一下,之所以redis集群的资源使用率这么低,是因为功能刚刚上线,还没有起量,展示了一下三月初的服务(上线两周后)的cpu使用率,如下图:
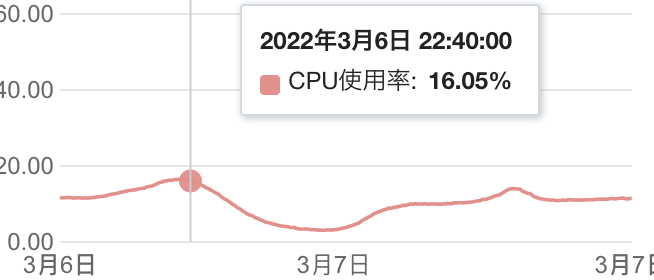
虽然从redis的监控图中没有看出来问题,但是我们可以留意到,在出问题的哪个时间点,redis的cpu有一个向上的抖动,而后迅速下降的情况。如果用形象的话来说,就好像一个排水口,在某一时刻突然引来了一股汹涌的波涛,从而导致而在排水口瞬间被堵塞;此时如果我们对出水口的速度进行求导数,那么其趋势会先骤升又下降,也就如redis的cpu所示,因此从排水口的出水侧看,就好像排水口被堵住了一样没有怎么出水。redis也同样,由于在某个瞬间的请求量骤升而导致服务在瞬间断开从而看起来好像闪断一样。
下游服务的监控
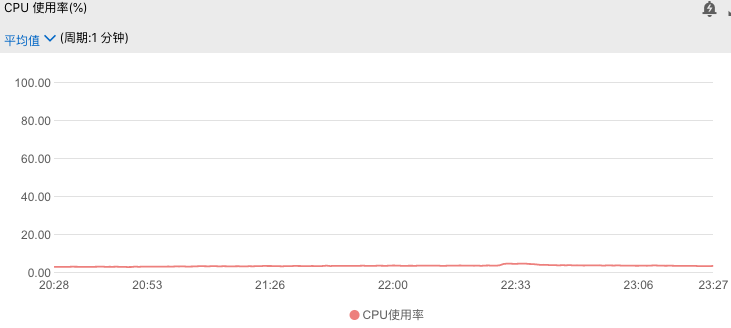
为了定位最终的问题所在,我还是看了一下下游服务的监控,也就是我的服务调用的书库服务。如果我们的服务RT过长是由于下游服务的问题所导致,那么下游服务必然也会因为某个事件而造成超时抑或报错的问题。而由于该服务为grpc服务,没有来得及加入监控,因此我只查看了一下其redis的性能,如下:
1)redis的cpu监控
2)redis的内存监控
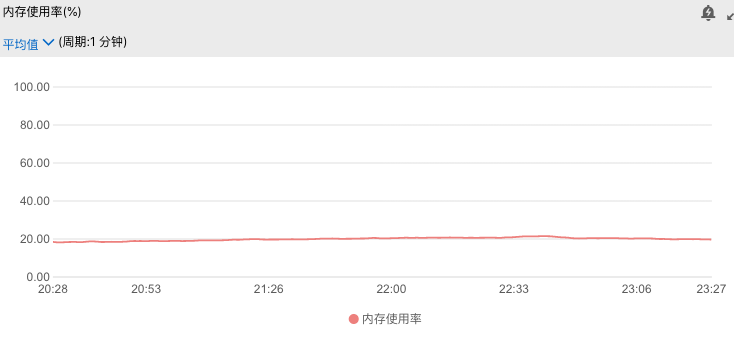
可以清楚的看到下游服务如此平静毫无波澜十分稳定。
结论篇
我们通过源码分析,理解了go-redis连接池的底层原理和实现;又通过观察出故障的服务的pod监控、redis监控以及相关下游服务的监控,可以得出如下结论:由于用户高峰期的抵达,在同一时刻有大量的请求打到对应的服务pod上,纵使redis本身处理能力很快,而由于我们设置的redis连接池的poolsize过小(只有5),在瞬间的并发请求redis的goroutine过小,不足以消费的完堆积在pod的网络io队列中的goroutine,因为gin框架下一个用户请求就会开启一个goroutine,所以如果流入的goroutine过多,而处理的很慢,就会对后续流入pod的请求造成一定的问题(比如envoy大盘上的连接堆积,rt回环时间过大);而对于pod中段评服务进程内的goroutine,也会因为poolsize过小拿不到waitturn的令牌机会而抛出”redis: connection pool timeout“的报错。而对于k8s的管理服务来说,虽然流量过大,但是还没有触发到pod的扩容阈值,因此pod也没有进行及时的扩容,这里补充一下运维老哥提供的扩容记录hpa:
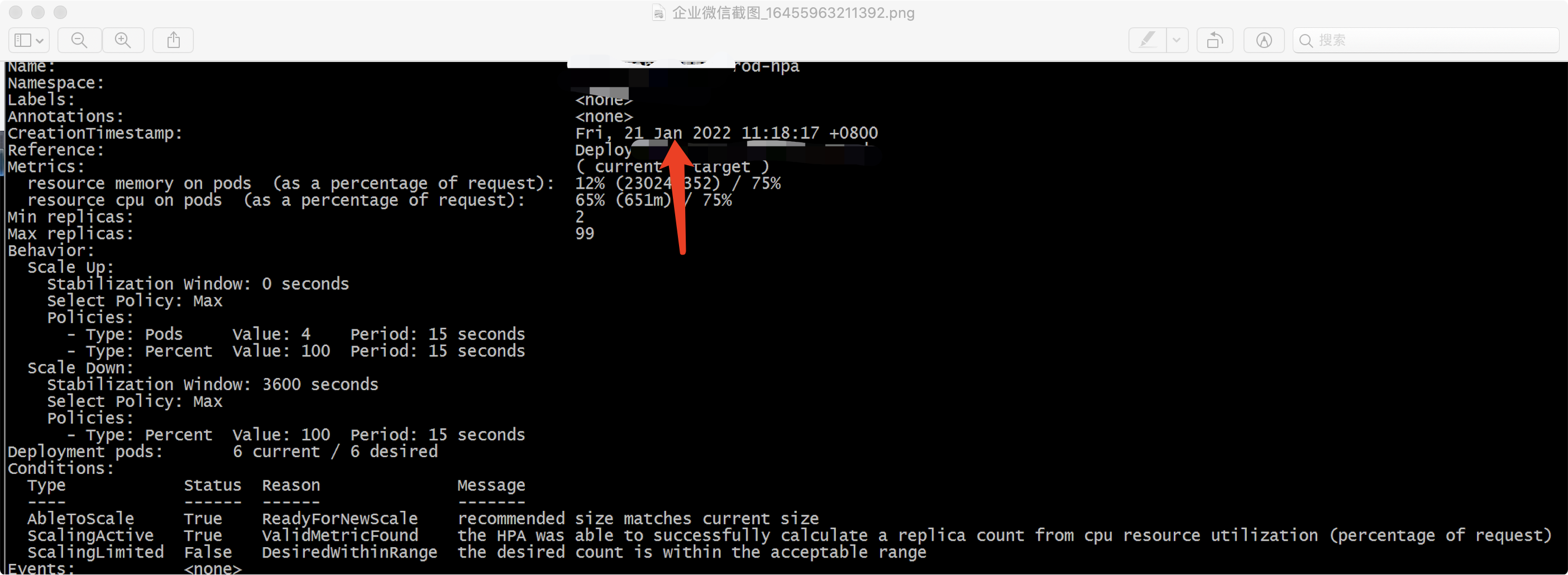
可以看到距离最近的一次扩容只是1.21(ps:这是我们压测的扩容时间),当然,上述的分析难免会有一些遗漏的点,比如监控的误差等等,但是总体的分析还是相对准确且合理。
解决方案
如果想要解决这个问题,我们需要做什么工作?最关键的一点就是我们要找到pod所能承受的连接数和redis-pool连接池以及redis本身支持的连接数的一个平衡关系。比如,一个pod支持的最大并发连接为1000,redis本身支持10000,而我们的redis-pool的poolsize也要找到一个合适的值,比如100。那么我们可以简单的理解为在高峰期,我们服务的可以以最高的连接负荷扩容到10个pod去处理请求;而如果只设置成5,或者10的poolsize,就会造成pod不会扩容,而进程内会出现连接池超时的报错。同样的,如果假设10个pod都已经打满,以1000的并发处理服务请求,那么此时就需要对redis进行升配了(当然从我们redis监控中也会得到相应的反馈)。当然,最好的办法就是能够实时观测进程内redis-pool的stat,并结合实际生产环境的情况进行动态调整,不过这个实现起来还是需要很多的时间的。
以上便是我通过一次线上服务的日志报错,对底层源码的深入探究以及线上监控的深度排查,不得不说确实提高了我golang源码阅读的”功力“,同时也让我对redis连接池的底层有了深入的了解,并且也提高了生产环境的问题排查能力。
番外篇-后续
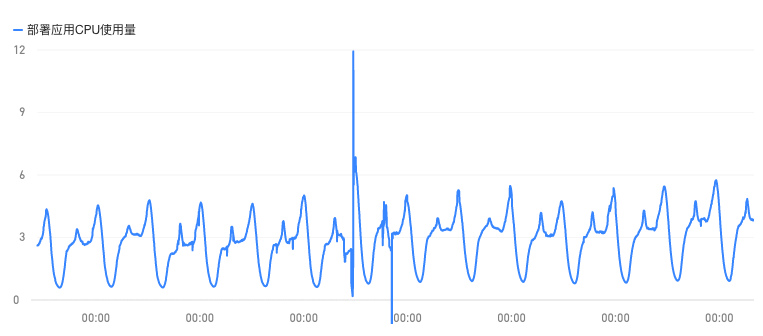
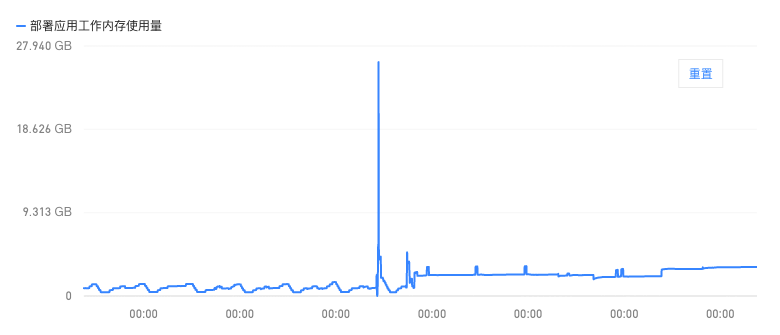
在我发现了redis-pool的poolsize设置过小后,我们把线上服务的连接池进行了扩容(由框架默认的5个增加到了1000而后又增加至2000,可想而知高峰期来临时的请求数量的前后差异性),同时为了保险起见,我们也将k8s的pod的minReplicas设置调大,保证了在高峰期来临的瞬间,也能有足够的pod副本来处理服务(虽然会稍微消耗资源,但是保证了服务不出出错)。而后的几天,服务器的日志就没有出现redis-pool的报错了,下面就是后续pod的监控,简单列了cpu和内存的:
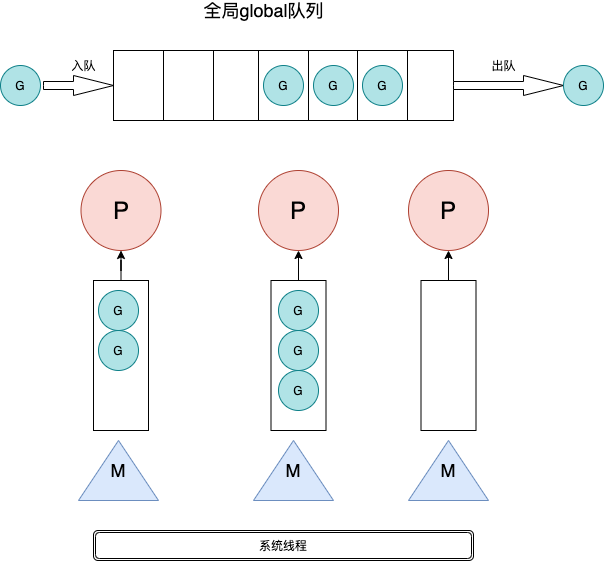
而与此同时,在同事看了我这篇文章之后为我提供了另一个方面的意见,是从golang进程本身的GMP调度模型角度来考虑。我们知道golang的调度模型属于三大并发模型中的”两级线程模型“,M个用户线程对应N个内核线程,有着相当高的并发效率,而且其主要是通过三个实体进行管理的分别为:G(Goroutine),M(Machine),P(Processor),这里不全部展开说他们之间的详细调度的交互方式,只是简单的概括一下有助于后面的分析:G为goroutine的运行时抽象的描述,也就是我们口中经常说的golang的用户级别的协程,每当我们代码里写出”go funcName“的代码样式的时候,G其实就涉及到了一个goroutine的新建、休眠、恢复和停止等状态的管理(这个管理就是runtime运行时的管理);而M则代表OS的内核级别的线程,是操作系统层面调度和执行的实体,简单的说你想在你的代码段中进行一次系统调用,虽然你没有显示的去声明以及初始化一个系统线程,你依然需要M的执行和操作系统级别的资源进行交互;而P是G和M的桥梁,它实现了对资源的一种抽象和管理(它不是具体的一段代码实体,而是一个管理的数据结构,控制着go代码的并行度)。
那么golang是如何对goroutine进行管理和调度的呢?首先我们要知道,在go进程中,是有一个全局的goroutine队列用来存放所有的go任务队列,而与此同时每一个P中还会有一个Local的队列用来存放每个P对应管理的G。如果在运行时,想要运行到我们的代码段并执行的话,必须要有一个M来绑定一个P并从其Local队列中取出要执行的G,而后M会启动一个系统级别的线程去执行。这里就需要插入一下go调度的核心算法work-stealing:
- 每个P维护一个G的本地队列;
- 当一个G被创建出来,或者变为可执行状态时,就把他放到P的可执行队列中;
- 当一个G在M里执行结束后,P 会从队列中把该G推出;如果此时P的队列为空,即没有其他G可以执行,M就随机选择另外一个P,从其可执行的G队列中取走一半。
为了让大家看的清晰,我简单绘制了一下GMP的关系图如下:
上面我讲述了是所有的GMP都美好的运行着,但是我们知道程序在运行的时候经常会出现类似系统调用或者网络问题等阻塞(golang的网络底层通过netpoller实现了网络IO阻塞不会导致M被阻塞仅阻塞G),而如果让某个G长久的阻塞而影响阻碍其他G的运行,再或者某个G一直占用M不释放而导致某些绑定了P的G甚至go进程全局队列中的G得不到执行,这是一种极大浪费资源的现象,对于并发高效的golang来说是无法容忍的,因此必须要有抢占式的调度,这里比如当goroutine因为channel操作阻塞的时候,会被放到一个wait队列中并将状态修改为waiting状态;此时的M就会去寻找其他的G(按着一定的策略)并执行;倘若此时P中没有可以执行的G了,M就会解绑P并休眠;当这个G被唤醒的时候,则会加入到相应的P的局部队列中等待被执行.以上就是从宏观的角度对 Goroutine 和它的调度器进行的一些概要性的介绍,我想通过上述的对GMP调度的讲解,来分析如果在我们业务高峰期的时候,每秒几万的服务请求打到server时,每一个请求就会创建一个新的goroutine并且每一个goroutine都要做相应的下游业务逻辑比如从数据库或缓存中获取数据,进行网络通信和系统调用等等操作。倘若处理效率不得当,就会有大量的goroutine堆积,而在runtime时候go对各个线程的调度分配都需要耗费一定的资源,而对于我们目前才用云式服务来讲,当pod中运行的go程序处于阻塞状态的goroutine过多而导致堆积,且此时pod的指标达到了一定的阈值,就会进行横向扩容(如上文pod数量在高峰期增加);那如果没有设置阈值,则会有比如OOM的内存溢出风险,异或就是还没有到达oom的地步但是redis-pool无法支撑此量级的压力。当然,不仅仅是redis,像其他的grpc、mysql、elasticsearch等数据库或其他方需要调用的服务,都会有类似潜在的风险发生,因此我们必须对相应的服务进行治理,比如grpc我们会有curcuit-breaker来根据下游服务的情况进行服务的治理并在一些特定的情况下进行服务的降级等等。因此,总结的说,虽然go并发能力很强,但是还是要结合业务具体的情况做特定的配置治理,否则说不定某一个时间点就会发送你意想不到的错误!