背景:delete删除后 空间却没有释放
在使用mysql的时候,发现尽管一张表删除了许多数据,但是这张表的实际占用空间却并没有变小。
现象回溯 :
手动批量插入数万条数据,然后delete 掉一部分
# 查看表空间
SELECT
TABLE_NAME AS '表名',
( DATA_LENGTH + INDEX_LENGTH )/ (1024*1024) AS "M",
TABLE_ROWS AS '行数'
FROM
information_schema.TABLES
WHERE
TABLE_SCHEMA = 'test'
AND TABLE_NAME = 'author_news';

#查看空洞空间存储大小
show table status from test like 'author_news';

返回结果中的data_free即为空洞所占据的存储空间。
此时的数据并没有被真正的删除 ,只是数据的删除标识deleteMark被打开,执行查询时,如果发现数据存在但是删除标识是开启的话,那么返回空,这便会留下许多的数据空洞、碎片,而这些空洞会占据原来数据的空间。这些空洞可能会被再度利用起来,也有可能一直存在。这种空洞不仅额外增加了存储代价,同时也降低表的扫描效率。
前提:参数innodb_file_per_table = on
(innodb引擎)MySQL所有数据都被逻辑地存放在一个空间中 ,称之为表空间 ( tablespace ) 。表空间又由段 ( segment ) 、区 ( extent ) 、页 ( page ) 组成。段就是表,区就是连续的几个页,页是最小单位。默认情况下 InnoDB存储引擎有一个共享表空间 ibdata1 ,即所有数据都放在这个表空间内 。如果我们启用了参数innodb_file_per_table ,则每张表内的数据可以单独放到一个表空间内 。
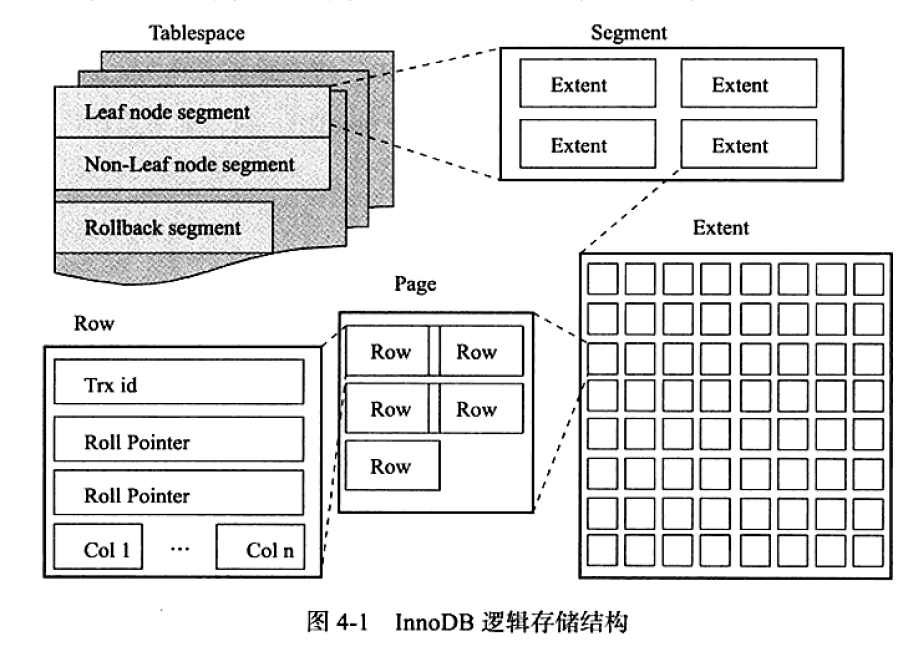
一张表单独存储为一个文件更容易管理,而且在你不需要这个表的时候,通过drop table或者truncate命令,系统就会直接删除这个文件,释放空间。而如果是放在共享表空间中,即使表删掉了,空间也是不会回收的。
从MySQL 5.6.6版本开始,innodb_file_per_table默认值是ON。(ps:MySQL 8.0版本开始,已经允许把表结构定义放在系统数据表中了,也就是对.frm为后缀的表结构文件做了进一步优化)
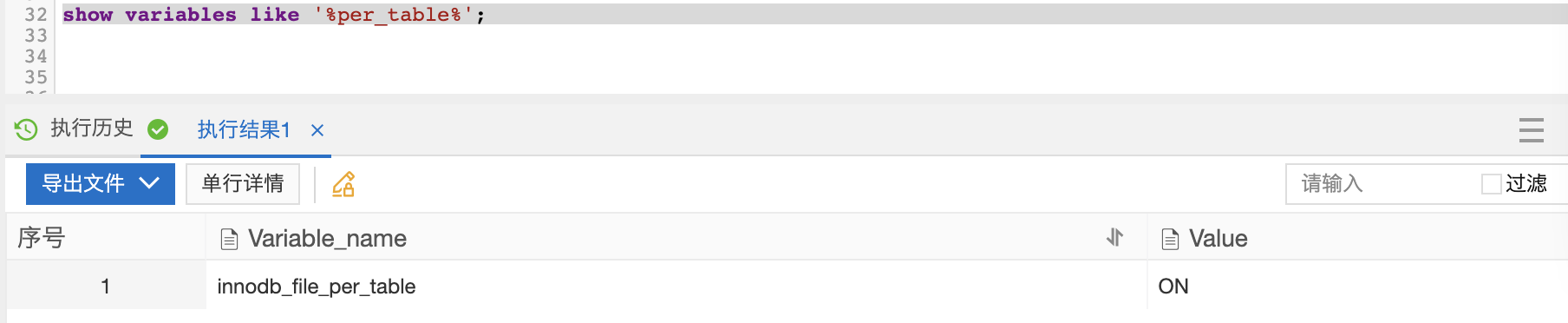
查看命令:
show variables like '%per_table%';
问题1:为什么不直接物理删除?
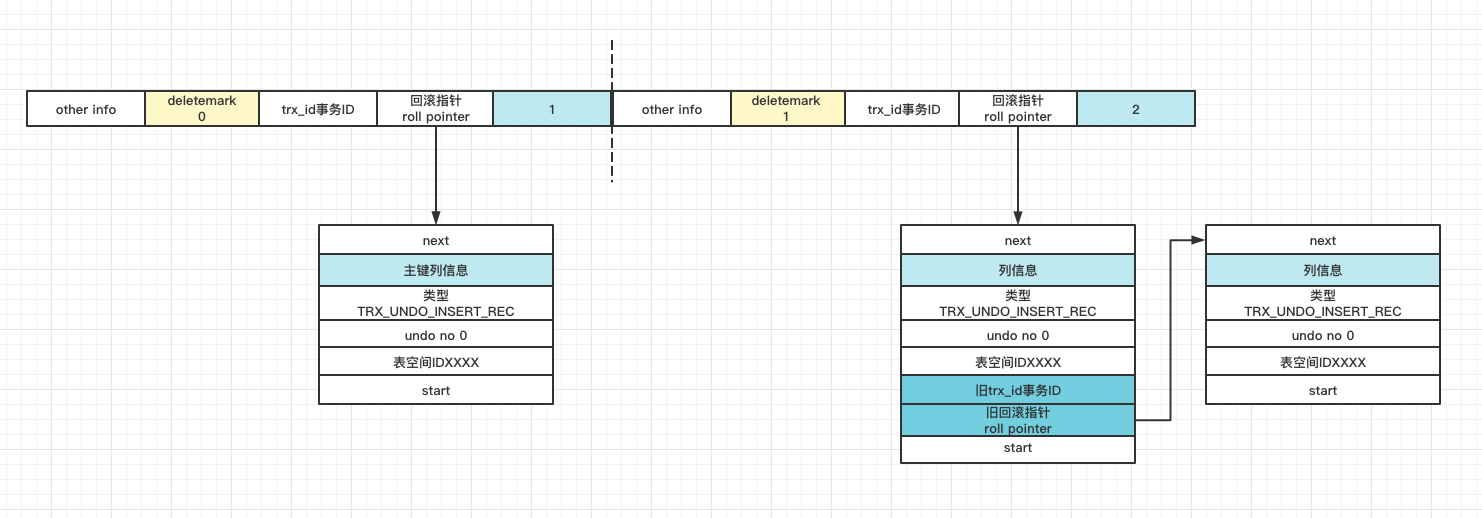
MySQL数据库InnoDB存储引擎是支持多版本并发控制(MVCC),如果数据是物理删除,也就是原来版本的数据没有了,mysql也就不再支持可重复读,这得益于undo log的存在。当读取的某一行被其他事务锁定时,它可以从undo log中分析出该行记录以前的数据版本是怎样的,从而让用户能够读取到当前事务操作之前的数据。可以简单的理解为,每次更新数据的时候将更新前的数据先写入undo log中,这样当需要回滚的时候,只需要顺着undo log找到历史数据即可。undo log与原始数据之间是用指针链接起来的,即每条数据都有个回滚指针指向undo log。
引入问题1:redo log与undo log的区别?
redo log称为重做日志,用来保证事务的原子性和持久性;undo log称为回滚日志,用来保证事务的一致性。(undo log并不是redo log的逆过程)
redo 和 undo 都可以视为一种恢复操作,一种是正向恢复,一种是逆向恢复。redo 恢复提交事务修改后的操作,保证了因断点等异常情况下的mysql重启后的数据的不会丢失,而undo回滚行记录到某个特定历史版本,实现了mysql的mvcc。两者记录的内容不同,redo通常是物理日志,记录的是页的物理修改操作(注意这里记录的不是sql,binlog记录的是sql)。undo也是逻辑日志,存放数据修改时被修改前的值。 (这里推荐文章: 详细分析MySQL事务日志(redo log和undo log))
问题2:标记删除不是很浪费空间吗?
被标记删除的数据空间是可被复用的。mysql后台还有个purge thread,功能之一就是检查这些有deleteMark的数据(另一个功能:清理undo页),当有deleteMark的数据如果没有被其他事务引用时,那么会被标记成可复用,进行真正的删除。因为叶子节点存储的数据是有序的原因(索引),这样当下次有同样位置的数据插入时,可以直接复用这块磁盘空间。当整个页都可以复用的时候,也不会把它还回去,会把可复用的页留下来,当下次需要新页时可以直接使用,从而减少频繁的页申请。

假设,我们要删掉30这个记录,InnoDB引擎只会把30这个记录标记为删除。如果之后要再插入一个ID在20和40之间的记录时,可能会复用这个位置。但是,磁盘文件的大小并不会缩小。
引入问题2:如何理解 基于页的存储方式
mysql数据是存储在磁盘上的,mysql主要的性能瓶颈其实是在磁盘IO。以机械磁盘为例,访问磁盘的时间由三部分构成: 机械臂寻道时间 + 磁盘旋转时间 + 数据传输时间。
(以机械磁盘为例,我们最终的数据都是落在磁盘的一个一个扇区上的,当一个扇区写满了,就得换下一个扇区,这时就要通过盘片的转动找到目标扇区,这是物理运动。如果要写入的下一个扇区和当前的扇区是紧挨着的,这叫顺序IO,如果要写入的扇区和当前的扇区中间隔了几个扇区,这叫随机IO,很明显随机IO需要更长的转动时间。所以查询一个数据的时候,减少IO是非常关键的,特别是随机IO。)为了减少磁盘IO,mysql采用了高效的B+树的索引结构来组织数据。
B+树
所有的B树都有着一个入口,也就是根节点。根节点(页)包含了如索引ID、INodes(内部节点)数量等信息。INode页包含了关于页本身的信息、值的范围等。最后还有叶子节点,也就是我们数据实际所在的位置。
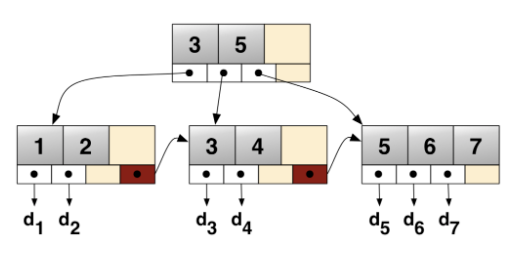
一般树的高度就代表了IO的次数,越矮的话,树的高度越低,那么对应的IO次数就越少。千万级的数据,高度在3-5左右,查询时间复杂度是O(log(N))。
页原理
当使用InnoDB管理表和行,InnoDB会将他们以分支、页和记录的形式组织起来。InnoDB不是按行来操作的,它可操作的最小粒度是页,页加载进内存后才会通过扫描页来获取行/记录。也就是说通过B+树检索到的是目标行数据所在的页,这个页上有很多数据,都是索引序号相邻的,当找到目标页后,会把目标页加载到内存中,然后通过二分法找到目标数据。
所以树的高度直接影响检索一条数据的快慢,这和数据表的大小并没有太大的关系。(ps:B+树高度的计算:假设表的记录数是N,每一个BTREE节点平均有B个索引KEY,那么B+TREE索引树的高度就是logNB(等价于logN/logB) 。
由于索引树每个节点的大小固定,所以索引KEY越小,B值就越大,索引树的高度就越小,那么基于索引的查询的性能就越高。所以相同表记录数的情况下,索引KEY越小,索引树的高度就越小,所以咱们创建索引时能用int字段建索引不用bigint字段。(推荐文章:MySQL索引背后的数据结构及算法原理)
问题3:可复用的空间一直没有被利用咋办?
页合并
删除的记录不是真的物理删除,记录被标记为删除并且它的空间变得允许被其他记录声明使用,但这删除的记录空间可能会被复用,也可能不被复用,如果很多没被复用就会造成页空间存在大量的碎片。此时页合并出场,用来优化空间的使用,提升页的利用率。简单来说就是页A现在有很多可以被复用的空间,它的邻居页B也有很多可以复用的空间,此时页A就可以和页B合并,如果合并后能省出来一页,那么多出来的一页就可以被下次使用,从而达到页最大利用的效果。

如果两个页pageA和pageB都只有少量的可复用空间,那么合并后,即使pageA可以填满,但是另一个页Page也还是有碎片空间的,并且碎片更大,这时候数据移动的开销可能要大于存储的开销,得不偿失。

一个合理的合并条件很关键,InnoDB中何时合并受MERGE_THRESHOLD这个参数影响,它的默认值是50%,两个50%就可以省出一个页。

pageA已经有50%的数据被删除了,它的邻居pageB只使用了不到50%的数据,这时候会将pageB的数据移动到pageA上,那么整个pageB就是空页了,可以提供给别的数据使用。这里有一点,除了删除会触发页合并外,更新插入可能也会触发页合并。
页分裂
此时还有一种场景,假设当我们要插入6这条数据,但是pageA目前没有足够的空间来存放一条数据,尝试找pageA的相邻页pageB,但此时pageB也没有足够的空间来存放一条数据,由于要求数据的连续性,数据6必须在数据5和数据7之间,那么只能新建一个页,新建一个页后,会尝试从pageA中移动一部分数据到新的页上,并且会重新组织页与页之间的关系,即在pageA和pageB之间会隔一道新页pageC。这样B树水平方向的一致性仍然满足,满足原定的顺序排列逻辑,然而从物理存储上讲页是乱序的,而且大概率会落到不同的区。
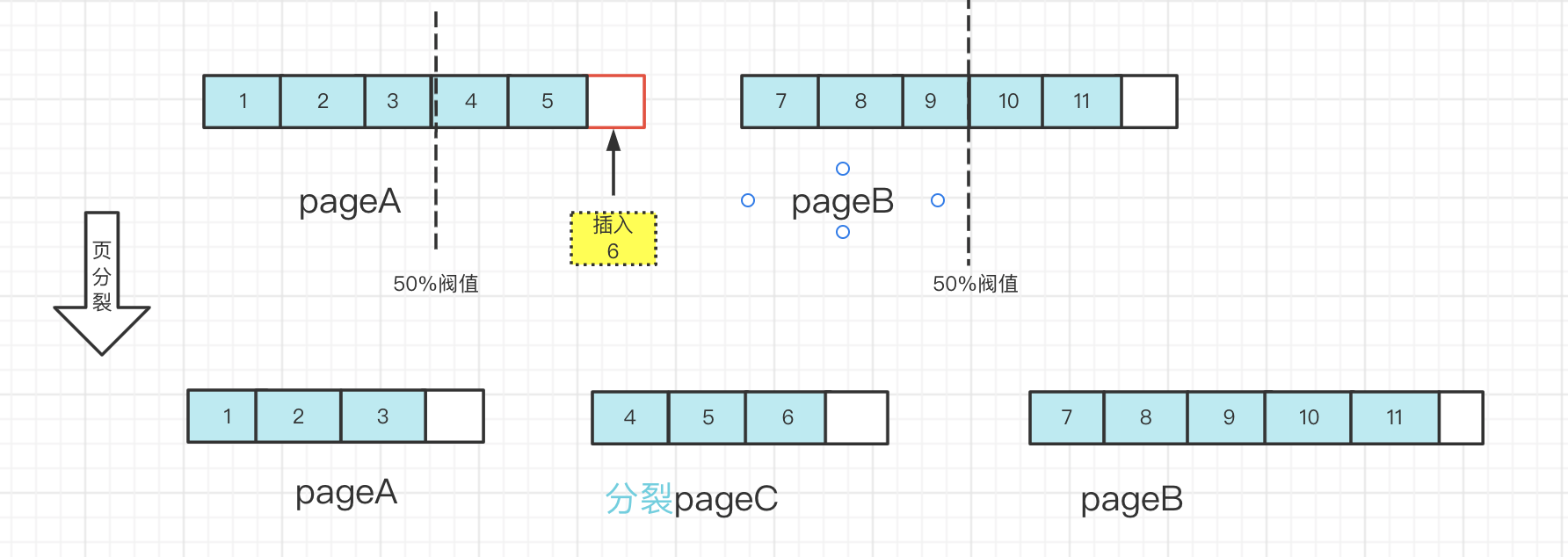
页分裂造成页的利用率降低,造成页分裂的原因有很多,比如:
1、离散的插入,导致数据不连续;2、把记录更新成一个更大记录,导致空间不够用的情况下;
不管是页的合并还是页的分裂,都是相对耗时的操作,除了移动数据的开销外,InnoDB也会在索引树上加锁,在操作频繁的系统中这会是个隐患。如果表中没有合并和分裂(也就是写操作)的操作,称为“乐观”更新,只需要使用读锁(S),有合并或者分裂操作则称为“悲观”更新,使用写锁(X)。
问题4:如何清理碎片?
重建索引可以让数据更加紧凑,页的利用率达到更高。
但是如何重建索引?
1、先drop index然后add index(推荐工具https://github.com/github/gh-ost)
2、mysql一般推荐使用:
alter table xx engine=InnoDB
这个命令可以重建我们这个表,基于mysql的online ddl,这个过程它是不影响正常的读写的,它的过程如下:
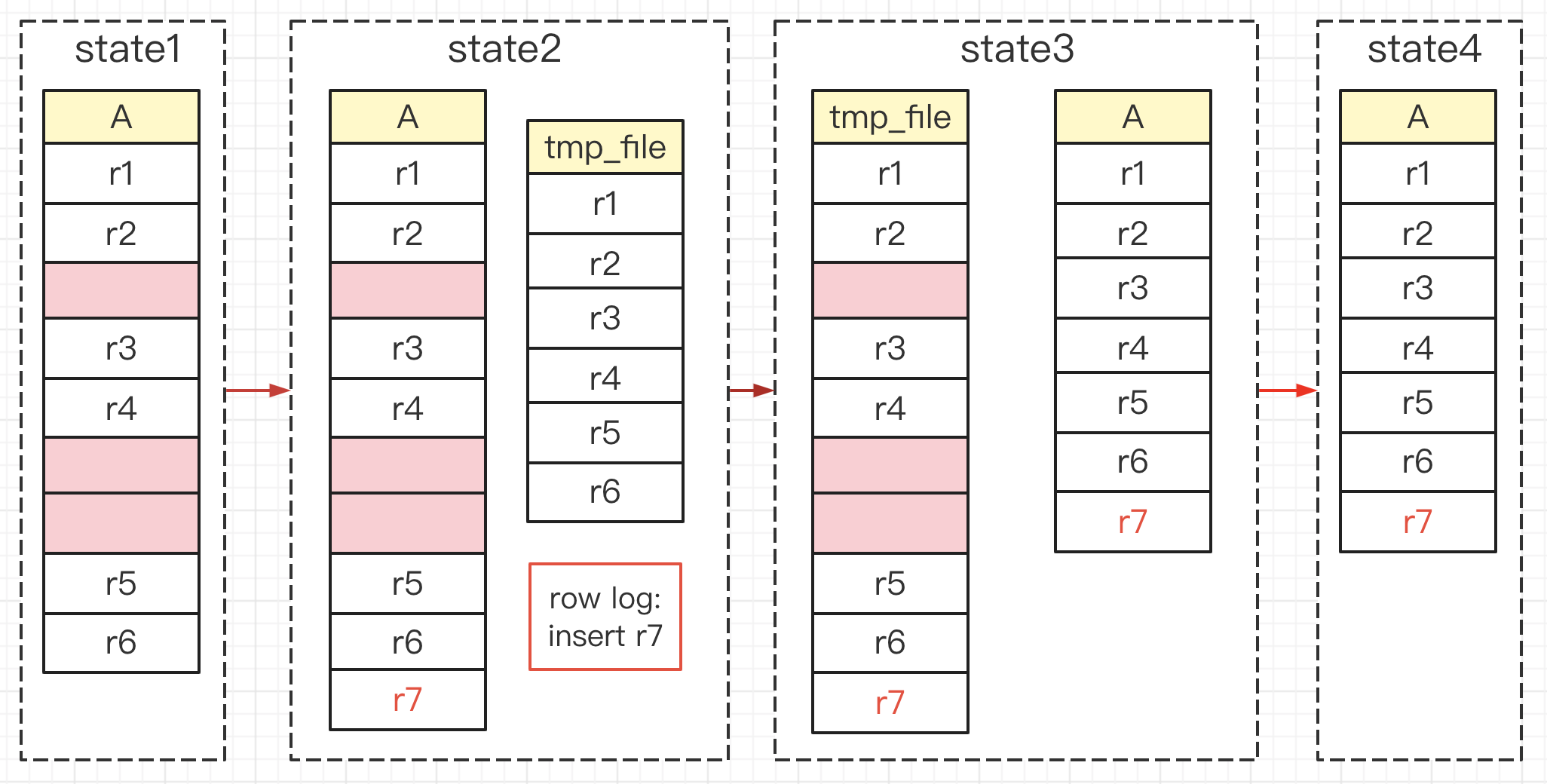
1)建立一个临时文件,扫描表A主键的所有数据页;
2)用数据页中表A的记录生成B+树,存储到临时文件中;
3)生成临时文件的过程中,将所有对A的操作记录在一个日志文件(row log)中,对应的是图中state2的状态;
4)临时文件生成后,将日志文件中的操作应用到临时文件,得到一个逻辑数据上与表A相同的数据文件,对应的就是图中state3的状态;
5)用临时文件替换表A的数据文件。
由于3,4步骤的日志文件记录和重放操作这个功能的存在,这个方案在重建表的过程中,允许对表A做增删改操作。这也就是Online DDL名字的来源。
3、OPTIMIZE TABLE XX
该命令同样会整理数据文件的碎片重新整理表,但运行该命令 MySQL会锁定表,使用时需谨慎。
引入问题4:为什么我重建了表但空间却没有收缩?
InnoDB在重建后的页会会预留个1/16的空间,而不是占满整个页。如果是占满整页,这时更新一条需要更大空间的老数据,就会需要申请新的页,申请新的页又会造成碎片。所以如果表本身就很紧凑情况下会导致重建后的表空间反而会变大。
问题5:mysql有三种删除数据方式delete、 truncate、 drop 的正确使用
从执行速度来说: drop > truncate >> DELETE
delete
delete是一行一行执行删除的,并且同时将该行的的删除操作日志记录在redo和undo表空间中以便进行回滚(rollback)和重做操作,生成的大量日志也会占用磁盘空间。
truncate
truncate属于数据库DDL定义语言,不走事务,需要慎用,因为元数据直接就没了,执行后立即生效,无法恢复。truncate 删除表会立刻释放磁盘空间 ,不管是 InnoDB和MyISAM truncate也会重置auto_increment的值为1。delete后表仍然保持auto_increment。
drop
drop属于数据库DDL定义语言,同Truncate;执行后立即生效,无法找回 ,立刻释放磁盘空间 ,不管是 InnoDB 和 MyISAM; drop 语句将删除表的结构。
思考题:mysql中,一张表里有1亿数据,未分表,其中一个字段是用户类型,用户类型是普通和vip用户,普通用户的数据量差不多占1/3,根据条件把普通用户的行都删掉。请问如何操作?
如果 delete 的数据是大量的数据,则会:
- 如果不加 limit 则会由于需要更新大量数据,从而索引失效变成全扫描导致锁表,同时由于修改大量的索引,产生大量的日志,同时可能导致锁表锁很长时间,期间线上业务会受影响。
- 由于产生了大量 binlog 导致主从同步压力变大。
- 由于标记删除产生了大量的存储碎片,MySQL 是按页加载数据,这些存储碎片不仅大量增加了随机读取的次数,并且让页命中率降低
- 由于产生了大量日志,表占用空间大大增高。
正常操作流程:
方案1:delete 后加上 limit 限制控制其数量,这个数量让他会走索引,从而不会锁整个表。
在删除完成后,通过如下语句,重建表:alter table 表 engine=InnoDB;
方案2:新建一张同样结构的表,在原有表上加上触发器,更新插入到新表,或者binlog订阅更新新增数据写到新表。保证线上业务有新数据会同步。之后,将所有vip的数据,插入新表,同时如果已存在则证明发生了更新同步就不插入。普通用户数据由于业务变化,并不在这个表上更新,所以这样通过了无表锁同步实现了大表的数据清理。