一.背景
七猫正处于一个高速发展的阶段,数据分析和业务的发展方向非常注重数据的正确性。为了保证数据质量,我们之前的做法为在相关任务中加上自定义逻辑来检查数据是否正确。但是随着业务的快速迭代,数据量的高速增长和数据链路的复杂化,这种纯人工开发逻辑的方式已经难以跟上迭代速度,所以需要找到一个工具来帮助解决现状。
二.七猫选用 DolphinScheduler 数据质量模块的原因
在以往的数据质量监控方式中,大概总结起来有如下几个痛点:
- 纯人工开发监控逻辑效率不高,需要额外花费很多人力
- 不同业务在多个集群中均有数据质量监控,无法统一进行管理
- 七猫拥有多个云环境和多个集群,对于跨集群使用的数据不易进行质量监控
针对以上的痛点,我们调研了多款组件,结合我们自己的开发模式,最终选择了 DolphinScheduler 来进行数据质量的开发,主要是考虑到有如下优势:
- 支持可视化界面配置,提供丰富的数据质量规则,简化开发提高效率
- 支持多数据源,能够同时对不同类型的数据库的数据配置监控任务,覆盖面广
- 支持多集群和多租户的配置,满足跨集群对共用数据的质量监控
- 有完善的权限管理功能,不同场景设置不同权限,保证数据的私密性
- 提供了丰富的API,通过包装能够简化任务配置操作,加快质量监控任务上线
并且 DolphinScheduler 本身作为调度器也在七猫多个业务线使用中,能够很好的集成使用,方便开发和配置。
注:DolphinScheduler 在3.0以上版本才有数据质量模块,如有使用意向需注意安装版本
三.DolphinScheduler 数据质量在七猫的实践
1.多集群的数据源打通
由于业务复杂和技术需要,七猫在各业务线上部署了多套集群,为了能在一套系统中对所有集群的数据进行质量监控,运维同学配合大数据团队在 DolphinScheduler 打通了多集群多数据库的连接。
如图,在数据源中心输入主机IP和端口、用户等消息,配置单个集群的数据源连接:
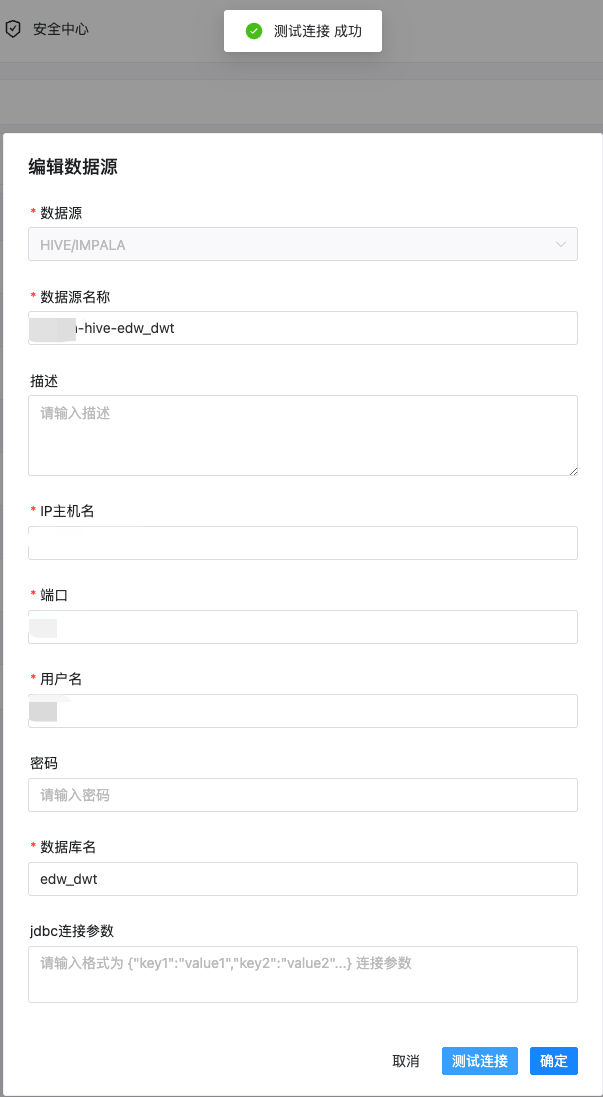
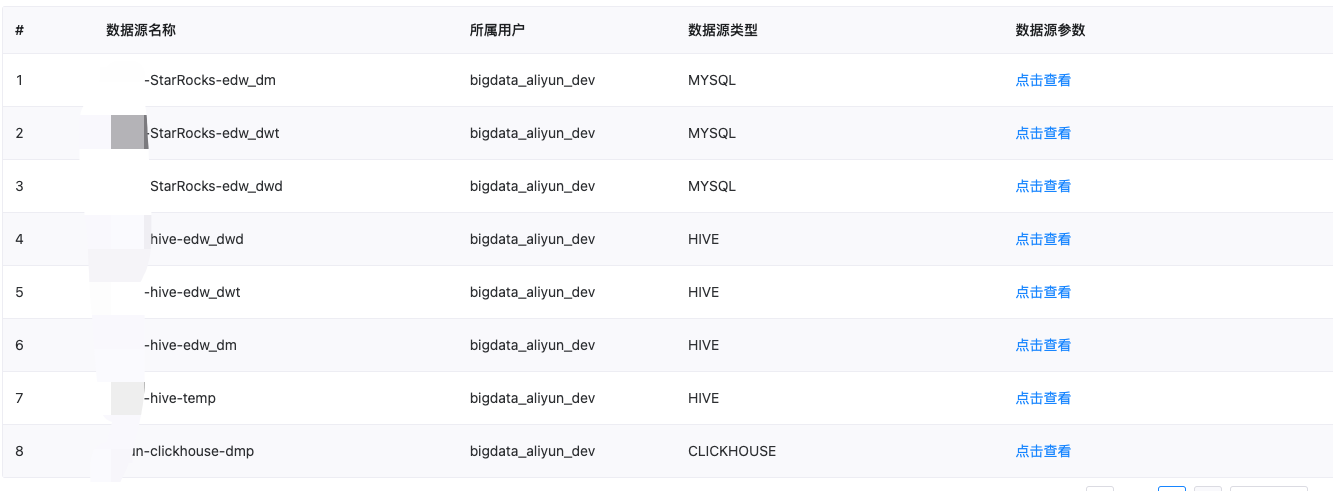
我们将每个集群的多个数据库连接配置化,方便业务对各种场景下的数据进行质量监控:
2.权限管理
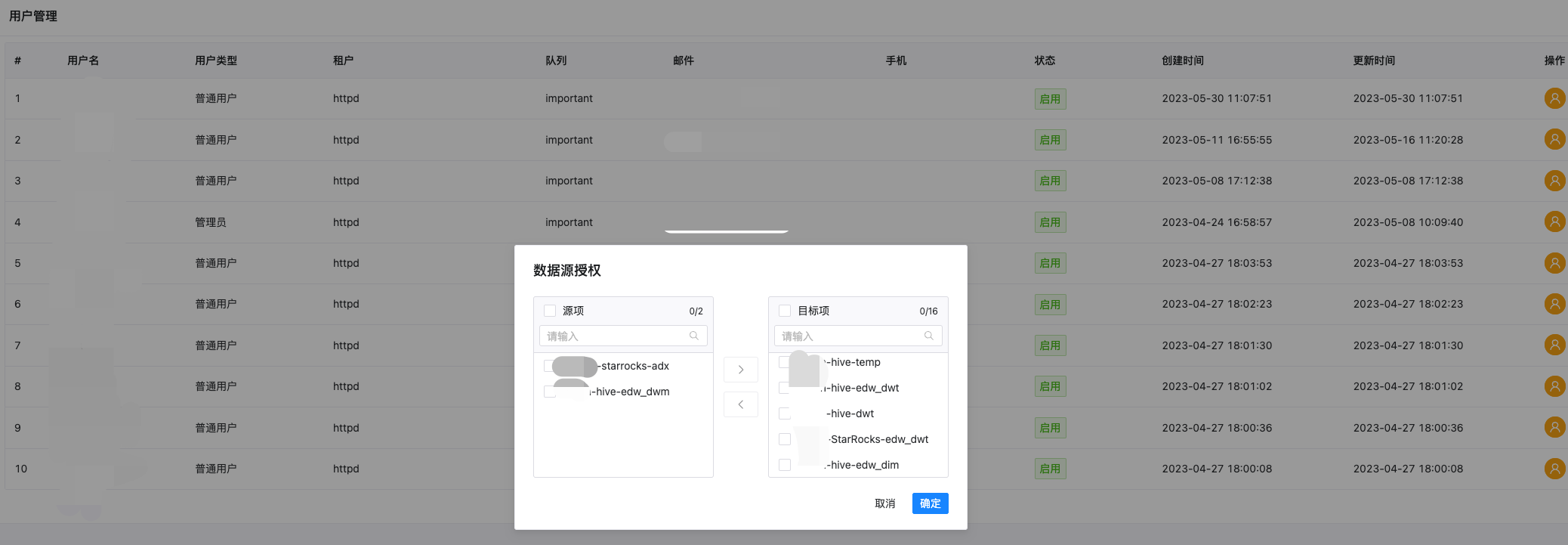
各业务团队都在对自己的业务数据进行处理和质量监控,由于部分业务有着例如成本、收益等具有敏感性的数据,这时候就需要将数据使用权限进行管理。不同部门使用不同权限的账号,在保证敏感数据私有化的情况下也能统一的对共用数据做质量管理。
如图,我们对每个用户的细化到每个数据源的 database 粒度进行授权,尽可能的将各库各层级的数据进行权限隔离:
3.数据质量任务的配置和使用
DolphinScheduler 目前提供了如下规则:
- 空值检测
- 自定义SQL
- 多表准确性
- 两表值比对
- 字段长度校验
- 唯一性校验
- 正则表达式
- 及时性校验
- 枚举值校验
- 表行数校验
接下来我们以几个例子来给大家介绍七猫如何使用这些规则来监控数据质量。
3.1 单表单字段监控
对于数据质量监控,最常见的就是对重要字段的完整性进行检查,这里以字段空值检查为例,介绍下单表单字段的监控配置,并且仔细讲解下 DolphinScheduler 数据质量任务的配置项填写规则。
首先进行数据质量任务的配置,高版本中在工作流里提供了专门的任务类型选项:

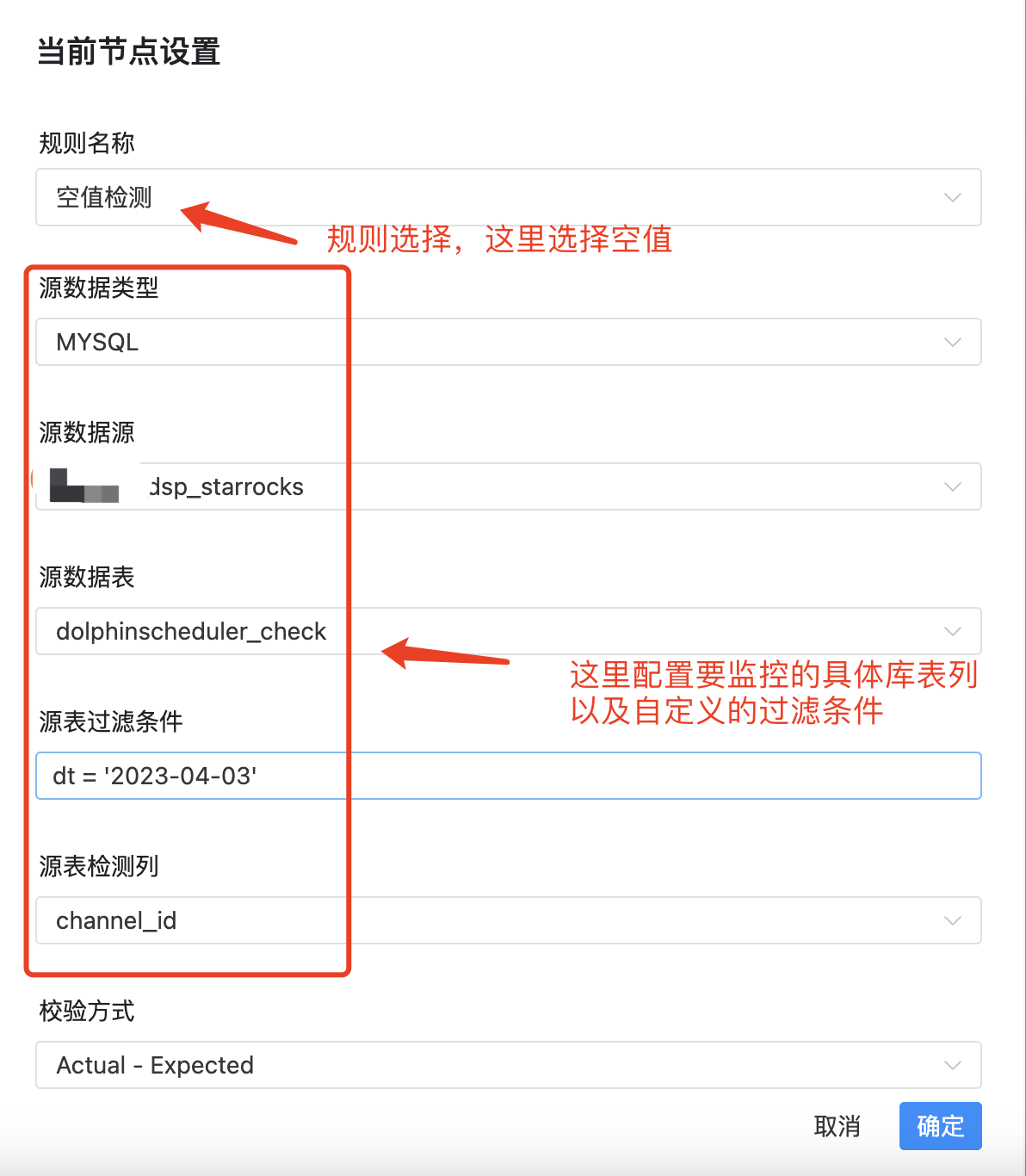
如上图,数据质量配置项大概分为三类:
a.监控数据选择配置项
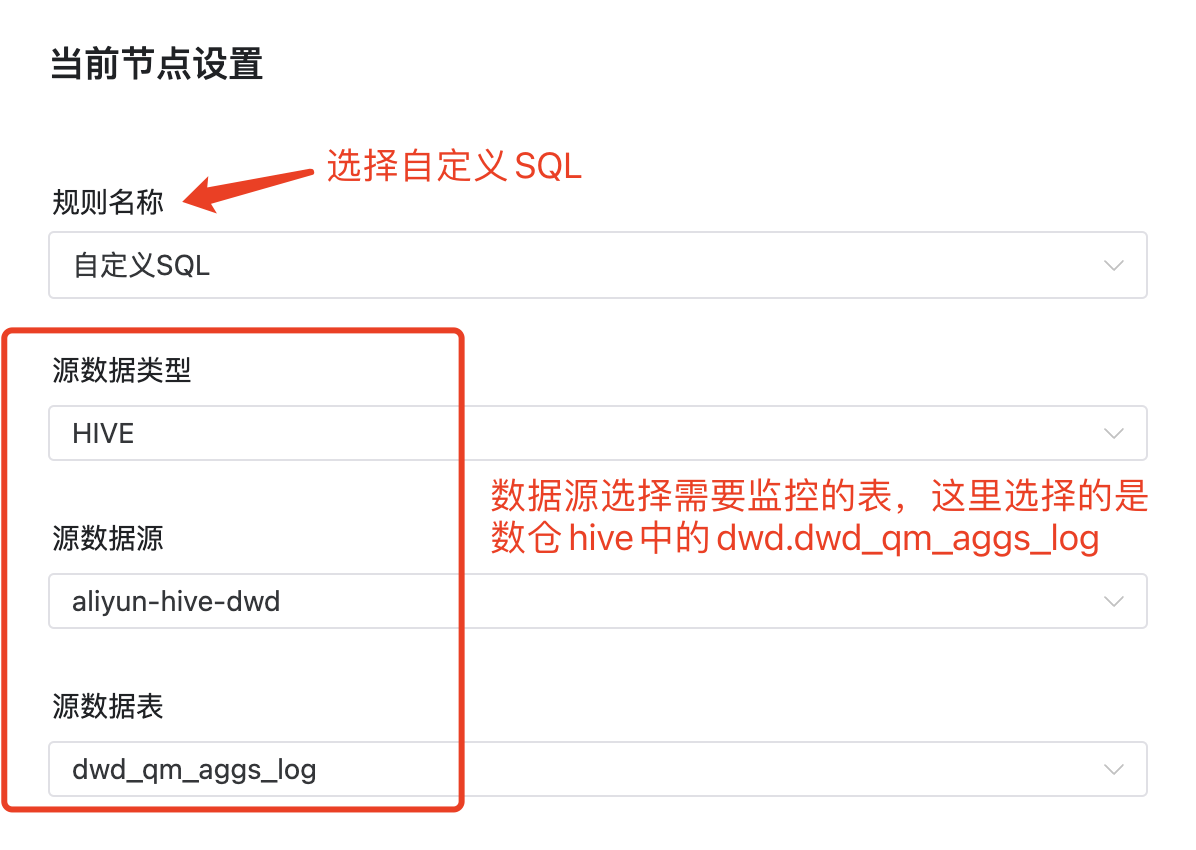
源数据类型:MYSQL(配置可以是StarRocks或者mysql数据源)、HIVE(配置的是hive数据源)等
源数据源:监控的数据表所在的数据源
源数据表:监控的数据表
源表过滤条件:按照具体业务逻辑进行数据过滤
源表检测列:具体监控的数据表字段
b.监控规则配置
规则名称:这里选择空值检查,根据具体监控类型做不同选择
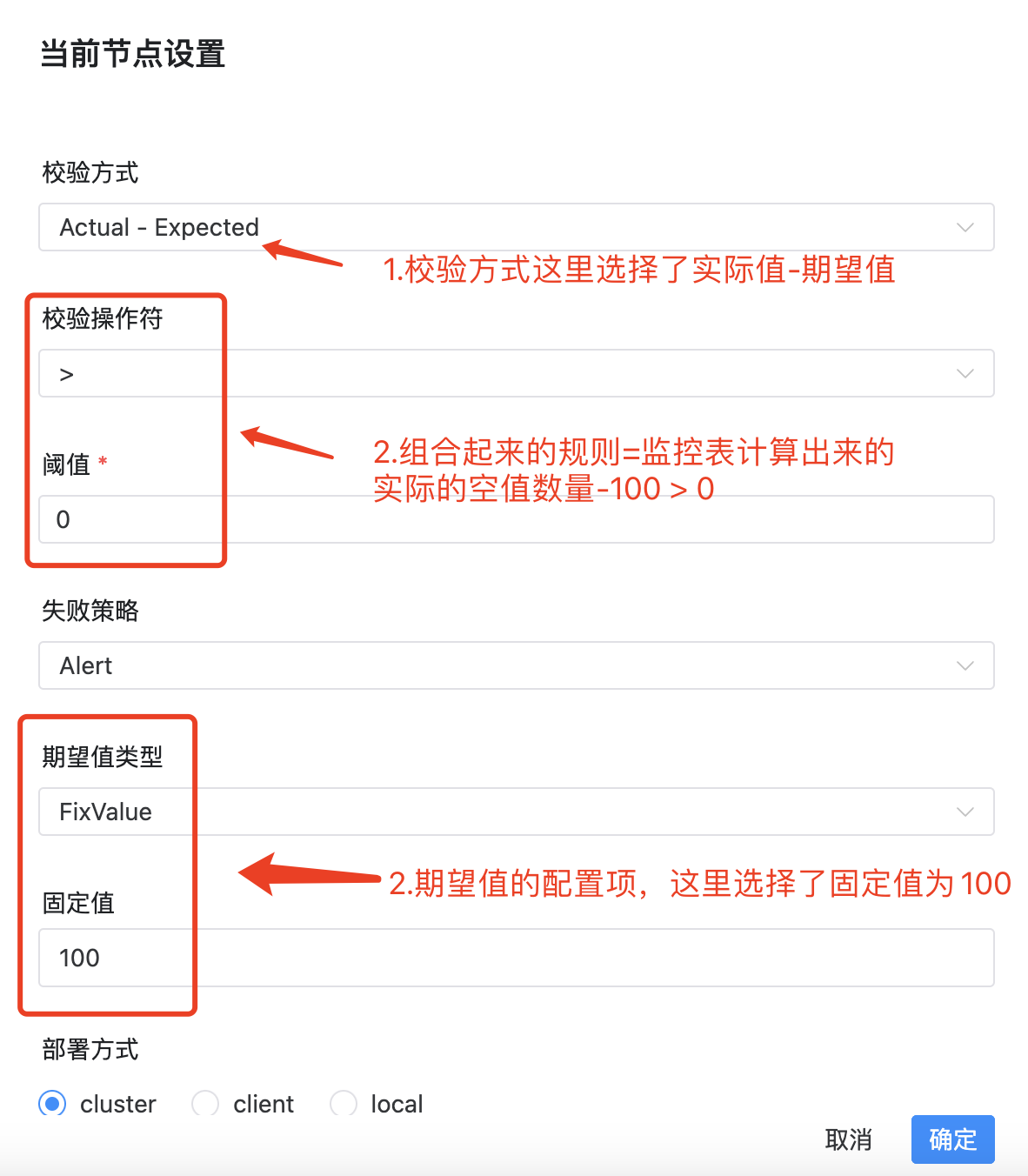
校验方式:
- [Expected-Actual][期望值-实际值]
- [Actual-Expected][实际值-期望值]
- [Actual/Expected][实际值/期望值]x100%
- [(Expected-Actual)/Expected][(期望值-实际值)/期望值]x100%
校验操作符:=、>、>=、<、<=、!=
期望值类型:
- 固定值(最常用,和自定义值比较)
- 日均值(和任务当天执行的所有实际值的平均值进行比较,例如,第一次的执行的空值数量为1,第二-次执行的空值数量为2,第三次就是和 (1+2)/2=1.5进行比较)
- 周均值(与日均值类似,比较的是本周周一至昨日计算的实际值均值)
- 月均值(与日均值类似,比较的是本月1号至昨日计算的实际值均值)
- 最近7天均值(与日均值类似,比较的是前七天的实际值均值)
- 最近30天均值(与日均值类似,比较的是前三十天的实际值均值)
- 源表总行数
- 目标表总行数
组合成校验公式:[校验方式][操作符][阈值],如果结果为真,则表明数据不符合期望,执行失败策略
c.任务执行配置
失败策略:
- alter:数据质量任务失败了,DolphinScheduler 任务结果为成功,发送告警
- block:数据质量任务失败了,DolphinScheduler 任务结果为失败,发送告警(建议设置为block,方便告警通知)
通过这样简单的配置,我们能够快速的对大量数据进行完整性、唯一性进行监控。
3.2 单表自定义逻辑监控
针对带有业务逻辑的数据,已有的规则无法灵活的满足各种数据检查,这时候就需要使用自定义SQL来进行配置。
例子:埋点事件波动的监控
七猫有着6000+埋点事件,例如阅读埋点、充值埋点等重要埋点数据的波动都会对业务发展方向有影响,所以对各种埋点数据进行监控是非常重要的。这里展示下七猫运用 DolphinScheduler 快速进行埋点事件数据波动的监控。
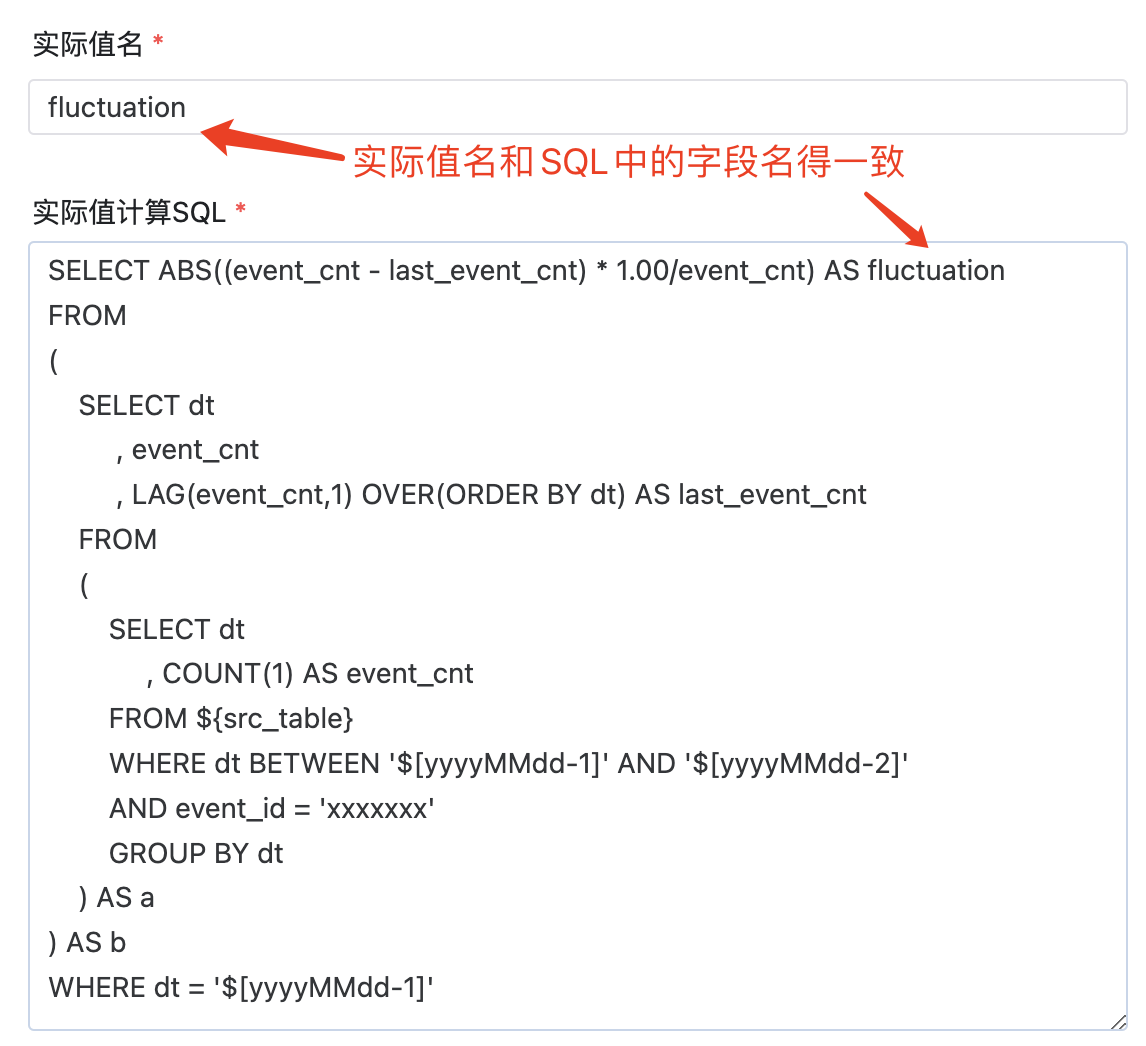

配置如上图,在实际值计算SQL配置项中填写监控逻辑,能够实现各种复杂业务数据的监控。我们对于数据量各种波动监控,我们也准备了相应SQL模板来简化大家的开发,提高效率。这里以同比、环比为例:
1.同比模版
--同事件今日数据量和昨日数据量超过某阈值监控
SELECT ABS((event_cnt - last_event_cnt) * 1.00/event_cnt) AS fluctuation
FROM
(
SELECT dt
, event_cnt
, LAG(event_cnt,1) OVER(ORDER BY dt) AS last_event_cnt
FROM
(
SELECT dt
, COUNT(1) AS event_cnt
--自定义sql的来源表必须写成${src_table}
FROM ${src_table}
WHERE dt BETWEEN '$[yyyyMMdd-2]' AND '$[yyyyMMdd-1]'
--监控的事件
AND event_id = 'xxxxxxx'
GROUP BY dt
) AS a
) AS b
WHERE dt = '$[yyyyMMdd-1]'
2.环比模版
--同事件周环比数据量超过某阈值监控
SELECT ABS((event_cnt - last_event_cnt) * 1.00/event_cnt) AS fluctuation
FROM
(
SELECT dt
, event_cnt
, LAG(event_cnt,1) OVER(ORDER BY dt) AS last_event_cnt
FROM
(
SELECT dt
, COUNT(1) AS event_cnt
--自定义sql的来源表必须写成${src_table}
FROM ${src_table}
WHERE dt IN ('$[yyyyMMdd-1]','$[yyyyMMdd-7]')
--监控的事件
AND event_id = 'xxxxxxx'
GROUP BY dt
) AS a
) AS b
WHERE dt = '$[yyyyMMdd-1]'
--同事件月环比数据量超过某阈值监控
SELECT ABS((event_cnt - last_event_cnt) * 1.00/event_cnt) AS fluctuation
FROM
(
SELECT dt
, event_cnt
, LAG(event_cnt,1) OVER(ORDER BY dt) AS last_event_cnt
FROM
(
SELECT dt
, COUNT(1) AS event_cnt
FROM ${src_table}
WHERE dt IN ('$[yyyyMMdd-1]','$[yyyyMMdd-30]')
--监控的事件
AND event_id = 'xxxxxxx'
GROUP BY dt
) AS a
) AS b
WHERE dt = '$[yyyyMMdd-1]'
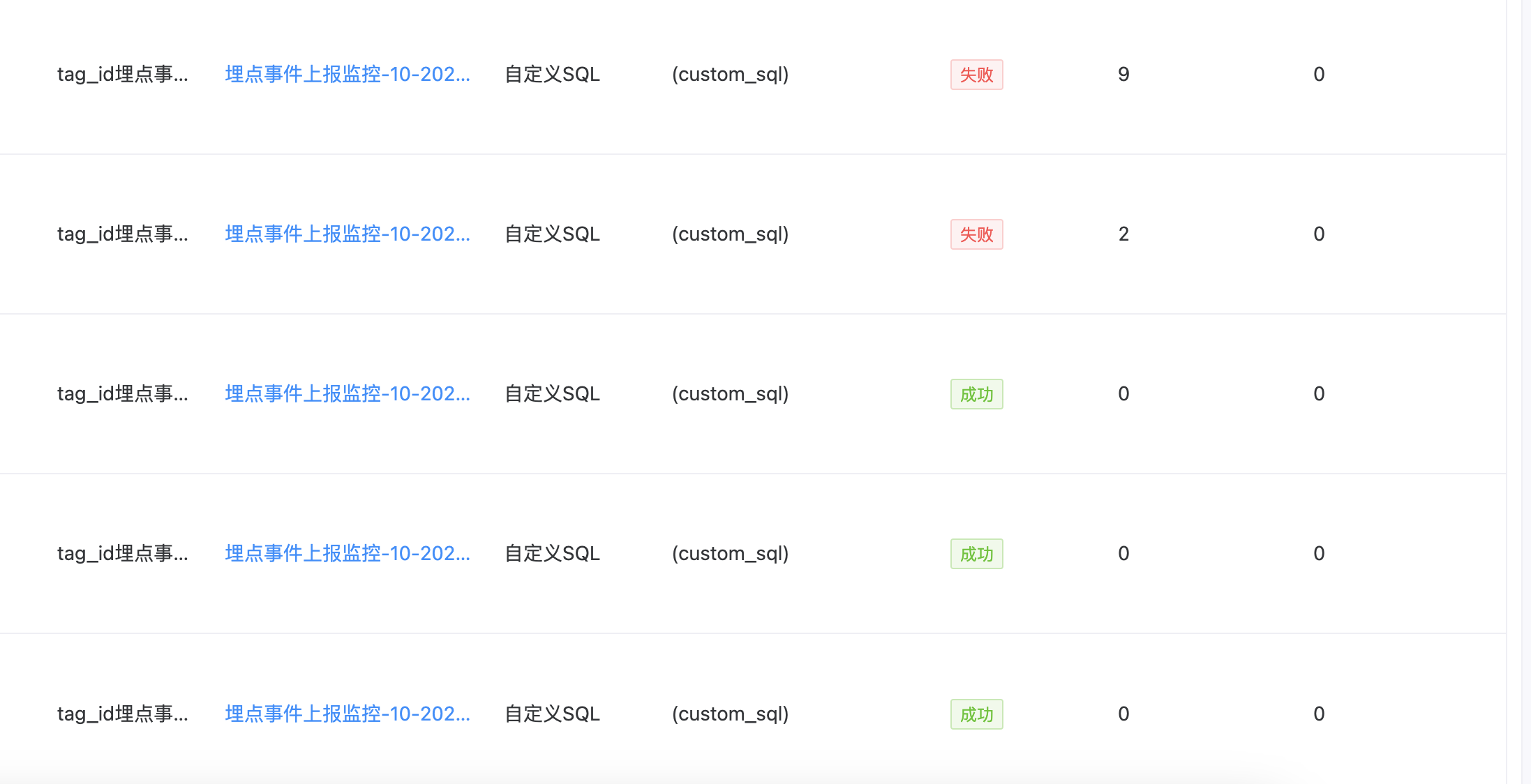
配置上线后可对每日的数据质量监控结果进行展示:
3.3 多表数据的质量监控
各业务部门有着自己的数据集群,但是例如一些通用数据比如人物画像需要在多个业务中使用,经常会有集群间数据同步的操作。为了保证数据同步无丢失,这个时候就能使用多表准确性或者两表值比对来进行监控。
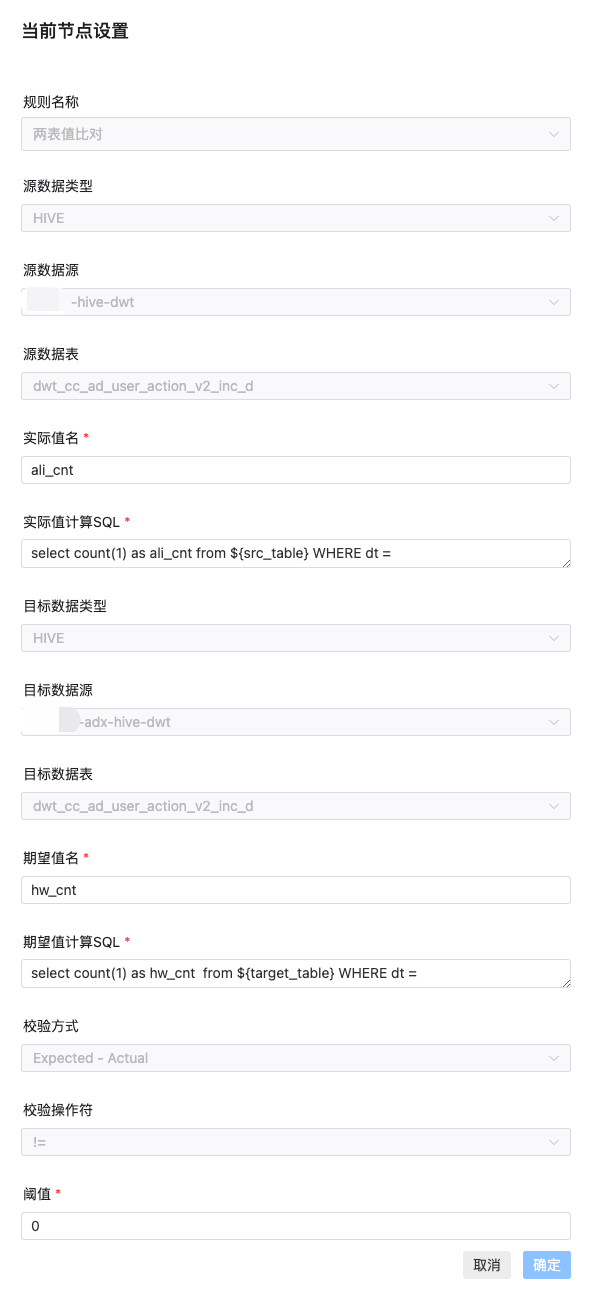
如上图,配置项大概分为4类:
1.监控规则的选择:
规则名称:因为是两个集群的数据比对,我们选择两表值对比
数据源类型:可以配置 Mysql、Hive、StarRocks 等多重数据源,这里选择Hive
2.源集群库表的数据监控:
源数据源:这里我们选择集群1的dwt库
数据源表:选择要监控的表dwt_cc_ad_user_action_v2_inc_d
实际值名:实际值计算SQL中监控的字段名
实际值计算SQL:按照监控逻辑自定义,这里只监控数据量,填写求count值的SQL即可
3.目标集群库表的数据监控配置:
目标数据源:这里我们选择集群2的dwt库
目标数据表:选择要监控的表dwt_cc_ad_user_action_v2_inc_d
实际值计算SQL:按照监控逻辑自定义,这里只监控数据量,填写求count值的SQL即可
4.校验规则
校验方式:选择Expected - Actual
校验符:选择!=
阈值:0
组合起来为:源数据表数据量-目标数据表数据量 != 0 则报错
配置完后,上线方式和普通任务一样进行每日调度,并且在数据质量模块可查看监控结果:

通过这种方式,很好的解决了之前无法快速方便的进行跨集群间数据间的质量监控。
4.数据质量任务的执行
我们通过日志可以看到 DolphinScheduler 的数据质量任务实际上就是一个SPARK任务,提交的参数就是将我们的配置项封装的一个JSON,通过这个JSON我们能了解到数据质量任务的执行过程:
{
"name":"$t(null_check)",
"env":{
"type":"batch",
"config":null
},
--reader通过jdbc方式读到我们配置的数据,并新建临时表dm_dolphinscheduler_check
"readers":[
{
"type":"JDBC",
"config":{
"database":"xxxx",
"password":"xxxx",
"driver":"com.mysql.cj.jdbc.Driver",
"user":"xxxx",
"output_table":"dm_dolphinscheduler_check",
"table":"dolphinscheduler_check",
"url":"jdbc:mysql://xxxx/xxxx?allowLoadLocalInfile=false&autoDeserialize=false&allowLocalInfile=false&allowUrlInLocalInfile=false"
}
}
],
--transformers将源数据源、源数据表、过滤条件等配置项拼出具体的执行sql,执行后创建成临时表null_items
"transformers":[
{
"type":"sql",
"config":{
"index":1,
"output_table":"null_items",
"sql":"SELECT * FROM dm_dolphinscheduler_check WHERE (channel_id is null or channel_id = '') AND (dt = '2023-04-02')"
}
},
{
"type":"sql",
"config":{
"index":2,
"output_table":"null_count",
"sql":"SELECT COUNT(*) AS nulls FROM null_items"
}
}
],
--writers将transformers中执行出来的结果记录到dolphinscheduler中元数据(t_ds_dq_execute_result、t_ds_dq_task_statistics_value)中,为了后续计算使用(比如日均值、月均值)和展示用
"writers":[
{
"type":"JDBC",
"config":{
"database":"xxxx",
"password":"xxxx",
"driver":"com.mysql.cj.jdbc.Driver",
"user":"xxxx",
"table":"t_ds_dq_execute_result",
"url":"jdbc:mysql://xxxx/xxxx?useUnicode=true&characterEncoding=UTF-8&useSSL=false&allowLoadLocalInfile=false&autoDeserialize=false&allowLocalInfile=false&allowUrlInLocalInfile=false",
"sql":"select 0 as rule_type,'$t(null_check)' as rule_name,0 as process_definition_id,63210 as process_instance_id,75254 as task_instance_id,null_count.nulls AS statistics_value,1 AS comparison_value,1 AS comparison_type,1 as check_type,0 as threshold,3 as operator,0 as failure_strategy,'hdfs://xxxx/0_63210_lst_null_check' as error_output_path,'2023-04-23 19:08:07' as create_time,'2023-04-23 19:08:07' as update_time from null_count "
}
},
{
"type":"JDBC",
"config":{
"database":"xxx",
"password":"xxx",
"driver":"com.mysql.cj.jdbc.Driver",
"user":"xxx",
"table":"t_ds_dq_task_statistics_value",
"url":"jdbc:mysql://xxxx/xxxx?useUnicode=true&characterEncoding=UTF-8&useSSL=false&allowLoadLocalInfile=false&autoDeserialize=false&allowLocalInfile=false&allowUrlInLocalInfile=false",
"sql":"select 0 as process_definition_id,75254 as task_instance_id,1 as rule_id,'T2OWMPCONLYL0VOKMHFKDOVANMUSBQID2NKIREVVSSI=' as unique_code,'null_count.nulls'AS statistics_name,null_count.nulls AS statistics_value,'2023-04-23 19:08:07' as data_time,'2023-04-23 19:08:07' as create_time,'2023-04-23 19:08:07' as update_time from null_count"
}
},
--最后将错误数据写入hdfs中生成相应csv文件,例如空值检查,会把为空的字段数据记录上传
{
"type":"hdfs_file",
"config":{
"path":"hdfs://xxxx/0_63210_lst_null_check",
"input_table":"null_items"
}
}
]
}
4.七猫对于 DolphinScheduler 数据质量的扩展
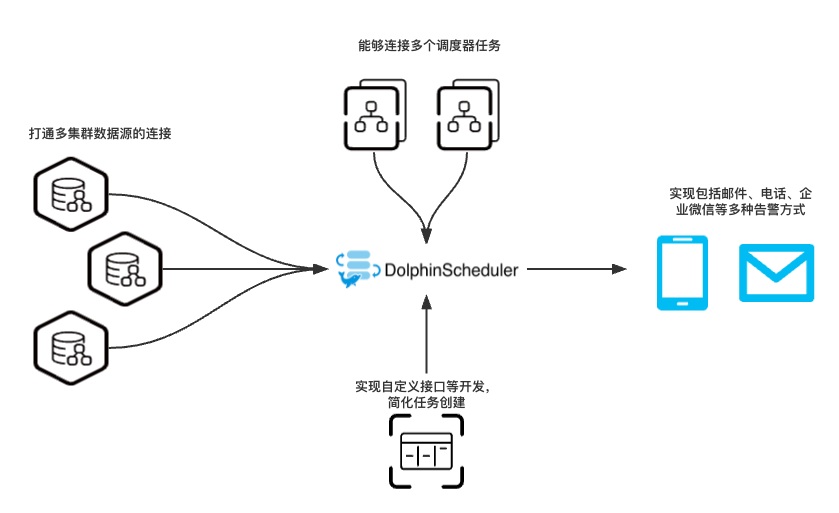
如图所示:
1.七猫完成了多集群在一套 DolphinScheduler 集群上的配置,能够对不同数据源进行关联性监控,打破壁垒
2.七猫通过自研方式实现了调度器间任务的依赖,能够将 dataworks、Azkaban等调度器上的任务和 DolphinScheduler 数据质量任务互相依赖
3.对 DolphinScheduler 数据质量接口进行自定义开发,更加简化了配置,提高开发效率。例如创建数据质量任务接口:
curl --location --request GET 'http://xxxx/ds/project/process-definition/gen-task-code/9880911953888?genNum=1' \
--header 'token: xxxxxx' \
--header 'User-Agent: Apifox/1.0.0 (https://www.apifox.cn)'
4.实现了包括企业微信、电话等多种告警方式,能够及时发现问题解决问题
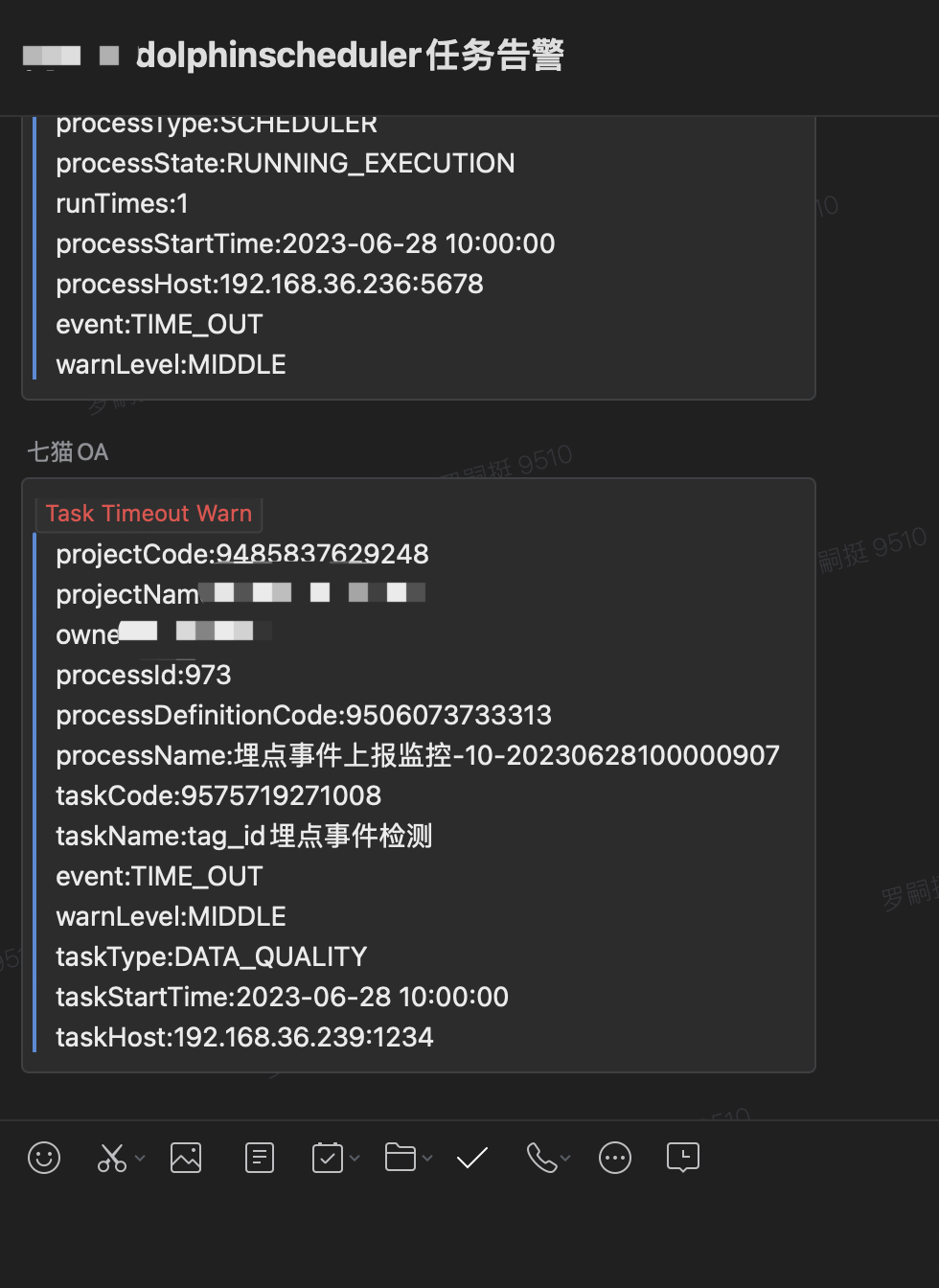
5.踩坑经验
DolphinScheduler 的数据质量模块相对来说不是很成熟,在使用中也有遇到一些问题:
1.DolphinScheduler 安装好后,首次执行数据质量任务报jar不存在
原因:配置文件common.properties中data-quality.jar.name指定的jar在lib目录下不存在
解决方式:打包编译好后放到指定位置解决。
2.数据质量任务时报org.apache.spark.SparkException: No main class set in JAR; please specify one with --class
原因:数据质量的jar包中没有默认指定Main-Class,需要手动指定
解决方式:在选项参数中必须显示指定执行主类:--class org.apache.dolphinscheduler.data.quality.DataQualityApplication
3.数据质量任务一直处于执行状态
原因:dolphinscheduler 的元数据库中任务名类型为varchar(64),当任务名长度超长时,更新元数据会一直失败重试
解决方式:将元数据库中t_ds_alert中tittle字段的长度调大
6.展望和总结
dolphinscheduler 数据质量在七猫使用场景目前还有些不足:
-
只支持 Jdbc 和 Hive 两种类型的数据源,不能完全覆盖业务场景
-
数据校验规则还不是特别丰富,如业务特别复杂则不能满足使用
我们的规划:
-
调研增加新的数据源类型,例如 Hdfs、kylin 等
-
调研支持用户可以自定义监控规则,覆盖全场景
总结:这些只是七猫数据质量监控的一小部分。我们无论是对数仓各层进行数据完整性、数据一致性等校验,还是对各数据库数据的复杂监控,七猫都有了自己完整的体系后建设。希望大家能够通过这个文档对 dolphinscheduler 数据质量有所收获。