一、为什么七猫要引入StarRocks
1. 背景
之前,我们会采用多种架构来满足业务需要,比如数据报表结果存储在Clickhouse、OLAP查询使用Trino、业务数据的实时同步采用Hudi等。随着业务的迅速发展,已经越来越难满足业务的需要,主要有以下几点原因:
- 涉及到的组件很多,开发、运维人员需要去熟悉精通多个组件,成本较高。
- Clickhouse不支持标准SQL,需要时刻注意SQL语法的问题。
- Clickhouse的并发能力差,Join的性能也不理想。
- Trino的查询响应时长不稳定。
- Hudi在采用Merge-On-Read存储格式时,查询性能不理想。
为了解决这些问题,我们调研了很多款技术组件,结合我们目前的使用场景,综合考虑,我们选择了StarRocks。
2. StarRocks能够支持的场景
StarRocks能够很好的支持我们目前业务中涉及到的各个场景,主要如下:
- 实时分析
- OLAP分析(内外表均可)
- 数仓结果表查询(内外表均可)
- 多维查询(内外表均可)
- 业务库实时同步
当然在满足业务的同时,对数据开发、分析等业务人员比较友好的是:标准的SQL语法、兼容Mysql协议与函数。
二、StarRocks 在七猫的使用场景
- 实时同步业务库数据:FlinkCDC监听数据库Binlog来实时同步更新至StarRocks,然后进行实时分析。
- Spark数据导入:针对数仓分析结果表数据(千万以内)同步至StarRocks而开发的同步工具。
- FlinkSQL数据导入:针对数仓中的任意数据集(明细表、结果表、主题表等)、Kafka数据等任意Flink能够支持的数据导入。
- 经营指标分析:一个非常综合的使用场景,包括:业务库数据实时同步实时分析、表存储模型的选型、多维数据分析、数据的导入。
- 互动域查询提速:借助于StarRocks强大的查询性能,采用合适的存储引擎,对近30天内的海量明细数据查询加速。
三、StarRocks 的技术点
在使用StarRocks时,表数据模型的选择是非常重要的,选择不合适的模型,有可能造成:查询性能不满足预期、数据维护不方便、业务体验差等。在此,列出了各个模型以及推荐的使用场景,来提供参考。
1. 明细模型
适用场景:
- 分析原始数据,例如原始日志、原始操作记录等。
- 查询方式灵活,不需要局限于预聚合的分析方式。
- 导入日志数据或者时序数据,主要特点是旧数据不会更新,只会追加新的数据。
2. 聚合模型
适用于分析统计和汇总数据。比如:
- 通过分析网站或 APP 的访问流量,统计用户的访问总时长、访问总次数。
- 广告厂商为广告主提供的广告点击总量、展示总量、消费统计等。
- 通过分析电商的全年交易数据,获得指定季度或者月份中,各类消费人群的爆款商品。
在这些场景中,数据查询和导入,具有以下特点:
- 多为汇总类查询,比如 SUM、COUNT、MAX 等类型的查询。
- 不需要查询原始的明细数据。
- 旧数据更新不频繁,只会追加新的数据。
3. 更新模型
适用场景:实时和频繁更新的业务场景,例如分析电商订单。在电商场景中,订单的状态经常会发生变化,每天的订单更新量可突破上亿。
4. 主键模型
主键模型适用于实时和频繁更新的场景,例如:
- 实时对接事务型数据至 StarRocks。事务型数据库中,除了插入数据外,一般还会涉及较多更新和删除数据的操作,因此事务型数据库的数据同步至 StarRocks 时,建议使用主键模型。实时同步增删改的数据至主键模型,可以简化数据同步流程,并且相对于 Merge-On-Read 策略的更新模型,查询性能能够提升 3~10 倍。通过 Flink-CDC 等工具直接对接 TP 的 Binlog
- 利用部分列更新轻松实现多流 JOIN。在用户画像等分析场景中,一般会采用大宽表方式来提升多维分析的性能,同时简化数据分析师的使用模型。而这种场景中的上游数据,往往可能来自于多个不同业务(比如来自购物消费业务、快递业务、银行业务等)或系统(比如计算用户不同标签属性的机器学习系统),主键模型的部分列更新功能就很好地满足这种需求,不同业务直接各自按需更新与业务相关的列即可,并且继续享受主键模型的实时同步增删改数据及高效的查询性能。
数据域的表多为dwt层表,都是已经经过清洗聚合加工处理过的数据,且包含主键,主要提供给业务方、报表查询加速使用。因此除了聚合模型外,剩余三种模型都可以使用,但在重新导入(overwrite)数据时,需要注意几点:
- 明细模型:在导入前,需要先删除分区数据,否则数据会重复。
- 更新模型:重新导入,虽然可以不用先删除分区,但是相同主键下会存在多个版本数据,查询时需要在线聚合多版本(Merge-On-Read),性能会受到影响,但是写入的吞吐量高。
- 主键模型:重新导入,采用了 Delete+Insert 的策略,保证同一个主键下仅存在一条记录,这样就完全避免了 Merge 操作,但是写入吞吐较更新模型低。
四、最佳实践
1. 最佳实践-业务数据库实时同步
通过FlinkCDC工具监控数据库Binlog实时同步至Starrcosk,选用主键模型创建数据表。
- StarRocks
-- 实际广告收入表
CREATE TABLE edw_ods.ods_partner_adv_base_profit (
app string comment '产品标识',
id int,
......
updated_at int
) ENGINE=OLAP
PRIMARY KEY (app,id)
COMMENT '广告收益'
DISTRIBUTED BY HASH(id) BUCKETS 5
PROPERTIES (
"replication_num" = "3",
"in_memory" = "false",
"storage_format" = "DEFAULT",
"enable_persistent_index" = "true"
) ; - FlinkSQL
CREATE TABLE source_table_qm (
id int,
......
updated_at int,
PRIMARY KEY (id) NOT ENFORCED
) WITH (
'connector' = 'mysql-cdc',
'hostname' = 'xxx',
'port' = '3306',
'username' = 'xxx',
'password' = 'xxx',
'connect.max-retries' = '10',
'scan.incremental.snapshot.enabled' = 'true',
'database-name' = 'xxx',
'table-name' = 'xxx'
);
CREATE TABLE source_table_xm (
id int,
......
updated_at int,
PRIMARY KEY (id) NOT ENFORCED
) WITH (
'connector' = 'mysql-cdc',
'hostname' = 'xxx',
'port' = '3306',
'username' = 'xxx',
'password' = 'xxx',
'connect.max-retries' = '10',
'scan.incremental.snapshot.enabled' = 'true',
'database-name' = 'xxx',
'table-name' = 'xxx'
);
CREATE TABLE sink_table (
app string,
id int,
......
updated_at int,
PRIMARY KEY (app, id) NOT ENFORCED
)
WITH (
'connector' = 'starrocks',
'jdbc-url'='jdbc:mysql://xxx1:9030,xxx2:9030,xxx3:9030?characterEncoding=utf-8&useSSL=false',
'load-url'='xxx1:18030;xxx2:18030;xxx3:18030',
'database-name' = 'edw_ods',
'table-name' = 'ods_partner_adv_base_profit',
'username' = 'xxx',
'password' = 'xxx',
'sink.properties.column_separator' = '\\x01',
'sink.properties.row_delimiter' = '\\x02',
'sink.max-retries' = '3',
'sink.semantic' = 'exactly-once'
);
INSERT INTO sink_table
SELECT
cast('reader_free_all' as string) as app,
id,
......
updated_at
FROM source_table_qm
union all
SELECT
cast('reader_fast_panda_all' as string) as app,
id,
......
updated_at
FROM source_table_xm;
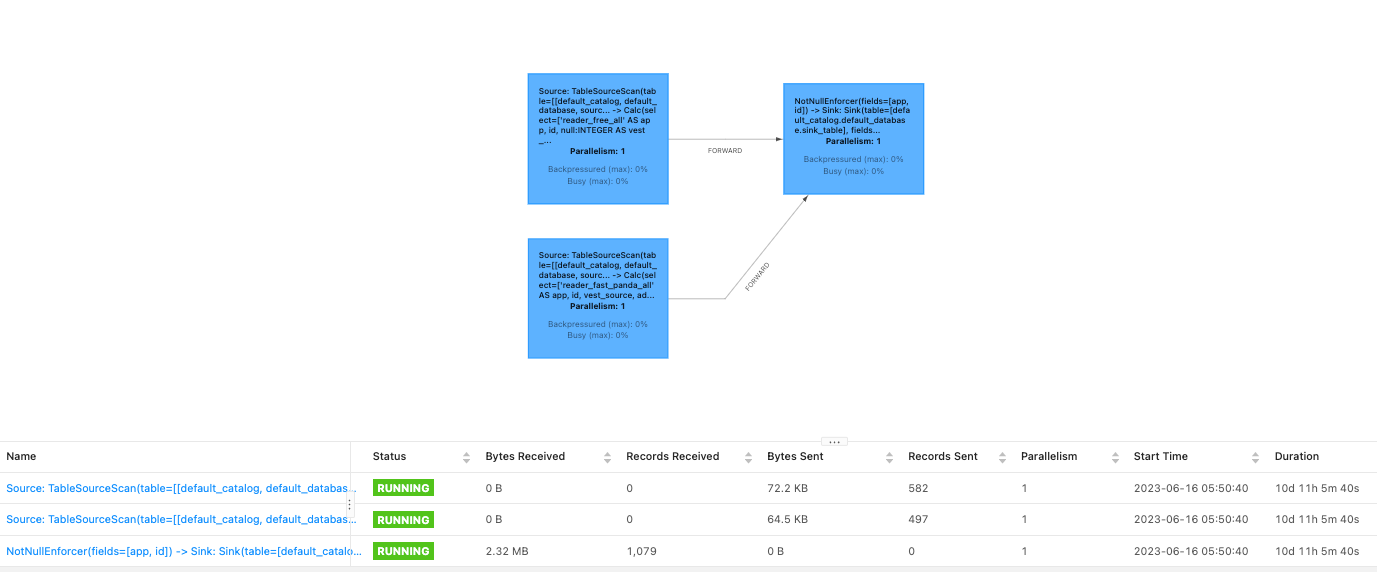
2. 最佳实践-Spark数据导入
在Spark中写入StarRocks的方式有多种,包括使用JDBC连接、使用Hadoop输入/输出格式、使用Spark Connector等。每种方式都有其优缺点,不同的应用场景可能需要选择不同的方式。以下是各种方式的性能特点:
- JDBC连接方式
使用JDBC连接的方式可以方便地将Spark中的数据写入StarRocks,但由于JDBC连接需要进行网络传输和数据转换,因此相对于其他方式,性能较低。如果数据量较小或对性能要求不高,可以选择使用JDBC连接的方式。
- Hadoop输入/输出格式方式
使用Hadoop输入/输出格式的方式可以直接使用StarRocks的Load命令将数据写入数据库中,因此性能较高。但需要注意的是,该方式需要在代码中手动设置输出路径,且需要保证输出路径在Hadoop集群中是可用的。如果数据量较大或对性能要求较高,可以选择使用Hadoop输入/输出格式的方式。
- Spark Connector方式
使用Spark Connector的方式可以在Spark中直接操作StarRocks表,性能较高且使用方便。但需要注意的是,该方式需要在代码中设置StarRocks相关的配置信息,并且需要使用特定版本的Spark Connector与StarRocks版本兼容。如果需要进行复杂的数据操作或对性能要求很高,可以选择使用Spark Connector的方式。
如果对性能要求较高,可以考虑使用Hadoop输入/输出格式的方式;如果对性能要求不高,可以选择使用JDBC连接的方式;如果需要更方便地操作StarRocks表,可以选择使用Spark Connector的方式。
早期,我们使用了JDBC的方式写入,但是导入性能不理想,后来自己实现通过Spark+Stream Load的导入方式,它适合导入数据量较少的场景下使用(千万级别以下),一般用于分析结果数据的导入,速度很快。但是当前版本无法控制批次等缓冲策略,导入超大数据量会导致BE节点瞬间打满,会导入失败。
未来,我们会尝试Hadoop输入/输出格式方式的方式来提高导入性能和稳定性。
3. 最佳实践-FlinkSQL数据导入
FlinkSQL写StarRocks一般我们会采用JDBC和Flink Connector来写入,Flink Connector的底层原理也是使用Stream Load来进行写入,需要注意分隔符的问题。JDBC的写入性能较差,一般我们不去采用,两种写入方式的Sink Table语句如下:
- JDBC方式
CREATE TABLE starrocks_table (
id INT,
name VARCHAR(20),
age INT
) WITH (
'connector' = 'jdbc',
'url' = 'jdbc:mysql://<host>:<port>/<database>',
'table-name' = '<table>',
'username' = '<username>',
'password' = '<password>',
'sink.buffer-flush.max-rows' = '5000' -- 可选,控制批量写入的行数
); - Flink Connector方式
CREATE TABLE starrocks_table (
id INT,
name VARCHAR(20),
age INT
) WITH (
'connector' = 'starrocks',
'jdbc-url'='jdbc:mysql://<host>:9030?characterEncoding=utf-8&useSSL=false',
'load-url'='<host>:18030',
'database-name' = '<database>',
'table-name' = '<table>',
'username' = '<username>',
'password' = '<password>',
'sink.properties.column_separator' = '\\x01',
'sink.properties.row_delimiter' = '\\x02',
'sink.max-retries' = '3',
'sink.semantic' = 'exactly-once'
);
4. 最佳实践-经营指标分析
在经营分析中大量使用StarRock,主要使用了功能如下:
- FlinkCDC同步内容、原创业务库数据:通过监听Mysql的Binlog来实时同步业务库数据至Starrocks,具体实现方式上面已介绍。
- Spark导入结果数据:大盘、总览数据由于纬度已经固定,由数仓平台计算完成后,通过自研的导入工具导入数据,具体实现方式上面已介绍。
- 视图View:由于经营分析涉及到的结果表多达二三十张,页面加载时会同时创建很多连接,并且会查询几十次,性能十分低下,通过View将多张表的结果union后,后台只用查询一个View就可以同时查询出几张至十几张表的结果,实际性能提升十分明显。
- 交互式即席查询OLAP:将在数仓中预处理好的中间明细结果通过Spark导入,再根据页面自定义维度来实时即席查询,性能十分高效。
- 使用了主键/更新模型表:在导入数据时,不用删除对应分区的数据,直接insert就可以实现更新对应的数据,优化了业务人员的使用体验,尤其在回溯历史数据的时候,效果很好。
5. 最佳实践-互动域查询提速
将数仓中的数据有针对性的处理后导入StarRocks中,再借助StarRocks的强大性能来对查询进行加速。目前我们对外提供的查询引擎为Trino,Trino本身不存储数据,数据源为数仓Hive中的数据(外表),业务人员经常反馈查询慢,因此进行了提速专项工作。
- 主要流程:收集常用埋点过滤条件以及常用字段,在StarRocks中创建明细模型表(日志数据),通过FlinkSQL同步至StarRocks表中。
- StarRocks建表语句:日志数据通常都比较大,考虑到存储成本,因此我们只保留近30天的数据,自动删除过期分区数据,自动创建新分区。
CREATE TABLE edw_dwd.dwd_interact_qm_aggs_log (
`dt、` date comment '分区字段',
`project` string comment '项目名称',
`event_id` string comment '事件id',
......
`count` int
)
ENGINE=OLAP
DUPLICATE KEY(dt,project,event_id)
PARTITION BY RANGE (dt) (
START ("2023-01-01") END ("2025-12-31") EVERY (INTERVAL 1 day)
)
DISTRIBUTED BY HASH(source_uid) BUCKETS 320
PROPERTIES (
"replication_num" = "2",
"in_memory" = "false",
"storage_format" = "DEFAULT",
"enable_persistent_index" = "true",
"compression" = "ZSTD",
"dynamic_partition.enable" = "true", -- 动态分区
"dynamic_partition.time_unit" = "DAY",
"dynamic_partition.start" = "-30", -- 自动保留近30天分区,删除30天前的分区
"dynamic_partition.end" = "3",-- 自动创建后3天分区
"dynamic_partition.prefix" = "p", -- 分区前缀
"dynamic_partition.buckets" = "320" -- 自动创建的分区buckets
);
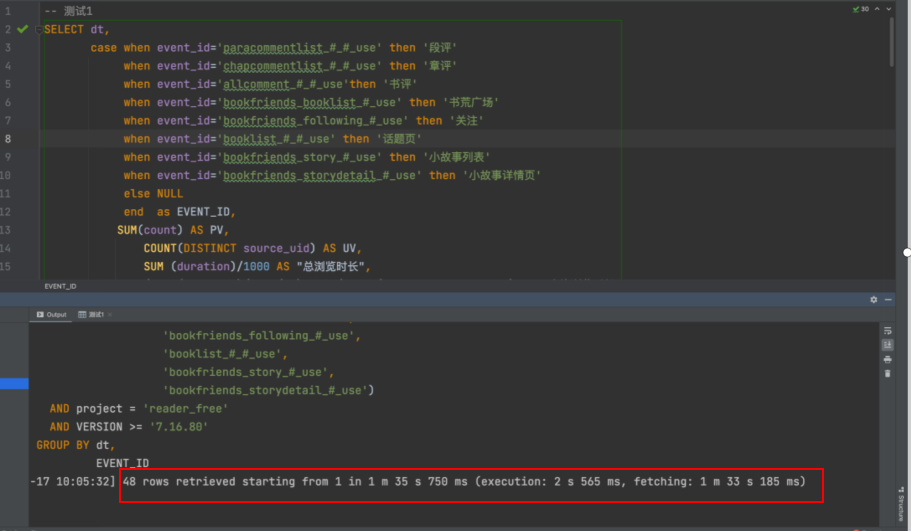
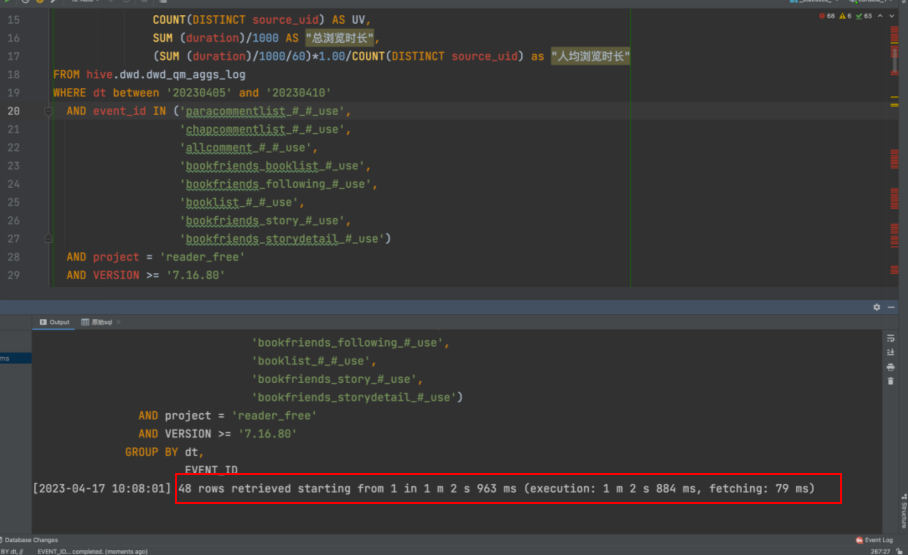
相同查询相同数据量在Trino、StarRocks外表、StarRocks内表的查询如下图所示(StarRocks机器配置略低):
- Trino
- StarRocks外表
- StarRocks内表
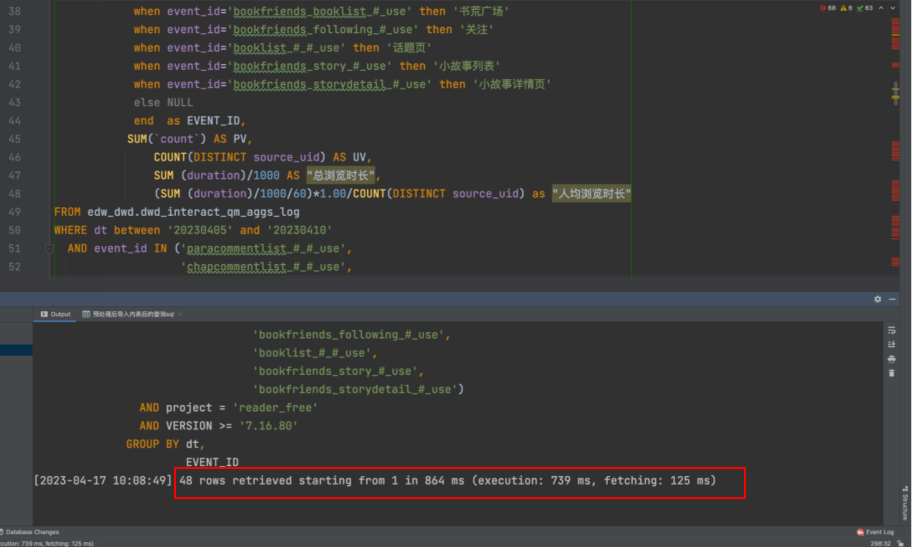
结论:
- StarRocks经过互动域埋点ETL导入内表后,所有查询均在毫秒级完成,符合预期。
- 通过外表查询Hive场景下,StarRocks单dt查询性能相较Trino有一倍提升,符合预期。
- 通过外表查询Hive场景下,StarRocks多dt查询性能相较Trino需要sql计算复杂度,由于Trino节点数、机器配置更高,在聚合维度很细的场景下,查询更快,Starrocks容易达到资源、IO瓶颈、会出现查询内存超过worker节点的错误。
提速效果得到了互动域小组的高度认可。
五、踩坑点
1. 删除分区数据
-- 当我们进行删除的时候,如果没有添加force,数据不会被删除,数据会被放置到BE节点存储目录下的trash目录,一天后会被删除。在这个过程中,我们可以进行数据的恢复。如果需要立刻删除数据则必须添加force 关键字。
-- 查看PartitionName
show partitions from edw_dwd.dwd_interact_qm_aggs_log;
-- 对于动态分区表需要先设置"dynamic_partition.enable" = "false",删除完分区后再设置回来
ALTER TABLE edw_dwd.dwd_interact_qm_aggs_log SET ("dynamic_partition.enable" = "false");
alter table edw_dwd.dwd_interact_qm_aggs_log drop partition p20230410 force;
ALTER TABLE edw_dwd.dwd_interact_qm_aggs_log SET ("dynamic_partition.enable" = "true");
-- 对于非动态分区表可直接删除
2. Delete数据
-- delete只支持删除少量数据,比如几千条这样,删除大数据量,会导致be节点hang住
delete from edw_dwd.dwd_interact_qm_aggs_log where dt = '2023-04-11' ;
3. 删除表
-- 当我们进行删除的时候,如果没有添加force,数据不会被删除,数据会被放置到BE节点存储目录下的trash目录,一天后会被删除。在这个过程中,我们可以进行数据的恢复。如果需要立刻删除数据则必须添加force 关键字。
drop table edw_dwd.dwd_interact_qm_aggs_log force;
4. FlinkSQL导入数据
- 在FlinkSQL中StarRocks的Sink表必须设置PRIMARY KEY
- load-url参数中端口为fe-http端口,开源版本默认为8030,阿里云默认为18030
- 写入时要尤其注意分隔符的问题,一般只要业务库中的字符串中没有乱码、换行符,用默认即可,如果怎么调整都不行,可以使用sql 'sink.properties.format' = 'json','sink.properties.strip_outer_array' = 'true'参数用json的方式导入,但是会略微降低导入性能。
六、展望未来
目前StarRocks在七猫的应用,已经处在比较成熟的阶段,但我们依然在不断进步,不断探索新的技术优化点,未来,我们将会去探索StarRocks的很多高级功能特性,提高资源利用率、查询性能,并且能够有效控制成本。主要技术点如下:
- CBO 统计信息
CBO 优化器是查询优化的关键。一条 SQL 查询到达 StarRocks 后,会解析为一条逻辑执行计划,CBO 优化器对逻辑计划进行改写和转换,生成多个物理执行计划。通过估算计划中每个算子的执行代价(CPU、内存、网络、I/O 等资源消耗),选择代价最低的一条查询路径作为最终的物理查询计划。
- 异步物化视图
异步物化视图支持多表关联以及更加丰富的聚合算子。异步物化视图可以通过手动调用或定时任务的方式刷新,并且支持刷新部分分区,可以大幅降低刷新成本。除此之外,异步物化视图支持多种查询改写场景,实现自动、透明查询加速。
- Colocate Join
Colocate Join 功能是分布式系统实现 Join 数据分布的策略之一,能够减少数据多节点分布时 Join 操作引起的数据移动和网络传输,从而提高查询性
- Query Cache
StarRocks 提供的 Query Cache 特性,可以帮助您极大地提升聚合查询的性能。