1. 七猫选用 StarRocks 的原因
1.1 历史的痛点
之前七猫采用的是clickhouse用于存储明细和聚合数据。随着业务的快速发展,已经越来越不满足用户的需求,主要表现为以下几点:
- 使用门槛高,不支持标准sql,做分片后关联需要注意sql写法
- 并发能力差,join性能不理想
- 运维成本高,故障恢复难度高
- 数据快速膨胀,查询性能达到瓶颈
- clickhouse去重效果差
1.2 OLAP引擎选型
为了解决这些问题,我们调研了多款OLAP引擎,没有一款引擎能从数据规模,查询性能,灵活性三个方面满足我们的需求。结合实际,综合考虑,我们选择了 StarRocks 作为七猫大数据基础平台新一代 OLAP 引擎。主要考虑到 StarRocks 有以下几点优势:
- 极致查询性能:单表查询性能已经超过 ClickHouse,多表 Join 经过 CBO 优化,性能远超 ClickHouse
- 同时支持明细和聚合模型:支持 Duplicate/Aggregate/Unique 三种数据模型,同时支持物化视图
- 高效数据导入:支持高效流式导入和批量导入
- 运维简单,高可用:多副本,一致性协议支持高可用,自动化运维,操作简单
2. StarRocks 原理介绍
2.1 系统架构图
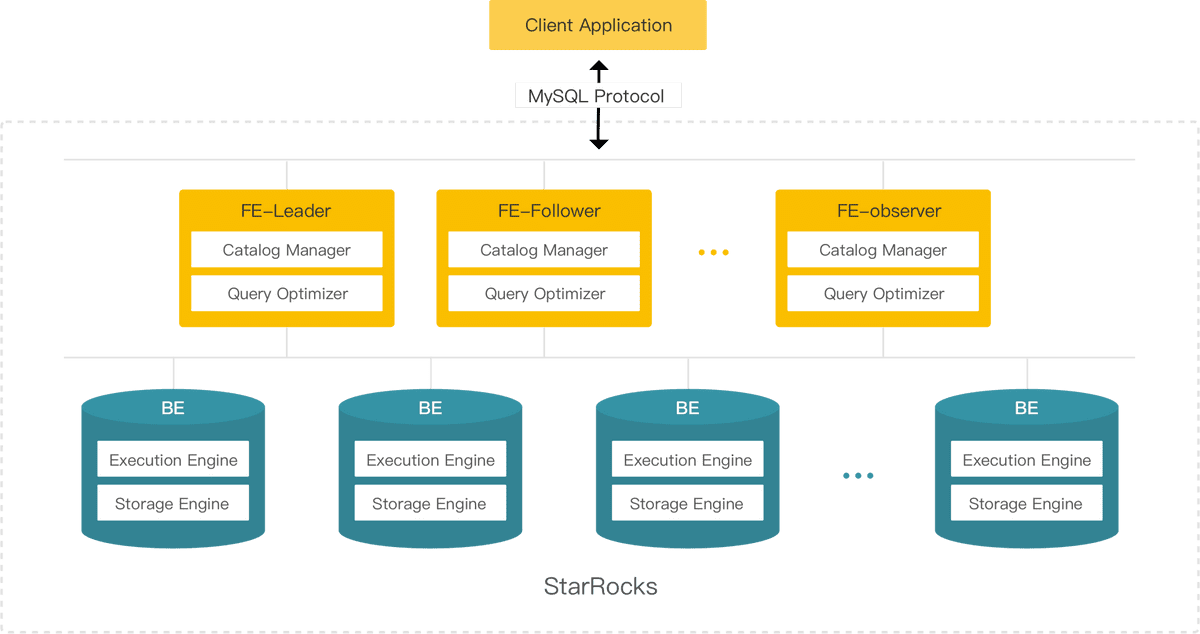
2.2 FE
FE 是 StarRocks 的前端节点,负责管理元数据,管理客户端连接,进行查询规划,查询调度等工作。每个 FE 节点都会在内存保留一份完整的元数据,这样每个 FE 节点都能够提供无差别的服务。
FE 有三种角色:Leader FE,Follower FE 和 Observer FE。Follower 会通过类 Paxos 的 Berkeley DB Java Edition(BDBJE)协议自动选举出一个 Leader。三者区别如下:
Leader
- Leader 从 Follower 中自动选出,进行选主需要集群中有半数以上的 Follower 节点存活。如果 Leader 节点失败,Follower 会发起新一轮选举。
- Leader FE 提供元数据读写服务。只有 Leader 节点会对元数据进行写操作,Follower 和 Observer 只有读取权限。Follower 和 Observer 将元数据写入请求路由到 Leader 节点,Leader 更新完数据后,会通过 BDB JE 同步给 Follower 和 Observer。必须有半数以上的 Follower 节点同步成功才算作元数据写入成功。
Follower
- 只有元数据读取权限,无写入权限。通过回放 Leader 的元数据日志来异步同步数据。
- 参与 Leader 选举,必须有半数以上的 Follower 节点存活才能进行选主。
Observer
- 主要用于扩展集群的查询并发能力,可选部署。
- 不参与选主,不会增加集群的选主压力。
- 通过回放 Leader 的元数据日志来异步同步数据。
2.3 BE
BE 是 StarRocks 的后端节点,负责数据存储、SQL执行等工作。
- 数据存储方面,StarRocks 的 BE 节点都是完全对等的,FE 按照一定策略将数据分配到对应的 BE 节点。BE 负责将导入数据写成对应的格式存储下来,并生成相关索引。
- 在执行 SQL 计算时,一条 SQL 语句首先会按照具体的语义规划成逻辑执行单元,然后再按照数据的分布情况拆分成具体的物理执行单元。物理执行单元会在对应的数据存储节点上执行,这样可以实现本地计算,避免数据的传输与拷贝,从而能够得到极致的查询性能。
3. StarRocks 在七猫的实践
3.1 集群架构
采用StarRocks作为七猫大数据基础平台的OLAP引擎后,我们的当前的架构是这样的:
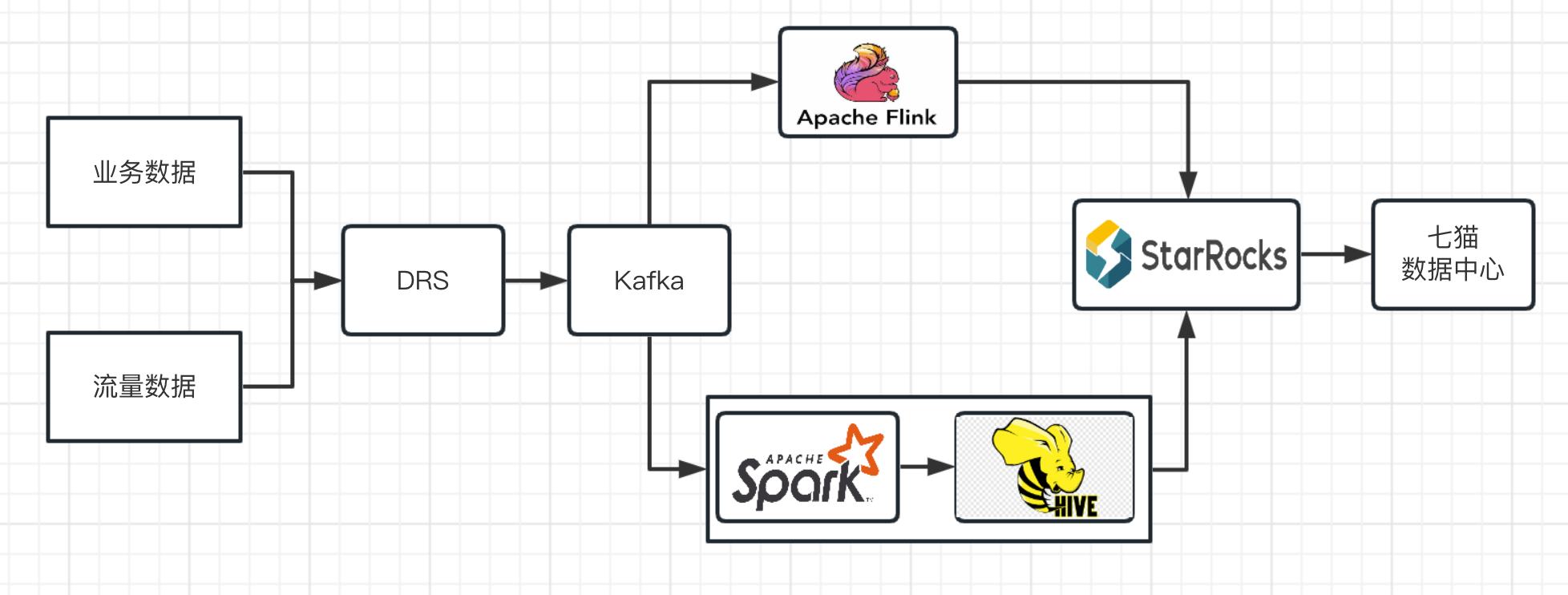
业务数据和流量数据通过DRS服务,写入至Kafka中。实时数据通过 Flink 进行 ETL,实时写入 StarRocks 中;离线数据通过 Spark 进行 ETL,写入 Hive 中,然后导入到 StarRocks 中。由 StarRocks 作为统一的查询引擎,架构简单明了。
目前已经落地2套StarRocks集群,还有1-2套集群正在测试阶段。其中规模较大的集群为:3个FE,20个BE,同时有一套针对StarRocks监控系统(Prometheus+Grafana)。
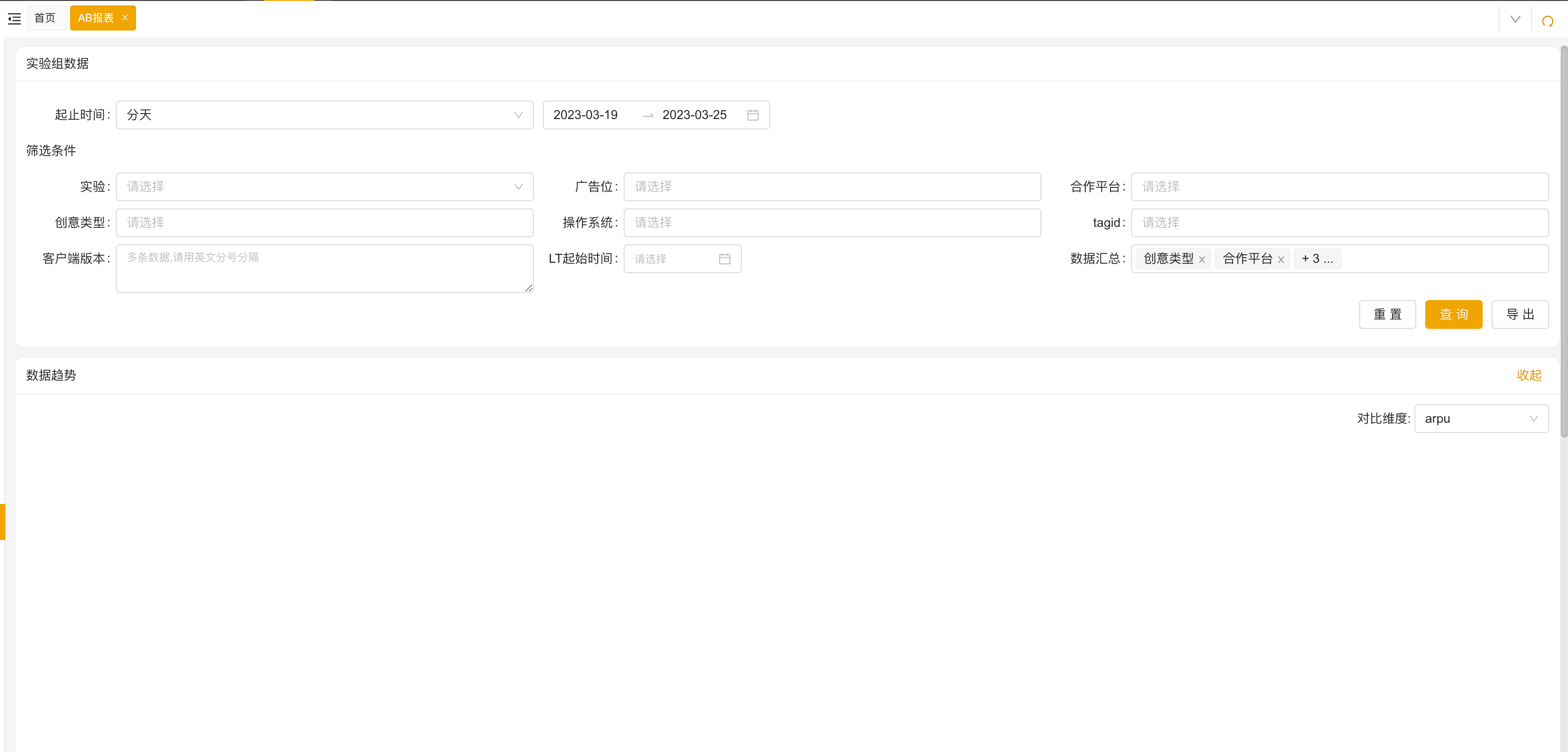
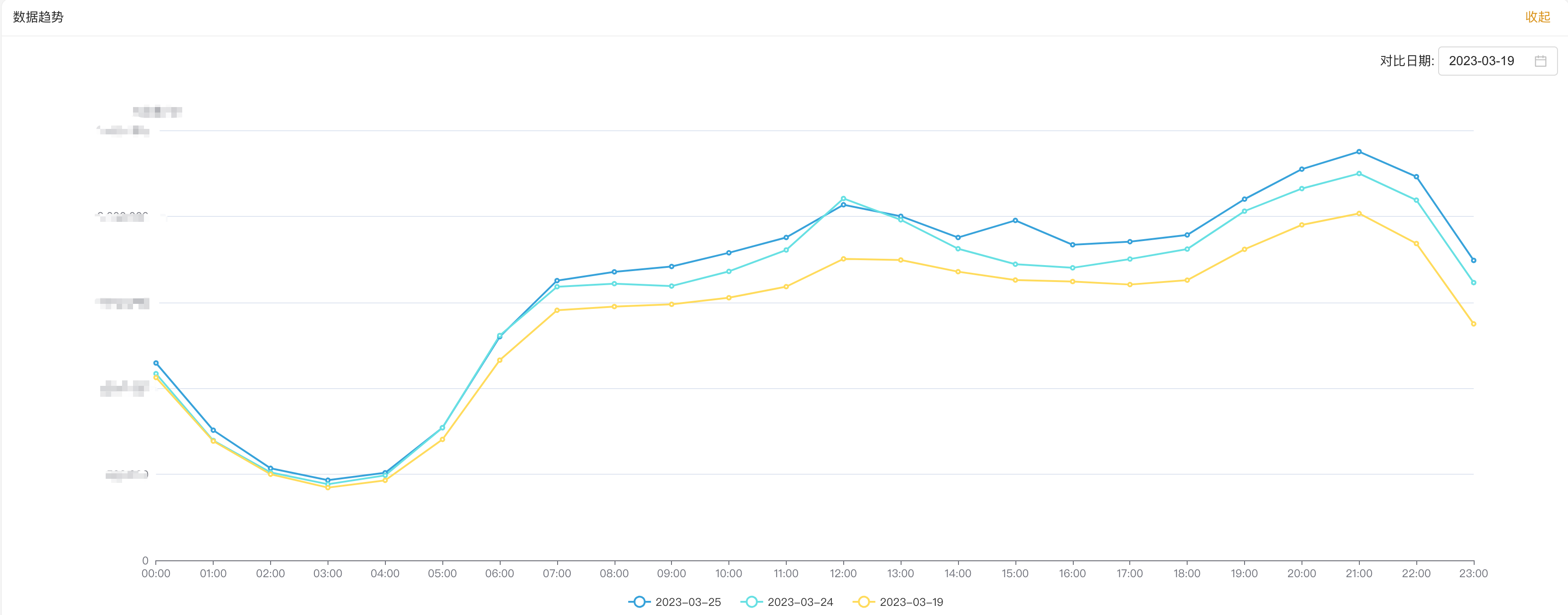
3.2 平台展示
下图是我们基于 StarRocks 实现的一个广告数据分析平台,主要是提供业务分析以及看板、报表等等这些服务。
4. StarRocks 优化
4.1 对象存储(Obs)兼容性优化
在利用StarRocks读取对象存储(Obs)上存储的Hive表时,我们碰到StarRocks无法识别对象存储(Obs)地址。

经过源码分析是由于计算签名时的Canonical Request String将objKey中的‘=’编码为‘%3D’, 但是发送请求时没有做urlencode,造成对象存储(Obs)服务端403。我们针对源码修改、编译、部署后顺利实现StarRocks读取对象存储(Obs)上存储的Hive表。
在生产集群中我们也碰到其他一些问题,StarRocks社区都能帮我们快速解决问题,后续我们也会将此功能贡献给StarRocks社区,携手社区共同发展。
5. 总结
总的来说,首先我们觉得 StarRocks 运维简单,成本低。由于StarRocks同时支持明细和聚合模型,可以满足大多数场景,之前采用的多种引擎构建数据中心的架构,现在可以采用 StarRocks 作为唯一引擎,架构简单明了,运维高效便捷。第一: StarRocks 查询性能优越,StarRocks 近乎实时的查询性能,针对很多典型场景进行优化的各种特性(Colocate Shuffle Join,Bucket Shuffle Join,CBO等),给用户带来了良好的使用体验。第二:StarRocks 既可存算一体,也可存算分离。目前 StarRocks 是存算一体的系统,但它同时支持 ES/MySQL/Hive 等外表功能,可以实现对 Hadoop 生态的查询,可以做到存算分离,对于节省成本,打通 Hadoop 生态很有意义。