1.什么是熔断?
熔断这一概念来源于电子工程中的断路器(Circuit Breaker)。在互联网系统中,当下游服务因访问压力过大而响应变慢或失败,上游服务为了保护系统整体的可用性,可以暂时切断对下游服务的调用。这种牺牲局部,保全整体的措施就叫做熔断。
2.为什么要做熔断?
在讲解熔断之前,我们先了解下什么雪崩效应。
什么是雪崩效应?
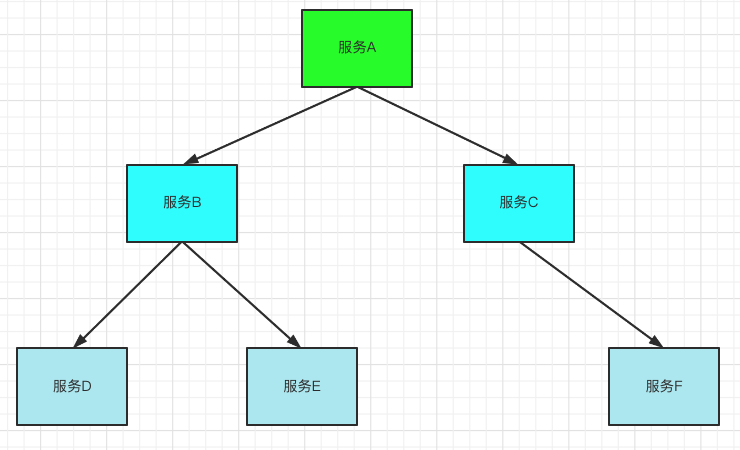
如上图所示,如果在A的链路上某个或几个被调用的子服务不可用或延迟较高,则会导致调用A服务的请求被堵住。堵住的请求会消耗占用掉系统的线程、io等资源,当该类请求越来越多,占用的计算机资源越来越多的时候,会导致系统瓶颈出现,造成其他的请求同样不可用,最终导致业务系统崩溃,这种现象称为雪崩效应。
服务雪崩效应是一种因“服务提供者的不可用”(原因)导致“服务调用者不可用”(结果),并将不可用逐渐放大的现象。
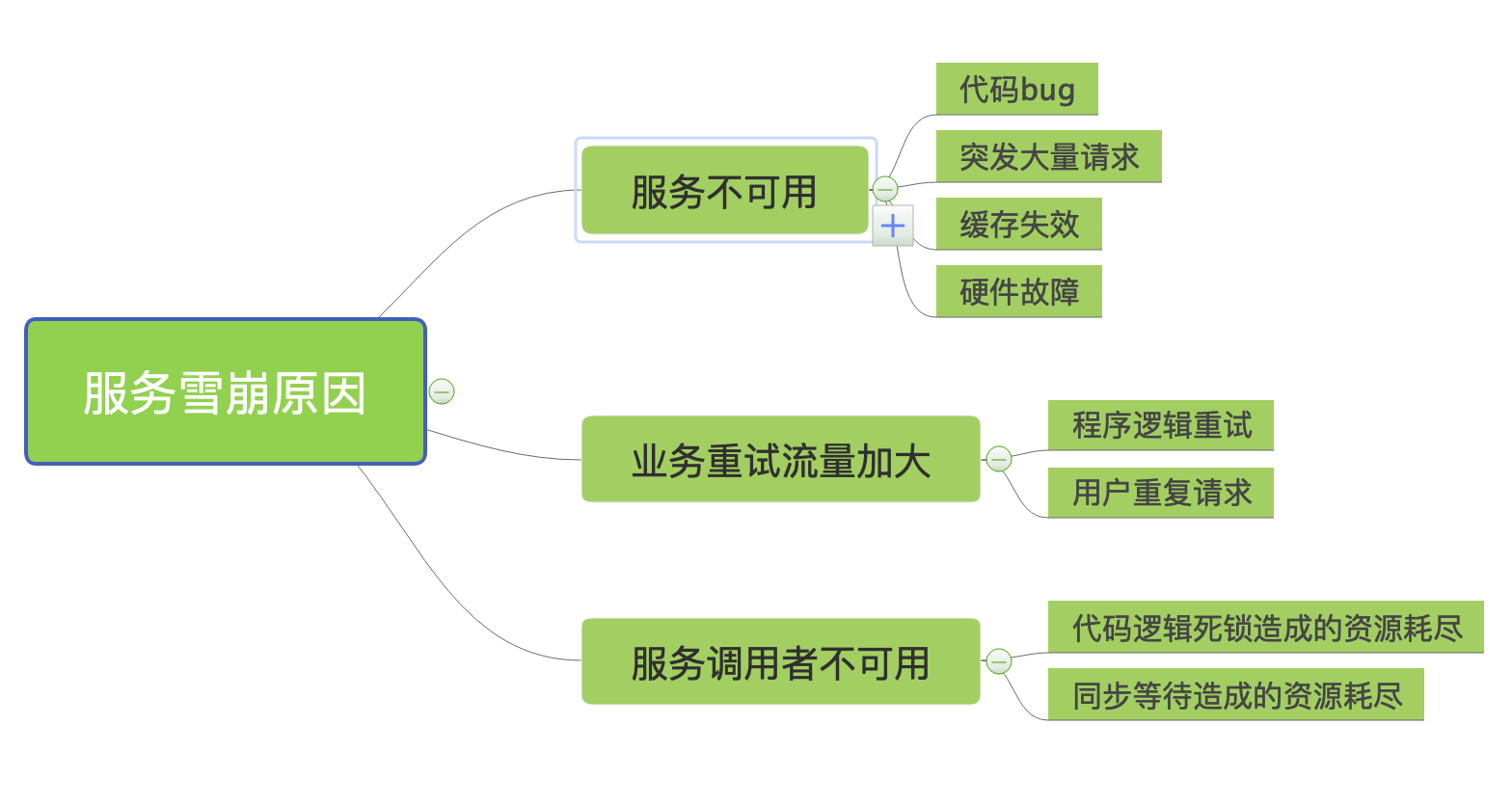
如上图所示,服务雪崩的过程可以分为三个阶段:
①服务提供者不可用;
②重试加大请求流量;
③服务调用者不可用;
如何避免雪崩?
服务熔断和服务降级是解决雪崩效应的两个重要手段。
服务熔断是指:当下游的服务因为某种原因突然变得不可用或响应过慢,上游服务为了保证自己整体服务的可用性,不再继续调用目标服务,直接返回,快速释放资源。如果目标服务情况好转则恢复调用,熔断机制是应对雪崩效应的⼀种微服务链路保护机制。例如在高压电路中,如果某个地方的电压过高,熔断器就会熔断,对电路进行保护。同样,在微服务架构中,熔断机制也是起着类似的作用。当调用链路的某个微服务不可用或者响应时间太长时,会进行服务熔断,不再有该节点微服务的调用,快速返回错误的响应信息。当检测到该节点微服务调用响应正常后,再恢复正常的调用链路。
服务降级是指:从系统整体考虑,当某个服务熔断之后,服务器不再被调⽤时,客户端可以为发送的请求准备⼀个本地的fallback回调,返回⼀个与方法返回值类型相同的缺省值,这样做,虽然服务水平下降,但整体仍然可用,服务熔断可以理解为一种特殊的服务降级。
3. 熔断技术选型
我们目前项目使用的Hystrix包来做服务熔断;Hystrix包的地址是:github.com/afex/hystrix-go
Hystrix介绍
Hystrix(豪猪--->身上很多刺--->保护自己),宣⾔“defend your app”,是由Netflflix开源的⼀个延迟和容错库,⽤于隔离访问远程系统、服务或者第三⽅库,防⽌级联失败,从而提升系统的可⽤性与容错性。Hystrix主要通过以下几点实现延迟和容错。
①包裹请求:
使⽤HystrixCommand包裹对依赖的调⽤逻辑。 ⾃动投递微服务⽅法(@HystrixCommand 添加Hystrix控制)。
②跳闸机制:
当某服务的错误率超过⼀定的阈值时,Hystrix可以跳闸,停⽌请求该服务⼀段时间。
③资源隔离:
Hystrix为每个依赖都维护了⼀个⼩型的线程池(舱壁模式)(或者信号量)。如果该线程池已满, 发往该依赖的请求就被⽴即拒绝,⽽不是排队等待,从⽽加速失败判定。
④监控:
Hystrix可以近乎实时地监控运⾏指标和配置的变化,例如成功、失败、超时、以及被拒绝 的请求等。
回退机制:当请求失败、超时、被拒绝,或当断路器打开时,执⾏回退逻辑。回退逻辑由开发⼈员 ⾃⾏提供,例如返回⼀个缺省值。
⑤⾃我修复:
断路器打开⼀段时间后,会⾃动进⼊“半开”状态。为了保证系统不出现雪崩等问题,服务熔断必不可少。
Hystrix参考链接:https://github.com/Netflix/Hystrix/wiki
快速安装
go get -u github.com/afex/hystrix-go/hystrix
简易使用
hystrix.Go("my_command", func() error {
// talk to other services
return nil
}, func(err error) error {
// do this when services are down
return nil
})
4.断路器 HystrixCircuitBreaker核心工作流程
Hystrix主要是通过 HystrixCircuitBreake来实现熔断的,HystrixCircuitBreaker 有三种状态 :分别是CLOSED :关闭;OPEN :打开;HALF_OPEN :半开。
其中,断路器处于打开状态时,链路处于非健康状态,其实熔断器工作,命令执行时,直接调用回退逻辑,跳过正常逻辑。
HystrixCircuitBreaker 状态变迁如下图 :
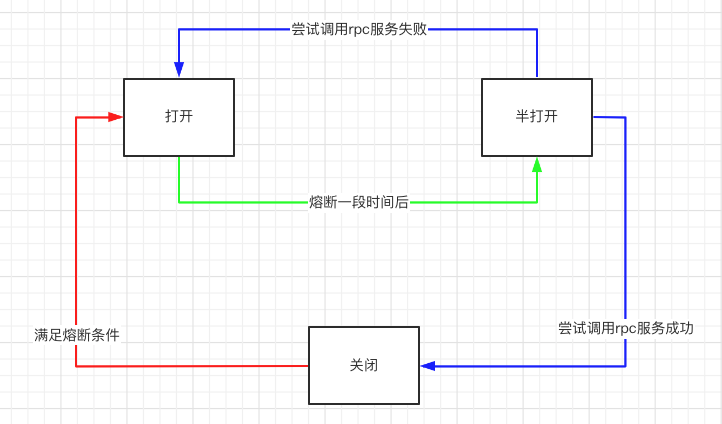
①红线 :
初始时,断路器处于 CLOSED 状态,链路处于健康状态。
当满足如下条件,断路器从 CLOSED 变成 OPEN 状态:
-
熔断前的调用次数(由参数RequestVolumeThreshold控制,默认是20 )内,总请求数超过一定量。 -
错误请求占总请求数超过一定比例( 由参数ErrorPercentThreshold控制,默认值是50%)。
②绿线 :
断路器处于 OPEN 状态,命令执行时,若当前时间超过断路器开启时间一定时间(由参数SleepWindo控制,默认是5000ms ),断路器变成 HALF_OPEN 状态,尝试调用正常逻辑,此时只允许一个请求通过,根据请求的执行是否成功,来决定打开或关闭熔断器(对应图中的蓝线部分)。
③蓝线:
如果上面尝试调用正常逻辑成功,则关闭断路器,恢复服务的正常调用;如果上面尝试调用正常逻辑失败,则保持断路器的开启状态继续熔断。
5. hystrix.go的熔断各参数详解
type CommandConfig struct {
Timeout int `json:"timeout"`
MaxConcurrentRequests int `json:"max_concurrent_requests"`
RequestVolumeThreshold int `json:"request_volume_threshold"`
SleepWindow int `json:"sleep_window"`
ErrorPercentThreshold int `json:"error_percent_threshold"`
}
①RequestVolumeThreshold
启用熔断器功能窗口时间内的最小请求数。试想如果没有这么一个限制,我们配置了 50% 的请求失败会打开熔断器,窗口时间内只有 3 条请求,恰巧两条都失败了,那么熔断器就被打开了,5s 内的请求都被快速失败。此配置项的值需要根据接口的 QPS 进行计算,值太小会有误打开熔断器的可能,值太大超出了时间窗口内的总请求数,则熔断永远也不会被触发。建议设置为 QPS * 窗口秒数 * 60%。
对应的使用RequestVolumeThreshold参数判断熔断器是否打开的源码如下:
// IsOpen is called before any Command execution to check whether or
// not it should be attempted. An "open" circuit means it is disabled.
func (circuit *CircuitBreaker) IsOpen() bool {
circuit.mutex.RLock()
o := circuit.forceOpen || circuit.open
circuit.mutex.RUnlock()
if o {
return true
}
//如果近10秒的请求次数小于配置的RequestVolumeThreshold参数,则熔断器不会熔断,返回false;
if uint64(circuit.metrics.Requests().Sum(time.Now())) < getSettings(circuit.Name).RequestVolumeThreshold {
return false
}
if !circuit.metrics.IsHealthy(time.Now()) {
// too many failures, open the circuit
circuit.setOpen()
return true
}
return false
}
注意:在上面这段逻辑中,circuit.metrics.Requests().Sum(time.Now())是在统计近10秒的请求次数, getSettings(circuit.Name).RequestVolumeThreshold是获取当前RequestVolumeThreshold的配置,如果近10秒的请求次数小于配置的RequestVolumeThreshold参数,则熔断器不会熔断,基础数据太少了,容易因特殊数据产生偏差。
②ErrorPercentThreshold
在通过滑动窗口获取到当前时间段内 Hystrix 方法执行的失败率后,就需要根据此配置来判断是否要将熔断器打开了。 此配置项默认值是 50,即窗口时间内超过 50% 的请求失败后会打开熔断器将后续请求快速失败。
func (m *metricExchange) IsHealthy(now time.Time) bool {
return m.ErrorPercent(now) < getSettings(m.Name).ErrorPercentThreshold
}
③SleepWindow
熔断器打开后,所有的请求都会快速失败,但何时服务恢复正常就是下一个要面对的问题。熔断器打开时,Hystrix 会在经过一段时间后就放行一条请求,如果这条请求执行成功了,说明此时服务很可能已经恢复了正常,那么会将熔断器关闭,如果此请求执行失败,则认为服务依然不可用,熔断器继续保持打开状态。此配置项指定了熔断器打开后经过多长时间允许一次请求尝试执行,默认值是 5000ms。
// AllowRequest is checked before a command executes, ensuring that circuit state and metric health allow it.
// When the circuit is open, this call will occasionally return true to measure whether the external service
// has recovered.
func (circuit *CircuitBreaker) AllowRequest() bool {
return !circuit.IsOpen() || circuit.allowSingleTest()
}
func (circuit *CircuitBreaker) allowSingleTest() bool {
circuit.mutex.RLock()
defer circuit.mutex.RUnlock()
now := time.Now().UnixNano()
openedOrLastTestedTime := atomic.LoadInt64(&circuit.openedOrLastTestedTime)
if circuit.open && now > openedOrLastTestedTime+getSettings(circuit.Name).SleepWindow.Nanoseconds() {
swapped := atomic.CompareAndSwapInt64(&circuit.openedOrLastTestedTime, openedOrLastTestedTime, now)
if swapped {
log.Printf("hystrix-go: allowing single test to possibly close circuit %v", circuit.Name)
}
return swapped
}
return false
④Timeout
定义执行command的超时时间,一旦超时则返回失败, 默认值是1000ms。
⑤MaxConcurrentRequests
最大并发请求数,也就是同时有多少个请求可以同事处理,默认值是10,具体要根据业务的场景设置,设置过小会影响业务。
6.hystrix.go包的核心原理
①UnaryClientInterceptor()方法
使用方调用拦截器UnaryClientInterceptor()方法处理熔断逻辑,具体方法如下:
func UnaryClientInterceptor() grpc.UnaryClientInterceptor {
return func(ctx context.Context, method string, req, reply interface{}, cc *grpc.ClientConn, invoker grpc.UnaryInvoker, opts ...grpc.CallOption) error {
return hystrix.Do(method, func() (err error) {
return invoker(ctx, method, req, reply, cc, opts...)
}, nil)
}
}
②Goc方法
其中代码中的UnaryClientInterceptor()内部逻辑都是调用的是hystrix的Do方法;而Histrix包的Do方法的核心逻辑又是调用了Histrix包的Goc方法,Goc方法才是实现了熔断的功能的幕后功臣,下面我们一起来分析下Goc方法。
// GoC runs your function while tracking the health of previous calls to it.
// If your function begins slowing down or failing repeatedly, we will block
// new calls to it for you to give the dependent service time to repair.
//
// Define a fallback function if you want to define some code to execute during outages.
func GoC(ctx context.Context, name string, run runFuncC, fallback fallbackFuncC) chan error {
cmd := &command{
run: run,
fallback: fallback,
start: time.Now(),
errChan: make(chan error, 1),
finished: make(chan bool, 1),
}
// dont have methods with explicit params and returns
// let data come in and out naturally, like with any closure
// explicit error return to give place for us to kill switch the operation (fallback)
circuit, _, err := GetCircuit(name)
if err != nil {
cmd.errChan <- err
return cmd.errChan
}
cmd.circuit = circuit
ticketCond := sync.NewCond(cmd)
ticketChecked := false
// When the caller extracts error from returned errChan, it's assumed that
// the ticket's been returned to executorPool. Therefore, returnTicket() can
// not run after cmd.errorWithFallback().
returnTicket := func() {
cmd.Lock()
// Avoid releasing before a ticket is acquired.
for !ticketChecked {
ticketCond.Wait()
}
cmd.circuit.executorPool.Return(cmd.ticket)
cmd.Unlock()
}
// Shared by the following two goroutines. It ensures only the faster
// goroutine runs errWithFallback() and reportAllEvent().
returnOnce := &sync.Once{}
reportAllEvent := func() {
err := cmd.circuit.ReportEvent(cmd.events, cmd.start, cmd.runDuration)
if err != nil {
log.Printf(err.Error())
}
}
go func() {
defer func() { cmd.finished <- true }()
// Circuits get opened when recent executions have shown to have a high error rate.
// Rejecting new executions allows backends to recover, and the circuit will allow
// new traffic when it feels a healthly state has returned.
if !cmd.circuit.AllowRequest() {
cmd.Lock()
// It's safe for another goroutine to go ahead releasing a nil ticket.
ticketChecked = true
ticketCond.Signal()
cmd.Unlock()
returnOnce.Do(func() {
returnTicket()
cmd.errorWithFallback(ctx, ErrCircuitOpen)
reportAllEvent()
})
return
}
// As backends falter, requests take longer but don't always fail.
//
// When requests slow down but the incoming rate of requests stays the same, you have to
// run more at a time to keep up. By controlling concurrency during these situations, you can
// shed load which accumulates due to the increasing ratio of active commands to incoming requests.
cmd.Lock()
select {
case cmd.ticket = <-circuit.executorPool.Tickets:
ticketChecked = true
ticketCond.Signal()
cmd.Unlock()
default:
ticketChecked = true
ticketCond.Signal()
cmd.Unlock()
returnOnce.Do(func() {
returnTicket()
cmd.errorWithFallback(ctx, ErrMaxConcurrency)
reportAllEvent()
})
return
}
runStart := time.Now()
runErr := run(ctx)
returnOnce.Do(func() {
defer reportAllEvent()
cmd.runDuration = time.Since(runStart)
returnTicket()
if runErr != nil {
cmd.errorWithFallback(ctx, runErr)
return
}
cmd.reportEvent("success")
})
}()
go func() {
timer := time.NewTimer(getSettings(name).Timeout)
defer timer.Stop()
select {
case <-cmd.finished:
// returnOnce has been executed in another goroutine
case <-ctx.Done():
returnOnce.Do(func() {
returnTicket()
cmd.errorWithFallback(ctx, ctx.Err())
reportAllEvent()
})
return
case <-timer.C:
returnOnce.Do(func() {
returnTicket()
cmd.errorWithFallback(ctx, ErrTimeout)
reportAllEvent()
})
return
}
}()
return cmd.errChan
}
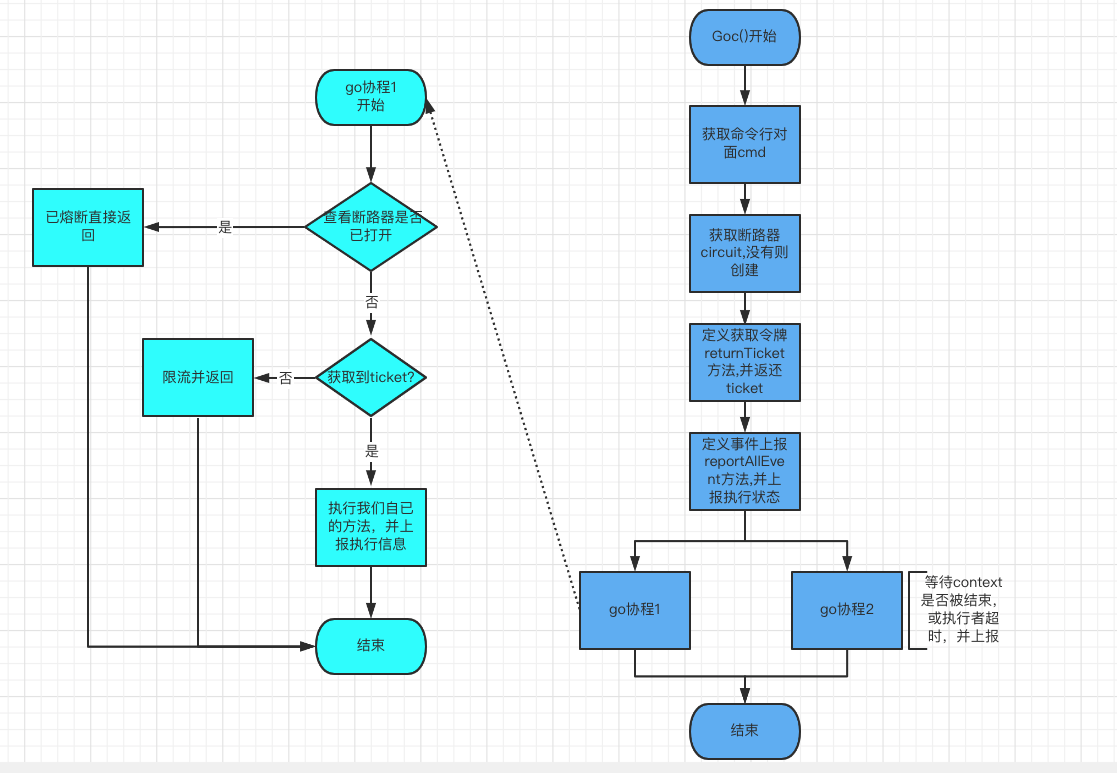
Goc()会调用我们的函数(grpc请求),并且跟踪监控请求的调用情况, 如果请求响应较慢,或者请求经常失败,当达到配置参数对应的条件时,就会出发熔断,之后在SleepWindow时间窗内,将不再会发送请求;Goc()主要逻辑流程图如下:
7.项目中遇见的问题以及解决方案
①书城接口出现类似雪崩的问题
问题描述:
书城调用的rpc服务,出现故障,导致书城相关接口大量请求超时,影响了用户体验。
解决方案:
代码增加熔断处理,下游rpc服务不可用时,触发了熔断机制,做了业务降级,接口返回了降级数据,从而降低了对用户的影响。
②30s接口频繁被熔断
问题描述:
30s接口请求量较大,内部调用了时长服务等远程服务,上线后出现了熔断的现象。
解决方案:
排查下来发现是因为MaxConcurrentRequests没有设置,默认值是10,在这个业务场景下,这个值明显设置过小,导致了熔断;后来将MaxConcurrentRequests设置为100,顺利解决了上述问题。
8. 熔断总结
服务熔断现已经是微服务稳定运行的不可或缺的利器,服务调用端可以通过熔断机制进行自我保护,防止出现由于调用下游服务的各种异常而影响调用端的业务的情况,并且现在很多功能完整的微服务框架都会内置熔断器。
其实,不仅微服务调用之间需要熔断器,在调用依赖资源的时候,比如 mysql、redis 等也可以考虑引入熔断器的机制,做一些适当的熔断降级,来提升系统的稳定性。