浅析 Epub 格式及解析设计
一、背景
随着移动互联网的发展进步,移动终端电子阅读已经成为人们生活中必不可少的精神娱乐。七猫免费小说旨在为国人提供免费好看的小说、图书,丰富人民的精神文化。那么,移动终端如何能够提供好的内容、样式排版?
这就需要对电子书格式进行深入的研究,掌握常见的EPub电子书格式、实现可定制化、差异化、掌握电子书的标准规范,基于标准规范化设计自己的电子书解析引擎,可实现跨平台阅读。
二、标准Epub格式解读
相关储备知识:XML、HTML、CSS
为了便于研究,本文基于未加密的Epub文件进行解读分析,由于Epub文件本质上是压缩文件,可通过本地解压操作,得到相关的内部文件结构,以本地下载的电子书《数学思维.epub》为例:
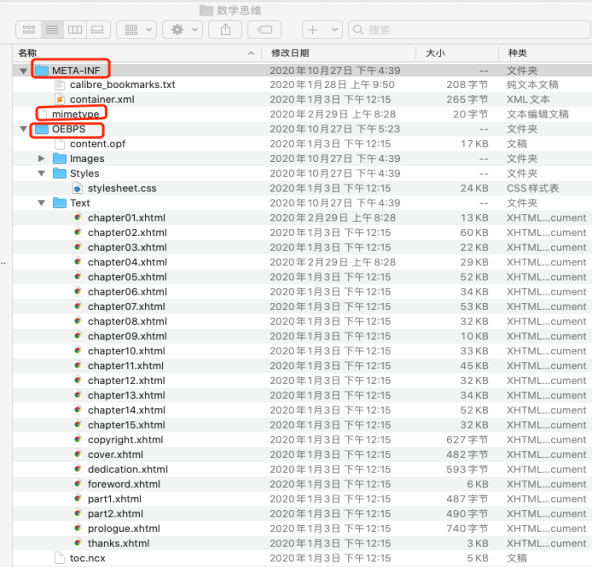 图1: Epub文件结构
图1: Epub文件结构
文件格式主要包括三部分:
(1) mimetype
指定MIME媒体类型
(2) META-INF文件夹
container.xml文件(定义.opf文件的路径及media-type)、
其他文件
(3) OEBPS文件夹
包含images文件夹、
电子书章节内容xhtml文件、
样式表*.css文件(定义电子书内容中各选择器的标签样式)、
content.opf文件(书籍的全部信息)、
toc.ncx文件(电子书的树形目录结构)
2.1 媒体类型及container.xml文件
1. mimetype --- application/epub+zip
2. container.xml
 图2: container 文件内容
图2: container 文件内容2.2核心文件 opf
定义了电子书的全部相关信息:
metadata、manifest、spine、guide、tour(可无)标签
核心文件opf解读,分小节说明。
主要包括书籍的相关元数据:标题、作者、标识信息、出版者、语言等。示例:
<metadata xmlns:dc="http://purl.org/dc/elements/1.1/" xmlns:opf="http://www.idpf.org/2007/opf">
<dc:title>数学思维</dc:title>
<dc:creator opf:role="aut" opf:file-as="[英]郑乐隽">[英]郑乐隽</dc:creator>
<dc:identifier id="bookid">urn:uuid:29d919dd-24f5-4384-be78-b447c9dc299b</dc:identifier>
<dc:date>2020-01-02T16:00:00+00:00</dc:date>
<dc:publisher>中信出版集团</dc:publisher>
<dc:language>zh-CN</dc:language>
<dc:identifier opf:scheme="calibre">68f5c372-e9be-4375-8770-bc278dd1ec60</dc:identifier>
<dc:identifier opf:scheme="ISBN">9787521712612</dc:identifier>
<meta content="0.7.4" name="Sigil version"/>
<meta name="cover" content="cover-image"/>
<meta content="OEBPS/Text/chapter03.xhtml" name="chargeFrom"/>
<meta name="calibre:title_sort" content="数学思维"/>
<meta name="calibre:author_link_map" content="{"[英]郑乐隽": ""}"/>
</metadata> |
2.2.2 manifest标签
定义了全部内容文件列表,每个文件定义了关联的id、文件路径、media-type。
格式:<item href=”” id=”” media-type=””> 示例:
<manifest>
<item href="Text/cover.xhtml" id="cover.xhtml" media-type="application/xhtml+xml"/> <item href="Text/part1.xhtml" id="part1.xhtml" media-type="application/xhtml+xml"/> <item href="toc.ncx" id="ncx" media-type="application/x-dtbncx+xml"/>
<item href="Styles/stylesheet.css" id="stylesheet.css" media-type="text/css"/> <item href="Images/cover.jpg" id="cover-image" media-type="image/jpeg"/> </manifest> |
2.2.3 spine标签
定义了电子阅读的顺序骨架。
格式:<itemref idref=””> 示例:
<spine toc="ncx">
<itemref idref="cover.xhtml"/>
<itemref idref="copyright.xhtml"/>
<itemref idref="dedication.xhtml"/>
<itemref idref="prologue.xhtml"/>
<itemref idref="foreword.xhtml"/>
<itemref idref="part1.xhtml"/>
<itemref idref="chapter01.xhtml"/>
<itemref idref="chapter02.xhtml"/>
// ...
<itemref idref="chapter06.xhtml"/>
<itemref idref="chapter07.xhtml"/>
<itemref idref="chapter08.xhtml"/>
<itemref idref="part2.xhtml"/>
<itemref idref="chapter09.xhtml"/>
// ...
<itemref idref="chapter15.xhtml"/>
<itemref idref="thanks.xhtml"/>
</spine> |
manifest标签和spine标签之间联系,manifest中定义了源文件地址及其id值,而spine标签内每一项指向引用文件的id,也就知道是哪个源文件。所以,要想逐个解析spine内的文件内容,必须先解析manifest标签,建立文件和id的映射关系。
2.2.4 guide标签
指南,一次列出电子书的特定页面
<guide>
<reference href="Text/cover.xhtml" title="cover" type="cover"/>
</guide> |
本例中,指南是一个封面图片。
2.2.5 tour标签
导读,可以根据读者水平或阅读目的,按一定的次序,选择电子书的部分页面组成导读,可以没有。
2.2.6 ncx 目录文件
定义了电子书的目录结构,目录可以分为多级。
目录以 navMap作为一级目录根节点,该层级下的navPoint子节点为一级节点;navPoint下也可以有子节点navPoint,作为二级目录,三级目录等等。
<ncx> <navMap>
<navPoint id="navPoint-1" playOrder="1">
<navLabel>
<text>封面</text>
</navLabel>
<content src="Text/cover.xhtml" />
</navPoint>
<navPoint id="navPoint-2" playOrder="2">
<navLabel>
<text>版权页</text>
</navLabel>
<content src="Text/copyright.xhtml" />
</navPoint>
//... <navMap> </ncx> |
navLabel标签内的文本目录名,content标签是目录对应的文件内容地址。
关于ncx和spine的区别,spine骨架,定义的是要看的电子书每个文件的阅读顺序;而ncx是目录结构,骨架的一个文件可能有子目录,因此,ncx包含的navPoint节点与spine的itemref节点相比,可能多或相等。
举个例子,某电子书一级目录下有二级、三级目录:
 图3:目录手机效果
图3:目录手机效果对应的ncx文件部分内容如下:
<navMap> <navPoint id="navPoint-1">
<navLabel>
<text>Introduction</text>
</navLabel>
<content src="Text/ch001.xhtml#introduction"/>
</navPoint>
<navPoint id="navPoint-2">
<navLabel>
<text>PART I: TOTAL BUSINESS RE-CONFIGURATION</text>
</navLabel>
<content src="Text/ch002.xhtml#part-i-total-business-re-configuration"/>
<navPoint id="navPoint-3">
<navLabel>
<text>Chapter 1: Why Businesses Don’t Grow</text>
</navLabel>
<content src="Text/ch002.xhtml#chapter-1-why-businesses-dont-grow"/>
<navPoint id="navPoint-4">
<navLabel>
<text>The most common startup story</text>
</navLabel>
<content src="Text/ch002.xhtml#the-most-common-startup-story"/>
</navPoint>
<navPoint id="navPoint-5">
<navLabel>
<text>Your three options</text>
</navLabel>
<content src="Text/ch002.xhtml#your-three-options"/>
</navPoint>
</navPoint>
<navPoint id="navPoint-6">
<navLabel>
<text>Chapter 2: How Companies Grow and Die</text>
</navLabel>
<content src="Text/ch002.xhtml#chapter-2-how-companies-grow-and-die"/>
<navPoint id="navPoint-7">
<navLabel>
<text>Growth stage 1: Courtship</text>
</navLabel>
<content src="Text/ch002.xhtml#growth-stage-1-courtship"/>
</navPoint>
<navPoint id="navPoint-8">
<navLabel>
<text>Growth stage 2: Infancy</text>
</navLabel>
<content src="Text/ch002.xhtml#growth-stage-2-infancy"/>
</navPoint>
</navPoint> <navMap> |
可见,在一个文件 Text/ch002.xhtm内,可以存在多级目录,指定的位置格式:
[文件路径]#[id值]
Text/ch002.xhtm#part-i-total-business-re-configuration
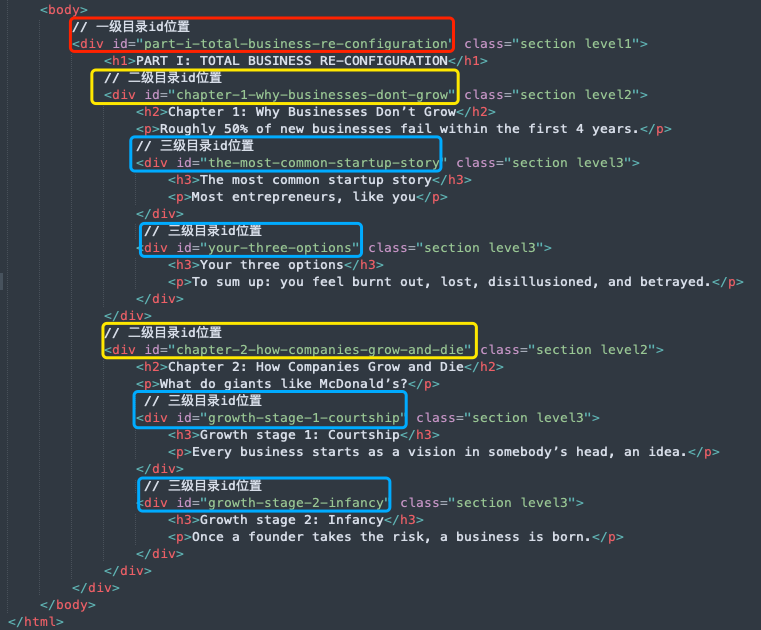 图4:Text/ch002.xhtm文件内容
图4:Text/ch002.xhtm文件内容说明:<div> 可定义文档中的分区或节(division/section),可查阅 W3C div。
2.3 css样式表
该文件定义了书中的样式和类的具体属性,用来以指定格式显示内容。文件的使用一般是在内容文件xhtml的head标签内定义链接的样式表,示例:
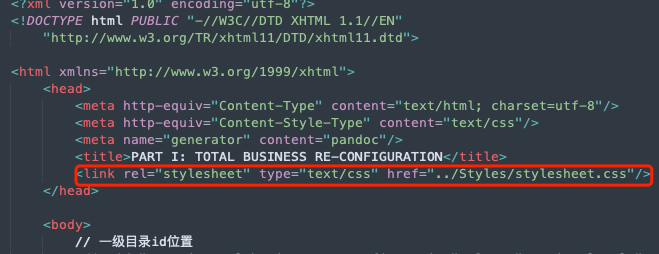 图5: css文件引用
图5: css文件引用在下面的body体内,根据对应的标签匹配样式表,获取对应的内容样式。
样式表文件定义示例:
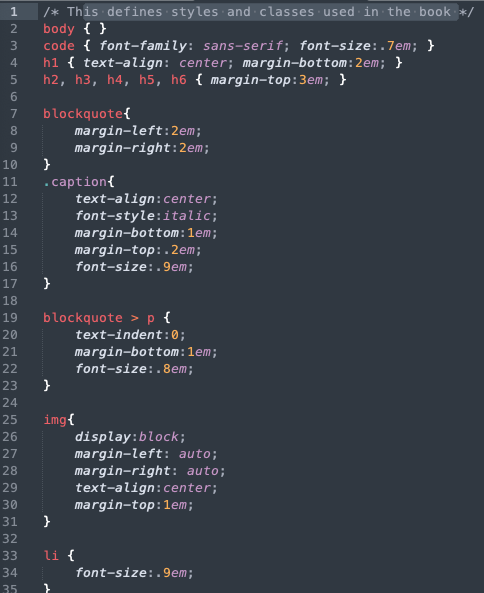 图6: css文件内容示例
图6: css文件内容示例定义了相关的选择器、类选择器、图片、标题等相关等样式属性。
关于选择器相关知识,可自行查阅W3C CSS相关课程。
当然,除了文件css样式表外,body体内的标签也可以直接使用style属性。
三、Epub书籍解析设计
主要包括:
章节目录列表的建立、样式表的读取、章节文件的读取、
根据前面第二章的知识,大概可分解如下几步:
第一步:读取META-INF/container.xml文件
根据文件内容读取得到 opf文件路径;
第二步:读取解析opf文件
得到电子书的全部信息,包括解析manifest标签得到各个文件路径path及id集合;解析spine标签得到骨架顺序引用的文件id集合; 解析出目录文件路径,基于spine标签属性toc指定的文件id;解析得到封面图片;解析读取guide及tour目录集合信息;
第三步:解析toc目录文件ncx
获取电子书的目录结构,基于navMap节点,建立其层级下的navPoint子节点。
第四步:解析.css样式表文件
解析之前需要全局扫描Epub压缩文件,得到全部的样式文件集合,建立样式表文件的映射关系,以便解析xhtml章节文件时获取属性。
第五步:解析章节内容
基于spine骨架顺序的xhtml文件集合,顺序解析各个文件,可采用文件缓存写入本地,构建指定规范的数据文件,以便按照指定格式解析渲染。
解析设计流程图:
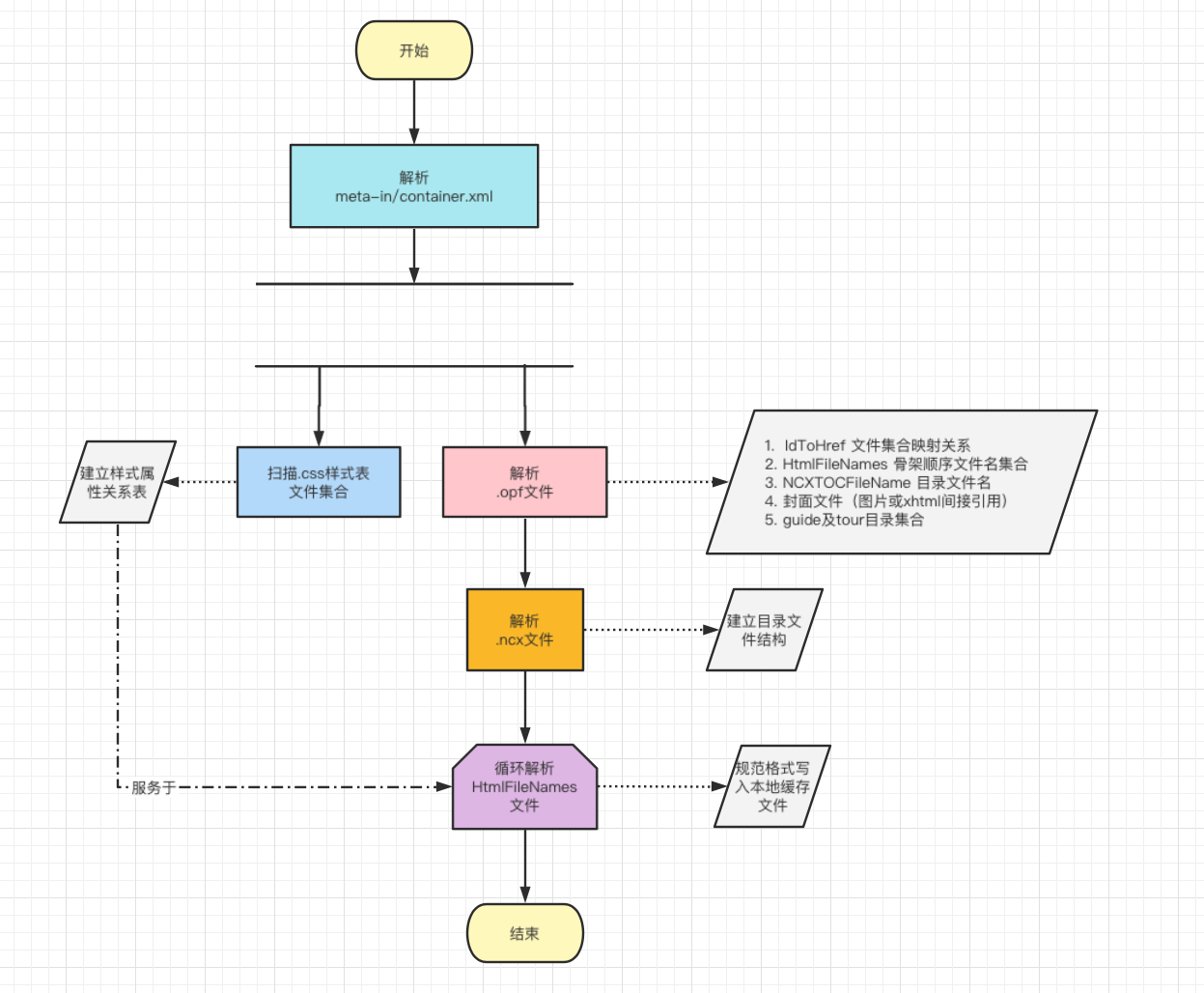 图7:解析流程图
图7:解析流程图四、当前设计局限性及未来优化
上述的Epub书籍解析流程,一般情况下,对于较小的书籍,打开的耗时体验还可以接受,但对于比较大的书籍,且存在复杂样式,书籍的打开体验有待提高。对于此问题,未来考虑将上述流程进行优化,循环解析不是必要的,可对于打开的指定章节文件进行解析加载,也可以预加载相邻的章节,这样可以大幅度提高阅读器的打开体验。
参考文献:
https://www.docin.com/p-1110595694.html
https://www.jianshu.com/p/d930dc5599aa/
https://www.w3school.com.cn