前言
七猫日志接收系统系列文章将会全方位介绍七猫日志接收系统,总共分为四篇:
- 七猫日志接收系统之架构设计(上)
- 七猫日志接收系统之架构设计(下)
- 七猫日志接收系统之客户端埋点 SDK
- 七猫日志接收系统之服务端埋点 SDK(完结篇)
本文是七猫日志接收系统系列文章的完结篇,将简单介绍服务端埋点,并重点分析服务端埋点 SDK 的设计与实现。本文依赖的埋点事件模型和埋点日志上报流程等知识,已在上篇文章中进行介绍过,在此不再赘述。
服务端埋点
服务端埋点指的是在服务器端收集和记录用户行为数据的过程。它通常涉及在服务端的代码中添加跟踪代码,以收集用户与应用程序交互的信息,例如页面访问、操作事件等。
服务端埋点的必要性
既然有了客户端埋点,我们为什么还需要服务端埋点呢?原因主要有以下方面:
- 数据准确性:服务端埋点可以提供更准确的数据,因为它直接在服务器端记录用户行为,不受客户端环境、网络延迟或用户操作的影响。
- 数据完整性:服务端埋点可以捕获到在客户端无法获取的数据,例如请求的详细信息、服务侧处理的中间关键参数,甚至是服务端处理请求时的负载等信息。
- 数据安全性:服务端可以保护用户的隐私,有些隐私数据不方便出现在客户端。
封装 SDK 的优势
埋点上报本质上是请求日志接收系统提供的 API 接口。尽管调用接口看起来似乎并不复杂,业务方可以直接对接,但是通过封装 SDK,我们统一处理了以下三方面的工作:
- 为了防止中间人劫持,日志接收系统接收的日志为加密日志,SDK 对日志做了统一的加密处理;
- 为了保证下游日志接收系统稳定运行,SDK 对日志进行批量聚合上报;
- 为了保障数据完整性,减少网络环境对日志上报的影响,SDK 对上报失败日志进行统一重传。
通过这些封装处理,我们提供 Go 版本的 SDK ,能够降低业务方接入日志接收系统的开发成本。
服务端埋点 SDK
业务流程
埋点上报的整体业务流程如下图:
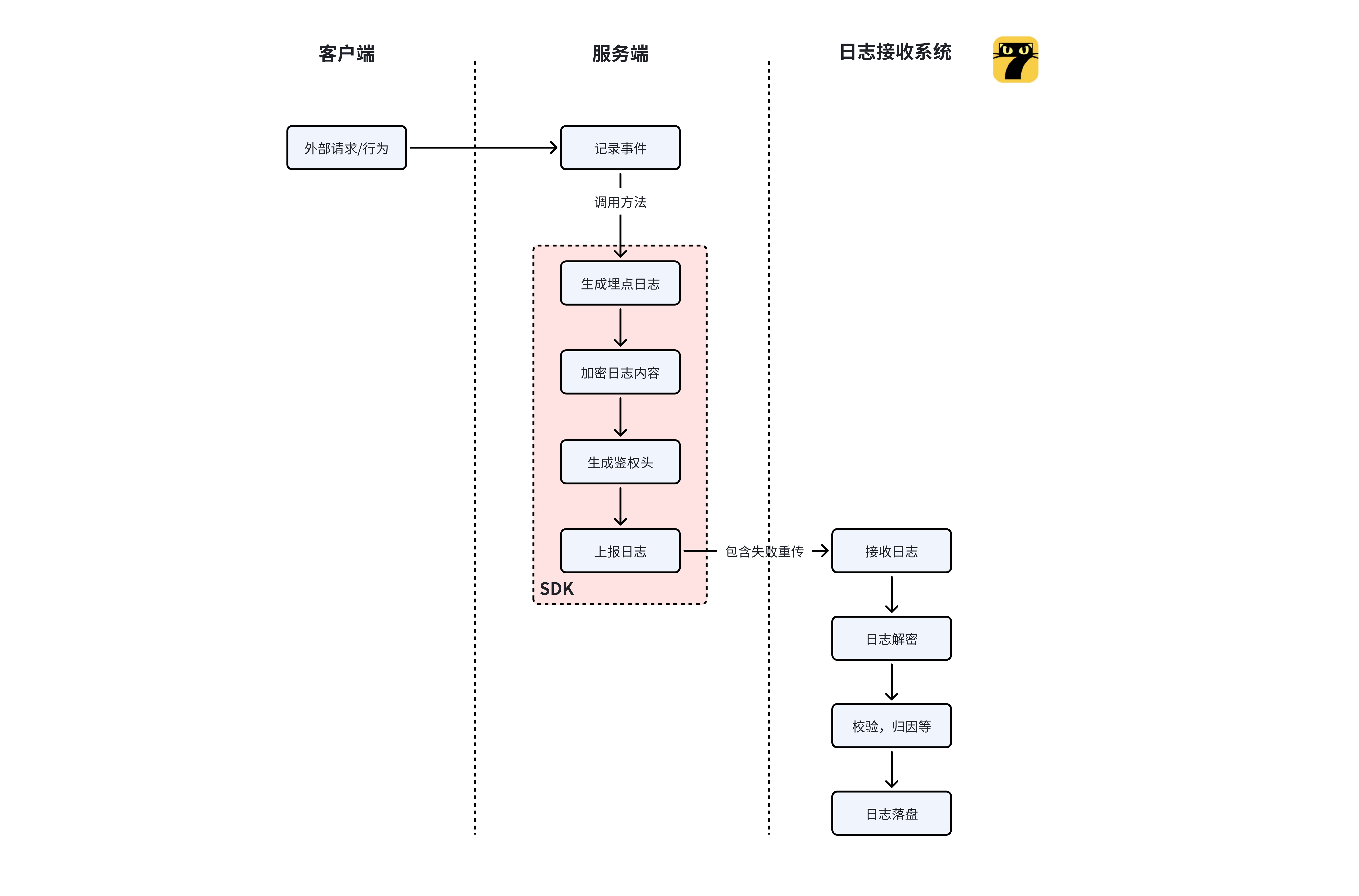
- 由来自客户端的外部请求/行为,触发了服务端的某个事件,服务端记录事件,随后调用 SDK 方法;
- SDK 会将事件组装成埋点日志内容,并且从业务方选用的字段采集器将除了事件之外的其他日志字段采集,并对整体日志加密,调用日志接收系统接口;
- 日志接收系统会对日志内容解密,随后进行校验归因等处理,将日志落盘后,由 Filebeat 将日志传递到下游(具体可回顾系列文章:七猫日志接收系统之架构设计(上)(下))。
上报流程
下面我们详细看下 SDK 在日志上报的流程上是怎么做的,如下图:
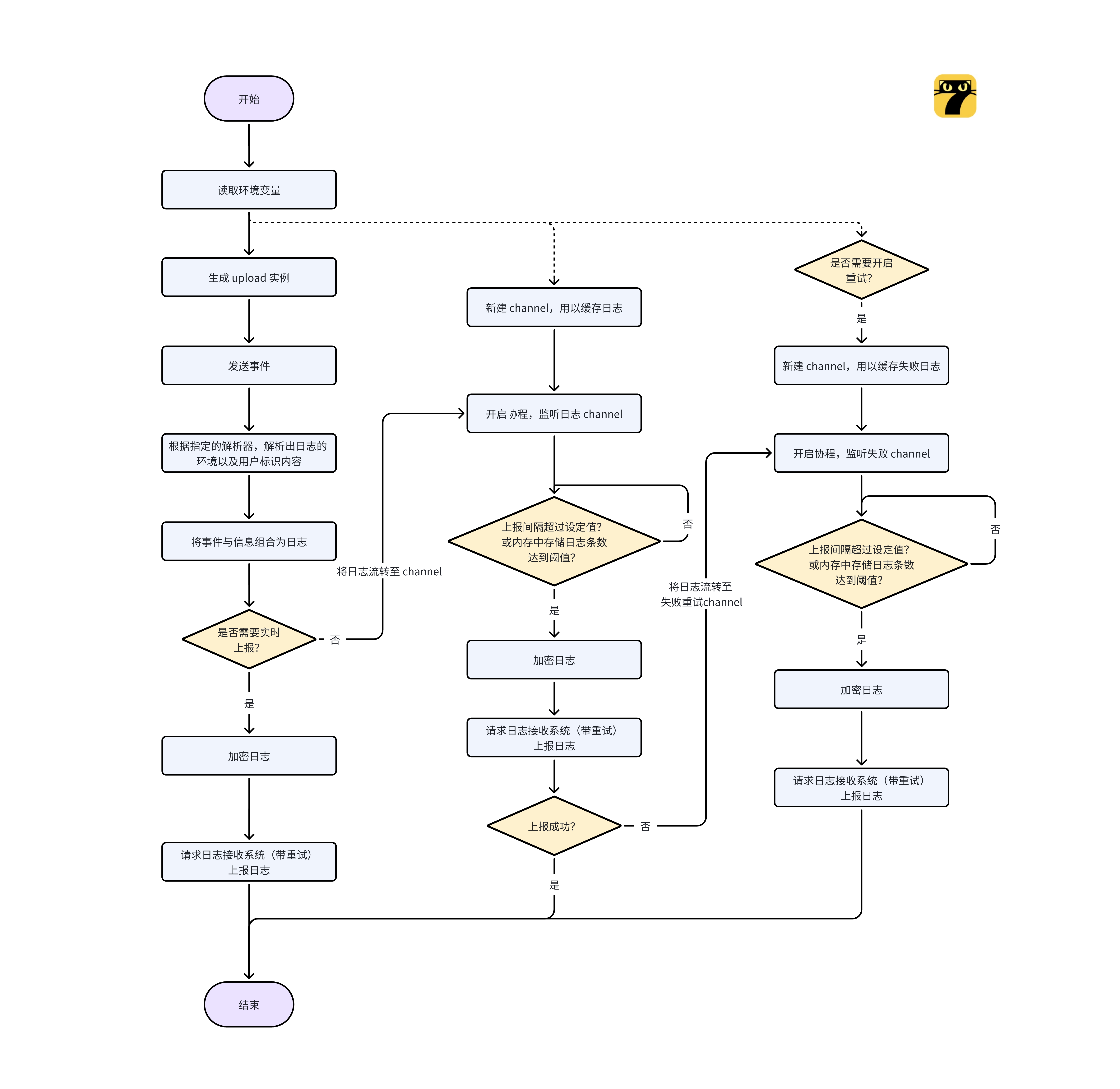
1、首先 SDK 会从环境变量读取上报相关配置(包括上报重试次数,重试间隔,批次大小,时间间隔等):
- 新建 channel 以及开启对应的协程监听,在时间间隔达到设定值或者内存中日志条数大于等于设定的批次大小时,触发一次上报行为;
- 若配置了失败重传,则额外再新建一个 channel 以及开启一个协程监听,用以处理上报失败的日志。
2、业务方新建一个 Upload 实例(上报的环境,是否需要实时上报等配置均可通过 Functional Options 的方式设置);
3、埋点事件发生后,业务方可以调用方法,发送事件,SDK 会根据业务方指定的解析器(下方会介绍),解析出日志需要的环境以及用户标识等字段,并将其与事件相关字段结合,形成一条完整的埋点日志:
- 若配置了实时上报,则立即加密日志,请求日志接收系统将日志上报;
- 否则将日志传递至日志 channel,等待批次满了或者时间间隔达到,加密日志,触发上报。
4、若日志上报 channel 上报日志失败,且业务侧开启了失败重传,则将失败的日志传递至 失败日志 channel,等待批次满了或者时间间隔达到,加密日志,触发上报。
使用流程
1、首先业务方需要先在后台注册项目,并且获取系统分配的密钥对;
2、对于上报动作,SDK 提供了很多环境变量给业务方用以控制上报细节。当然业务方也完全可以使用默认值。SDK 提供的环境变量如下:
参数 | 说明 |
UPLOAD_BATCH_SIZE | 每批上报的日志大小,若日志在内存中条数积累到该值,则触发一次上报 |
UPLOAD_BATCH_INTERVAL_MS | 上报的时间间隔,单位:毫秒。 若距离上一次上报时间间隔满足该值,则触发一次上报 |
UPLOAD_TRY_TIMES | 上报请求总次数,若该值设置大于 1,表示开启重试。 且该值设置不能小于 1 次 |
UPLOAD_TRY_INTERVAL_MS | 上报尝试的时间间隔,决定每次重试之间的时间间隔 |
UPLOAD_FAIL_SIZE | 失败日志每批的日志大小 |
UPLOAD_FAIL_INTERVAL_MS | 失败日志上报尝试的时间间隔 |
UPLOAD_LOGGER_LEVEL | 设置日志级别,为了减少对业务方的打扰,可以通过设置该环境变量设定 SDK 打印日志的级别 |
3、随后在代码中,安装 SDK 包,使用如下的示例,新建一个埋点日志上报实例,如下所示:
func New(appid, secret string, opts ...Option) *Upload其中 appid, secret 即为系统分配的密钥对,除此之外 SDK 通过 Functional Options 的方式(具体见下节介绍)提供了很多可配置项。可选项如下:
方法名 | 描述 |
SetLogger | 设置日志组件,SDK 系统内部默认提供了基于 zap 的 logger,业务方可以按照自己的需要替换为其他的日志组件。 |
SetIsRealtime | 设置是否实时上报,若业务方对于某些特定重要埋点不希望等待定时或者定量上报,那么针对此类事件,可以初始化一个实时上报的实例,这样采集到的埋点事件就会立即上报到日志接收系统。 |
AddIdentityKeys | 补充用户信息字段,SDK 内部默认集成了较为普适的日志字段,当然可能满足不了业务方的需求,业务方可以使用这个方法来扩充日志中用户标识相关字段的 keys(下同,区别在仅在于下方方法是扩充环境相关字段的 keys)。 |
AddEnvironmentKeys | 补充环境信息字段。 |
关键技术
Functional Options
由于 Go 语言不支持重载函数,初始化一个具有多个成员变量的对象时,我们往往需要多种创建不同配置实例的函数签名,并且还得用不同的函数名来应对不同的配置选项。比如,如下的示例:
// Upload 上传实例
type Upload struct {
appid string // APP ID
secret string // APP 秘钥
// ... 其他参数
logger log.Logger // 日志组件
realtime bool // 是否开启实时上报
}针对这样一个 Upload 结构,你可以创建一个默认的,或者一个需要实时上报的,那么你需要实现如下的初始化函数:
// 初始化默认 Upload
func NewDefaultUpload(appid, secret string) *Upload {
return &Upload{
appid: appid,
secret: secret,
}
}
// 初始化需要实时上报的 Upload
func NewUploadWithRealtime(appid, secret string) *Upload {
return &Upload{
appid: appid,
secret: secret,
realtime: true,
}
}这样写配置多了非常的不优雅,当然你也可以选择引入一个 Config 结构,把一些非必填的配置移入该结构中,对于原有实例就只保留必填项。如下:
// Upload 上传实例
type Upload struct {
appid string // APP ID
secret string // APP 秘钥
// ... 其他参数
}
// UploadCfg 可选配置
type UploadCfg struct {
logger log.Logger // 日志组件
realtime bool // 是否开启实时上报
}
func NewUploadWithCfg(appid, secret string, cfg &UploadCfg) *Upload {
u := &Upload{
appid: appid,
secret: secret,
}
if cfg != nil {
u.realtime = cfg.realtime
u.logger = cfg.logger
}
return u
}这样基本上可以解决问题,但是其实有点不好的是,Config 并不是必需的,我们需要判断是否是 nil 或是空结构体Config{} 这引入了额外的判断。想要更加优雅直观,这个时候就轮到我们 Functional options 登场了。我们先定义一个函数类型:
type Option func(o *Upload)然后我们可以使用函数式的方式定义一组如下的函数:
func SetLogger(l log.Logger) Option {
return func(o *Upload) {
o.logger = l
}
}
func SetIsRealtime() Option {
return func(o *Upload) {
o.realtime = true
}
}上面这些函数会设置自己的 Upload 参数。然后我们再定一个 NewUpload()的函数,其中有一个可变参数 options 可以传递多个上面的函数,然后使用一个循环来设置我们的 Upload 对象:
func NewUpload(appid, secret string, opts ...Option) *Upload {
l := log.New("[Upload-SDK]", getEnvLogLevel())
u := &Upload{
appid: appid,
secret: secret,
logger: l,
}
for _, opt := range opts {
opt(u)
}
// ...其他逻辑
return u
}于是,我们在创建 Upload 对象时,就可以通过如下的方式:
u1 := NewUpload("appid", "appsecret", SetLogger(l), SetIsRealtime())这样做看起来整体非常优雅整洁,想要让这个实例配置开启或添加什么配置,就直接在方法调用中添加,从代码上也可以直接看出业务需要使用的配置。
建议大家在平常的代码中使用这种方式来进行个性化的实例创建,其主要好处有:
- 直觉式的编程
- 高度的可配置化
- 很容易维护和扩展
- 自解释性
- 对于新人很容易上手
字段采集器
前文中也有提到,我们埋点日志预置了一些比如环境信息,用户信息等字段。对于这些字段在服务端埋点 SDK 中的采集,我们抽象了采集器的概念。不同采集器通过 Go 的 Interface(接口)实现。Go 没有典型的面向对象语言中的类、对象、继承等相关概念,但是通过 Interface 我们也能实现类似继承、多态等功能。
它定义了一组方法的集合,这些方法可以被任意类型实现。比如我们针对字段采集器设定了如下的接口定义:
type Parser interface {
ParseIdentity(keys []string) map[string]interface{}
ParseEnvironment(keys []string) map[string]interface{}
}这表示一个字段采集器,需要实现 ParseIndentity 以及 ParseEnvironment 两个方法。这两个方法会根据预设的 key 列表从对应的解析器中获取值,并转换为日志对应部分。
只要实现这两个方法,就可以认为它是一个字段采集器并且可以在 SDK 组装日志方法中传递了,以下为 SDK 组装日志时的方法及其在发送事件时的使用:
func (u *Upload) parseIdentity(parser Parser) map[string]interface{} {
return parser.ParseIdentity(u.identityKeys)
}
func (u *Upload) parseEnvironment(parser Parser) map[string]interface{} {
return parser.ParseEnvironment(u.environmentKeys)
}
func (u *Upload) SendEvents(parser Parser, events []Event) {
if events == nil {
return
}
if parser == nil {
parser = new(emptyParser)
}
// 构造消息体
data := &Data{
Environment: u.parseEnvironment(parser),
Identity: u.parseIdentity(parser),
Aggs: events
}
u.send(data)
}为什么需要使用 Interface?
因为服务端参数传递的环境各不相同,我们不能强制要求所有的业务方都把环境信息和用户信息直接通过枚举的方式传递,这会加重业务方的使用负担。因此,在 SDK 中预设了 3 种采集器:
headerParser: 从 HTTP 请求头中采集;contextParser: 从上下文中采集;bytesParser: 从字节流中采集。
在我们的实际应用中,这三类采集器已经基本可以满足需求,但是如果业务方确实有特定需求,可以按照业务的实际情况,通过实现 ParseIdentity 和 ParseEnvironment 方法,来构建属于自己的采集器并无缝与 SDK 的数据采集流程对接。通过使用接口,我们增强了整体 SDK 的可扩展性。
微批处理
当接入的业务方越来越多时,如果每个业务方接收到事件都直接上报的话,那么对底层日志接收系统而言,压力将非常大。并且其实绝大多数的事件对于实时性的要求并没有那么高。
因此,我们需要考虑在 SDK 内使用一些手段来做一定程度的削峰。由于是 SDK,需要考虑业务方接入负担,故我们不考虑引入 Kafka 等中间件,我们考虑对日志进行批量上传。
我们使用 Go 的 channel 来做数据的传递,并通过协程监听的方式做到微批处理。整体流程图如下:
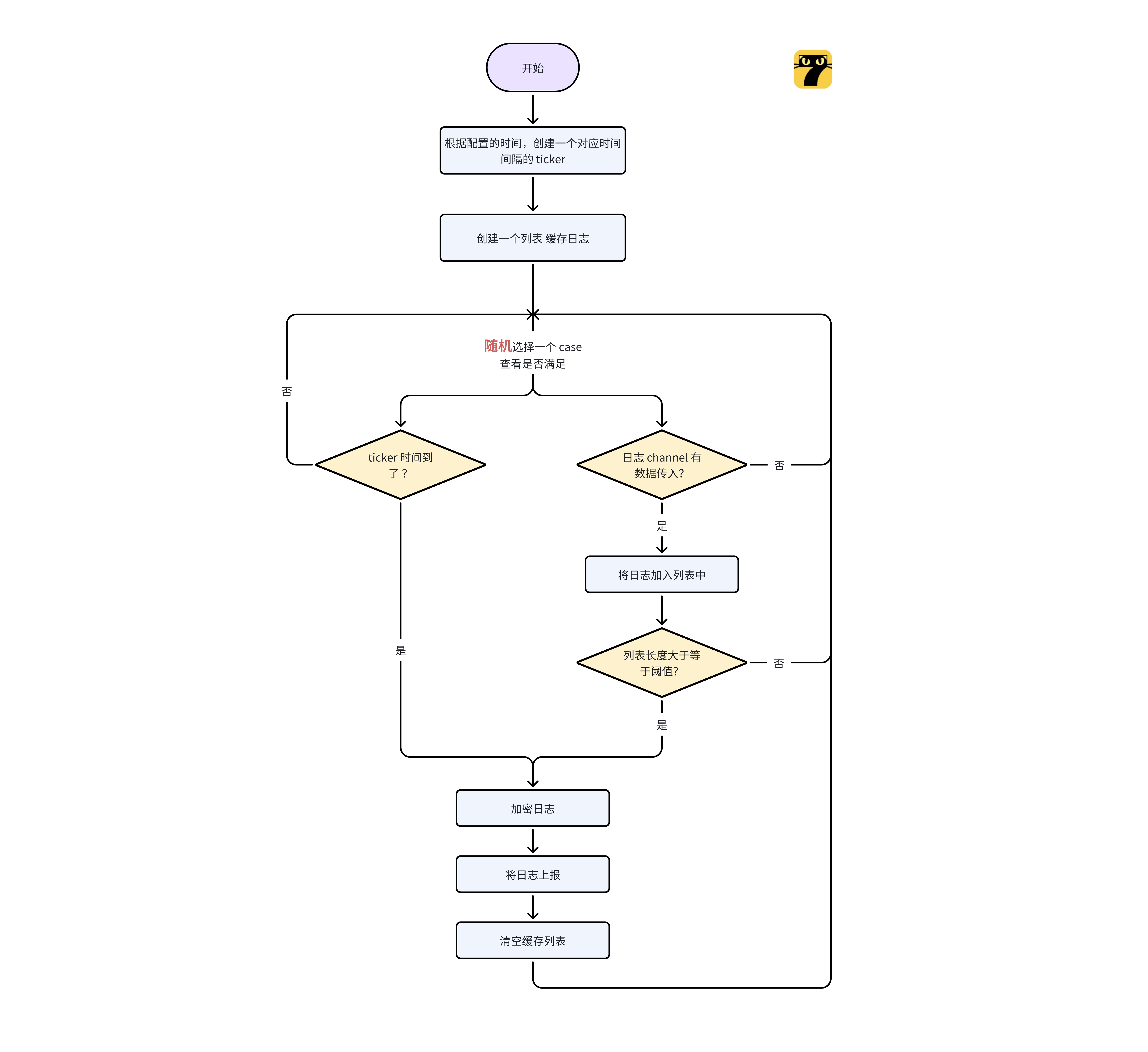
- 首先我们新建一个日志的 channel,并且开启一个协程;
- 根据用户配置的上报时间间隔,设定一个对应的 ticker;在内存初始化一个列表用户暂存日志;
- 开启循环,监听日志 channel,以及 ticker 的 channel:
- 如果 ticker 到了,且日志列表不为空,则将其中日志内容加密上报,同时清空当前的日志列表;
- 如果日志 channel 有日志传入,则将其添加在日志列表中,当日志列表长度大于阈值,则触发一次上报,并清空日志列表;
- 如果上述两种情况都满足,基于 Go 的特性,会随机选择一条分支处理;
- 如果上述两种情况都不满足,则会阻塞,原地等待,直到有一个分支满足为止。
使用这样的技术,我们就可以在业务端侧做到日志的微聚合,减少请求日志接收系统的频次,减少下游的压力。
不过使用内存缓存日志,可能会由于服务重启而数据丢失,经过实践,这种重启丢失数据的影响可以忽略不计,原因一是牵涉的数据量少,二是数据重要程度相对低,核心数据还是会保留在数据库里。
此外,我们已经做了 0 丢失的高可用重启方案,但有一定实现成本,后续如果业务方对数据 0 丢失有强需求,会再考虑推进平衡成本与实现。
重试处理
由于网络情况错综复杂,在请求日志接收系统的过程中,难免会遇到网络拥塞或闪断等,导致上报失败。为了提高日志上报的成功率,我们在 SDK 内集成了失败重传的功能,业务方可以通过环境变量设定失败重传的上报间隔,以开启该功能。
为了防止失败重传阻塞正常日志上传,我们使用的方案也是和微批处理一样的通过 channel 和 ticker 的方式处理。具体处理逻辑和上述一样,无非是额外新建了一个 channel 用于上报失败日志的传递,逻辑细节此处不再赘述。
总结
在本系列文章中,我们首先回顾了七猫日志接收系统近四年来的演进历程,接着基于最新的 v4 版本详细介绍七猫日志接收系统架构,并从日志处理效率、系统的高可用以及成本控制等方面进行架构设计分析,然后给大家介绍了埋点事件模型、埋点数据上报流程,最后分析了客户端埋点 SDK 和服务端埋点 SDK 实现细节。
统计埋点是作为重要的数据采集手段,可以将用户行为信息转化为数据资产,为产品分析、业务决策、数据推荐、商业化应用等提供可靠的数据支持,是七猫非常重要的基础设施之一,希望通过我们系列文章的总结分享,能够给大家带来一些帮助。
在整个系列文章的整理过程中,涉及到客户端开发、服务端开发、大数据开发及运维相关的同事,在此一并表示感谢。