背景
七猫在经过一系列调研、探索和尝试之后,最终选择了阿里云效作为服务端 DevOps 平台,帮助我们做好持续集成、持续交付、持续部署,高频、快速地交付⾼质量软件。但对于客户端 DevOps,在我们经过大量的调研与试用,对比了诸如阿里云效 + EMAS、华为云和火山引擎等多家第三方客户端 DevOps 平台之后,总结出这些平台存在以下问题:
- 需要使用平台的项目管理系统,从我们当前使用的 TAPD 迁移过去成本高;
- 大部分流水线功能较单一,且功能平台较为分散;
- 流程的可定制性、扩展性较差,二次开发难度大;
- 没有灰度发布、回归测试、全渠道发布等核心流程。
因为存在以上问题,第三方客户端 DevOps 平台无法满足七猫客户端开发及发版的核心需求,于是基于自身的业务特性,我们走上了客户端 DevOps 自研之路。需要说明的是,七猫客户端 DevOps 的自研,并非是完全从零开始搭建一套完善的 DevOps 平台,而是基于七猫业务流程特性,将现有的开源工具和成熟方案,与我们自己的业务后台进行整合。
DevOps 流水线
首先,简单介绍一下我们对于 DevOps 流水线的理解。软件工程团队中的 DevOps 流水线是一组自动化流程,能够让开发人员可靠且有效地编译、构建并将代码或制品部署到生产环境。传统的服务端 DevOps 流水线中最常见的模块有构建自动化、持续集成、测试自动化和部署自动化。而对于七猫客户端来说,DevOps 流水线同样是一套标准的流程,只不过这些流程中除了包含代码开发、合并、打包、测试等组件外,还需要包含人工手动审核、AB 测试、自动放量、推送应用商店后台等功能,从而能够实现小渠道发布、全渠道发布等发布流程。
经过抽象,我们可以将业务中的功能模块抽象成以下几个部分:
- 项目管理
- 代码管理
- 编译打包
- 测试管理
- 发布管理
- 线上监控
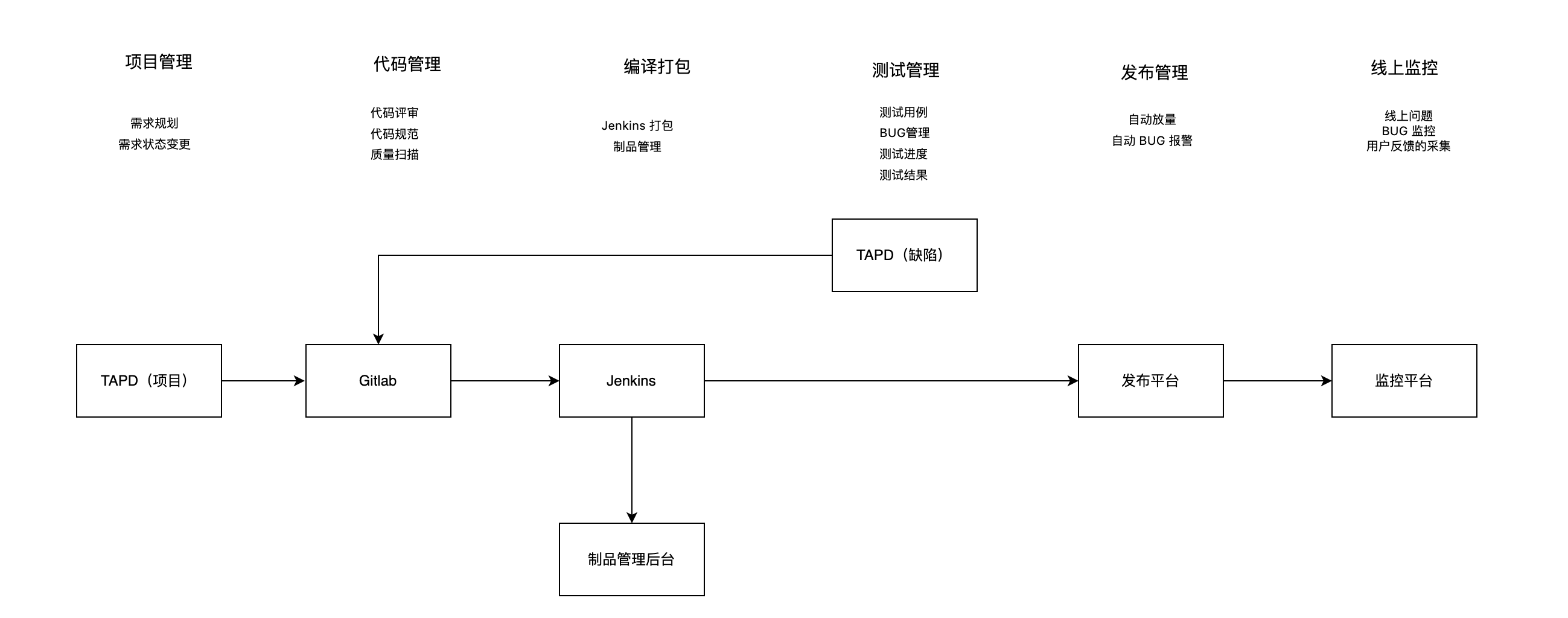
根据实际的业务需要,我们整理了从开发、测试到产品上线发布中涉及的各项流程,抽象出一条条特定的流水线,通过开发 Web 后台、Webhook 服务、企业微信群机器人、企业微信自定义应用等,将这些流程工具化、规范化、自动化和可视化,从而帮助开发、测试及产品人员提高开发、测试和发版的效率。对于我们来说,客户端 DevOps 流水线就是基于业务流程,串联其所需的各功能模块以实现流程的工具化、规范化、自动化和可视化。
设计与实现
整体架构
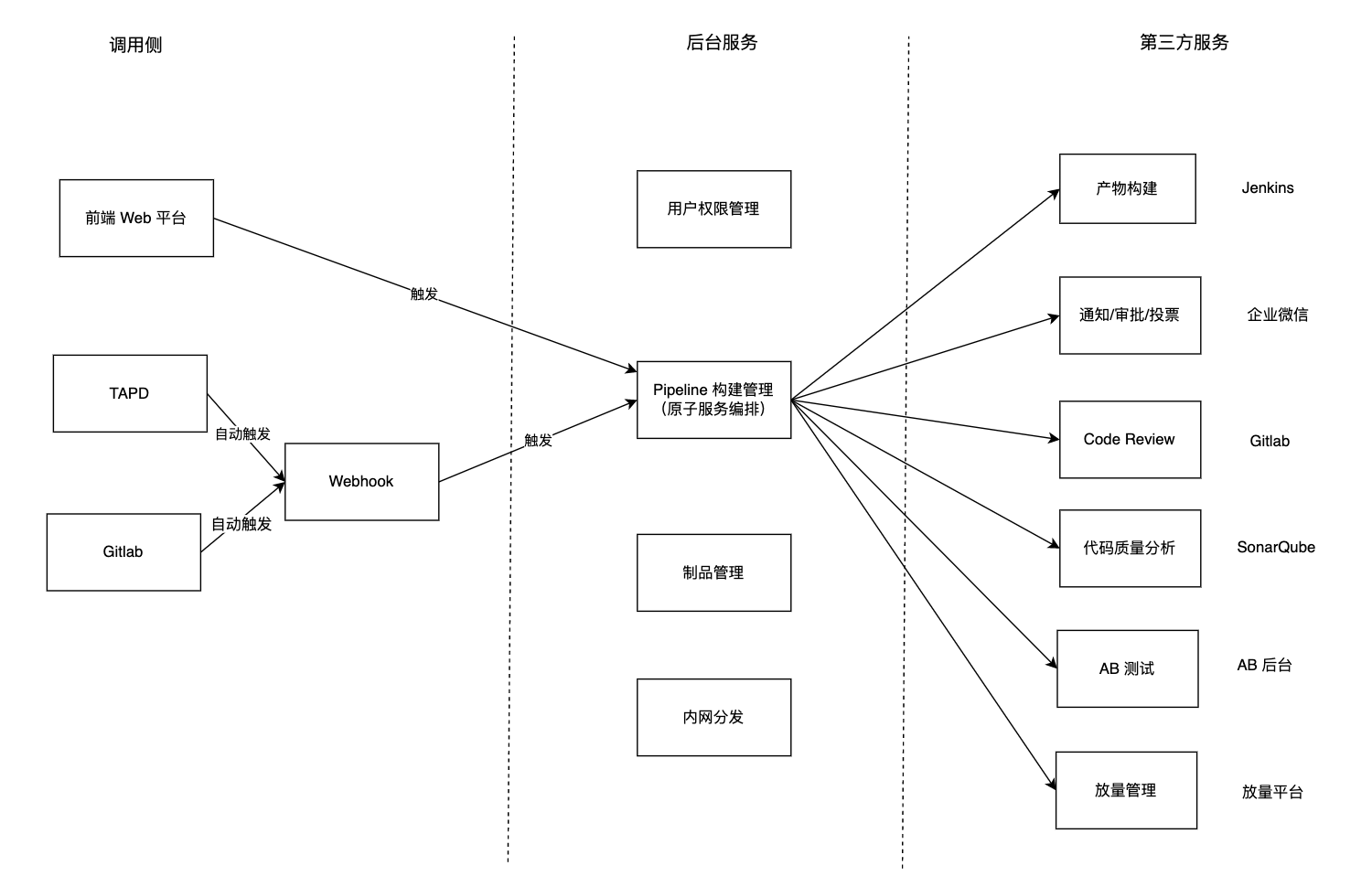
从上图可以看出,我们将整个 DevOps 平台划分为了三个部分:调用侧、后台服务与第三方功能服务。其中调用侧主要是 Web 前台、项目管理平台(TAPD)和代码管理平台(Gitlab),主要用于触发、查看和管理流水线,以及查看和管理构建详情与制品等业务操作。后台服务实现用户权限管理、制品管理、内网分发以及最核心的流水线构建管理。第三方功能服务则实现具体的业务功能,它们将被封装成一个个原子服务,并通过流水线进行编排管理。
本文着重介绍客户端流水线设计与实现。在实现 DevOps 流水线之前,我们首先梳理出了一些流水线中所涉及的核心概念,通过理解这些概念,我们可以更加清晰全面的理解七猫客户端 DevOps 流水线设计与实现的思路。
流水线
如上文上述,我们将流水线(Pipeline)定义为一个规范化、可拆分的完整业务流程。对于客户端的开发、测试及发版,我们整理出了以下这些流程,每个流程都可以对应得到一条流水线:
- 编译打包流水线,实现自动编译打包,并在成功编译后通知测试人员进行测试;
- Android 小渠道发布流水线,实现 Android 小渠道发布流程;
- Android 全渠道发布流水线,实现 Android 全渠道发布流程;
- iOS 发版流水线,实现 iOS 完整的发版流程。
如对于编译打包流程,主要包含:获取源代码信息、编译打包和通知测试人员测试三个功能模块,将这三个功能串联起来,我们便得到了一条完整的【编译打包流水线】:

原子服务
原子服务(Atomic Service)是流程中各项功能的抽象,一个原子服务可以通过参数化的方式来灵活实现一个特定的功能,而流水线则可以看作是对原子服务的编排。针对上文所述的多条流水线,我们抽象出了实际需要用的原子服务主要有:
- 代码源设置服务,实现代码源配置功能;
- 编译打包服务,实现 Jenkins 编译打包功能;
- 企业微信群通知服务,实现企业微信群通知功能;
- 卡点服务,基于企业微信应用实现投票和审核功能;
- 代码质量检测服务,基于 SonarQube 实现代码质量检测功能;
- 自动放量服务,基于七猫升级平台实现小渠道和全渠道自动放量功能;
- AB 测试服务,基于七猫 AB 后台实现 AB 测试功能。
对于上文示例的【编译打包流水线】,我们使用到的原子服务包括:代码源设置服务、编译打包服务和企业微信群通知服务。
原子服务需要实现一组预定义好的接口,使用这个接口(atomic.Service)我们可以统一原子服务的行为方式,以便流水线有能力对原子服务进行编排。抽象后的原子服务接口大致如下:
package atomic
type Service interface {
// Prepare 运行前准备
Prepare()
// GetName 返回原子服务预定义名称
GetName() string
// 运行前置处理
BefereRun()
// Run 运行服务
Run()
// Status 查看服务运行状态
Status()
// Stop 停止服务
Stop()
}
构建与阶段
一次构建(Build)就是一次流水线的运行实例。构建包含了流水线运行参数、上下文信息、状态及输出的制品信息等。阶段(Stage)与流水线中的原子服务一一对应。原子服务是模板,阶段则是构建过程中原子服务的实例,包含了原子服务运行所需参数、状态、运行结果等信息。
流水线流程
上文提到,流水线是对原子服务的编排,根据业务梳理出来的流程,我们可以通过 YAML 或 JSON 来配置编排内容,比如对于【编译打包流水线】,我们使用 YAML 格式进行编排如下:
- atomic_id: 0
repo_branch: origin/develop
repo_url: git@gitlab.com:android.git
stage_key: source_code
stage_name: 代码源
- atomic_id: 1
platform: android
server_url: https://jenkins-dev123.qimao.com
server_user: user
server_password: password
job_name: 七猫DevOps专用
trigger_token: trigger_token
stage_key: jenkins_build
stage_name: Android Jenkins 构建
- atomic_id: 2
stage_key: wecom_service_notify
stage_name: 企业微信服务通知
我们可以看到,流水线中包含了三个阶段:
- atomic_id 为 0 表示代码源配置服务,主要包含了代码仓库地址和默认分支设置;
- atomic_id 为 1 表示编译打包服务,主要包含了触发 Jenkins 构建编译打包所需要的参数;
- atomic_id 为 2 表示企业微信通知服务,具体的通知参数需要在构建时进行输入。
有了编排配置之后,我们在实际触发流水线时,还需要传入必要的构建参数,结合这些构建参数,在调用流水线触发接口后,将通过如下图所示的流程运行流水线,这个过程对应了一次流水线构建。
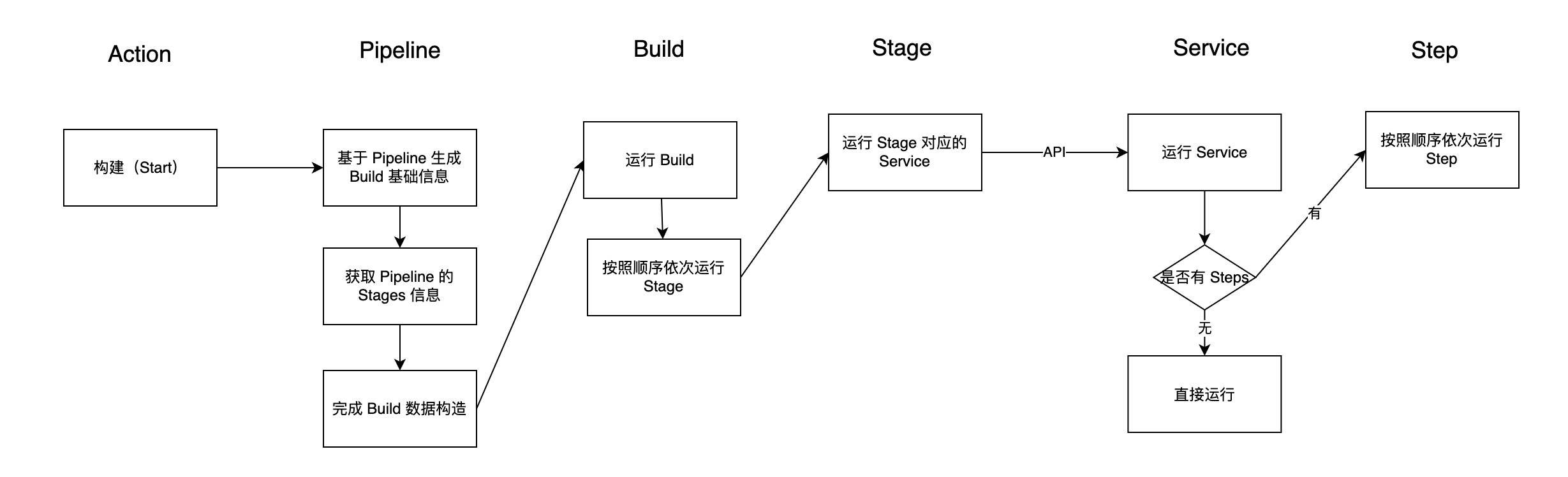
对于【编译打包流水线】来说,具体的执行逻辑如下所示:

通过定义上述原子服务与编排配置,我们只需要在执行构建时将每个原子服务(阶段)需要的参数(上下文信息)通过配置进行整合,就可以通过实现以下方式执行不同流水线了:
package build
func running(ctx *Contex) error {
// 预处理逻辑
ptr := ctx.stageList.Head // stageList 为双向链表结构
for ptr != nil {
if err := stageRun(ptr, ctx); err != nil {
fmt.Println(err)
break
}
ptr = ptr.GetNext()
}
// 后置处理逻辑,如判断流水线是否结束等
}
func stageRun(s stage.Stage, ctx *Context) error {
defer ctx.flush()
s.BeforeRun(ctx.stageList)
return s.Run()
}
运行结果数据 YAML 详情示例如下:
build_log_id: 393
build_num: 214
key: build:ua:1:393
notify_to: 张三
pipeline_id: 1
stages:
- atomic_id: 0
build_log_id: 393
build_num: 214
pipeline_id: 1
repo_branch: origin/develop
repo_url: git@gitlab.com:android.git
run_status: 3
stage_key: source_code
stage_name: 代码源
trigger_mode: 手动触发
- artifacts: |
download:
- jenkins_url: https://jenkins-dev123.qimao.com/job/七猫DevOps专用/200/artifact/grabhttpspackage.apk
name: grabhttpspackage.apk
url: https://artifacts123.oss-cn-beijing123.aliyuncs.com/grabhttpspackage.apk
atomic_id: 1
build_log_id: 393
build_notify_to: 李四
build_num: 214
build_type: grabhttp
job_name: 七猫DevOps专用
ori_log_url: https://jenkins-dev123.qimao.com/job/七猫DevOps专用/200/consoleFull
pipeline_id: 1
platform: android
pod_repo_update: 0
remark: 演示
repo_branch: origin/develop
repo_url: git@gitlab.com:android.git
run_log_file_path: https://artifacts123.oss-cn-beijing123.aliyuncs.com/ae76341871c7b8121836f855574cacc1.log
run_status: 3
server_password: password
server_url: https://jenkins-dev123.qimao.com
server_user: user
stage_key: stage-key
stage_name: Android jenkins 构建
status_key: 3df1534b-77c6-4bd2-ad12-1f437ededd73
stop_notified: false
trigger_mode: 手动触发
trigger_name: 张三
trigger_token: trigger-token
version: "1.1"
- atomic_id: 2
build_log_id: 393
build_num: 214
notified: true
notify_to: 张三,李四,王五
pipeline_id: 1
run_status: 3
stage_key: wecom_service_notify
stage_name: 企业微信服务通知
status: 3
stopper: ""
trigger: 张三
trigger_mode: 1
trigger_notified: true
总结与扩展
本文概述了七猫手机客户端 DevOps 流水线设计与实现思路,整体看下来非常简单,这主要得益于流水线这一模型本身非常强大且富有生命力,我们在 Web Service,云计算,以及大数据的流式计算等身上都看到了这一思维模型。
流水线(Pipeline)也常译成管道,最开始是道格·麦克罗伊(Doug McIlroy)发明了 Unix 管道这一概念:让数据像水管一样流动,把若干个命令串起来,前面命令的输出成为后面命令的输入,如此完成一个流式计算。管道是一个伟大的发明,它的设哲学就是 KISS – 让每个模块只做一件事,并把这件事做到极致,软件或程序的拼装会变得更为简单和直观。
七猫客户端 DevOps 流水线的设计就是遵循 Unix 管道的理念,将业务功能封装成独立的原子服务,通过业务流程将原子服务进行串联,从而能够动态的拼装业务流程,快速建立新的流水线。希望通过本文对客户端 DevOps 流水线的设计与实现的介绍,能够给大家的日常开发工作带来一些启发。