1、背景
有时候我们想知道项目里面各个api的qps和耗时,或者请求第三方服务的qps、成功率、失败率等等。统计这个其实有很多方案,比如:
- envoy:可以从网络层统计(运维已支持),但是不支持业务自定义统计
- sls:pod日志接sls日志系统也能统计,目前部分项目已支持但仅有部分日志,比较耗资源,可视化支持较差
- Prometheus:支持多种监控指标,搭建简单,支持业务自定义统计,可视化支持较好
经过讨论之后,我们决定使用Prometheus,然后在运维平台的grafana中接入,再画出需要的图。本文简单的介绍下大致的流程。
2、项目里面接入Prometheus的监控指标
2.1 什么是Prometheus?
prometheus是一款开源系统监控和警报工具包,基于metric采样的监控,可以自定义监控指标,定时拉取数据,存储到一个时间序列数据库中,之后可通过PromQL语法查询。主要有以下特点:
- 多维数据模型,时间序列数据通过metric名以key、value的形式标识;
- 使用PromQL语法灵活地查询数据;
- 不需要依赖分布式存储,各服务器节点是独立自治的;
- 时间序列的收集,通过 HTTP 调用,基于pull 模型进行拉取;
- 通过push gateway推送时间序列;
- 通过服务发现或者静态配置,来发现目标服务对象;
- 多种绘图和仪表盘的可视化支持,以及报警;
2.2 接入Prometheus包
通过go get 命令安装相关依赖库,示例如下:
go get github.com/prometheus/client_golang/prometheus
go get github.com/prometheus/client_golang/prometheus/promhttp
首先在程序中加入如下代码,注册http服务,暴露端口和提供数据的路由地址
import (
"github.com/prometheus/client_golang/prometheus/promhttp"
"net/http"
)
func main() {
go func() {
http.HandleFunc("/_/metrics", promhttp.Handler().ServeHTTP)
_ = http.ListenAndServe(":6060", nil)
}()
}
运行程序,然后在浏览器中打开地址:http://localhost:6060/_/metrics,可以看到初始的metric数据,如下
go_gc_duration_seconds{quantile="0"} 5.8723e-05
go_gc_duration_seconds{quantile="0.25"} 5.8723e-05
go_gc_duration_seconds{quantile="0.5"} 0.000145591
go_gc_duration_seconds{quantile="0.75"} 0.000145591
go_gc_duration_seconds{quantile="1"} 0.000145591
go_gc_duration_seconds_sum 0.000204314
go_gc_duration_seconds_count 2
go_goroutines 10
......
go_info{version="go1.17.11"} 1
go_memstats_sys_bytes 1.9090192e+07
go_threads 11
promhttp_metric_handler_requests_in_flight 1
promhttp_metric_handler_requests_total{code="200"} 0
promhttp_metric_handler_requests_total{code="500"} 0
promhttp_metric_handler_requests_total{code="503"} 0
- go_* 为前缀的指标是关于Go运行时相关的指标,比如垃圾回收时间、goroutine数量等,其他语言的客户端库也会暴露各自语言特有的运行时指标。
- promhttp_* 为promhttp 工具包的相关指标,用于跟踪对指标请求的处理。
2.3 添加业务所需要的自定义指标
Prometheus有4个指标,具体如下:
- Gauges(仪表盘):表示一个能够任意变化的指标,可增可减。
- Counters(计数器):表示一个累积的指标数据,只增不减,除非监控系统发生了重置。
- Histograms(直方图):在客户端把采集到的数据放到配置的bucket中,然后在服务端侧使用 histogram_quantitle() 函数通过区间来计算分位数;客户端性能低,服务端性能高,可支持聚合。
- Summaries(摘要):客户端侧计算分位数,直接存储采集到的数据;客户端性能高,服务端性能低,不支持聚合;
由于我们项目有多个pod,需要聚合数据,所以选择Histograms指标。下面简单的封装下代码:
// HistogramVec 初始化全局变量
var HistogramVec = &histogram{
mu: &sync.RWMutex{},
store: make(map[string]interface{}),
}
// 定义结构体
type histogram struct {
mu *sync.RWMutex
store map[string]interface{}
}
// gen 通过label的方式,动态创建对象并注册
func (h *histogram) gen(name string, labels []string) interface{} {
# 加锁,避免重复创建对象
h.mu.RLock()
if v, ok := h.store[name]; ok {
h.mu.RUnlock()
return v
}
h.mu.RUnlock()
h.mu.Lock()
opts := prometheus.HistogramOpts{
Name: name, // 指标名称
Buckets: []float64{0.05, 0.1, 0.5, 1, 2}, // 根据实际要求定义buckets,默认单位是秒
}
# 创建对象
histogramVec := prometheus.NewHistogramVec(opts, labels)
# 注册服务
_ = prometheus.Register(histogramVec)
h.store[name] = histogramVec
h.mu.Unlock()
return histogramVec
}
// Observe 通过label的方式,写入自定义指标
func (h *histogram) Observe(name string, kv map[string]string, startAt time.Time) {
var (
lbNames, lbValues []string
timeSub = time.Now().Sub(startAt).Seconds()
)
for k := range kv {
lbNames = append(lbNames, k)
}
sort.Strings(lbNames)
for i := range lbNames {
lbValues = append(lbValues, kv[lbNames[i]])
}
v := h.gen(name, lbNames)
if v != nil {
vv := v.(*prometheus.HistogramVec)
vv.WithLabelValues(lbValues...).Observe(timeSub)
}
}
需要注意的是要合理设置buckets的值,因为会把http请求,按照耗时分布在对应的bucket中(默认时间单位是秒),比如0.05s内完成的请求,会放在第一个bucket中;0.1s内完成的请求,会放在第二个bucket中,以此类推... 而服务端是通过bucket的区间来计算分位数画图的,所以所以bucket的粒度太大、或者太小都会影响准确度。可以参考官方的辅助函数prometheus.LinearBuckets() 和prometheus.ExponentialBuckets() 生成bucket。
下面启动http服务,然后添加自定义指标,代码如下:
// 获取gin实例
r := gin.Default()
// 中间件,监控每个路由
r.Use(func(c *gin.Context) {
startAt := time.Now()
c.Next()
// 自定义指标的名称
HistogramVec.Observe("http_request", map[string]string{
"api": c.Request.URL.Path, // 每个路由的地址
"status": strconv.Itoa(c.Writer.Status()), // 当前路由返回的http状态值
}, startAt)
})
// 路由1,http返回200
r.GET("/api/t1", func(c *gin.Context) {
// 随机返回http状态值,测试组合指标
status := []int{http.StatusOK, http.StatusUpgradeRequired,,http.StatusInternalServerError}
index := rand.Intn(len(status))
c.JSON(http.StatusOK, gin.H{"a": "11"})
})
// 路由2,http返回非200
r.GET("/api/t2", func(c *gin.Context) {
// 随机延迟,测试耗时
rt := rand.Intn(1000)
time.Sleep(time.Millisecond * time.Duration(rt))
c.String(http.StatusInternalServerError, "pong")
})
// 启动程序
_ = r.Run(":8080")
运行命令go run main.go 启动程序,然后请求接口
curl http://localhost:8080/api/t1
curl http://localhost:8080/api/t1
curl http://localhost:8080/api/t1
curl http://localhost:8080/api/t2
curl http://localhost:8080/api/t2
curl http://localhost:8080/api/t2
然后在浏览器中打开地址:http://localhost:6060/_/metrics,可以看到刚刚添加的metric数据(http_request_*前缀,http_request为前面定义的值), 如下:
http_request_bucket{api="/api/t1",status="200",le="0.05"} 1
http_request_bucket{api="/api/t1",status="200",le="0.1"} 1
http_request_bucket{api="/api/t1",status="200",le="0.5"} 1
http_request_bucket{api="/api/t1",status="200",le="1"} 1
http_request_bucket{api="/api/t1",status="200",le="2"} 1
http_request_bucket{api="/api/t1",status="200",le="+Inf"} 1
http_request_sum{api="/api/t1",status="200"} 5.5298e-05
http_request_count{api="/api/t1",status="200"} 1
http_request_bucket{api="/api/t1",status="500",le="0.05"} 2
http_request_bucket{api="/api/t1",status="500",le="0.1"} 2
http_request_bucket{api="/api/t1",status="500",le="0.5"} 2
http_request_bucket{api="/api/t1",status="500",le="1"} 2
http_request_bucket{api="/api/t1",status="500",le="2"} 2
http_request_bucket{api="/api/t1",status="500",le="+Inf"} 2
http_request_sum{api="/api/t1",status="500"} 0.00012158700000000001
http_request_count{api="/api/t1",status="500"} 2
http_request_bucket{api="/api/t2",status="500",le="0.05"} 0
http_request_bucket{api="/api/t2",status="500",le="0.1"} 2
http_request_bucket{api="/api/t2",status="500",le="0.5"} 3
http_request_bucket{api="/api/t2",status="500",le="1"} 3
http_request_bucket{api="/api/t2",status="500",le="2"} 3
http_request_bucket{api="/api/t2",status="500",le="+Inf"} 3
http_request_sum{api="/api/t2",status="500"} 0.46105082500000005
http_request_count{api="/api/t2",status="500"} 3
可以看到api和status两个参数值组合的数据,最后一列为累计计数,后缀*_bucket 为各个bucket的计数,后缀 _sum 为累积总和,后缀 _count 为累计计数。如果label越多,生成的指标也会越多,所以应该控制下数量,否则内存会暴增。
3、采集项目中的metrics数据
3.1 通过ServiceMonitor创建服务发现
因为我们项目是部署在阿里云的k8s集群中,所以使用他们的ServiceMonitor服务创建自定义服务发现,会主动采集各个pod里面的metric数据,并存储。
准备工作:需要运维同学先配置好相关基础依赖,然后在k8s集群中部署好项目(目前已直接支持)。
首先需要先创建一个Service服务,yaml配置如下:
apiVersion: v1
kind: Service
metadata:
name: demo-metrics-service # 自定义服务名字
namespace: default # 命名空间
labels:
app: demo-metrics-service # 自定义服务名字
spec:
selector:
app: http-deployment-name # 对应Deployment服务名称
ports:
- name: demo-metrics-ports # 自定义服务端口名字
port: 6060 # 上面http服务中暴露的Prometheus端口
protocol: TCP
targetPort: 6060
再创建ServiceMonitor服务,yaml配置如下:
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
name: demo-monitor-name # 自定义monitor服务名字
namespace: default # 命名空间
spec:
endpoints:
- interval: 30s # Prometheus对当前pod采集的周期,每隔30s拉取一次数据
path: /_/metrics # 采集路径,即上面http服务中定义的路由地址
port: demo-metrics-ports # 上面自定义服务端口名字
namespaceSelector:
matchNames:
- default # 命名空间
selector:
matchLabels:
app: demo-metrics-service # 上面自定义服务名字
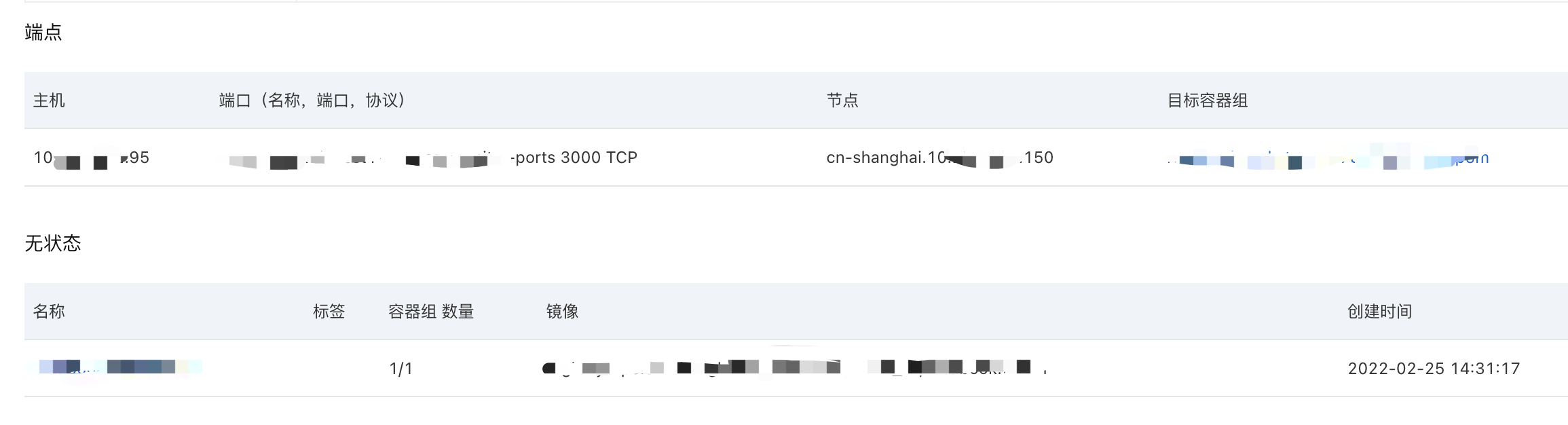
然后在k8s中部署好。在服务中,可以看到刚刚配置好的服务,并且能关联对应pod,表示成功,如下图所示:
3.2 也可以自己手动搭建Prometheus服务
如果项目是单独部署在ECS上,也可以考虑从官网https://prometheus.io/download/ 下载包,自己安装Prometheus server,然后在配置文件prometheus.yml中添加node_exporter(即监控地址)配置(采集的数据默认以文件形式存储在本地),配置如下:
scrape_configs:
# 添加需要收集机器的监控数据,可以添加多个节点
- job_name: 'prometheus-node'
metrics_path: '/_/metrics' #采集路径
static_configs:
- targets: ['127.0.0.1:6060'] #需要采集的地址
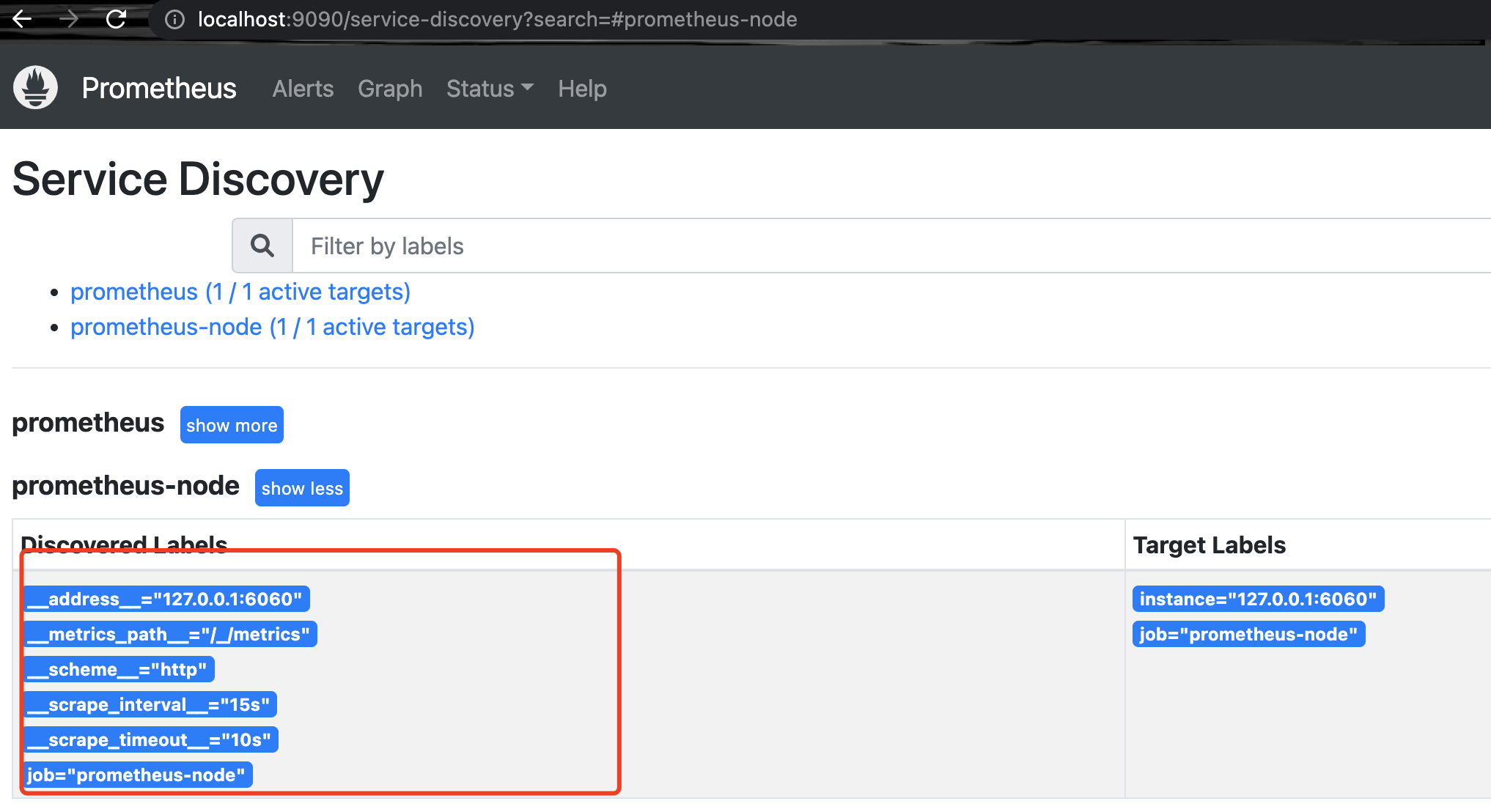
然后再重启Prometheus服务,就可以在可视化界面(比如http://localhost:9090) 查看到相应监控内容。如下图所示,表示成功。
4、grafana上画图
指标数据有了,也能采集到了,那么接下来需要将指标数据可视化。Prometheus自带UI其实也是可视化的,但其功能较为简单、无法实时关注相关监控指标的变化趋势,所以我们选择Grafana作为可视化的解决方案。
4.1 什么是grafana?
Grafana是一个跨平台的开源的度量分析和可视化工具,可以通过将采集到的数据查询再可视化展示出来,并及时报警通知。UI灵活,有丰富的插件,功能强大,主要有以下特点:
- 展示方式:快速灵活的客户端图表,面板插件有许多不同方式的可视化指标和日志,官方库中具有丰富的仪表盘插件,比如热图、折线图、图表等多种展示方式;
- 数据源:支持许多不同的数据源,每个数据源都有一个特定的查询编辑器,该编辑器支持对应数据源的查询语法,常用的数据源有:Prometheus,Elasticsearch,MySQL,PostgreSQL等
- 通知提醒:以可视方式定义重要指标的警报规则,在数据达到阈值时发送通知;
- 混合展示:在同一图表中混合使用不同的数据源,可以基于每个查询指定数据源;
4.2 安装并设置数据源
这一步运维同学已经弄好,可直接使用了。这里再简单的介绍下,从官网https://grafana.com/grafana/download 下载安装并安装好,默认是3000端口。启动grafana服务,在浏览器中输入:http://localhost:3000 即打开了grafana的界面。点击左边的设置符号,会出现如下选项

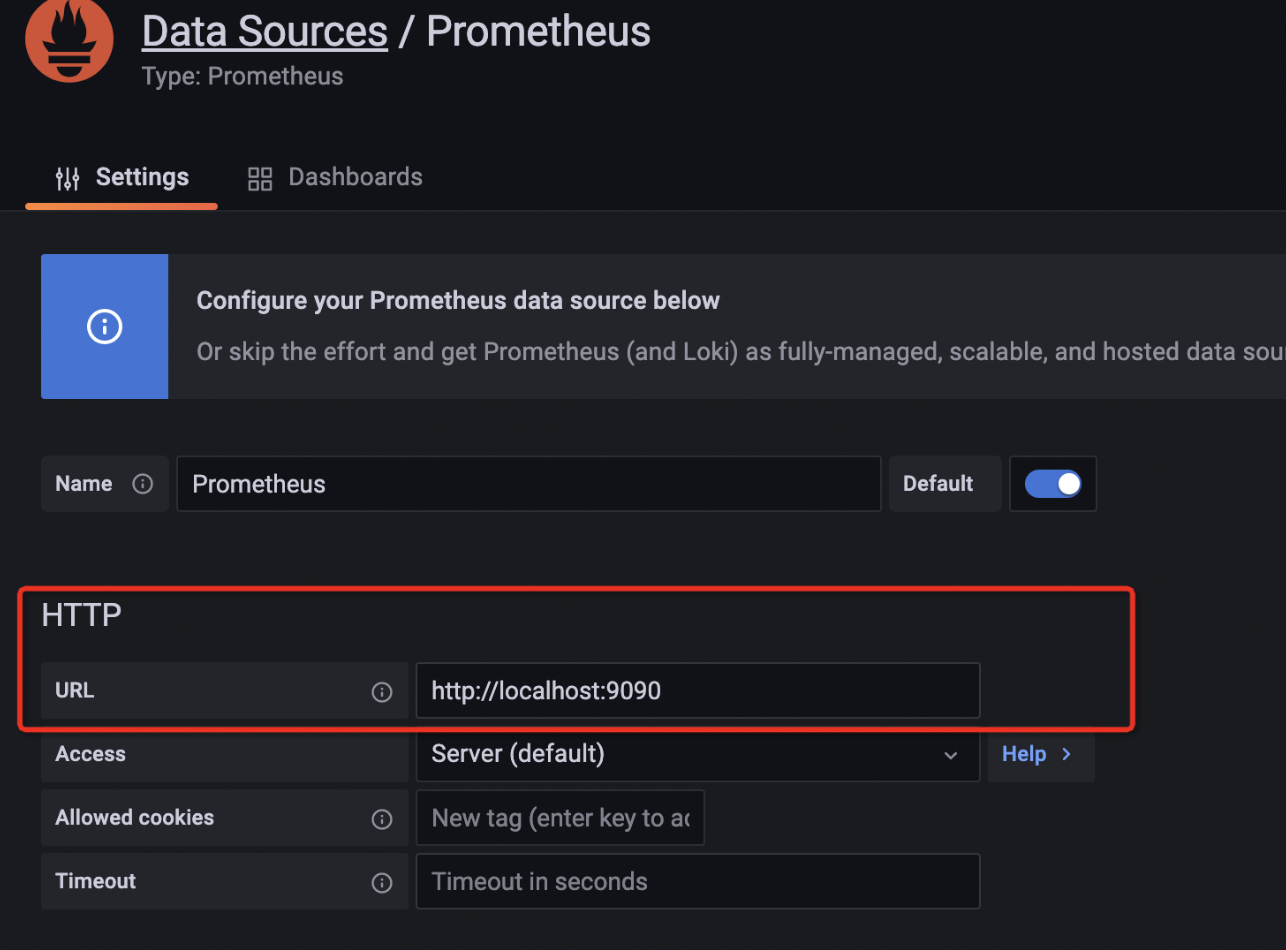
点击Data Sources选择数据源,这里选择prometheus数据源,然后点击进入数据源的配置页面,在url处填写prometheus server的服务器地址,即上面手动搭建prometheus server时使用的9090端口,如下:
配置好数据源后,然后点击左侧的dashboard选项,新建一个dashboard控制面板,就是我们项目的控制面板,也可以新建分组等。
4.3 创建panel
在建好的控制面板中,新建一个panel,可以自定义选择图形,这里我们使用了默认的Time series图,来显示api接口的qps,如图所示:
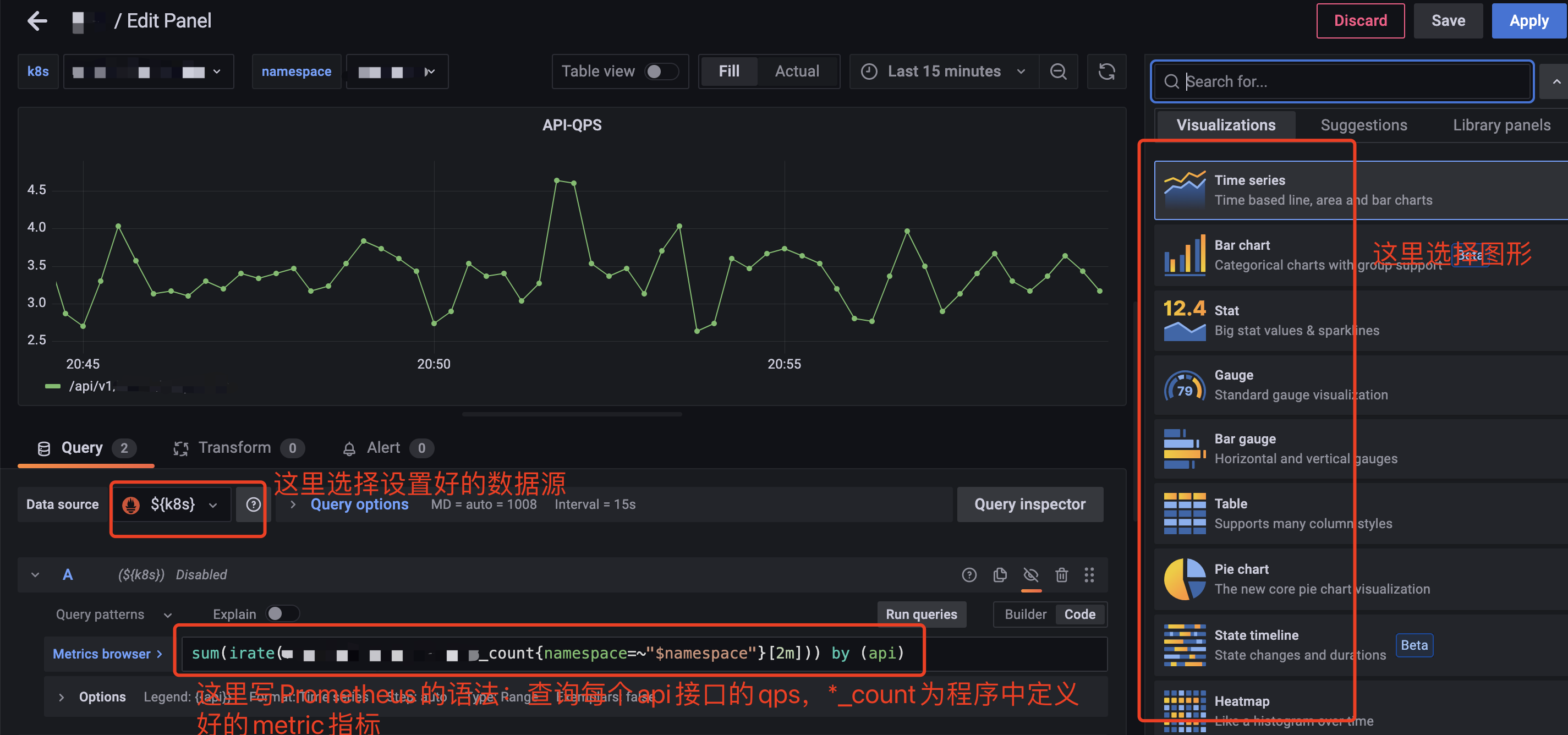
查询的Prometheus语法可根据需要,再自定义编写。比如下图所示,查询的是各个接口返回http状态为200的p99耗时。
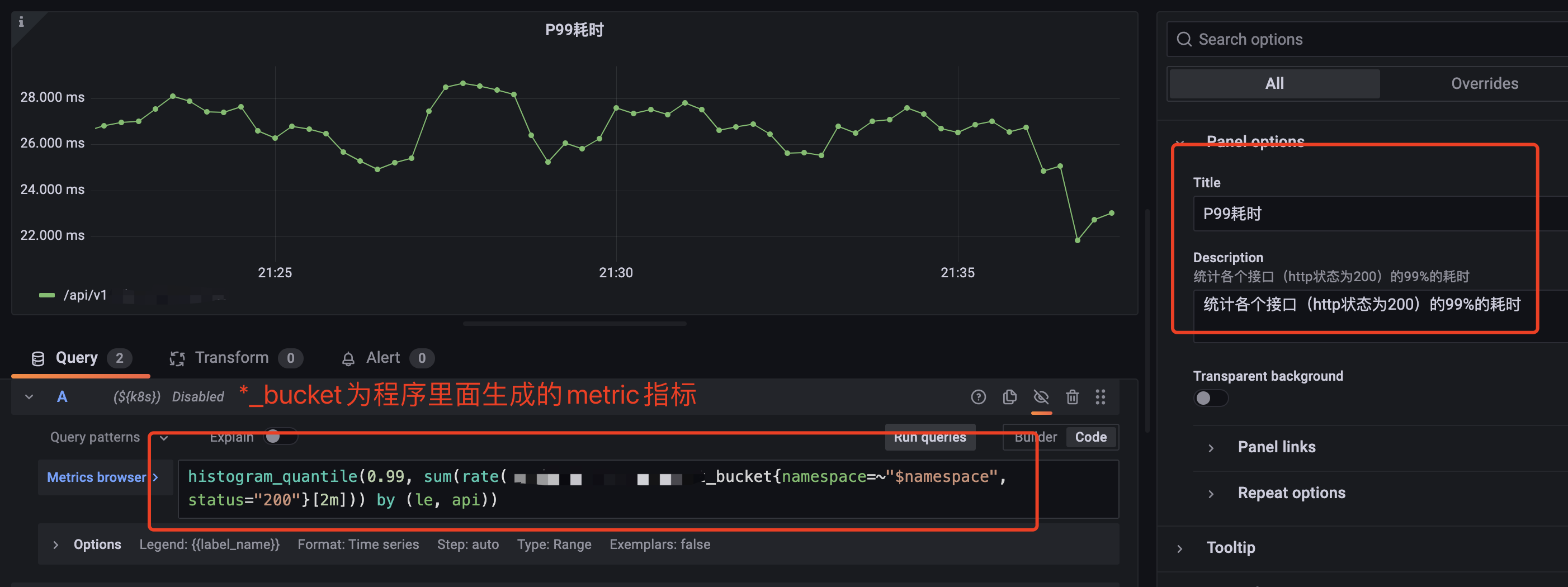
如果不确定想要啥图形,或者不知道查询语法怎么写。可以去Grafana官网下载Dashboard模板:https://grafana.com/grafana/dashboards/,搜索数据源为Prometheus的模块,把下载的json文件导入就可以了,很方便。
4.4 添加报警Alert Manager
报警分为两部分:在prometheus server中添加报警规则并将报警传递给alert manager;然后alert manger再将报警发送消息通知,比如:钉钉、邮件、企业微信等。这部分当然也是运维同学配置好了,有兴趣的可以查看官方的配置文档:https://grafana.com/docs/grafana/v9.3/alerting/ 。然后我们在刚刚创建好的panel中点击alert创建报警规则,比如:每隔5分钟检测一次,平均耗时超过多少的,并且持续1分钟才发送报警,如图:
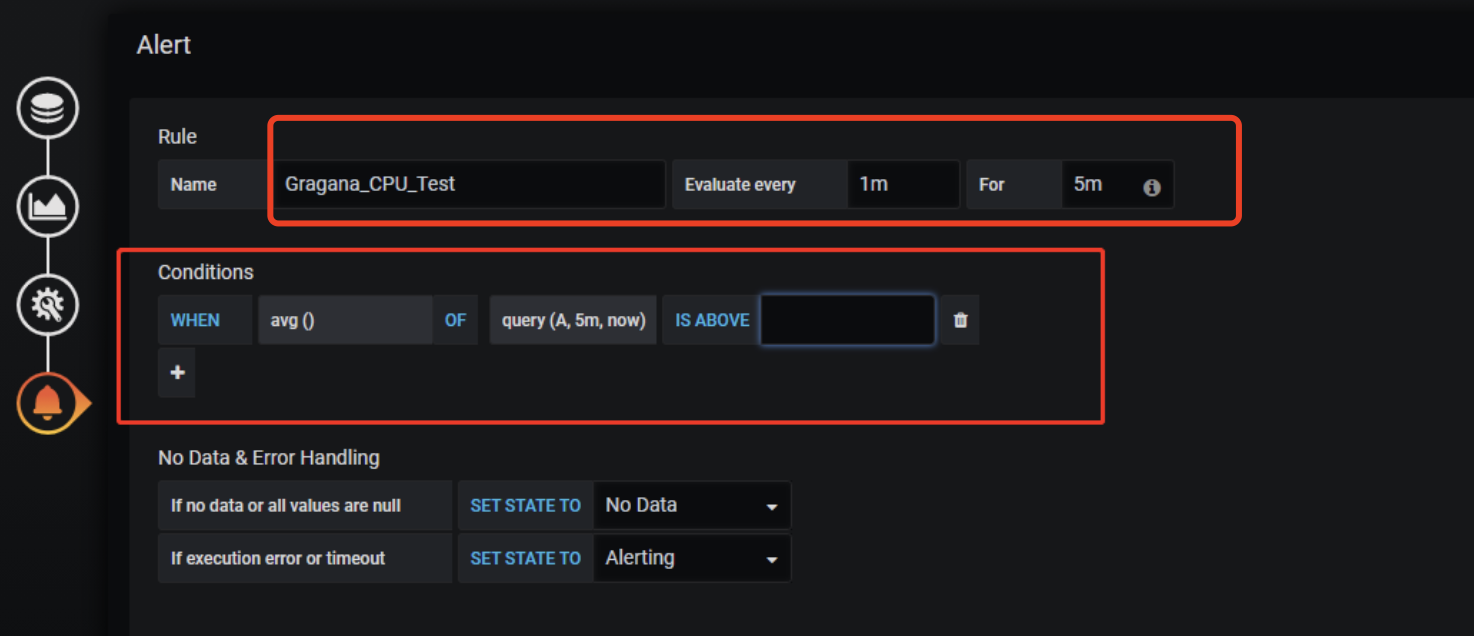
然后再选择报警通知的方式(运维已配置好的)。
5、总结
以上,简单的介绍了golang + Prometheus + grafana整个流程,属于抛砖引玉,实际项目中的使用会比这复杂些。有了这套监控,我们可以随时查看项目的情况,比如:线上机器的负载等系统指标,业务中需要知道的数据等。印象比较深刻的是,有一次云书架改版升级,某个接口的qps从最开始的八百多,到两千多,再到新接口的六七千。从曲线图上很直观的看到了qps的变化,以及接口耗时的增加;然后进行一系列的业务降级,及数据库升配等操作,期间也灵活的临时添加了其他辅助业务的统计, 通过持续观察及对比这些指标,再配合其他资源负载情况,我们可以很容易知道当前项目的负载情况。
需要特别注意的是,Histograms指标写入的label参数最好是固定的几个值,如果值是动态的或者很多的话,内存可能会溢出(已踩过坑)。