一、前言
ANR 问题一直是 Android 性能优化的重点问题,当主线程消息调度不及时或者执行耗时方法时轻则造成卡顿,重则发生ANR,严重影响用户的体验。故而分析发生ANR时主线程在过去一段时间内调度的消息和执行的方法无疑是定位ANR原因的突破口,基于这两点,我们开发了一套主线程消息调度耗时采集和耗时方法采集工具,本文便是阐述相关的原理和实现。
二、主线程消息调度耗时采集
主线程消息调度耗时采集主要是基于Android的消息分发机制,通过代理系统方法对每条消息的开始和结束进行跟踪并记录该条消息的内容以及耗时,随后将不同耗时的消息进行聚合分组并上报分析。一般情况下发生ANR前30s的长耗时消息具有较大的价值,同时为了减小性能损耗以及方便后续查看,我们将多条消息累计耗时达到300ms记录为一组,在整个app运行过程中总共会记录100组消息,同时新的消息记录会覆盖最老的那组消息,这样我们便可以实时记录最近30s内执行的消息(多数情况下总记录时长会大于30s)。当然除了记录发生ANR前的历史消息,发生ANR时正在执行的消息以及消息队列中还未执行的消息也需要进行记录,这样我们便掌握了主线程消息调度的过去、现在和未来,当发生ANR时,我们便可以将这些内容输出到文件中上报至性能监控平台进行分析,以下对具体实现展开说明。
1、消息分发机制
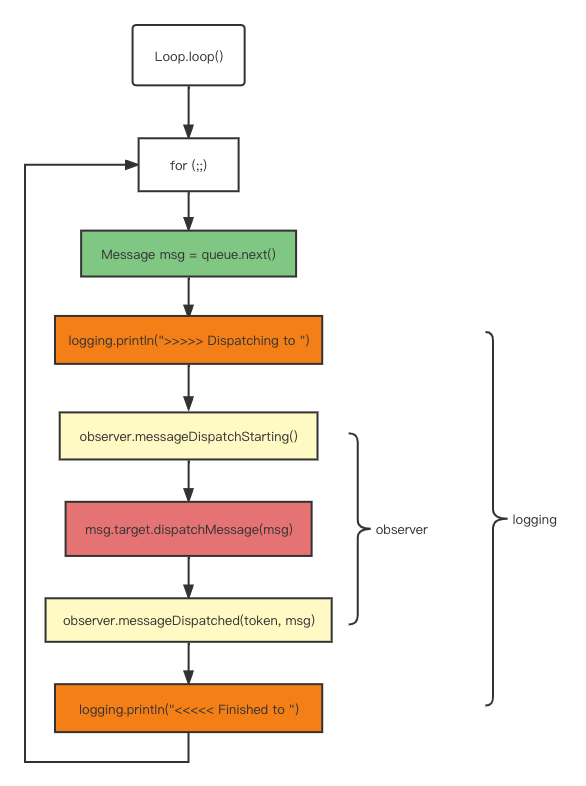
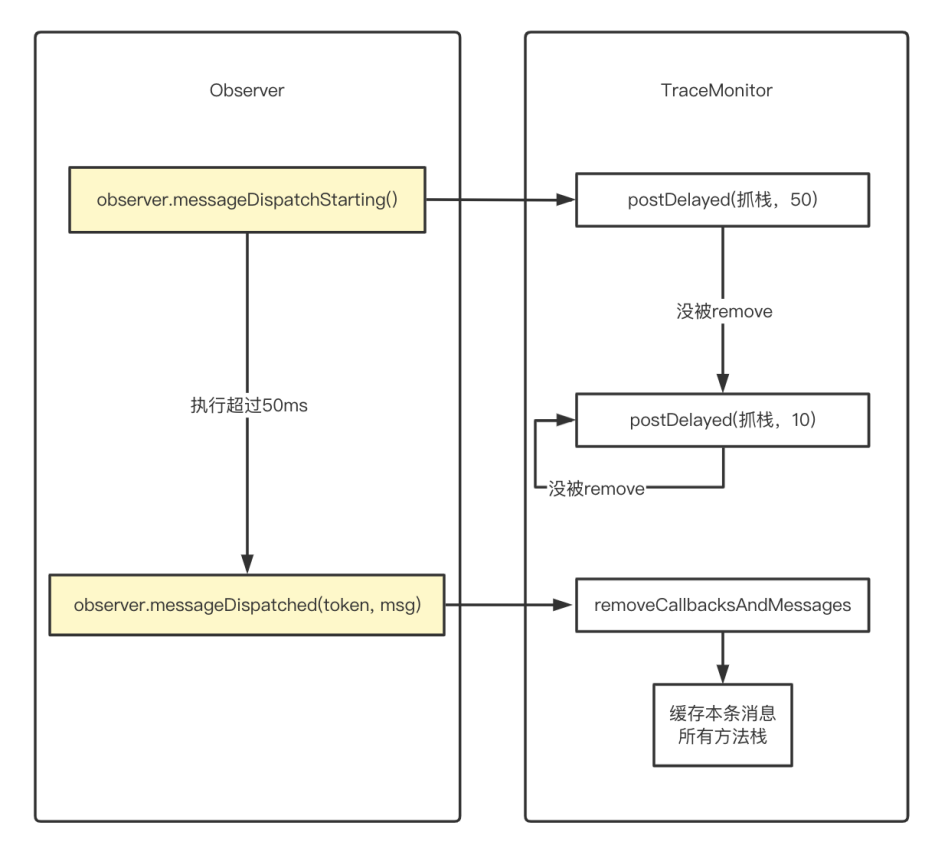
这里的消息分发机制利用到的关键类是Looper,Looper中的loop方法内部for死循环不断的通过MessageQueue拿消息,拿到消息之后在消息执行之前会去调用Printer.println和observer.messageDispatchStarting,同样在消息执行完成之后会调用Printer.println和observer.messageDispatched(这里的observer是Android 10新增的),且messageDispatched方法参数为当前消息对象,我们可以从中获取到消息的具体内容。利用这两对方法便可以实现对消息的跟踪和记录消息的内容以及耗时。
public final class Looper {
private static Observer sObserver;
@UnsupportedAppUsage
private Printer mLogging;
public static void loop() {
...
for (;;) {
Message msg = queue.next(); // might block
...
if (logging != null) {
logging.println(">>>>> Dispatching to " + msg.target + " " + msg.callback + ": " + msg.what);
}
...
Object token = null;
if (observer != null) {
token = observer.messageDispatchStarting();
}
...
try {
msg.target.dispatchMessage(msg);
if (observer != null) {
observer.messageDispatched(token, msg);
}
...
}
...
if (logging != null) {
logging.println("<<<<< Finished to " + msg.target + " " + msg.callback);
}
...
}
}
/** {@hide} */
public interface Observer {
Object messageDispatchStarting();
void messageDispatched(Object token, Message msg);
void dispatchingThrewException(Object token, Message msg, Exception exception);
}
}
通过反射代理Looper中的Observer和设置Printer
private void hookLooperObserver() {
if (Build.VERSION.SDK_INT != Build.VERSION_CODES.Q) {
return;
}
try {
Class Oclass = Class.forName("android.os.Looper$Observer");
ObserverInvercation invercation = new ObserverInvercation();
Object o = Oclass.cast(Proxy.newProxyInstance(Oclass.getClassLoader(), new Class[]{Oclass}, invercation));
Class loop = Looper.class;
Field sObserver = loop.getDeclaredField("sObserver");
sObserver.setAccessible(true);
sObserver.set(getMainLooper(), o);
getMainLooper().setMessageLogging(invercation.printer);
} catch (ClassNotFoundException e) {
e.printStackTrace();
} catch (IllegalAccessException e) {
e.printStackTrace();
} catch (NoSuchFieldException e) {
e.printStackTrace();
} catch (Exception e) {
e.printStackTrace();
}
}2、消息聚合分组
消息聚合分组主要是根据消息的累计耗时情况进行分组记录,由于实际业务场景很多情况都是耗时较少的消息,这类消息对于排查问题基本可以忽略不计,同时我们更加关心耗时较长的消息,所以我们对这类耗时较短消息进行累计,达到一定阈值后将这些消息的数量和累计耗时合并成一条记录。而耗时较长的消息则记录其具体的内容、耗时以及等待时长。根据这个思路,可以分为三种情况:
1、累计耗时达到300ms内的所有消息耗时均小于50ms,则只记录消息数量以及累计的耗时。

2、累计耗时达到300ms内存在耗时>=50ms且<300ms的消息,则单独记录这些消息内容、耗时、等待时长,最后记录所有消息数量以及累计的耗时。
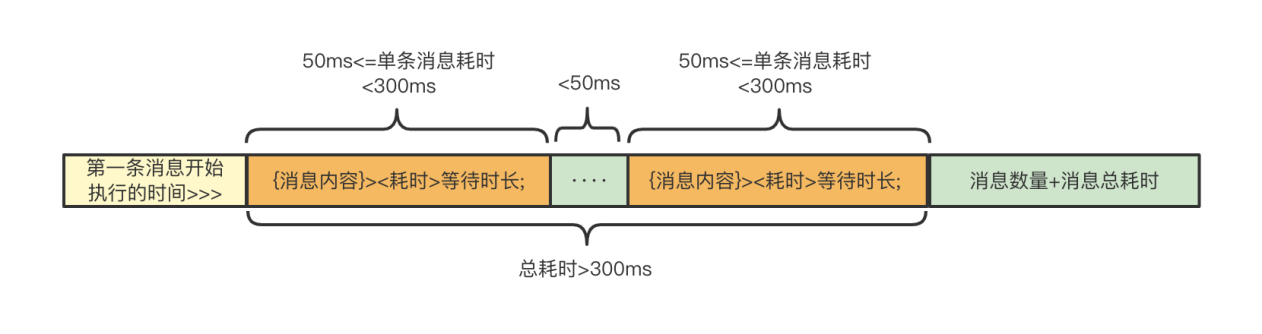
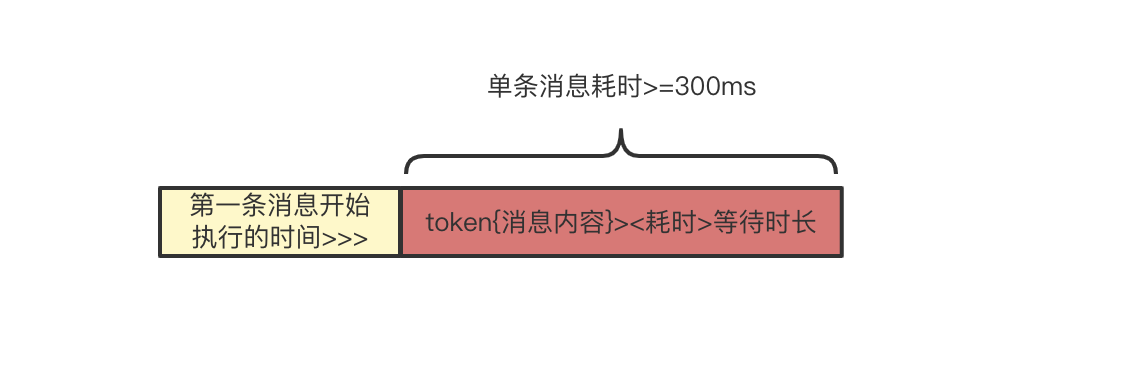
3、当单条消息耗时达到300ms,则将之前累计的消息聚合记录为一组,本条消息单独记录为一组,并记录其token。
public class ObserverInvercation implements InvocationHandler {
private static final AtomicLong atomicInteger = new AtomicLong(1);
private static int RECORD_ARRAY_SIZE = 100;
private static String[] messageRecord = new String[RECORD_ARRAY_SIZE];
private static StringBuilder stringBuilder = new StringBuilder();
private static long MESSAGE_WORK_TIME = 300;
private static long MESSAGE_WORK_TIME_50 = 50;
@Override
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
if (Looper.getMainLooper().isCurrentThread()) {
if ("messageDispatchStarting".equals(method.getName())) {
uptimeMillis = SystemClock.uptimeMillis();
long token = atomicInteger.getAndIncrement();
traceMonitor.startMsg(token);
return token;
}
if ("messageDispatched".equals(method.getName())) {
long token = (long) args[0];
traceMonitor.endMsg(token);
getTime((Message) args[1], token);
}
}
return null;
}
private void getTime(Message message, long token) {
long when = message.getWhen();//message 指定开始的时间,基于开机时间
long clock = SystemClock.uptimeMillis();//当前的时间,基于开机时间
long wait = uptimeMillis - when;//等待的时长 开始执行 - 指定开始
long work = clock - uptimeMillis;//执行的时长 当前时间 - 开始时间
if (record) {
saveMessageRecord(message, work, wait, transaction(message), uptimeMillis, token);
}
}
private void saveMessageRecord(Message message, long work, long wait, String transaction, long clock, long token) {
if (work >= MESSAGE_WORK_TIME) {
String msg = clock + ">>>" + token + message.toString() + ">" + transaction + "<" + work + ">" + wait;
if (messageCount == 0) {
messageRecord[currentIndex % RECORD_ARRAY_SIZE] = msg;
currentIndex++;
} else {
stringBuilder.append(messageCount).append("+").append(workTimeCount);
messageRecord[currentIndex % RECORD_ARRAY_SIZE] = stringBuilder.toString();
messageRecord[(++currentIndex) % RECORD_ARRAY_SIZE] = msg;
workTimeCount = 0;
messageCount = 0;
stringBuilder.setLength(0);
currentIndex++;
}
} else {
if (messageCount == 0) {
stringBuilder.append(clock).append(">>>");
}
messageCount++;
if (work > MESSAGE_WORK_TIME_50 || !TextUtils.isEmpty(transaction)) {
stringBuilder.append(message).append(">").append(transaction).append("<").append(work).append(">").append(wait).append(";");
}
workTimeCount += work;
if (workTimeCount >= MESSAGE_WORK_TIME) {
stringBuilder.append(messageCount).append("+").append(workTimeCount);
messageRecord[currentIndex % RECORD_ARRAY_SIZE] = stringBuilder.toString();
workTimeCount = 0;
messageCount = 0;
stringBuilder.setLength(0);
currentIndex++;
}
}
if (currentIndex > RECORD_ARRAY_SIZE) {
currentIndex = currentIndex % RECORD_ARRAY_SIZE;
}
}
}3、记录与分析
除了记录主线程历史消息调度及耗时之外,在app发生ANR时当前正在执行的消息以及消息队列中待调度的消息也可以给我们分析问题时提供更多线索。因此我们将这三块内容按一定的格式输出到一个文件中方便我们分析。文件内容从上到下分为三块:历史调度消息、当前执行消息、消息队列中待调度消息。我们分析消息的时,先看当前消息是否执行了很长时间,如果当前消息耗时较短,则从历史调度消息中查看是否有长耗时消息,若以上排查找到了长耗时消息,最后可以去看消息队列中是否有消息被阻塞了,通过以上排查便能初步定为到是否是长耗时消息导致了ANR,然后根据消息具体内容从业务和代码层面去定位修复。
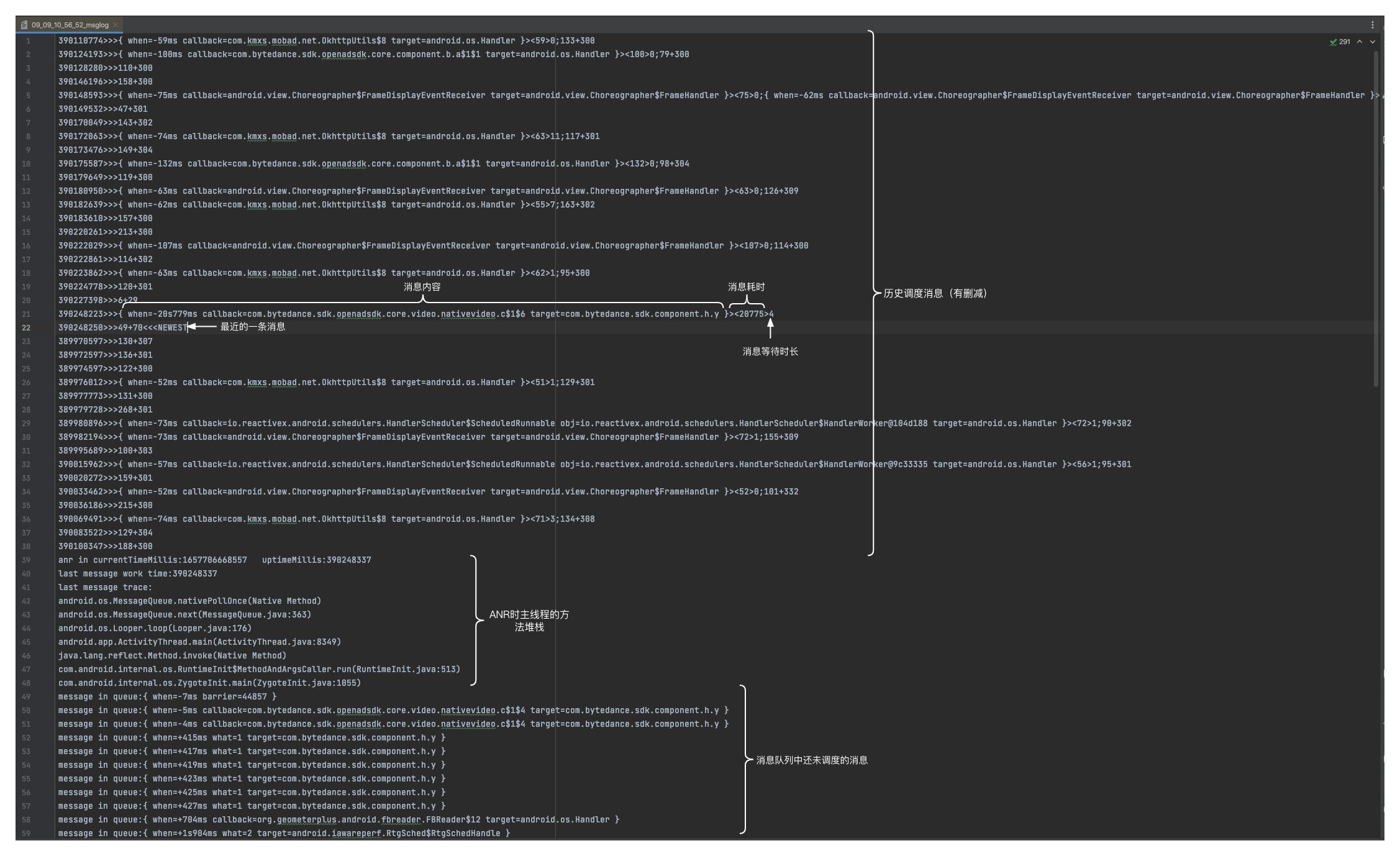
三、主线程耗时方法采集
通过以上内容我们初步定位到了导致ANR发生的消息,但是耗时消息动辄就有十多秒且内部执行了很多方法,对于排查问题提供的信息还是不够精确,如果我们能够知道这个消息调度过程中都执行的哪些方法以及它们的耗时,无疑对我们排查问题有巨大帮助。因此在前文的基础之上我们继续深入探索,从单条消息调度过程中的方法执行情况更细粒度的去定位问题。考虑到长耗时方法对排查此类问题更有价值以及尽量减小工具对性能带来的影响,我们采用采样的方式来对方法耗时进行采集。具体思路是:在每个消息开始执行时,触发子线程的超时监控,如果在超时之后本次消息还没执行结束,则对主线程以一定的时间间隔进行抓栈,直到该条消息执行完毕,抓栈完毕之后根据消息耗时在过滤掉少于1s(耗时较少)的方法堆栈。接下来我们看一下具体的实现。
1、耗时消息监控
通过启动一个工作线程监听主线程的消息调度,当发现主线程单条消息执行时间超过既定阈值(50ms)时,工作线程便开始每间隔一段时间(10ms)去抓取主线程的方法堆栈并缓存到集合中直到当前消息执行完成,随后根据方法堆栈集合的大小来判断当前记录的整个消息的耗时是否为长耗时消息,耗时时间为50ms+集合大小*10ms,这里定义集合大小达到95(总计1000ms)即为较长耗时消息。为了减小对内存的占用,将满足较长耗时消息的方法处理成树形结构后缓存至队列中,整个过程仅缓存最近的10组数据。
public class TraceMonitor {
private HandlerThread thread;
private Handler handler;
private Thread mainThread;
private long threadPeer;
private static long curToken; //当前message的token
public static int poolSize = 10; //缓存大小
private static long minDelayMills = 50; //执行大于50ms的消息开始抓栈
private static long delayMills = 10; //抓栈间隔
private static long minCount = 95; //抓栈次数,只保存大于这个次数的方法栈。方法耗时约 = delayMills * minCount + 50
private static boolean stop = false;
private static List<String[]> curTraces = Collections.synchronizedList(new LinkedList<>());
private static Queue<TraceInfo> allTraces = new LinkedList<>();
public TraceMonitor() {
thread = new HandlerThread("Thread-TraceMonitor");
thread.start();
handler = new Handler(thread.getLooper());
messageQueue = thread.getLooper().getQueue();
mainThread = Looper.getMainLooper().getThread();
threadPeer = Sliver.getThreadNativePeer(mainThread);
}
public void startMsg(long token) {
if (stop) return;
curToken = token;
handler.postDelayed(new TraceRunnable(token), minDelayMills);
}
class TraceRunnable implements Runnable {
long token;
public TraceRunnable(long token) {
this.token = token;
}
@Override
public void run() {
getMainThreadTrace(token);
}
}
private void getMainThreadTrace(long token) {
handler.postDelayed(new TraceRunnable(token), delayMills);
String[] stackTrace = Sliver.getStackTrace(mainThread, threadPeer);
add(token, stackTrace);
}
/**
* 保存方法栈
*/
private void add(long token, String[] trace) {
if (stop) return;
if (curToken != token) {
curToken = token;
curTraces.clear();
}
curTraces.add(trace);
if (curTraces.size() > 5000) {//防止OOM
stop = true;
}
}
public void endMsg(long token) {
if (stop) return;
handler.removeCallbacksAndMessages(null);
if (curTraces.size() >= minCount) {
try {
handler.post(new SaveTraceRunnable(token, new LinkedList<>(curTraces)));
} catch (Exception e) {
}
}
curTraces.clear();
}
}2、频繁抓栈处理
由于上述的堆栈抓取是采样的方式,因此采样间隔决定了数据的精确度,为了拿到相对准确的方法耗时数据,我们将抓栈间隔设置为10ms,因此抓栈还是较为频繁。这也引出了一个问题:Java获取调用栈的方法是Thread.getStackTrace(),这个方法在频繁调用时偶尔会出现 Crash。原因是系统抓栈方法内部逻辑是:通过SuspendThreadByPeer方法挂起线程 -> 生成调用栈 -> 恢复线程,而通过SuspendThreadByPeer每次挂起失败会检查一下是否超时,如果超时则会抛出 FATAL 异常。因此考虑到稳定性不可以直接使用Java提供的抓栈方法,从网上文章了解到可以使用SuspendThreadById而非SuspendThreadByPeer,SuspendThreadById功能同样是挂起线程,只不过是通过线程的 id 来挂起,而有一点不同是当线程挂起超时, ThreadSuspendByIdWarning 的 log 等级由 FATAL 变成了 WARNING,也就是仅仅打印 log,并不会崩溃。
SIGABRT:
#00 pc 000000000007066c /apex/com.android.runtime/lib64/bionic/libc.so (abort+160) [arm64-v8a::b91c775ccc9b0556e91bc575a2511cd0]
#01 pc 00000000004e0d60 /apex/com.android.runtime/lib64/libart.so (art::Runtime::Abort(char const*)+2512) [arm64-v8a::617b4481d2d525502ced0629cac33c57]
#02 pc 000000000000c600 /system/lib64/libbase.so (android::base::LogMessage::~LogMessage()+684) [arm64-v8a::7e6f8e823512d07994e0f2250d7d708b]
#03 pc 000000000053b23c /apex/com.android.runtime/lib64/libart.so (art::ThreadSuspendByPeerWarning(art::Thread*, android::base::LogSeverity, char const*, _jobject*)+656) [arm64-v8a::617b4481d2d525502ced0629cac33c57]
#04 pc 000000000053a700 /apex/com.android.runtime/lib64/libart.so (art::ThreadList::SuspendThreadByPeer(_jobject*, bool, art::SuspendReason, bool*)+1976) [arm64-v8a::617b4481d2d525502ced0629cac33c57]
#05 pc 0000000000449218 /apex/com.android.runtime/lib64/libart.so (art::VMStack_getThreadStackTrace(_JNIEnv*, _jclass*, _jobject*)+316) [arm64-v8a::617b4481d2d525502ced0629cac33c57]
#06 pc 000000000006840c /system/framework/arm64/boot-core-libart.oat [arm64-v8a::c77ae31598a40f6366394d30a82bd5be]既然无法使用Thread.getStackTrace()直接去拿方法调用栈,就需要自己去写native方法去实现getStackTrace了,好在网上已经有了轮子,不过demo仅适配了 Android 12,而我们要在Android 10上进行试验,所以需要做下Android 10的兼容适配。适配的过程就是根据不同系统的源码去修改相应的偏移量和结构体,关键代码如下:
通过dlopen_ex和dlsym_ex拿到系统函数地址初始化动态调用系统函数指针
//初始化系统函数指针
void ArtHelper::initMethods() {
//获取libart库句柄
void *handle = dlopen_ex("libart.so", RTLD_NOW);
//栈回溯函数
WalkStack_ = reinterpret_cast<void (*)(StackVisitor *, bool)>(dlsym_ex(handle,"_ZN3art12StackVisitor9WalkStackILNS0_16CountTransitionsE0EEEvb"));
//线程挂起函数
SuspendThreadByThreadId_ = reinterpret_cast<void *(*)(void *, uint32_t, SuspendReason,bool *)>(dlsym_ex(handle,"_ZN3art10ThreadList23SuspendThreadByThreadIdEjNS_13SuspendReasonEPb"));
//线程恢复函数
Resume_ = reinterpret_cast<bool (*)(void *, void *, SuspendReason)>(dlsym_ex(handle,"_ZN3art10ThreadList6ResumeEPNS_6ThreadENS_13SuspendReasonE"));
//方法描述信息函数
PrettyMethod_ = reinterpret_cast<std::string (*)(void *, bool)>(dlsym_ex(handle,"_ZN3art9ArtMethod12PrettyMethodEb"));
}根据不同系统源码设置对应的偏移量和结构体
//线程id偏移量
//#define THREAD_ID_OFFSET 8 //Android 12
#define THREAD_ID_OFFSET 12 //Android 10
#define TID_OFFSET 12
#endif
Runtime-12:https://cs.android.com/android/platform/superproject/+/android-12.0.0_r1:art/runtime/runtime.h
Runtime-10:https://cs.android.com/android/platform/superproject/+/android-10.0.0_r1:art/runtime/runtime.h
//Runtime结构体
struct PartialRuntime {
void *heap_;
void *jit_arena_pool_;
void *arena_pool_;
// Special low 4gb pool for compiler linear alloc. We need ArtFields to be in low 4gb if we are
// compiling using a 32 bit image on a 64 bit compiler in case we resolve things in the image
// since the field arrays are int arrays in this case.
void *low_4gb_arena_pool_;
// Shared linear alloc for now.
void *linear_alloc_;
// The number of spins that are done before thread suspension is used to forcibly inflate.
size_t max_spins_before_thin_lock_inflation_;
void *monitor_list_;
void *monitor_pool_;
void *thread_list_;
void *intern_table_;
void *class_linker_;
void *signal_catcher_;
// void *jni_id_manager_; //Android 10中没有
void *java_vm_;
void *jit_;
void *jit_code_cache_;
};最终通过native层拿到方法堆栈返回给java层
//native 抓栈方法
extern "C" JNIEXPORT jobjectArray JNICALL
Java_com_km_sliver_Sliver_getStackTrace(JNIEnv *env, jclass clazz, jobject threadPeer,jlong native_peer) {
bool timeOut;
//通过偏移量拿到threadid
auto *tid_p = reinterpret_cast<uint32_t *>(native_peer + THREAD_ID_OFFSET);
//线程挂起
void *thread = ArtHelper::SuspendThreadByThreadId(*tid_p, SuspendReason::kForUserCode,&timeOut);
stack<string> s_;
//构造visitor
FetchStackTraceVisitorR visitor = FetchStackTraceVisitorR(thread, &s_, nullptr);
//栈回溯
ArtHelper::StackVisitorWalkStack(&visitor, false);
//线程恢复
ArtHelper::Resume(thread, SuspendReason::kInternal);
//数据处理返给java层
int _size = s_.size();
jobjectArray array = env->NewObjectArray(_size, env->FindClass("java/lang/String"),env->NewStringUTF(""));
for (int i = 0; i < _size && !s_.empty(); i++) {
env->SetObjectArrayElement(array, i, env->NewStringUTF(s_.top().c_str()));
s_.pop();
}
return array;
}3、方法堆栈数据处理
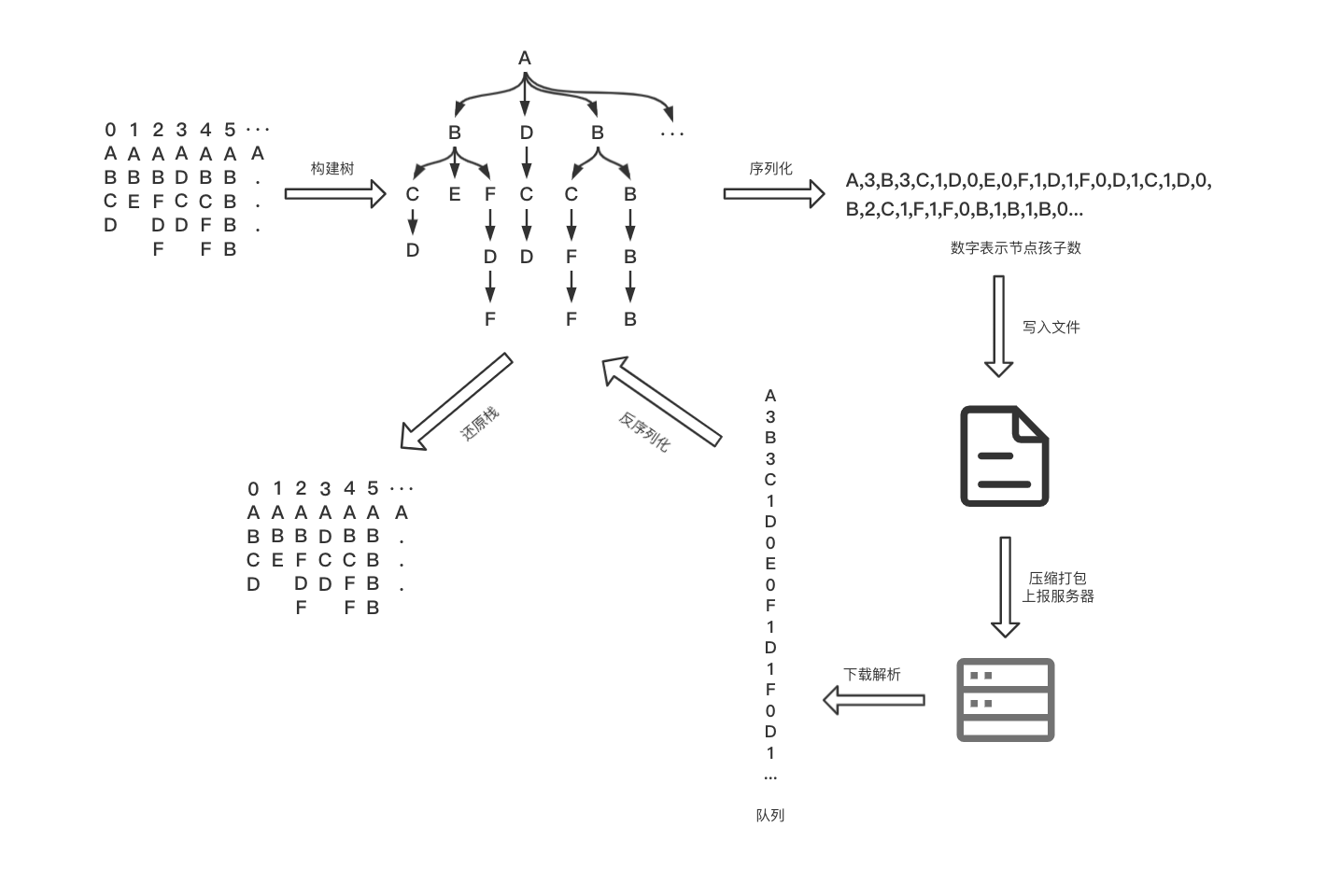
采集到的原始方法堆栈数据量会比较大,可能达到几百K甚至十几M,非常占用内存和磁盘空间,所以需要进行处理压缩其占用的空间。这里便可以采用树形结构来存储,因为采集的方法调用栈入口方法都是main,每个方法的调用就好比树的分支,树的根节点即是main,每个子节点可以存储方法的信息以及调用次数,这样便可将每次调用栈中重复冗余的方法用数量标记来代替,大大减少了空间占用。
public static class TraceNode {
public String trace;
public int count = 0;
public int level = 0;
public int offset = 0;
public List<TraceNode> child = new ArrayList<>();
public TraceNode(String stackTrace) {
trace = stackTrace;
}
public TraceNode(String stackTrace, int count_, int offset_, int level_) {
trace = stackTrace;
count = count_;
offset = offset_;
level = level_;
}
private TraceNode hasChild(String stackTrace) {
if (child.isEmpty()) {
return null;
} else {
if (child.get(child.size() - 1).trace.equals(stackTrace)) {
return child.get(child.size() - 1);
}
return null;
}
}
public TraceNode addChild(String stackTrace) {
TraceNode node = null;
int nodeOffset = 0;
if (child.isEmpty()) {
nodeOffset = this.offset;
} else {
TraceNode lastChild = child.get(child.size() - 1);
if (lastChild.trace.equals(stackTrace)) {
node = lastChild;
} else {
nodeOffset = lastChild.offset + lastChild.count;
}
}
if (node != null) {
node.count++;
} else {
node = new TraceNode(stackTrace);
node.level = level + 1;
node.count++;
node.offset = nodeOffset;
child.add(node);
}
return node;
}
}
/**
* 方法堆栈构造trace树
*/
public static TraceNode buildTraceTree(List<String[]> tracesList) {
TraceNode root = new TraceNode(tracesList.get(0)[0]);
root.count = tracesList.size();
tracesList.forEach(new Consumer<String[]>() {
@Override
public void accept(String[] trace) {
TraceNode pre = root;
for (int i = 1; i < trace.length && pre != null; i++) {
pre = pre.addChild(trace[i]);
}
}
});
return root;
}
4、数据存储与解析
采集到的数据最终是要上报至后台的,故需要将数据进行序列化并存储在文件中,等待合适的时机再进行上报,这里的序列化就是简单的前序遍历,通过";"将各个节点进行拼接生成字符串。而后我们从后台拿到数据文件需要对其进行反序列化并还原成原始的方法堆栈。反序列化就是将序列化后的字符串通过";"进行分割,并存放在队列中,然后依次读取队列中的值构造成TraceNode,最终生成Trace树。然后通过简单的遍历Trace树即可还原为原始的方法堆栈数据。
private static String SPLIT_STR = ";";
/**
* 序列化,前序遍历
*/
public static String serialize(TraceNode root) {
if (root == null) return "";
StringBuilder sb = new StringBuilder();
buildString(root, sb);
return sb.toString();
}
private static void buildString(TraceNode root, StringBuilder sb) {
if (root == null) return;
sb.append(root.trace).append(SPLIT_STR).append(root.count).append(SPLIT_STR).append(root.offset).append(SPLIT_STR).append(root.child.size()).append(SPLIT_STR);
for (TraceNode child : root.child) {
buildString(child, sb);
}
}
/**
* 反序列化
*/
public static TraceNode deserialize(String data) {
if (data.length() == 0) return null;
String[] str = data.split(SPLIT_STR);
Queue<String> queue = new LinkedList<>();
Collections.addAll(queue, str);
return buildTree(queue, 0);
}
private static TraceNode buildTree(Queue<String> queue, int level) {
String trace = queue.poll();
int count = Integer.parseInt(queue.poll());
int offset = Integer.parseInt(queue.poll());
int size = Integer.parseInt(queue.poll());
TraceNode root = new TraceNode(trace, count, offset, level);
root.child = new ArrayList<>(size);
for (int i = 0; i < size; i++) {
root.child.add(buildTree(queue, level + 1));
}
return root;
}
/**
* 树还原为原始方法堆栈
*/
private static List<String>[] recoverTrace(TraceNode root) {
List<TraceNode> list = new ArrayList<>();
final Queue<TraceNode> queue = new LinkedList<>();
int size = root.count;
final List<String>[] traceArray = new ArrayList[size];
for (int i = 0; i < size; i++) {
traceArray[i] = new ArrayList<>();
}
queue.offer(root);
while (!queue.isEmpty()) {
TraceNode traceNode = queue.poll();
list.add(traceNode);
if (!traceNode.child.isEmpty()) {
traceNode.child.forEach(new Consumer<TraceNode>() {
@Override
public void accept(TraceNode node) {
queue.offer(node);
}
});
}
}
final int[] level = {0};
final int[] currentOffset = {0};
list.forEach(new Consumer<TraceNode>() {
@Override
public void accept(TraceNode node) {
if (node.level != level[0]) {
level[0] = node.level;
currentOffset[0] = 0;
}
currentOffset[0] = node.offset;
if (node.count > 1) {
for (int i = 0; i < node.count; i++) {
traceArray[currentOffset[0] + i].add(node.trace);
}
} else {
traceArray[currentOffset[0]].add(node.trace);
}
currentOffset[0] += node.count;
}
});
return traceArray;
}5、数据展示与分析
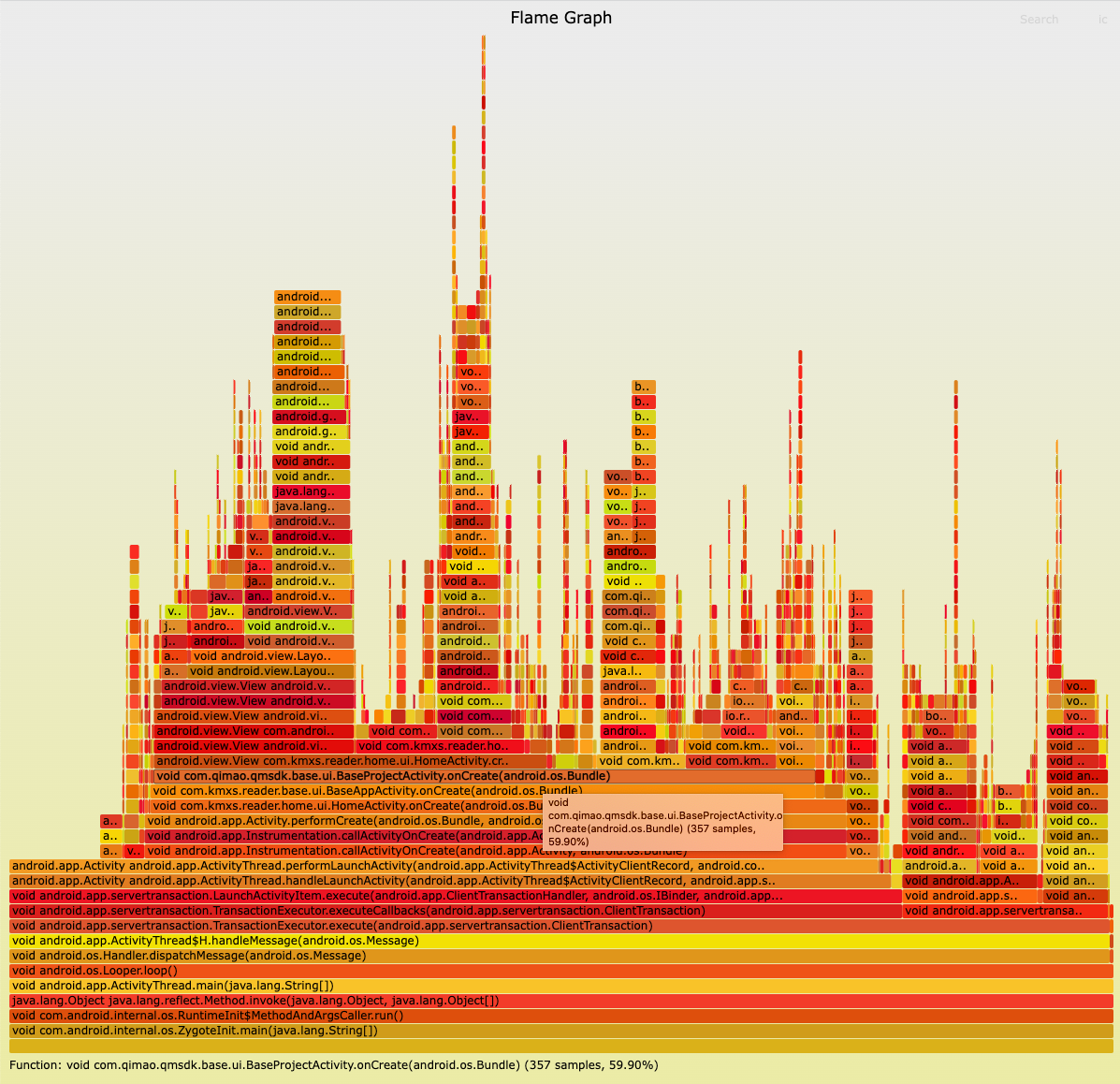
由于原始的堆栈数据过于庞大,我们需要借助火焰图生成工具将方法堆栈数据生成火焰图,通过生成的火焰图我们可以很直观的看到该条消息调度过程中执行的方法以及方法的耗时(耗时很小的方法不会展示,因为是采样的,耗时小于采样间隔的方法可能不会被采集到)。火焰图是svg格式的,鼠标选中可以看到对应方法出现的次数,通过与采样间隔相乘即可计算出相应的耗时,比如samples是100,采样间隔是10ms,则方法耗时可近视为1000ms。通过以上操作我们数据都已准备完毕便可以开始分析ANR的原因了,我们的耗时方法堆栈是通过token和耗时消息进行一一对应的,上文已经讲述了如何分析耗时消息,接下来只需要根据耗时消息的token去查看对应方法堆栈生成的火焰图即可。整个流程:分析消息文件查找耗时较长的消息→ 通过消息的token找到对应的火焰图→ 根据火焰图分析耗时方法→根据耗时方法定位到具体代码。

四、总结
以上,我们详细介绍了基于主线程消息调度的耗时监控采集工具,让我们在发生ANR时可以了解到主线程消息调度的“过去、现在、将来”以及更细粒度的方法调用和执行耗时,为我们排查ANR问题提供了思路,避免陷入异常上报堆栈误区,准确找到真正有问题的方法。不过ANR 方法耗时过长并不一定都是这些方法在代码层面存在问题,CPU 负载过高、内存资源紧张等情况也会造成性能变差,所以拿到这些辅助定位信息也是我们后面的目标之一。
Android ANR 的治理是一个长期的事情,需要有完备的调查手段和方法论。以上工具原理虽然不复杂,但如果想做到可靠的性能与稳定性还是非常困难的,同时还有很多待优化的地方,后续会在此基础上继续探索,不断完善,努力打造性能更好,功能更全,更加稳定的 ANR消息监控数据采集工具。