背景
随着商业化业务的快速发张,业务人员对 ADX 后台系统的使用要求也提高了,ADX 的技术架构进行了一轮重构来满足新的业务需求,其中也包括 ADX 数据架构的升级。本文从业务需求出发,结合七猫数据现状,进行技术选型,升级到了新一代流批一体的数据架构。
需求与挑战
海量数据实时接入:每秒钟 100万条左右记录。
海量数据存储:至少存储 3 年历史数据。
实时明细数据查询:明细数据上传之后,能够被实时查询到,用于问题诊断。
准实时报表需求:准实时报表需要每 5 分钟更新一次。
多维度跨时间范围报表需求:按周、按月的多维度下钻查询占比较大。
成本需求:对比当前的架构,重构后的数据架构能够将成本降低。
当前架构存在的问题
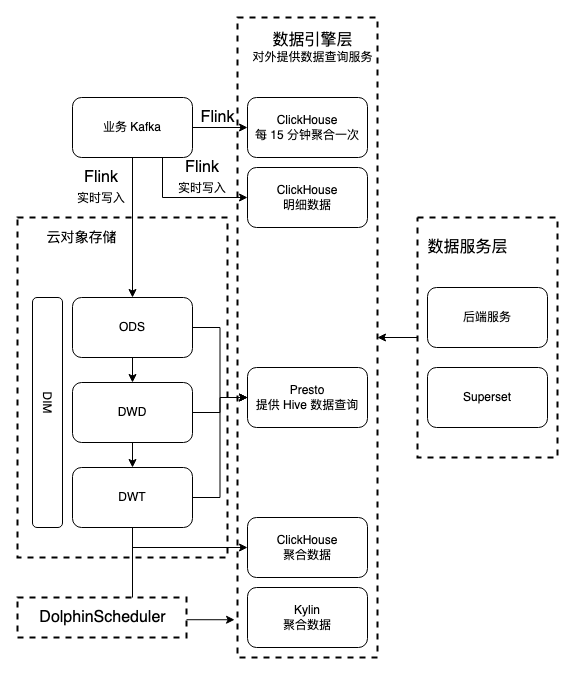
图“ADX数据架构-v1“是重构前 ADX 的数据架构。数据源是 ADX Kafka,通过 3 个 Flink 作业消费 Kafka 中的数据:
- Kafka -> Flink -> 每 15 分钟聚合的 ClickHouse 表:用于每 15 分钟更新一次报表。
- Kafka -> Flink -> ClickHouse 明细表:用于实时数据查询满足问题诊断的需求。
- Kafka -> Flink -> 云对象存储:用于存储历史数据和离线数仓的数据处理。
其中,“每 15 分钟聚合的 ClickHouse 表“ 和 “ClickHouse 明细表“ 被后端服务和 Superset 调用,用于报表展示和数据查询;“云对象存储“中的数据经过数据加工、聚合之后,分别存到“ClickHouse 聚合数据“和“Kylin 聚合数据“表中,提供预计算的多维数据查询服务。
DolphinScheduler 负责数仓作业的定时调度。
如果使用以上架构来支持“需求与挑战“中列出的需求点,会面临以下问题:
- “ClickHouse 明细表“实时写入压力大。当前配置的 ClickHouse 集群扛不住“双11“超过100万记录/秒的并发写入。要支撑峰值数据写入,集群必须扩容。
- ClickHouse 表存储成本大。ClickHouse 集群上存储的数据是本地存储,存储成本是云对象存储的 4-5 倍。ClickHouse 存储的数据越多,成本的上升得越快。
- 数据重复存储。“ClickHouse 明细表“中的数据与“云对象存储“中的数据是一致的。“ClickHouse 明细表“的存在是为了让明细数据能够被实时查询到,这带来了数据的冗余和成本的上升。
- 依赖 Presto 集群。在 Hive 表中但不在 ClickHouse 表中的数据无法被业务人员直接使用,必须要导入到 ClickHouse 表才能被查询。要把所有数据导入到 ClickHouse 表是不现实的。因此需要借助 Presto 的能力,让业务人员查询 Hive 表的数据。
技术选型
为了解决当前数据架构存在的问题,进行了调研和技术选型,最终引入了 StarRocks 来替换 ClickHouse 和 Presto 集群。在介绍新的数据架构之前,先介绍一下 StarRocks。
StarRocks 是一款高性能分析型数据仓库,使用向量化、MPP 架构、可实时更新的列式存储引擎等技术实现多维、实时、高并发的数据分析。StarRocks 既支持从各类实时和离线的数据源高效导入数据,也支持直接分析数据湖上各种格式的数据。StarRocks 兼容 MySQL 协议,可使用 MySQL 客户端和常用 BI 工具对接。
StarRocks的实践案例

小红书广告中心的架构跟当前 ADX 的架构类似,通过 Flink 将聚合后的数据写入到 ClickHouse 和 Redis 中,2021年之后,通过 StarRocks 取代了 ClickHouse ,简化了数据架构。

与小红书类似,众安保险也逐步用 StarRocks 代替了 ClickHouse。
除了小红书和众安保险,美团、携程、京东等公司也有很多 StarRocks 的实践案例。这为七猫使用 StarRocks 提供了参考。
StarRocks的性能对比

StarRocks 的单表查询能力不输 ClickHouse,在多表关联的场景下,StarRocks的性能优势明显。

在 StarRocks 给出的数据中。StarRocks 的性能比 Presto 有 2-3倍的提升。

在某些场景下,StarRocks 的查询性能优于 Kylin,但 Kylin 的使用成本更低。
通过 StarRocks 的实践案例和性能指标的分析,使用 StarRocks + Kylin 的组合,提供查询服务。
数据架构升级
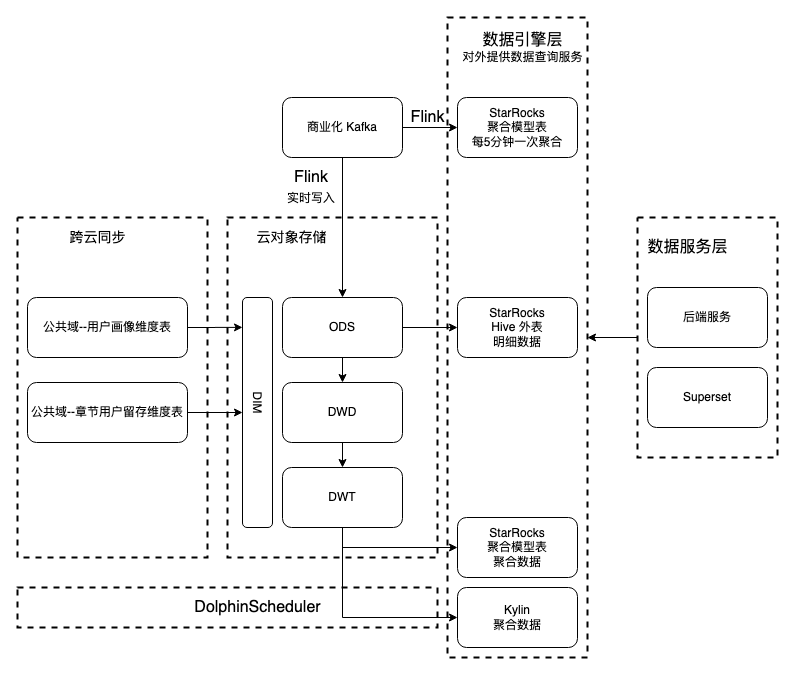
图“ADX数据架构-v2“是 ADX 升级之后的架构。与“ADX数据架构-v1“相比,用 StarRocks 替换了 ClickHouse,并且节省了一套 Presto 集群和一个 Flink 任务。通过 2 个 Flink 作业消费 Kafka 中的数据:
- Kafka -> Flink -> 每 5 分钟聚合的 StarRocks 表:用于每 5 分钟更新一次报表。
- Kafka -> Flink -> 云对象存储:用于存储历史数据和离线数仓的数据处理,并且通过 StarRocks 读 Hive 外表的能力,直接查询 Hive 表中的数据。这个能力不但节省了一个 Presto 集群,而且查询性能有了显著提升。
此外,打通了云间数据同步的能力。
该架构有以下优势
- 支持高并发写入。由于明细数据是直接写入云对象存储,利用云对象存储弹性扩容的能力,能够支持“双11“超过100万记录/秒的并发写入。
- 减少数据冗余。消除了明细数据写两份(一份写云对象存储,一份写 ClickHouse)的数据冗余问题。
- 精简架构。StarRocks 替换 ClickHouse,节省一个 Presto 集群和一个 Flink 作业。
- 查询性能提升,对比 Presto,StarRocks 查询性能有了显著提升。
- 节约成本。上述减少数据冗余、节省一个 Presto 集群和一个 Flink 作业,能够有效降低成本。
落地效果
“ADX数据架构-v2“在2023年春节前上线,在线上平稳运行将近两个月的时间。
DSP 新业务采用了 ADX 的新架构,充分复用了 ADX 沉淀的技术和功能,目前已上线。
未来展望
从运维部门得到的反馈,这套流批一体的新架构能够显著降低成本,期望能够在其它业务上进行推广。在运维部门的帮助下,StarRocks 外表与 Superset 不兼容的问题于近期解决。
大数据团队目前正积极地调试其他业务线的 StarRocks 使用,结合当前的业务和数据现状,为将来的迁移做准备。另一方面,也会注重通用能力的抽象,将流批一体的能开放出来,以及其易用的方式提供给其它团队使用。