一、摘要
七猫小说APP内容推荐的精准度,依赖策略算法的持续迭代,预估模型是算法的核心能力。此前,七猫各项推荐业务接入模型需要一定的学习成本,且各项业务模型独立开发,不同业务间的模型能力不能快速协作和复用,无法形成合力,造成一定的人力浪费。针对这些痛点,我们基于开源框架,自主建设了一个机器学习平台,从特征、训练、部署等方面简化模型接入流程,将通用的数据、基建进行统一,提升模块的复用能力,减少重复开发和人力资源浪费。
经过一段时间的迭代,自研平台可基本对标业界通用的算法平台,赋能业务初见成效:底层通用算法技术各业务可低成本复用,算法以有限人力同时支撑内容成长/内容分发/商业化等多个方向的提效,将新业务的接入周期从一周缩短到一天,大幅减少人力投入,提升迭代效率。
二、现状和挑战
通常,一个完整的模型接入流程形如:
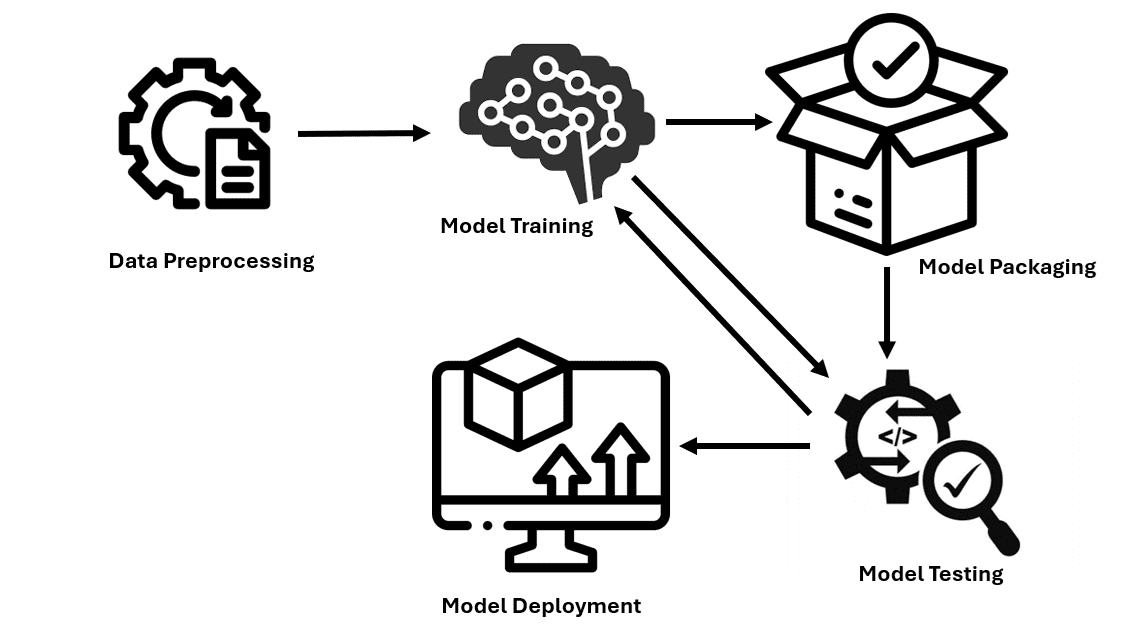
以之前模型接入流程为例,用户需要:准备训练数据、配置特征、配置模型参数、部署训练环境、模型训练、打包部署到线上,才能真正服务于线上业务。其中训练环境与模型无关,理论上不影响模型训练效果,但需要用户手动操作部署。比如,当前k8s训练集群,用户需要打包tensorflow和其他配置到镜像,需要了解docker和镜像的一些概念,需要熟悉打包操作,需要熟悉kubectl查询日志命令等,这些都会带来额外的学习成本。此外,由用户自行操作的打包,可能造成不同模型的训练环境不一致,还可能带来一些权限问题。这些都是应当避免的。线上部署,需要配置线上特征和模型的在线环境,阿里云/华为云服务通常会提供一些部署操作说明,但也需要一定的入手成本。
可以看到,模型要实际作用于业务,一般涉及诸多配置项和手动操作。这些配置绝大多数与模型效果无关,但需要用户对其内在含义有一定的了解。这些额外的学习成本,制约了模型的接入速度,对于业务本身没有价值。
针对这些问题,自建平台从训练框架和在线推理两方面解决:
- 训练框架方面:封装部署流程,全程自动化,让用户对前置链路的部署操作无感;模型代码模块化,降低模型配置和开发难度。
- 在线推理方面:训练完成后自动部署到线上,简化在线特征配置,用户无须关心后置链路的部署问题。
优化之后,在自建平台上接入模型,用户只需要:准备训练数据、配置特征(简化)、配置模型参数(简化)、模型训练。
三、训练框架
训练框架由主模块(AICat)和辅助SDK(mlengine)组成,其中mlengine负责训练无关流程的串联(环境部署、监控等),AICat负责实际训练。整体流程如下:

3.1 mlengine
mlengine是训练辅助库,封装为SDK,其作用可以从模型生产的三个阶段来阐述:
- 训练前,用户手动设置了特征和模型的参数,需要将改动上传至AICat库。mlengine辅助AICat统一管理模型代码,可以及时捕捉用户的改动。
- 训练时,mlengine提供一个基础镜像,安装了原生的tensorflow和一些必要的训练依赖库,用户只需要指定AICat库的分支名和模型名称,mlengine会自动为模型分配唯一的训练环境(拷贝基础镜像,并安装AICat库指定分支的代码)。这样,所有模型的tensorflow环境统一,而不同模型的结构代码各自独立。mlengine还会实时监控模型训练状态,提供了统一的api查询训练日志,用户无须额外学习集群的一些查询命令了(比如kubectl)。
- 训练完成后,mlengine还会为每个模型自动分配模型保存路径和训练日志路径等,自动从相关路径拉取模型部署到线上。
这些自动化操作,大大降低了平台的使用难度。
3.2 AICat
AICat是模型训练库,基于原生tensorflow,旨在提供一个简单的的模型开发范式,主要包含五部分:特征工程、模型构建、分布式训练、监控、Debug工具。
3.2.1 特征工程
特征即属性,特征值通常是字符明文,而模型的输入必须是数值,因此需要对特征值进行处理。模型特征根据类型不同,一般可分为两大类,离散特征(取值是字符串,如书籍分类)和连续特征(取值是数值,比书籍点击率)。

连续特征处理即归一化。一般,不同连续特征取值量级有差异(比如点击率一般小于1,曝光一般成千上万),简单放在一起可能造成模型训练失败,因此需要将量级约束到同一尺度下。
- 业界常用归一化方法有,最大最小值归一化、高斯归一化等,可能的问题有两个:需要事先统计连续值的分布;这些分布如果不同天有差异,则同一个连续值在不同天,归一化之后的值不一样,影响模型的稳定性。
- AICat采用log归一化,保证了连续值归一化之后的稳定性和单调性,同时log归一化不需要统计连续值的分布,操作更便捷。

离散特征处理即ID化。一般,需要为每一个字符明文值分配一个ID,该ID关联一个唯一的embedding(模型可学习的多维参数)。
- 简单的ID化方法是,为当前所有特征取值构建一个词表,每个取值在词表中的位置即为ID。可能的问题有两个:如果词表与模型绑定,则词表在建立之后无法更改,对于新增离散特征,无法分配新的ID;如果词表与模型独立,当有新增离散特征时,词表随之更新,但要单独维护词表,且保证更新前后的兼容性(旧特征位置不可变,新增特征只能追加到词表末尾),处理较为复杂。
- AICat采用了另一种业界流行的处理方法,直接对于每一个值经过hash映射为一个数字ID,大大简化了流程。当hash空间设置得当,hash冲突率很低,对于每个新增特征也能分配唯一的ID。

此外,AICat还针对复杂特征提供了适配的算子,比如序列特征离散、序列特征归一化、序列特征分桶后离散等。这些算子基本涵盖了模型训练所需的常用特征处理。
综上,AICat的特征处理,结合一些文档示例说明,可以让用户很方便了解算子的实际处理过程,快速构建模型训练所需的特征配置。
3.2.2 模型构建
AICat已涵盖了多种业界常用模型结构,用户可直接调用。如果用户有开发模型结构的需求,AICat基于Keras进行一定的封装优化,降低了开发难度:
- 定义了多种业界常用可嵌入的模型子结构(比如MLP、SeNet等),用户可直接组装,减少重复开发;
- 定义了一个兼容性强的Base模型,用户可直接继承,复用Base模型的属性和方法;
- 提供多种embedding拼接方法,拼接时使用tensorflow式矩阵调用,尽量避免python式循环操作,可降低embedding的获取耗时。
综上,AICat提供了一些模型开发的范式,用户往往只需要自定义子结构的组装方式、loss计算函数,减少了开发量。
3.2.3 分布式训练
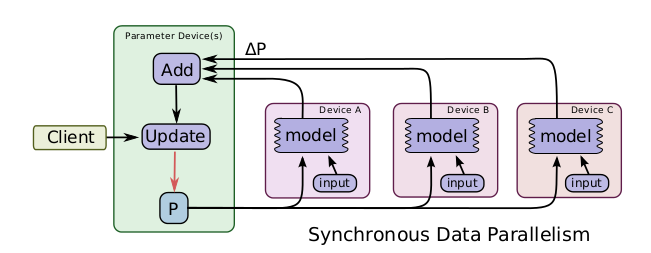
分布式训练,即多台机器协同,加快模型训练,一般分为同步训练和异步训练,两种方式的优缺点:
- 同步训练,所有机器都在同一个时刻更新模型参数,模型的协调性更好,训练出来的模型往往效果更好,但训练速度慢。
- 异步训练,各机器独立更新参数,协调性稍差,但训练速度快。
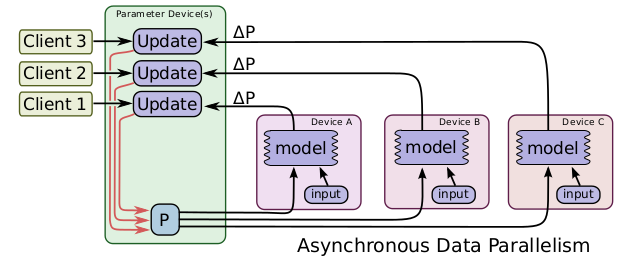
目前训练机器往往是同型号同规格,异步训练的方式不会对模型效果有很大的负面影响。对于大参数量的模型,一台机器存储不下,同步训练方式不能正常训练,但异步训练方式,多台机器共同储存一套模型参数,可以正常训练。
综上所述,AICat采用异步训练方式,兼顾了训练速度和训练效果。
3.2.4 监控
AICat监控系统齐全:
- Grafana实时查看训练机器的CPU、内存等使用情况,方便资源调优。
- Kibana实时打印训练日志,方便查看训练进度和模型效果。
3.2.5 Debug工具
AICat还提供了一些辅助工具,比如本地测试、本地预估、本地算子耗时分析等,方便用户自定义模型时排查可能出现的问题。
四、在线推理
当模型训练完成后,mlengine模块会自动将保存的模型上传到线上。模型保存时,封装了特征处理算子,保证了离线在线预估一致性。要使模型真正生效,还需要传给模型线上特征。平台采用了特征组管理模式,将特征按需分类,用户选择特征组,模型即可正常推理了。
除了便捷性,在线推理还从成本和管理方面进行了优化,包括:
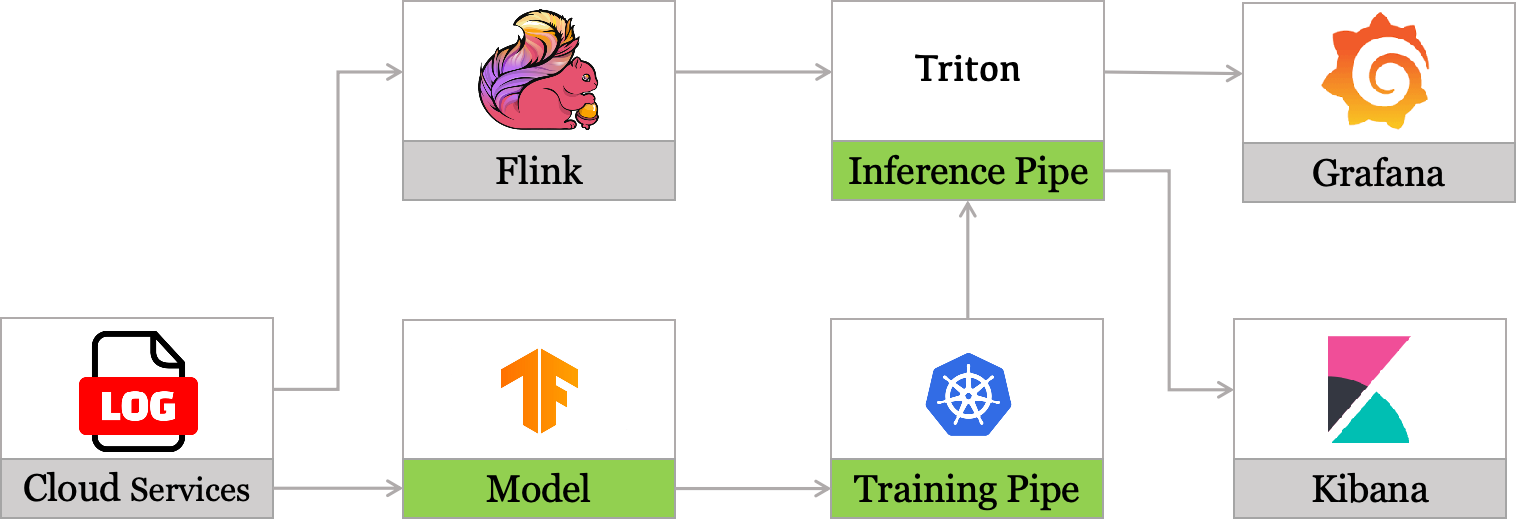
- 模型推理服务:基于Triton和特征平台统一承接在线模型接入需求(与业务解耦),支持多种训练框架,包含RPC服务框架、业务调度框架、模型的管理更新框架、模型计算引擎、监控数据采集、样本采集框架等。
- 用户画像服务:基于MongoDB构建用户画像服务,通过拆分冷热存储方案提高用户数据覆盖率的同时降低存储成本,为各业务提供统一用户画像数据,支持策略和模型的快速迭代。
简而言之,用户可默认模型训练完成后线上即刻部署了模型,此时,用户只需要简单勾选模型关联的特征组,模型就可以实际服务于业务了。
五、总结和展望
自研机器学习平台当前已具备了快速接入模型业务,且稳定迭代的能力,但仍然有很多不足,主要表现在:
- 平台缺少模型效果分析工具。比如当前模型的auc,大致是什么水平,是否还有提升空间,以及怎么改进,平台缺少相关工具,指导用户进行下一步的迭代优化。
- 平台对于大模型的支持不足。比如,百亿参数模型,虽然离线可以训练,但线上不支持分布式部署,单机部署可能内存不足,使得大模型无法真正服务于线上业务。
对于这些不足之处,后续已有一定的规划。比如大模型的分布式部署,分析了常见的大模型结构,可以拆分出embedding参数和网络参数部分,其中embedding参数采用分布式部署,网络参数单机部署,可以解决内存不足问题。
未来,平台将持续收集用户需求,进行针对性优化,以期更好地服务各类模型。