前言
目前公司正在搭建广告ADX平台,使用自研的七猫SDK渲染图文、视频广告,用户在阅读器内看书时,为了节省用户流量,视频广告在移动网络下不会播放视频,只会显示封面,但是用户选择看激励视频时,遇到了一些问题。下面分析下几种不同方案各自存在的问题,以及我们最后的解决方案。
第一种方案是不做任何缓存,直接播放,用户每次播放视频素材都会消耗一次流量;
结论:这种方案比较消耗流量。
第二种方案是等待视频下载完成再播放,在视频下载过程中,用户面对着黑屏要一直等待,直到视频下载完成,之前某家联盟广告就是采用的这种方案,线上收到很多用户反馈黑屏时间长、视频无法播放的情况,因为网络不好时,用户等待时间可能超过30s,极大的影响用户体验;
结论:观看视频体验不友好。
第三种方案是边下边播,视频在播放的同时下载资源到本地,视频在播放时需要消耗一次流量,同时视频下载会消耗一次流量,相当于第一次播放下载会消耗两倍流量,后续播放相同素材就从本地读取,不会消耗流量。
结论:这种方案也比较消耗流量。
那么有没有更好的方式,让用户体验友好的同时自始自终只消耗一倍流量呢?请耐心往下看。
最终技术方案
想要实现一倍流量,一种方案是存储播放器加载的数据到本地,下次直接从本地读书数据播放,项目中使用的是系统的mediaPlayer播放器,播放逻辑封装在c层,想要实现缓存,必须要改系统源码,实现起来难度较大,且对系统稳定性有影响。
另一种方案是在播放器与视频源服务器之间加了一层代理服务器,截取视频播放器发送的请求,根据截取的请求,向网络服务器请求数据,然后写到本地,本地代理服务器从文件中读取数据并发送给播放器进行播放。目前市面上使用上述原理的成熟框架主要有两种:AndroidVideoCache和JeffVideoCache,两者都实现了边下边播功能,且消耗一倍流量,技术原理也是一样的,下图是两者的区别。
| 功能对比 | JeffVideoCache | AndroidVideoCache |
|---|---|---|
| GitHub star | 99 | 4.9k |
| 支持视频类型 | m3u8、mp4、mov | mp4、mov |
| 播放器 | mediaPlayer、exoPlayer、ijkPlayer | mediaPlayer、exoPlayer、ijkPlayer |
| 视频预加载 | 支持 | 不支持 |
| 缓存清理 | 过期时间、文件大小 | 文件个数、文件大小 |
| 缓存分片 | 支持 | 不支持 |
依上图可知,jeffVideoCache实现的功能更加全面,但是使用的人数少,后期维护风险大,androidVideoCache也能满足节省流量的需求,由于社区活跃、功能更加稳定,因此后者更适合在我们的项目中应用。
AndroidVideoCache的应用
1.基本使用
使用builder模式构建httpProxyCacheServer对象,将服务端的url转为本地的url链接,设置给播放器,开始播放。
HttpProxyCacheServer proxy = new HttpProxyCacheServer.Builder(this).build();
String proxyUrl = proxy.getProxyUrl(url);
videoView.setVideoPath(proxyUrl);
videoView.start();2.原理简介
主要的实现原理是在本地客户端实现一个代理服务器,客户端将视频链接转为本地host链接给播放器,代理服务器的sockt监听到请求过来时,会再开一个线程,从原始的url读取数据到本地的文件,同时socket读取本地文件的数据写入,mediaPlay通过binder通信读取数据给c层,播放视频。
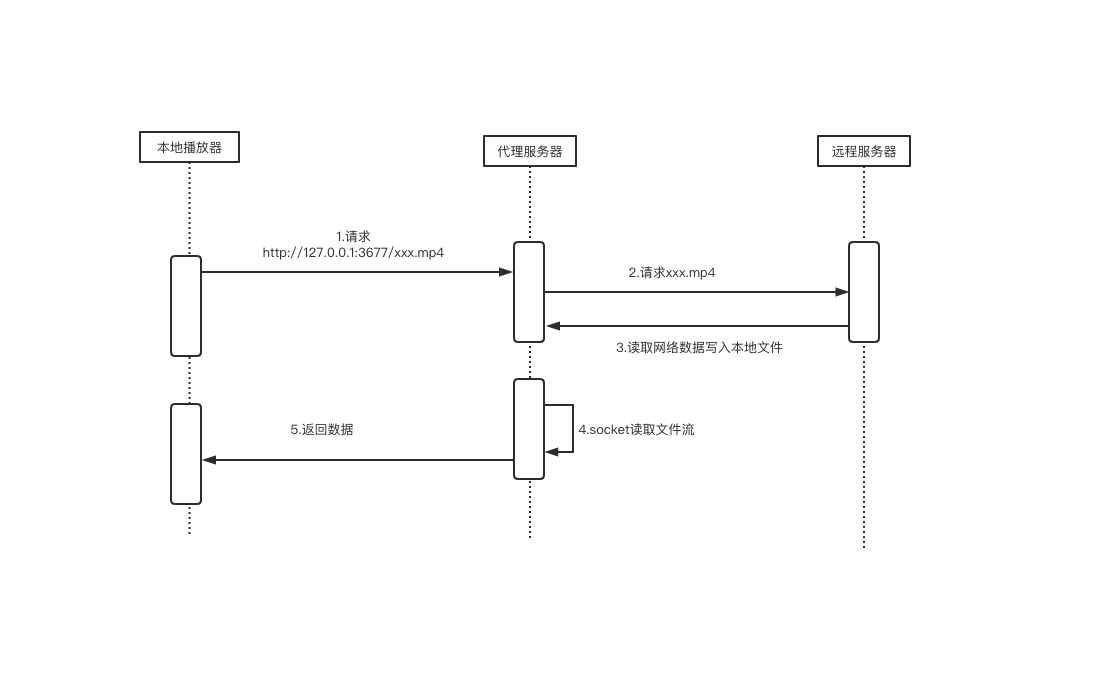
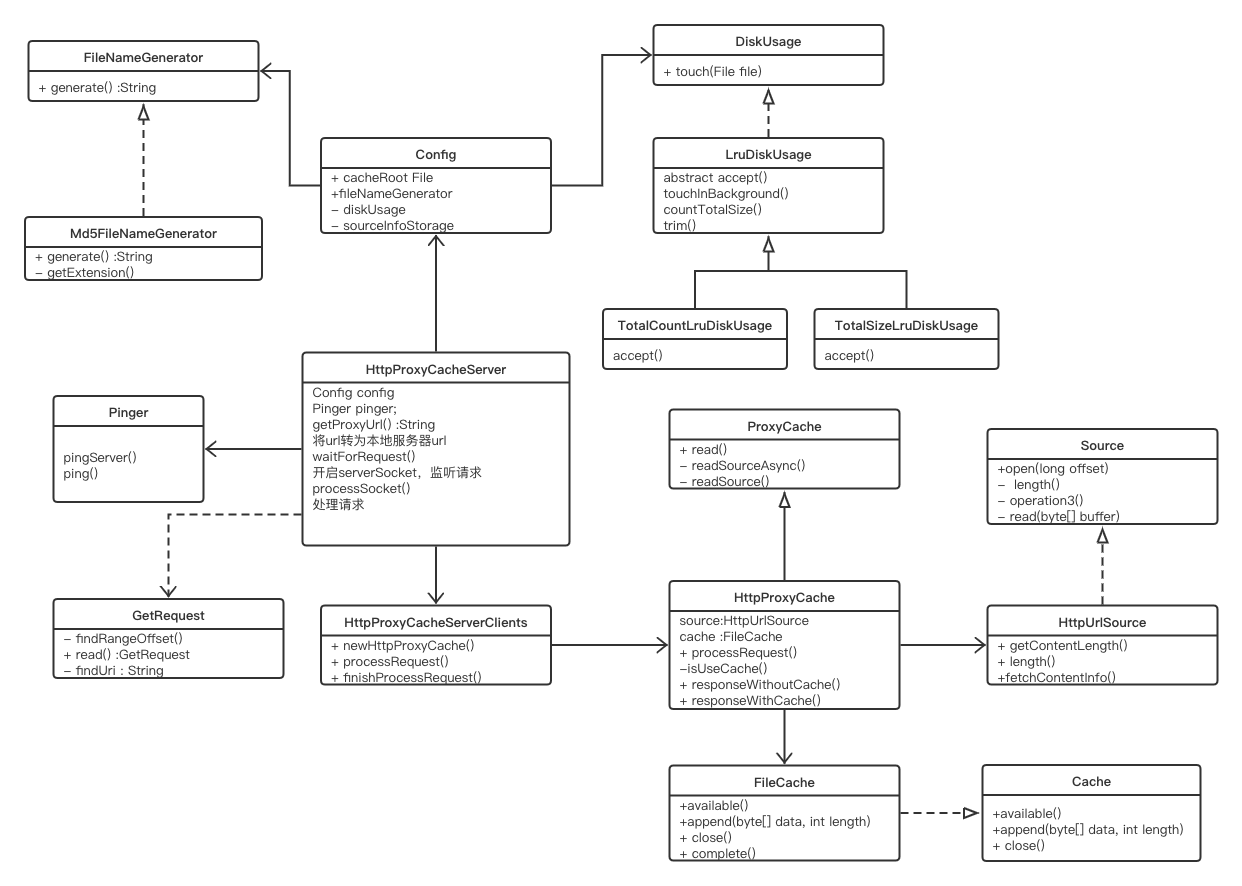
3.源码分析
在讲源码之前,先了解mediaplayer视频播放来源,可以是文件,也可以是网络url请求,下面是mediaPlayer源码。
private void setDataSource(String path, String[] keys, String[] values,
List<HttpCookie> cookies)
throws IOException, IllegalArgumentException, SecurityException, IllegalStateException {
final Uri uri = Uri.parse(path);
final String scheme = uri.getScheme();
if ("file".equals(scheme)) {
//file开头是本地文件uri,从本地读取
path = uri.getPath();
} else if (scheme != null) {
nativeSetDataSource(
//传递mediaHttpService给c层
MediaHTTPService.createHttpServiceBinderIfNecessary(path, cookies),
path,
keys,
values);
return;
}
final File file = new File(path);
try (FileInputStream is = new FileInputStream(file)) {
setDataSource(is.getFD());
}
}nativeSetDataSource是个native方法,通过jni调用创建MediaHTTPConnection对象,内部HttpUrlConnection负责发起真正的网络请求数据。AndroidVideoCache要将请求转为本地的代理服务器的请求,需要将url配置成本地的host和端口号,下面是对url的处理流程图。
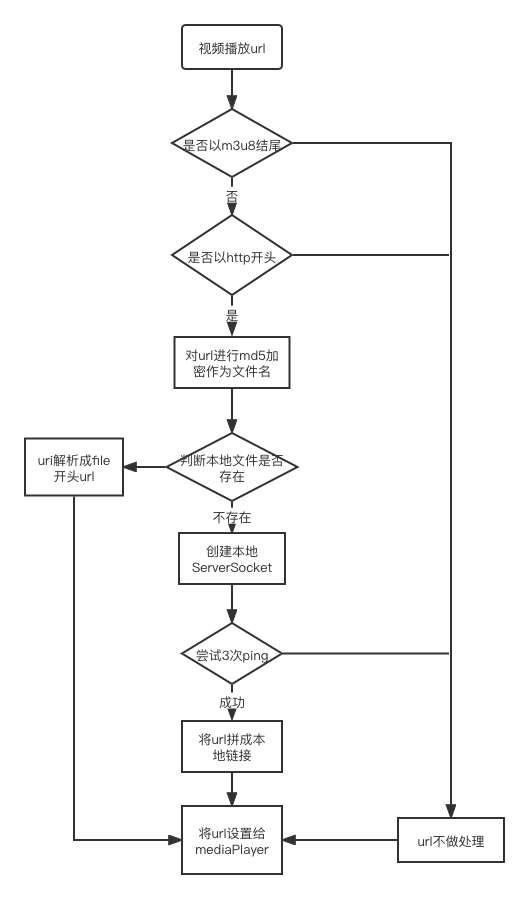
文件缓存不支持.m3u8格式的视频素材,因为它是多文件格式返回,无法做客户缓存,rtmp/rtsp开头是直播类的请求也不支持,然后对url做md5加密作为文件名,如果本地已缓存成功,播放器从本地读取数据播放,不存在则ping本地连接,成功则说明本地代理服务器可用。第一行代码使用建造者模式,配置参数。
private static final long DEFAULT_MAX_SIZE = 512 * 1024 * 1024;
//文件默认保存路径,有外置存储权限会保存在外置卡中,没有会保存在cache文件夹下
private File cacheRoot;
//文件名生成器,默认是对url进行md5加密
private FileNameGenerator fileNameGenerator;
//缓存清除策略,默认是LRU清理算法
private DiskUsage diskUsage;
//资源信息存储策略,存储url,length,mimetype,默认存储数据库
private SourceInfoStorage sourceInfoStorage;
//为url添加请求头,默认不添加
private HeaderInjector headerInjector;
public Builder(Context context) {
this.sourceInfoStorage = SourceInfoStorageFactory.newSourceInfoStorage(context);
this.cacheRoot = StorageUtils.getIndividualCacheDirectory(context);
this.diskUsage = new TotalSizeLruDiskUsage(DEFAULT_MAX_SIZE);
this.fileNameGenerator = new Md5FileNameGenerator();
this.headerInjector = new EmptyHeadersInjector();
}
public HttpProxyCacheServer build() {
Config config = buildConfig();
//构建代理服务器对象
return new HttpProxyCacheServer(config);
}
}创建本地代理服务器ServerSocket,最多允许8个客户端并发连接读取数据,然后创建一个线程一直等待客户端连接,这里用了CountDownLatch线程同步锁,因为创建线程耗时操作,防止服务端没有创建好就走了下面代码,出现异常情况。Sokect通信原理见下图。
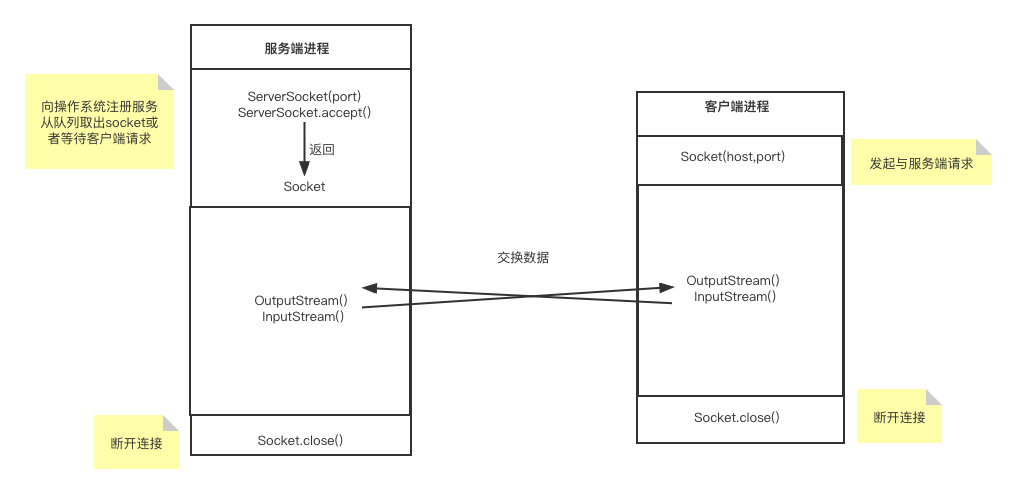
public class HttpProxyCacheServer {
private static final String PROXY_HOST = "127.0.0.1";
private ExecutorService socketProcessor=Executors.newFixedThreadPool(8);
private HttpProxyCacheServer(Config config) {
this.config = checkNotNull(config);
try {
InetAddress inetAddress = InetAddress.getByName(PROXY_HOST);
this.serverSocket = new ServerSocket(0, 8, inetAddress);
this.port = serverSocket.getLocalPort();
IgnoreHostProxySelector.install(PROXY_HOST, port);
CountDownLatch startSignal = new CountDownLatch(1);
this.waitConnectionThread = new Thread(new WaitRequestsRunnable(startSignal));
this.waitConnectionThread.start();
startSignal.await();
this.pinger = new Pinger(PROXY_HOST, port);
HttpProxyCacheDebuger.printfLog("Proxy cache server started. Is it alive? " + isAlive());
} catch (IOException | InterruptedException e) {
socketProcessor.shutdown();
throw new IllegalStateException("Error starting local proxy server", e);
}
}
private void waitForRequest() {
try {
while (!Thread.currentThread().isInterrupted()) {
//此方法一直阻塞...,有请求过来时会往下走
Socket socket = serverSocket.accept();
socketProcessor.submit(new SocketProcessorRunnable(socket));
}
} catch (IOException e) {
onError(new ProxyCacheException("Error during waiting connection", e));
}
}
//客户端socket处理任务
private void processSocket(Socket socket) {
try {
GetRequest request = GetRequest.read(socket.getInputStream());
String url = ProxyCacheUtils.decode(request.uri);
if (pinger.isPingRequest(url)) {
pinger.responseToPing(socket);
} else {
HttpProxyCacheServerClients clients = getClients(url);
clients.processRequest(request, socket);
}
} catch (SocketException e) {
} catch (ProxyCacheException | IOException e) {
onError(new ProxyCacheException("Error processing request", e));
} finally {
releaseSocket(socket);
HttpProxyCacheDebuger.printfLog("Opened connections: " + getClientsCount());
}
}
}socketProcessor线程池的作用是并发处理客户端请求,如果是ping请求,会向ping回写ping ok字段,socket收到之后会比对字段,相同则表示连接成功。正常请求会创建HttpProxyCacheServerClients代理客户端管理类,它主要做的是客户端代理HttpProxyCache生命周期管理和回调监听。
public void processRequest(GetRequest request, Socket socket) throws ProxyCacheException, IOException {
startProcessRequest();
try {
clientsCount.incrementAndGet();
proxyCache.processRequest(request, socket);
} finally {
finishProcessRequest();
}
}
//创建客户端代理对象
private synchronized void startProcessRequest() throws ProxyCacheException {
proxyCache = proxyCache == null ? newHttpProxyCache() : proxyCache;
}
//关闭客户端代理线程
private synchronized void finishProcessRequest() {
if (clientsCount.decrementAndGet() <= 0) {
proxyCache.shutdown();
proxyCache = null;
}
}
}HtttpProxyCache是处理请求的核心类,首先会写响应头,包括content-length,accept-range,content-type等键值对,然后判断是否从文件读取缓存,从文件缓存读的条件是文件长度为0,或者request.partial为false,其实就是没有ranage字段,或者有请求头range字段,但值小于缓存文件已读取的长度加上总长度的20%,然后太大也不走文件缓存。
public void processRequest(GetRequest request, Socket socket) throws IOException, ProxyCacheException {
OutputStream out = new BufferedOutputStream(socket.getOutputStream());
String responseHeaders = newResponseHeaders(request);
out.write(responseHeaders.getBytes("UTF-8"));
long offset = request.rangeOffset;
if (isUseCache(request)) {
responseWithCache(out, offset);
} else {
responseWithoutCache(out, offset);
}
}
private boolean isUseCache(GetRequest request) throws ProxyCacheException {
long sourceLength = source.length();
boolean sourceLengthKnown = sourceLength > 0;
long cacheAvailable = cache.available();
/**
*Content-Length的值要大于0
*range字段值要大于0
*range值要比缓存偏移值大,但不能超过总长度的20%
*NO_CACHE_BARRIER:0.2f
**/
return !sourceLengthKnown || !request.partial || request.rangeOffset <= cacheAvailable + sourceLength * NO_CACHE_BARRIER;
}先看读取文件缓存的实现逻辑,我们知道一开始文件里面肯定是空的,所以要先从远程服务器里面读到文件,然后再从文件读取,先看文件的读写操作类,用的是RandomAccessFile对象,因为它既可以读,也可以写,同时还可以seek到某个位置,一般用于分段下载场景。需要注意的是,在创建文件时是在原文件名中添加了.download的后缀名,表示文件正在下载中,然后在下载完成时会重新命名成原来的名字。
public FileCache(File file, DiskUsage diskUsage) throws ProxyCacheException {
try {
if (diskUsage == null) {
throw new NullPointerException();
}
this.diskUsage = diskUsage;
File directory = file.getParentFile();
Files.makeDir(directory);
boolean completed = file.exists();
this.file = completed ? file : new File(file.getParentFile(), file.getName() + TEMP_POSTFIX);
this.dataFile = new RandomAccessFile(this.file, completed ? "r" : "rw");
} catch (IOException e) {
throw new ProxyCacheException("Error using file " + file + " as disc cache", e);
}
}
public synchronized int read(byte[] buffer, long offset, int length) throws ProxyCacheException {
try {
dataFile.seek(offset);
return dataFile.read(buffer, 0, length);
} catch (IOException e) {
String format = "Error reading %d bytes with offset %d from file[%d bytes] to buffer[%d bytes]";
throw new ProxyCacheException(String.format(format, length, offset, available(), buffer.length), e);
}
}
public synchronized void append(byte[] data, int length) throws ProxyCacheException {
try {
if (isCompleted()) {
throw new ProxyCacheException("Error append cache: cache file " + file + " is completed!");
}
dataFile.seek(available());
dataFile.write(data, 0, length);
} catch (IOException e) {
String format = "Error writing %d bytes to %s from buffer with size %d";
throw new ProxyCacheException(String.format(format, length, dataFile, data.length), e);
}
}读取远程数据是readSourceAsync方法,它又开启了新的线程,每次读8192个字节,一次性写完,然后socket线程每次从文件读8192个字节,然后写入到socket中,如果文件读比文件写快的话,有设置1s的同步线程锁,当文件写完一个buffer,通知这边读一个buffer,从而保证有序进行读取。
private void responseWithCache(OutputStream out, long offset) throws ProxyCacheException, IOException {
byte[] buffer = new byte[DEFAULT_BUFFER_SIZE];
int readBytes;
while ((readBytes = read(buffer, offset, buffer.length)) != -1) {
out.write(buffer, 0, readBytes);
offset += readBytes;
}
out.flush();
}
public int read(byte[] buffer, long offset, int length) throws ProxyCacheException {
ProxyCacheUtils.assertBuffer(buffer, offset, length);
while (!cache.isCompleted() && cache.available() < (offset + length) && !stopped) {
readSourceAsync();
waitForSourceData();//等待1s
checkReadSourceErrorsCount();
}
int read = cache.read(buffer, offset, length);
if (cache.isCompleted() && percentsAvailable != 100) {
percentsAvailable = 100;
onCachePercentsAvailableChanged(100);
}
return read;
}
private void waitForSourceData() throws ProxyCacheException {
synchronized (wc) {
try {
wc.wait(1000);
} catch (InterruptedException e) {
throw new ProxyCacheException("Waiting source data is interrupted!", e);
}
}
}
private void notifyNewCacheDataAvailable(long cacheAvailable, long sourceAvailable) {
onCacheAvailable(cacheAvailable, sourceAvailable);
synchronized (wc) {
wc.notifyAll();
}
}
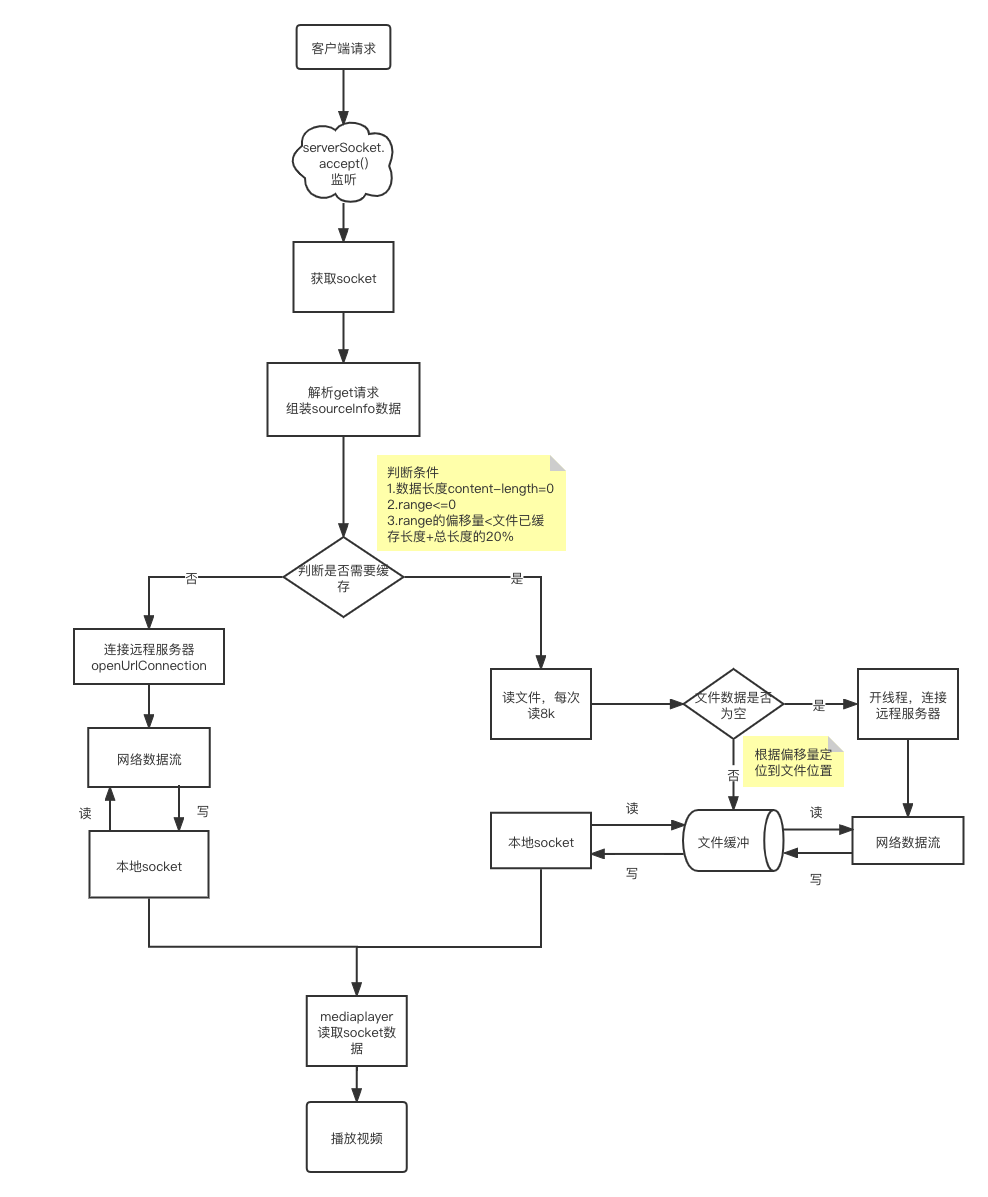
大概的源码分析完了,总结一下就是将播放地址转为本地host和port给mediaPlayer,客户端开启serverSocket监听请求,mediaplayer发送请求时,socket解析请求,判断是否需要走文件缓存,还是走直接下载方式,文件下载成功存储到本地,下次同一url请求时直接从本地文件读取,不消耗流量。
4.结果分析

测试结果符合预期,边下边播只消耗了一倍的流量,后续播放从本地文件读取,不消耗流量,如图所示,使用charles抓包看到发起了两次网络请求,第一次只请求了很小的数据量,第二次才请求了完整的数据,为什么会请求两次呢?这和mp4的格式有关系,下图是用mediaParser工具查看到的mp4文件结构
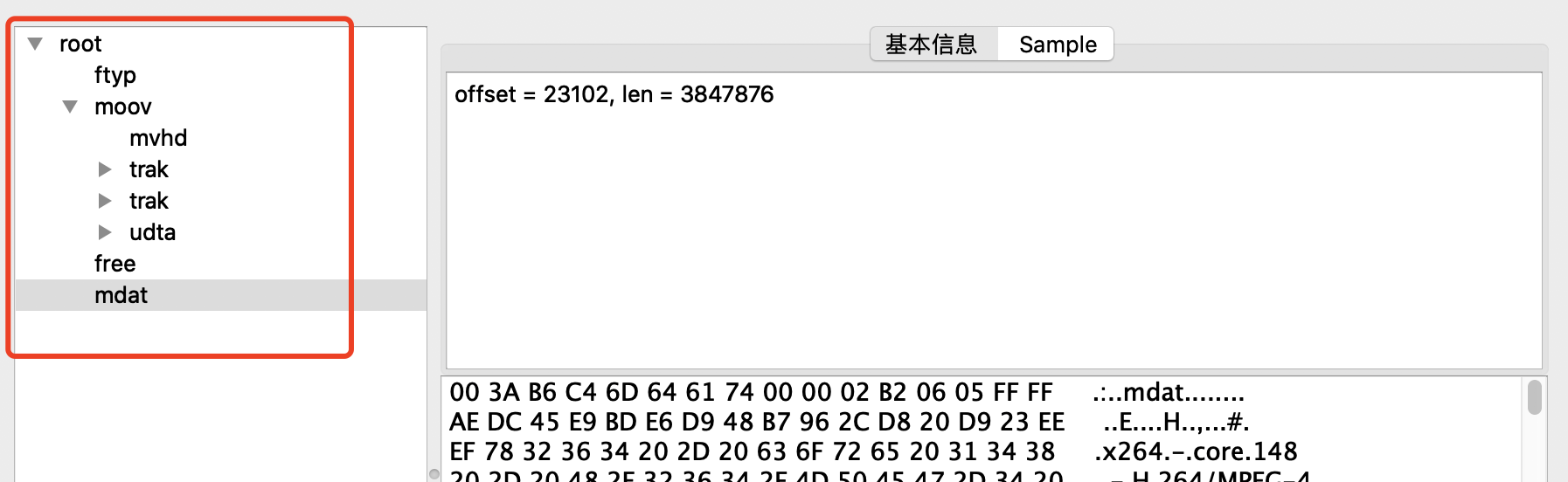
其中 moov 记录 MP4 视频的元信息,特别是 trak记录着视频播放数据的时间和空间信息。而 mdat 则是保存着视频音频信息。而视频的拖动,快进,都是需要根据 moov 和拖动至的时间,来计算要 seek 到的文件位置。 但是 MP4 文件,不一定 moov 就在文件开头,也有可能在文件末尾。
在发起http请求时,会先读取moov头部信息(moov 一般都比较小),获取到视频的总长度,再接着往下读取;如果发现开头没有,立马 RESET 这个连接,节省流量,通过 Range 头读取文件末尾数据,因为前面一个 HTTP 请求已经获取到了 Content-Length ,知道了 MP4 文件的整个大小,通过 Range 头读取部分文件尾部数据也是可以读取到的。
思考总结
在分析源码的过程中,发现了androidVideoCache的一些不足之处:
1.视频预加载
框架不支持视频预加载功能,客户端需要手动实现预缓存,后续可以将这个功能封装到框架中。
2.线程管理
线程池创建不合理,客户端响应线程用固定线程池的方式,会增多项目线程数,引发oom,可以根据cpu的核心数创建线程个数,节约资源;new Thread方式可以改用线程池方式创建。
//客户端响应线程池
private ExecutorService socketProcessor = Executors.newFixedThreadPool(8);
//本地服务器监听线程
this.waitConnectionThread = new Thread(new WaitRequestsRunnable(startSignal));
this.waitConnectionThread.start();
//读取网络数据线程
sourceReaderThread = new Thread(new SourceReaderRunnable(), "Source reader for " + source);
sourceReaderThread.start();3.AndroidVideoCache采用数据库进行存储缓存的信息,可以不使用,减少IO操作。
public Builder(Context context) {
this.sourceInfoStorage = SourceInfoStorageFactory.newSourceInfoStorage(context);
}
数据库缓存了素材的url,长度和类型,以便于下次使用时直接从数据库中查询,其实是没有必要的,因为每次请求都会创建新的对象,不需要缓存。
4.支持m3u8视频格式,视频分片下载,节省流量。
mp4格式是整段视频,每次开启下载时,都会把整个视频下载下来,m3u8格式是数据返回是分片的,视频可以一段一段下载,节省流量。
参考文献:
1.https://juejin.cn/post/6844903773521838087
2.https://zhuanlan.zhihu.com/p/395181238
3.https://blog.qiusuo.im/blog/2015/02/05/play-mp4-using-http/