供稿来自:@吴昌鑫
一、背景
App 稳定性是影响用户体验的重要因素之一,随着 App 功能及使用场景的日益复杂,稳定性保障贯穿开发、日常监控、问题解决等各个阶段。
- 开发人员日常值班、添加告警任务,关注稳定性趋势和 Top 问题波动。
- 运营和测试关注用户反馈,发现问题会第一时间同步开发、跟进解决。
这其中也一直存在一些问题:
- 形式化:人工值班制度效率低下,易流于形式。
- 效率不高:由于稳定性问题有较强的专业性,运营和测试发现问题,第一时间无法找到处理人,还需要值班开发人员初步分析,再转给处理人,涉及人员多、流程繁琐就很容易导致处理不及时;对于值班开发人员也不友好,经常充当工具人。
随着 AI 发展,希望通过稳定性 Agent 交付一个稳定性系统,能自主感知问题、自主分析,并且让非专业同学也能高效、精准地解决问题。
涉及多个岗位人员,频率高,还是希望能在飞书上闭环,所以选用了飞书Aily(低代码 Agent 搭建平台) 进行开发。
二、技术实现
整体流程:
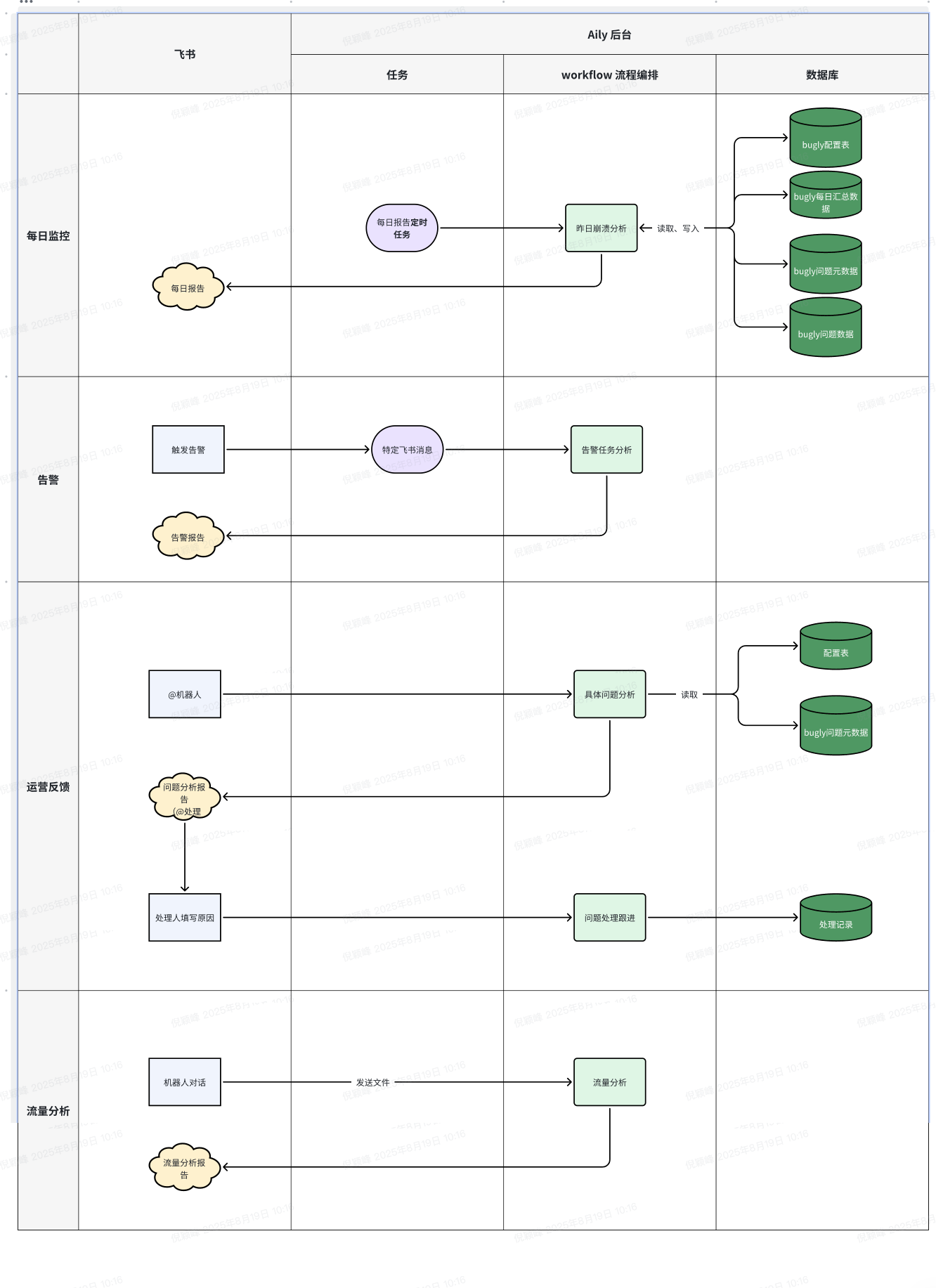
智能监控
智能监控主要覆盖稳定性指标日报、告警分析、运营反馈三个场景:
- 客户端开发人员均需了解并重视 App 稳定性数据;然而,日常多数开发人员不会主动访问 bugly 后台,因此期望以更简化、更轻量的方式促使大家参与其中。
- 稳定性波动在很大程度上是由线上配置变更引起的,其发生时间常处于上下班高峰期或凌晨,给排查和响应效率带来了极大阻碍,所以我们借助主动感知告警、智能分析来提升整体响应效率。
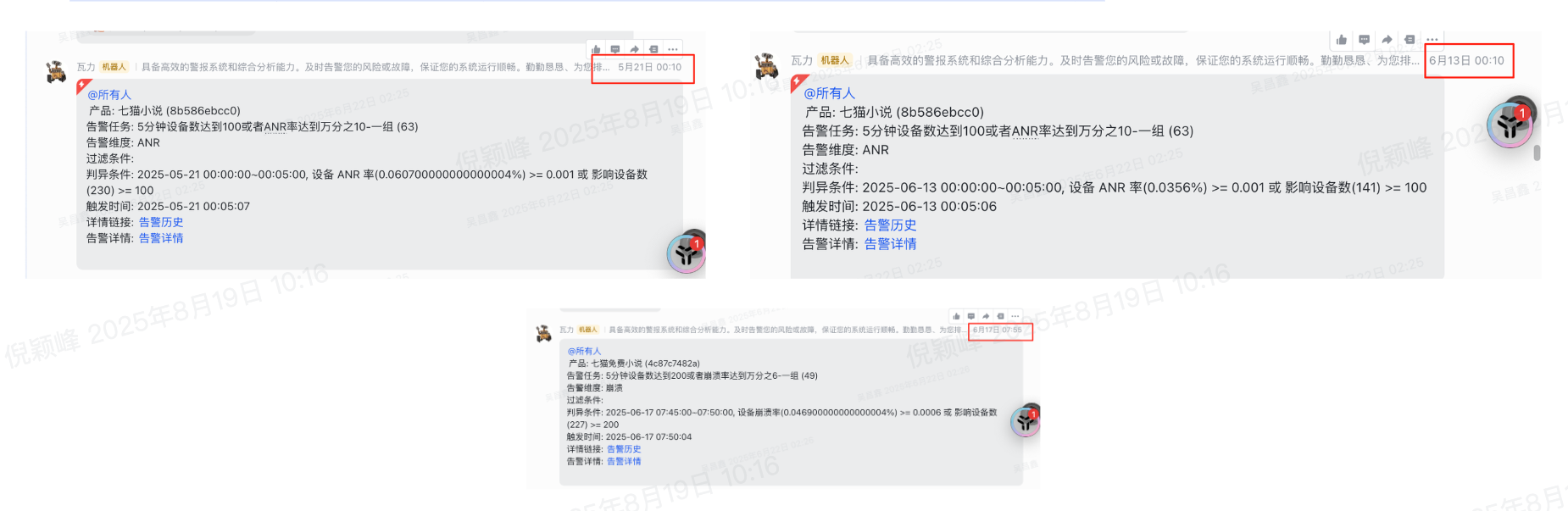
3. 当测试人员、运营人员收到用户反馈的闪退问题时,会前往 bugly 后台搜索闪退记录 -> 并在反馈群告知开发人员 -> 等待开发人员转交给具体处理人员,整个流程冗长、效率低下;通过稳定性 Agent 能够快速分析崩溃原因、找到处理人员。

智能归因
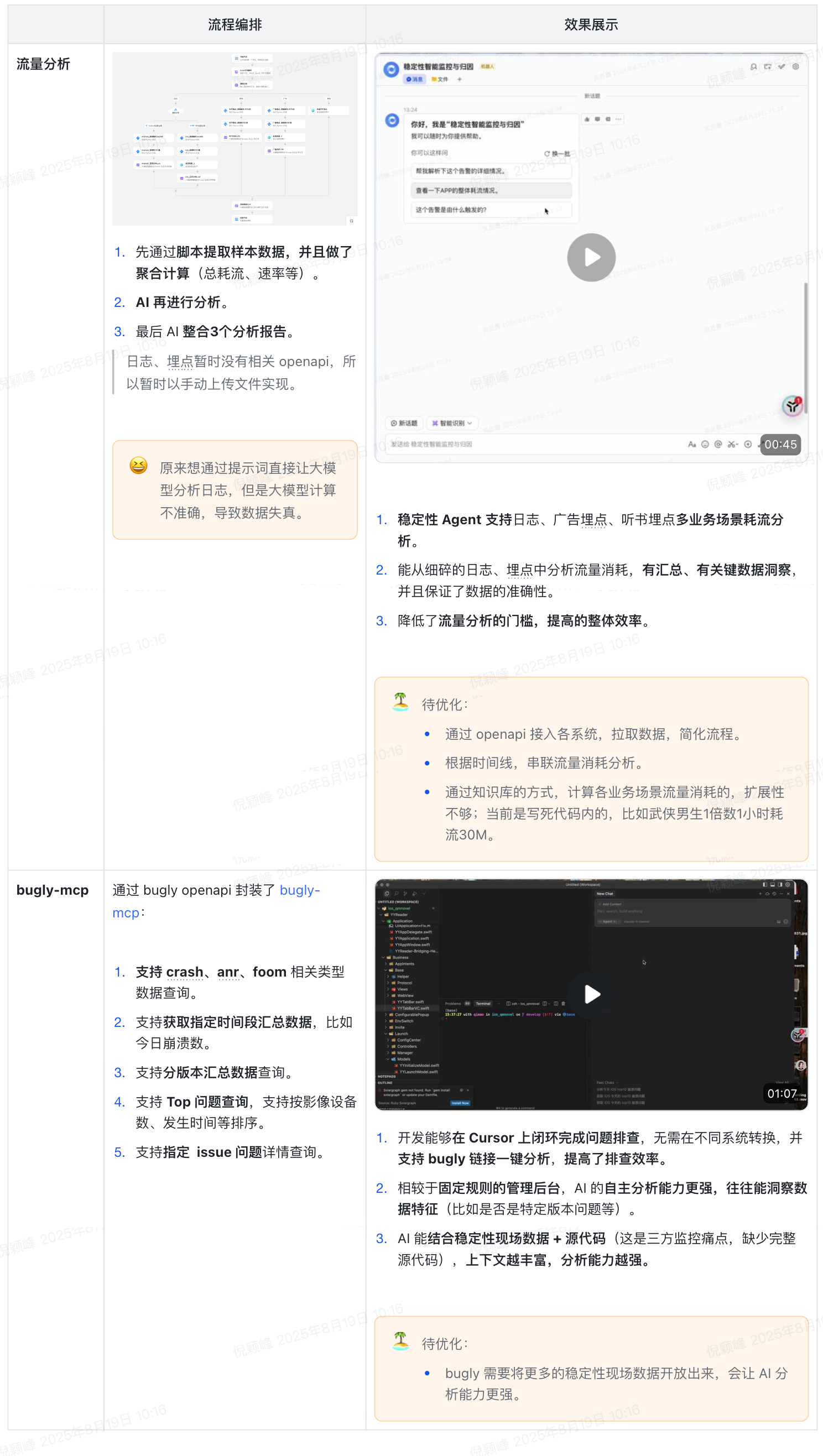
虽然我们做了大量稳定性、性能监控,但是有时候无法通过监控数据(比如崩溃堆栈)直接归因,需要结合代码、用户日志、用户埋点等进一步分析;但是各个系统都是独立的,希望通过 AI 打破数据孤岛、聚合智能归因。
- 时不时会收到用户反馈流量问题(比如1天耗流几十G,对用户伤害大),但是现在监控覆盖不全(比如受限于采样,iOS webview、流媒体播放都是独立进程、无法监控),需要结合耗流场景(广告、听书)进一步诊断分析;但是日志埋点往往数据量大,信息比较零散,人工分析耗时间;尝试通过 AI 整合多系统数据,聚合分析。
- Bugly 是三方采购的稳定性监控平台,数据本身和我们自有系统相隔离;尝试通过 bugly-mcp,整合外部系统和自有系统,聚合智能分析。
AI 本身擅长处理大量数据,并且给到充足的上下文信息,AI 的分析能力将进一步增强。
三、总结与展望
稳定性 Agent 目前尚不能算作一个智能体,其智能化程度不足,细节方面仍需进一步优化;不过,期望在传统流程的基础上对“Agent”进行升级,使其具备一定的自主性(感知与决策能力),提高效率,并且使其更加简单易用。
- 通过接入更多数据,持续提升其能力。例如,在问题跟进过程中,只需提供一个用户 ID,便能实现稳定性问题的分发、流转与跟进。
- (畅想)推动越来越多的系统实现 Agent 化,如日志系统、埋点系统等,借助多 Agent 协作来自主完成复杂任务;例如,在反馈群中,当运营反馈用户 A 出现崩溃情况时,稳定性 Agent 会立即向日志 Agent 和埋点 Agent 索要该用户的相关信息,日志 Agent 和埋点 Agent 返回相关内容后,稳定性 Agent 结合监控数据、日志以及埋点信息,自主分析出用户在何种场景下因何问题发生了崩溃。