背景
提升自然语言转换为 SQL 查询可能的3个方向有:1. Prompt 工程,以用户角色提供充足的上下文信息;2. 建设知识库,以系统角色提供上下文信息;3. 增强模型的NL2SQL能力 。
在第3个方向上,我们发现:本地部署的 deepseek-r1:32b 的 NL2SQL 的准确度与满血版的在线 deepseek-r1:671b 存在较大差距。这说明模型能力会影响 NL2SQL 准确性。
本文通过蒸馏 DeepSeek 模型,探索:通过提升模型专业能力,能够提高 NL2SQL 的准确度
蒸馏模型与探索过程
由于测试服务器的性能限制,本文采用 DeepSeek-R1-Distill-Qwen-7B 模型进行蒸馏。
本文通过对 DeepSeek-R1-Distill-Qwen-7B 模型进行本地部署,使用 NL2SQL 数据集 Spider 数据集进行训练和蒸馏,对比本地蒸馏 DeepSeek 模型与满血 DeepSeek 模型在数据集 Spider 上的转换准确度,来验证:通过提升模型专业能力,能够提高 NL2SQL 的准确度。
探索的步骤如下:
- 本地部署 DeepSeek-R1-Distill-Qwen-7B 模型
- 使用 NL2SQL 数据集:Spider 进行训练,蒸馏出模型:DeepSeek-R1-Distill-Qwen-7B__Spider
- 对比 DeepSeek-R1-Distill-Qwen-7B__Spider 与 满血在线 deepseek-r1:671b 在 Spider 数据集上的 NL2SQL 准确度。
1.本地部署 DeepSeek-R1-Distill-Qwen-7B 模型
a. 安装 Ollama
注意:设置端口和IP访问策略,保障网络安全
curl -fsSL https://ollama.com/install.sh | sh
ollama run deepseek-r1:32b
b. 下载 DeepSeek-R1-Distill-Qwen-7B 到本地
https://hf-mirror.com/deepseek-ai/DeepSeek-R1-Distill-Qwen-7B/tree/main
2. 数据集预处理
a. 下载 Spider 数据集
https://github.com/taoyds/spider/tree/master/evaluation_examples/examples
b. 使用以下 Python 脚本,将 Spider 数据集转换成 LLama-Factory 蒸馏模型需要的格式
def load_json_data(json_file_path):
with open(json_file_path, "r", encoding="utf-8") as f:
json_data = json.load(f)
return json_data
def convert_spider_to_llamafactory(spider_data):
converted_data = []
for item in spider_data:
# 将 db_id 拼接到 instruction 中
instruction = f"Using the database '{item['db_id']}', translate the following natural language question into a SQL query."
input_text = item["question"]
output_text = item["query"]
converted_item = {
"instruction": instruction,
"input": input_text,
"output": output_text
}
converted_data.append(converted_item)
return converted_data
dataset_source_file = "train_spider.json"
dataset_target_file = "llama_train_spider.json"
json_data = load_json_data(dataset_source_file)
converted_json_data = convert_spider_to_llamafactory(json_data)
# 生成 llama_train_spider.json,证
save_json_data(converted_json_data, dataset_target_file)
3. 蒸馏 DeepSeek-R1-Distill-Qwen-7B__Spider
a. 下载安装 LLaMA-Factory
git clone https://gitee.com/james-hadoop/LLaMA-Factory.git
cd LLaMA-Factory
pip install -e ".[torch,metrics]" -i https://pypi.tuna.tsinghua.edu.cn/simple
llamafactory-cli help
b. 将数据集,注册到 LLaMA-Factory
cd LLaMA-Factory
vi data/data_info.json
data_info.json 文件内容片段
{
"llama_train_spider": {
"file_name": "llama_train_spider.json"
},
"llama_chase_train": {
"file_name": "llama_chase_train.json"
},
"identity": {
"file_name": "identity.json"
},
"alpaca_en_demo": {
"file_name": "alpaca_en_demo.json"
},
"alpaca_zh_demo": {
"file_name": "alpaca_zh_demo.json"
}
}
c. 训练模型
nohup \
llamafactory-cli train \
--model_name_or_path ~/DeepSeek-R1-Distill-Qwen-7B \ # 模型的路径
--output_dir ~/DeepSeek-R1-Distill-Qwen-7B__Spider/train \ # 生成的模型路径
--dataset_dir data \
--dataset llama_train_spider \ # llama_train_spider 数据集
--cutoff_len 2048 \
--stage sft \
--do_train True \
--preprocessing_num_workers 16 \
--template deepseek3 \
--flash_attn auto \
--learning_rate 5e-05 \
--num_train_epochs 10.0 \ # 模型训练的轮数
--seed 168 \
--max_samples 100000 \
--per_device_train_batch_size 2 \
--gradient_accumulation_steps 8 \
--lr_scheduler_type cosine \
--max_grad_norm 1.0 \
--logging_steps 5 \
--save_steps 100 \
--warmup_steps 0 \
--packing False \
--report_to none \
--bf16 True \
--plot_loss True \
--trust_remote_code True \
--ddp_timeout 180000000 \
--include_num_input_tokens_seen True \
--optim adamw_torch \
--finetuning_type lora \
--lora_rank 8 \
--lora_alpha 16 \
--lora_dropout 0 \
--lora_target all \
&
```d. 模型训练成功后,编辑模型导出配置文件
cd LLaMA-Factory/examples/merge_lora
vi deepseek_r1_7b__spider.yaml
deepseek_r1_7b__spider.yaml 文件内容
### Note: DO NOT use quantized model or quantization_bit when merging lora adapters
### model
model_name_or_path: ~/DeepSeek-R1-Distill-Qwen-7B # 基准模型的路径
adapter_name_or_path: ~/DeepSeek-R1-Distill-Qwen-7B__Spider/train # 训练生成的模型的路径
template: llama3
trust_remote_code: true
### export
export_dir: ~/DeepSeek-R1-Distill-Qwen-7B__Spider/export # 模型导出的路径
export_size: 5
export_device: cpu
export_legacy_format: false
这个步骤执行成功之后,将会在 ~/DeepSeek-R1-Distill-Qwen-7B__Spider/export 这个路径下生成蒸馏后的模型。
4. 将 Hugging Face 模型转换成 Ollama 模型
由于上述步骤生成的模型是 Hugging Face 模型,而本文选择了 Ollama + AnythingLLM 作为演示工具,因此需要将 HF 模型转换成 Ollma 模型。
a. 下载部署llama.cpp
git clone https://gitee.com/shuilongying/llama.cpp.git
cd llama.cpp
mkdir build
cd build
cmake ..
make
b. 将 HF 模型转换成 Ollama 模型
cd llama.cpp
python convert_hf_to_gguf.py ~/DeepSeek-R1-Distill-Qwen-7B__Spider/export
c. Ollama 加载模型
ollama create DeepSeek-R1-Distill-Qwen-7B__Spider -f ./Modelfile
d. 使用 AnythingLLM 验证模型正常使用
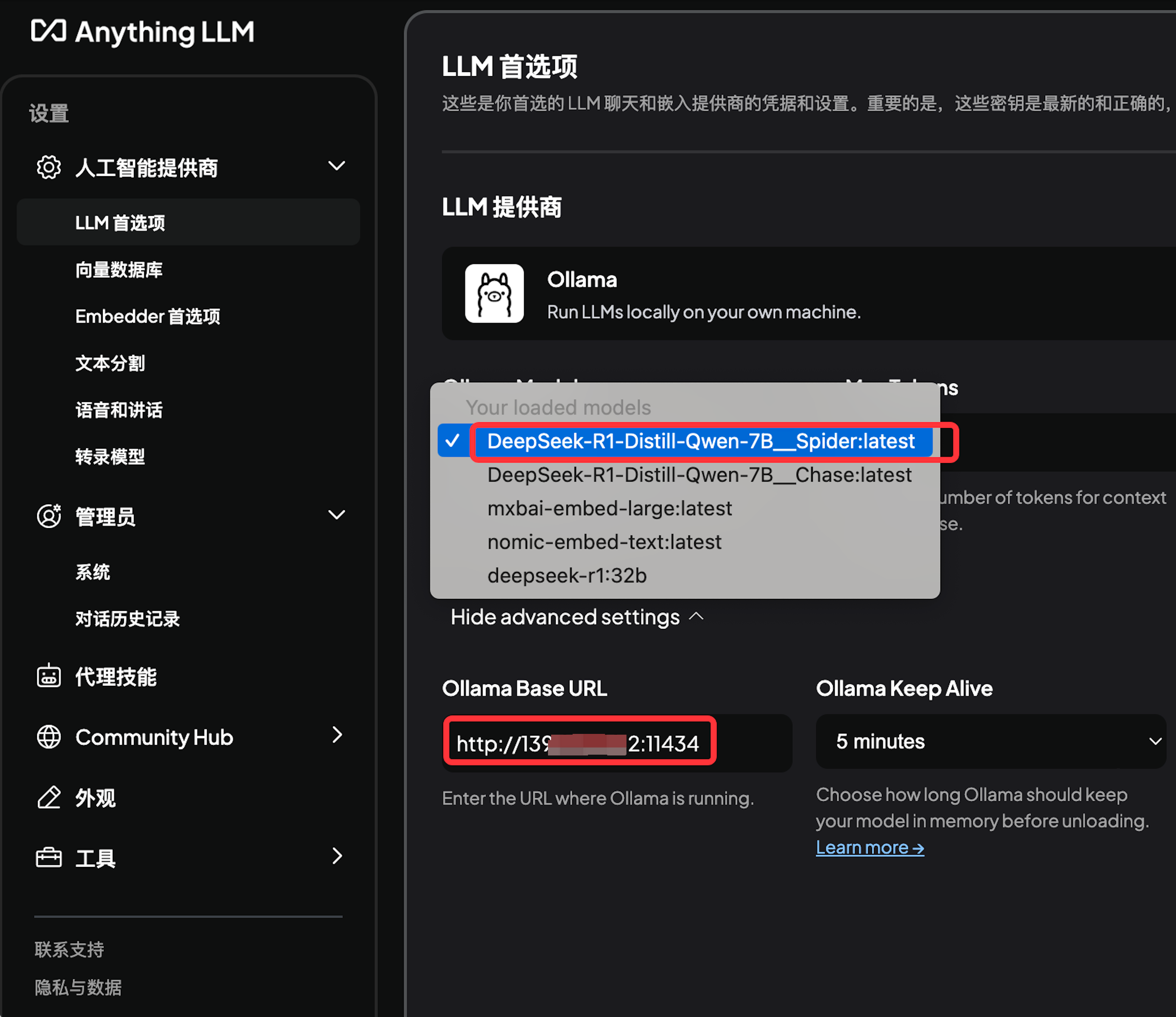
5. 效果对比
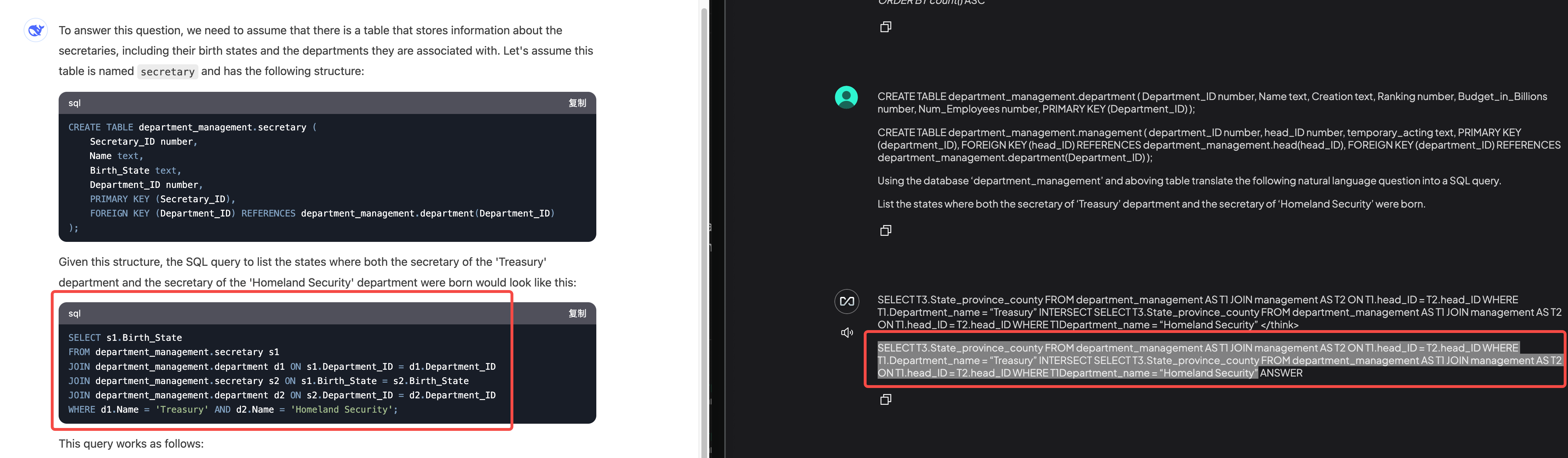
通过下面满血 DeepSeek 与 蒸馏 DeepSeek 模型生成的 SQL 可以发现:在 Spider 数据集上进行 NL2SQL,蒸馏模型的准确度更高。
标准答案SQL
-- 标准答案来自 Spider 数据集
SELECT T3.born_state FROM department AS T1 JOIN management AS T2 ON T1.department_id = T2.department_id JOIN head AS T3 ON T2.head_id = T3.head_id WHERE T1.name = 'Treasury' INTERSECT SELECT T3.born_state FROM department AS T1 JOIN management AS T2 ON T1.department_id = T2.department_id JOIN head AS T3 ON T2.head_id = T3.head_id WHERE T1.name = 'Homeland Security'
满血 DeepSeek(左) Vs 蒸馏 DeepSeek(右)
与左边满血 DeepSeek 相比,右边的蒸馏 DeepSeek 模型与上面的标准答案 SQL 更接近。
结论
- 通过效果对比,可以看出,经过本地蒸馏出来的 DeepSeek 模型在特定的语言环境下,效果比满血版的 DeepSeek 模型更好。
- 训练和蒸馏本地 deepseek-r1 模型,提升 NL2SQL 准确度技术上是可行的。
展望
- 由于测试环境显存限制(22GB左右),本文基于 DeepSeek-R1-Distill-Qwen-7B 模型进行蒸馏,模型能力上限不高。如果使用显存更大的环境来蒸馏模型,能够提升模型能力的上限,提升 NL2SQL 的准确度。
- 在使用蒸馏模型的同时,建设元数据知识库、提供更加充分且准确的上下文信息,是进一步提升 NL2SQL 的准确度的方向。