背景
StarRocks提供了高效查询和数据处理的功能。为了方便用户进行复杂的查询操作,StarRocks引入了视图和物化视图技术,在 StarRocks在七猫的应用(二)中也提到视图与物化视图的作用。
视图是一种灵活的查询工具,它可以将多个表虚拟地组合在一起。用户可以通过视图简单地执行查询操作,而无需了解底层的物理表结构和数据分布。此外,视图还可以根据用户需求进行定制,提供更灵活的查询功能。
物化视图则是用于支持多表关联和丰富的聚合操作。物化视图是预先计算并存储的视图,可以快速地执行复杂的查询操作。与视图不同,物化视图可以存储实际的数据结果,从而提升查询速度。此外,物化视图还支持多种查询重写场景,可以在查询执行时自动或透明地重写查询语句,以提高查询效率。
通过引入视图和物化视图两种技术,StarRocks实现了更高效的查询操作和更复杂的数据处理任务。这两种技术为用户提供了方便快捷的数据查询和处理服务,从而提高数据查询的整体性能和效率。
收益
1、视图
- 提升开发效率:因视图无需创建实体表,只需要在基础表上根据需求创建视图来应对业务需求,节省了创建视图表及维护表结构的时间,开发时间缩短为原来的1/3。
- 查询简化:视图可以将复杂的查询逻辑进行封装,使得查询时可以直接使用视图,无需编写复杂的查询语句。这样可以简化查询逻辑,降低查询的复杂度和难度。对于一些复杂的查询场景,使用视图可以将查询语句的长度缩短到原来的1/2。
2、物化视图
- 查询效率提升:在七猫的业务中,使用物化视图可以将预计算的结果缓存,命中缓存后查询时间由1.64s缩短至0.35s, 缩短到原来的1/5甚至更短(性能测试见下文)。
- 数据一致性提高:物化视图是基于基表的预计算结果,因此可以确保数据的一致性。当基表的数据发生变化时,物化视图会进行相应的更新,以保证数据的准确性。这样可以避免由于数据不一致而导致的问题,提高数据的可信度和准确性。
要了解物化视图可以先了解视图的概念。视图是一个虚拟表(可以认为是一条SQL语句),基于它创建时指定的查询语句返回的结果集。而物化视图则是将这个虚拟表进行实体化,其本身可以理解为是一个特殊的表。
视图
概念
StarRocks的视图功能强大,支持标准SQL语法,包括聚合、JOIN、排序、窗口函数和自定义函数等功能。视图是一种虚拟的表,它不占用物理存储空间。
图例
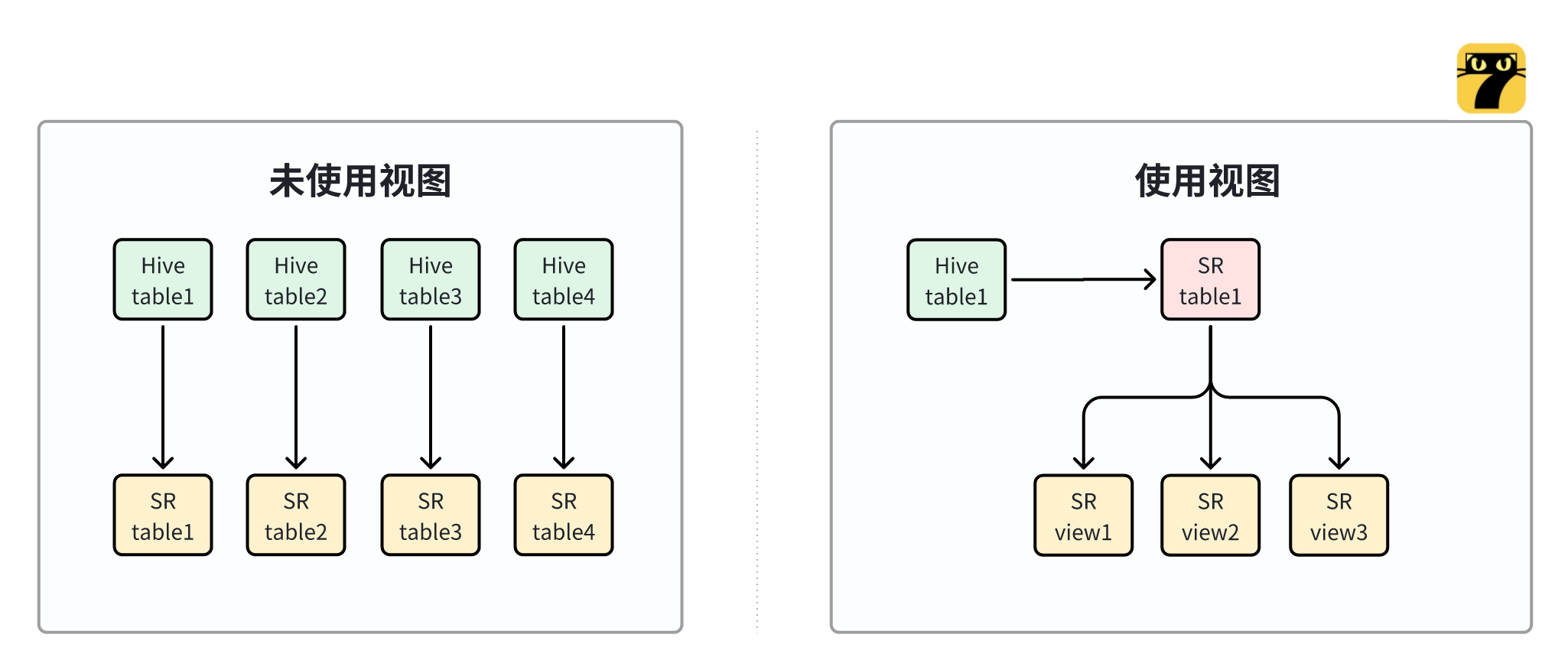
图1右图相比于图1左图的优势:
- 保障数据一致性:通过在Hive中只计算一次数据,并将结果存储在StarRocks中,可以确保数据的一致性。这是因为所有基于该数据的查询都将使用相同的源数据,从而避免了在不同的视图或物化视图中可能出现的任何不一致。
- 节省物理存储空间:由于只计算一次数据并将结果存储在StarRocks中,因此可以节省大量的存储空间。原本需要在Hive中存储的4份数据现在只存储一份,降低了存储的需求。
- 对前端查询使用没有差别:虽然底层的数据计算和存储方式发生了改变,但对前端查询使用没有任何差别。前端应用仍然可以像往常一样发送查询请求,无需关心底层的处理逻辑。
- 可快速调整逻辑:当发现视图逻辑存在问题时,由于查询语句的灵活性,可以快速地进行调整,而无需像在Hive中那样更改建表语句或封装逻辑代码,从而节省了时间和精力。
物化视图
概念
StarRocks 中的物化视图仅能基于基础表创建,是一种特殊的查询加速索引,可提升查询效率。
图例
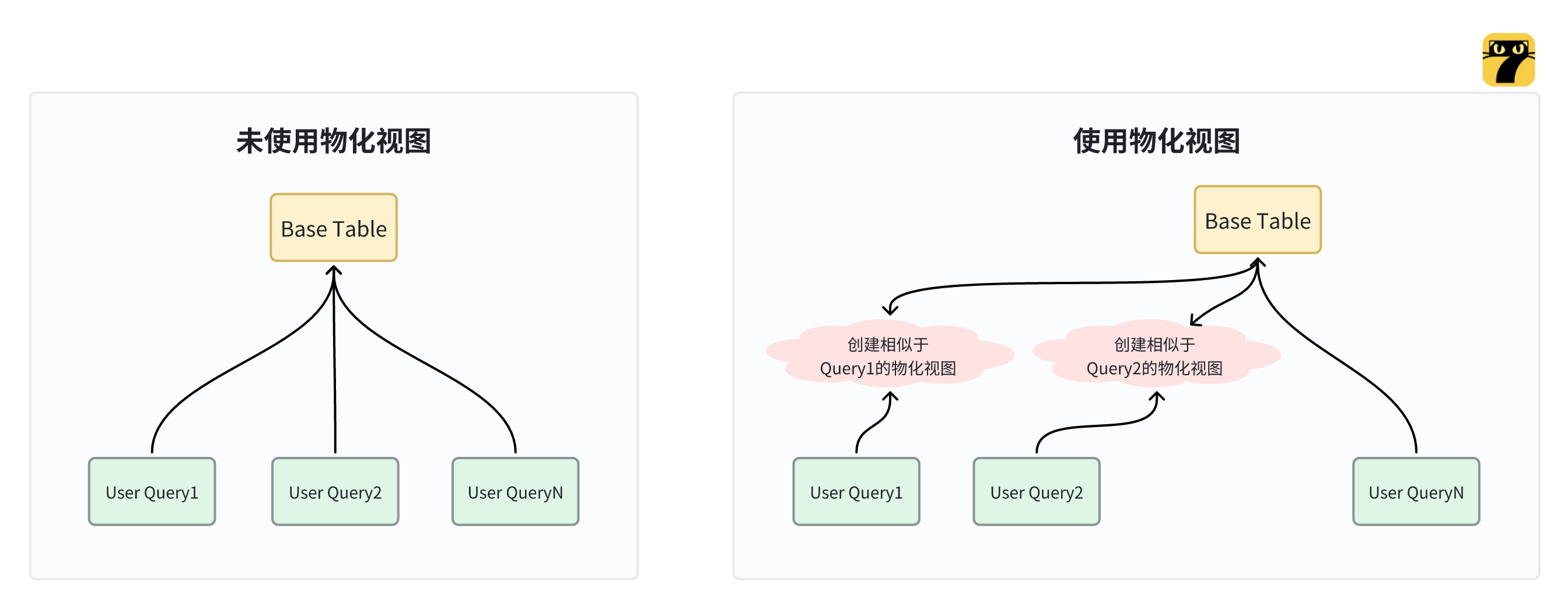
图2左图是未使用物化视图,查询语句直接查询基础表,图2右图在创建物化视图后,当查询语句命中物化视图后,其直接走物化视图生成数据直接查询数据,因物化视图中存储了结果数据,可直接返回数据,效率大幅提升。
特点StarRocks的物化视图具有以下特点:
- 预先计算生成预聚合表,用于加速聚合类查询请求;
- 在数据导入时自动完成数据汇聚,与原始表数据保持一致;
- 在查询时无需特别指定物化视图,系统会自动选择最优的物化视图来满足查询请求。
StarRocks的物化视图分为同步物化视图和异步物化视图,相较于同步物化视图,异步物化视图支持多表关联以及更加丰富的聚合算子。异步物化视图可以通过手动调用或定时任务的方式刷新,并且支持刷新部分分区,可以大幅降低刷新成本。除此之外,异步物化视图支持多种查询改写场景,实现自动、透明查询加速。
实现原理
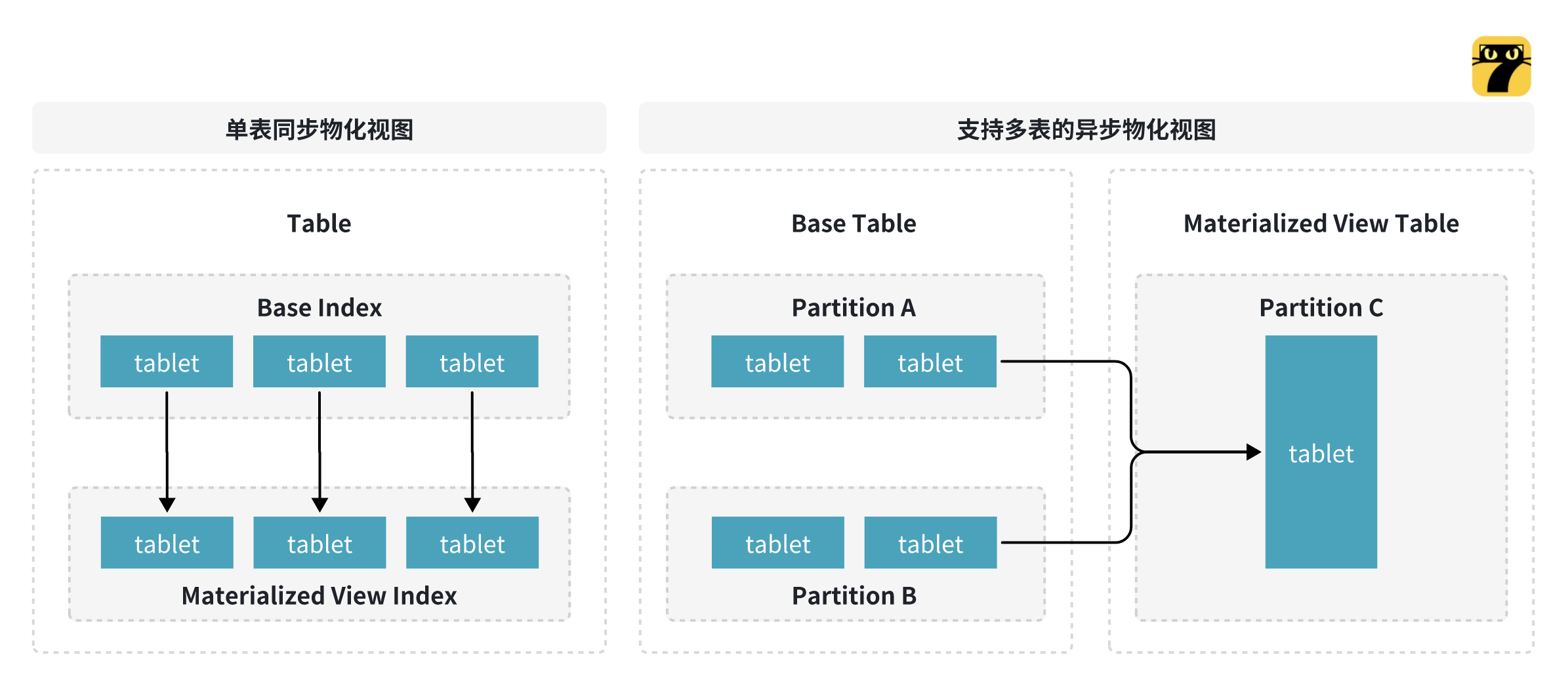
先来了解一下多表物化视图的框架,即数据模型。在早期的版本中,我们实际上支持的是单表同步物化视图,也就是我们基于一个原始表去创建物化视图,实际上物化视图是以索引的形式去存在的。
在图3左图中可以看到表的基础索引中的 Tablet 和物化视图索引的 Tablet 是一一对应,但是在多表异步的物化视图的框架中,Tablet 不是一一的对应关系,物化视图实际上是以表的模型去做实现的。以图3右图为例,假设 Base 表有两个 Partition A 和 B,假设物化视图有 Partition C,那么 Partition A、Partition B 的 Tablet 和物化视图的 Partition C 中的 Tablet 是映射关系,这种关系不是一一对应的关系。
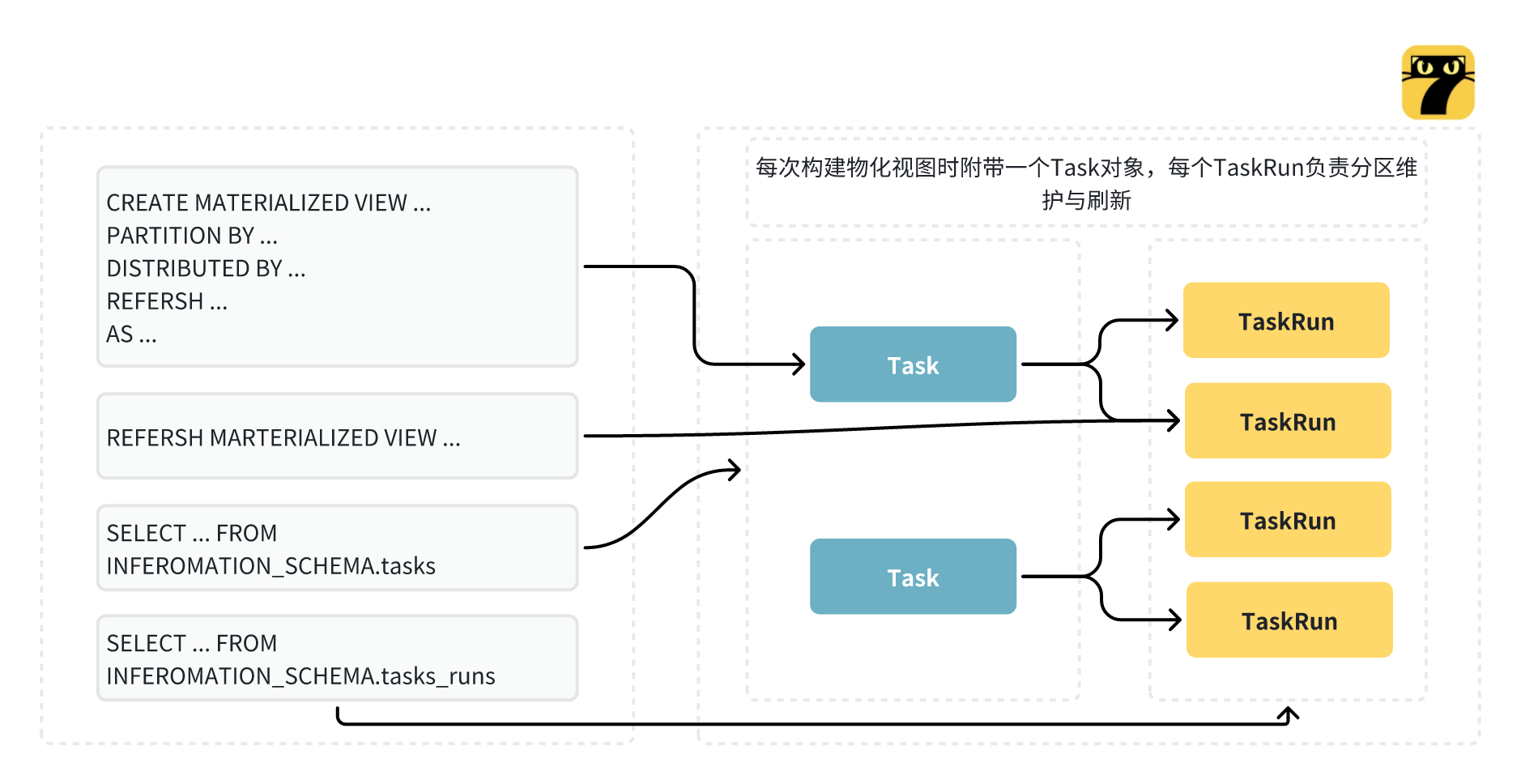
再来看一下物化视图的整体框架。在新的版本中主要实现了多表异步物化视图,那么就需要一个异步物化视图的调度框架及相应的一些实现逻辑。以图4举例,比如在创建物化视图以及刷新物化视图的时候,都需要有对应的 Task,以及 TaskRun 执行单元去做相应的处理。
下表从支持的特性角度比较了 StarRocks 中的异步物化视图以及同步物化视图:
| 单表聚合 | 多表关联 | 查询改写 | 刷新策略 | 基表 | |
| 异步物化视图 | 是 | 是 | 是 | 异步刷新手动刷新 | 支持多表构建。基表可以来自:Default CatalogExternal Catalog(v2.5)已有异步物化视图(v2.5)已有视图(v3.1) |
| 同步物化视图 | 仅部分聚合函数 | 否 | 是 | 导入同步刷新 | 仅支持基于 Default Catalog 的单表构建 |
同步物化视图的能力
准备工作
-- 建表并导入数据
CREATE TABLE dm_test_source_uid_click_detail
(
dt date not null comment '日期分区',
source_uid varchar(65533) not null comment '用户归因id',
experiment_user_total_click_count bigint(20) null comment '实验用户当天总点击次数',
is_new_user int(11) null comment '是否新增用户'
) ENGINE=OLAP
DUPLICATE KEY (`dt`,`source_uid`)
COMMENT '同步物化视图测试数据'
PARTITION BY RANGE (dt)(
START ("2023-06-01") END ("2024-12-31") EVERY (INTERVAL 1 day) )
DISTRIBUTED BY HASH(source_uid) BUCKETS 5
PROPERTIES (
"replication_num" = "1",
"in_memory" = "false",
"storage_format" = "DEFAULT",
"enable_persistent_index" = "true",
"compression" = "ZSTD",
"dynamic_partition.enable" = "true", -- 动态分区
"dynamic_partition.time_unit" = "DAY",
"dynamic_partition.end" = "3",-- ⾃动创建后3天分区
"dynamic_partition.prefix" = "p", -- 分区前缀
"dynamic_partition.buckets" = "120" -- ⾃动创建的分区buckets
);性能测试
MySQL [edw_dm]> select source_uid, sum(experiment_user_total_click_count) as total_click_count
-> from dm_test_source_uid_click_detail
-> group by source_uid
-> order by sum(experiment_user_total_click_count) desc
-> limit 10;
+----------------------------------------------+-------------------+
| source_uid | total_click_count |
+----------------------------------------------+-------------------+
| 020000000000 | 435834 |
| DU1Q0ESbb92e4SwEiF8k0viUzWFE4q0aNi20RFUxUTBFU2JiOTJlNFN3RWlGOGswdmlVeldGRTRxMGFOaTIwc2h1 | 142483 |
| 2CFDAB840D47 | 142307 |
| b4c3032d-10ea-473a-a7ca-c836c1365785 | 63772 |
| 862127048826166 | 41989 |
| DU-bWjbd2pwGP2qaXy_fMaQluuMPs_ABa139RFUtYldqYmQycHdHUDJxYVh5X2ZNYVFsdXVNUHNfQUJhMTM5c2h1 | 39446 |
| DUTTgkzs9uYuEDU6BZZUoUD_3kCcYTsWNn20RFVUVGdrenM5dVl1RURVNkJaWlVvVURfM2tDY1lUc1dObjIwc2h1 | 34036 |
| 60AB67DAD2C7 | 26822 |
| 864795045425790 | 26124 |
| 3159E77CA8B849EB87F1BEAEC84C1BB057f9ad9276174b854e485283cfd4c5d2 | 25563 |
+------------- --------------------------------+-------------------+
10 rows in set (1.64 sec)查看执行计划
-- Query Profile
MySQL [edw_dm]> EXPLAIN select source_uid, sum(experiment_user_total_click_count) as total_click_count
-> from dm_test_source_uid_click_detail
-> group by source_uid
-> order by sum(experiment_user_total_click_count) desc
-> limit 10;
+-------------------------------------------------------------+
| Explain String |
+-------------------------------------------------------------+ |
| 0:OlapScanNode |
| TABLE: dm_test_source_uid_click_detail |
| PREAGGREGATION: ON |
| partitions=7/579 |
| rollup: dm_test_source_uid_click_detail |
| tabletRatio=35/35 |
| tabletList=36675955,36675957,36675959,36675961,36675963,36676095,36676097,36676099,36676101,36676103 ... |
| cardinality=104442511 |
| avgRowSize=2.0 |
| numNodes=0 |
+-- -----------------------------------------------------------+
51 rows in set (0.00 sec)
可以看到,此时查询时间为 1.64 秒,其 Query Profile 中的 rollup 项显示为 dm_test_source_uid_click_detail(即基础表),说明该查询未使用物化视图加速。
创建同步物化视图
create MATERIALIZED view dm_test_source_uid_click_detail_view as
select source_uid, sum(experiment_user_total_click_count) as total_click_count
from dm_test_source_uid_click_detail
group by source_uid查看同步物化视图构建状态
MySQL [edw_dm]> SHOW ALTER MATERIALIZED VIEW\G;
*************************** 1. row ***************************
JobId: 36680962
TableName: dm_test_source_uid_click_detail
CreateTime: 2023-10-08 15:11:51
FinishedTime: 2023-10-08 15:12:23
BaseIndexName: dm_test_source_uid_click_detail
RollupIndexName: dm_test_source_uid_click_detail_view
RollupId: 36680963
TransactionId: 10249873
State: FINISHED
Msg:
Progress: NULL
Timeout: 86400
1 row in set (0.08 sec)再次执行查询操作
MySQL [edw_dm]> select source_uid, sum(experiment_user_total_click_count) as total_click_count
-> from dm_test_source_uid_click_detail
-> group by source_uid
-> order by sum(experiment_user_total_click_count) desc
-> limit 10;
+-------------------------------------+-------------------+
| source_uid | total_click_count |
+-------------------------------------+-------------------+
| 020000000000 | 435834 |
| DU1Q0ESbb92e4SwEiF8k0viUzWFE4q0aNi20RFUxUTBFU2JiOTJlNFN3RWlGOGswdmlVeldGRTRxMGFOaTIwc2h1 | 142483 |
| 2CFDAB840D47 | 142307 |
| b4c3032d-10ea-473a-a7ca-c836c1365785 | 63772 |
| 862127048826166 | 41989 |
| DU-bWjbd2pwGP2qaXy_fMaQluuMPs_ABa139RFUtYldqYmQycHdHUDJxYVh5X2ZNYVFsdXVNUHNfQUJhMTM5c2h1 | 39446 |
| DUTTgkzs9uYuEDU6BZZUoUD_3kCcYTsWNn20RFVUVGdrenM5dVl1RURVNkJaWlVvVURfM2tDY1lUc1dObjIwc2h1 | 34036 |
| 60AB67DAD2C7 | 26822 |
| 864795045425790 | 26124 |
| 3159E77CA8B849EB87F1BEAEC84C1BB057f9ad9276174b854e485283cfd4c5d2 | 25563 |
+------------------------------------+-------------------+
10 rows in set (0.35 sec) 可以看到,此时查询时间已经缩短为 0.35 秒。
查看执行计划
MySQL [edw_dm]> EXPLAIN select source_uid, sum(experiment_user_total_click_count) as total_click_count
-> from dm_test_source_uid_click_detail
-> group by source_uid
-> order by sum(experiment_user_total_click_count) desc
-> limit 10;
+---------------------------------------------------------+
| Explain String |
+---------------------------------------------------------+ |
| 0:OlapScanNode |
| TABLE: dm_test_source_uid_click_detail |
| PREAGGREGATION: OFF. Reason: Aggregate Operator not match: SUM <--> NONE |
| partitions=7/579 |
| rollup: dm_test_source_uid_click_detail_view |
| tabletRatio=35/35 |
| tabletList=36681934,36681936,36681938,36681940,36681942,36681924,36681926,36681928,36681930,36681932 ... |
| cardinality=187279486 |
| avgRowSize=2.0 |
| numNodes=0 |
+---------------------------------------------------------+
51 rows in set (0.01 sec)
可以看到,在查询SQL不变的情况下, Query Profile 中的 rollup 项显示为 dm_test_source_uid_click_detail_view(即同步物化视图),说明该查询已命中同步物化视图。
由此可见,使用物化视图可以加速查询效率。
删除物化视图在以下三种情况下,您需要删除同步物化视图:
- 同步物化视图创建错误,需要删除正在创建中的同步物化视图。
- 创建了大量的同步物化视图,导致数据导入速度过慢,并且部分同步物化视图重复。
- 相关查询频率较低,且业务场景可容忍较高的查询延迟。
删除正在创建的同步物化视图
可以通过取消正在进行的同步物化视图创建任务删除正在创建的同步物化视图。首先需要通过查看同步物化视图构建状态 获取该同步物化视图的任务 ID JobId。得到任务 ID 后,需要通过 CANCEL ALTER 命令取消该创建任务。
CANCEL ALTER TABLE ROLLUP FROM dm_test_source_uid_click_detail_view (12090);删除已创建的同步物化视图
可以通过 DROP MATERIALIZED VIEW 命令删除已创建的同步物化视图。
DROP MATERIALIZED VIEW dm_test_source_uid_click_detail_view;异步物化视图的能力
本次介绍异步物化视图的【查询改写加速查询效率】的能力,其他能力请参考异步物化视图 @ Materialized_view
StarRocks 的异步物化视图采用了主流的基于 SPJG(select-project-join-group-by)模式透明查询改写算法。在不修改查询语句的前提下,StarRocks 可以自动将在基表上的查询改写为在物化视图上的查询。通过其中包含的预计算结果,物化视图可以帮助您显著降低计算成本,并大幅加速查询执行。
基于异步物化视图的查询改写功能,在以下场景下特别有用:
1、指标预聚合
如果您需要处理高维度数据,可以使用物化视图来创建预聚合指标层。
2、宽表 Join
物化视图允许您在复杂场景下下透明加速包含大宽表 Join 的查询。
3、数据湖加速
构建基于 External Catalog 的物化视图可以轻松加速针对数据湖中数据的查询。
StarRocks 的异步物化视图自动查询改写功能具有以下特点:
- 强数据一致性:如果基表是 StarRocks 内表,StarRocks 可以保证通过物化视图查询改写获得的结果与直接查询基表的结果一致。
- 多表 Join:StarRocks 的异步物化视图支持各种类型的 Join,包括一些复杂的 Join 场景,如 View Delta Join 和 Join 派生改写,可用于加速涉及大宽表的查询场景。
- Union 改写:可以将 Union 改写特性与物化视图分区的生存时间相结合,实现冷热数据的分离,允许从物化视图查询热数据,从基表查询历史数据。
- 基于视图构建物化视图:可以在基于视图建模的情景下加速查询。
- 基于 External Catalog 构建物化视图:可以通过该特性加速数据湖中的查询。
基于查询语句创建异步物化视图
可以通过 CREATE MATERIALIZED VIEW 语句为特定查询语句创建物化视图。
以下示例根据上述查询语句,基于表 goods 和表 order_list 创建一个“以订单 ID 为分组,对订单中所有商品价格求和”的异步物化视图,并设定其刷新方式为 ASYNC,每天自动刷新。
CREATE MATERIALIZED VIEW order_mv
DISTRIBUTED BY HASH(`order_id`)
REFRESH ASYNC START('2022-09-01 10:00:00') EVERY (interval 1 day)AS SELECT
order_list.order_id,sum(goods.price) as total
FROM order_list INNER JOIN goods ON goods.item_id1 = order_list.item_id2
GROUP BY order_id;说明:
- 创建异步物化视图时必须至少指定分桶和刷新策略其中之一。
- 您可以为异步物化视图设置与其基表不同的分区和分桶策略,但异步物化视图的分区列和分桶列必须在查询语句中。
- 异步物化视图支持分区上卷。例如,基表基于天做分区方式,您可以设置异步物化视图按月做分区。
- 异步物化视图暂不支持使用 List 分区策略,亦不支持基于使用 List 分区的基表创建。
- 创建物化视图的查询语句不支持非确定性函数,其中包括 rand()、random()、uuid() 和 sleep()。
- 异步物化视图支持多种数据类型。
- 默认情况下,执行 CREATE MATERIALIZED VIEW 语句后,StarRocks 将立即开始刷新任务,这将会占用一定系统资源。如需推迟刷新时间,请添加 REFRESH DEFERRED 参数。
- 异步物化视图刷新机制
- 目前,StarRocks 支持两种 ON DEMAND 刷新策略,即异步刷新(ASYNC)和手动刷新(MANUAL)。
- 在此基础上,异步物化视图支持多种刷新机制控制刷新开销并保证刷新成功率:
1、支持设置刷新最大分区数。当一张异步物化视图拥有较多分区时,单次刷新将耗费较多资源。您可以通过设置该刷新机制来指定单次刷新的最大分区数量,从而将刷新任务进行拆分,保证数据量多的物化视图能够分批、稳定的完成刷新。
2、支持为异步物化视图的分区指定 Time to Live(TTL),从而减少异步物化视图占用的存储空间。
3、支持指定刷新范围,只刷新最新的几个分区,减少刷新开销。
4、支持设置数据变更不会触发对应物化视图自动刷新的基表。
5、支持为刷新任务设置资源组。
为避免全量刷新任务耗尽系统资源导致任务失败,建议您基于分区基表创建分区物化视图,保证基表分区中的数据更新时,只有物化视图对应的分区会被刷新,而非刷新整个物化视图。
手动刷新异步物化视图
可以通过 REFRESH MATERIALIZED VIEW 命令手动刷新指定异步物化视图。StarRocks v2.5 版本中,异步物化视图支持手动刷新部分分区。在 v3.1 版本中,StarRocks 支持同步调用刷新任务。
-- 异步调用刷新任务。
REFRESH MATERIALIZED VIEW order_mv;-- 同步调用刷新任务。
REFRESH MATERIALIZED VIEW order_mv WITH SYNC MODE;可以通过 CANCEL REFRESH MATERIALIZED VIEW 取消异步调用的刷新任务。
直接查询异步物化视图
异步物化视图本质上是一个物理表,其中存储了根据特定查询语句预先计算的完整结果集。在物化视图第一次刷新后,您即可直接查询物化视图。
MySQL > SELECT * FROM order_mv;
+----------+--------------------+
| order_id | total |
+----------+--------------------+
| 10001 | 14.5 |
| 10002 | 10.200000047683716 |
| 10003 | 8.700000047683716 |
+----------+--------------------+
3 rows in set (0.01 sec)注:可以直接查询异步物化视图,但由于异步刷新机制,其结果可能与从基表上查询的结果不一致。
Join 改写
StarRocks 支持改写具有各种类型 Join 的查询,包括 Inner Join、Cross Join、Left Outer Join、Full Outer Join、Right Outer Join、Semi Join 和 Anti Join。 以下示例展示 Join 查询的改写。创建以下基表:
CREATE TABLE customer (
c_custkey INT(11) NOT NULL,
c_name VARCHAR(26) NOT NULL,
c_address VARCHAR(41) NOT NULL,
c_city VARCHAR(11) NOT NULL,
c_nation VARCHAR(16) NOT NULL,
c_region VARCHAR(13) NOT NULL,
c_phone VARCHAR(16) NOT NULL,
c_mktsegment VARCHAR(11) NOT NULL) ENGINE=OLAP
DUPLICATE KEY(c_custkey)DISTRIBUTED BY HASH(c_custkey) BUCKETS 12;
CREATE TABLE lineorder (
lo_orderkey INT(11) NOT NULL,
lo_linenumber INT(11) NOT NULL,
lo_custkey INT(11) NOT NULL,
lo_partkey INT(11) NOT NULL,
lo_suppkey INT(11) NOT NULL,
lo_orderdate INT(11) NOT NULL,
lo_orderpriority VARCHAR(16) NOT NULL,
lo_shippriority INT(11) NOT NULL,
lo_quantity INT(11) NOT NULL,
lo_extendedprice INT(11) NOT NULL,
lo_ordtotalprice INT(11) NOT NULL,
lo_discount INT(11) NOT NULL,
lo_revenue INT(11) NOT NULL,
lo_supplycost INT(11) NOT NULL,
lo_tax INT(11) NOT NULL,
lo_commitdate INT(11) NOT NULL,
lo_shipmode VARCHAR(11) NOT NULL) ENGINE=OLAP
DUPLICATE KEY(lo_orderkey)DISTRIBUTED BY HASH(lo_orderkey) BUCKETS 48;基于上述基表,创建以下物化视图:
CREATE MATERIALIZED VIEW join_mv1
DISTRIBUTED BY HASH(lo_orderkey)AS
SELECT lo_orderkey, lo_linenumber, lo_revenue, lo_partkey, c_name, c_address
FROM lineorder INNER JOIN customer
ON lo_custkey = c_custkey;该物化视图可以改写以下查询:
SELECT lo_orderkey, lo_linenumber, lo_revenue, c_name, c_address
FROM lineorder INNER JOIN customer
ON lo_custkey = c_custkey;
其原始查询计划和改写后的计划如下:

StarRocks 支持改写具有复杂表达式的 Join 查询,如算术运算、字符串函数、日期函数、CASE WHEN 表达式和谓词 OR 等。例如,上述物化视图可以改写成以下查询:
SELECT
lo_orderkey,
lo_linenumber,
(2 * lo_revenue + 1) * lo_linenumber,
upper(c_name),
substr(c_address, 3) FROM join_mv1;聚合改写
StarRocks 异步物化视图的多表聚合查询改写支持所有聚合函数,包括 bitmap_union、hll_union 和 percentile_union 等。例如,创建以下物化视图:
CREATE MATERIALIZED VIEW agg_mv1
DISTRIBUTED BY hash(lo_orderkey)ASSELECT
lo_orderkey,
lo_linenumber,
c_name,
sum(lo_revenue) AS total_revenue,
max(lo_discount) AS max_discount
FROM lineorder INNER JOIN customer
ON lo_custkey = c_custkey
GROUP BY lo_orderkey, lo_linenumber, c_name;该物化视图可以改写以下查询:
SELECT
lo_orderkey,
lo_linenumber,
c_name,
sum(lo_revenue) AS total_revenue,
max(lo_discount) AS max_discount
FROM lineorder INNER JOIN customer
ON lo_custkey = c_custkey
GROUP BY lo_orderkey, lo_linenumber, c_name;其原始查询计划和改写后的计划如下:
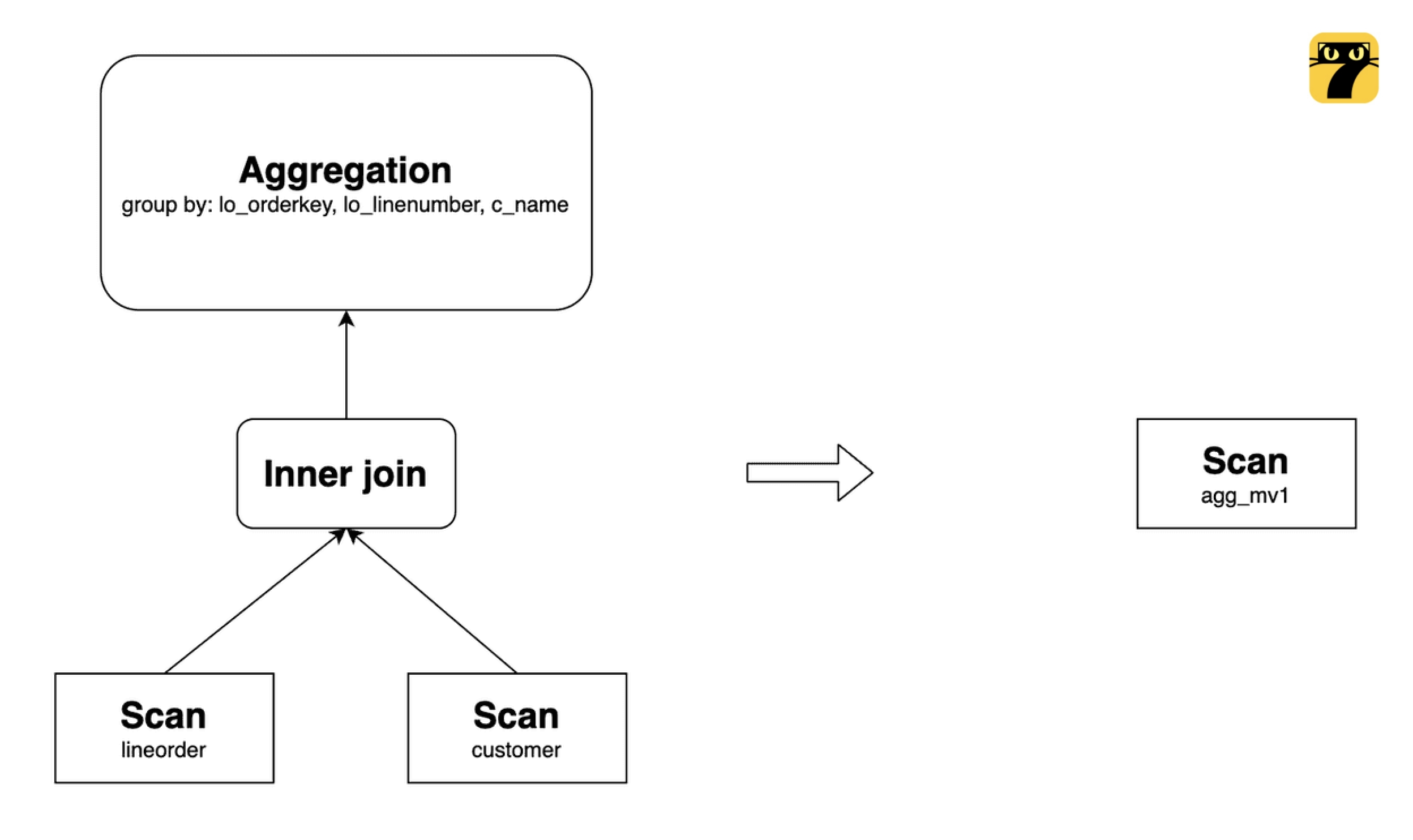
注:没有相应 GROUP BY 列的 DISTINCT 聚合无法使用聚合上卷查询改写。但是,从 StarRocks v3.1 开始,如果聚合上卷对应 DISTINCT 聚合函数的查询没有 GROUP BY 列,但有等价的谓词,该查询也可以被相关物化视图重写,因为 StarRocks 可以将等价谓词转换为 GROUP BY 常量表达式。
基于视图构建物化视图
StarRocks 支持基于视图创建物化视图。后续针对视图的查询可以被透明改写。例如,创建以下视图:
CREATE VIEW customer_view1
ASSELECT c_custkey, c_name, c_address
FROM customer;
CREATE VIEW lineorder_view1
ASSELECT lo_orderkey, lo_linenumber, lo_custkey, lo_revenue
FROM lineorder;根据以上视图创建物化视图:
CREATE MATERIALIZED VIEW join_mv1
DISTRIBUTED BY hash(lo_orderkey)AS
SELECT lo_orderkey, lo_linenumber, lo_revenue, c_name
FROM lineorder_view1 INNER JOIN customer_view1
ON lo_custkey = c_custkey;查询改写过程中,针对 customer_view1 和 lineorder_view1 的查询会自动展开到基表,然后进行透明匹配改写。
基于 External Catalog 构建物化视图
StarRocks 支持基于 Hive Catalog、Hudi Catalog 和 Iceberg Catalog 的外部数据源上构建异步物化视图,并支持透明地改写查询。基于 External Catalog 的物化视图支持大多数查询改写功能。
设置物化视图查询改写
可以通过以下 Session 变量设置异步物化视图查询改写。
| 变量 | 默认值 | 描述 |
| enable_materialized_view_union_rewrite | TRUE | 是否开启物化视图 Union 改写。 |
| enable_rule_based_materialized_view_rewrite | TRUE | 是否开启基于规则的物化视图查询改写功能,主要用于处理单表查询改写。 |
| nested_mv_rewrite_max_level | 3 | 可用于查询改写的嵌套物化视图的最大层数。类型:INT。取值范围:[1, +∞)。取值为 1 表示只可使用基于基表创建的物化视图来进行查询改写。 |
验证查询改写是否生效
可以使用 EXPLAIN 语句查看对应 Query Plan。如果其中 OlapScanNode 项目下的 TABLE 为对应异步物化视图名称,则表示该查询已基于异步物化视图改写。
mysql> EXPLAIN SELECT
order_id, sum(goods.price) AS total
FROM order_list INNER JOIN goods
ON goods.item_id1 = order_list.item_id2
GROUP BY order_id;
+------------------------------------+
| Explain String |
+------------------------------------+
| PLAN FRAGMENT 0 |
| OUTPUT EXPRS:1: order_id | 8: sum |
| PARTITION: RANDOM |
| |
| RESULT SINK |
| |
| 1:Project |
| | <slot 1> : 9: order_id |
| | <slot 8> : 10: total |
| | |
| 0:OlapScanNode |
| TABLE: order_mv |
| PREAGGREGATION: ON |
| partitions=1/1 |
| rollup: order_mv |
| tabletRatio=0/12 |
| tabletList= |
| cardinality=3 |
| avgRowSize=4.0 |
| numNodes=0 |
+------------------------------------+
20 rows in set (0.01 sec)禁用查询改写
StarRocks 默认开启基于 Default Catalog 创建的异步物化视图查询改写。您可以通过将 Session 变量 enable_materialized_view_rewrite 设置为 false 禁用该功能。对于基于 External Catalog 创建的异步物化视图,你可以通过 ALTER MATERIALIZED VIEW 将物化视图 Property force_external_table_query_rewrite 设置为 false 来禁用此功能。
限制
单就物化视图查询改写能力,StarRocks 目前存在以下限制:
- StarRocks 不支持非确定性函数的改写,包括 rand、random、uuid 以及 sleep。
- StarRocks 不支持窗口函数的改写。
- 如果物化视图定义语句中包含 LIMIT、ORDER BY、UNION、EXCEPT、INTERSECT、MINUS、GROUPING SETS、WITH CUBE 或 WITH ROLLUP,则无法用于改写。
- 基于 External Catalog 的物化视图不保证查询结果强一致。
- 基于 JDBC Catalog 表构建的异步物化视图暂不支持查询改写。
最佳实践
视图
推荐回查二期项目原本需在Hive中计算4张表后同步至StarRocks供前端展示使用,经需求分析研究后确定在Hive中只计算一张基础明细表同步至StarRocks,使用视图方式创建其余所需的表结构。视图的优势在于它们不占用物理存储空间,并且可以随基础明细表的更新而同步更新。这样可以节省Hive和StarRocks的存储空间,同时提高查询效率。
- 推荐回查所需用表明细
序号 | 来源 | 表名 | 说明 |
1 | Hive | dm_rec_xxx_inc_d | 基础明细表 |
2 | 由序号1表创建视图 | dm_rec_xxx_inc_d_view | 视图 |
3 | 由序号1表创建视图 | dm_rec_xxx_inc_d_view | 视图 |
4 | 由序号1表创建视图 | dm_rec_xxx_inc_d_view | 视图 |
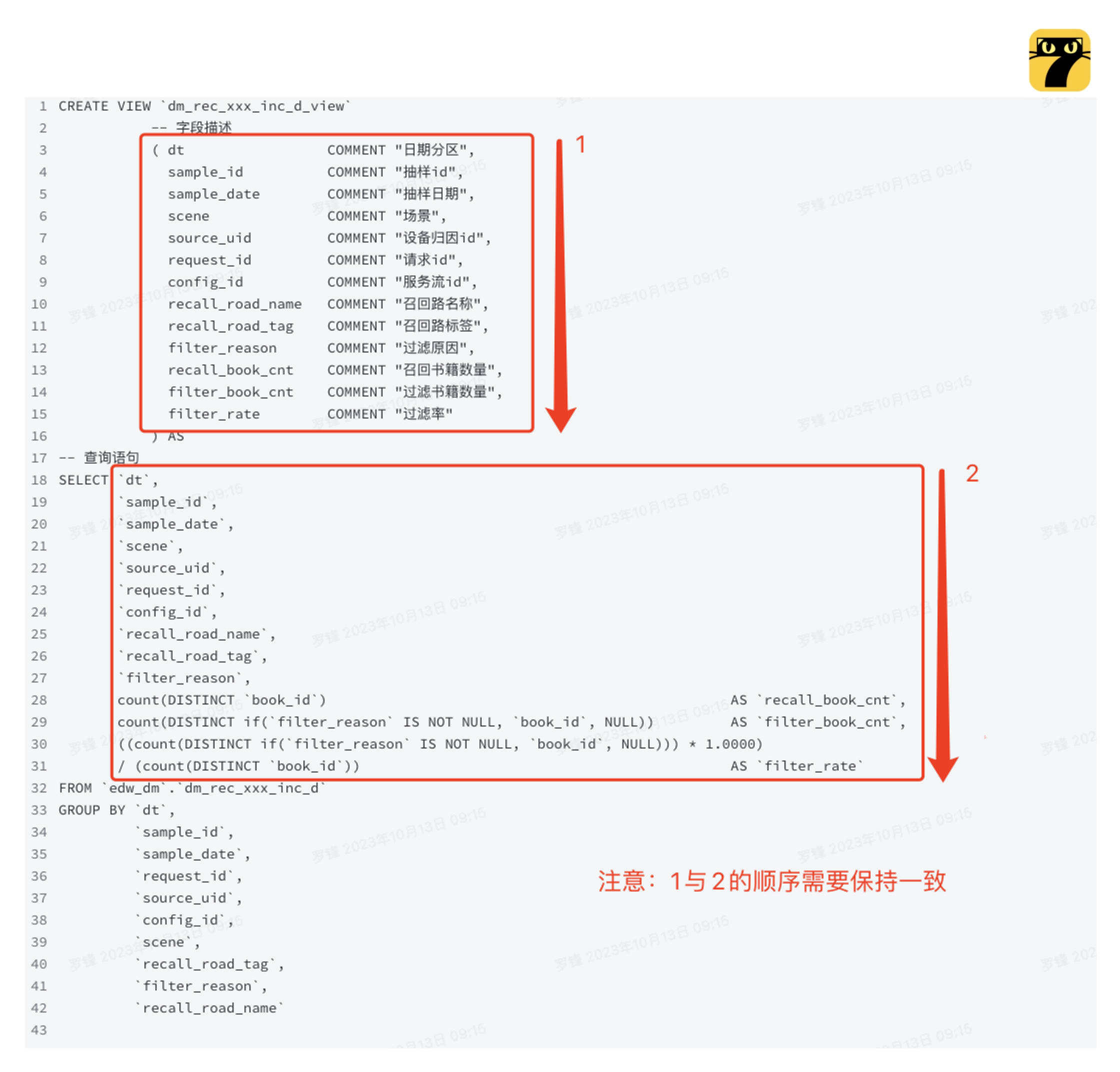
- 推荐回查视图创建语法示例
CREATE VIEW `dm_rec_xxx_inc_d_view`
-- 字段描述
( dt COMMENT "日期分区",
sample_id COMMENT "抽样id",
sample_date COMMENT "抽样日期",
scene COMMENT "场景",
source_uid COMMENT "设备归因id",
request_id COMMENT "请求id",
config_id COMMENT "服务流id",
recall_road_name COMMENT "召回路名称",
recall_road_tag COMMENT "召回路标签",
filter_reason COMMENT "过滤原因",
recall_book_cnt COMMENT "召回书籍数量",
filter_book_cnt COMMENT "过滤书籍数量",
filter_rate COMMENT "过滤率"
) AS
-- 查询语句
SELECT `dt`,
`sample_id`,
`sample_date`,
`scene`,
`source_uid`,
`request_id`,
`config_id`,
`recall_road_name`,
`recall_road_tag`,
`filter_reason`,
count(DISTINCT `book_id`) AS `recall_book_cnt`,
count(DISTINCT if(`filter_reason` IS NOT NULL, `book_id`, NULL)) AS `filter_book_cnt`,
((count(DISTINCT if(`filter_reason` IS NOT NULL, `book_id`, NULL))) * 1.0000)
/ (count(DISTINCT `book_id`)) AS `filter_rate`
FROM `edw_dm`.`dm_rec_xxx_inc_d`
GROUP BY `dt`,
`sample_id`,
`sample_date`,
`request_id`,
`source_uid`,
`config_id`,
`scene`,
`recall_road_tag`,
`filter_reason`,
`recall_road_name`
物化视图
- 精确去重以上文提到的 点击业务 相关的明细表
dm_test_source_uid_click_detail,其中记录了点击日期dt、用户 IDsource_uid、是否新增is_new_user以及点击次数experiment_user_total_click_count。
该场景需要频繁使用如下语句查询新增与非新增维度下的UV。
SELECT dt, is_new_user, count(distinct source_uid) as cnt
FROM dm_test_source_uid_click_detail
GROUP BY dt, is_new_user;如需实现精确去重查询加速,您可以基于该明细表创建一张同步物化视图,并使用 bitmap_union() 函数预先聚合数据。
CREATE MATERIALIZED VIEW active_type_uv AS
SELECT dt, is_new_user, bitmap_union(to_bitmap(source_uid))
FROM dm_test_source_uid_click_detail
GROUP BY dt, is_new_user;
同步物化视图创建完成后,后续查询语句中的子查询 count(distinct source_uid) 会被自动改写为 bitmap_union_count (to_bitmap(source_uid)) 以便查询命中物化视图。
- 近似去重以上文表
advertiser_view_record为例,如果想在查询新增与非新增维度下的UV实现近似去重查询加速,可基于该明细表创建一张同步物化视图,并使用hll_union() 函数预先聚合数据。
CREATE MATERIALIZED VIEW active_type_uv2 AS
SELECT dt, is_new_user, hll_union(hll_hash(user_id))
FROM dm_test_source_uid_click_detail
GROUP BY dt, is_new_user;- 增设前缀索引假设基表
tableA包含k1、k2和k3列,其中仅k1和k2为排序键。如果业务场景需要在查询语句中包括子查询where k3=x并通过前缀索引加速查询,那么您可以创建以k3为第一列的同步物化视图。
CREATE MATERIALIZED VIEW k3_as_key AS
SELECT k3, k2, k1
FROM tableA- 聚合函数匹配关系使用同步物化视图查询时,原始查询语句将会被自动改写并用于查询同步物化视图中保存的中间结果。下表展示了原始查询聚合函数和构建同步物化视图用到的聚合函数的匹配关系。您可以根据业务场景选择对应的聚合函数构建同步物化视图。
原始查询聚合函数 | 物化视图构建聚合函数 |
sum | sum |
min | min |
max | max |
count | count |
bitmap_union,bitmap_union_count,count(distinct) | bitmap_union |
hll_raw_agg,hll_union_agg,ndv,approx_count_distinct | hll_union |
踩坑点
- 视图创建时字段说明顺序须与查询逻辑字段顺序一致,否则会出现字段乱序问题
- 物化视图的创建数量需要适度,过多的物化视图可能会增加数据导入和更新的时间,从而影响系统的性能和效率。在实践中,我们可以通过分析查询需求和数据量来权衡物化视图的数量,以取得最佳的性能和效率平衡。在创建物化视图时,我们可以考虑以下几点:
1. 查询频率和数据量:对于使用频率较高、数据量较大的查询,可以创建相应的物化视图以加速查询。
2. 更新频率和数据量:如果基础表的数据更新频率较高,或者更新的数据量较大,可以创建较少的物化视图以减少数据更新的开销。
综合考虑以上因素,我们可以根据具体情况来确定每张表的物化视图数量,以取得最佳的性能和效率平衡。一般来说,建议每张表的物化视图数量在5个以内,但具体数量还需要根据实际需求和数据量等因素来确定。
展望未来
StarRocks在七猫未来的技术优化方向。具体来说,未来的技术优化将集中在以下几个方面:
- CBO优化器:CBO(Cost-Based Optimizer)是一种查询优化技术,它通过估算不同执行计划的代价来选择最优的查询执行计划。未来的工作中,可以进一步改进CBO优化器,使其更加准确地估计代价,从而选择更加高效的查询执行计划。
- Colocate Join:Colocate Join是一种分布式系统实现Join数据分布的策略,它可以减少数据多节点分布时Join操作引起的数据移动和网络传输,从而提高查询性能。未来可以进一步探索Colocate Join的实现方法和优化策略,以更好地适应七猫的应用场景。
- Query Cache:Query Cache是一种可以提高聚合查询性能的技术,它可以将查询结果缓存起来,以避免重复计算。未来可以进一步探索Query Cache的实现方法和优化策略,以更好地提高聚合查询的性能。
综上所述,未来可以在CBO优化器、Colocate Join和Query Cache等方面进行技术优化,进一步提高StarRocks在七猫应用的资源利用率、查询性能,并且能够有效控制成本。