一、背景
- 随着公司业务的发展,海量小说数据激增,构建高效数据管理与分析平台刻不容缓,OpenLake(开放数据湖,一种致力于打破数据孤岛,实现各类数据自由流通与协同处理的理念)理念及 Paimon 湖格式因此备受关注。
- 然而,传统数据处理手段在应对海量小说数据时,性能瓶颈与低效率问题突出。StarRocks 作为先进的 MPP(大规模并行处理,Massively Parallel Processing)数据库,其物化视图等特性,为解决这一困境提供了创新思路,也为公司自研分析平台提供了技术支持。
二、收益
(一)极致查询性能提升
- 基础查询加速:在直接查询 Paimon Append Only(仅追加写) 表格式的大规模小说数据集(如:paimon 中的dwd.paimon_dwd_filted_flattened_log_inc_h表),StarRocks 展现出惊人的速度,总耗时仅 148.92 秒,相较 Trino 的 640.8 秒,查询效率提升至 4.3 倍。这使得业务能够迅速从海量数据中获取关键信息,为业务决策争取宝贵时间。
- 物化视图的飞跃:对于复杂的关联和聚合查询,StarRocks 的物化视图发挥了显著的作用。以分析AB 实验指标为例,从直接查询原始表的 14 秒左右,骤降至构建物化视图后的 0.09s 秒左右。这一优化不仅极大缩短了查询延迟,更使得对查询性能要求极高的业务场景得以高效实现,为算法在精准推荐、优化策略方面提供了强大、更快速的数据支持。
(二)简化数据管理流程
StarRocks 的 Catalog 功能允许在同一系统内无缝管理内、外部数据。针对 Paimon 湖格式的小说数据,用户无需繁琐地手动创建外表及指定数据源路径,即可轻松实现数据访问与查询,极大的简化了数据管理操作,降低了管理成本与出错风险,提高了数据管理的整体效率。
(三)增强数据融合分析能力
StarRocks 支持 Paimon 表与其他数据湖格式以及自身内表的关联查询。这一特性使得自研分析平台能够整合多元数据,开展更全面、深入的数据分析。例如,将 Paimon 湖格式存储的用户阅读行为数据与 StarRocks 内表中的小说内容数据关联分析,深度洞察用户对不同题材小说的偏好,为精准推荐和内容创作方向提供有力依据。
三、实现方案
接下来将从以下三个方面介绍:
- 快 - 使用StarRocks直接查询(自研分析平台)
- 更快 - 开启Data cache查询
- 超级快 - 构建异步物化视图
(一)快 - 使用StarRocks直接查询(自研分析平台)
StarRocks 支持 Catalog(数据目录)功能,实现在一套系统内同时维护内、外部数据,不需要手动建外表,指定数据源路径,即可轻松访问并查询各类数据湖格式,例如Hive,Paimon,Iceberg等。开箱即用,不需要任何数据导入和迁移。例如:在StarRocks里创建一个filesystem类型的Paimon catalog:
CREATE EXTERNAL CATALOG paimon_catalog
properties(
"type" = "paimon",
"paimon.catalog.type" = "filesystem",
"paimon.catalog.warehouse" = "oss://<bucket>/paimon/warehouse");这一操作搭建起了 StarRocks 与 Paimon 数据湖之间的桥梁,为后续的数据交互奠定了基础。数据团队无需再花费大量时间和精力去手动配置复杂的连接参数,就能轻松让 StarRocks 识别并连接到存储小说业务数据的 Paimon 数据湖。
我们使用相同的硬件资源(配置详情见附录),对比了StarRocks和Trino分别查询Paimon Append Only表格式的TPC-H 100G数据集,Trino 使用了最新的 Paimon-Trino 版本,已包含了对 ORC 文件读取的优化,测试结果如下:执行SQL查询Paimon数据湖(以TPC-H Q1为例):
TPC-H (Transaction Processing Performance Council ,TPC)是一种用于评估数据库系统性能的基准测试工具
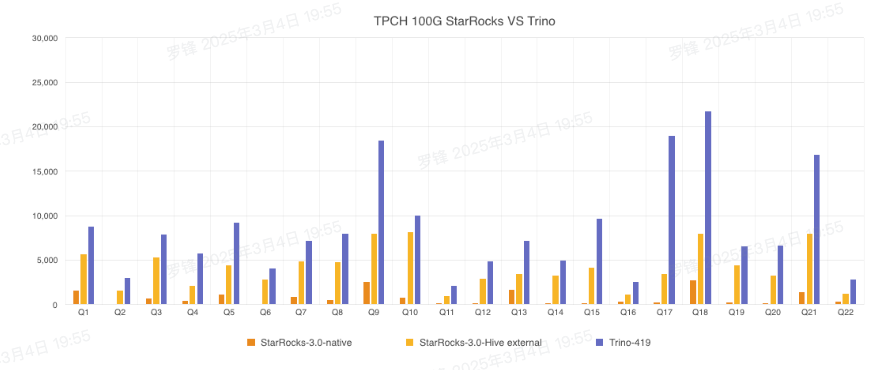
以上对比测试结论来自StarRocks官方文档。链接https://docs.starrocks.io/zh/docs/benchmarking/TPC-H_Benchmarking/
StarRocks 本地存储查询总耗时为 17s,StarRocks Hive 外表查询总耗时为 92s,Trino 查询总耗时为187s。可以得到,在本测试场景下,StarRocks的查询效率是Trino的10倍,是StarRocks Hive外表查询的 2 倍。
使用StarRocks直接查询Paimon数据是实际生产环境中最常见的场景,操作简单,可以满足大部分Paimon数据湖分析的需求。
(二)更快 - 开启Data cache查询Paimon湖格式
在数据湖分析场景中,StarRocks 作为 OLAP 查询引擎需要扫描 HDFS 或对象存储上的数据文件。查询实际读取的文件数量越多,I/O 开销也就越大。此外,在即席查询场景中,如果频繁访问相同数据,还会带来重复的 I/O 开销。
为了进一步提升该场景下的查询性能,StarRocks 2.5 版本开始提供 Data Cache 功能。通过将外部存储系统的原始数据按照一定策略切分成多个 block 后,缓存至 StarRocks 的本地节点,从而避免重复的远端数据拉取开销,实现热点数据查询分析性能的进一步提升。例如:开启Data cache的步骤
1.BE增加如下配置并重启:
# 开启data cachedatacache_enable=true# 单个磁盘缓存数据量的上限,本示例20G
datacache_disk_size=21474836480# 内存缓存数据量的上限,本示例4G
datacache_mem_size=4294967296# 缓存使用的磁盘路径
datacache_disk_path=/mnt/disk1/starrocks/storage/datacache;/mnt/disk2/starrocks/storage/datacache;/mnt/disk3/starrocks/storage/datacache;/mnt/disk4/starrocks/storage/datacache2.在 mysql 客户端执行下列命令
SET enable_scan_datacache = true;再次执行查询,就可以看到明显的查询效率提升。我们可以在 query profile 里观测当前 query 的 cache 命中情况,观测下述指标查看 Data Cache 的命中情况:
- DataCacheReadBytes:从内存和磁盘中读取的数据量。
- DataCacheWriteBytes:从外部存储系统加载到内存和磁盘的数据量。如以下的示例,显示该query在data cache里读取了10.107 GB的数据
- DataCache:
- DataCacheReadBlockBufferBytes: 920.146 MB
- __MAX_OF_DataCacheReadBlockBufferBytes: 14.610 MB
- __MIN_OF_DataCacheReadBlockBufferBytes: 1.762 MB
- DataCacheReadBlockBufferCounter: 27.923K (27923)
- __MAX_OF_DataCacheReadBlockBufferCounter: 440
- __MIN_OF_DataCacheReadBlockBufferCounter: 55
- DataCacheReadBytes: 10.107 GB
- __MAX_OF_DataCacheReadBytes: 163.518 MB
- __MIN_OF_DataCacheReadBytes: 20.225 MB
- DataCacheReadDiskBytes: 563.468 MB
- __MAX_OF_DataCacheReadDiskBytes: 30.965 MB
- __MIN_OF_DataCacheReadDiskBytes: 0.000 B
- DataCacheReadMemBytes: 9.556 GB
- __MAX_OF_DataCacheReadMemBytes: 142.791 MB
- __MIN_OF_DataCacheReadMemBytes: 20.225 MB
- DataCacheReadCounter: 41.456K (41456)
- __MAX_OF_DataCacheReadCounter: 655
- __MIN_OF_DataCacheReadCounter: 81
- DataCacheReadTimer: 9.157ms
- __MAX_OF_DataCacheReadTimer: 48.792ms
- __MIN_OF_DataCacheReadTimer: 478.759us
- DataCacheSkipReadBytes: 0.000 B
- DataCacheSkipReadCounter: 0
- DataCacheWriteBytes: 0.000 B
- DataCacheWriteCounter: 0
- DataCacheWriteFailBytes: 0.000 B
- DataCacheWriteFailCounter: 0
- DataCacheWriteTimer: 0ns我们开启Data cache后,再次执行TPC-H 100G基准测试,第一次执行总耗时为134.59s,第二次执行总耗时为110.2s,第三次执行总耗时113.12s,第一次相对后两次较慢是因为StarRocks要从对象存储OSS里拉数据,并做本地cache,后两次从profile可以看到基本全命中本地cache做运算,执行时间稳定在110s左右。
可以得到,在本测试场景下,开启cache之后,查询性能提升了35.4%左右。
在生产环境中,data cache的性能在不同的query pattern以及不同的数据量下,查询性能有 30% 的提升。
(三)超级快 - 构建异步物化视图
生产环境环境中的应用程序经常基于多个大表执行复杂查询,通常涉及大量的数据的关联和聚合。处理此类查询通常会大量消耗系统资源和时间,造成极高的查询成本,StarRocks 可以使用异步物化视图解决以上问题。异步物化视图是一种特殊的物理表,其中存储了基于基表特定查询语句的预计算结果。当您对基表执行复杂查询时,StarRocks 可以直接复用预计算结果,避免重复计算,进而提高查询性能。物化视图具有以下优势点:
1.物化视图全链路可观测:
- 创建链路观测:监控创建物化视图语句的执行状态和参数配置,以便及时发现问题并优化。
- 数据刷新链路观测:追踪刷新任务调度、数据更新情况及刷新性能,确保数据的时效性和一致性。
- 依赖链路观测:明确物化视图与基表及上下游任务的依赖关系,保障数据链路的稳定性。
2.低效率物化视图检测:
- 查询性能:通过对比响应时间及分析查询计划,判断物化视图是否有效提升查询效率。
- 数据质量:校验数据一致性与完整性,确保物化视图数据准确可靠。
- 使用频率:分析使用频率和业务价值,评估物化视图对业务的实际贡献
3.物化视图智能推荐:
- 数据收集与分析:挖掘查询日志,分析数据依赖关系,了解用户查询模式和数据访问习惯,为推荐提供依据。
- 性能评估与预测:基于历史数据评估现有物化视图性能,构建预测模型预估不同配置下的查询性能。
- 推荐结果展示与交互:通过可视化展示推荐结果,并提供交互界面,方便用户调整和定制。
案例:在AB 实验中,以留存数据查询指标的查询速度较慢且查询 SQL 较为复杂的情况为例,基于进组后的用户行为数据,创建异步物化视图,来展示物化视图优化后的效果:所选指标 “D007点击用户活跃留存-指标数据” 的 SQL 如下,当前查询时长约为 14 秒。
-- D007点击用户活跃留存-指标数据
-- 查询响应时长:14秒
SELECT data_date,
group_id,
sum(is_current_scene_click_user) AS conversion_user_count ,
sum(if(is_current_scene_click_user = 1, is_retain_user_01d + is_retain_user_02d + is_retain_user_03d + is_retain_user_04d + is_retain_user_05d + is_retain_user_06d + is_retain_user_07d, 0)) * 1.0000 / sum(is_current_scene_click_user) AS click_user_count_after_day_lt7 ,
sum(if(is_current_scene_click_user = 1, is_retain_user_01d, 0)) AS click_user_count_after_day_1 ,
...
sum(if(is_current_scene_click_user = 1, is_retain_user_30d, 0)) AS click_user_count_after_day_30
FROM edw_dwt.dwt_ab_core_metric_source_uid_group_id_inc_d_view
WHERE 1 = 1
AND 1 = 1
AND exp_id = 3674
AND project IN ('xxx',
'xxx_ios')
AND dt >= '2024-01-01'
AND dt <= '2024-01-31'
GROUP BY data_date,
group_id
ORDER BY data_date DESC,
group_id ASC;
对数据集进行优化和加速之后,查询时长缩短至:0.09秒。
-- 0.09 秒(优化前 14 秒)
-- 查询性能提升 14 倍以上
SELECT dt,
group_id,
sum(current_scene_click_user_cnt) AS conversion_user_count,
(sum(is_retain_user_01d) + sum(is_retain_user_02d) + sum(is_retain_user_03d) + sum(is_retain_user_04d) + sum(is_retain_user_05d) + sum(is_retain_user_06d) + sum(is_retain_user_07d)) * 1.0000 / sum(current_scene_click_user_cnt) AS click_user_count_after_day_lt7,
sum(is_retain_user_01d) AS experiment_user_count_after_day_1,
sum(is_retain_user_02d) AS experiment_user_count_after_day_2,
sum(is_retain_user_03d) AS experiment_user_count_after_day_3,
...
FROM
-- 紫色斜体字体为 StarRocks 物化视图数据集
(SELECT dt,
project,
exp_id,
group_id,
is_new_user,
is_read_user,
is_current_scene_click_user,
sum(is_retain_user_01d) AS is_retain_user_01d,
sum(is_retain_user_02d) AS is_retain_user_02d,
sum(is_retain_user_03d) AS is_retain_user_03d,
...
FROM
(SELECT dt,
project,
source_uid,
exp_id,
group_id,
is_read_user,
is_current_scene_click_user,
is_current_scene_click_10min_user,
is_full_module_10min_con_user,
is_retain_user_01d,
is_retain_user_02d,
is_retain_user_03d,
...
dt AS data_date
FROM edw_dwt.dwt_ab_core_metric_source_uid_group_id_inc_d_view
WHERE dt >= '2024-06-01') t_1
GROUP BY dt,
project,
exp_id,
group_id,
is_new_user,
is_read_user,
is_current_scene_click_user) t_dataset
WHERE dt >= '2024-01-01'
AND dt <= '2024-01-31'
AND exp_id = 3674
AND project IN ('xxx',
'xxxx',
'xxxxx')
AND is_current_scene_click_user = 1
GROUP BY dt,
group_id
ORDER BY dt,
group_id;
通过分析指标对应的 SQL 中用到的维度、度量之后,进行相应的优化,提升指标的响应速度:14秒 -> 0.09秒 。
StarRocks 的查询优化器能够自动识别适合使用物化视图的查询,并对查询 SQL 进行智能改写,从物化视图中直接读取预计算结果。当业务需求是查询过去两年内不同年龄层用户对各类小说的互动情况时,StarRocks 会自动从物化视图中快速获取数据,而无需对原始的海量用户行为数据进行实时计算,极大提升了查询效率。
四、StarRocks其他能力探索
二级分区能力
CREATE TABLE `dwt_ab_core_metric_xxx_test` (
`dt` date NOT NULL COMMENT "日期分区yyyy-MM-dd",
`exp_id` bigint(20) NOT NULL COMMENT "实验id",
`source_uid` varchar(65533) NULL COMMENT "source_uid",
`project` varchar(65533) NULL COMMENT "项目reader_free或reader_free_ios",
`exp_name` varchar(65533) NULL COMMENT "实验名称",
`group_id` bigint(20) NULL COMMENT "实验组id",
`group_name` varchar(65533) NULL COMMENT "实验组名称",
`xxx` varchar(65533) NULL COMMENT "xxx",
`xxx` bigint(20) NULL COMMENT "xxx",
...
) ENGINE=OLAP
DUPLICATE KEY(`dt`, `exp_id`, `source_uid`, `project`)
COMMENT "desc"
PARTITION BY (`dt`,`exp_id`)
DISTRIBUTED BY HASH(`source_uid`, `project`) BUCKETS 1
PROPERTIES (
"replication_num" = "3",
"in_memory" = "false",
"enable_persistent_index" = "true",
"replicated_storage" = "true",
"compression" = "ZSTD"
);
注:bucket 数量需控制在1 bucket = 1G 数据量AB实验底层StarRocks存储采用dt分区,在实验指标查询时需要扫描dt范围内的所有数据,然后筛选出指定实验的数据进行指标计算,其中约90%被扫描的数据不是指标SQL查询所需要的数据,该部分数据对SQL结果不产生影响,但非常影响查询效率。通过对 StarRocks 技术探索,将诉求反馈给云平台后,相关负责积极配合升级版本,解决二级分区存储数据的能力。底表数据存储采用二级分区方案,即在SQL查询时只需扫描指定实验的指定dt范围,可以减少90%的无用数据的扫描量。
效果对比:
| Query | 以及分区查询速度(s) | 二级分区查询速度(s) |
| 1 | 22.69 | 0.25 |
| 2 | 23.92 | 0.24 |
| 3 | 31.10 | 0.28 |
| 4 | 23.18 | 0.31 |
| 5 | 16.03 | 0.56 |
图中能够清晰看到,数据存储采用二级分区相较一级分区,在查询性能上有了显著飞跃。采用二级分区存储数据后,单条 SQL 查询速率得到了有效控制,可稳定在 1 秒以内完成,极大地提升了数据处理效率。这一优化对前端页面展示效果的改善尤为明显。此前,前端页面每次数据展示耗时超过 60 秒,严重影响用户体验。而如今,借助二级分区存储带来的高效查询能力,前端页面展示时间大幅缩短,全部数据可在 5 秒内完成展示,实现了流畅、快速的用户交互体验。
慢查询分析能力我们可以根据平台提供的查询性能分析报告可以分析慢 SQL 原因,并提出优化建议。
优势:
- 精确诊断: StarRocks 可展示慢 SQL 详细执行计划与性能指标,精准定位问题所在,如查询操作、资源瓶颈等,还能深度剖析数据处理细节,帮助用户发现隐藏问题,为优化提供明确方向。
- 资源洞察与数据优化: 能直观呈现慢 SQL 的系统资源使用情况,分析资源与性能关联,监控并优化资源利用。同时可自动检测数据倾斜,分析原因并提供建议,有效解决数据分布不均问题,提升查询效率。
- 历史查询价值挖掘: 保存查询历史记录,便于分析慢 SQL 出现规律与趋势,提前预防性能问题。其界面友好、操作便捷,提高工作效率。
五、风险点
(一)数据一致性挑战
在使用物化视图时,若基表数据更新频繁,而物化视图的刷新策略设置不合理,可能导致物化视图数据与基表数据不一致,影响查询结果的准确性。例如,手动刷新的物化视图若未能及时更新,在数据变化剧烈时,查询结果可能存在严重的滞后情况。
(二)配置复杂性风险
尽管 StarRocks 为查询 Paimon 数据湖提供了相对简便的操作方式,但在创建 Catalog、配置 Data Cache 以及构建物化视图等过程中,仍需进行诸多的参数配置。对于不熟悉 StarRocks 的用户,参数设置错误可能导致功能无法正常使用或性能严重下降。例如,创建 Paimon Catalog 时 warehouse 路径设置错误,将无法建立与 Paimon 数据湖的有效连接。
六、未来展望
(一)性能优化持续推进
- Primary Key 表性能进阶:利用 PK 表进一步提升查询性能,尤其在处理包含删除操作的 Primary Key 表数据时,实现更高效的数据获取与查询加速。
- 元数据管理优化:通过缓存 Paimon 元数据,减少重复 I/O 操作,降低 Analyze 阶段的延迟,提升查询过程中获取数据结构信息的速度,从而优化整体查询性能。
(二)功能特性深度完善
- 执行计划智能优化:接入 Paimon 表统计信息,使 StarRocks 的查询优化器能够更精准地估算不同执行计划的成本,从而为复杂 SQL 查询的执行选择最优执行路径,显著提高复杂查询的执行效率。
- 物化视图功能强化:进一步完善 Paimon 异步物化视图的查询与改写功能,优化物化视图的构建与刷新策略,确保物化视图与基表数据的高度一致性,同时提升查询改写的智能化水平,更好地满足复杂多变的业务查询需求。继续探索智能物化视图在七猫的应用,StarRocks 可以根据历史查询,智能推荐物化视图构建,进一步加速查询效率。
(三)应用场景拓展创新
随着技术的不断演进,StarRocks 在 OpenLake 中的应用将更为广泛深入。在实时数据处理与分析领域,结合其高性能查询能力与对 Paimon 数据湖的支持,有望实现对实时产生的海量小说业务数据的秒级分析,为平台运营提供近乎实时的决策支持。此外,在与其他大数据工具和平台的深度集成方面,StarRocks 将不断探索创新,助力公司构建更加完善、高效的数据生态系统,推动公司业务迈向新的高度。