鉴于之前调研的夜莺等一体化监控告警工具,我们综合总结下来,使用阿里云提供的ARMS告警系统,以减轻运维成本,目标是解决当前多而繁杂的业务系统中各式各样的告警机器人治理问题,我们需要一个聚合的,可容错的,可削峰的,可溯源的监控告警系统。
下面我们一起来看下当下在商业化广告这边应用实践
一、总体流程图

二、过去与现在的对比图

三、普罗监控侧告警配置
1.编写普罗告警规则
vim pixiu.yaml
YAML |
关键参数说明:
- 当前集群监控的名称:
metadata.name: pixiu-ad-test
- 策略组的名称,切记不要有大写:
spec.groups.name: pixiu-ad-test-request
- 告警文案:
description: 当前数量{{ $value }}
- rules.alert.expr: 要执行的sql语法,记得自己grafana去验证下是否能查出数据
使yaml生效
- kubectl apply -f pixiu.yaml
查看当前集群monitor状态
- kubectl -n monitor get prometheusrule
以及查看刚刚发布的监控配置:
- kubectl -n monitor get prometheusrule -o yaml pixiu-ad-test
2.飞书群/个人 生效收到告警配置

选择策略对应的配置名称,就是上面yam里配置的 labels.notice: pixiu-ad-test
没有显示,就说明目前你配置的规则还没有触发阈值,当有了以后,这里就显示名称了,接下来点到通知对象中,配置接收人

首先去配置通知对象,飞书群聊里,怎么添加机器人不用多说了,直接上货!


这里是通用模版,我们已经有成熟的大量模版了,都是运维大大们的功劳~感谢感谢
• 如果还需要自定义信息,可以查看这个文档来了解规则。
• 如果想通知到多个飞书个人,可以查看这里文档所示,作相应排班管理

最后配置完成后保存,你将马上收到飞书的新消息, (当然最好永远收不到告警消息☺️ )通过点击链接,可以看到你yaml中配置的面板信息。

- 配置通知对象
https://arms.console.aliyun.com/#/alarm/notifyObject (联系运维申请权限)
- 在阿里云配置告警策略
https://arms.console.aliyun.com/#/alarm/notifyPolicy/list (联系运维申请权限)
3. 监控侧告警服务流程图
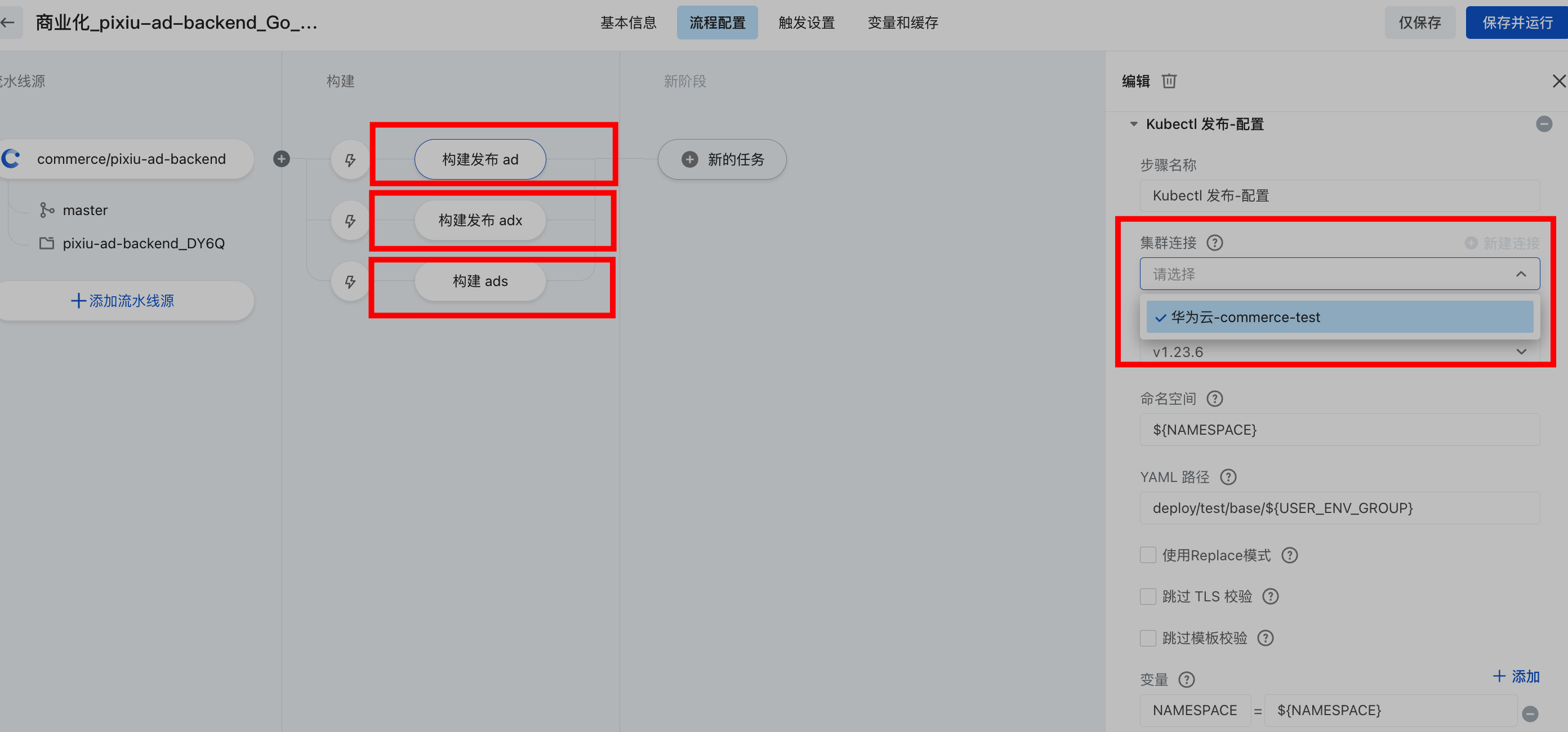
当存在多个集群的多个业务情况下,由于采集指标源prometheus是部署在各自的集群内部指定命名空间,这里我们采用流水线的方式来集体管控对多个prometheus源进行监控配置管理,如下所示,我们在流水线中配置多个构建发布,通过不同集群的链接配置,可以发布到各自集群内。

4.监控告警流水线发布
四、业务开发侧配置监控告警
1.业务侧告警流程
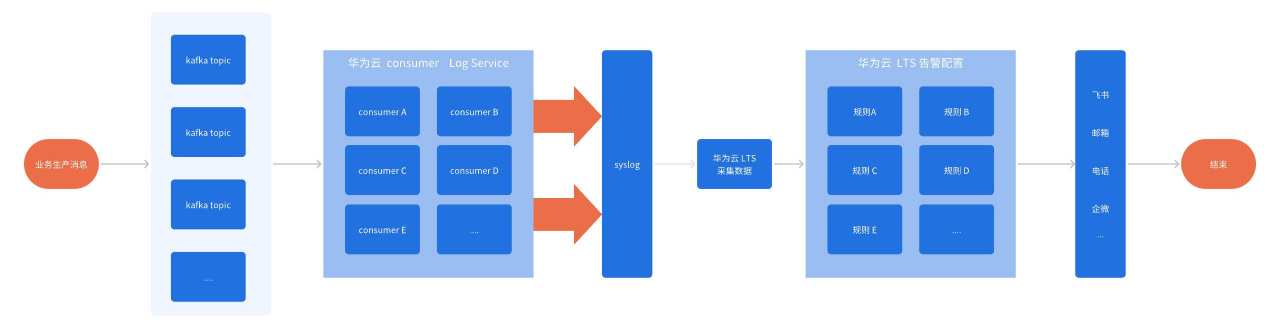
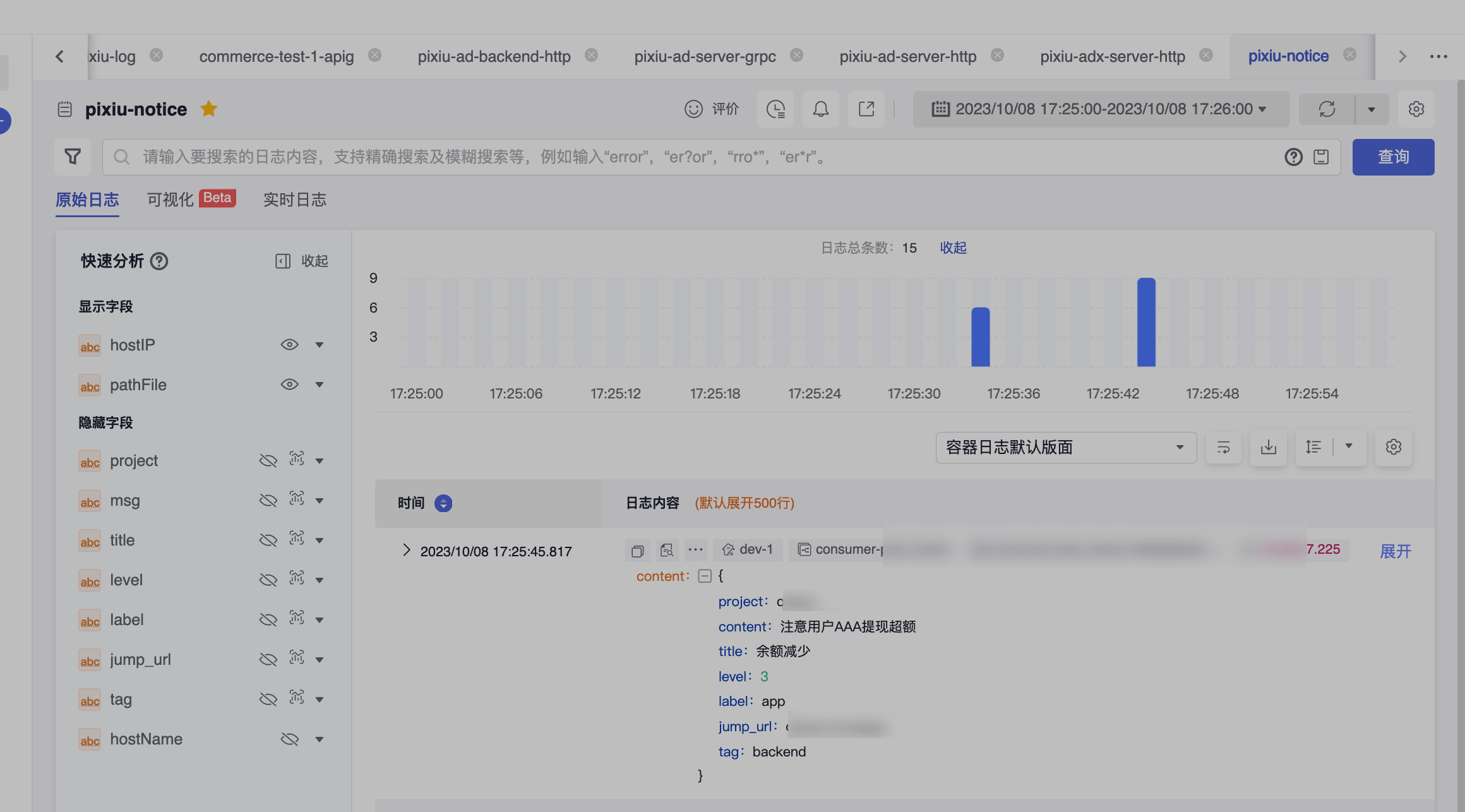
通过消费kafka消息,在LTS中可以看到所有消息内容,在这里我们可以根据筛选条件指定告警规则。

配置好后,静等几分钟,当消息触发规则后,我们在飞书群里就会收到如下告警

2.华为云文档
- syslog数据采集
https://support.huaweicloud.com/bestpractice-lts/lts_07_0019.html
- 告警列表配置
https://support.huaweicloud.com/usermanual-lts/lts_04_0060.html
五、总结
通过上面介绍能够得到以下结论
- 我们可以感受到配置一个告警规则是多么简单,只需要了解yaml的编辑格式,和要查询到sql,填入后,kubectl发布一下就生效了, 当然我们可以更简单,通过流水线自动发布生效。
- 业务侧繁杂的消息通知内容,我们可以all in one 通过kafka生产消费,实现可聚合的,可容错的,可削峰聚合的,可溯源的监控告警系统。
万丈高楼,根基最重要,在我们将这些繁杂的数据信息搭建完成后,后续的告警和监控更是鼠标随意点点就完成了。