前言:
七猫社区Timeline Feed架构演进是一个旨在改进和优化社区动态展示功能的项目它是书友圈中一个不可获缺的tab。2.0通过对现有架构进行演进,我们可以提升用户体验、优化性能,并满足不断增长的用户需求。
在过去的几年里,随着用户数量和社区活跃度的快速增长,我们的Timeline Feed架构面临了一些挑战。例如,随着动态内容和评论数量的增加,对于消息投递、更快速加载和高效处理用户操作的需求愈发迫切。为了解决这些问题并提供更好的用户体验,我们决定对Timeline Feed架构进行全面的升级并指定版本为 2.0。
本次架构演进旨在达成以下目标:
提高加载速度和性能:
- 优化解决查询痛点
- 引入热门信息缓存机制
- 使用异步处理等技术手段
- 降低服务器响应时间
优化数据存储和管理:
- 重新设计和规划数据存储结构
- 采用更适合大规模社区的存储方案(引入GDB图数据库)
- 确保数据的安全性和一致性(解决状态不延迟、不一致情况)
- 配合算法进行三层UGC内容推荐关系(后续)
增强动态推送机制:
- 由原单推模式改进为动态推拉结合机制
- 实现更及时和准确的动态更新推送
- 用户能够第一时间获取感兴趣的UGC内容、关注的作者书籍更新动态
总之,这次七猫社区Timeline Feed架构演进旨在通过技术创新和系统优化来提升用户体验、优化性能,并满足用户不断增长的需求。我们将持续努力,为用户提供一个更好、更具吸引力的社区动态展示平台。
社区 Timeline Feed 1.0 架构
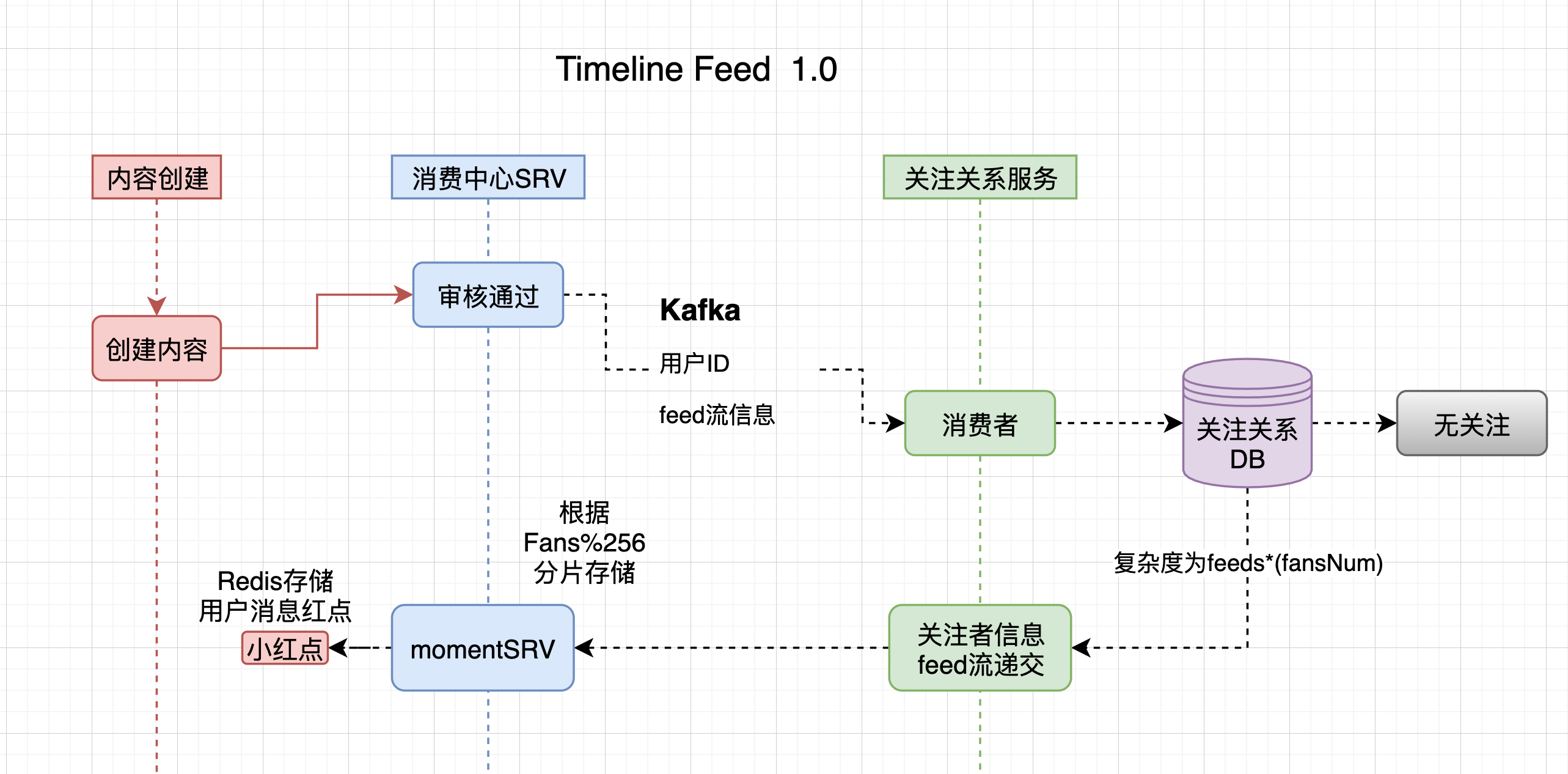
在Timeline feed 1.0 架构设计中我们单纯的采用了单纯"推"模式进行feed流的从生产投放到用户timeline数据堆中并同步更新用户小红点,使其在其他入口实现数据更新感知。
为什么要更新 2.0?
痛点:
- 数据更新不一致
从流程中我们可以看到我们只实现了审核通过后feed流推的动作,数据是会发生状态变更的当一个审核通过内容变为审核不通过,在timeline中他依然处于可用状态,(目前采用向外分发时进行过滤,本身这并没有什么问题,但是我们设想有1万人关注了用户A且此人信息写入极其频繁,如果他在制造20条信息后又将此些信息删除回发生什么?),很不幸我们就遇到很多这样的用户,在分发时过滤导致整页为空的结果。 - 资源浪费和数据膨胀
由于是单边关系,上线运行一段时间后当进行数据回查时发现由于上述复杂度原因(feeds*fansNum)数据已达到24亿之多,(RT时间少全靠索引建的好)为了保障可用性,我们结合用户行为分析后进行数据清理了20.4亿不会曝光数据,也就是说分发数据仅占6/1。
从以上痛点来看每一条都是不可容忍的情况,近期产品要针对此模块进行优化,经过与小组内充分讨论,2.0架构应运而生。
评估标准
黄金指标
| 接口 | 延迟上限 | 可用性 | 说明 |
|---|---|---|---|
| Feed列表接口 | <= 200ms | 5个9 | 动态列表展示信息 |
| Feed流创建接口 | <= 200ms | 5个9 | 新消息事件投递箱 |
| 关注关系 | <= 100ms | 5个9 | 用于查询用户关注关系 |
| 外部模块引流接口 | <= 200ms | 4个9 | 主要服务于外部占位块及红点 |
存储容量
假设1篇发Feed消息2kb,则存储量 = 2kb * 写入量 * (关注关系)* 天
网关占用比例
这里我们网络请求带宽忽略不计,渲染时内部网络调用也不计入,主要是feed流在下发时占用带宽 27.07 KB (27,719 bytes)+cdn内容图片流量700KB*20,我们放大预估qps为1k,则消耗带宽近似等于 20*700kb+27kb * 1000 * 12h(评论分摊高低峰) *60min * 60s 最大约等于 1.088pb
负载特性
Feed系统是一个典型的读多写少负载场景,通常为1500:1,一个用户发Feed,有1500个用户会阅读此Feed。
驱动设计
拆分:节点、实体(会有唯一标识进行聚合)
区分:边、服务调用关系(领域)
我将此业务划分为6个有效边界(这里并不是所有都拆分成各自服务,适合的才是最好的)
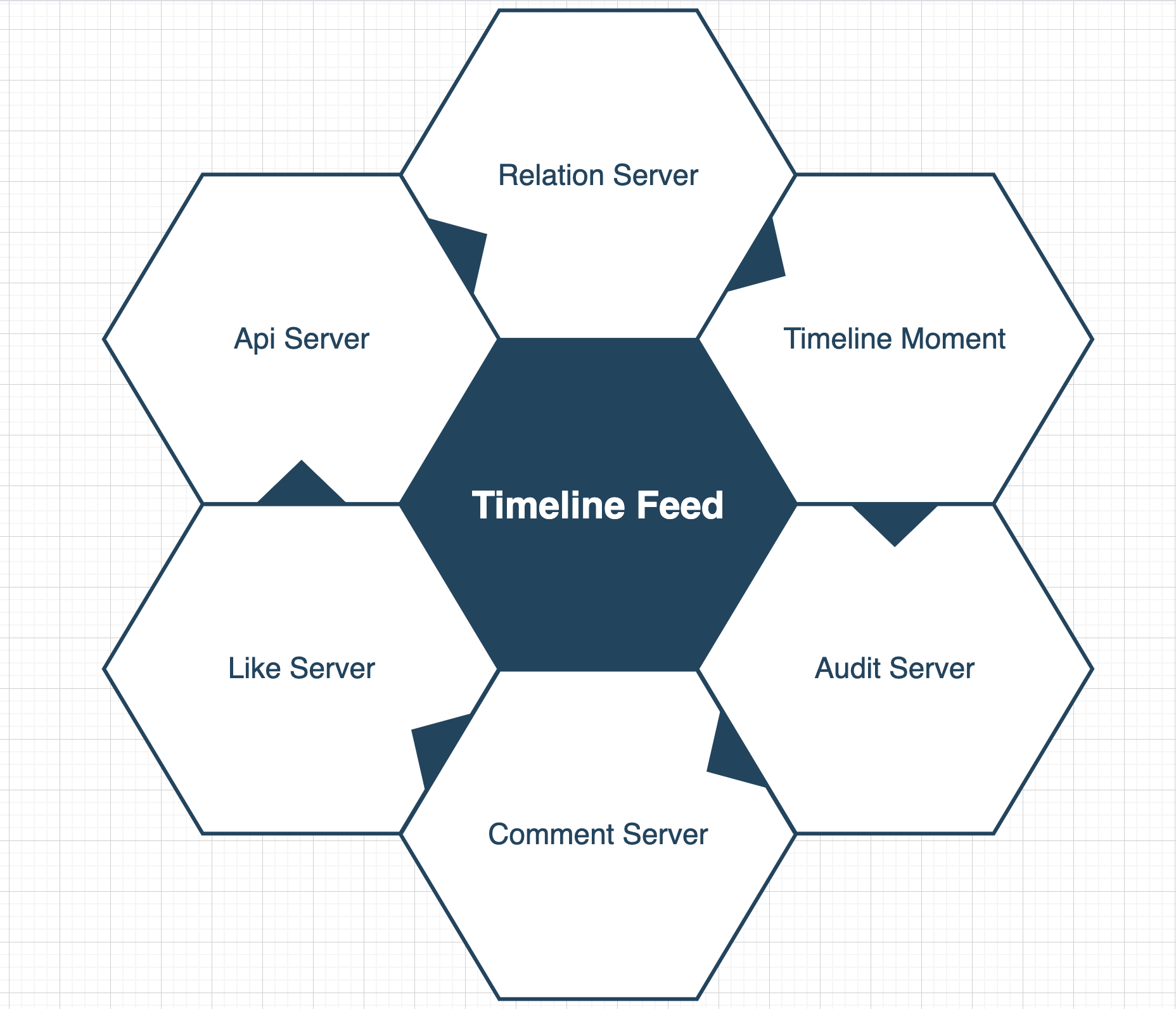
这里重点讲下黄金指标涉及逻辑:
用户关注
API server 调用relation server写入即可。
发布item
1、用户发布item时,写入item到timeline moment,然后调用relation server获得粉丝关系列表。
2、(pipline)触发一系列异步任务、审核、数据压缩、NLP打标签等流程。
3、对于小众关注关系(可根据调整划分)异步写入每个粉丝user的inbox列表中,并做好ts排序。
读取Feed列表
1、当用户获取feed列表时,直接从TimelineMoment读取并根据各自feed类型进行添加server组合渲染。
2、index中存储为基础数据,通过item的id进行作者。
3、判断过滤规则,保证内容有效且合规后放出。
4、对于大v采用"Pull"的方式以减少数据膨胀。
等,其他一些简单逻辑这里就不介绍了
。
。
。
整洁架构图示
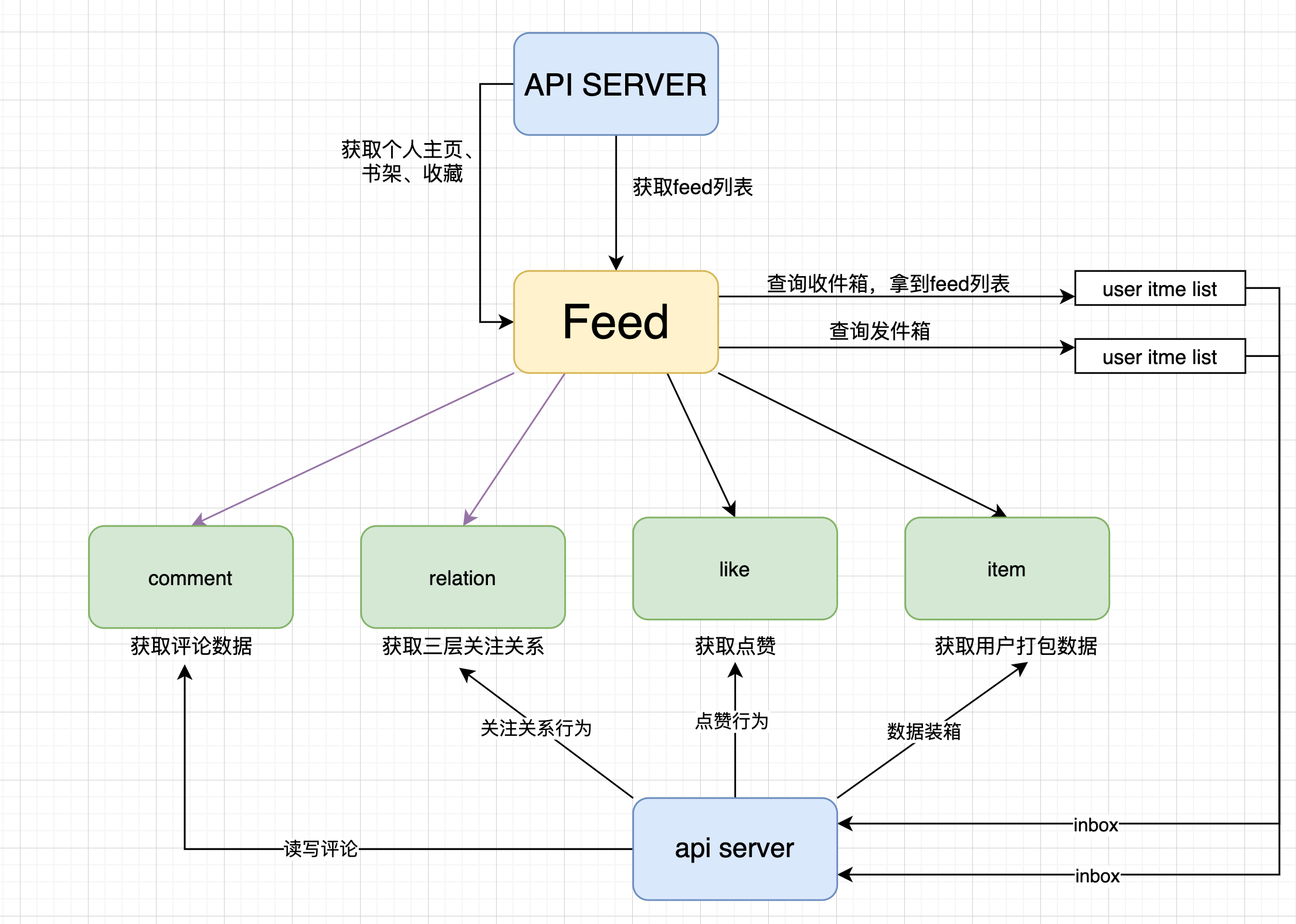
当用户刷新时,有新的内容怎么办?
我们在feed列表查询过程中,会同步查询用户大V发件箱,当有new feed的时候在返回结果中附增,调用单独的接口进行客户端插排,这里的目的是为了不影响用户已阅读列表timeline的排序规则。
设计
| 方案 | 收益 | 缺点 |
|---|---|---|
| 给粉丝数增加上限 | 实现最为简单粗暴 | 产品功能受限(容易被产品暴打) |
| 推拉结合 | 1、读的延迟不如纯写放大,但是要快于完全的度放大。 2、解决大V热点问题。 |
1、如果调用大v发件箱失败,那么用户永远得不到信息。 2、大V发件箱过大造成缓存大Key问题。 3、由于历史推模式,如果一个feed被删除,那么删除状态如何及时更新? |
方案有了,缺点有了,我们接下来进行拆分设计达到解决目的。
推拉结合
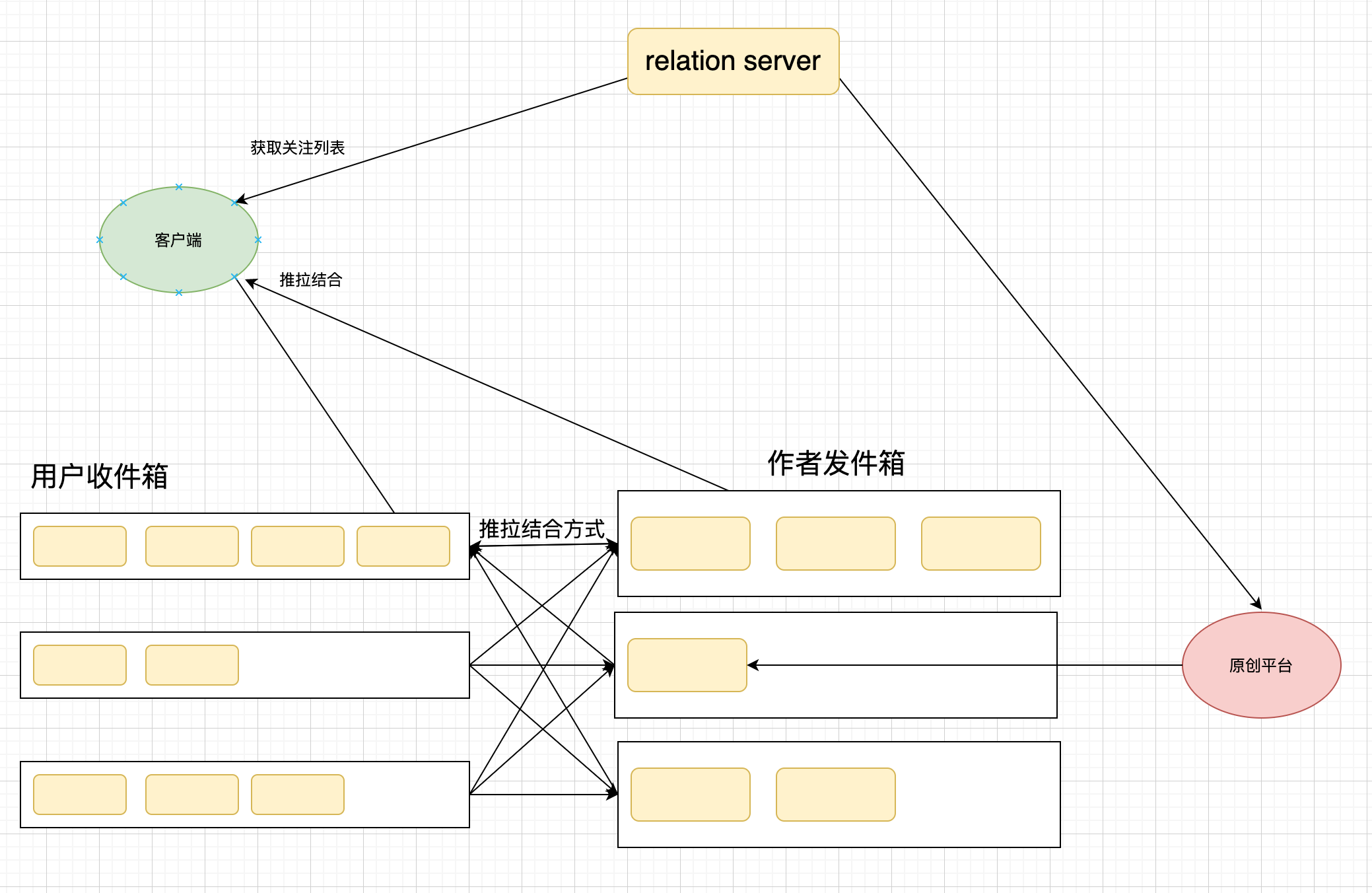
分级:
1、发布itme时,使用feed流式计算,来识别是否大V发文。
2、采用GDB 图数据库提高粉丝数获取关系速度。
3、发布item时,如果是大V则仅写入到自身的发件箱中。
4、发布item时,如果是普通用户,则进行写放大的推模式。(1.0)
5、读取feed时,读取gdb,从中识别出那些事大V用户,并读取自身的收件箱,然后读取其他大v的收件箱,进行数据装箱合并,返回最新的feed数据。(这里的代价由于多次组装会增高rt,通过不断优化进行缺点最小化)。
6、结合社区活跃用户数(避开僵尸用户),对于这些用户避免写放大。
建设补偿机制:
1、当写入用户收件箱失败时,则增加重试机制。
2、如果同步重试失败进入补偿队列进行补偿,保证最终一直。(一直失败则必然报警人工排查)
预刷数据:
用户在检查待拉取刷新时不够消费列表(pull模式),则结合用户收件箱进行补充(因为有时间位点不会造成数据重复问题)。
状态同步:
1、推模式,在原有消息写入流新增状态变更流,重走release server,当item接收到变更类型时根据状态变更moment状态。
2、拉模式,这种消息变更起来较快(必定缓存)如果遇到极端情况刚可分发就进行删除,那么执行上一步预热数据,从用户收件箱填充再配合补偿重试机制解决。
感悟:
对于2.0架构,我们需要进行大量的优化和升级设计。回顾1.0设计的初衷,我们没有进行充分的方案推演和可行性分析,导致后期维护时需要弥补很多技术债务。这进一步凸显了一个完善的架构的重要性。在未来的工作中,我们需要注重架构设计,以确保系统的可持续发展和稳定性,在此,也感谢为七猫社区Timeline Feed架构所贡献思路、代码的同事们。
规划
下一期我们计划对"七猫社区"的点赞服务进行架构总结和分析,重点关注其中的设计要素、幂等实现和数据落地。通过整理总结,我们希望找到进一步优化的机会,逐渐提升"七猫社区"的强大能力。这个计划将帮助我们深入理解系统的架构,并为未来的发展做出有针对性的改进。