前言
转眼间,七猫的算法推荐平台已走过了近三个年头,三年来,算法推荐引擎从0到1,经过一次次迭代更新,逐渐变得完善。这篇文章主要从我们推荐引擎的技术架构出发,给大家分享一下我们的架构演化之路,以及对未来演进方向的展望
推荐引擎简介
推荐引擎是推荐系统的核心组件,它是实现推荐系统功能的关键技术。推荐引擎利用算法和模型来分析用户的行为和项目的特征,生成个性化的推荐结果。
推荐引擎的主要任务是根据用户的个人信息偏好,历史行为和物品的属性等,预测用户对其他物品的兴趣程度,并为用户提供个性化的推荐列表。推荐引擎可以根据不同的推荐策略和算法,实现不同类型的推荐,如基于内容的推荐、协同过滤、深度学习和神经网络模型等。
在业界,对于推荐引擎的工作流程通常包括以下几个阶段:
- 召回阶段:基于相似度,协同过滤等算法或者通过离线u2i,i2i,u2i2i,以及DSSM双塔模型在线召回等策略,把参与推荐的物品从各个召回路进行数据召回
- 过滤阶段:对收集到的数据根据指定策略分别进行过滤、去重等处理。
- 粗排阶段:对过滤后的物品列表进行初步排序,指定算法粗排或通过模型粗排等,并进行数量截取
- 特征工程:对模型需要的特征数据进行统一读取,处理,特征转换,特征算子开发等,生成模型推理所需的特征矩阵,包含用户类特征,物品类特征,交叉类特征,embedding特征,上下文特征等
- 精排阶段:获取特征数据,调用训练好的模型,对用户进行个性化的推荐,生成推荐结果。
- 重排阶段:根据运营策略,算法调权,结果打散等对推荐结果进行二次排序,返回最终结果
回首过去:从零开始
市场上推荐系统很多,如美食、电商、视频、广告、搜索推荐等,每种推荐系统侧重点都不一样,美食和电商推荐目标是让你下单,长视频和短视频的目标是提高你刷视频的时间,搜索推荐是致力于向你提供更加准确的搜索结果,想你所想......而小说推荐,市面上鲜有耳闻。
我们从常见推荐系统中归纳总结,同时为了可以快速上手,我们调研了阿里的PAI-EAS模型服务,希望可以小成本的验证算法推荐给我们带来的收益。
经过一段时间的开发实践,我们在详情页进行了第一次的算法推荐实验,通过多天的实验数据观察,最终效果令人振奋,各种指标均有100%以上的提升,有些甚至达到了300%以上,由此更坚定了我们做算法推荐平台的决心
初始架构
第一版,我们以场景为中心,建立了一套简单的单体架构。参考业界主流的推荐引擎工作流程,我们暂时只实现了召回,过滤,精排等核心阶段,整体架构如下:

该架构为我们打开了新世界的大门,让我们深刻的体会到了算法带给我们的巨大提升。随着AB实验的不断展开,一些弊端也逐渐显现...
- 策略不够灵活
在最开始的单体架构中,我们针对召回,过滤,特征,精排等分别定制了一批模块化的策略,通过模型来确定具体执行的流程。而随着推荐系统在七猫内部的地位不断的升级, 新场景不断的涌现,快速验证推荐算法效果的必要性不断提高等,我们迫切需要一种解决方案,以可配置化的方式动态支持我们的实验流程。
- 流量分配不足
AB实验仅支持服务流级别的流量分桶策略,且七猫app下每个场景的流量参差不齐,有的场景仅有百万级的访问量。随着算法人员对ab实验的需求不断加大,流量分配逐渐成了一个不可忽视的问题 。
- 架构扩展性低,耦合度高
由于底层架构的限制,每新增一个场景,就要复制一套代码,添加一套逻辑,且其中大部分功能都是重复的,而我们七猫APP有30多个场景,随着新场景的不断接入,人力成本持续增加。
- 跨物品和APP支持不足
随着公司业务方向的推进,我们的推荐引擎需要对七猫、熊猫,星空等免费小说APP同时进行支持,另外随着有声书、话题、书单等物品逐渐接入算法,现有架构难以满足多样的推荐需求
立足当下:微服务与可配置化
于是,我们结合当下痛点问题,基于业务需求出发,重新设计,对整个推荐引擎进行了微服务化和可配置化的改造
可配置化
在整个推荐流程中,策略是最为重要的一环,其代表了每个推荐流程所要执行的具体逻辑,帮助算法人员针对不同模型定制化的执行不同的策略。
我们曾调研过业界各家推荐策略的执行流程,发现有很多虽然也用了配置化,但具体的执行流程依然是在代码中进行控制,比如百度推荐中台采用的小流量号方案,通过各小流量号的拼接组成完整的推荐服务流,然而每个小流量号需要执行的具体逻辑还需要在代码中硬性指定,这对追求高效开发和快速实验的我们是不太能接受的
于是在大数据同学的配合支持下,我们创新性的实现了支持热更新,配置化,可插拔,流量可控的推荐流程和策略管理平台


由引擎提前设计好策略格式,算法同学通过自定义参数配置成具体策略,并通过服务流串联为一个完整的推荐流程。这样,我们就实现了在不需要调整代码的情况下,实时的调整各种推荐策略,给算法同学提供更灵活可控的操作空间,大大提高了算法人员对推荐效果进行快速验证的效率
在该平台下,我们先后开发了一系列算法通用策略,如协同过滤召回,u2i、u2i2i在离线召回,属性匹配过滤,表达式过滤,交叉特征,并发模型调用等,所有算法同学都可零成本使用。同时也针对小说,有声书,话题,书单等分别定制了一些特有的策略,以满足各自的业务需求。而这一切,仅需要对我们的系统做很少的调整,需求迭代效率明显增加。
针对AB实验流量不足的问题,我们在大数据同学的配合下实现了基于阶段的流量分流模型
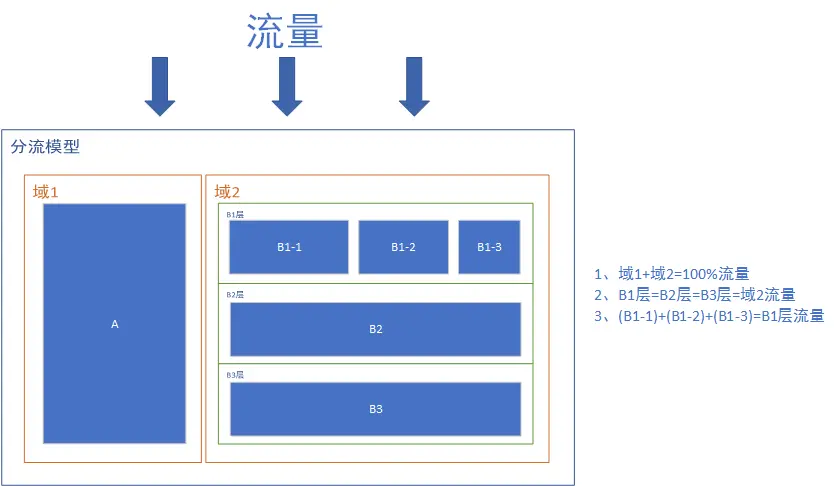
- 域1和域2拆分流量,两者是互斥的,可理解为我们不同的服务流。
- 流量流过域2中的B1层、B2层、B3层时,这三层的流量与域2的流量相等,且都是正交的,相当于我们不同的执行阶段,如召回,精排等。
- 流量流过域2中的B1层时,又把B1层分为了B1-1,B1-2,B1-3,此时这三者之间又是互斥的,相当于我们每个阶段下按照不同的策略组分层。
随着功能的不断演进,我们在ABTest的基础上,又基于用户行为,提出了服务流组的概念
根据用户所处的生命周期,行为数据等,动态的指定其要执行的具体流程,进一步扩充了实验的维度,提高了算法实验效率。
在配置化的推荐管理平台与AB实验平台的双层加持下,我们算法团队的迭代效率得到了很大提升,新策略的开发基本可以在一周内上线。同时由于在最开始就做好了策略的通用性设计,其他有类似需求的算法人员基本可以零成本接入,策略复用性大大提高。
微服务化
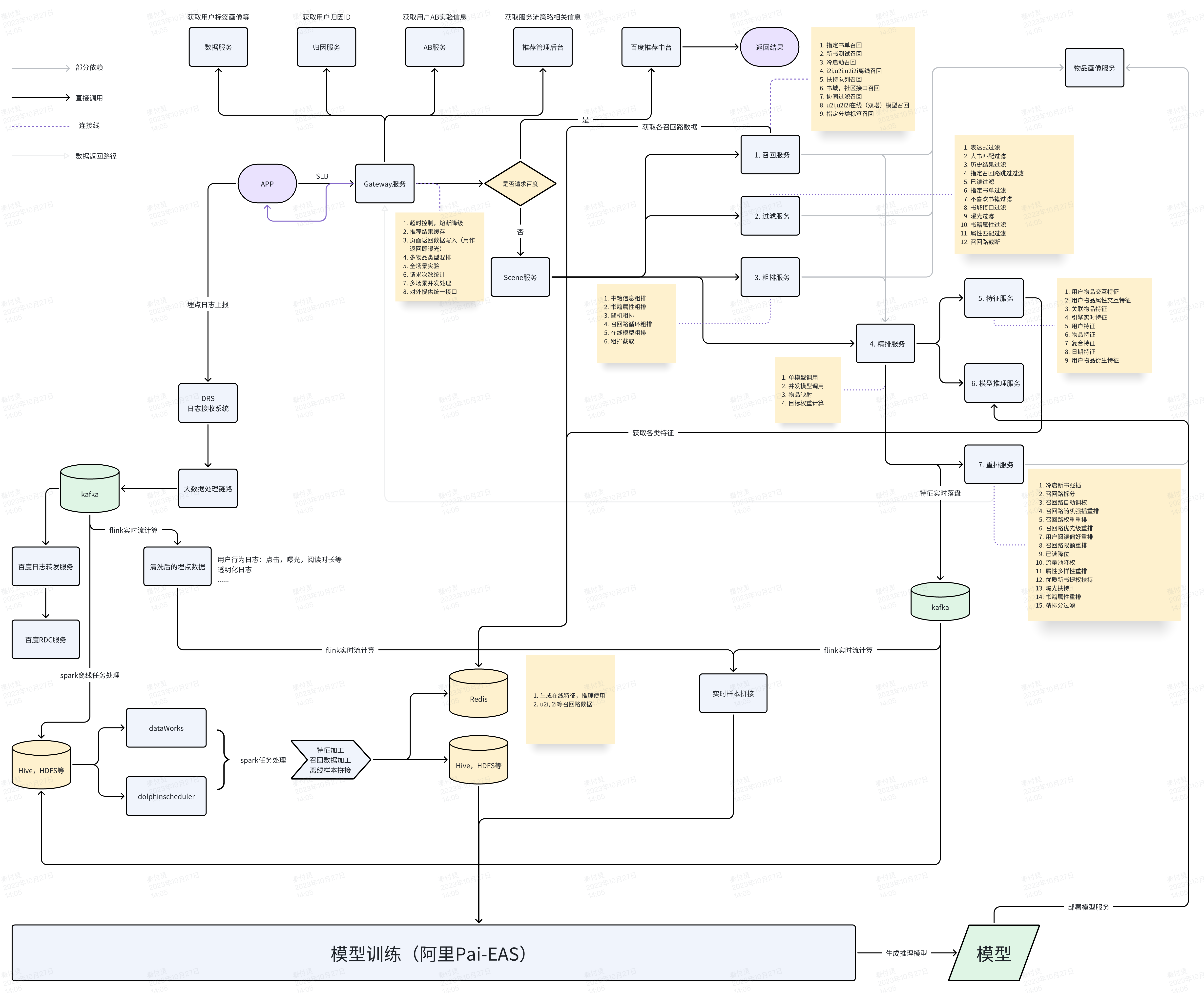
我们从推荐流程的角度,参考业界的常用流程,解耦了对推荐场景的依赖,使得一套服务可以满足各种场景的推荐需求。基于新场景的接入需求,我们完成了技术架构的微服务改造,并对旧场景逐步进行了迁移,构成了我们当前内容推荐的主要架构

每个场景在gateway阶段分别开放单独的接口,以满足各推荐场景的个性化推荐需求,并在scene阶段收到一起,合并为统一接口进行后面的流程调用。
然而,这种方式依然存在一些问题,APP的场景模块在不断变动或新增,每个场景有可能90%以上的逻辑都是可以复用的,而每新增一个场景就要新增一个接口的方式,导致了很多重复性的工作,浪费时间精力,且对我们代码的质量产生了不好的体验。于是我们就想,像scene一样把接口整合起来,是不是一种更好的方案?
于是我们重新设计了一版gateway的统一接口,通过分类必选参数和可选参数等,用以应对新增的各类场景需求。
经过优化后,与服务端新增场景的需求对接不再需要考虑接口格式等问题,服务端对接接口成本趋于0,新场景开发上线时间由3天缩减至0.5天,
此时的系统架构

遇到的问题
随着业务的发展,我们从对单一APP的支持,扩展到了对多APP多场景的支持,同时由于产品迭代,对推荐策略不断的增加和废弃,系统架构也逐渐出现了一些问题。
- 代码过于臃肿,很多废弃的策略没有及时下线,产生很多无用代码
- Repo层与业务深度绑定,导致难以复用
- 代码架构简单,传统的MVC方式,使得代码的可扩展性提升比较局限
- 为保证需求迭代效率牺牲了一部分的程序健壮性,多了很多“能run就行”的设计
- 新功能的开发受已有设计的影响较大,经常在现有功能的基础上做兼容,无法给出更加合理的设计
重新出发:推荐中台
我们逐渐认识到,推荐引擎不应该像算法模型那样聚焦于某一个方向,而是更侧重于工程本身,目标是为算法提供高扩展性、高可用的推荐服务支持,不应该局限于做小说的推荐引擎。 而现有架构从一开始的定位就是小说书籍推荐,没有一开始就上升到物品推荐的层面,确实是我们眼光狭隘了。不过从另一方面想,“一切从需求出发,避免过度设计”,也是我们所追求的一个理念。
然而,在没有业务支撑的情况下贸然进行技术架构升级是一件费力且收效甚微的事情,直到我们决定要自建七猫广告推荐平台......
为了解决业务逻辑与系统架构耦合的问题,在支持快速迭代的同时保证系统的稳定性和高扩展性,我们不约而同的想到了与微服务最搭的DDD(领域驱动设计)。
领域驱动设计是很早就提出的一种架构设计方法论,在这里就不详细展开了,感兴趣的可以自行了解一下。
我们参考了三点实验室 提供的一种DDD整洁架构方案,并结合我们的业务现状,构建了我们全新的推荐系统架构:
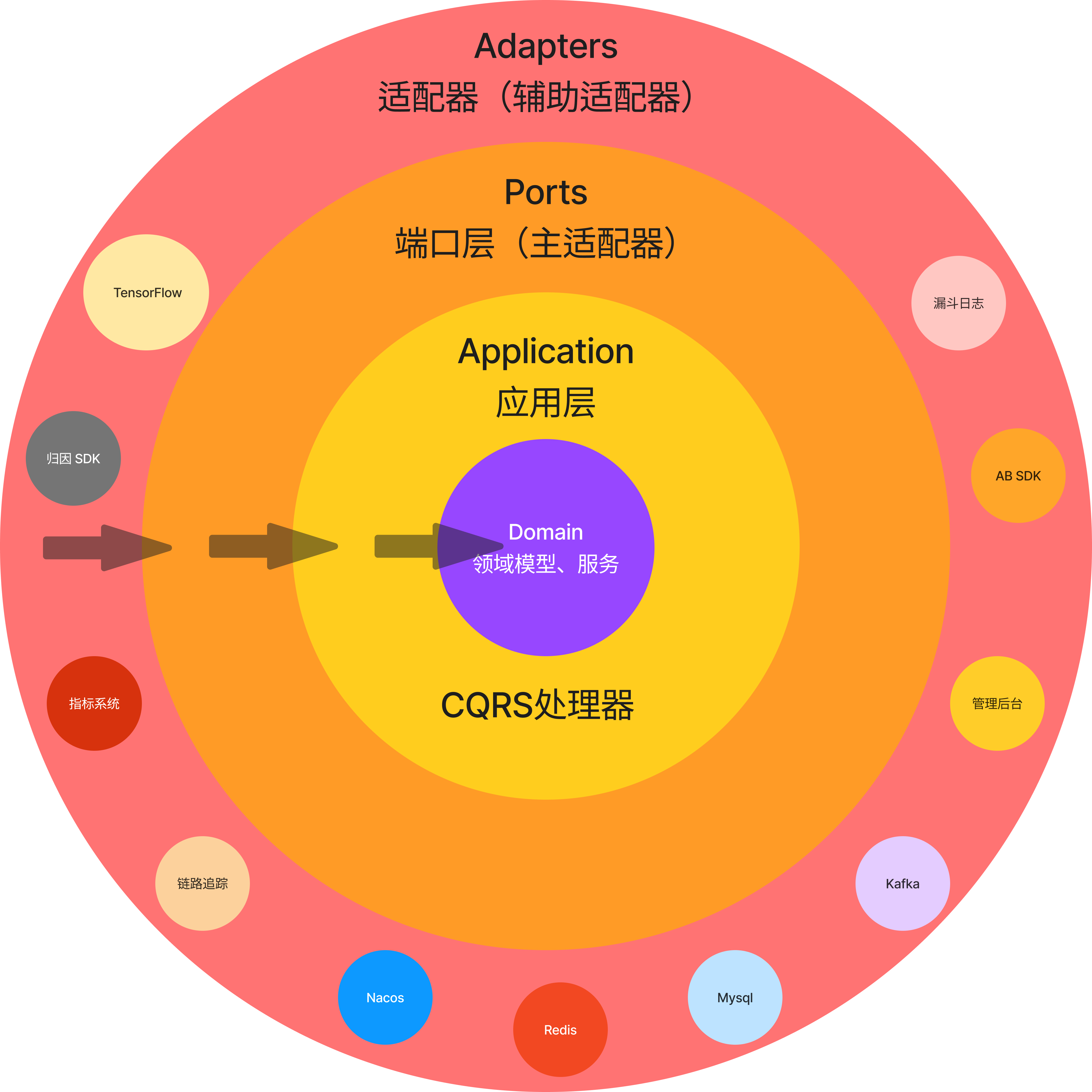
这里提供了两个核心思想:
- 分离端口和适配器
- 限制代码结构相互引用的方式,即依赖倒置原则(Dependency Inversion Principle)。抽象实现细节,实现关注点分离。
外层(实现细节)可以引用内层(抽象),但反之则不然。相反,内层应该依赖于接口
我们基于整洁架构,在业务实现上参考了火山引擎智能推荐平台,重新设计了支持多物品类型推荐的统一接口,提供了高扩展性,高内聚,低耦合的技术架构与良好开发体验,并有效支持了广告推荐和搜索推荐双平台的稳定运行。
至此,形成了我们推荐中台的主要技术架构:

对比其他推荐系统有什么优势
- 策略动态配置,支持热插拔,复用性、可定制化能力强
- 支持推荐阶段级别流量正交的AB实验
- 支持多场景以及多模型的并发调用,根据物品属性有选择的调用不同模型
- 支持多物品并发推荐及混排等
- 在推荐模型上,我们创造性的训练了基于时长指标的推理模型,更加符合小说推荐的场景
当前存在的问题
- 由于内容推荐策略较多,迁移成本较大,当前仍运行在老架构平台
- 当前系统对外部依赖较多,在线模型资源、数据库、kafka、第三方SDK等异常对推荐系统稳定性有较大影响
- 推荐系统当前大部分的存储和缓存都是由Redis进行承接,对Redis等内存缓存的依赖较重,达5TB以上,使用成本相对较高
- 推荐中台目前只是初具雏形,需要更好的进行结构拆分整合,以适应未来更多的挑战
展望未来:稳定性、资源与迭代效率
近两年来随着算法的快速迭代,我们逐渐忽略了对稳定性与资源占用的要求,新功能的上线,策略的升级等都有可能对我们的稳定性带来比较大的挑战,同时不断增加的资源成本也是我们亟需解决的一个问题。
下一步,我们将进一步整合推荐中台,优化代码结构,完成内容推荐的策略迁移,针对第三方服务做到热插拔机制,减少其对我们的稳定性产生影响。
在离线任务上,接手模型部署管理流程,通过argo-flow规范化的处理模型的构建和部署,以及各在离线任务的高效管理。
对于迭代效率,随着目前算法团队的不断壮大,基于阶段的分层AB实验流量也逐渐捉襟见肘,后续我们会规划基于策略正交的AB实验,给算法人员带来更加高效的迭代体验。
另外,我们也会通过全面接入物品画像,用户画像,以及将Redis逐步替换成性价比更高的GaussDB的方式进一步降低资源使用成本,争取在更低的成本下给用户带来更好的推荐体验