前言
七猫日志接收系统系列文章将会向大家介绍七猫日志接收系统及相关的埋点 SDK,总共分为四篇:
- 七猫日志接收系统之架构设计(上)
- 七猫日志接收系统之架构设计(下)
- 七猫日志接收系统之客户端埋点 SDK(本篇)
- 七猫日志接收系统之服务端埋点 SDK
本文为系列的第三篇,将介绍客户端埋点 SDK 的实现,主要涵盖了埋点日志的采集、存储、上传等一系列流程。一般来说,埋点事件日志数据要经历以下几个步骤处理:
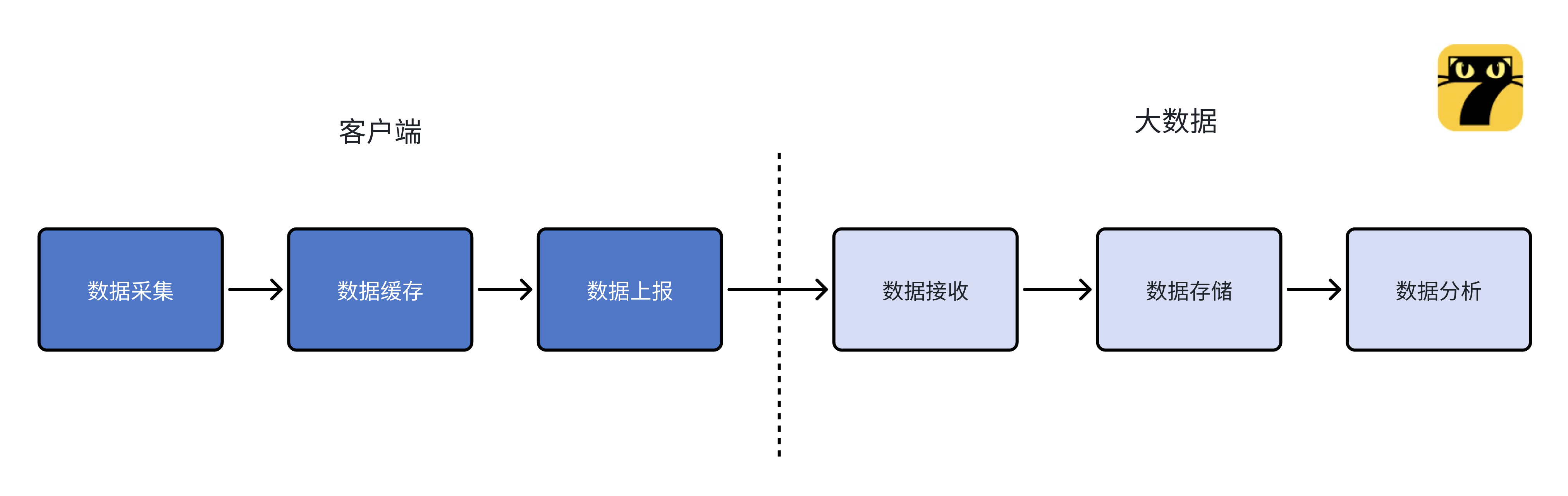
其中,数据采集、数据缓存、数据上报是后续数据分析性的基础,要保证采集的准确性、丰富性、完整性和及时性,直接影响到了后续数据的使用。
注:笔者是 iOS 端开发人员,部分实现细节主要依据于 iOS,但是双端原理都是相通的。
埋点事件模型
为了便于后文叙述展开,我们先来了解一下埋点模型的定义,此处只进行简单说明,更多细节请参看本站文章七猫统计埋点实践。
事件模型定义
事件模型:谁(WHO)在什么时间(WHEN)在什么地点(WHERE)做了什么事情(WHAT)。 其中各元素代表的意义:
元素 | 意义 |
WHO | 设备标识符集合 |
WHEN | 事件触发时间、接收时间等 |
WHERE | 设备环境、网络环境、业务环境等 |
WHAT | 事件、事件属性等 |
例如:韩梅梅在 2021-05-28 09:10:15 分在 WI-FI 环境下启动了七猫免费小说。其余的 WHO、WHEN、WHERE 都是通过客户端 SDK 统一的方式来定义和获取的,一次实现之后,少量优化和维护。而 WHAT 代表事件及属性,是跟业务使用紧密结合的,其质量的好坏,直接决定了后续数据分析系统报表的质量。
事件的定义
事件定义包含事件 ID 和事件属性两个部分。事件 ID:事件 ID 以“页面_组件_展位_事件类型”四段式位置追踪规范组成唯一事件 ID。其中各元素代表的意义:
元素 | 意义 |
页面 | APP 中一个独立的功能页面 |
组件 | APP 中某个页面下的一个功能模块区域 |
展位 | APP 中某个页面某个组件下的具体的一个功能元素 |
事件类型 | 该次事件动作的类型,如展现、点击、阅读等 |
在七猫埋点后台进行埋点管理时,也按照对应页面、组件、展位、事件类型进行定义,各元素命名规范:
- “#”可以用作所有元素的通配符;
- 不能出现汉字、拼音、拼音英文混用的情况;
- 只有展位可以用数字命名,如果用数字要用纯数字,不要加入其他符号;关于页面、组件、展位的定义,参照以下组图进行理解:
事件属性:事件属性指事件携带的可定义属性,如 bookid(书籍 ID)、chapterid(章节 ID)、duration(看书时长)等,事件属性会提供一个固定列表,在使用中发现属性列表不能满足需要时,由大数据研发评估后增加属性。
埋点事件采集
代码埋点
最简单通用的的埋点方式,传入事件名(采用了四段式 SPM 模型【参见:超级位置模型 SPM(Super Position Model)】,标识唯一性)以及事件参数:
// 参数类型
typealias EventID = String
typealias EventParams = [String: PropertyType]
// 埋点方法
Analytics.track(eventId: EventID, eventParams: EventParams)参数类型支持基础数据类型、集合类型,并在编译时进行强校验、并支持存储格式转换:
public protocol PropertyType {
var storageValue: PropertyType { get }
}
public extension PropertyType {
var storageValue: PropertyType { self }
}
/**
需要支持 字符串,整形、浮点型、List(字符串)
*/
// MARK: - Swift Extension
extension String: PropertyType {}
extension Bool: PropertyType {}
extension Int: PropertyType {}
extension Int8: PropertyType {}
extension Int16: PropertyType {}
extension Int32: PropertyType {}
extension Int64: PropertyType {}
extension UInt: PropertyType {}
extension UInt8: PropertyType {}
extension UInt16: PropertyType {}
extension UInt32: PropertyType {}
extension UInt64: PropertyType {}
extension Double: PropertyType {}
extension Float: PropertyType {}
extension CGFloat: PropertyType {}
extension Array: PropertyType where Element == String {}
// MARK: - OC Extension
extension NSString: PropertyType {}
extension NSNumber: PropertyType {}
extension NSArray: PropertyType {}代码埋点的优势在于埋点时机的精准性、参数的灵活性,能够满足精细化的需求;但是代码埋点业务入侵比较大、开发量较大,并且受发版限制。
注:本文暂不讨论全埋点、可视化埋点等,聚焦与埋点的基础能力。
预置埋点事件
除了业务自定义埋点信息以外,SDK 内部会预置特定埋点和事件参数,以丰富埋点数据、方便后续数据分析。
预置埋点事件
事件名 | 事件触发时机 | 事件参数 |
启动事件 | App 回前台 | ts(时间戳) |
结束时间 | App 退后台 | ts(时间戳) |
App 启动次数、使用时长、PV/UV 等都是统计的关键指标,大数据侧可以通过预置埋点计算得出。iOS 端,Home 键双击、来电、任务栏下拉都不会触发进后台(enterBackground),只会触发失去焦点(resignActive),所以前后台切换可以在失去焦点/获取焦点中实现。
预置事件属性
属性名 | 属性类型 | 备注 |
ts | 整形 | 时间戳,标记事件发生时间,方便数据分析做用户行为路径分析 |
session | 整形 | 会话 ID,标记单次“启动”发生的行为,方便数据分析用户行为。 |
除了业务传入的自定义参数,SDK 内部也会为每个事件添加预置参数,丰富埋点信息。
预置上报信息
类型 | 信息名 | 备注 |
App信息 | version、build | 版本号 |
channel | 渠道号 | |
package | 包名 | |
...... | ||
设备信息 | machine | 型号 |
os | 系统版本号 | |
...... | ||
用户信息 | userid | 用户id |
idfa/idfv/oaid/imei/mac | 设备唯一值 | |
...... |
考虑到 App 信息、设备信息、用户信息基本都是短时间内不会变动的,为了减少流量消耗、带宽占用等,单次上报额外会额外添加的信息,而非是每个事件预置属性。同时,SDK 也提供了一定的自定义的能力,支持业务扩展:
// 添加静态属性
Analytics.addIdentity(with key: String, value: String)
// 添加动态属性
Analytics.addIdentity(with key: String, value: @escaping () -> String)埋点事件缓存
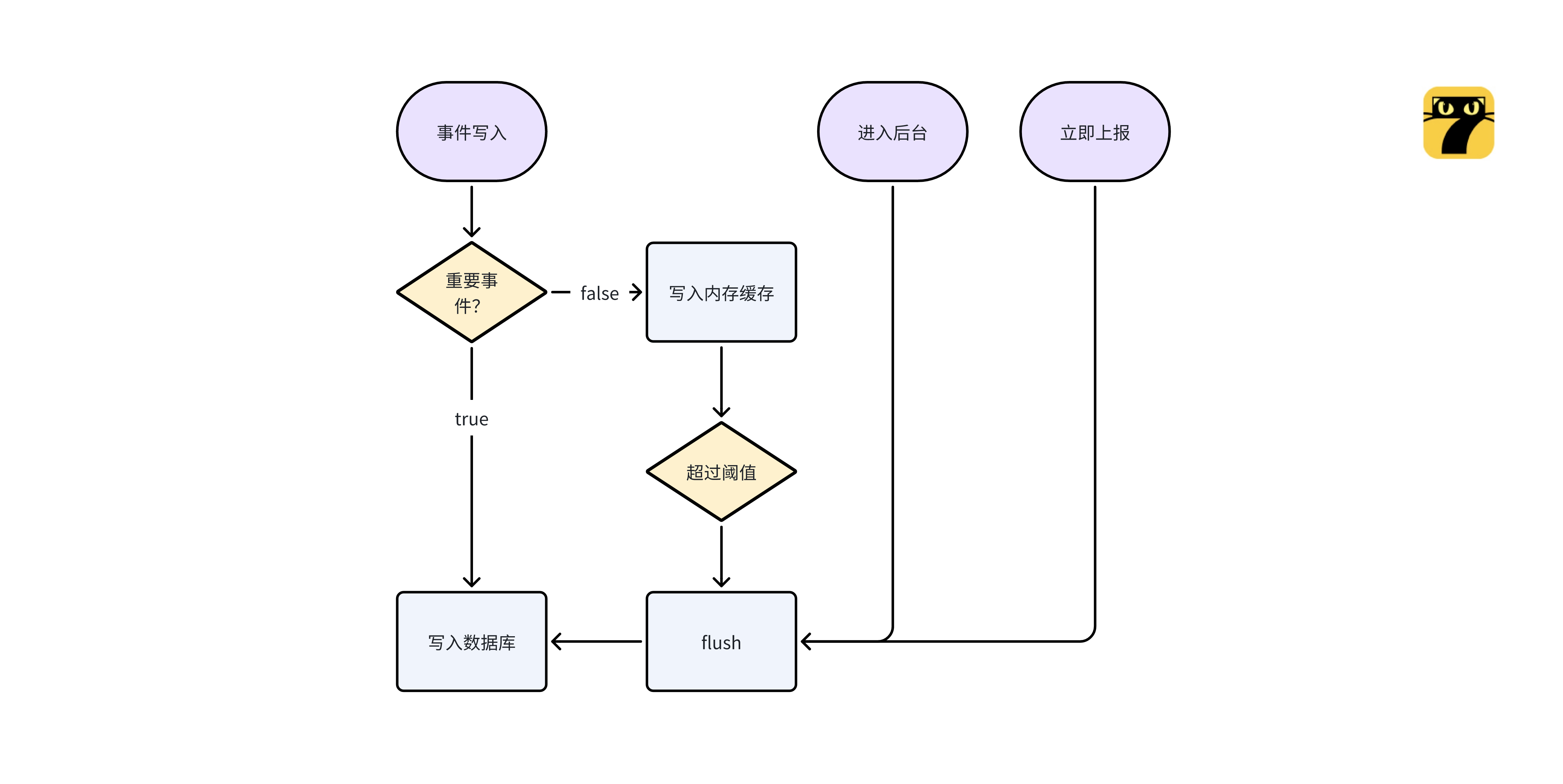
埋点触发非常的频繁,考虑到用户体验、减少电量和流量的消耗,默认都不会立即上报;SDK 内部会进行埋点二级缓存(内存+磁盘):
- 磁盘缓存:存在跨启动上报的场景,会缓存到数据库内。
- 内存缓存:为了降低 IO 的频率,会先进行内存缓存、达到阈值后写入数据库。
为了保证数据完整性,在进入后台等时机也会触发内存同步磁盘;但是还是无法避免极端场景(比如崩溃)下数据丢失的可能性,这还是当前可接受的。
缓存策略分两种,重要事件会立即写入磁盘(比如启动事件、避免极端场景数据丢失),普通自定义事件会先缓存到内存、再写入到磁盘。
当然也会有缓存清理策略,当本地缓存过大时,也会根据事件重要程度有不同的清理策略(线上我们也发现有部分极端用户,长时间断网看书、累计了巨量数据)。
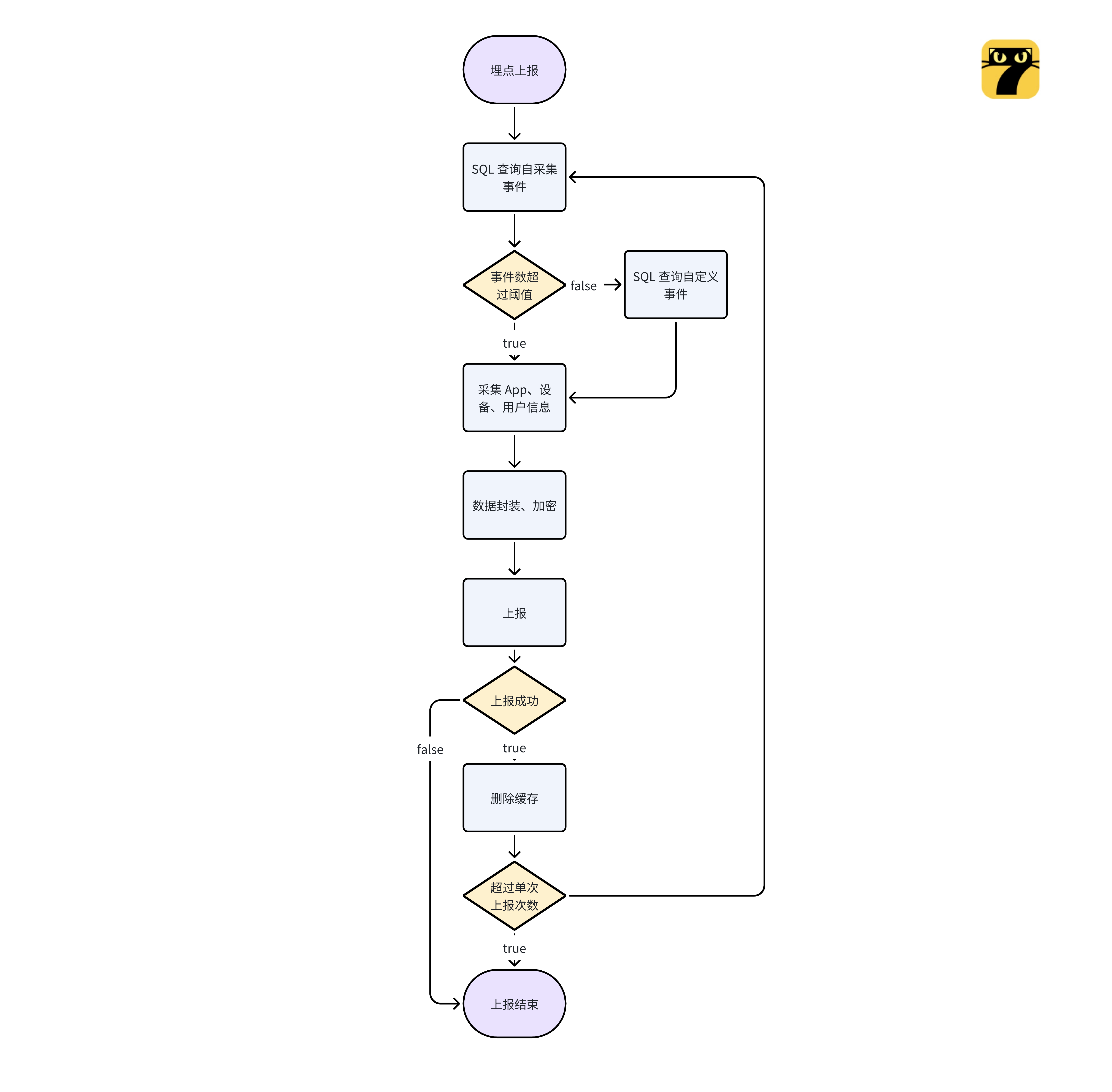
埋点事件上报
埋点上报的策略一般包含:
- 定时上报:减少上报频率,固定间隔上报聚合埋点数据;
- 立即上报:特殊的埋点、服务端可配置化,写入即上报,比如推广归因、算法及时推荐等需要;
- 手动上报:特殊业务场景,也支持业务手动触发上报。
同时为了防止单次数据量过大,单次上报也会做些控制以及优化:
- SDK 会优先上报重要事件;
- 限制每次上报事件数量;
- 针对相同事件做聚合处理;
- App 信息、设备信息、用户信息和事件同层级;
- 单次上报会进行连续 N 次上报。
最后上报的数据格式:
{
"events":[
{
"event_id":"bookstore_banner_title_click",
"event_params":{
"title":"幸运七活动",
"content":"参加活动赢好礼"
},
"event_count":"10"
},
{
"event_id":"bookstore_recommend_tip_show",
"event_params":{
"bookid":"7812641",
"title":"一剑独尊"
},
"event_count":"8"
}
],
"app":{
"version":"7.34",
"channel":"appstore"
},
"device":{
"os":"iOS"
},
"user":{
"idfa":"080006E2-5666-49C1-8786-3FD9FC77DC0A",
"idfv":"080006E2-5666-49C1-8786-3FD9FC77DC0B"
}
}总结和展望
本文聚焦于客户端统计 SDK 基础能力,不过于发散;客户端主要是保证采集的准确性、丰富性、完整性和及时性。除此之外,还有许多细节却同样重要,比如如何保证 ID 的唯一性(避免卸载重装误判)、保证 SDK 的性能以及稳定性等等,这里就不一一展开了。
随着业务持续发展,对于统计的基础能力要求也越来越高,我们也持续落地了一些新的能力,比如增加了链路追踪能力;同时我们也正在进行一些新的探索。