背景
Metrics(指标)、Logging(日志记录)、和Tracing(追踪)通常被称为可观测性的三大支柱。在微服务架构下,分布式追踪是一种关键工具,用于帮助排查和理解服务问题,它允许跟踪请求流程并提供关键的信息,以便更容易发现和解决问题。
随着服务数量的日益增加,承接全量的 Tracing 数据所需的资源越来越多。如果全量采集,链路中产生的span 所占的存储成本将会很高。目前生产环境采用0.1% 的采集率,存储成本较低。这种策略虽然很节省资源,但其缺点在一次次线上问题排查中逐渐暴露:
- 一个进程中包含多个接口:不论按固定概率采样还是限流采样,都会导致小流量接口一直采集不到调用链数据
- 线上服务出错是小概率事件,导致出错的请求被采中的概率更小,就导致采到的调用链信息量不大,引发问题的调用链却丢失的问题
OpenTelemetry 生态中提供了一些简单的手段应对上面的问题。
OpenTelemetry
OpenTelemetry合并了OpenTracing和OpenCensus项目,提供了一组API和库来标准化遥测数据的采集和传输。OpenTelemetry提供了一个安全,厂商中立的工具,这样就可以按照需要将数据发往不同的后端。
OpenTelemetry项目由如下组件构成:
- 推动在所有项目中使用一致的规范
- 基于规范的,包含接口和实现的APIs
- 不同语言的SDK(APIs的实现),如 Java, Python, Go, Erlang等
- Exporters:可以将数据发往一个选择的后端
- Collectors:厂商中立的实现,用于处理和导出遥测数据
Tail Sampling Processor
为了解决这些问题,我们可以采取一种方法,即将所有生成的数据发送到一个中间平台,该平台会先进行暂存和清洗,然后再决定是否要保留或丢弃整个跟踪信息。具体操作如下图所示:当一个请求到达时,每个服务会将其生成的跟踪信息(Span)发送到一个名为OpenTelemetry Collector的中间组件。在Collector上有一个尾部采样组件,该组件会在接收到第一个Span后,等待一段时间(例如5秒),以便继续收集来自其他服务、具有相同Trace ID的Span。等待时间结束后,大量的Span会按照它们的Trace ID进行分类汇总,然后对属于同一个Trace ID的Span进行遍历,以检查是否包含错误信息,或者累计耗时是否超过了预设的阈值等。基于这些信息,可以有依据地筛选出高价值的跟踪信息,将它们纳入后续的处理流程。这种方法有助于更有效地处理跟踪数据,识别潜在问题,以及提高整体性能。
这种采样的模式称为尾部采样,它由 Collector 依据完整 Trace 的信息进行决策,决策的依据比头部采样丰富很多。但是由于需要承载大量临时数据,所以对基础设施要求很高。它的效果在于:
- 持久化的数据有依据、有规律、有价值;
- 减少了展示有价值数据所需的成本,例如存储资源,并且对提高查询速度也有帮助。
需要注意的是,在实际部署中,整个架构要做到高可用,往往会存在多个 Collector 节点,而同一个 Trace 的不同 Span 是由不同服务产生的,这些服务位于不同地方,尾部采样要求他们都落入相同的 Collector 节点,那么必然需要一层负载均衡架设在 Collector 之前,依照 Trace ID 进行转发。让 otel-agent 按照 traceID 做负载均衡,使用exporters 中的loadbalancing 组件。
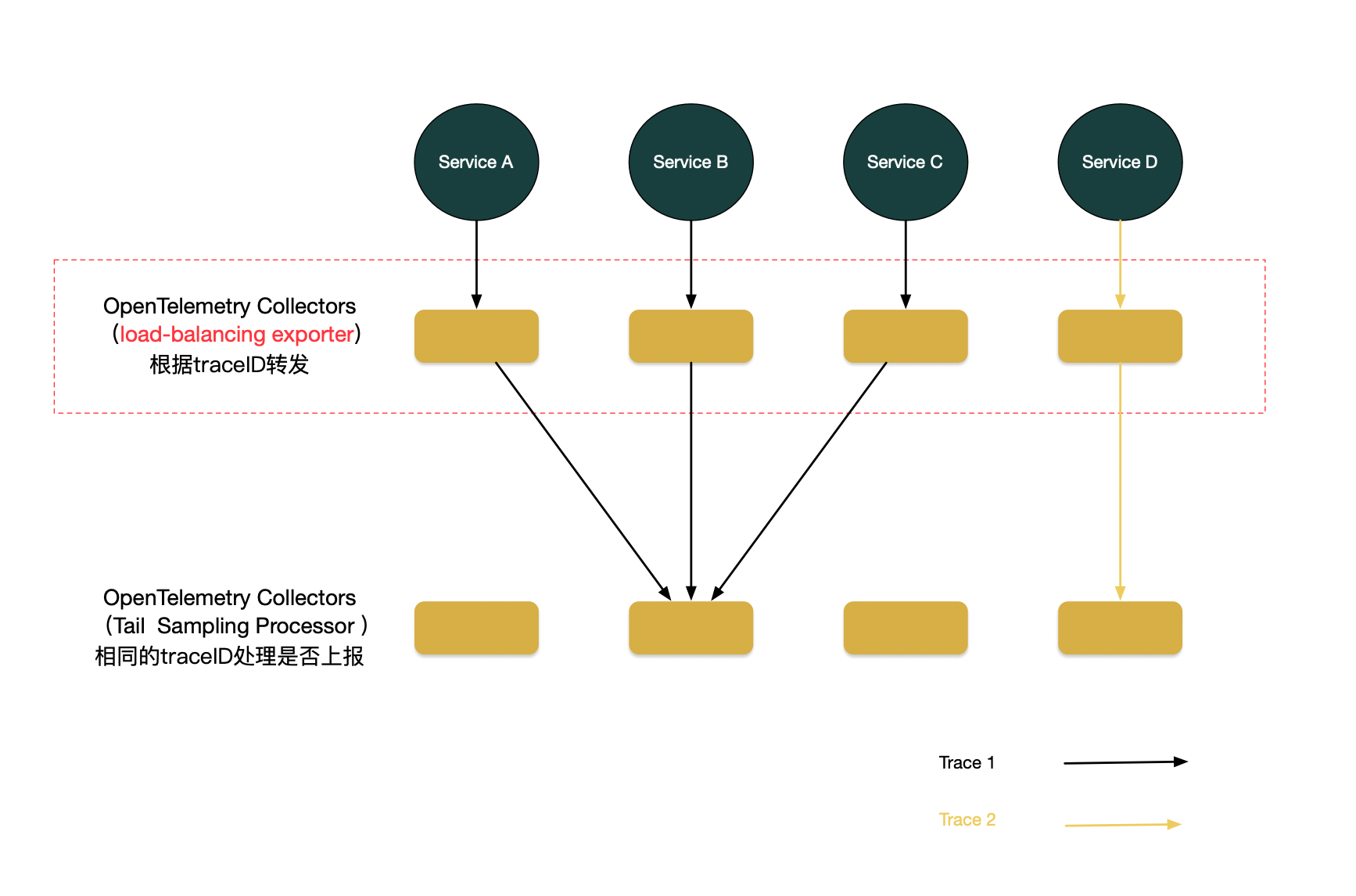
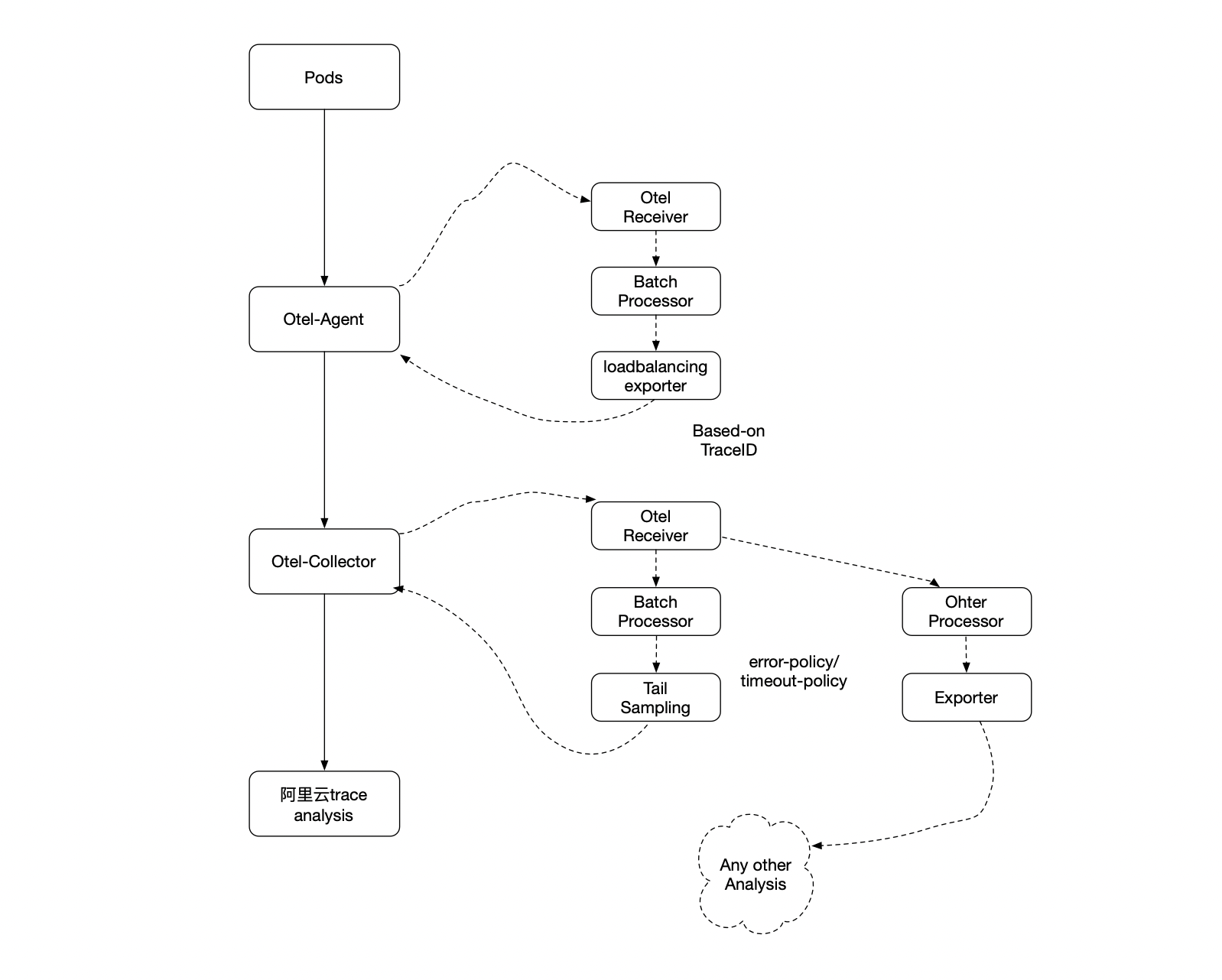
架构图如下:
pod 通过sdk 的方式上报到otel-agent,agent 的receivers使用otel grpc的方式接收trace;processors 使用 batch 来批量处理;exporters 使用 loadbalancing 方式根据traceID 负载到下游同一个collector。
otel-collector 由grpc 接收相同traceID的span,本地批量处理,基于这些信息根据 tail_sampling 配置规则决定是否上报到阿里云analysis平台。同时可配置不同的processor 处理不同数据导出到不同的平台。
部署和配置
loadbalancing 采用k8s的方式部署,配置如下:
exporters:
loadbalancing:
protocol:
otlp:
timeout: 5s
sending_queue: # 发送队列
enabled: true
num_consumers: 50 # 消费者数量
queue_size: 5000000 # 队列长度
retry_on_failure:
enabled: false # 是否重试
tls:
insecure: true
resolver:
k8s: # k8s service 方式获取pod 的IP 进行负载均衡
service: otel-collector.observable
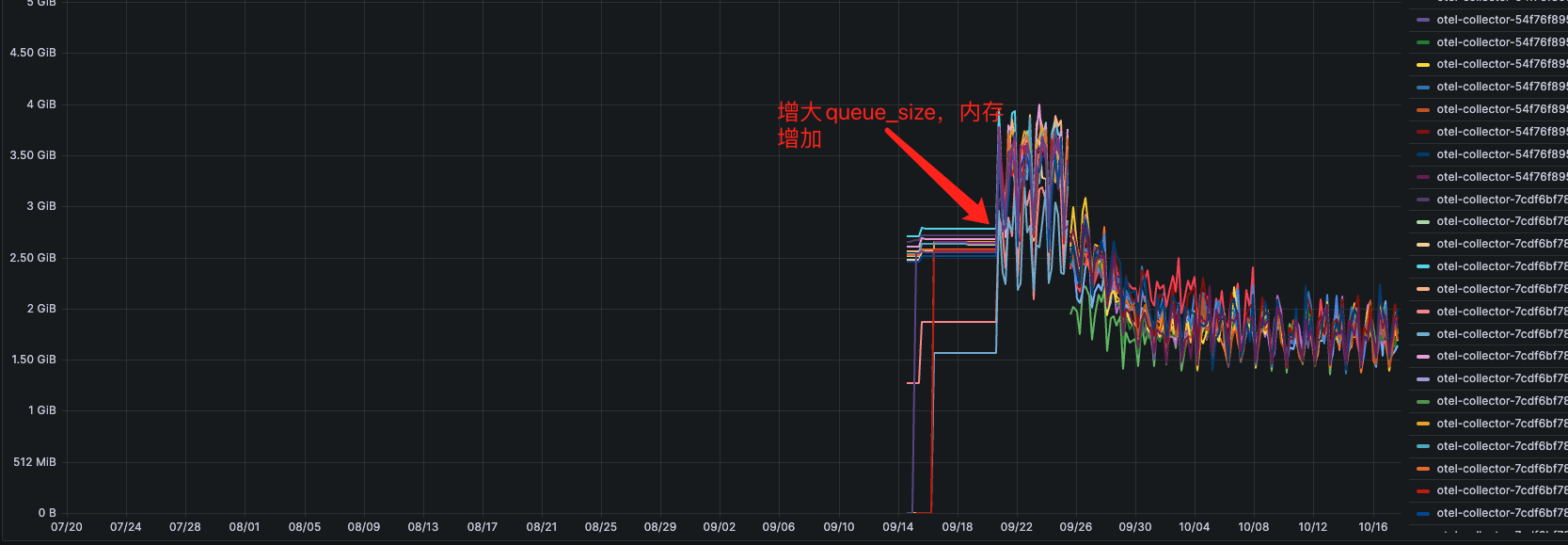
otlp 中的队列,queue_size 这个参数指定了队列的最大容量,即可以在队列中缓存等待发送的数据点的最大数量。如果队列已满,新的数据点可能会被丢弃或被替代。这个参数可以用来控制队列的内存使用和数据传输的稳定性。
配置 retryonfailure = true,增大queuesize值,会导致内存增加;后续根据请求的qps 和span 产生量,配置合理的queuesize。
使用k8s 负载均衡方式,需要创建对应的账号权限
- 创建 service account
apiVersion: v1
kind: ServiceAccount
metadata:
name: otel-loadbalancer
namespace: observable
- 创建 role
apiVersion: rbac.authorization.k8s.io/v1
kind: Role
metadata:
name: otel-loadbalancer-role
namespace: observable
rules:
- apiGroups:
- ""
resources:
- endpoints
verbs:
- list
- watch
- get
- 创建role binding
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:
name: otel-loadbalancer-rolebinding
namespace: observable
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: Role
name: otel-loadbalancer-role
subjects:
- kind: ServiceAccount
name: otel-loadbalancer
namespace: observable
关注的调用链全采样:研发在分析、排障过程中想查询的任何调用链都是重要调用链。总结以下优先级高场景:
- 在调用链上error 级别日志
- 整个调用链请求耗时超过 250ms
processors:
tail_sampling:
decision_wait: 5s # 等待5秒,超过5秒后的traceid将不再处理
num_traces: 1500000
expected_new_traces_per_sec: 10 # 新增的trace 数量
policies: # 上报规则策略
[
{
name: error-policy,
type: status_code, # 状态码,err
status_code: { status_codes: [ ERROR ] }
},
{
name: timeout-policy,
type: latency, # 耗时,超过250ms 上报
latency: { threshold_ms: 250 }
}
]
numtraces 推荐的计算规则:假设每秒有100 traces(不是span),配置 decisionwait:5,则 numtraces=100*5*2=1000;numtraces 越大,对应的内存也会越大。
decision_wait 是一个全链路的上报采集的等待时间,超时则丢弃后续traceID 的链路信息;请根据业务设置相应的超时时间,但是如果超时时间设置的特别大,会导致占有内存增加。
相关issues https://github.com/open-telemetry/opentelemetry-collector-contrib/issues/17275
效果
部分服务的有效链路追踪信息如下:
- 系统消息,每天产生的有效链路追踪只有2条,很容易处理对应的问题
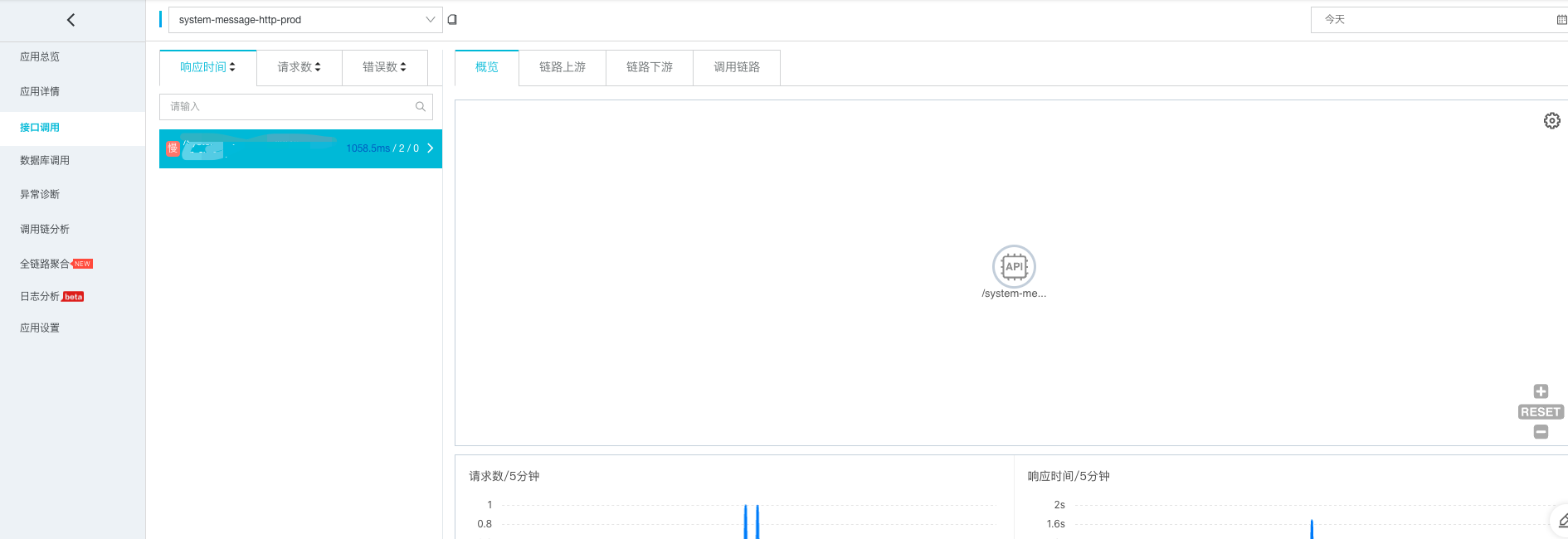

- 其他服务,redis操作产生的error,都被全量采集
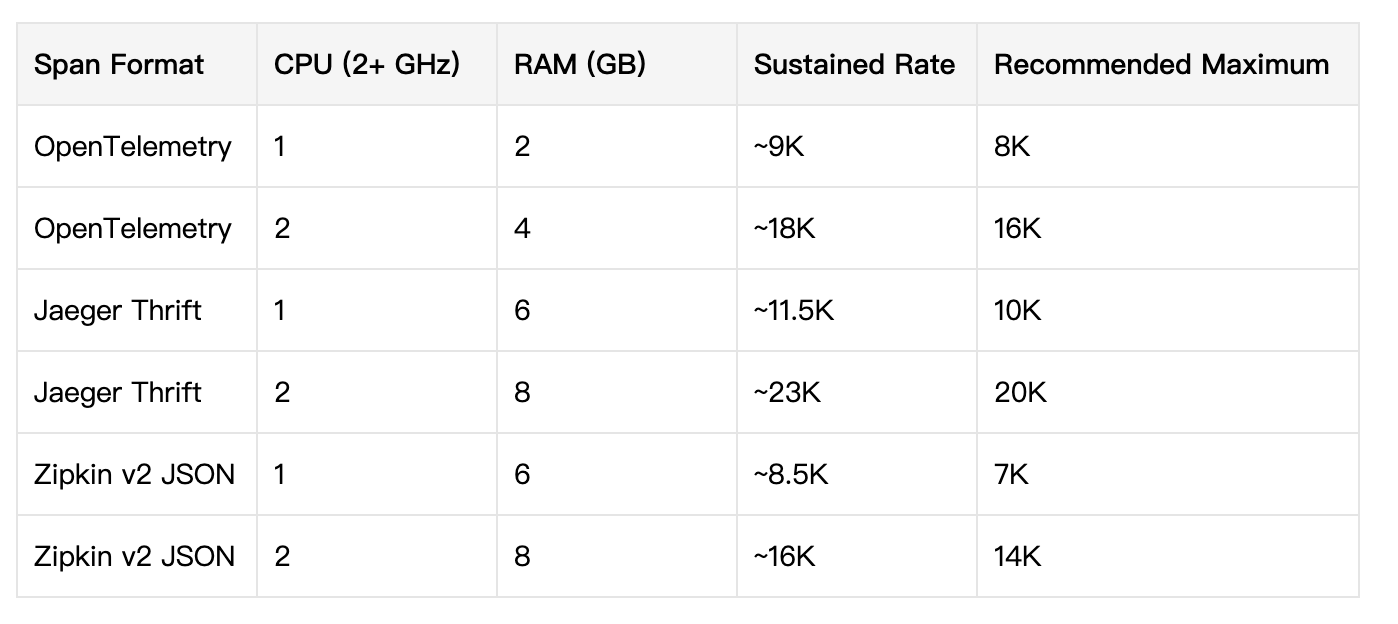
资源使用
以下是官方给出的资源使用情况,测试脚本。测试配置如下:
- FlushInterval(ms) [default: 1000] (刷新间隔 1秒)
- MaxQueueSize [default: 100] (最大队列100)
- SubmissionRate(spans/sec): 100,000 (每秒产生10w 的span)
头部采集法

尾部采集法
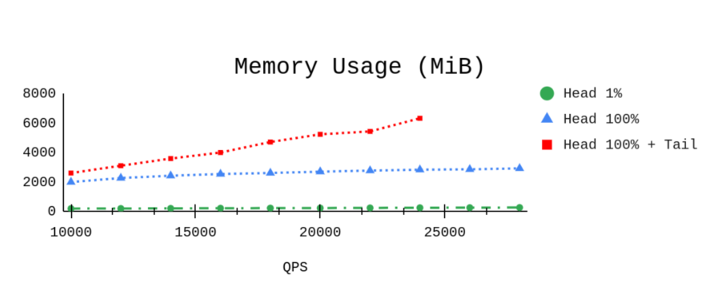
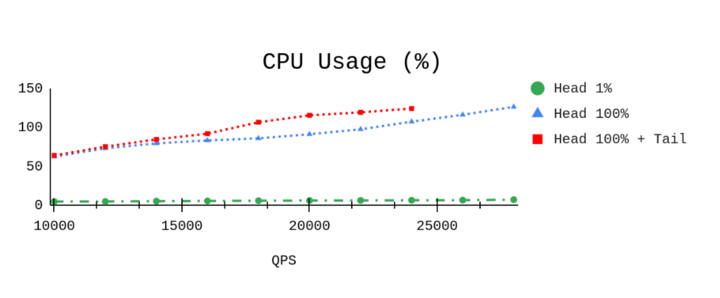
尾部采样需要更多的基础设施资源,这在内存上体现得比较明显;目前生产环境的资源消耗也是符合预期的。
本地压测
测试代码 https://github.com/open-telemetry/opentelemetry-collector-contrib/blob/main/testbed/tests/trace_test.go#L399,需要修改为tail sampling processor,默认是没有加载的;可以参考README 来实现。
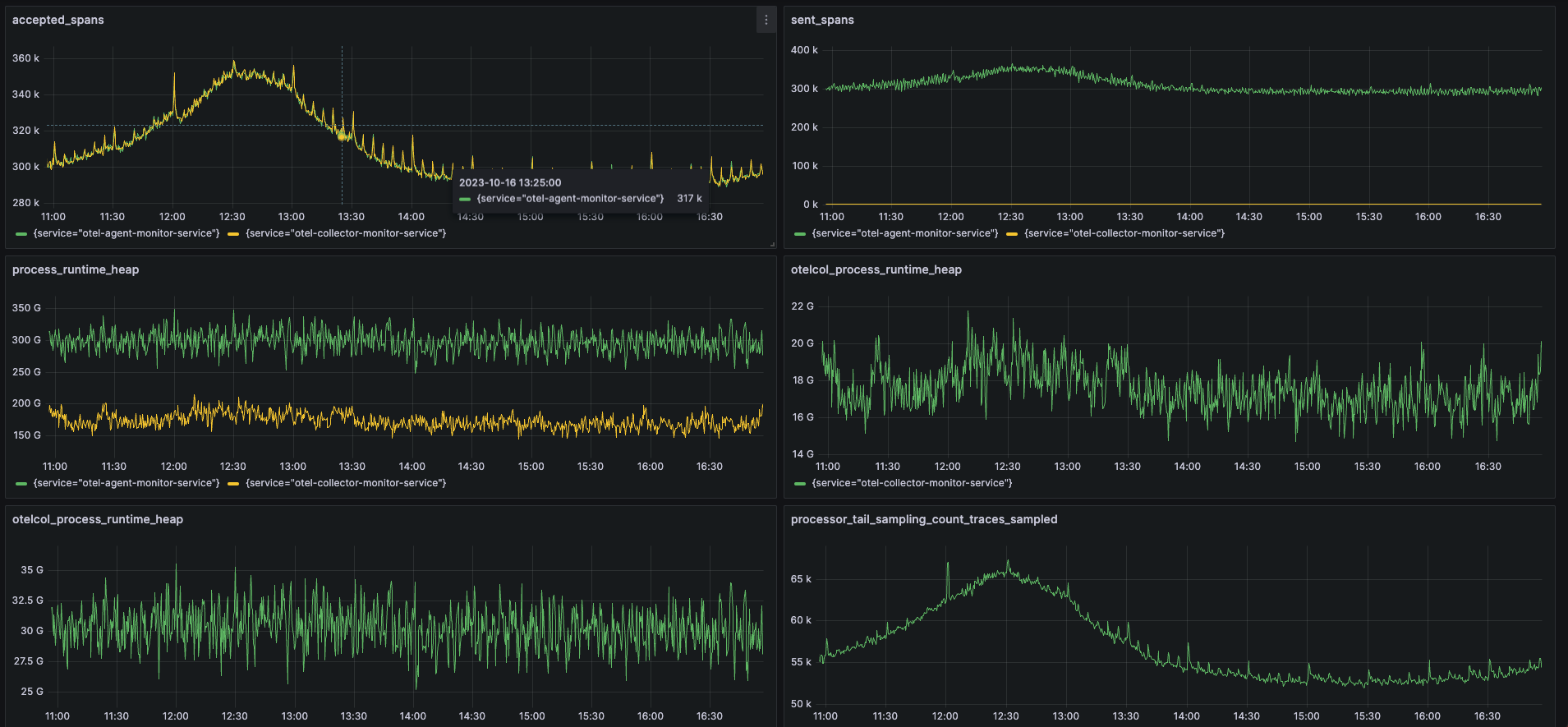
生产资源使用情况
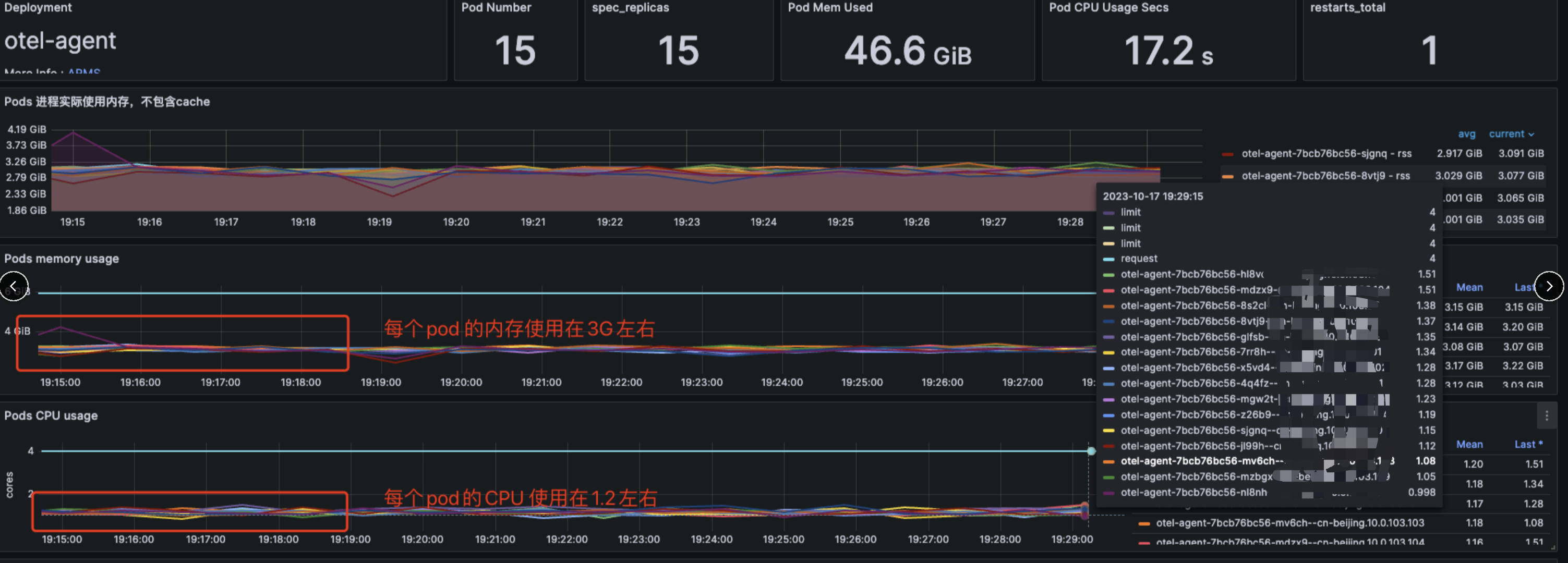
otel-agent 的CPU 内存资源消耗:
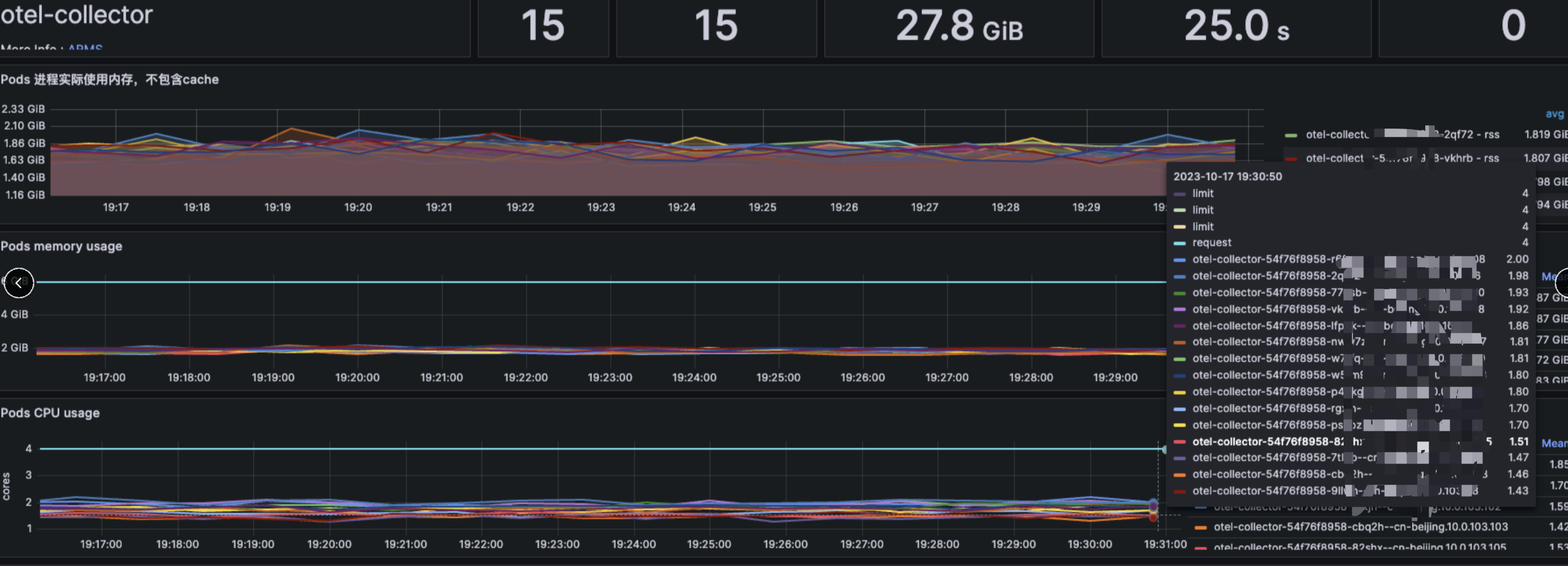
otel-collector 的CPU内存 资源消耗:
320k/8k = 40CPU,目前collector使用了30CPU,优化的点在于使用k8s方式部署,每个pod的cpu被限制使用4C,没有配置automaxprocs,导致CPU使用40C左右,使用automaxprocs后优化了 1C/pod 左右。对比图如下:

小结
借助开源项目,我们得以通过花费极少的人力,解决当前内部调用链追踪应用的稳态分析及异常检测需求,相比较头部全量采集的存储成本,我们使用OpenTelemetry tail-based sampling 的方式大大降低了成本,存储成本降了几十倍。调用链追踪是可观测性平台的重要组件,未来将继续把一些精力放在 telemetry data 的整合上,为研发提供更全面、一致的服务观测分析体验。
参考
https://opentelemetry.io/docs/collector/
https://github.com/open-telemetry/opentelemetry-collector/blob/main/docs/performance.md