性能监控与优化是现代软件开发中不可或缺的一环,尤其是在分布式系统和服务端应用中。通过有效的性能监控工具,开发者能够快速定位并解决性能瓶颈,从而提升系统的响应速度和用户体验。继《使用 Pyrscope 结合 Holmes 加速找到服务瓶颈》之后,Pyroscope 在我们的团队中发挥了重要作用。例如,在 ADX 服务中,通过对深拷贝操作的优化,实现了性能提升 10%的目标;在配置中心方面,我们也通过性能监控发现并解决了多个关键瓶颈。
然而,尽管 Pyroscope 和 Holmes 已经在性能监控方面取得了显著成果,但仍存在一些不足之处。首先,目前只有 Holmes 异常上报机制,缺乏正常运行时的数据上报,这使得在排查问题时缺乏对比基准。其次,随着 Go 语言版本 1.21 的发布,Profile-Guided Optimization (PGO) 已经成为标准特性之一,但 Holmes 上报的数据多为异常情况下的数据,也不太适合直接用于 PGO 编译。
一、背景
为了克服上述挑战,我们需要探索一种新的方法来收集正常运行时的数据,并有效地利用这些数据来指导编译优化。具体来说,我们需要解决两个主要问题:
1.如何上报正常的数据?
在日常运营中,系统大部分时间都处于正常运行状态,这些状态下的数据对于理解和优化系统行为至关重要。然而,现有的监控工具往往侧重于异常情况的捕捉,忽略了常态数据的收集。因此,我们需要一种机制来自动收集并上报正常运行时的数据,以便于后续分析和优化。
2.如何将这些数据作用于PGO编译?
PGO 是一种基于程序执行模式的编译优化技术,通过分析程序在实际运行中的行为来指导编译器生成更高效的机器码。然而,由于 Holmes 目前主要上报的是异常情况下的数据,我们需要找到一种方法来清洗和转换这些数据,使其适用于 PGO 流程,从而真正发挥 PGO 在性能优化方面的潜力。
本文将探讨如何通过合理的配置和工具链来实现上述目标,包括使用 Pyroscope 进行持续性能监控、通过 Alloy 进行数据采集,以及如何利用正常运行时的数据来进行 PGO 优化。通过这一系列的实践,我们将不仅能够更有效地识别性能问题,还能够在编译阶段就实现性能优化,从而进一步提升
二、架构设计
在监控系统中,数据采集通常有两种模式:拉取(Pull)和推送(Push)。原有系统中,Holmes 主要采用推送模式,即将异常数据推送到 Pyroscope 中。然而,在大规模集群环境下,推送模式可能会带来较高的性能开销和存储成本。因此,考虑使用拉取模式来采集正常运行时的数据是一个合理的选择。
推送模式(Push):
- 优点:实时性强,数据可以立即发送到监控系统。
- 缺点:在大规模环境下,每个Pod都需要主动主动数据,可能导致网络带宽和监控系统的负载增加。
拉取模式(Pull):
- 优点:减轻了目标监控系统的负载,可以更好地控制数据采集频率和批量大小。
- 缺点:相对于推送模式,实时性稍差,但可以通过配置来减少延迟。
Grafana Agent 和 Grafana Alloy 都支持拉取模式。由于 Grafana Agent 已不再更新,未来是 Grafana Alloy 主流,因此我们这里也采用 Grafana Alloy 进行采集数据。
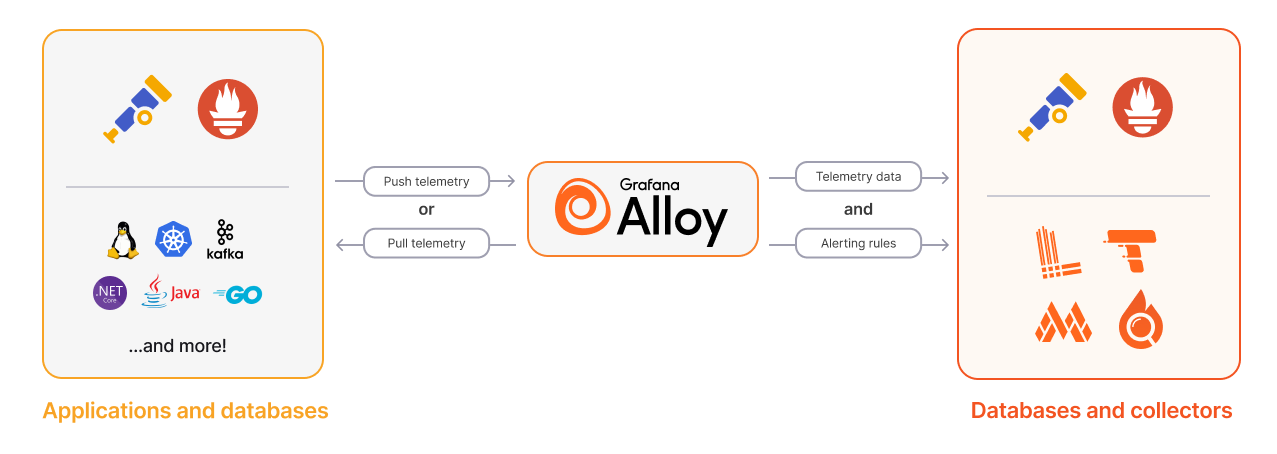
最终我们的架构如下图所示:
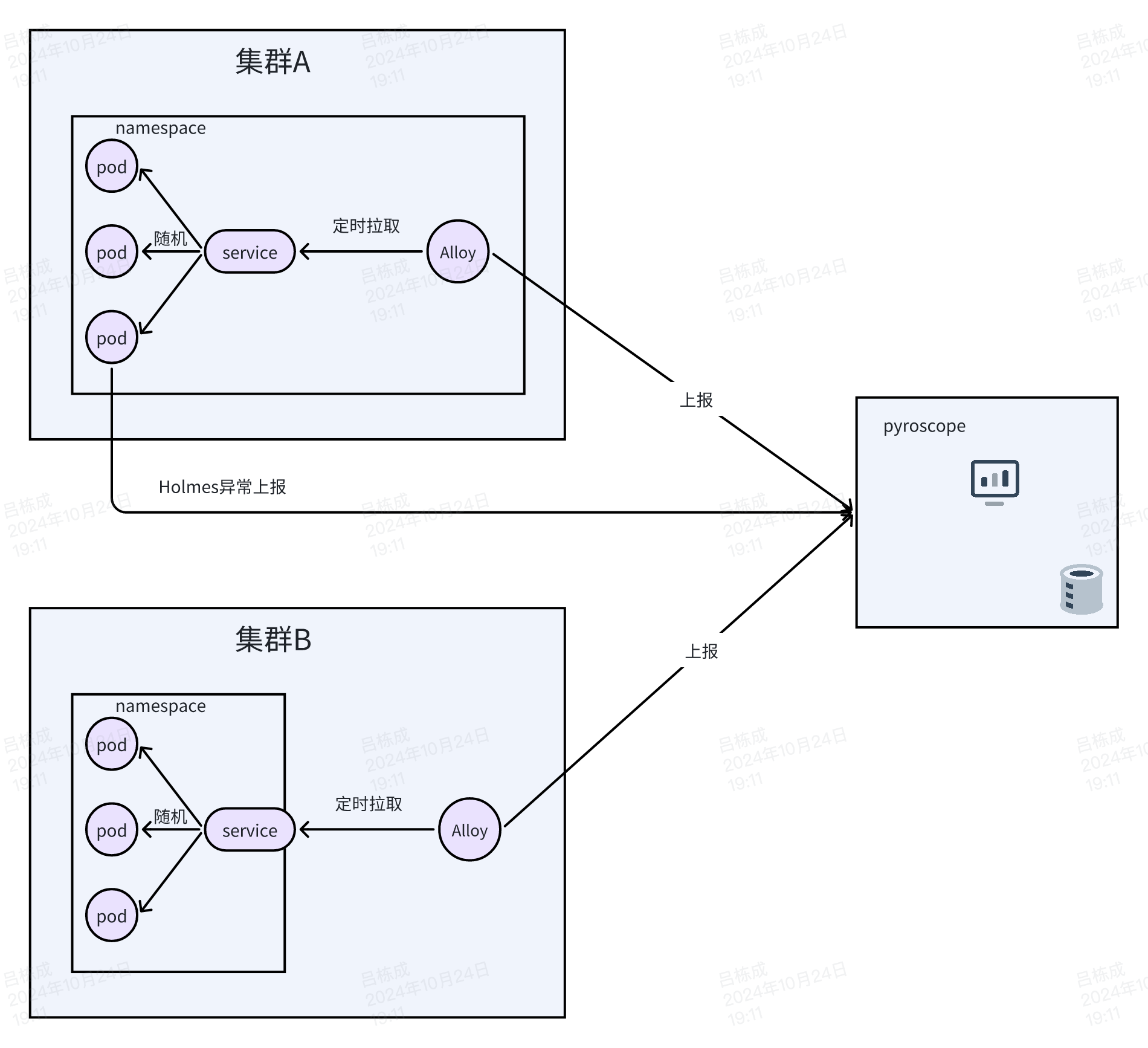
三、部署
Pyroscope
1. Helm 简介
Helm 是 Kubernetes 社区中最流行的包管理工具,它允许用户轻松地安装、卸载、升级和管理 Kubernetes 上的应用程序。Helm 使用类似于 Linux 包管理工具(如 apt 或 yum)的概念,但在 Kubernetes环境下称为“图表”(Charts)。
2.部署Pyroscope
- 安装 helm。
- 添加grafana的官方helm存储库并更新。
helm repo add grafana https://grafana.github.io/helm-charts
helm repo update3.查找pyrscope并安装,pyrscope-custom为自定义名称。
> helm search repo pyroscope
NAME CHART VERSION APP VERSION DESCRIPTION
grafana/pyroscope 1.7.1 1.7.1 🔥 horizontally-scalable, highly-available, mul...
> helm -n test-3 install pyroscope-custom grafana/pyroscope
NAME: pyroscope-custom
LAST DEPLOYED: Tue Oct 8 14:01:38 2024
NAMESPACE: test-2
STATUS: deployed
REVISION: 1
TEST SUITE: None
NOTES:
Thanks for deploying Grafana Pyroscope.
# Pyroscope UI & Grafana
Pyroscope database comes with a built-in UI, to access it from your localhost you can use:
```
kubectl --namespace test-2 port-forward svc/pyroscope-custom 4040:4040
```
You can also use Grafana to explore Pyroscope data.
For that, you'll need to add the Pyroscope data source to your Grafana instance and configure the query URL accordingly.
See https://grafana.com/docs/grafana/latest/datasources/grafana-pyroscope/ for more details.
The in-cluster query URL for the data source in Grafana is:
```
http://pyroscope-custom.test-2.svc.cluster.local.:4040
```
# Collecting profiles.
There are various ways to collect profiles from your application depending on your needs.
Follow our guide to setup profiling data collection for your workload:
https://grafana.com/docs/pyroscope/latest/configure-client/4. 验证安装
❯ kubectl -n test-2 get pod | grep py
pyroscope-custom-0 1/1 Running 0 92s
pyroscope-custom-alloy-0 2/2 Running 0 92s5. 转发端口
kubectl -n test-2 port-forward svc/pyroscope-custom 4040:40406.打开本地界面
但是使用时发现了很多问题,如

这些都是由pyrscope配置决定的,那如何去修改和更新pyrscope的配置呢?
- 直接修改 configmap 中的配置,但存在着更新即丢失的情况,且不利于后期维护,同时也违背了helm 的初心。
- 通过helm values进行配置。
那如何通过helm value进行配置呢?
pyroscope:
# 持久化存储
persistence:
enabled: true
selector:
matchLabels:
app.kubernetes.io/name: phlare
existingClaim: pyroscope-pvc
config: |
pyroscopedb:
max_block_duration: 1h
limits:
ingestion_rate_mb: 12
ingestion_burst_size_mb: 12
max_profile_size_bytes: 0
max_query_length: 2d
max_profile_stacktrace_samples: 48000
querier:
query_store_after: 72h
alloy:
# 关闭alloy
enabled: false具体配置信息可以参考官方文档说明。
将上面的yaml配置保存为yaml文件,这里就以pyrscope.yaml为例子。
执行helm升级命令,该命令将发布升级到新版的chart。
helm -n test-2 upgrade pyroscope-custom grafana/pyroscope -f pyroscope.yaml这个时候,再去查看我们的pod,此时仅剩pyrscope-custom-0
> kubehw_test -n test-2 get pod | grep py
pyroscope-custom-0 1/1 Running 0 3m29s那pyrscope-custom-alloy-0去了哪里呢?
由于我们的pyrscope服务为单点部署,在该点集群或者机器中无需收集信息,因此在配置文件中设置了alloy.enabled=false,helm update就可以根据配置进行alloy下线处理了。
Alloy
目前我们已经成功将Pyroscope部署好了,那Pyroscope的数据哪里来的呢?除了Holmes上报,还有其他办法吗?
1.部署alloy
Alloy 为OTel、Prometheus、Pyrscope、Loki和许多其他指标、日志、跟踪和配置文件工具提供原始管道。此外,还可以使用 Alloy 管道执行不同的任务。Alloy 与 OTel Collector、Prometheus Agent 和Promtail完全兼容。也可以将其用作这些方案的替代方案,也可以将其组合成多个收集器和代理的混合系统。可以在 IT 基础架构中的任何位置部署 Alloy,Alloy 非常灵活,您可以在本地轻松配置它以满足在本地、云端或两者混合的需求。
和 Pyrscope 一样,直接使用 helm 部署。
> helm install -n test-2 alloy2 grafana/alloy
NAME: alloy2
LAST DEPLOYED: Tue Oct 8 14:49:16 2024
NAMESPACE: test-2
STATUS: deployed
REVISION: 1
TEST SUITE: None
NOTES:
Welcome to Grafana Alloy!此刻,Alloy也部署成功了!
2.配置Alloy
部署成功了,那怎么去采集数据,又如何将数据上报的热像仪中去呢?经过一系列的研究,同样使用 helm value 的模式。以这里 web_server 为例
controller:
type: deployment
alloy:
configMap:
content: |-
logging {
level = "warn"
format = "logfmt"
}
pyroscope.write "pyroscope_write" {
endpoint {
// pyroscope地址
url = "http://127.0.0.1:4040"
}
}
pyroscope.scrape "web_server" {
// 服务pprof相关指标抓取地址,通过service服务暴露到集群中,source是标签,区分holmes上报
targets = [{"__address__" = "web-monitor-service:9101", "service_name" = "web-server", "source" = "alloy"}]
forward_to = [pyroscope.write.pyroscope_write.receiver]
// 抓取时间:5分钟
scrape_interval = "300s"
// 抓取超时时间:60s
scrape_timeout = "60s"
// process_cpu 采集时间15s
delta_profiling_duration = "15s"
// 配置相关抓取指标
profiling_config {
profile.process_cpu {
enabled = true
}
profile.memory {
enabled = true
}
profile.mutex {
enabled = true
}
profile.block {
enabled = true
}
profile.goroutine {
enabled = true
}
}
}
通过helm upgrade升级配置即可。打开刷新pyrscope,web-server服务就会出现在相关的服务中了。
打开刷新 Pyrscope,网络服务器服务就会出现在相关的左上角服务中了。
四、利用PGO进行性能优化
1. PGO概念与原理
PGO首先要对程序进行剖分(Profile),收集程序实际运行的数据生成profiling文件,根据该文件来进行性能优化:通过缩小代码大小,减少错误分支预测,重新组织代码布局减少指令问题存储等方法。
PGO向编译器提供最常执行的代码区域,编译器这些区域后可以对这些区域进行已知的和具体的优化。PGO通过缩小代码大小、减少分支错误预测和重新组织代码布局来减少指令存储问题来提高应用程序性能。编译器提供有关应用程序中最常执行的区域的信息。通过了解这些领域,编译器能够在优化应用程序时使用外接程序和外部设置。
PGO由三个阶段组成。如下图:
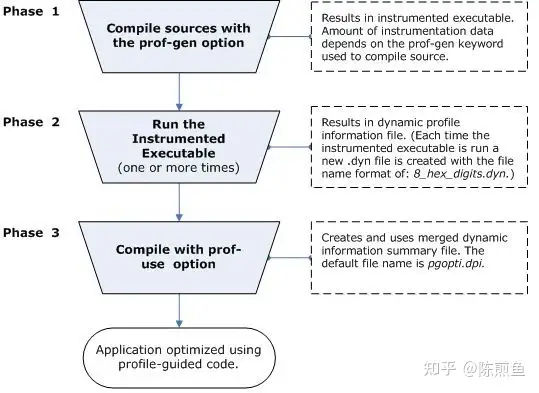
- 检测程序。从您的源代码编译器和特殊代码编译器创建并链接检测程序。
- 运行检测的执行文件。每次执行插桩代码时,插桩程序都会生成一个动态信息文件,用于最终编译。
- 最终编译。当您第二次编译时,动态信息文件将合并到一个摘要文件中。使用此文件中的概要信息摘要,编译器尝试优化程序在最密集的运行路径中执行。
2. 实施PGO优化
Pyrscope 除了提供性能监控之外还在 1.7 版本中提供了 pgo 功能,可以通过 profilecli 工具对 pgo 文件进行导出,而且经过 Pyrscope 处理后的 pgo 文件更小,更快速地导出。
在流水线中进行编译之前增加导出命令,--no-aggregate-callees而且官方默认的--aggregate-callees使用正好,这里也是一个坑,具体已经提问题了,等待对方回复。
profilecli query go-pgo --query='{service_name="web-server",source="alloy"}' --url="http://127.0.0.1" --no-aggregate-callees在压缩后使用go version -m 编译依赖信息输出,确认是否使用PGO文件编译。
go version -m bin/web-server最终会在流水线输出中相关的编译依赖,第8行就明确的表示使用了pgo编译。
[15:53:01] bin/web-server: go1.22.7
[15:53:01] path command-line-arguments
[15:53:01] dep xxxxxxx/commerce/webd-server (devel)
...............
[15:53:01] build -buildmode=exe
[15:53:01] build -compiler=gc
[15:53:01] build -ldflags="-w -s"
[15:53:01] build -pgo=/root/workspace/web-server/default.pgo
[15:53:01] build -tags=jsoniter,musl
[15:53:01] build CGO_CFLAGS=
[15:53:01] build CGO_CPPFLAGS=
[15:53:01] build CGO_CXXFLAGS=
[15:53:01] build CGO_ENABLED=1
[15:53:01] build CGO_LDFLAGS=
[15:53:01] build DefaultGODEBUG=httplaxcontentlength=1,httpmuxgo121=1,tls10server=1,tlsrsakex=1,tlsunsafeekm=1
[15:53:01] build GOAMD64=v1
[15:53:01] build GOARCH=amd64
[15:53:01] build GOOS=linux
[15:53:01] 任务返回状态码: 03. 实践案例
经过在测试环境对的web-server压测,使用PGO优化后性能提升了15%左右,符合官方给出的3%-15%的性能提升范围。上线后,该服务单核负载能力提升了16%,效果但在某些服务中提升的效果甚微,初步分析与这些服务偏I/O密集型相关。

五、迭代稳定性
1. 问题
当服务再次发布上线后,观察到cpu负载再次恢复到优化之前的负载数。
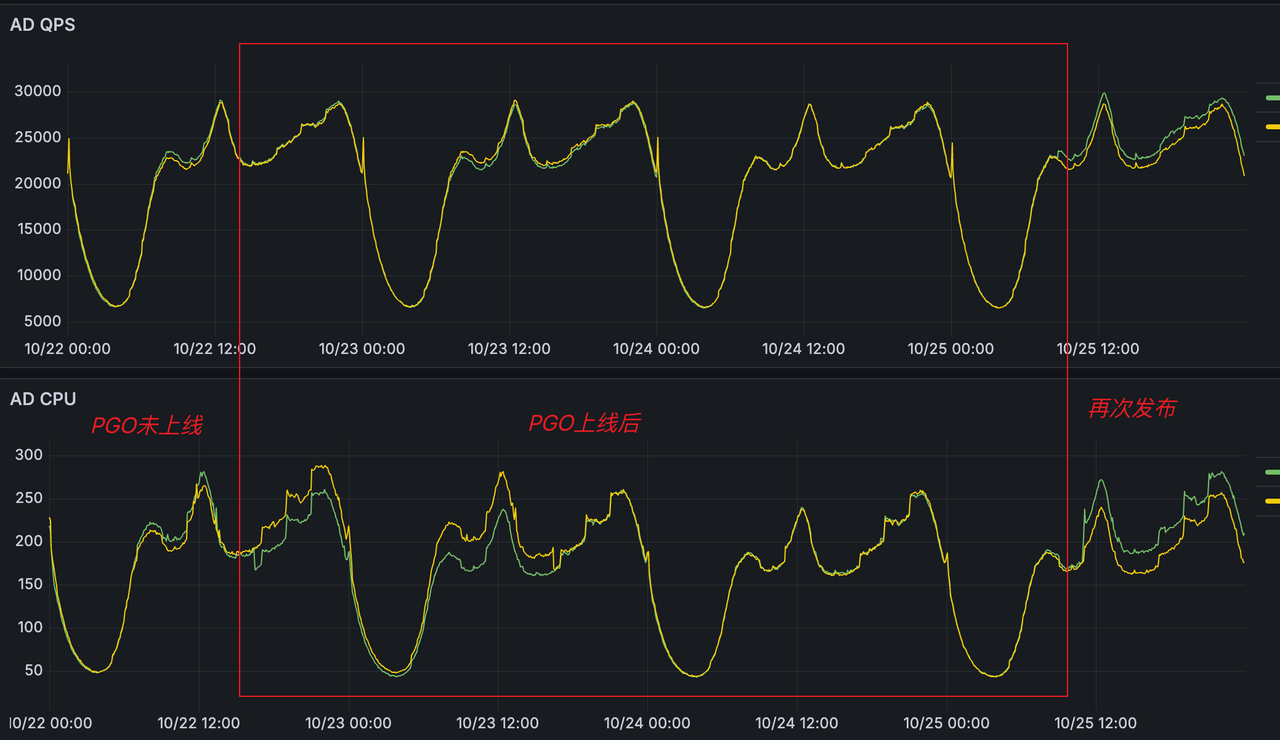
后经志新翻阅文档,注意到autofdo这段提到
We use CPU profiles to identify hot functions to target with optimizations. In theory, a hot function could be sped up so much by PGO that it no longer appears hot in the next profile and does not get optimized, making it slow again.
简单点来说,经过pgo优化热点函数后,该热点函数就大概率不会再后续的profile(pgo文件)中体现了,那么PGO再次编译时就不会再去优化热点函数,性能就会再次变慢。
2. 验证
经过后期再次迭代的上线,在没有大改动和QPS环比不变的的情况下,CPU负载再次下降18%左右,符合我们的设想。

3. 解决方案
流水线采取二阶段构建方案:先采取灰度发布(少量且无PGO)进行线上采集,使用alloy对灰度发布的pod进行收集数据,5-10分钟后再次pgo编译打包上线。
六、总结
通过 Pyroscope 与 Alloy 结合使用,我们不仅能够更加高效地识别性能问题,还能在编译阶段实现性能优化获取 PGO 文件,从而进一步提升系统的整体性能优化。PGO 作为一种重要的性能优化手段,在实际中在中应用中展现出了显著的效果。