一、TSDB是什么
TSDB(时序数据库)是 Time Series Database(时间序列数据库)的简称,TSDB是一种高性能、低成本、稳定可靠的在线时间序列数据库服务,提供高效读写、高压缩比存储、时序数据插值及聚合计算等服务,广泛应用于物联网(IoT)设备监控系统、企业能源管理系统(EMS)、生产安全监控系统和电力检测系统等行业场景,除此以外,还提供了时空场景的查询和分析的能力。
TSDB 具备秒级写入百万级时序数据的能力,提供了高压缩比、低成本存储、预降采样、插值、多维聚合计算、可视化查询结果等功能,解决由设备采集点数量巨大、数据采集频率高造成的存储成本高、写入和查询分析效率低的问题。
二、常见的TSDB有哪些
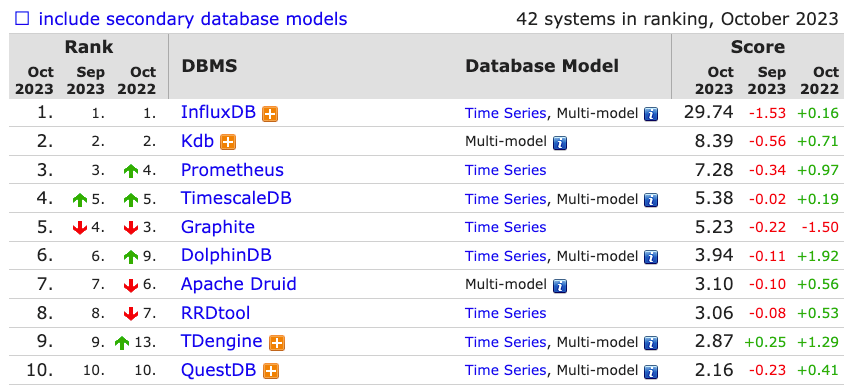
在 https://db-engines.com/en/ranking/time+series+dbms 可以看到时间序列数据库的完整排名。
下面是一些使用较多的数据库:InfluxDB 是一款用Go语言编写的开源分布式时序、事件和指标数据库,无需外部依赖。该数据库现在主要用于存储涉及大量的时间戳数据,如DevOps监控数据,APP metrics,loT传感器数据和实时分析数据。Prometheus 是一款基于时序数据库的开源监控告警系统,非常适合Kubernetes集群的监控,其内部实现的自研TSDB,也有着出色的性能表现。Kdb+ 官方称其为世界上最快的时间序列数据库,它有非常高的性能和丰富高效的时间序列函数。列式存储的特性,使得对于某个列的统计分析操作异常方便。全球顶尖的投行、高盛、摩根、国内许多证券公司和私募基金也开始使用,在延迟性上有着苛刻要求的金融领域,kdb+有着独特的优势。
三、Promethes TSDB 发展历程
V1(2012) Prometheus 1.0 版本,使用 LevelDB,这是由 Google 开源的一个KV存储引擎,依据LSM-Tree(Log Structed-Merge Tree)原理实现。
V2(2015) Prometheus 1.0 版本,基于 LevelDB,并且引入了 Facebook Gorilla 压缩算法,它可以将16个字节的数据压缩到平均1.37个字节。
V3(2017) Prometheus 2.0 版本,引入了全新的自研 TSDB,它在保持数据高压缩比的同时,有着更高的处理速度,更低的CPU使用率及硬盘I/O。每秒可采集数百万个样本,新的压缩算法可以将每个样本的大小控制在1.3 bytes 左右。
四、Promethes 数据模型
Time Series Data 由指标名称和可选的标签键值对组成唯一标识(Identifier),Samples 则是实际的数据,它包含:一个 float64 类型的值(v),以及一个int64类型的毫秒级时间戳(t)。
identifier -> (t0, v0), (t1, v1), (t2, v2), (t3, v3), ....
metric name>{<label name>=<label value>, ...}
# 实例
http_request_total{instance="10.0.0.1:80", path="/list", service="book", status="200"}
http_request_total{instance="10.0.0.2:80", path="/login", service="book", status="404"}
# 简化,将 metric name 作为一个标签
{__name__="http_request_total", instance="10.0.0.1:80", path="/list", service="book", status="200"}
{__name__="http_request_total", instance="10.0.0.2:80", path="/home", service="book", status="404"}
# Samples
[
(1698936904.911, 121)
(1698936919.911, 126)
(1698936934.911, 132)
...
]
所有的数据点都可以在下面这张二维平面上展开,水平维度代表 Time,垂直维度代表 Series。
series
^
│ . . . . . . . . . . . . . . . . . . . . . . {__name__="http_request_total", path="/list"}
│ . . . . . . . . . . . . . . . . . . . . . . {__name__="http_request_total", path="/get"}
│ . . . . . . .
│ . . . . . . . . . . . . . . . . . . . ...
│ . . . . . . . . . . . . . . . . . . . . .
│ . . . . . . . . . . . . . . . . . . . . . {__name__="rpc_request_total", method="list"}
│ . . . . . . . . . . . . . . . . . {__name__="rpc_request_total", method="get"}
│ . . . . . . . . . . . . . .
│ . . . . . . . . . . . . . . . . . . . ...
│ . . . . . . . . . . . . . . . . . . . .
v
<-------------------- time --------------------->
Promethes 会周期性的拉取每个 Time Series 的当前值,从而形成这些数据点。对每个数据源而言,这个操作都是完全独立的,这意味着会有高度并发的数据写入。
如果有许多的数据源,每个数据源中又有大量不同的 Time Series,数据量级甚至可以达到百万级别,在这种情况下,只能选择批量写入。我们知道随机写入很慢,即使用SSD作为存储,也会遇到写放大问题,顺序写入和批量写入是最好的选择,Promethes TSDB 的实现中也始终贯彻着这一理念。
海量的数据点要占用大量的存储空间,所以需要对这些数据进行压缩,考虑到 Series Data 的特性,即同一个 Series 中相邻 Samples 的(时间戳、值)数值变化很小,可以使用 Gorilla 压缩算法,这个算法由 Facebook 在2015年提出,用以解决其监控系统中存储和传输大量时间序列数据的问题。Facebook Gorilla Paper 传送门
五、Promethes TSDB V3 的设计与实现
1、Prometheus TSDB 的组成
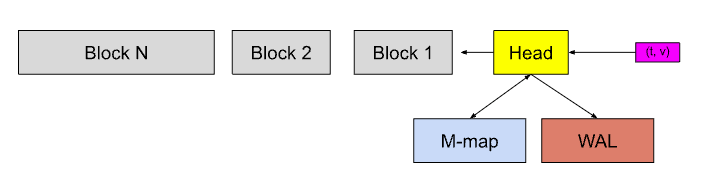
Head 中是存放于内存的最新数据。
WAL 用于数据恢复,类似于 MySQL 中的 bin log。
M-map 将硬盘中的数据映射到内存,类似于交换分区(Swap Space),可以使对硬盘数据的访问更简单高效。
Block 是持久化到硬盘上的数据,默认每2个小时的数据都会创建一个新的 Block。
2、Head
新接收到的 Samples(t,v),都会先写入 Head,同时为了避免内存中数据的丢失,会做一次预写日志(WAL),每隔一段时间会将数据刷到硬盘并通过 M-map 技术映射到内存,(默认)每隔2小时,又会用这些数据生成一个新的 Block 刷到硬盘中,硬盘中的 Block 在变旧后会被进一步合并,最终这些 Block 会在超过保留时间后被清除。
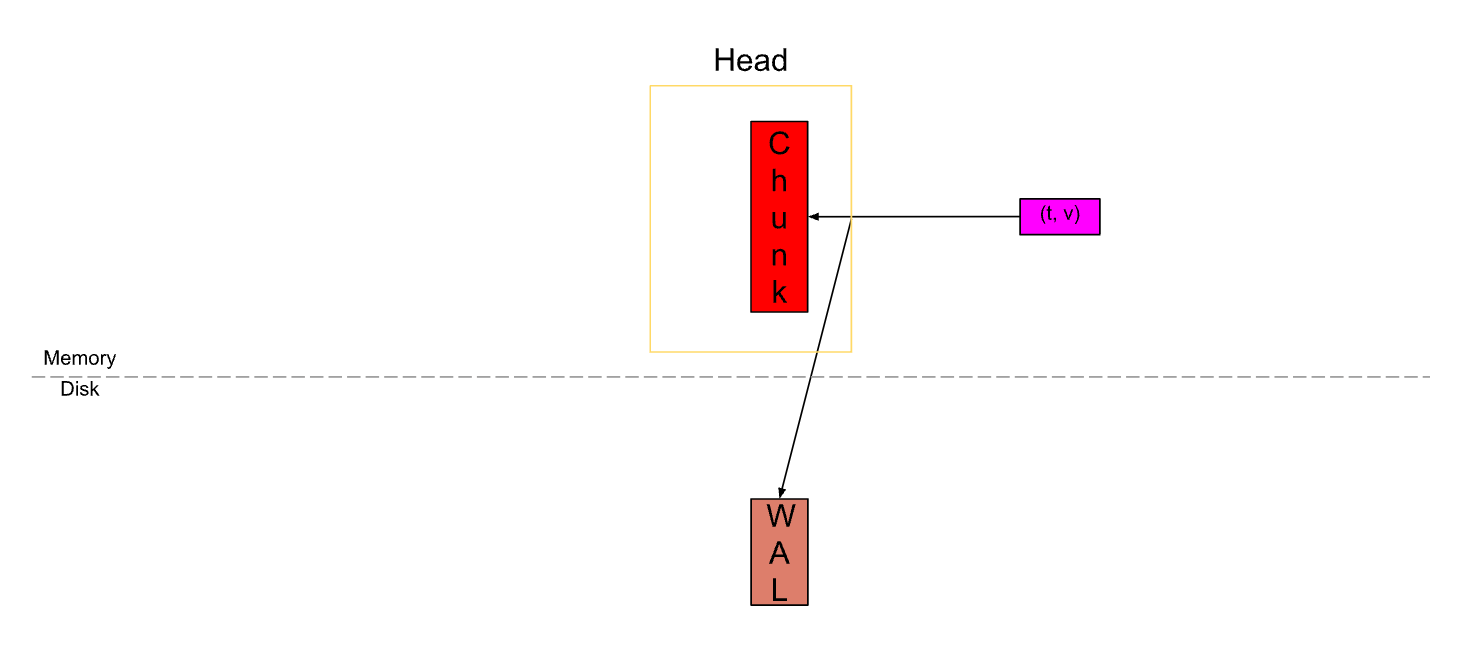
Samples 会被先放到 Chunk 中,这是我们唯一可以主动写入数据的单元。同时还会将其记录到预写日志(WAL)中,以提供可靠的持久性和恢复能力。

当 Chunk 中的样本数量达到120个(SamplesPerChunk)或者超过了2个小时(ChunkRange),就会切割出一个新的 Chunk。老的 Chunk 则视为”已满“。
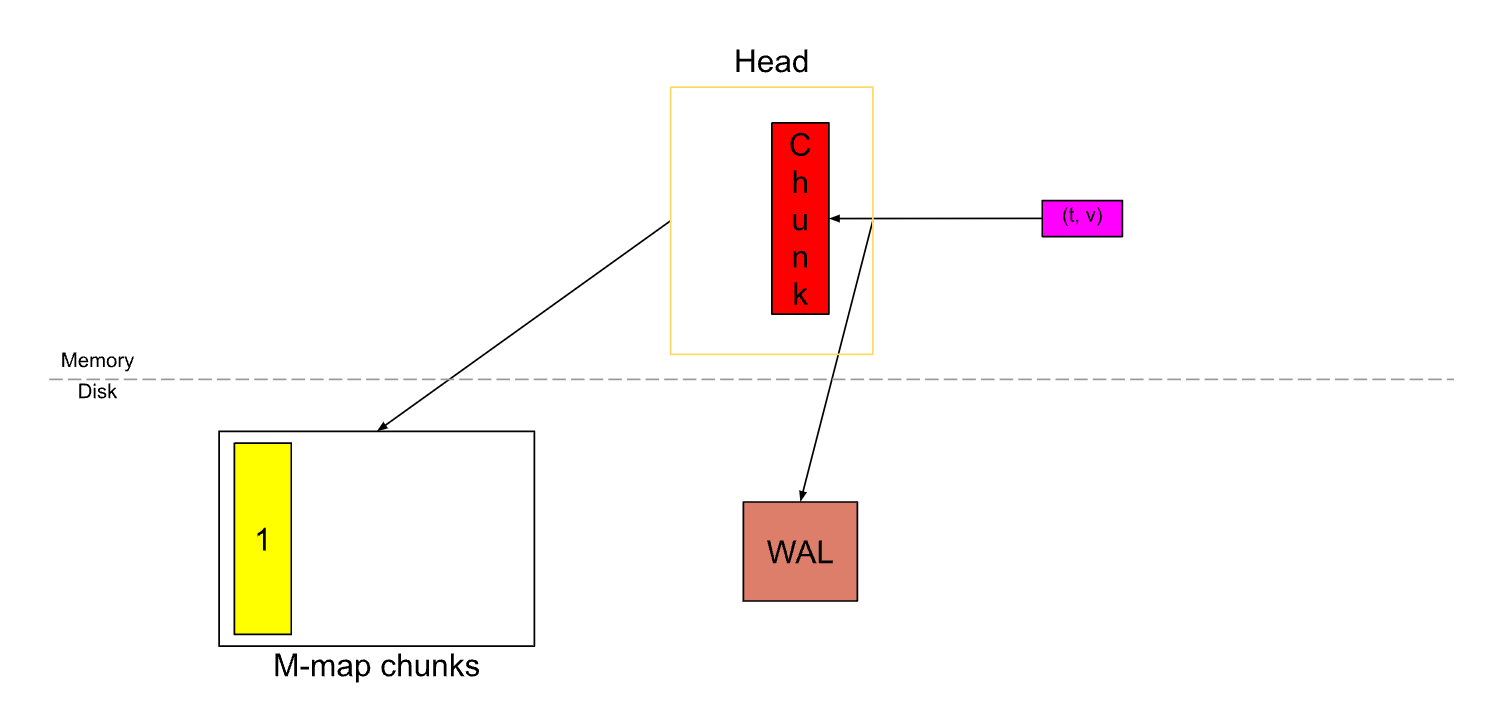
随后这个老的 Chunk 会被刷新到硬盘,并且通过 M-map 技术将硬盘中的数据映射到内存。
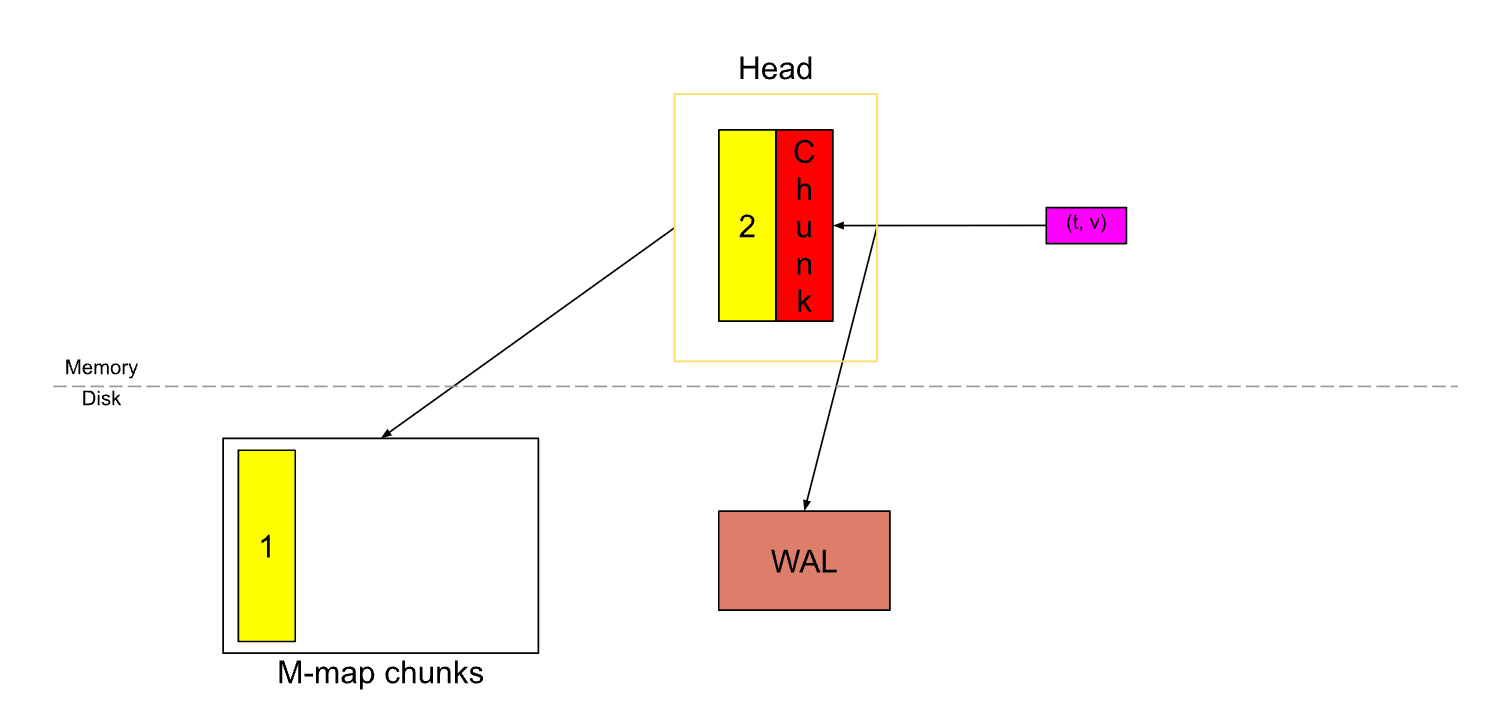

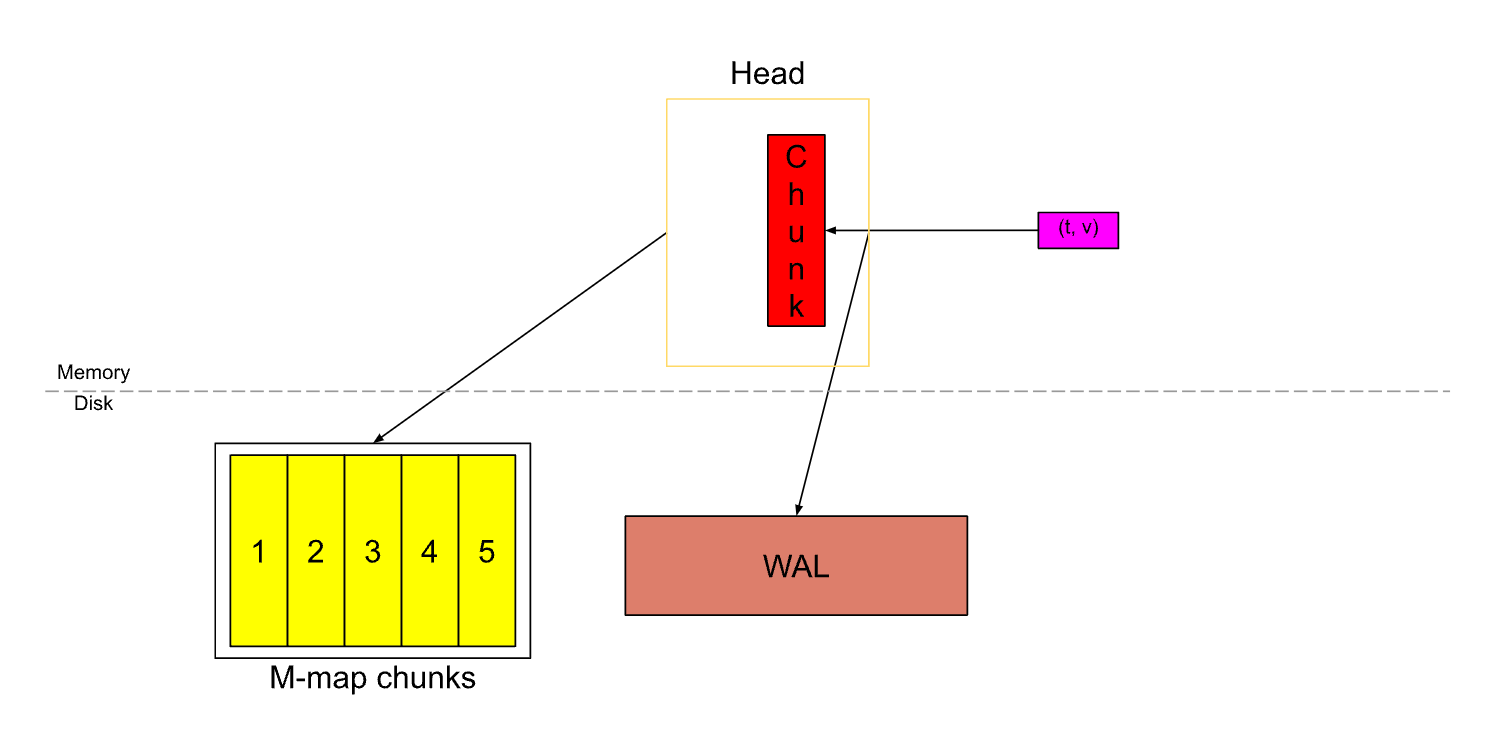
随着 Samples 的不断写入,Head 中的 Chunk 经过了多次切割,直到出现下面这种情况,Head 中的 Chunk 几乎已满,这时 Head 中已有将近3小时的数据。(计算方式:假设每15秒拉取一次数据,每个 Chunk 中最多有120个 Samples,那么每个 Chunk 就横跨了30分钟,30分钟 * 6 = 3小时)
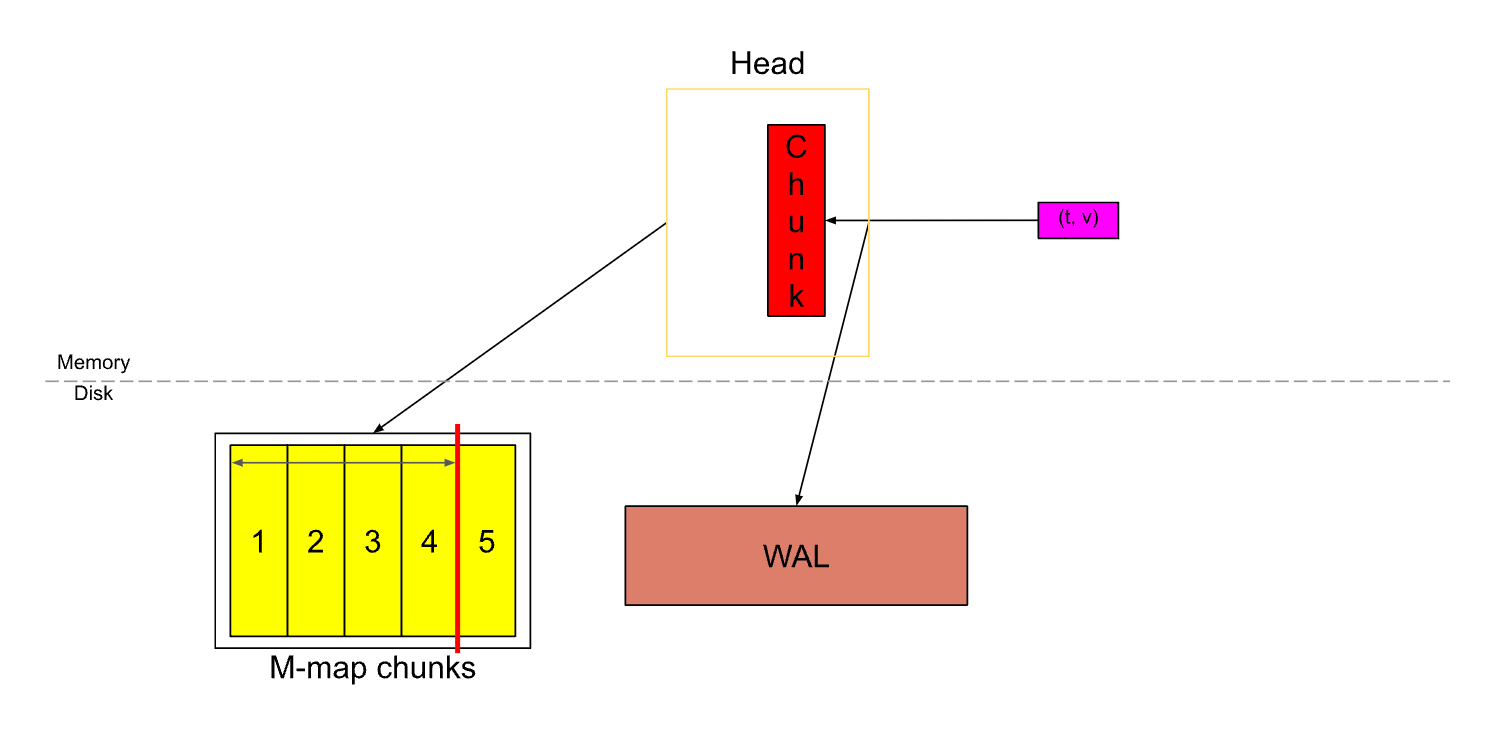
当 Head 中的数据超过了 ChunkRange * 3 / 2 时,第一个 ChunkRange 数据会被压缩成一个持久的 Block 存储在硬盘上。同时,WAL 会被截断,并创建一个 Checkpoint。
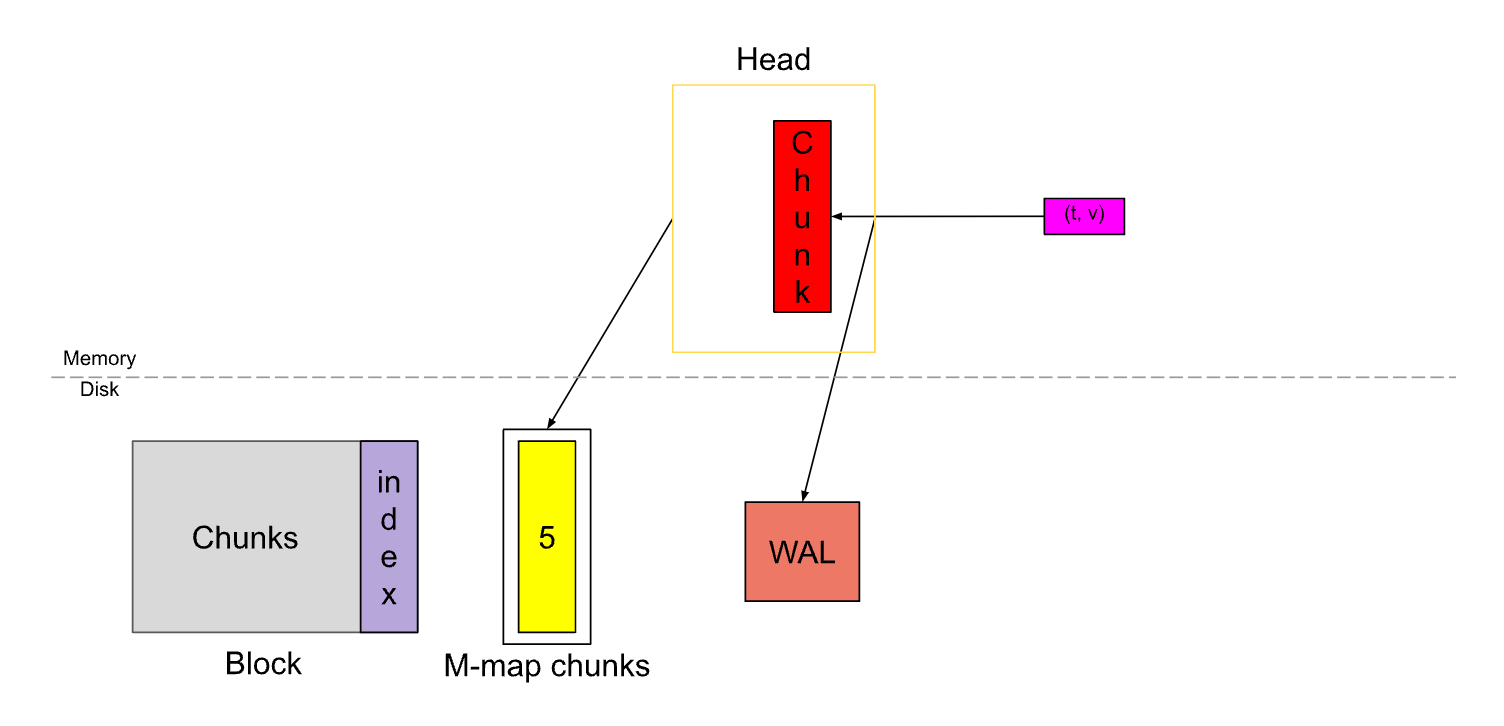
这里对 Chunk 和 Block 做下比较:
Chunk 是一个动态、可变的 Time Series Data 缓存区,Block 是一个静态、不可变的Time Series Data 存储单位。
两者的目的都是为了优化时间序列的存储和查询性能,但是 Chunk 还有一个额外的作用,即用于临时存储原始数据,并在持久化之前对其进行压缩和处理。
3、WAL & Checkpoint
WAL
预写日志(WAL)是一种常见的数据库技术,它在数据写入硬盘之前先将操作记录到一个日志文件中。WAL 的主要作用是提供可靠的持久性和恢复能力。
在 WAL 中有三种记录:
Series 记录包含写入请求中所有 Series 的标签值,创建 Series 时会生成一个唯一的引用,可以用来查找此 Series。一个 Series 只有在首次出现时才会记录一次,先写入 Head,再写 WAL。
Samples 记录中包含了对应序列的引用以及属于该 Series 的样本列表。先写 WAL,再写入 Head。
Tombstones 记录用于删除请求,当接收到一个删除请求后,实际上不会立即将其删除,而是会先将其保存到 Tombstones 中,用来标记数据的删除状态,其中包含被删除的 Series 引用以及要删除的时间范围。在这之前,会在 WAL 中写入此记录。
data
└── wal
├── 000000
├── 000001
└── 000002
前面曾提到过,在 Head 被截断时,也会同时对 WAL 做截断。WAL 的实现是一个长度固定的文件,默认为128MB。每一个文件都称为一个段(Segment)。由于写请求可以是随机的,因此在不遍历所有记录的的情况下,要确定 WAL 段中 Samples 的时间范围很难,所以这里只删除了前2/3的段。比如上例中,只会删除 000000、000001 这两个文件。
这里有一点要特别注意,因为 Series 记录只会写入一次,所以如果盲目删除 WAL 段,可能会导致这些记录的丢失,这会影响启动时的数据恢复,另外,在前2/3段中也可能会有一些 Samples 没有从 Head 中截断,因此可能会发生丢失的情况。这些问题,将通过引入 Checkpoint 来解决。
Checkpoint
假设 HEAD 截断的时间点是T,对于要保留的 Series,需要遍历所有要删除的 WAL 段文件,并做如下操作:
删除所有不在 Head 中的 Series 记录。
删除所有在时间点 T 之前的 Samples 记录。
删除所有在时间点 T 之前的 Tombstones 记录。
将剩下的记录保存到 checkpoint.X 文件,这个 X 是在其上创建检查点的最后一个续写日志段的编号。
WAL 重放
先从最后一个检查点开始,按顺序迭代记录。比如 checkpoint.X,那就从 X+1 段开始重放。
针对单条记录,会按照如下的顺序进行操作:
Series 在 HEAD 中创建对应的 Series 并包含这个引用。Prometheus 可以通过引用映射来处理同一序列的多个序列记录。
Samples 将此记录中的 Samples 添加到 Head 中,记录中的引用指示要添加到哪个 Series。如果没找到,则跳过。
Tombstones 通过使用引用来识别 Series,将这些记录存储回 Head。
读写的底层细节
有大量写入请求时,要避免硬盘的随机写入,避免写放大。写放大(Write Amplification)是指在固态存储设备(如固态硬盘)中,由于其特殊的写入机制,写入操作可能导致实际的物理写入量大于逻辑上所需的写入量。通俗讲是因为写入的单位是 Page,而擦除的单位则是 Block,而一个 Block 包含了很多个 Page,这就会导致实际的写入量要大于所需的写入量。
在读取记录时,要确保记录没有损坏,比如突然关机或硬盘故障时出现的记录损坏。
为了解决上面这两个问题,WAL 会执行以下操作:
数据一次一页地写入硬盘。一页有 32KB 长。如果记录大于 32KB,则会将其分解为更小的片段,每个片段都会接收一个 WAL 记录标头,用以标识,以了解该片段是记录的结尾、开始还是中间(一条记录会有一个 WAL 记录头,即使它刚好一页)。
将记录的校验和附加在末尾,这样在读取时可以检测是否损坏。
压缩
Promethes TSDB 中默认会对 WAL 使用 Snappy 进行压缩,这是一种快速的压缩算法,其优点在于它的处理时间更短,能够快速的处理海量数据,在大数据领域中被广泛使用。
Snappy 的设计目标是在速度和压缩比之间取得平衡,适用于需要高性能的场景。与其他一些压缩算法相比,Snappy 的压缩和解压缩速度更快,但压缩比率可能稍低。
Snappy 的工作原理是通过使用一个简单而快速的哈希函数和字典来查找重复的数据块,然后使用短的标记来代表这些重复块,从而达到压缩数据的目的。解压缩过程则是根据标记和字典重建原始数据。
Snappy 压缩算法的主要优点包括:
快速的压缩和解压缩速度:Snappy以其高速的压缩和解压缩性能而闻名,特别适用于对速度要求较高的应用程序。
低延迟:由于Snappy的高速性能,压缩和解压缩过程所需的时间非常短,从而减少了处理数据的延迟。
适用于各种数据类型:Snappy适用于各种类型的数据,包括文本、二进制数据和多媒体数据等。
无损压缩:与有损压缩算法不同,Snappy是一种无损压缩算法,可以保留原始数据的完整性。
5、MMap
再回过来看下这两张图,当一个 Chunk 被填满后,会切割一个新的 Chunk,旧的 Chunk 将不可变,并且会被刷到硬盘上,同时通过 M-map 方式映射到内存中。
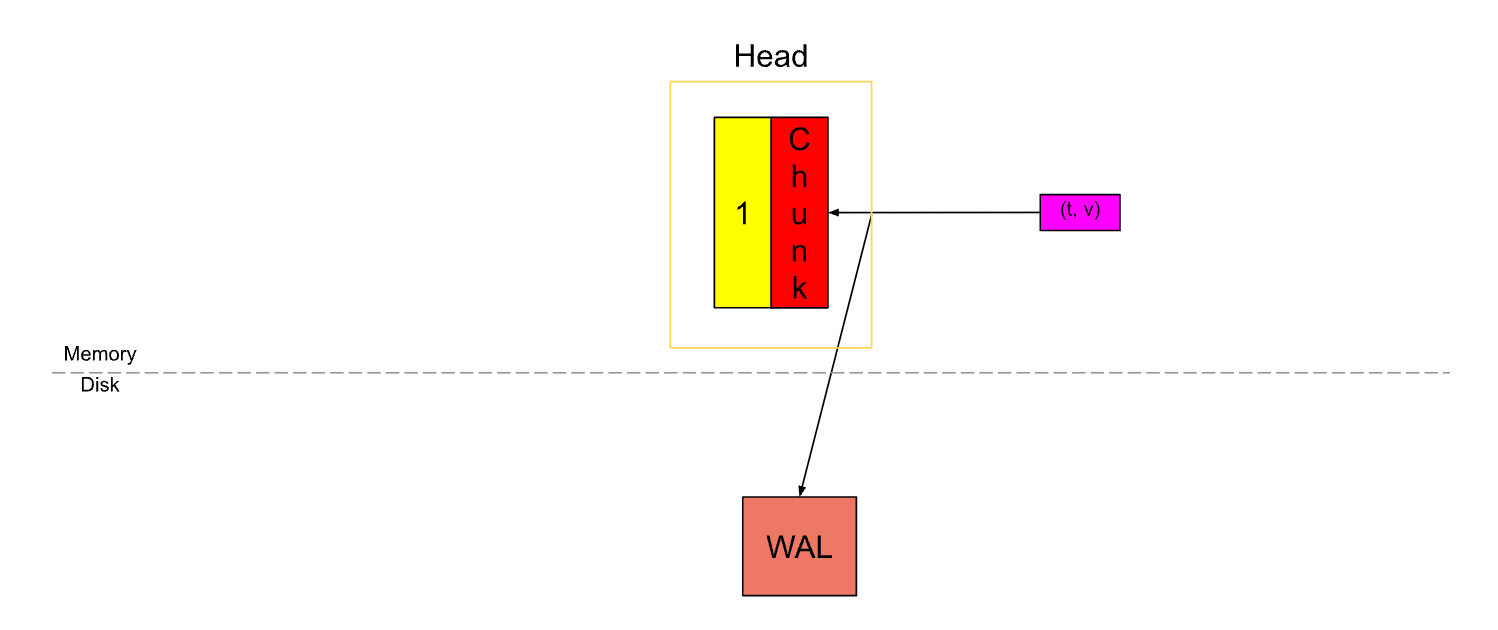
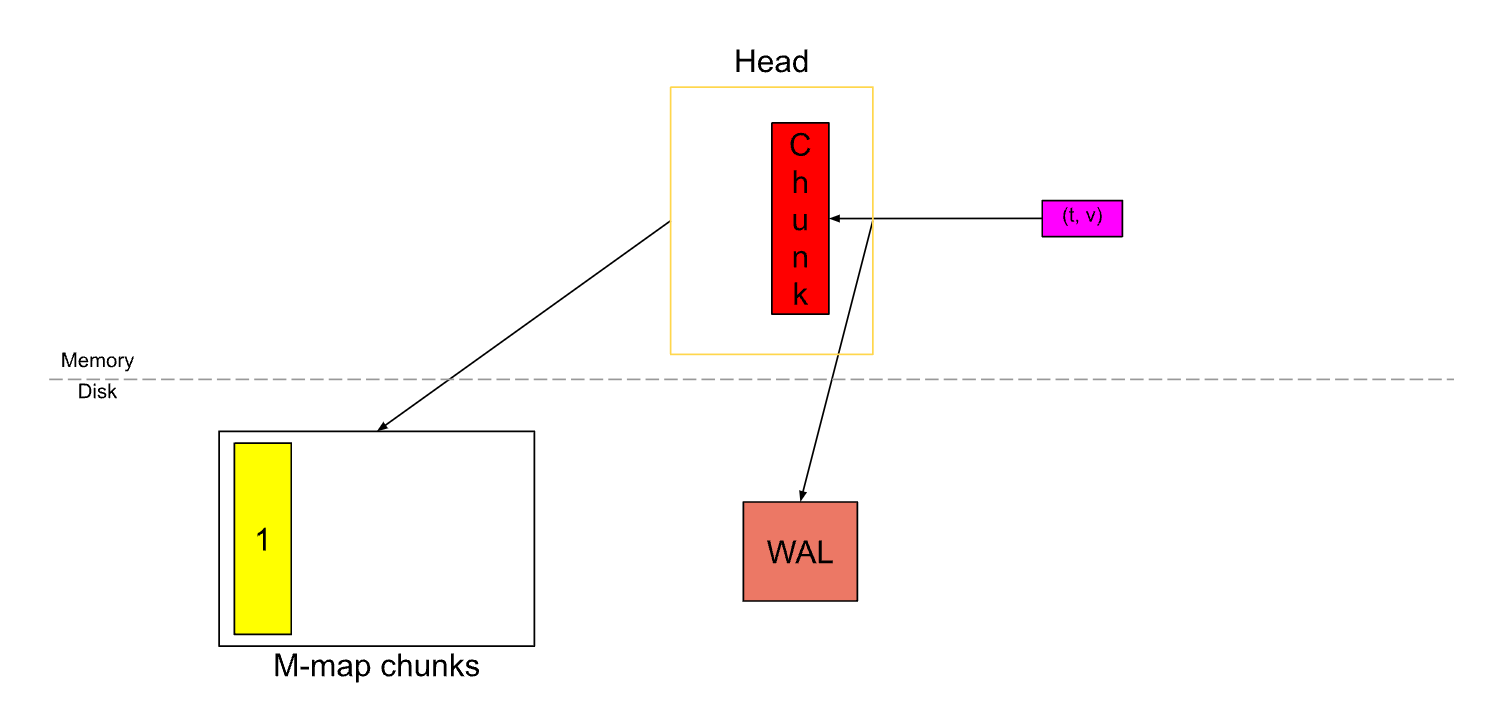
这些 Chunk 会被保存在 chunks_head 目录中。
data
├── chunks_head
| ├── 000001
| └── 000002
└── wal
├── checkpoint.000003
| ├── 000000
| └── 000001
├── 000004
└── 000005
每个文件最大为128MB。文件的标头如下:
┌──────────────────────────────┐
│ magic(0x0130BC91) <4 byte> │
├──────────────────────────────┤
│ version(1) <1 byte> │
├──────────────────────────────┤
│ padding(0) <3 byte> │
├──────────────────────────────┤
│ ┌──────────────────────────┐ │
│ │ Chunk 1 │ │
│ ├──────────────────────────┤ │
│ │ ... │ │
│ ├──────────────────────────┤ │
│ │ Chunk N │ │
│ └──────────────────────────┘ │
└──────────────────────────────┘
magic 是用来标识此类文件的任何数字。version 用来识别如何解码文件中的 Chunk。padding 则是预留的,用于以后的扩展。
再来看下 Chunk,其格式如下:
┌─────────────────────┬───────────────────────┬───────────────────────┬───────────────────┬───────────────┬──────────────┬────────────────┐
| series ref <8 byte> | mint <8 byte, uint64> | maxt <8 byte, uint64> | encoding <1 byte> | len <uvarint> | data <bytes> │ CRC32 <4 byte> │
└─────────────────────┴───────────────────────┴───────────────────────┴───────────────────┴───────────────┴──────────────┴────────────────┘
series ref 是用于访问内存中 Series 的 ID。其中前4个字节保存了该 Chunk 所在的文件号,后4个字节则记录了该 Chunk 在文件中的起始偏移量。
mint、maxt 分别是 Chunk 中 Samples 的最小及最大时间戳。
encoding 是用于压缩数据库的编码方式。
len 是从这里开始到之后的字节数,data 则是实际的 Chunk 压缩数据。
CRC32 是该 Chunk 上述内容的校验和,用来检查数据的完整性。
6、Block
硬盘上的 Block 是固定时间范围内的 Chunk 的集合,它是一个包含多个文件的目录。每个 Block 都有一个唯一的ID(ULID)。
ULID(Universally Unique Lexicographically Sortable Identifier)是一种可排序、唯一的标识符,由 Alizain Feerasta 在2016年提出,它结合了时间戳和随机数来生成一个32位的标识符,适用于分布式系统中标识数据实体和事件等场景。
data
├── 01EM6Q6A1YPX4G9TEB20J22B2R
| ├── chunks
| | ├── 000001
| | └── 000002
| ├── index
| ├── meta.json
| └── tombstones
├── chunks_head
| ├── 000001
| └── 000002
└── wal
├── checkpoint.000003
| ├── 000000
| └── 000001
├── 000004
└── 000005
meta.json
文件里存放的是 Block 的元数据。
{
"ulid": "01EM6Q6A1YPX4G9TEB20J22B2R", #
"minTime": 1602237600000,
"maxTime": 1602244800000,
"stats": {
"numSamples": 553673232,
"numSeries": 1346066,
"numChunks": 4440437
},
"compaction": {
"level": 1,
"sources": [
"01EM65SHSX4VARXBBHBF0M0FDS",
"01EM6GAJSYWSQQRDY782EA5ZPN"
]
},
"version": 1
}
chunks
所有的 chunk 都在这个目录里,每个文件最大为512MB。
┌──────────────────────────────┐
│ magic(0x85BD40DD) <4 byte> │
├──────────────────────────────┤
│ version(1) <1 byte> │
├──────────────────────────────┤
│ padding(0) <3 byte> │
├──────────────────────────────┤
│ ┌──────────────────────────┐ │
│ │ Chunk 1 │ │
│ ├──────────────────────────┤ │
│ │ ... │ │
│ ├──────────────────────────┤ │
│ │ Chunk N │ │
│ └──────────────────────────┘ │
└──────────────────────────────┘
其文件格式与 Head Chunk 文件类似,magic 是用来标识此类文件的任何数字。version 用来识别如何解码文件中的 Chunk。padding 则是预留的,用于以后的扩展。
这是单个 Chunk 的格式:
┌───────────────┬───────────────────┬──────────────┬────────────────┐
│ len <uvarint> │ encoding <1 byte> │ data <bytes> │ CRC32 <4 byte> │
└───────────────┴───────────────────┴──────────────┴────────────────┘
tombstones
用于存放 Samples 的删除标记。
这里保存的数据可以告诉我们在读取过程中要忽略哪个 Series 的什么时间范围。
┌────────────────────────────┬─────────────────────┐
│ magic(0x0130BA30) <4b> │ version(1) <1 byte> │
├────────────────────────────┴─────────────────────┤
│ ┌──────────────────────────────────────────────┐ │
│ │ Tombstone 1 │ │
│ ├──────────────────────────────────────────────┤ │
│ │ ... │ │
│ ├──────────────────────────────────────────────┤ │
│ │ Tombstone N │ │
│ ├──────────────────────────────────────────────┤ │
│ │ CRC<4b> │ │
│ └──────────────────────────────────────────────┘ │
└──────────────────────────────────────────────────┘
每个 Tombtone 看起来像这样
┌────────────────────────┬─────────────────┬─────────────────┐
│ series ref <uvarint64> │ mint <varint64> │ maxt <varint64> │
└────────────────────────┴─────────────────┴─────────────────┘
Index
Promethesu TSDB 中使用了倒排索引(Inverted Index)提供基于数据项内容子集的快速查找。这使得在查找具有如 service="home" 这种标签的 Series 时,不用遍历全部的 Series,就可以快速查找到相关 Series。
这一技术被广泛应用于搜索引擎、数据库系统和信息检索系统等领域,如:Elasticsearch 和 InfluxDB 中就有使用。
# 例
包含 path=”/index" 标签的 Series ID 为 3、5、7、9,那么标签"/index"的倒排索引就是[3,5,7,9]
包含 paht="/login" 标签的 Series ID 为 2、4、6、8,那么标签"/login"的倒排索引就是[2,4,6,8]
包含 service="home" 标签的 Series ID 为 2、5、9,那么标签"/home"的倒排索引就是[2,5,9]
如果要查找 service="home" AND path=”/index",则取 [2,5,9] 与 [3,5,7,9] 的交集,得到 [5,9]
如果要查找 path=”/index" OR path=”/login",则取 [3,5,7,9] 与 [2,4,6,8] 的并集,得到 [2,3,4,5,6,7,8,9]
7、Compaction
对于已经创建的 Block,需要定期进行维护,将多个 Block 进行合并压缩,保留较新的数据,删除较旧的数据,以节省硬盘空间并保持查询性能。
对 Block 进行合并压缩的好处如下:
前面提到过,为了提高效率,在删除数据时使用了逻辑删除,被删除的数据依然存在。当逻辑删除的数据达到一定比例时就有必要从硬盘中删除这些数据,节省硬盘空间。
如果更新频率足够低,那么其实相邻 Block 中的大部分时间数据都是相同的,因此通过合并压缩这些相邻的 Block,就可以删除大部分索引中的重复数据,节省硬盘空间。
当查询命中了多个 Block 时,就需要合并从各个 Block 中获取的结果,这种额外的开销,其实可以通过合并相邻的 Block 来尽量避免。
对于时间重叠的 Block,在查询时要对重复的数据进行删除,同样,这种额外的开销,也可以通过合并相邻的 Block 来尽量避免。
8、Retention
Prometheus TSDB 中可以通过设置保留策略来限制存储的数据量。可以通过大小和时间两个维度来进行设置。当满足任一保留策略时都会触发相关数据的删除操作。
基于时间的保留策略
指定数据最长保留时间,当一个 Block 中的数据完全超出了保留时间,它就会被删除。比如,保留期设为10天,那么当最老的 Block 的最大时间与最新的 Block 最大时间之间的间隔超过10天时,最老的 Block 将会被删除。
基于大小的保留策略
指定 TSDB 在硬盘上的最大大小。包括 WAL、Checkpoint、M-map Chunks 和 Persistent Block。当他们的总大小超过了大小保留策略设置的值,只有 Block 会被删除,其它内容都是必须的,不可以删除。
参考资料:
https://ganeshvernekar.com/blog/prometheus-tsdb-the-head-block/
https://ganeshvernekar.com/blog/prometheus-tsdb-wal-and-checkpoint/
https://ganeshvernekar.com/blog/prometheus-tsdb-mmapping-head-chunks-from-disk/
https://ganeshvernekar.com/blog/prometheus-tsdb-persistent-block-and-its-index
https://ganeshvernekar.com/blog/prometheus-tsdb-compaction-and-retention
https://github.com/prometheus/prometheus/blob/main/tsdb/docs/format/wal.md
https://github.com/prometheus/prometheus/blob/main/tsdb/docs/format/head_chunks.md