背景说明
七猫作为一家成熟的互联网公司,业务有超百万QPS的高并发。我们的产品开发逃不开的特色就是不停的升级升级再升级。随着敏捷小组的建立,发版频率也逐渐提升至每两周一次或者每周一次。然而系统升级总是会伴随着各种风险,一些系统风险比如:宕机风险,服务不可用的风险;还有一些用户体验风险:业务改动使得用户体验改变导致用户流失等风险。为了规避或者提前预知这些风险,灰度发布的概念应运而生。
灰度发布是指在黑与白之间,能够平滑过渡的一种发布方式。其主要思想就是把影响集中到一个点,然后慢慢发散到整个面,期间出现意外情况可以很快回退,整体影响可控。
我们基于 OpenResty + Lua 实现了一套简单易用的灰度发布的方案。
系统方案设计
本方案是基于 OpenResty + Lua 的方式实现。OpenResty 是一个基于 Nginx 和 Lua 的高性能 Web 平台,内部集成了大量精良的 Lua 库、第三方模块以及大多数的依赖项,可以用于方便地搭建高并发且强拓展性的动态 Web 应用、Web 服务和动态网关。
本方案主要是实现了对 HTTP 协议的灰度功能,主要基于 ngx_http_lua_module 模块实现。我们将主要通过以下三个方面来介绍:
- Nginx + Lua 实现灰度的方式和用法;
- 通过 Lua 接入 Prometheus,实现 Host 级别的 QPS,P99 延迟、状态码等详细监控;
- 针对高并发的关键性能优化;
本方案有以下优点:
- 运维成本低:几人小团队在几天时间可快速落地;
- 容易学习:Lua 脚本学习成本低,即使从未接触过,也可在短时间内迅速上手;
- 复杂度低:架构清晰,易于理解。Nginx 简单易用;
- 技术成熟: OpenResty 稳定性、性能和可靠性已经经过多年的实践和验证;
一、灰度发布的实现
先给大家上一张整体的流程图,如下:
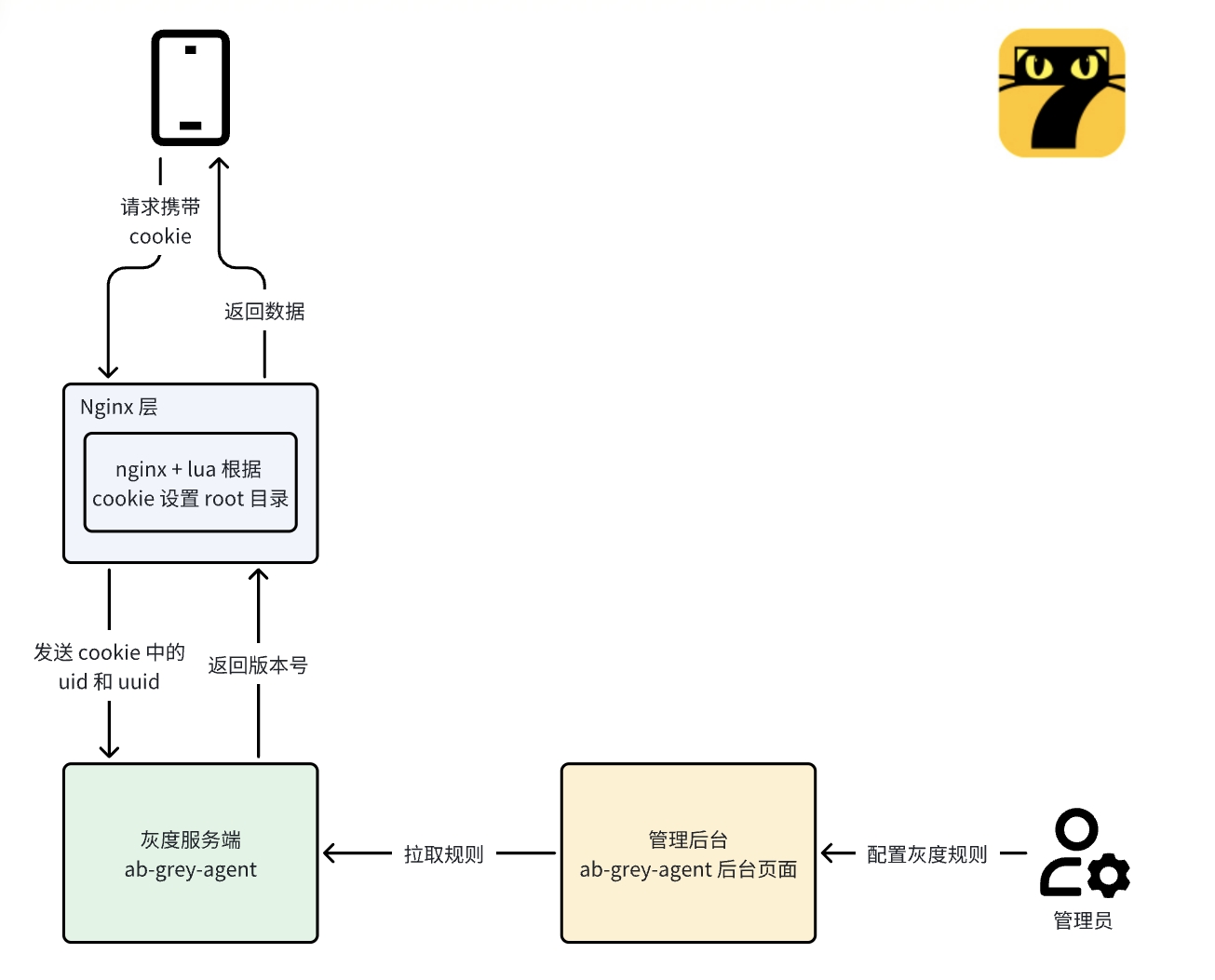
架构概览
可以看到,我们的整个流程分为 3 个部分:
- 管理后台:管理员在后台页面设置灰度用户百分比;
- 灰度服务端:定时定期拉取管理后台的灰度配置,处理请求 Cookie 中的 UID 和 UUID,返回版本号;
- Nginx 层:此处使用 Nginx + Lua 实现灰度发布的版本切换逻辑。整体流程来看,就是管理员在后台提前配置好灰度规则,灰度服务端拉取并同步该规则。同时提供接口,接收请求;
整体流程
- 用户请求服务端的时候 Cookie 中会带有 UID 和 UUID 字段;
- 使用 Lua 读取 Cookie 中 UID 和 UUID,如果没有 UUID 则生成;
- 发送 UID 和 UUID 到灰度服务端,灰度服务端根据 UUID 按预先设置好的版本比例随机(通过同步管理后台)返回版本号(如果 UID 有指定固定版本号,则优先返回固定版本);
- Lua 收到版本号后,修改目标 root 路径。(也可以修改 IP 或者端口号,以便应用到更复杂的场景);
- 返回内容和 UUID 写入用户本地 Cookie;
后台管理页
面管理后台的页面如下图,管理员通过此后台去配置用户的灰度流量比例和那些用户走灰度版本。
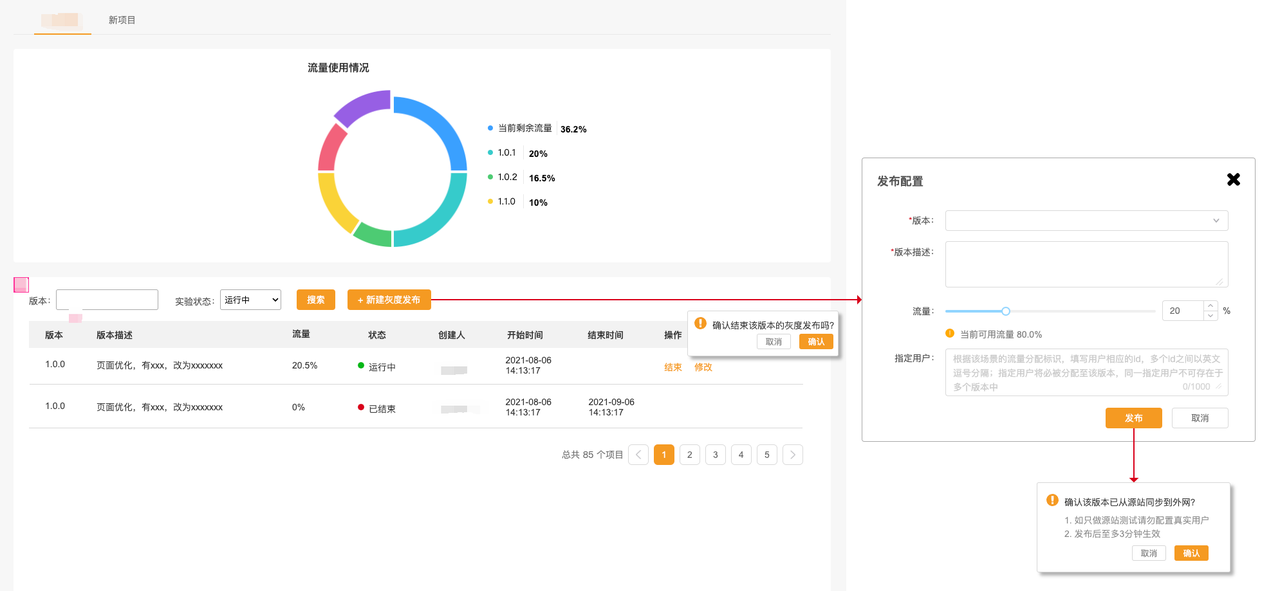
Cookie 操作说明
当浏览器收到包含 "Set-Cookie" 头部的响应时,它会解析该头部并将其中的 Cookie 信息存储在浏览器的 Cookie 存储中。这样,在之后的请求中,浏览器会自动在请求头中包含相应的 Cookie 信息,将其发送给服务器。
如何获取Cookie
获取单个cookie: ngx.var.cookie_name, 获取单个cookie,_后面的cookie的name,如果不存在则返回nil 。设置Cookie
ngx.header['Set-Cookie'] = {'a=32; path=/', 'b=4; path=/'}-- 批量设置cookie
ngx.header['Set-Cookie'] = 'a=32; path=/' -- 设置单个cookie,通过多次调用来设置多个值
ngx.header['Set-Cookie'] = 'c=5; path=/; Expires=' .. ngx.cookie_time(ngx.time() + 60 * 30) -- 设置Cookie过期时间为30分钟注:设置 Cookie 时要一定要加 Path 和 Expires(过期时间),不然无法生效,因为默认过期时间为立即。
Nginx + Lua 代码流程
起初,我们的代码流图如下图所示
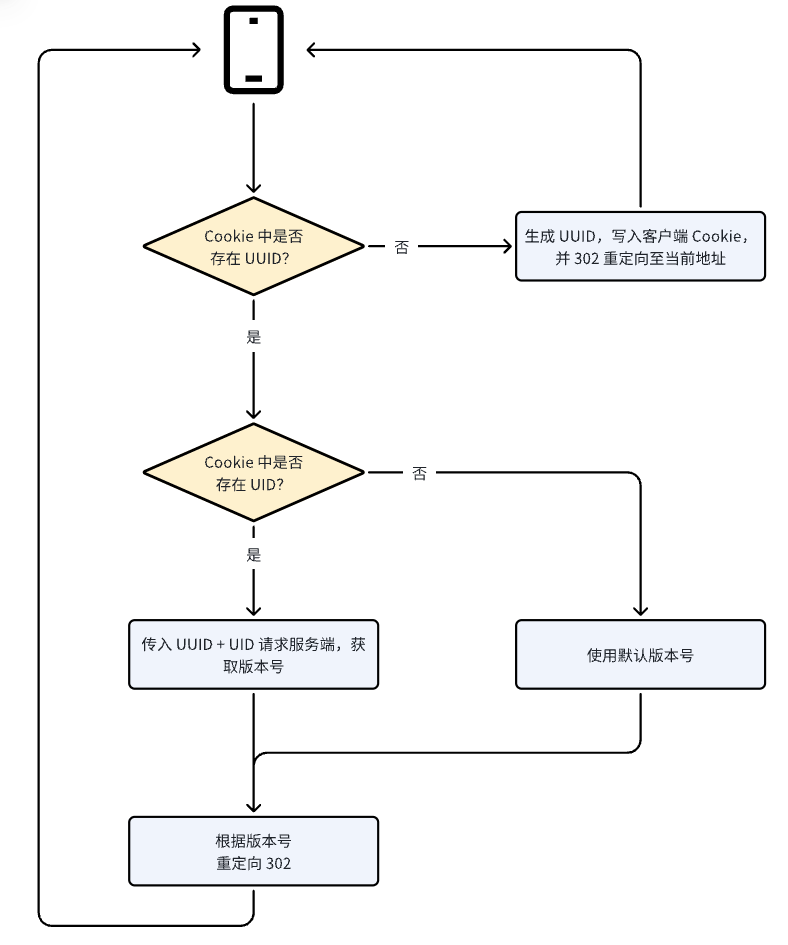
- 用户请求到 Nginx 层后,我们通过Lua 脚本判断 Cookie 中是否存在 UUID,如果不存在,则会为其生成一个,随后将新的 Cookie 写入客户端,然后返回 302 并重定向会当前 URL;
- 如果存在,则再判断 Cookie 中是否存在 UID,如果不存在,则使用默认版本号;存在则使用 UUID + UID 请求服务端接口,使用接口返回的版本号;
- 最后根据使用的版本号,返回客户端 302 并重定向。这个版本的流程其实存在一个比较明显的问题:逻辑上存在大量冗余。 用户第一次请求会客户端自动刷新一次,对用户体验有轻微影响。 为了减少冗余以及减轻对用户体验的影响,我们顺势优化了第二版的流程;
Nginx + Lua 代码流程 v2
优化后的流程图如下:
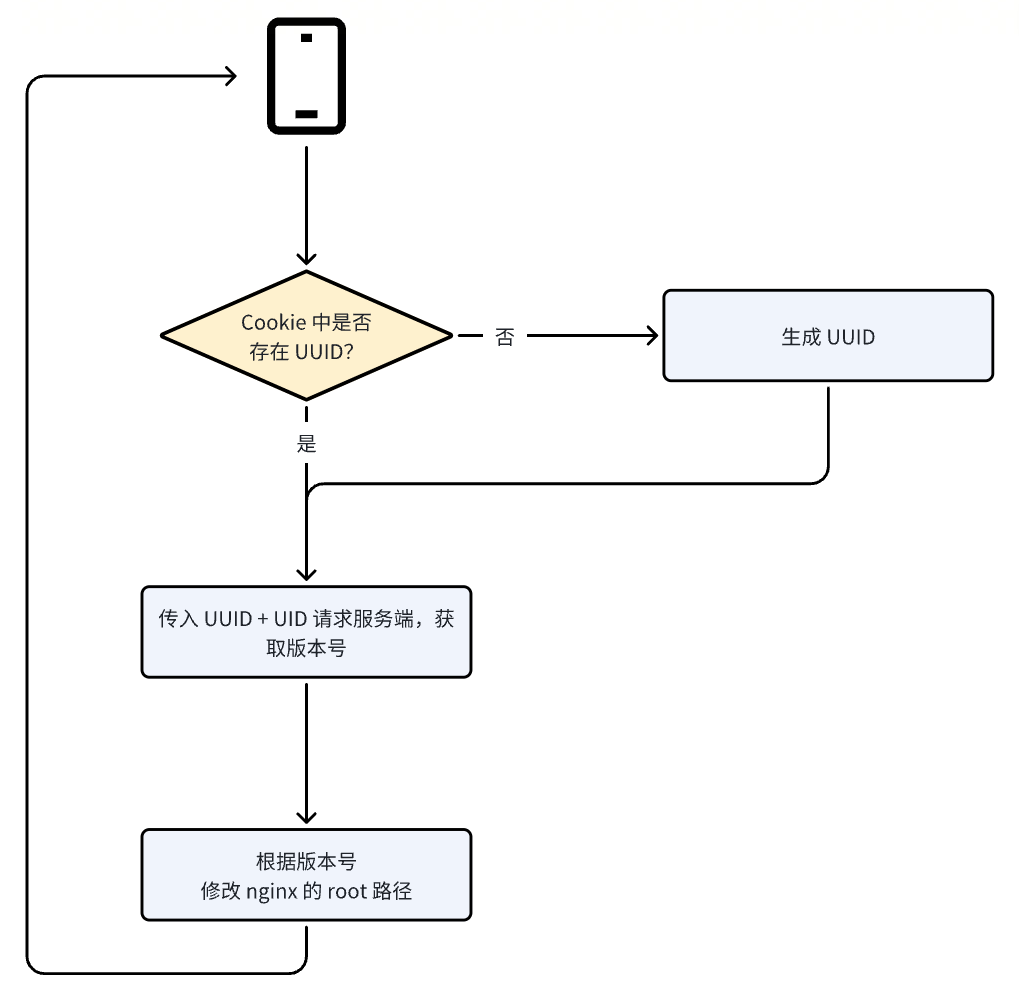
这个版本中,如果 Cookie 中的 UUID 不存在,则生成 UUID;如果存在,则直接使用 Cookie 中的 UUID ,通过 Lua 发送 Cookie 中的 UID 和 UUID 到服务端接口,获取版本号;最后根据版本号设置 nginx 的 root 目录。这一版的代码,做到了一次判断,一次请求,整体更加简洁高效。
代码部分实现示例
location / {
set $docroot ""; #设置默认root目录变量
index index.html;
rewrite_by_lua_block{
-- 请求ab-agnet程序,返回版本号,请求失败不返回
local function version(uid,my_uuid)
local res = ngx.location.capture('/api', { args = { account_id = uid , uuid = my_uuid } })
if res.body and string.match(res.body,"%d.%d.%d") then
ngx.var.docroot = string.match(res.body,"%d.%d.%d")
end
end
-- 新设备生成uuid写入cookie
local function writeUuid()
if ngx.var.cookie_uuid == nli then
local uuid = io.open("/proc/sys/kernel/random/uuid", "r"):read()
ngx.header["Set-Cookie"] = string.format("uuid=%s; Expires=%s;path=%s", uuid, ngx.cookie_time(ngx.time() + 86400 * 1000),"/")
return uuid
end
end
-- main
if ngx.var.cookie_uuid == nil then
if pcall(version,ngx.var.cookie_uid,writeUuid()) then
else
ngx.var.docroot = ""
end
else
if pcall(version,ngx.var.cookie_uid,ngx.var.cookie_uuid) then
else
ngx.var.docroot = ""
end
end
}
}注:ngx.location.capture不支持 http2.0,可以用 lua-resty-http 代替
二、监控方案
运维行业有句话:“无监控、不运维”,是的,这句话一点也不夸张,没了监控,什么基础运维,业务运维都是“瞎子”。所以说监控是运维这个职业的根本。监控系统不完善,运维人365天如何睡得踏实?所以作为一个运维工程师,重要场景的监控必不可少。
其实 Nginx 原生通过 stub_status 页面暴露了部分监控指标。Nginx Prometheus Exporter 会采集单个 Nginx 实例指标,并将其转化为 Prometheus 可用的监控数据, 最终通过 HTTP 协议暴露给 Prometheus 服务进行采集。我们可以通过 Exporter 上报重点关注的监控指标,用于异常报警和大盘展示。
但是默认 stub_status 暴露的指标可能过于通用了,不能满足我们的业务监控需要,官方提供的指标如下图:
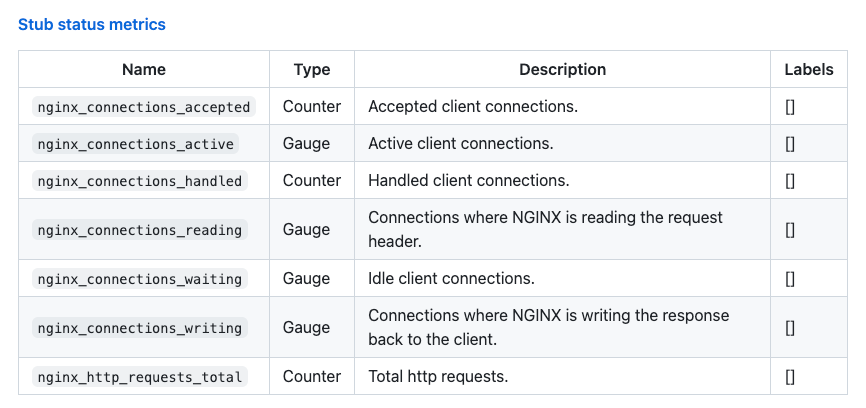
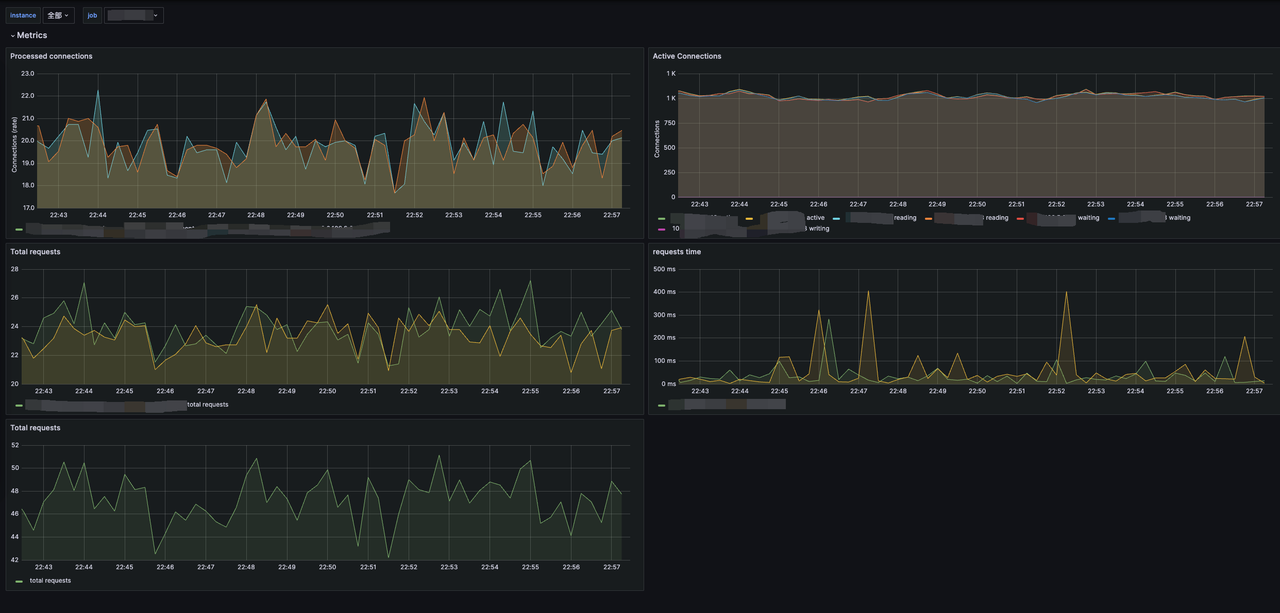
可以看到,都是一些 Nginx 连接数相关的指标,在实际的 Grafana 中看到的如下图,这些指标对我们来说并不友好,效果也只能说平平无奇。甚至可以说这样的监控几乎没有作用,我们也无法根据这个监控对业务运行情况作出判断,可以说几乎就是瞎子,这种情况下没有重要业务敢运行在上面。
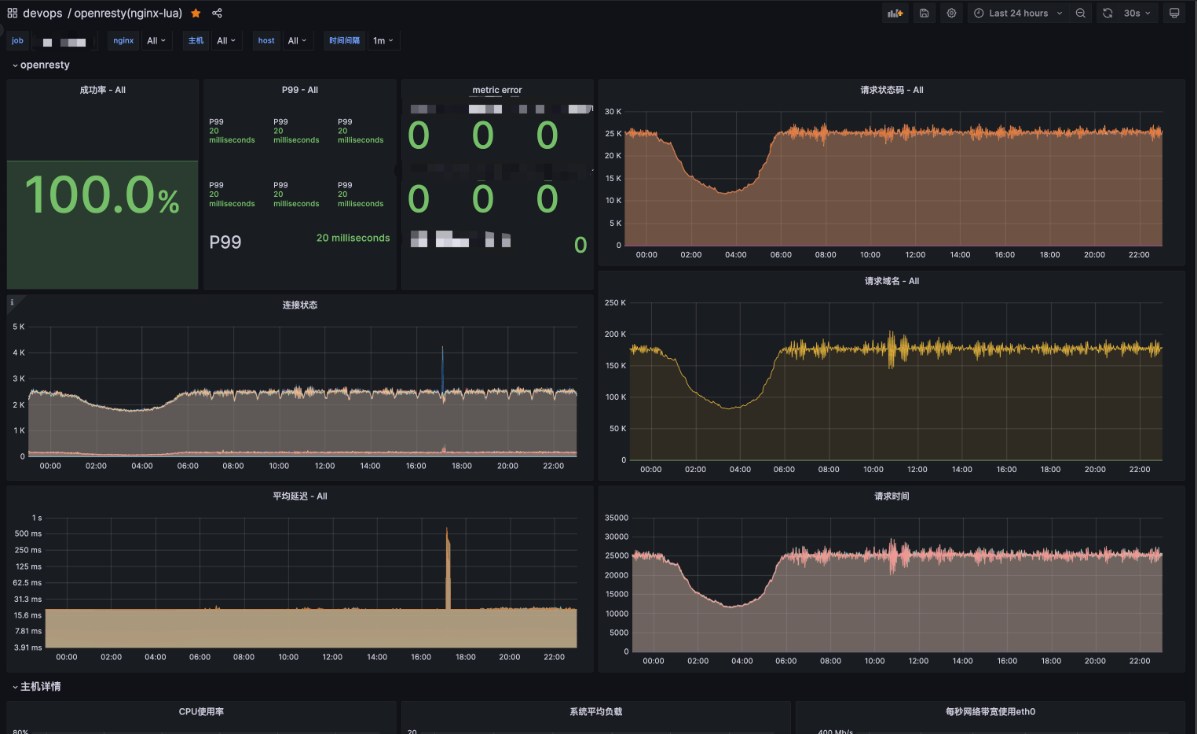
不过好在我们有 Lua ,通过 Lua 插件接入 Prometheus 监控。我们可以在 Host 级别上对 QPS,P99 延迟,请求状态码等详细情况进行监控,并在我们关心的某些指标异常时及时告警。下图为使用 Lua 插件实现的 Nginx 监控效果,可以看到指标明显变得更加丰富与直观了。
Nginx http 中代码配置
http {
........省略
lua_shared_dict prometheus_metrics 10M;
lua_package_path "/opt/app/openresty/site/lualib/?.lua;;";
init_worker_by_lua_block {
prometheus = require("prometheus").init("prometheus_metrics")
metric_requests = prometheus:counter(
"nginx_http_requests_total", "Number of HTTP requests", {"host", "status"})
metric_latency = prometheus:histogram(
"nginx_http_request_duration_seconds", "HTTP request latency", {"host"})
metric_connections = prometheus:gauge(
"nginx_http_connections", "Number of HTTP connections", {"state"})
}
log_by_lua_block {
metric_requests:inc(1, {ngx.var.server_name, ngx.var.status})
metric_latency:observe(tonumber(ngx.var.request_time), {ngx.var.server_name})
}
........省略
server {
listen 9113;
server_name 127.0.0.1;
........省略
location /metrics {
content_by_lua '
metric_connections:set(ngx.var.connections_reading, {"reading"})
metric_connections:set(ngx.var.connections_waiting, {"waiting"})
metric_connections:set(ngx.var.connections_writing, {"writing"})
prometheus:collect()
';
}
........省略
}启动后 Nginx 将会监听本地的 9113 端口, 在 Prometheus 中收集 https://host/metrics 中的监控指标,然后通过Grafana展示。
三、高并发:关键性能优化
随着业务发展,请求峰值可以达到 20 万/秒,在服务器一共 25 台的情况下,资源率使用不够均匀,偶尔有部分机器 CPU 核心跑到 100%,但是有些其他机器 CPU 核心仅 20%。因此业务整体非常不稳定,想要快速解决这个问题,只能靠扩更多的服务器获取稳定性,成本太高。
鉴于此,我们采用了如下三个方式提高我们的性能:
使用 reuseport
使用reuseport参数可以完美解决我们遇到的服务器 CPU 利用率不均匀的问题,并显著提高效率。我们先来看下 Nginx 的整体架构:
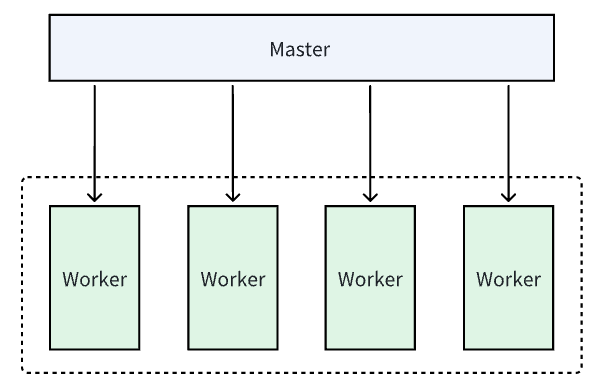
它采用了一种主从结构来处理客户端请求。这种结构包括一个主进程(Master Process)和多个工作进程(Worker Process):
主进程负责管理整个系统,它主要的职责是启动和停止工作进程,并进行配置文件的解析和加载。主进程还负责监听端口,接收客户端的请求,并根据配置文件的规则将请求分发给工作进程处理;
工作进程是实际处理客户端请求的进程,它们由主进程创建并管理。每个工作进程都是独立的,它们可以并行地处理多个请求。工作进程使用事件驱动的方式处理请求,这使得 Nginx 能够高效地处理大量并发连接;
主进程和工作进程之间通过进程间通信(IPC)进行通信。主进程可以向工作进程发送命令,如重新加载配置文件或停止工作进程。工作进程则将处理结果返回给主进程,由主进程再将结果返回给客户端;
这种主从结构使得 Nginx 能够充分利用多核处理器的能力,提供高性能和可伸缩性。主进程负责管理整个系统,工作进程负责处理实际的请求,它们之间的分工协作使得 Nginx 能够有效地处理大量的并发请求。
理解accept_mutex参数:
- 开启
accept_mutex:只有一个 worker 进程能够处理新连接,其他 worker 进程在互斥锁上等待,避免了竞争问题,但可能导致性能下降。 - 关闭
accept_mutex:所有 worker 进程都可以并发地处理新连接,避免了互斥锁的开销,可能获得更好的性能,但可能引发竞争问题。
理解 reuseport 参数
开启 reuseport 参数可以提高并发性能、分散连接负载、提高可用性,并减少连接竞争,特别适用于高并发场景下的网络应用。
由下图是开启前和开启后的流程对比:
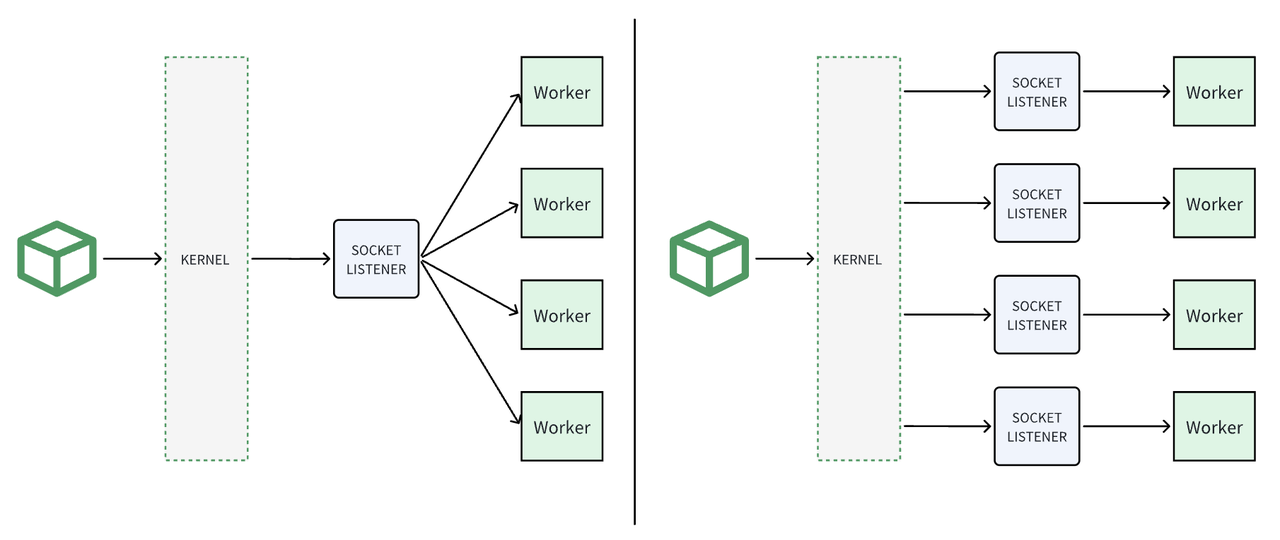
可以看到左边是未开启,系统只监听一个 Socket,然后把请求分给所有 worker 进程,免不了有大量大竞争,等待,cpu 上下文切换,负载不均衡等问题。右边是开启后,多个 Worker 进程都监听同一个端口,内核会将连接分发给各个进程或线程,从而实现连接负载的均衡。这有助于避免单个进程或线程成为瓶颈,提高系统的整体承载能力。总结一下开启reuseport 后有以下优点:
- 改善并发性能:
reuseport允许多个进程或线程同时监听同一个端口,每个进程或线程都能够独立地处理连接。这样可以提高并发性能,充分利用多核系统的处理能力; - 分散连接负载:当多个进程或线程监听同一个端口时,内核会将连接分发给各个进程或线程,从而实现连接负载的均衡。这有助于避免单个进程或线程成为瓶颈,提高系统的整体承载能力;
- 提高可用性:在使用
reuseport时,如果一个进程或线程崩溃或出现问题,其他进程或线程可以继续处理连接,从而提高系统的可用性和容错性; - 减少连接竞争:启用
reuseport后,每个进程或线程都拥有独立的套接字,避免了连接竞争问题。这可以减少锁竞争,降低延迟,并提高系统的整体性能;
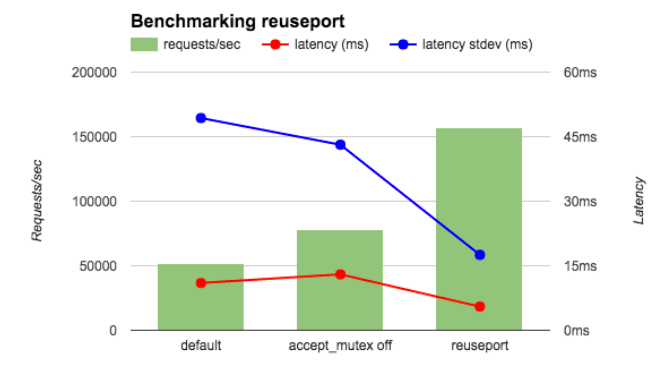
下面是三种情况的对比:
- Default:Accept_mutex on 的情况下性能最差;
- Accept_mutex off 的情况性能有少许提升;
- Reuseport 的情况下性能最好;
| Latency (ms) | Latency stdev (ms) | CPU Load | |
| accept_mutex on | 15.65 | 26.59 | 0.3 |
| accept_mutex off | 15.59 | 26.48 | 10 |
| reuseport | 12.35 | 3.15 | 0.3 |
反向代理使用 tcp 长链接
默认 proxy_http_version 版本为 1.0, Connection 默认为 close。 也就是 Nginx 每次转发流量到下游都使用会经过 TCP 的 3 次握手 4 次挥手的高开销动作,性能较差。
通过以下参数配置到 location 中,使用长链接,一次建立tcp通道,多次通讯,性能可以得到显著提升。
proxy_http_version 1.1;
proxy_set_header Connection ""; 开启HTTP 2.0
listen 443 ssl http2;
HTTP/2 相比 HTTP/1 大大提高了传输效率、吞吐能力。
- 通过静态表和 Huffman 编码的方式,将体积压缩了近一半,而且针对后续的请求头部,还可以建立动态表,将体积压缩近 90%,大大提高了编码效率,同时节约了带宽资源;
- 多个 Stream 只需复用 1 个 TCP 连接,节约了 TCP 和 TLS 握手时间,以及减少了 TCP 慢启动阶段对流量的影响;
- 二进制格式传输数据,极大提高了 HTTP 传输效率,而且二进制数据使用位运算能高效解析;
OpenResty+Lua 的功能扩展:
我们还用 OpenResty + Lua 的形式实现过如下功能,希望可以给你带来启发。
- 根据 Header 是否存在转发流量到对应 Location
- 根据 Header 是否存在转发流量到对应端口
- Redis读写,根据 Redis 读写结果实现功能,使用连接池提高性能。
- Nginx 的 mirror 模块复制流量转发到其他
- 使用 Lua 根据安卓版本决定如何灰度
- 根据来源 IP 使用生成固定的 UUID
不足与展望:
- lua脚本可维护性差,功能不易太过复杂,要控制代码量。上线后尽量不要在原来逻辑上做大幅修改;
- 容器场景下: 功能和灵活性不如服务网格和其他Ingress-Controller;
- 我们一直在探索使用功能更强大易用的网关: Kong、Envoy、ALB、Ingress-Nginx、Istio服务网格, 都各有所长;
- 目前Envoy作为我们主要使用的网关,主要应用在南北向流程场景中。 性能,可观测性,稳定性都有不错的表现;
- Ingress-Nginx用在对性能要求不高的场景中,将来会在Envoy之间二选一,统一架构;
- 服务网格正在探索中,以支撑越来越复杂的业务场景;
- OpenResty 应用在所有的非容器场景和百万QPS并发场景;