文章导读:在互联网APP项目推广中,媒体在线推广是市场推广中重要的推广手段之一,通常在运营中称之为买量或者付费推广,其主要形式为通过在媒体广告平台比如磁力引擎(快手)、巨量引擎(头条)、腾讯广告(广点通)等投放广告素材,在第三方APP中播放或展示广告素材,用户在使用第三方APP时点击广告,然后引导用户完成APP下载。在推广的过程中,广告主需要与媒体进行对接,广告主需要对媒体侧下发的点击信息进行接收,用户下载完成激活后,还需要通过媒体下发的点击信息对新增或者沉默后又活跃的用户进行识别,主要识别来源于哪个平台及具体的广告效果,最后还需要回传通知广告平台激活用户设备相关的信息,从而实现广告平台与广告主之间推广及效果追踪溯源的链路闭环。七猫的媒体推广业务架构也随着业务的发展进行了一系列的演进,本文整理了整个过程中重要的调整节点,介绍整个架构的演进过程
媒体推广业务介绍
以下是媒体推广的业务模型
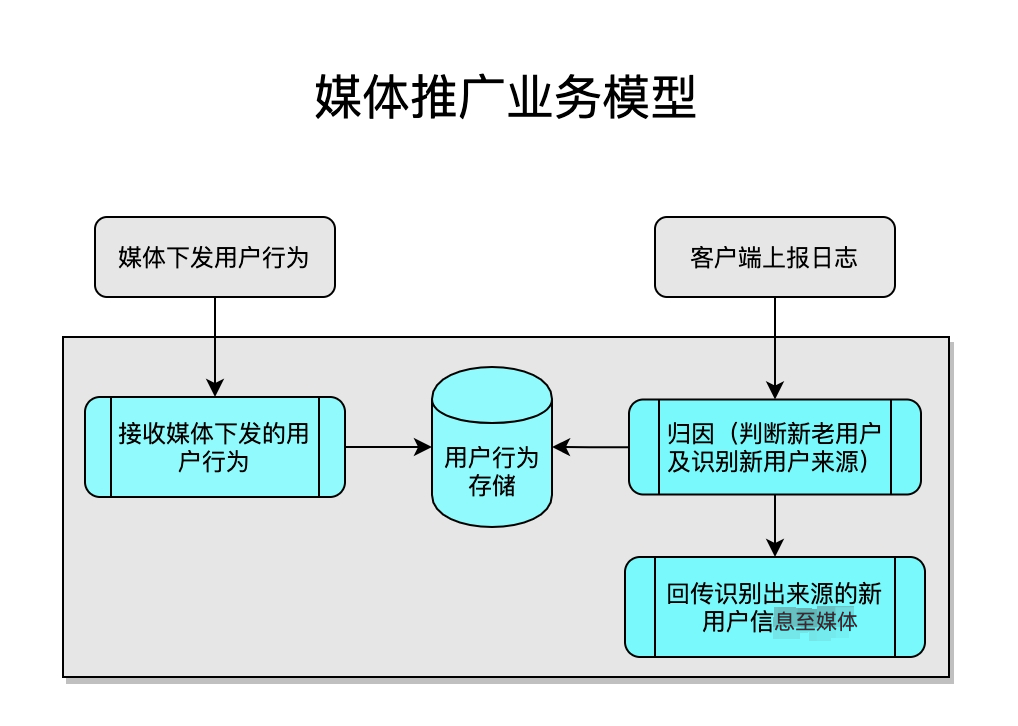
从上图可以看出,媒体推广业务主要包含三部分业务逻辑
一 接收及存储媒体侧下发的点击信息,以下简称为点击接收
二 通过客户端上报的日志识别新用户来源,以下简称为日志归因
三 回传媒体被识别为推广用户的信息,以下简称为媒体回传
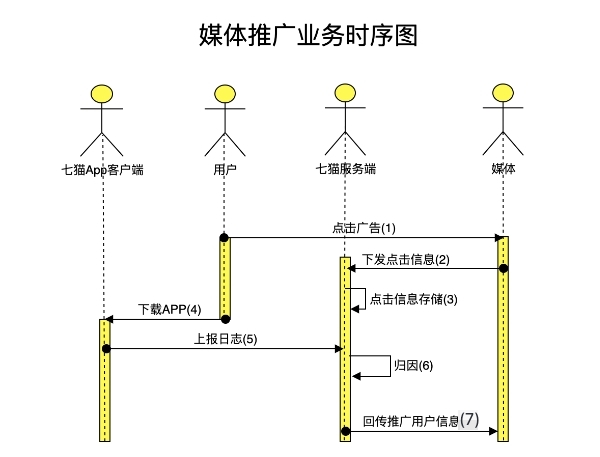
下图为媒体推广业务时序图,描述了各个系统间的主要交互
媒体推广业务架构演进
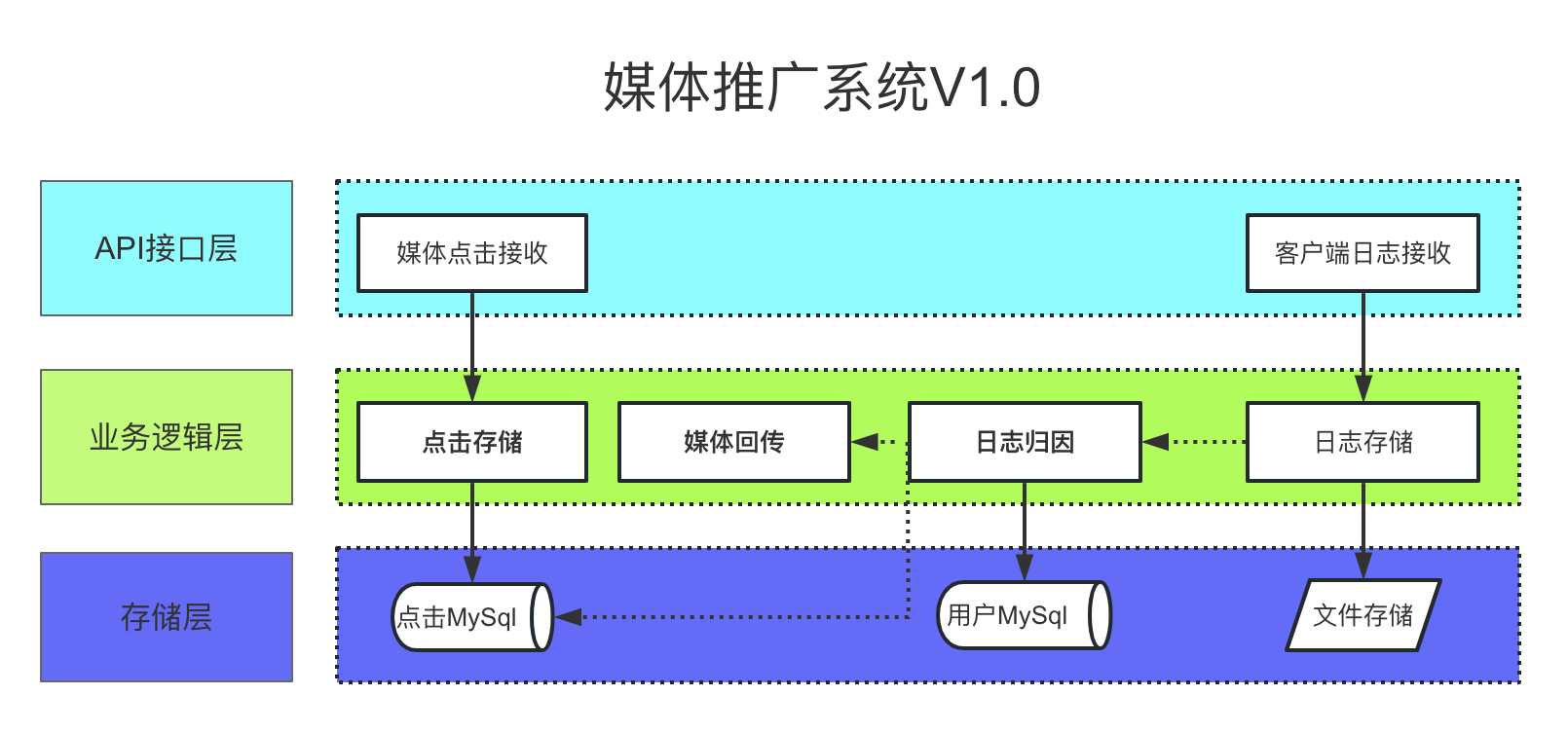
上图为最初的业务架构,由于媒体推广业务的重要逻辑部分与日志处理相关联,项目初期架构是在日志接收系统(PHP语言开发)的基础上添加模块快速实现
架构演进一:根据业务拆分系统
随着媒体推广业务量的快速增长以及APP用户量的相应增长,原架构出现了以下问题
- 媒体点击接收流量不稳定,流量的波动由媒体广告平台控制,在客户端日志接收的高峰时段(晚上8点半到11点),媒体点击接收的激增流量会导致系统的php-fpm的数量迅速飙升,同时由于点击存储会实时将数据写入MySql,一旦MySql的写入有异常,会话连接不能及时释放,就会导致php-fpm的连接不能释放,进而导致点击接收以及日志接收的请求失败,整个系统API层服务不可用
- 随着推广业务量的增加,日志接收处理逻辑中归因处理会导致日志请求返回时间的延长甚至导致超时,拖慢客户端的响应及后续业务逻辑
因此架构的第一次演进主要进行业务的拆分,以及归因的异步处理,演进后的架构如下图所示
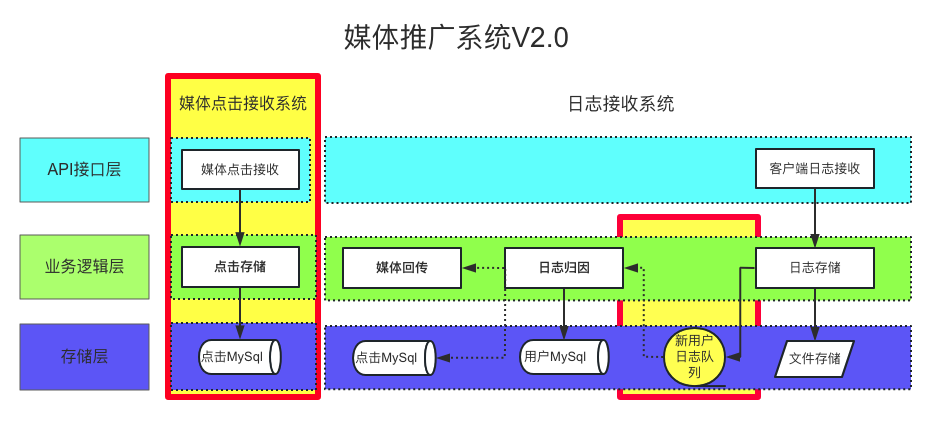
拆分后的两个系统进行独立部署,在高峰时段不会互相影响,引入RabbitMq队列,既解耦了日志接收与归因的业务逻辑,也保证了日志接收接口的稳定性
架构演进二 :语言的转换从PHP到Golang
随着媒体在线推广量的增加,媒体点击的流量也进一步增加,系统服务器数量也伴随着业务量的增加而增加,下图为当时媒体点击接收系统的拓扑图
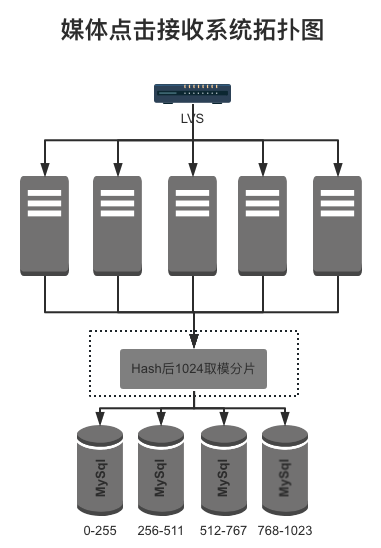
如上图所示,点击接收后端服务器数量已增加至5台,数据库存储已水平拆分至4个库中,但受限于PHP本身的网络模型,加上实时MySql存储的业务需求,在高峰时段频繁出现php-fpm的数量超过系统限制,导致下发点击请求失败而丢失点击数据;其次,由于归因业务逻辑的调整,归因查询点击数据的sql效率下降,影响请求在存储层的响应时间,触发MySql连接数超限,接口服务异常
在此背景下,公司技术部其他业务部门在应用Golang处理高并发,大流量的场景时反馈效果明显,我们也针对点击接收系统进行了Golang的重构开发,重构后的系统对比PHP版本,在高峰时段系统更加稳定,这里对比一下PHP版本与Golang版本的特点
| 媒体点击接收系统PHP版本 | 媒体点击接收系统Golang版本 | |
| 开发迭代速度 | 快速 | 前期慢,后期迭代维护快速 |
| 维护成本 | 高(开发太灵活,多人协作时易混乱;单元测试维护及规范难统一) | 低(规范结构相对统一,单元测试,集成测试维护方便) |
| MySql连接 | 高并发,流量大时容易连接过多,集成连接池复杂 | 集成连接池简单方便,只需重点关注连接参数的配置 |
| 部署 | 直接文件部署,方便,简单 | 编译后部署,需要简单的DevOps支持 |
架构演进三:RabbitMq切换Kafka,业务系统进一步优化拆分
随着推广流量的不断增加,RabbitMq新用户日志队列的流量也进一步增加,RabbitMq也从单机版部署升级成三台的集群模式,但在调整的过程中遇到了RabbitMq的弊端
- 消息的重复消费,在后端归因业务迭代上线异常后,不能回滚至上线节点重新消费日志数据,恢复业务数据
- 消息大量堆积时,会影响消费者状态,造成前后业务都受影响,例如:APP用户活跃高峰时段,日志上报量增加,导致队列数据迅速增加,消费速度一定的情况下,队列数据开始堆积,生产者抢占了mq服务内部大量的CPU资源,导致mq服务无法维护正常消费者的channel,消费者请求又在不断请求创建新的连接获取channel,最终导致生产者不能写入消息,消费者获取不到消费数据
- 在RabbitMq集群OOM等异常崩溃后,如果想要数据恢复,通常做法是新搭建集群恢复服务,同时从崩溃的集群中同步异常时的历史数据,恢复难度大,成本高
- RabbitMq集群的吞吐量,在实际压测后,3台高配(64核 32G内存)云主机搭建的RabbitMq集群的峰值在约5万QPS(压测数据来源于2018年),不能满足业务需要
鉴于上述弊端,在日志接收系统调整的时候,队列中间件由RabbitMq替换成了Kafka,除此之外,归因业务以及媒体回传业务都从日志接收系统拆分成独立的系统当中,通过消息中间件Kafka来连接,新系统全部应用Golang语言开发,新的系统架构如下图所示
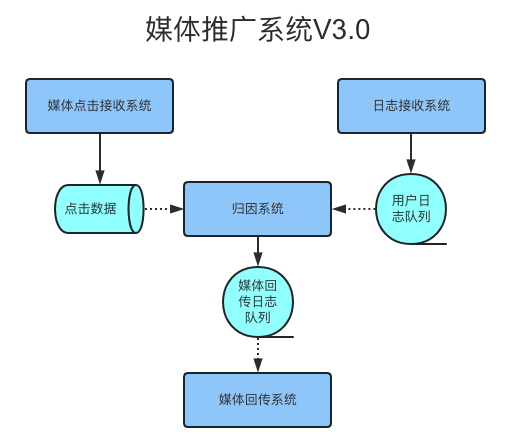
利用kafka消息中间件解耦拆分成各个子系统后,业务之间松耦合,方便各个业务模块快速迭代调整上线,保障了整体业务的稳定。
架构演进四:媒体点击系统点击数据库的双主库架构
从推广系统的业务模型图中可以看出,用户行为的存储是核心模块,在随着业务流量不断增加的过程中,我们通过Mysql云存储实例的不断升配来解决流量升高带来的存储压力,但随着基础数据量越来越大,这种解决方式常会出现以下问题
- 存储实例规格越来越大,成本不断升高
- 主从同步延迟较高,延迟数据量不断增加,主库一旦异常,主备不能正常切换对业务造成影响
- 升级耗时越来越长,超过业务低峰时间段,对部分业务造成一定的影响
- 流量激增时业务大量的插入以及过期数据的删除,导致升级配置的过程可能出现失败
结合业务特点,我们分析出问题产生的主要原因是,在升级过程中,有大量的业务写入,因此我们对用户媒体点击数据存储架构进行了优化,设计实现了双主库的架构,复制一套完全一致的存储实例,实际数据只存储在某一个实例上。同时对归因系统进行调整,将两套存储的查询结果进行聚合后返回业务使用,保障对业务没有影响。点击接收系统通过配置来快速有效控制实际数据存储的实例,从而控制待升级实例在升级的过程中没有任何数据的写入,保障实例快速升级且完成主从数据同步。如果某个实例出现不可用的情况,通过快速修改配置下线问题实例,保障业务快速恢复。
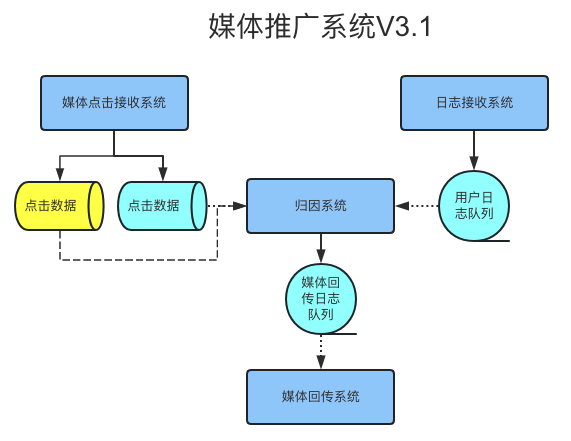
架构演进五:归因系统kafka消费者服务拆分
下图是归因系统v1.0架构
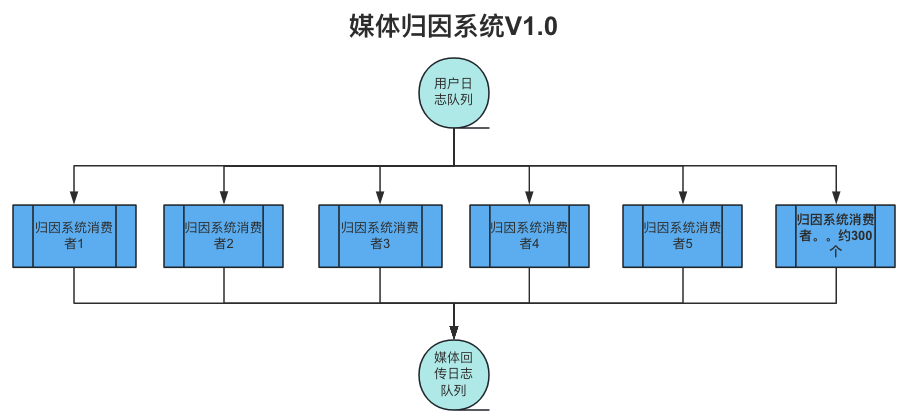
随着用户量的增加,归因系统的上游用户日志队列的数据量不断增加,我们通过扩展kafka的topic分区数量以及增加消费者的个数来保障归因业务的实时性,但这种扩展方式也存在以下问题
- 归因队列消费者个数与topic分区数量成正比倍数,例如8个分区,通常配置2个或者4个消费Pod,但最多8个消费Pod,如果消费堆积,就需要日志接收系统扩展分区,再对应增加归因系统消费者Pod数量,明显不够自动及灵活
- 业务更新发布,大量kafka消费者(最多时达到300个Pod)的重启耗时较长,高峰时段部署发布就会造成数据堆积,堆积数据消费恢复时间较长,对实时要求较高的下游回传业务有影响
- 经过分析,归因系统真正的瓶颈是归因业务部分的处理,在分区扩大到一定数量后,kafka队列消费者获取数据不再是瓶颈,业务处理部分的弹性扩容才是真正需要解决的问题
结合上述问题,我们对归因业务的架构进行了服务的拆分,把原来耦合在一起的消费数据获取和归因业务处理进行了服务的拆分,拆分为PubSub服务和归因服务,PubSub服务负责kafka消费数据的获取以及根据归因服务返回结果进行下游回传队列数据的推送,归因服务只负责归因业务逻辑的处理。拆分后的结构如下图
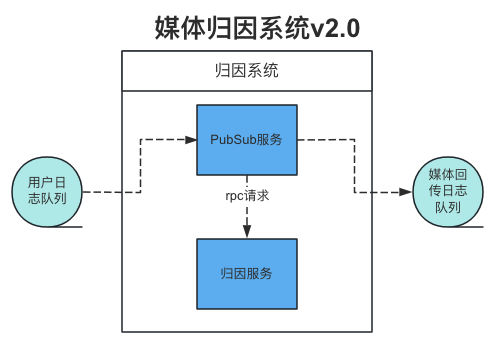
拆分后的两个服务进行单独的部署,各自配置108个Pod,对比之前300个消费Pod部署,减少了K8S集群的成本及压力。业务调整不需要对PubSub服务进行更新发布,只需要滚动更新归因服务Pod,对业务的影响也变得更小。归因服务也能根据流量的变化快速进行扩缩容。
总结
对比最初的媒体推广系统业务架构,当前的媒体推广系统已经拆分成多个独立的系统来共同支撑市场推广业务,每个系统的复杂性都远超最初系统的业务复杂度,以下是媒体推广系统架构演进过程中总结的一些经验
- 系统的第一个版本规划设计很重要,新项目的搭建一定要在团队中充分讨论架构设计是否合理以及后期的扩展性支持
- 新老系统的迁移切换是新系统架构设计的重要部分
- 针对项目迭代维护中遇到的问题要及时进行小范围的优化,等待没有明确规划的技术重构只能加剧项目维护的难度,较大的技术重构能解决历史遗留问题,但同时也会带新的且难以解决的问题
- 积极拥抱新技术,经常回顾程序设计原则