背景
Apache Kylin5 是一个 OLAP 分析引擎,他通过构建引擎来读取数据源数据生成预计算索引数据。
他通过查询引擎来查询预计算好的索引数据,也可以通过 Pushdown 能力,将查询下压给数据源引擎。
StarRocks 是一款 MPP 架构的分析型数据库,可以高效支持大数据量级的多维分析、实时分析、高并发分析等多种数据分析场景。
痛点
公司内部使用的两款查询引擎如下
-
StarRocks:查询性能出色,采用的向量化、CBO 等能力让其查询速度更上一层。
- 优点
- 查询优化手段很多:向量化、CBO、物化视图等。
- 数据量小时,无论是聚合还是明细查询都快。
- 缺点
- 大多数查询都是现算,导致查询并发不高。
- 数据量很大时,复杂查询比较吃力。
- 优点
-
Kylin:预计算之后的查询速度快,但是 Ad-Hoc 分析是其短板。
- 优点
- 预先定义好维度、度量的查询可以达到毫秒级查询。
- 数据量很大时,命中索引的复杂查询也可以保证秒级返回。
- 由于不需要现算,使得查询并发高。
- 缺点
- 需要熟悉业务的人员预先定义模型、维度、度量、索引,才能实现查询加速。
- Ad-Hoc 即席查询 无法命中索引的,查询速度由数据量决定,速度无法保障。
- 优点
为了统一的查询入口,我们将各有所长的 Kylin 和 StarRocks 融合在一起,会碰撞出怎样的火花呢?
如何融合 - 谁融合谁?
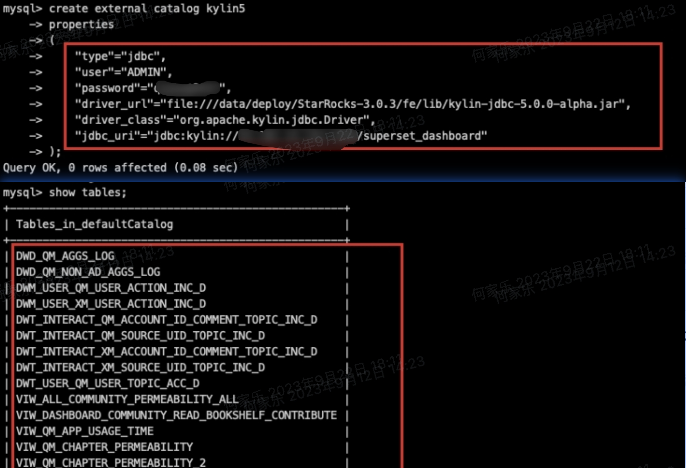
Kylin5 作为 StarRocks 的数据源
StarRocks 通过 Catalog 管理和查询内部数据与外部数据。
Kylin 是支持 JDBC 查询的。
抱着试一试的心态,修改了 StarRocks FE 的代码,让其 FE 端能识别 Kylin 的 JDBC 连接串。
结果是失败了,虽然成功连接上 Kylin5 并发起查询,但是无法获取查询结果返回给 Starrocks。
初步定位问题出自 BE 端,后续尝试研究一下 BE 的 C++ 代码,解决无法获取数据的问题。
StarRocks 作为 Kylin5 的数据源
StarRocks 作为 Kylin5 的数据源,需要满足 Kylin5 的以下三个功能点
- StarRocks 元数据获取
- StarRocks 支持 Spark 读取数据
- StarRocks 支持 Kylin5 的 PushDown 查询
构建流程
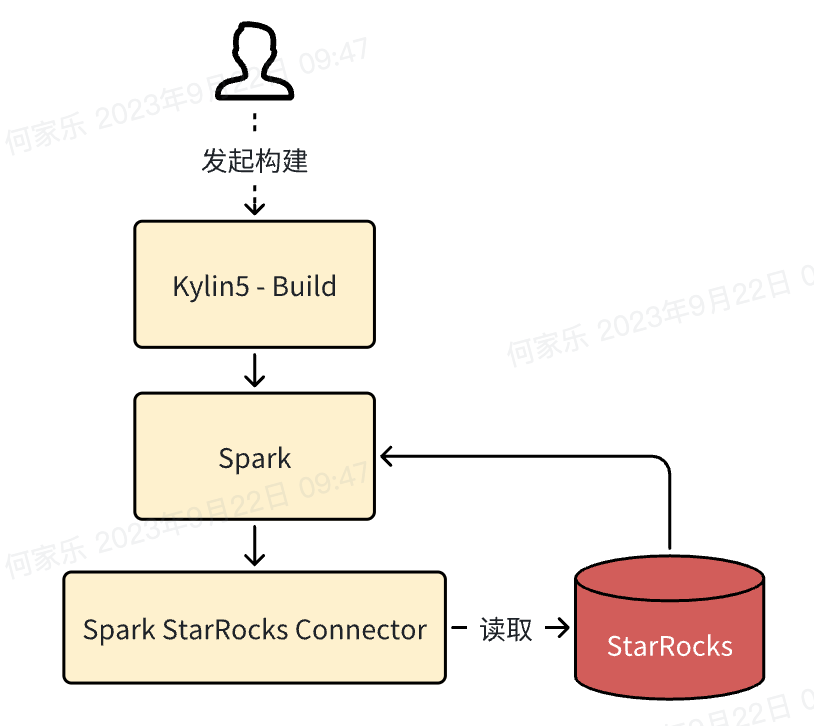
主要改动点
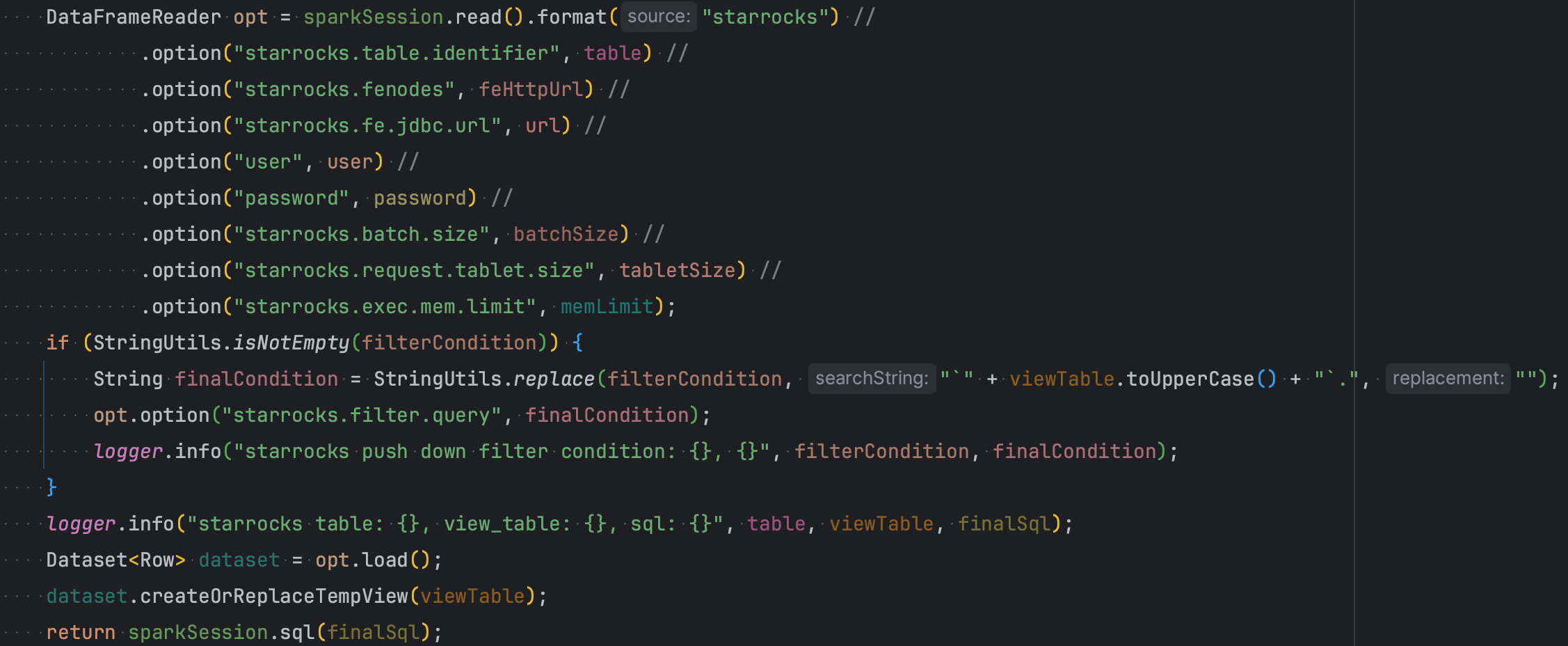
- Spark 由原先读取 Hive 数据源,修改为通过
Spark-StarRocks-Connector并行读取StarRocks数据。 - Kylin5 构建时取数的分区过滤条件,下推到 StarRocks 进行过滤。
如不进行下推,则会进行全表扫描后再过滤分区。
查询流程
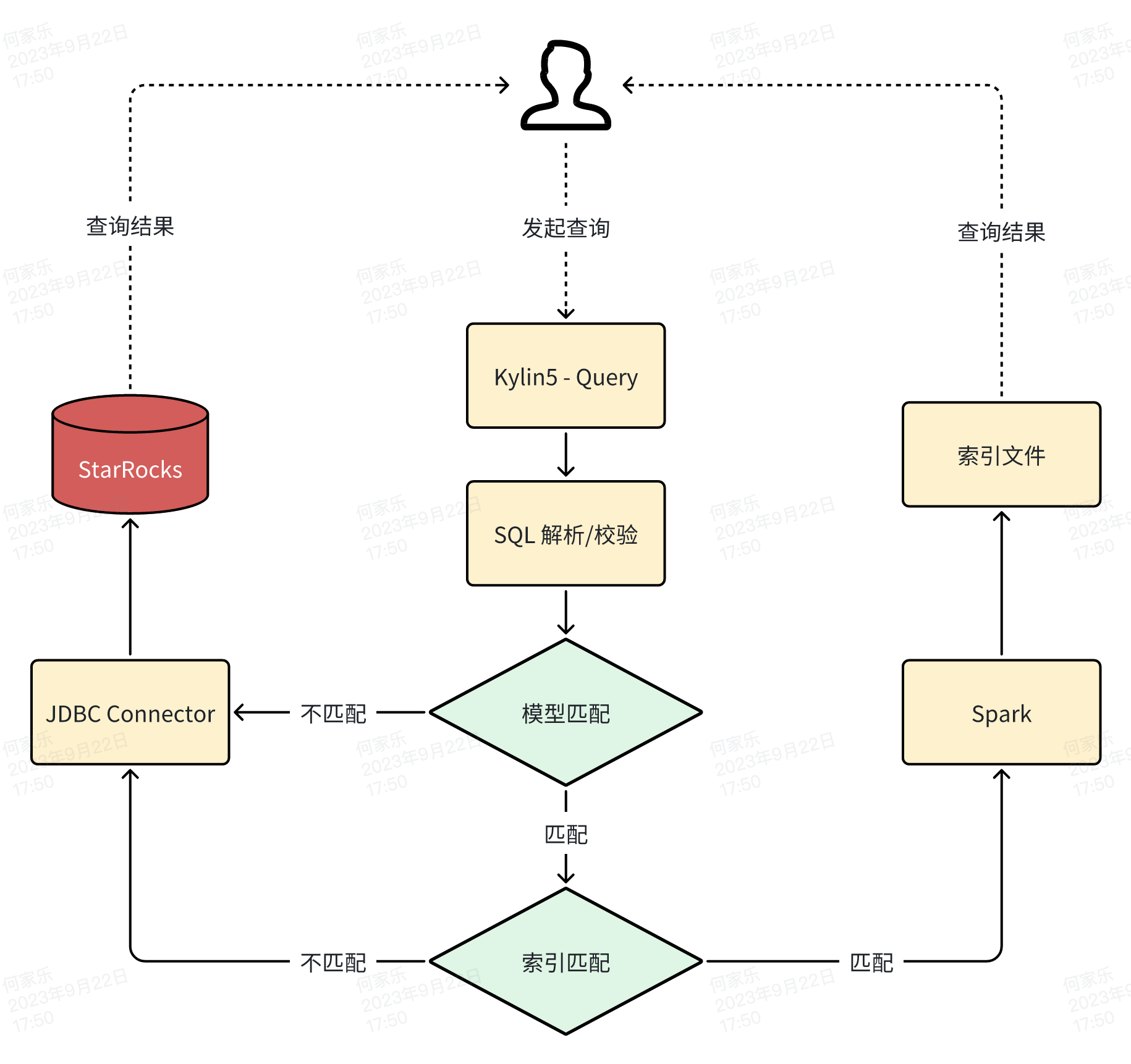
查询流程基本与原先一致
但是为了适配 StarRocks 的语法,对 Kylin5 做了一些小修改。
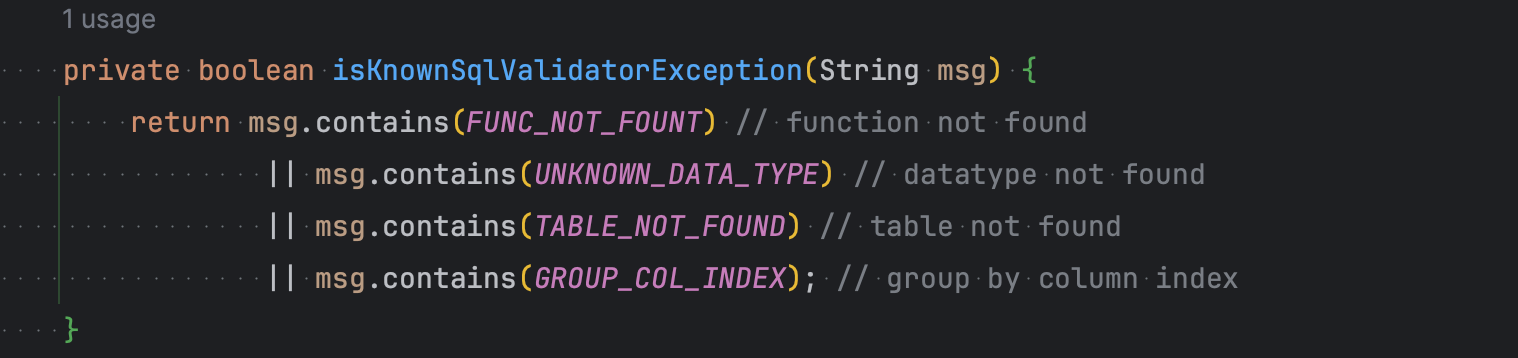
- Kylin5 查询 SQL 解析失败时,如果是以下几种情况,则直接将 SQL 下推到 StarRocks 进行查询。
- 表不存在
- 函数不存在
- 数据不存在
- Group By column Index
这么做的主要原因是
- Kylin5 使用的 Calcite 版本比较低,很多函数与主流查询引擎有些许差异。
- 当遇到 Calcite 无法解析的函数时,则会直接失败。
融合效果 - 融合后怎么进行查询?
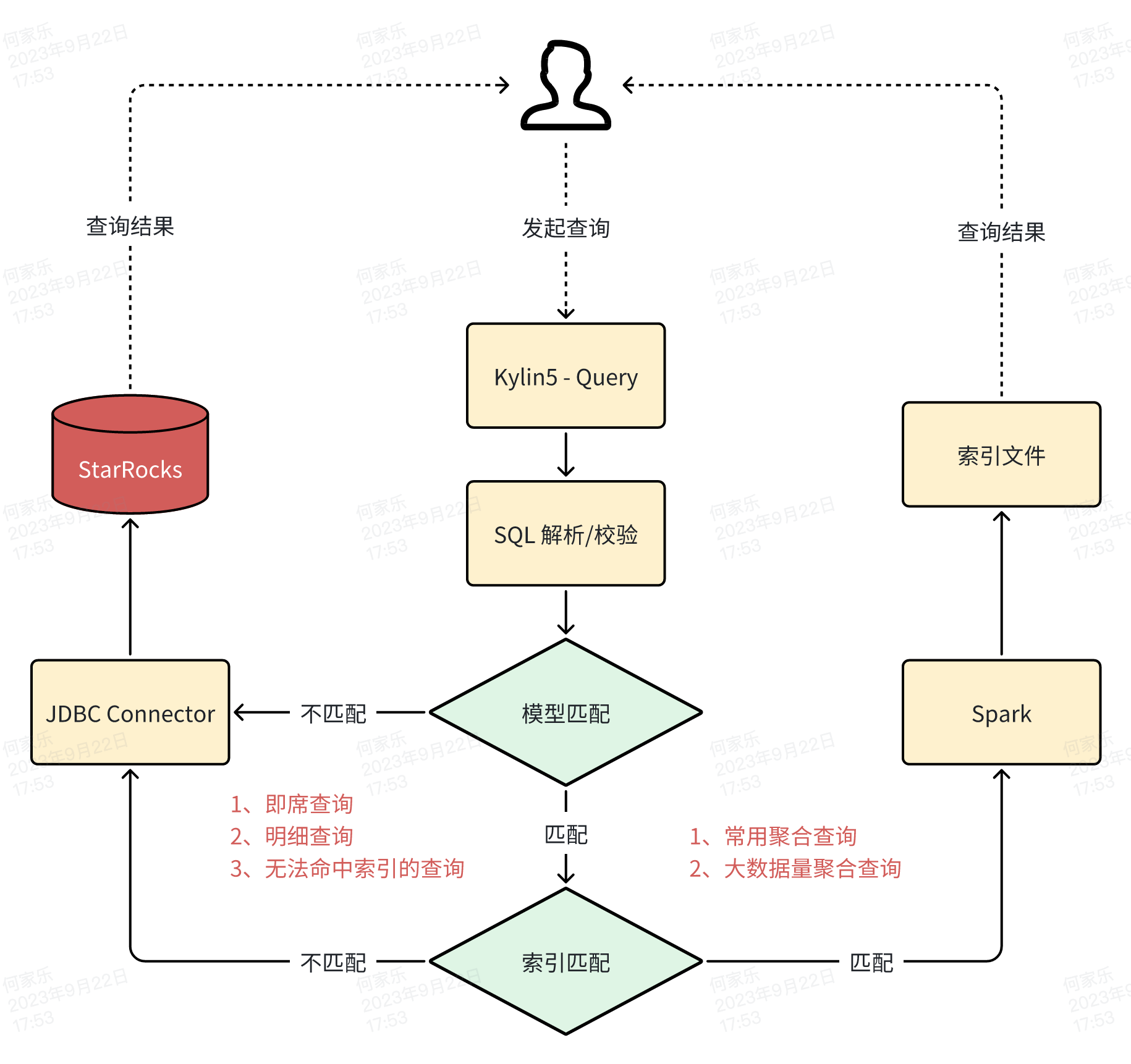
既然选择将 StarRocks 作为 Kylin5 的数据源。可以得到一个基本的架构
- Kylin5 只构建 StarRocks 中常用的聚合查询索引,用于回答聚合查询。
- StarRocks 作为 Kylin5 的 PushDown 引擎,用于回答即席查询和明细查询。
我们又回到这张图,可以根据是否命中索引,来区分 Kylin5 索引查询和 StarRocks 查询。
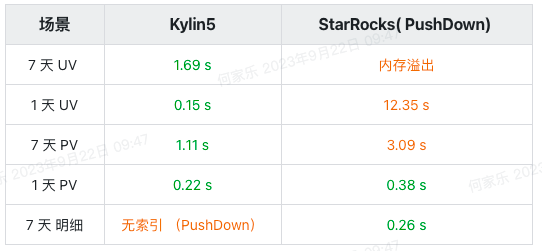
查询性能
可以发现,两个引擎是互补的关系,将 StarRocks 查起来比较费劲的 SQL 放到 Kylin5 上进行预计算做到能力分摊,合适的 SQL 分发到合适的引擎上进行查询。
- 数据量小的情况下,其实 Kylin5 预计算并没有特别突出的优势
- 数据量大,并且计算复杂(Count Distinct),Kylin5 预计算的优势开始凸显
- Kylin5 中没有索引可以回答查询时,会主动将查询 PushDown 到 StarRocks 中进行快速查询
在查询历史中,可以看到查询的回答方式,是索引回答还是 StarRocks 回答。
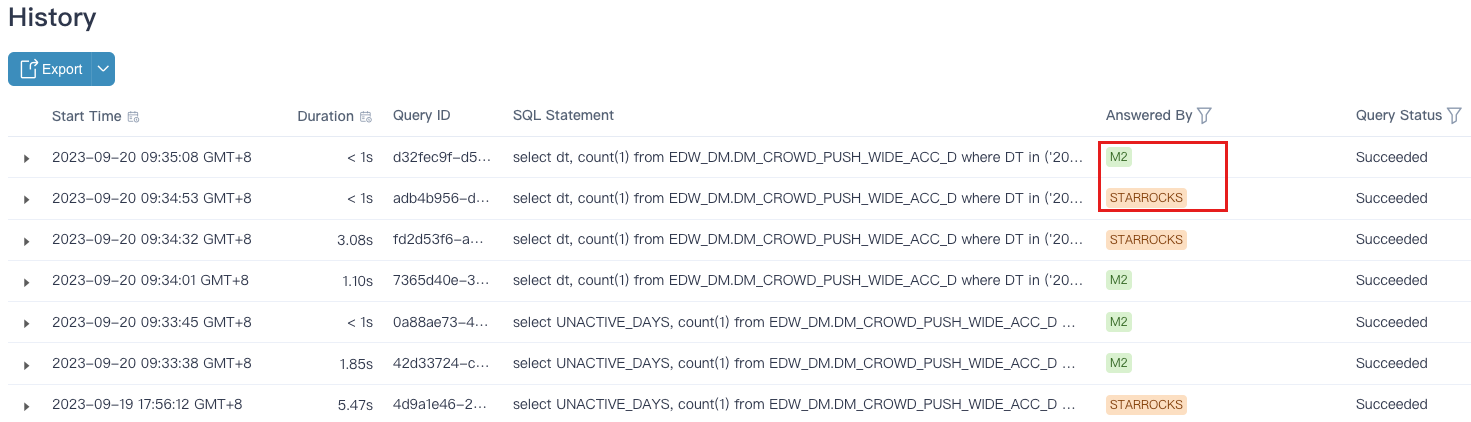
构建性能
StarRocks 单分区 7 亿条数据 共 55GB。
Kylin5 构建 2 个索引需要 15 分钟。
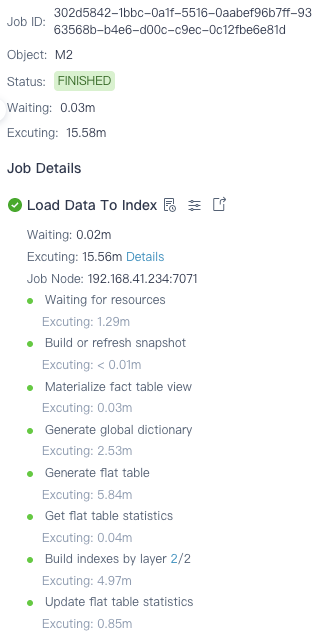
遇到的问题 - 踩了哪些坑?
后续软件版本更新若解决了这些问题,请忽略
1. 数据类型转换异常
注:2023-08-11 对接时遇到该问题,各组件版本信息如下
Spark:3.2.0
Connector: 1.1.0
StarRocks:2.5.1
问题描述
在使用 Starrocks-Spark-Connector-1.1.0 版本时,读取 Date 类型的字段转化成 Spark DateType 时出现了问题。
Connector 从 Starrocks 中读取到的数据 dt 字段是 String 类型,但是其 schema 又是 DateType,所以报错。
给社区开了个 ISSUE 详细信息可以进入下方链接查看。
数据类型转换异常 · Issue #77 · StarRocks/starrocks-connector-for-apache-spark
解决方法
社区的伙伴经过尝试无法复现,而我在将 Starrocks-Spark-Connector-1.1.0 降级到 1.0.0 ,就避开了此问题。
由此不再深究。因为 1.0.0 版本会将 Date 类型用 StringType 进行读取
2. Spark 读取 StarRocks 数据 Timeout
注:2023-08-30 对接时遇到该问题,各组件版本信息如下
Spark:3.2.0
Connector: 1.0.0
StarRocks [问题版本]:2.5.1
StarRocks [修复版本]:2.5.8 +
问题描述
具体细节不是特别清楚,感兴趣的小伙伴可以查看下方 PR 链接
[BugFix] Cancel fragment instance not query when close external scanner by wyb · Pull Request #20264
解决方法
此 BUG 已在 2.5.8+ 版本修复,故将 StarRocks 升级到 2.5.8 版本后,不再出现该报错。
3. Spark 读取 StarRocks 数据MemoryScratchSinkOperator
注:2023-08-31 对接时遇到该问题,各组件版本信息如下
Spark:3.2.0
Connector: 1.0.0
StarRocks [问题版本]:2.5.8
StarRocks [修复版本]:暂无,等待社区发布最新版本
问题描述
BE 内存统计时,错误的将输出的结果集的内存占用统计进了查询内存中,导致查询内存统计异常膨胀,超出阈值后被 BE Kill。
本不该被统计的内存,结果被错误的统计了,由此导致的查询被意外 Kill。

解决方法
目前暂无临时解决方法,社区已修复需等待社区发布最新版本。
[BugFix] Fix them mem statistics bug of MemoryScratchSink by trueeyu · Pull Request #30751 · StarRoc
总结
通过本次技术调研,确认了以Kylin5为基础,融合多种数据源进行联合查询的可行性。也确定了统一数据查询入口的可行性。
如应用到生产中,可以解决以下问题
- 统一查询入口,查询入口众多导致业务人员搞不清楚到底该去哪里查,哪里查询最合适。
- 不同查询引擎之间的负载均衡,查询引擎之间的互补,有效的分摊了查询引擎的压力。
除了 StarRocks,将来还可以继续探索将MySQL、PostgreSQL等其他数据库接入Kylin5,作为Kylin5的数据源。