背景介绍
七猫自有DSP项目主要由三大平台及广告引擎组成,其中平台包括效果平台、账户管家平台、管理员平台。广告引擎包括广告投放、引擎DRS(数据接收/消费等)。随着项目业务的增长、功能复杂度的提高,确保项目的稳定运行,自有DSP的自动化成为测试中必不可少的一部分。目前平台接口自动化巡检起到了一定的监控作用,可提前发现问题并及时解决问题,保证平台的可用性及稳定性。引擎接口自动化用于日常迭代测试及回归测试,可减少人工成本,提高测试效率,降低错误率,提高覆盖度保证广告投放的正确性。本文主要是介绍自有DSP项目自动化框架设计及实现方法。
一、行为驱动开发介绍
行为驱动开发(Behavior-Driven Development,BDD)是一种软件开发方法,强调通过描述系统行为的场景和特征来推动开发和测试的过程。BDD的核心思想是通过共享的语言和规范,促进开发团队、测试团队和业务利益相关者之间的沟通和协作。
在行为驱动开发测试中,它使用一种结构化的自然语言来编写可读性强的测试用例,这种语言被称为Gherkin。Gherkin使用关键词(如Feature、Scenario、Given、When、Then等)和描述性的文本来定义软件的行为和期望结果,使得测试用例更加易于理解和沟通。
二、Behave框架介绍
Behave是一个用于BDD(Behavior-Driven Development,行为驱动开发)测试框架。该框架提供了一种简单且易于理解的语法来编写BDD风格的测试用例,并可以结合多种编程语言进行编写,其中包括:python、java、ruby、c#等。
Behave框架的基本原理如下:
- 支持Gherkin语言:behave框架使用Gherkin语言作为测试用例的编写语言。Gherkin是一种易于理解和沟通的自然语言,可以帮助团队成员更好地理解和定义系统的行为,目前主要使用中文进行编写。
- Feature文件:Behave的测试用例以.feature文件的形式组织。每个.feature文件代表一个功能或特性,其中包含了多个场景(Scenario)。在.feature文件中,使用Gherkin语法编写场景的描述和步骤。
- 步骤定义(Step Definitions):Behave允许开发人员定义和重用测试步骤,使用Step Definitions来将Gherkin语法中的步骤映射到实际的编程代码中。用于实现每个步骤的具体操作和断言。在Step Definitions中,可以使用各种Python库和工具来执行操作和验证结果。
- 上下文(Context)对象:Behave提供了一个上下文(Context)对象,用于在测试步骤之间共享数据和状态。在Step Definitions中,可以通过Context对象来传递和获取数据,以及在不同的步骤之间保持状态。
- 运行测试:使用Behave运行测试非常简单。只需在命令行中执行
behave命令,并指定测试用例所在的目录或文件。Behave会解析.feature文件,并执行对应的Step Definitions来执行测试步骤和断言结果。 - 报告生成:Behave可以生成详细的测试报告和日志。这些报告可以支持多种形式(josn、allure等),并提供可视化的结果和统计信息,帮助团队了解测试的执行情况和结果
- 易于集成:Behave可以与其他Python测试工具和库无缝集成,如pytest、unittest和Selenium等。这使得开发人员可以根据自己的需求选择适合的工具和技术来进行测试。
总之,Behave框架是将Gherkin语法中的测试场景映射到实际的Python代码,通过Step Definitions实现具体的测试操作和断言。它提供了上下文对象来共享数据和状态,在执行测试时生成详细的报告。通过这种方式,Behave可以帮助开发团队编写和执行可读性强、可维护性好的BDD风格的测试用例,并提供可视化的测试结果和统计信息。
三、Behave+Python自动化设计与实现
3.1、设计原则
自动化测试主要是为了提高效率,保证项目质量。所以选择框架及设计时需要满足如下原则:
- 可维护性:设计测试用例时要考虑其可维护性,使得测试脚本易于理解、修改和扩展。使用清晰的命名约定、模块化的设计和良好的代码注释,以提高测试脚本的可读性和可维护性。
- 可重复性:测试用例应该是可重复执行的,即在不同环境和条件下都能产生一致的结果。
- 独立性 :测试用例应该是相互独立的,不依赖于其他测试用例的执行结果。这样可以提高测试的可靠性,便于定位和修复问题,并支持并行执行测试用例以提高效率。
- 可扩展性:设计测试用例时要考虑其可扩展性,能够应对系统的变化和需求的增加。使用参数化和数据驱动的方法,将测试数据和测试逻辑分离,以便灵活地扩展和调整测试用例。
- 高效性 :设计测试用例时要考虑其执行效率,尽量减少测试用例的执行时间和资源消耗。使用合适的并发执行、测试数据的优化和减少不必要的等待时间等方法,提高测试执行的效率。
- 可靠性 :测试用例应该是可靠的,能够准确地检测出软件中的缺陷。选择合适的断言和验证机制,确保测试结果的准确性和可靠性。
- 可复用性:设计测试用例时要考虑其可复用性,能够在不同的场景和项目中重复使用。使用模块化和抽象化的设计,将通用的测试逻辑和功能封装成可复用的组件或库。
- 可视化 :设计测试用例时要考虑其可视化,以便更好地理解和分析测试结果。使用合适的日志记录、报告生成和图表展示,帮助开发人员和其他团队成员快速理解测试结果和问题定位。
跟据具体的项目和需求,可以结合实际情况灵活应用这些原则,并不断优化和改进测试设计。
3.2、环境搭建
1)python环境安装:安装python解释器,直接进入官方网站进行安装(https://www.python.org/),选择适合项目的版本,建议使用3.x以上版本。执行如下命令即可查看是否安装成功。
Python --version2)python虚拟环境安装:多项目使用时通过安装虚拟环境可以更好的隔离项目,管理项目依赖,部署简单。使用 virtualenv构建虚拟环境工具,和 virtualenvwrapper管理虚拟环境工具。执行如下命令:
pip install virtualenv
pip install virtualenvwrapper
# 若为windows系统
pip install virtualenvwrapper-win安装好后,进行配置virtualenvwrapper环境和/root/.bashrc下虚拟环境工作目录 。配置成功后可进行激活
#./bashrc的内容
export WORKON_HOME=$HOME/.virtualenvs
#which python3配置解释器路径
export VIRTUALENVWRAPPER_PYTHON=/usr/bin/python3
source /usr/local/bin/virtualenvwrapper.sh
#保存退出后,激活
source /root/.bashrc创建虚拟环境: mkvirtualenv --python=指定Python版本 虚拟环境名。进入虚拟环境:workon 虚拟环境名,如下操作:
mkvirtualenv --python=$PYTHON_PATH {虚拟环境名称}
workon {虚拟环境名称}3)依赖库安装:常用依赖如下:
#behave安装
pip install benahve
#请求库
pip install requests
#数据库相关
pip install MySQL-python
pip install PyMySQL
pip install mysqlclient
pip install sqlalchemy
#报告
pip install allure-behave3.3、框架设计
遵循自动化编写原则如上文,进行框架设计。框架代码树如下:
|-- features
| |-- API-Test-Suites
| |-- projectone
| |-- -- case.feature
| |-- projecttwo
| |-- -- case.feature
| |-- configs
| |-- db_config.py
| |-- contants_conf.py
| |-- data
| |-- projectone
| |-- -- req_mapping.py
| |-- __init__.py
| |-- steps
| |-- common.py
| `|-- utils
| |-- http_req.py
| |-- func.py
| |-- attach_allure
| |-- outputs
| |-- report
| |-- environment.py
| |`-- run.py 框架结构介绍:
- features:#bhave框架一级目录
- API-Test-Suites:用例集,按项目进行划分,每个项目下按照功能进行feature文件创建
- configs:数据配置,主要包括数据库、redis、接口路由等配置
- data:接口参数配置,按项目区分主要为接口参数及默认值设置
- steps: 框架的步骤函数执行层,所有的用例都是通过此目录下的方法进行匹配执行
- utils :框架工具包,一些底层步骤函数调用方法、自定义报告、接口请求、飞书消息推送等
- outputs:框架报告
- environment.py: behave框架的全局变量配置文件,包括框架依赖的全局参数、自定义参数、包括定义不同作用域的前置后置处理逻辑等
- run.py:主要的框架执行入口,接收自定义参数匹配执行指定的用例集合,生成报告、发送报告等
3.4、框架实现
3.4.1、用例执行
1)入口文件执行:执行入口run.py文件
#进入到feature目录
python3 run.pyrun文件实现代码逻辑如下:
if __name__ == '__main__':
parser.add_argument('-e', '--env', type=str, default='test1', help='test1:test测试环境')
parser.add_argument('-p', '--project', type=str, default='projectone', help='项目名称')
parser.add_argument('-s', '--branch', type=str, default='master', help='用例分支')
args = parser.parse_args()
env = args.env.lower()
project = args.project.lower()
branch = args.branch.lower()
allure_result_dir = f'{ALLURE_REPORTS}/{project.lower()}'
allure_report_dir = ALLURE_HTML
try:
#执行测试用例
command1 = f"behave -f allure_behave.formatter:AllureFormatter -o {allure_result_dir} {BASE_PATH}/features/API-Test-Suites/{project}/"
result1 = subprocess.run(command1, shell=True, encoding='utf-8')
# 生成allure报告
command2 = f"allure generate {allure_result_dir} --clean -o {allure_report_dir}"
result2 = subprocess.run(command2, shell=True, encoding='utf-8')
prometheusPath = os.path.join(str(ALLURE_HTML))
# 调用飞书发送
send_message_to_feishu(engin, env, read_file(prometheusPath))
except subprocess.CalledProcessError as e:
print(f"subprocess执行标准错误输出: {e.stderr}")
raise
except Exception as e:
print(f"自动化脚本执行失败,命令异常,{command1}")
raise2)命令执行:进入虚拟环境,进入相应git项目下,features路径上级路径,执行如下相应的命令
#如执行指定的feature用例
behave features/API-Test-Suites/{项目名称}/功能用例文件.feature
#如执行执行具体场景的用例,可以在具体场景下打标签,指定标签执行
behave features/API-Test-Suites/{项目名称}/功能用例文件.feature --tags test3.4.2、用例匹配
根据执行命令中的路径找到要执行的用例文件,并在文件中进行关键字匹配,匹配成功后进行步骤执行。步骤执行调用具体的步骤函数,并执行函数封装功能,进行接口请求、响应及断言。具体步骤如下:
- 执行命令:behave features/API-Test-Suites/{$project}/xxx.feature --tags test
- 初始化:执行environment.py文件,可以在执行指定关键字前后进行设置,如下
import os,json
#执行feature文件前
def before_feature(context, feature):
context.thecookie = ''
if "skip" in feature.tags:
feature.skip(reason='skip by tag')
context.env = context.config.userdata["env"] if "env" in context.config.userdata.keys() else "qa"
print("this is before feature")
#执行feature文件后
def after_feature(context, feature):
print("this is after feature")
pass
#执行具体场景前
def before_scenario(context, scenario):
if "skip" in scenario.tags:
scenario.skip(reason='skip by tag')
#执行具体场景后
def after_scenario(context, scenario):
print("this is after scenario")- 用例查找:收集到用例之后会根据关键字Feature,Scenario,“*”解析用例的步骤,调用steps中步骤函数去执行,用例的步骤大致分为请求、结果校验两个部分,对应多个步骤去执行。用例格式具体如下
Feature:功能文件描述
@test
#======================================================
Scenario:[1.1]场景描述
* 请求"POST"接口"xx"
'''
{"req":2}
'''
* [结果校验]服务器返回成功,http返回码200
* 检查json字段返回内容
'''
{"code":3,"msg":"not support ","data":None}
'''- 步骤函数解析:在behave框架中,用例解析到的步骤和参数都会存储在context中,在send_request方法中,首先调用find_service方法查找请求接口的map配置信息,包含请求路由及请求的参数,拼接请求并调用Request方法获取对应的返回,放入context.response中,具体代码逻辑及map信息配置如下:
#步骤函数,以主要请求方法为主
@given(u'请求"(?P<method>.*)"接口"(?P<api>.*)"(?P<get_param>.*)')
def send_request(context, method, api, get_param):
svs = find_service(api)
print(svs)
APIConfig = eval(svs + "APIConfig")
ReqData = eval(svs + "ReqData")
if api in APIConfig.keys():
if context.table:
context.dict_text = table_to_dict(context.table)
elif context.text:
context.dict_text = eval(context.text)
else:
context.dict_text = {}
# 支持多环境
context.domain = 'PRE_' + APIConfig[api]["domain"] if context.env == 'pre' else 'QA_' + APIConfig[api]["domain"]
context.header = eval(context.dict_text['header']) if 'header' in context.dict_text.keys() else context.header
params = ReqData(context).params[APIConfig[api]["mapping"]] if APIConfig[api]["mapping"] else ""
context.params = json.dumps(params)
final_api = APIConfig[api]['final_api'] if "final_api" in APIConfig[api].keys() else api
url = context.host + final_api if context.host else eval(context.domain) + final_api
# 发起请求,获取返回值
context.response = Request(url, context.params, context.header, method).send_request()
# 获取body内容
context.res = context.response.get("body")
try:
context.res = json.loads(context.res)
except:
print("[WARN]Response body is not json")
context.res = context.response.get("body")
print("Response:", context.response)
else:
assert (False)#参数接口路由配置
QA_req_domain = "https://xxxxxx/"
SERVERAPIConfig = {
# 引擎对接adx接口
"api": {"domain": "req_domain", "mapping": "req_mapping"}
}
ReqData = {
#找到路由后,查找对应mapping信息
self.params["req_mapping"] = {
"Id": param.get("Id", 10001),
"Title": "事列",
}
}- 接口返回断言:发送请求后,获取真正的返回在context.respone中,与预期返回值对比,符合则用例通过,报错则用例失败,以上述用例为主,调用步骤函数后调用自定义封装的check_json_data方法,进行断言。
#断言步骤函数
@given(u'(?:.*检查.*json字段.*内容.*)')
def check_style_list_data(context):
expected_data = eval(context.text) if context.text else None
check_json_data(expected_data, context.res) #主要check_json_data代码实现
#JSON数据递归检查
def check_json_data(expected_data, real_data, msg=""):
#若返回中值=*值不做校验pass
if "*" == expected_data:
pass
else:
if isinstance(expected_data, dict):
assert_that(real_data, instance_of(dict), "%s real_data is not dict" % msg)
for key in expected_data:
assert_that(real_data, has_key(key))
check_json_data(expected_data[key], real_data[key], "key <%s>" % key)
elif isinstance(expected_data, list):
assert_that(real_data, instance_of(list), "%s real_data is not list" % msg)
assert_that(len(real_data), is_(len(expected_data)), "%s real_data length is not expected" % msg)
for _expected_data, _real_data in zip(expected_data, real_data):
check_json_data(_expected_data, _real_data)
else:
if re.match(r"(\d{4}-\d{2}-\d{2} \d{2}:\d{2}:\d{2})", str(expected_data)) != None:
assert_that(str(real_data), is_(str(expected_data)), msg)
else:
assert_that(real_data, is_(expected_data), msg)3.4.3、报告生成
用例执行完成后,无论成功还是失败,都会将用执行结果写进报告文件,报告的展示可以选择符合团队需要的自定义的格式,以allure为列,可以根据项目自定义报告格式。
#执行命令
behave -f allure_behave.formatter:AllureFormatter -o {outputs} {project}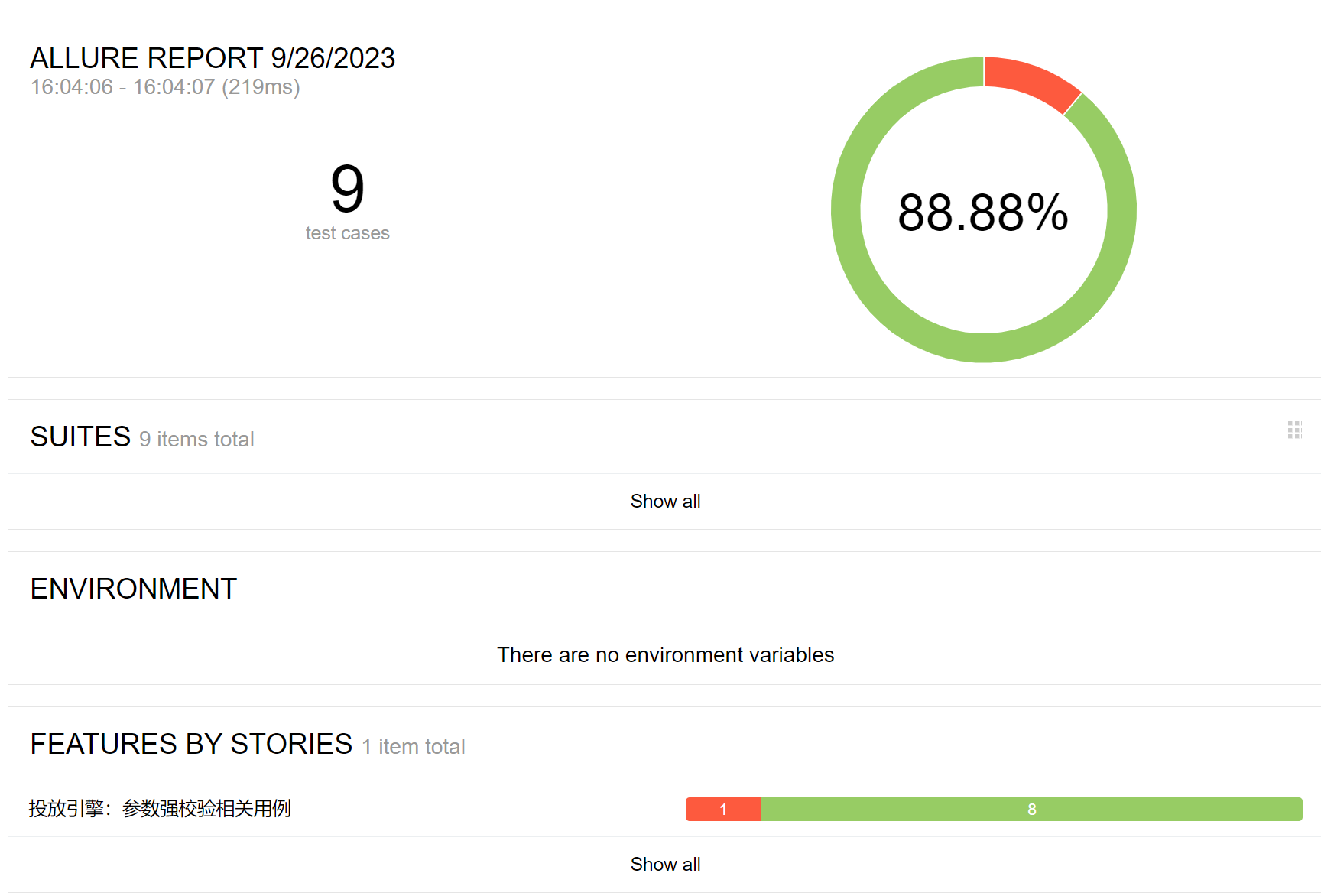
3.4.4、消息推送
用例执行后若有用例执行失败,可以推送到相关群主并@相应负责人员进行观察,具体实现如下:
import json
import requests
def send_message_to_feishu(platform, env, message, allure_dir, switch):
headers = {'Content-Type': 'application/json;charset=utf-8'}
message_split = message.split("\n")
data = {
"msg_type": "post",
"content": {
"post": {
"zh_cn": {
'title': f'用例title',
'content': [
[
{
"tag": "text",
"text": f"执行状态失败: {message_split[0].split()[1]}",
},
],
[
{
"tag": "text",
"text": f"执行状态通过: {message_split[2].split()[1]}",
},
],
[
{
"tag": "text",
"text": f"allure报告: [http://xxx/{allure_dir}]"
},
],
],
}
}
}
}
#若有失败用例,将消息推送并@相关人员排查
if int(message_split[0].split()[1]) > 0:
feishu_url = 'https://feishuurl'
data['content']['post']['zh_cn']['content'].append(
[
{"tag": "at", "user_id": "xxx", "user_name": "姓名"},
],
)
response = requests.post(feishu_url, headers=headers, data=json.dumps(data))
print(response)
if response.status_code == 200:
print("消息发送成功")
else:
print("消息发送失败")
群推送内容如下:
**项目名称,执行环境:**
执行状态失败: 3
执行状态通过: 199
执行状态跳过: 1
运行总计时长: 383184
用例耗时最长: 17190
allure报告: http://报告具体地址
@相关人员四、实践中遇到问题与解决方案
任何项自动化框架在实现过程中都会碰到一些问题,dsp项目也不例外,我们碰到的核心问题及解决方法方案记录如下,可进行参考。
4.1、报告定制化
测试报告是测试的重要组成部分,报告可以直观的帮助开发及测试人员发现问题,并找到问题产生原因,在实现过程中发现想要保留报告的有效性及更直观的丰富报告内容,需要做一些定制化的开发
4.1.1、问题一
问题描述:allure报告原生报告只显示执行顺序,开发人员通过报告查看无法直接定位问题原因。预期想将用例执行log直接体现在可视化报告中。
解决方案:通过allure内置函数allure.attach()进行自定义封装,将接口请求过程,返回值以指定的格式显示在报告步骤中,具体实现如下:
#请求放入报告中
def attach_request_info(url,method,header,params):
allure.attach(
url,
name="request url",
attachment_type=allure.attachment_type.TEXT
)
allure.attach(
str(params),
name="request params",
attachment_type=allure.attachment_type.TEXT
)
# 如果发生异常,将异常信息添加到报告中
def some_function(context):
try:
assert False, "Assertion failed!"
except AssertionError as e:
context.failed = True
allure.attach(str(e), name="Assertion Error", attachment_type=allure.attachment_type.TEXT)定制前内容:
定制后可以查看接口请求的全部过程,如下:
4.1.2、问题二
问题描述:多个平台用例同时执行时会生成多个报告,导致存在报告丢失及覆盖的情况;并且未设置报告有效期会产生大量文件,导致系统node资源达到上限,无法再生成报告。
解决方案:生成报告时报告名称按照项目及具体发生时间进行区分如project_2023_09_26_09_10_09,防止报告丢失或覆盖。编写crontab定时任务删除指定报告文件释放node资源,可以根据项目需求设置报告保存时长。
#!/bin/bash
target_date=$(date -d "2 days ago" +%Y_%m_%d)
echo "target_date: $target_date"
# 指定要删除的文件夹的路径
folder_path="/xxxxx/allure_html"
# 遍历文件夹
for folder in "$folder_path"/*; do
folder_name=$(basename "$folder")
if [ "$folder_name" = "testflie" ]; then
continue
fi
other_date=${folder_name:8:10}
if [[ $other_date < $target_date ]]; then
sudo rm -rf "$folder"
fi
done4.2、巡检实现
平台端接口主要涉及前后端交互,接口较多需要保证线上系统的稳定运行,所以在测试侧进行巡检检查接口可用性是非常重要的。
4.2.1、 问题一
问题描述:线上巡检需要指定巡检账户并要减少泄露风险,还要保证功能与其他用户一致,尤其存在跨平台交互的登录时,需要一个安全的系统巡检认证方式。
解决方案:后端约定一种算法及编码方式,若是登录接口请求时信息头携带加密字段,后端接收进行解码认证,若是巡检账户,返回巡检账户登录token,获取后再次进行请求,就可以和正常用户相同进行系统操作。防止认证token被滥用,设置有效期,过期后,框架存在重试机制,可以获取最新token,保证系统安全性。
4.2.2 、问题二
问题描述:由于系统巡检需要起到一定的监控作用,尤其是对外系统。所以需要根据系统特性设置不同的巡检时长。
解决方案:使用crontab定时任务,编写shell针对不同项目设置不同时长,从而达到巡检目的。
*/5 * * * * /bin/bash /xxxx/api_call.sh $环境 $项目#sh脚本调用框架入口文件
if [ "$1" = "auto" ]; then
cd /xxxx&&sudo python3 ./features/run.py -e "$1" -p "$2" -s "$3"
echo "执行测试脚本"
else
echo "不执行自动化用例"
fi
echo "$1" "$2" "$3"4.3、持续集成
自动化集成是自动化重要一部分,它可以加快开发速度、提高开发效率、确保组件协同工作,并通过持续集成和自动化测试提高软件质量。
4.3.1、问题一
问题描述:自动化测试想在项目流程中起到冒烟及回归作用,即开发提测后,自动触发用例执行,检查是否影响已有功能,若影响及时修改。
解决方案:
1)研究流水线部署,发现流水线可以定制流程配置,并可以选择不同的实现方式。其中选择执行命令的方式调用用例入口文件,并通过环境变量获取分支名,执行指定标签用例。
编写执行命令
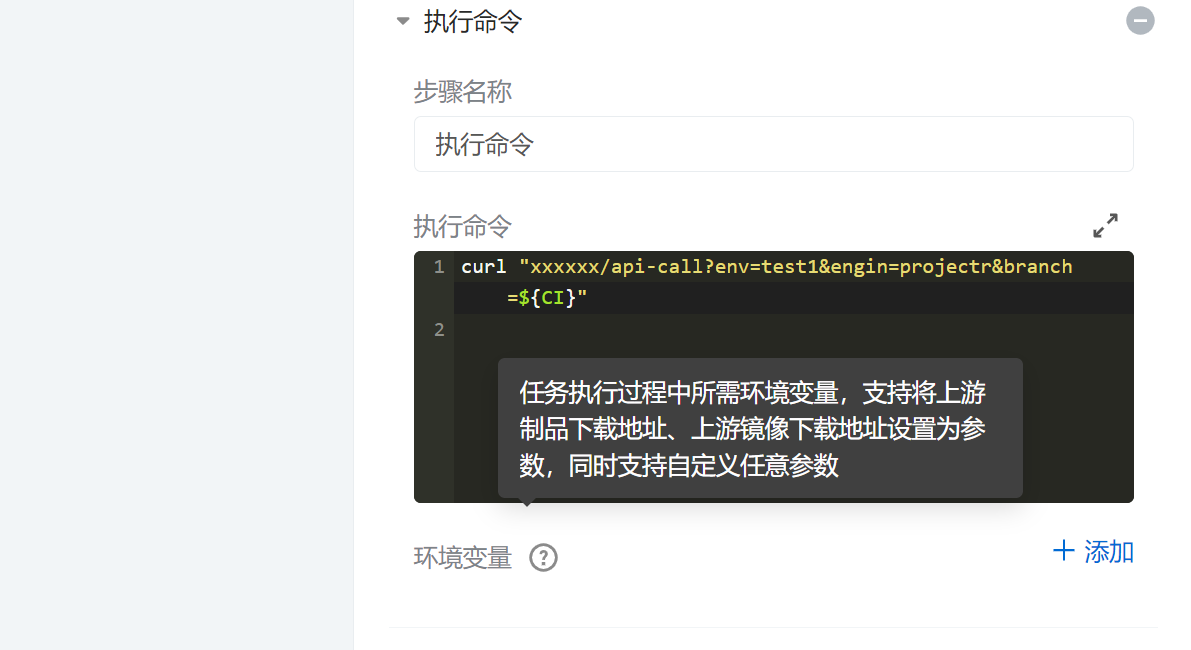
保存成功后,在部署后显示接口测试,可正常运行
2)编写流水线调用接口,接口主要功能为调用用例入口文件,主要技术使用python+flask
@app.route('/api', methods=['GET'])
def execute_script():
env = request.args.get('env')
project= request.args.get('project')
branch = request.args.get('branch', None)
#调用用例框架run.py文件执行
try:
cmd = f'/xxxx {env} {project} {switch}'
subprocess.Popen(cmd, shell=True)
response = {
'status': 'success',
'message': 'Shell script execution initiated.',
}
return jsonify(response), 200
except Exception as e:
response = {
'status': 'error',
'message': str(e)
}
return jsonify(response), 500
if __name__ == '__main__':
app.run(host='0.0.0.0')五、自动化应用场景
5.1、历史功能回归测试
目前接入迭代流程。开发提测部署后自动触发流水线接口回归,若用例存在失败数>1,则推送飞书消息及用例报告地址,@相关人员 进行排查。达到及时修改问题,减少人工回归成本及提高覆盖范围的目的。具体可参考流水线接入相关内容。
5.2、新版本功能测试
目前接口测试已跟随迭代同步进行。将自动化用例代码切迭代分支,并在该分支上直接编写测试用例,填写预期打上迭代标签。提测后直接执行迭代用例完成测试,提高了测试效率,较少测试时间。举个例子
@2.7.0.0
#======================================================
Scenario:[1.0]新增不同广告类型写入不同数据
* 请求"POST"接口"cache/index/add"
'''
{"Id":10000001,"PubType":2}
'''
* 检查json字段返回内容
'''
"ok"
'''
#执行版本测试
behave xxxx.feature --tags 2.7.0.05.3、线上平台巡检
目前自动化巡检已用于日常监测起到一定的作用。比如报表接口查询或下载超时会触发报警并推送飞书。开发及测试关注耗时情况及查看报告,可快速进行性能调优。若收到如下报错,可定位问题进行调整。
**自动化巡检,执行环境:线上**
执行状态失败: 1
运行总计时长: 111535
用例耗时最短: 36
用例耗时最长: 60124
用例耗时总计: 111435
执行重试次数: 1
运行次数总计: 1
allure报告: [http://xxxx/project_2023_09_24_08_01_53]
小贴士
自动化框架有很多种,可以根据项目特性进行合理选择,选择原则主要是:能提高测试效率,减少人工成本,保证项目质量最重要。