前言
前段时间我们推荐引擎这边发现一个非常诡异的事情,具体表现为线上k8s每次滚动更新或发版时,都会有大批量请求出现超时,进而触发服务端的p99熔断报警,导致推荐服务发生短暂不可用等情况(是的,你没听错,都会有,每发一次都报,服务端都烦了<手动狗头>)

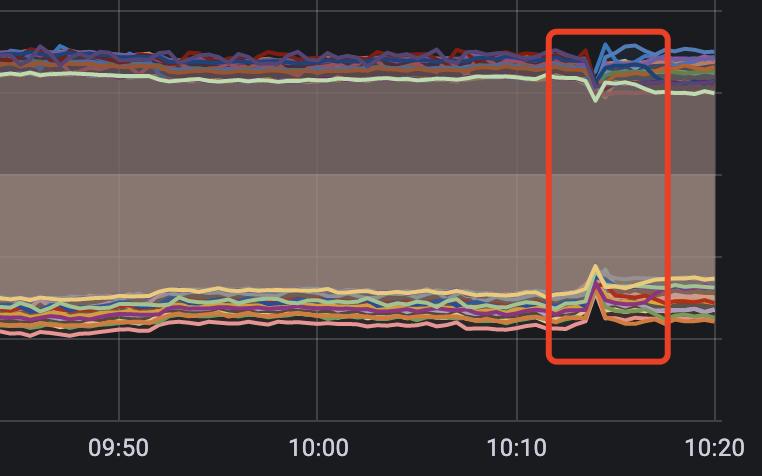
引擎端的监控数据表现为
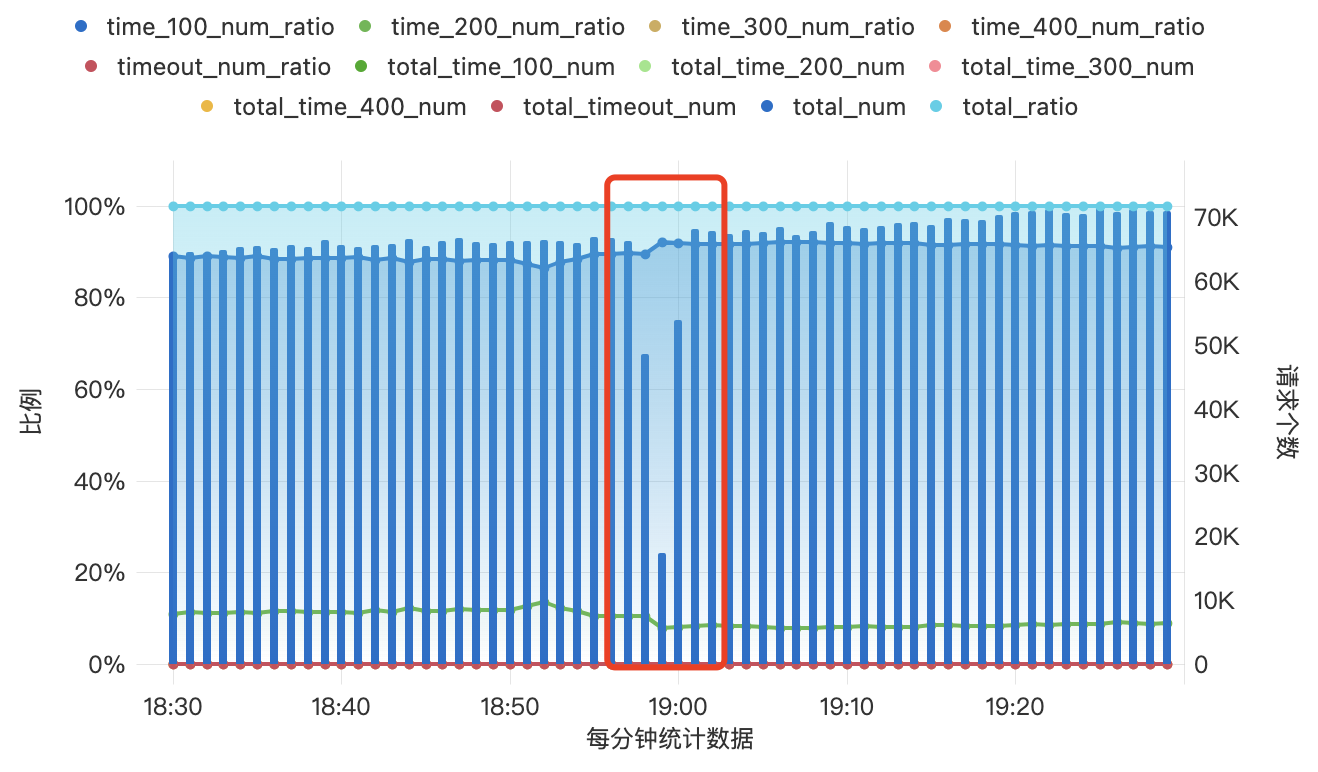
同时每天凌晨的时候也都会有一次流量骤降的情况,与滚动更新的表现相似。
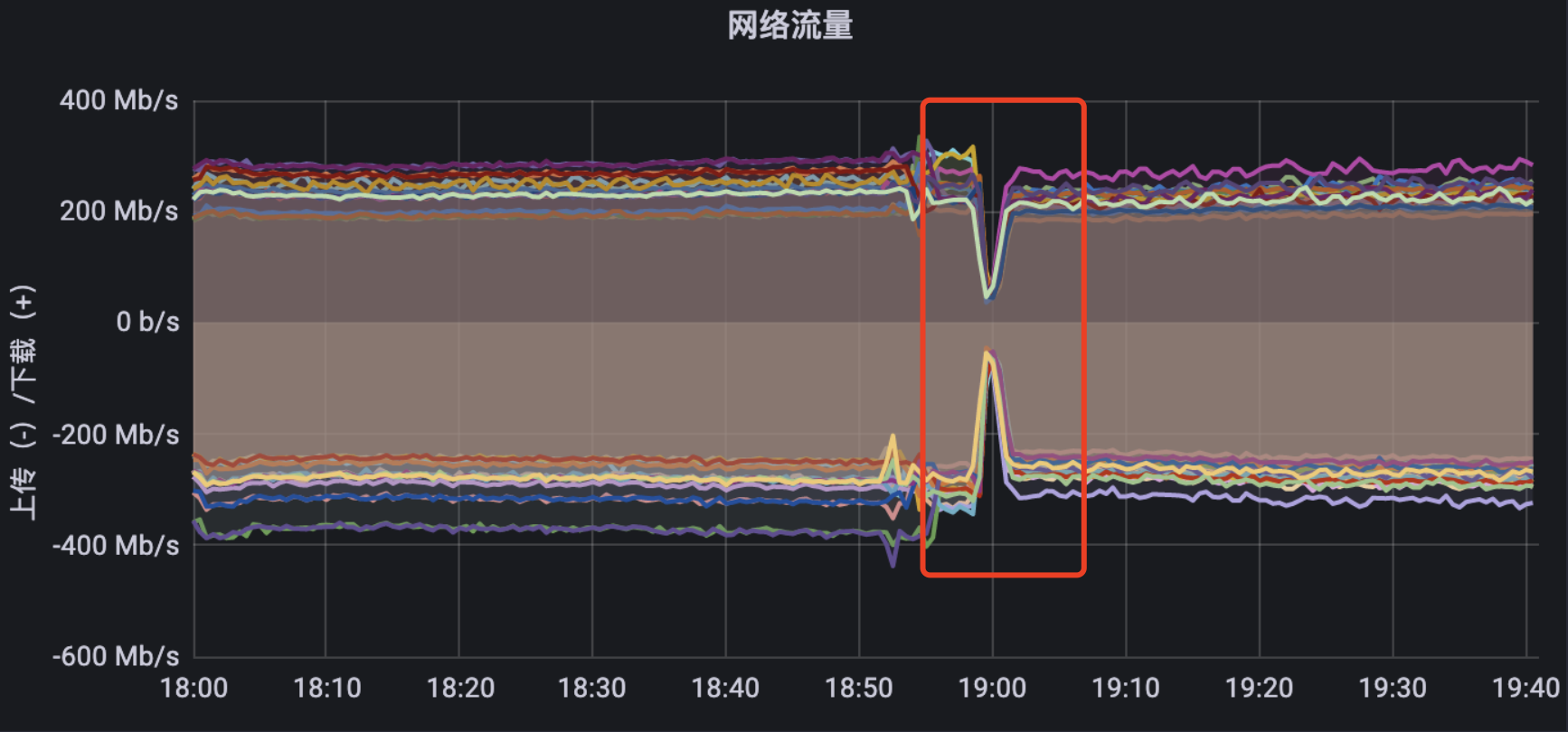
一开始我们是没有把这两者联想到一起的,自顾思考着各自可能的原因。本着不喜欢刨根问底的程序员不是好厨师的伟大思想作为指引的我,准备深入敌军内部一探究竟。然而随着探查的逐渐深入,那藏在谜团内部的神鬼莫测,也如清晨的层层迷雾一般随折炽热骄阳的升起而悄无声息的散开......
项目背景
引擎端的相关架构和网络配置:
- 一个k8s集群
- 一个统一的gateway网关,用来接收服务端的一切API请求,统一转发到各个微服务
- gateway对外通过SLB提供网络访问以及负载均衡的支持
- 集群内部通过headless进行网络转发,采用
round_robin的方式进行客户端负载
问题的思考
关于滚动时报警可能的原因?嗯,无非是有两点:
- 推荐引擎的原因
- 服务端的原因
好吧,一下子有点宽泛了哈哈,那我们首先排除一个正确答案,那就只剩下服务端了.
那么服务端究竟有什么问题呢?
众所周知,我们引擎端对每个请求都设置了400ms的全局超时时间,超过之后就会立即截断返回,可是服务端的报警里却均是1s以上的超时,难道说服务端自身处理单个请求的时间超过了600ms?
想到这里,突然想起来广智在脱口秀大会里面说的一段话:"我去理发店剪头,理发师给我设计了一个很潮很潮的发型,剪完之后,我沉默了...tony也沉默了...可是此时我们心里有了一个共同的想法......这也不能全赖他?"
豁然开朗啊,我说服务端的同学每次跟我们说报警这个事的时候怎么都那么客气呢,原来是这( ̄▽ ̄).
当然,凡事都不能侥幸依赖(甩锅)于外部原因,就算服务端确实有问题,那也不能解释引擎端一发版就触发400ms超时的问题,所以究其根本,问题还出在引擎端这里
那么再细化一点,引擎端会有可能是什么问题导致的呢?
- 代码有问题,全局超时时间没有生效,导致在引擎端耗费了更多的时间
- pod的数量问题,滚动更新的时候策略配置有误,导致可用的pod数量过少不足以支持整个服务的运行,造成请求积压响应变慢等
- 新启动的pod没有及时被发现,导致新的pod虽然起来了,但是请求依然访问的是旧的pod服务
- 其他原因
针对问题1,我通过本地调试等操作进行了相关确认,全局超时时间稳定可用,即问题1排除
针对问题2,相关服务的deployment配置均进行了相关的检查,确认滚动时会有足够的pod来满足当前服务的请求,即问题2也排除
那么问题3呢?问题3我们先跳过
那么问题4呢?问题4说你先把问题3解决了
好的,那么针对问题3,我们来思考一下,新启动的pod没有及时被发现?为什么没有被发现?
- 客户端DNS没有及时更新,导致没有获取到新的pod信息
- SLB的endpoints列表没有及时更新,导致没有获取到新的pod信息
- 引擎端的优雅退出没有生效,导致http2的长连接一直连接在旧的pod上
- SLB的服务摘流不及时,在Pod关闭的时候依然有很多新流量进来
- pod退出等待的时间较长,本来都已经没有请求进来了pod依然在正常运行,占用了可用pod的数量
下面针对这几个可能的原因再具体分析一下:
针对情况1,gateway对外走的的SLB负载均衡,没走客户端负载,直接枪毙
针对情况2,这种情况是有可能的,但是没有办法直接做判断,需要做实验进行验证
针对情况3,通过模拟发送SYSTERM信号给本地pod调式了一下grpc优雅退出的流程,发现逻辑是正常的,这个也可排除
针对情况4,服务摘流不及时.我们之前在解决集群内pod负载不均衡的问题时,曾经试过把deployment参数terminationGracePeriodSeconds和preStop分别设置为120和70s,相关参数在作用可在官方文档:Pod的生命周期查看,虽然preStop的时间设置了70s,能有效解决摘流不及时的问题,但是这个时间貌似有点长了需要进一步验证
针对情况5,与4类似,有可能是preStop时间过长,导致pod已经没有请求可处理了,而pod还一直在"占着茅坑不拉*"
从上面大家或许也都发现一些端倪了,几个待验证的点,都跟pod没有及时退出或SLB没有及时更新有关,那么该从什么方向入手才好呢?
众所周知,grpc是基于http2的长连接,那么长连接有什么特点呢?没错,就是说这个连接,它是个长的(好兄弟,别打脸).就是说啥呢,你不让它goaway,它就一直连着,管你死不死呢(因为它也不知道你死没死).那么我们是不是可以通过调整一下它们keepalive的一些参数,让它们定期的互ping一下,打声招呼:"喂,你死没死啊","我没死","好的''......
所以老铁们,来活儿了!
下面我们要做的,就是针对情况2,4和5来进行一个验证,根据实际的运行表现来一探究竟,看看到底是怎么个一回事
排查方案
模拟服务端调用推荐引擎SDK,调整相关参数,请求频率,实验条件等,根据实验步骤分析实验结果,找出相关问题所在及其产生原因,进而解决问题
实验准备
首先搞一段测试用的代码,非常简单,通过sleep的时长控制请求的频次
func TestThoughEndChapter(t *testing.T) {
t.Parallel()
client, _, err := recommend.New(context.Background(), "rec-test1:9090")
if !assert.Nil(t, err) {
t.Error(err)
}
reqBody := &api.GetEndChapterRecRequest{
Identity: &api.Identity{
PhoneType: api.PhoneType_Android,
UUID: "86971204419321",
OAID: "86971204419321",
TrustedID: "DuKB+e4YWAc7AcaeJ/yU71IFmbfcXNrn9y4B7hH8kcwY682j6eMQhD6HFG8at9s2vV9w2lDLqL5rd4VHS+XarM3",
},
ReferBookID: "215071",
PageSize: 10,
}
count := 0
for {
//ctx, cancelFunc := context.WithTimeout(context.Background(), 400*time.Millisecond)
ctx := context.Background()
begin := time.Now()
_, err := client.GetEndChapterRec(ctx, reqBody)
if !assert.Nil(t, err) {
t.Error(err)
}
//cancelFunc()
elapsed := time.Since(begin).Microseconds()
if elapsed > 400000 {
count++
println("###############################累计超时次数:", count, "本次耗时:", elapsed/1000, "ms")
}
log.Println(elapsed)
time.Sleep(900 * time.Millisecond)
}
}
New方法里进行grpc的dial操作,client的keepalive参数也在这里面添加和调整:
dialOptions := []grpc.DialOption{
grpc.WithTransportCredentials(creds),
grpc.WithWriteBufferSize(writeBufSize),
grpc.WithReadBufferSize(readBufSize),
grpc.WithDefaultCallOptions(
grpc.MaxCallRecvMsgSize(maxRecvBytes),
grpc.MaxCallSendMsgSize(maxSendBytes),
),
grpc.WithDefaultServiceConfig(string(dsc)),
grpc.WithChainUnaryInterceptor(chain...),
grpc.WithKeepaliveParams(keepalive.ClientParameters{
Time: 10 * time.Second,
Timeout: time.Second,
PermitWithoutStream: true,
}),
}
conn, err := grpc.DialContext(ctx, target, dialOptions...)
之后登录阿里云K8s控制台,准备查看pod日志和滚动部署等操作
实验环境
推荐引擎test1环境,为每个服务建立一个pod,相关配置基本与线上相同(当然不是指硬件配置,想啥呢)
实验步骤
- 客户端循环发起请求
- 此时登录k8s重新部署gateway
- 观察接口的响应数据
- 分析响应规律
- 多次实验保证结果的可靠性
开启实验
万事俱备,干就完了
实验一:设置client请求超时时间
实验条件
- client设置400ms请求超时时间
- client不加keepalive参数
- QPS为1
- server端不配置keepalive参数
实验表现
2022-05-04 15:27:05执行gateway重新部署,新pod的部署日志为:
| 类型 | 状态 | 更新时间 | 内容 | 消息 |
|---|---|---|---|---|
| Initialized | True | 2022-05-04 15:27:05 | - | - |
| Ready | True | 2022-05-04 15:27:16 | - | - |
| ContainersReady | True | 2022-05-04 15:27:16 | - | - |
| PodScheduled | True | 2022-05-04 15:27:05 | - | - |
2022-05-04 15:27:16新pod达可用状态,而旧的pod还在接收正常请求
2022-05-04 15:27:20滚动部署15秒后服务不可用,经过大概50秒后,2022/05/04 15:28:11服务重新可用
2022/05/04 15:27:17 146047
2022/05/04 15:27:18 137421
2022/05/04 15:27:19 143965
2022/05/04 15:27:20 145257
client_test.go:74:
Error Trace: client_test.go:74
Error: Expected nil, but got: &status.Error{s:(*status.Status)(0x140002300d0)}
Test: TestThoughEndChapter
client_test.go:75: rpc error: code = DeadlineExceeded desc = context deadline exceeded
###############################累计超时次数: 1 本次耗时: 401 ms
.
.
.
###############################累计超时次数: 37 本次耗时: 401 ms
2022/05/04 15:28:09 401104
client_test.go:74:
Error Trace: client_test.go:74
Error: Expected nil, but got: &status.Error{s:(*status.Status)(0x140000104c0)}
Test: TestThoughEndChapter
client_test.go:75: rpc error: code = DeadlineExceeded desc = context deadline exceeded
###############################累计超时次数: 38 本次耗时: 401 ms
2022/05/04 15:28:10 401575
client_test.go:74:
Error Trace: client_test.go:74
Error: Expected nil, but got: &status.Error{s:(*status.Status)(0x1400028e350)}
Test: TestThoughEndChapter
client_test.go:75: rpc error: code = Unavailable desc = error reading from server: read tcp 10.8.8.203:53192->rec-test1:9090: read: operation timed out
2022/05/04 15:28:11 241018
2022/05/04 15:28:12 147579
2022/05/04 15:28:13 149446
分析:纳尼,问题这么明显吗,怪不得一发版就报错呃...旧pod在terminal一段时间之后,依然有新的流量进入到该pod来,后在pod不可用时,新的请求依然在试图连接该pod,导致一直超时
实验二:取消client请求超时时间
实验条件
- client取消400ms请求超时时间
- client不加 keepalive参数
- QPS为1
- server端不配置keepalive参数
表现
重新部署约15秒后出现请求失败,但是是一直阻塞状态,直到60秒后才重新可用
2022/05/04 15:20:29 141237
2022/05/04 15:20:30 144872
client_test.go:74:
Error Trace: client_test.go:74
Error: Expected nil, but got: &status.Error{s:(*status.Status)(0x140002a6010)}
Test: TestThoughEndChapter
client_test.go:75: rpc error: code = Unavailable desc = closing transport due to: connection error: desc = "error reading from server: read tcp 10.8.8.203:53039->rec-test1:9090: read: operation timed out", received prior goaway: code: NO_ERROR
###############################累计超时次数: 1 本次耗时: 67295 ms
2022/05/04 15:21:38 67295894
2022/05/04 15:21:40 168517
2022/05/04 15:21:41 168432
分析:server端不可用时,client连接不上server,但连接并没有断开,所以就一直阻塞.且由于没有连接到server,此时相当于卡在了tcp阶段,server端的超时控制也是不可用的
实验三:增加client keepalive参数
实验条件
- client设置400ms请求超时时间
- 配置client keepalive参数
- QPS为1
- server端不配置keepalive参数
参数配置1:
keepalive.ClientParameters{
Time: 10 * time.Second,//时间小于10秒时按10秒处理
Timeout: 1 * time.Second,
PermitWithoutStream: true,//即使没有活动流也允许 ping,经验证true和false对我们系统来说关系不大
}
实验表现
- 请求15秒后出现超时
- 再经过10秒后请求恢复
参数配置3
keepalive.ClientParameters{
Time: 20 * time.Second,
Timeout: 1 * time.Second,
PermitWithoutStream: true,
}
实验表现
- 请求约15秒出现超时
- 经过20秒恢复
参数配置3
keepalive.ClientParameters{
Time: 30 * time.Second,
Timeout: 1 * time.Second,
PermitWithoutStream: true,
}
实验表现
- 请求约15秒出现超时
- 经过30秒恢复
分析:咦,是不是发现了点啥?是的没错,在一定的时间下,服务不可用时间基本与client ping的周期一致,至于请求约15秒后才出现超时具有不确定性,有时也会不到10秒就超时了
实验四:调整服务端的deployment参数
实验条件
- client设置400ms请求超时时间
- 不加client keepalive参数
- QPS为1
- server端不配置keepalive参数
- deployment参数调整
原来的参数配置:
terminationGracePeriodSeconds: 120
preStop: 70
参数配置1
terminationGracePeriodSeconds: 30
preStop: 20
实验表现
与实验一表现相似,但是仅超时了15s左右
2022/05/04 16:00:51 151892
2022/05/04 16:00:52 147875
2022/05/04 16:00:53 152839
client_test.go:74:
Error Trace: client_test.go:74
Error: Expected nil, but got: &status.Error{s:(*status.Status)(0x1400019c110)}
Test: TestThoughEndChapter
client_test.go:75: rpc error: code = DeadlineExceeded desc = context deadline exceeded
###############################累计超时次数: 1 本次耗时: 402 ms
2022/05/04 16:00:55 402347
.
.
.
###############################累计超时次数: 11 本次耗时: 401 ms
2022/05/04 16:01:08 401369
client_test.go:74:
Error Trace: client_test.go:74
Error: Expected nil, but got: &status.Error{s:(*status.Status)(0x14000122018)}
Test: TestThoughEndChapter
client_test.go:75: rpc error: code = DeadlineExceeded desc = context deadline exceeded
###############################累计超时次数: 12 本次耗时: 402 ms
2022/05/04 16:01:09 402059
2022/05/04 16:01:10 159264
2022/05/04 16:01:11 195547
参数配置2
terminationGracePeriodSeconds: 30
preStop: 10
实验表现
这次超时了大概10s
2022/05/04 16:13:06 152930
2022/05/04 16:13:07 153194
client_test.go:74:
Error Trace: client_test.go:74
Error: Expected nil, but got: &status.Error{s:(*status.Status)(0x14000010120)}
Test: TestThoughEndChapter
client_test.go:75: rpc error: code = DeadlineExceeded desc = context deadline exceeded
###############################累计超时次数: 1 本次耗时: 401 ms
.
.
.
2022/05/04 16:13:11 401039
client_test.go:74:
Error Trace: client_test.go:74
Error: Expected nil, but got: &status.Error{s:(*status.Status)(0x14000010028)}
Test: TestThoughEndChapter
client_test.go:75: rpc error: code = DeadlineExceeded desc = context deadline exceeded
###############################累计超时次数: 4 本次耗时: 401 ms
2022/05/04 16:13:12 401416
2022/05/04 16:13:13 222129
参数配置3
terminationGracePeriodSeconds: 30
preStop: 5
实验表现
矮油?这次超时了2秒左右,神奇吧
2022/05/04 16:17:02 147413
2022/05/04 16:17:03 139260
client_test.go:74:
Error Trace: client_test.go:74
Error: Expected nil, but got: &status.Error{s:(*status.Status)(0x140000b80d8)}
Test: TestThoughEndChapter
client_test.go:75: rpc error: code = Unavailable desc = last connection error: connection error: desc = "transport: Error while dialing dial tcp rec-test1:9090: connect: connection refused"
2022/05/04 16:17:04 21083
client_test.go:74:
Error Trace: client_test.go:74
Error: Expected nil, but got: &status.Error{s:(*status.Status)(0x140000b80f8)}
Test: TestThoughEndChapter
client_test.go:75: rpc error: code = Unavailable desc = last connection error: connection error: desc = "transport: Error while dialing dial tcp rec-test1:9090: connect: connection refused"
2022/05/04 16:17:05 604
2022/05/04 16:17:06 155038
2022/05/04 16:17:07 145616
参数配置4
terminationGracePeriodSeconds: 30
preStop: 1
实验表现
与参数配置1相似,但是只不可用了1秒
2022/05/04 16:24:03 149336
2022/05/04 16:24:04 143773
client_test.go:74:
Error Trace: client_test.go:74
Error: Expected nil, but got: &status.Error{s:(*status.Status)(0x1400033c090)}
Test: TestThoughEndChapter
client_test.go:75: rpc error: code = Unavailable desc = last connection error: connection error: desc = "transport: Error while dialing dial tcp rec-test1:9090: connect: connection refused"
2022/05/04 16:24:05 776
2022/05/04 16:24:06 142257
参数配置5
terminationGracePeriodSeconds: 30
preStop: 0
实验表现
与参数配置5相同
分析:preStop的时长确实影响到了pod,即当时长过长时,有可能会因为没有请求进来但是却占用着一个空闲的pod而影响到正常的请求,另外原因考虑也可能会影响到slb对endpoints的更新
实验五:调整服务端的keepalive参数
实验条件
- client设置400ms请求超时时间
- client配置keepalive参数
- QPS为1
- server端配置keepalive参数
- deployment参数不做调整
参数配置1
grpc:
keepalive_params:
max_connection_age: 1m
max_connection_idle: 15s
max_connection_age_grace: 5s
time: 5s
timeout: 1s
min_time: 5s
permit_without_stream: true
相当于grpc中keepalive的以下配置:
keepalive.EnforcementPolicy{
MinTime: 5 * time.Second, // If a client pings more than once every 5 seconds, terminate the connection
PermitWithoutStream: true, // Allow pings even when there are no active streams
}
keepalive.ServerParameters{
MaxConnectionIdle: 15 * time.Second, // If a client is idle for 15 seconds, send a GOAWAY
MaxConnectionAge: 60 * time.Second, // If any connection is alive for more than 30 seconds, send a GOAWAY
MaxConnectionAgeGrace: 5 * time.Second, // Allow 5 seconds for pending RPCs to complete before forcibly closing connections
Time: 5 * time.Second, // Ping the client if it is idle for 5 seconds to ensure the connection is still active
Timeout: 1 * time.Second, // Wait 1 second for the ping ack before assuming the connection is dead
}
具体可参考:keepalive的相关参数
实验表现
重新部署后,会出现持续5s的超时,之后恢复正常
参数配置2
grpc:
keepalive_params:
max_connection_age: 1m
max_connection_idle: 15s
max_connection_age_grace: 5s
time: 1s
timeout: 1s
min_time: 5s
permit_without_stream: true
实验表现
将ping的周期设置为每秒一次,重新部署后,持续的超时时间也降为了1s,之后恢复正常
分析:server端周期性ping client时,当发现自身服务不可用,会立即发送goaway信号给client,且会发送信号给slb使其将自身从endpoints中踢出并立即刷新endpoints列表(未核实,但从表现来看确实如此),从而使新的请求负载到新的pod中去
实验进行到这些,本以为能直接解决问题了,可还是会有那么一丢丢的不尽人意,即问题解决了,但没完全解决(捂个脸哭一下)本来直接到这里也可以就结束了的,毕竟理论上也可以解决线上的问题了,至少报警的问题不会再现.可是如果就只安于现状,那岂不是违背了我伟大思想的指导原则?于是痛定思痛,从实际出发,思考是否还有哪些地方没有考虑到...于是就有了实验六
实验六:创建多个pod
之前的多个实验,都是单pod滚动更新的,与线上的多pod的条件不一致.同时模拟kubelet发送SIGTERM信号debug了grpc的优雅退出,发现也没有问题.怀疑有可能之前的调整已经生效,只不过由于endpoints没及时更新,或者没有其他pod可用,导致期间无可提供服务的pod进而发生请求超时
实验条件
- client设置400ms请求超时时间(增加不设超时时间的对比)
- client配置keepalive参数(增加不配keepalive参数的对比)
- QPS为1(增加不同qps时的对比)
- server端配置keepalive参数
- deployment参数不做调整(增加调整参数的对比,如30s,5s)
- pod数量增加至3个(增加自动弹缩的对比,数量均大于1)
参数配置
grpc:
keepalive_params:
max_connection_age: 1m
max_connection_idle: 15s
max_connection_age_grace: 5s
time: 5s
timeout: 1s
min_time: 5s
permit_without_stream: true
实验表现
在该配置和各种实验对比参数调整的情况下,均未再表现出请求超时的情况,这不就成了吗这不是,这不就成了吗这不是
于是进行线上滚动更新验证,数据表现为:
参数调整前
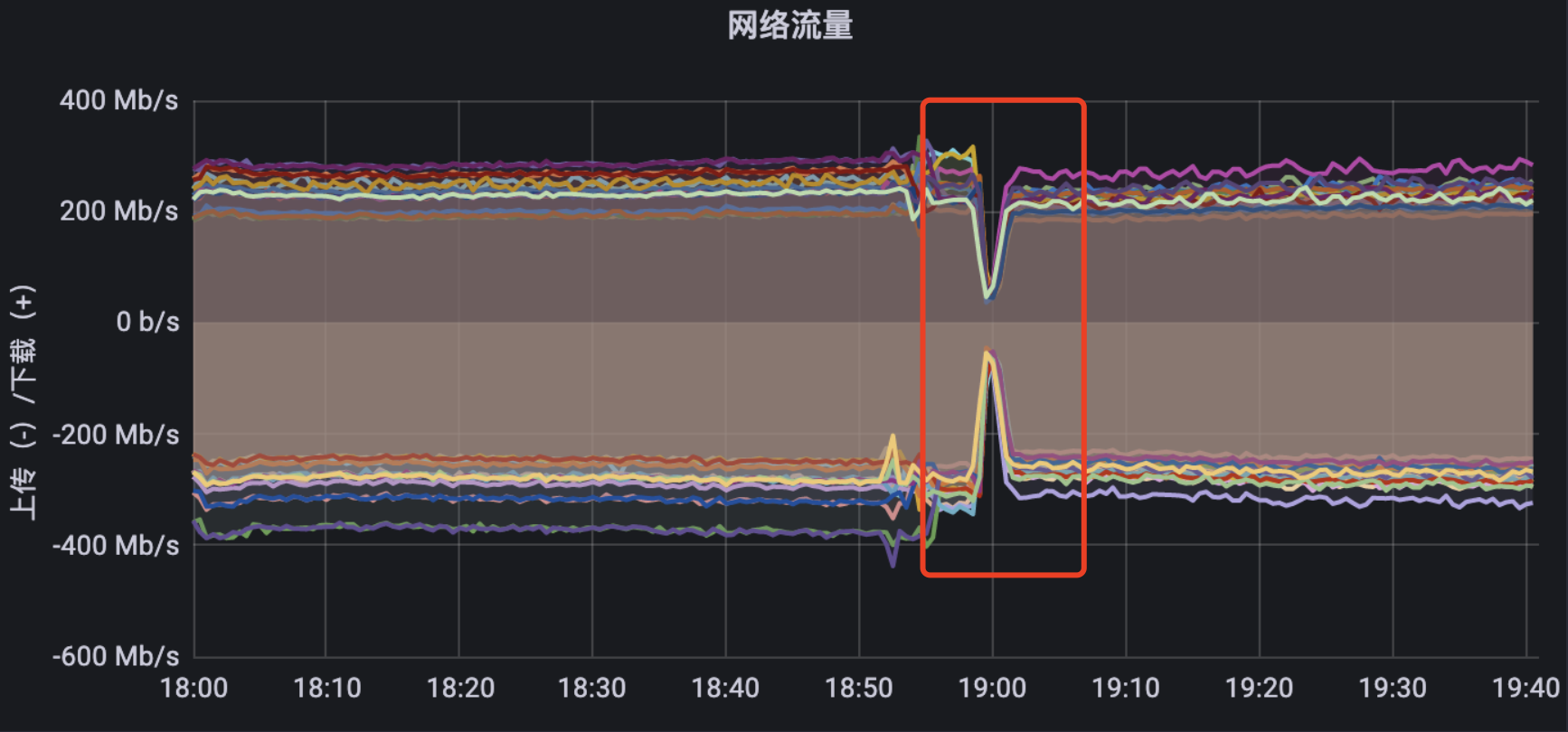
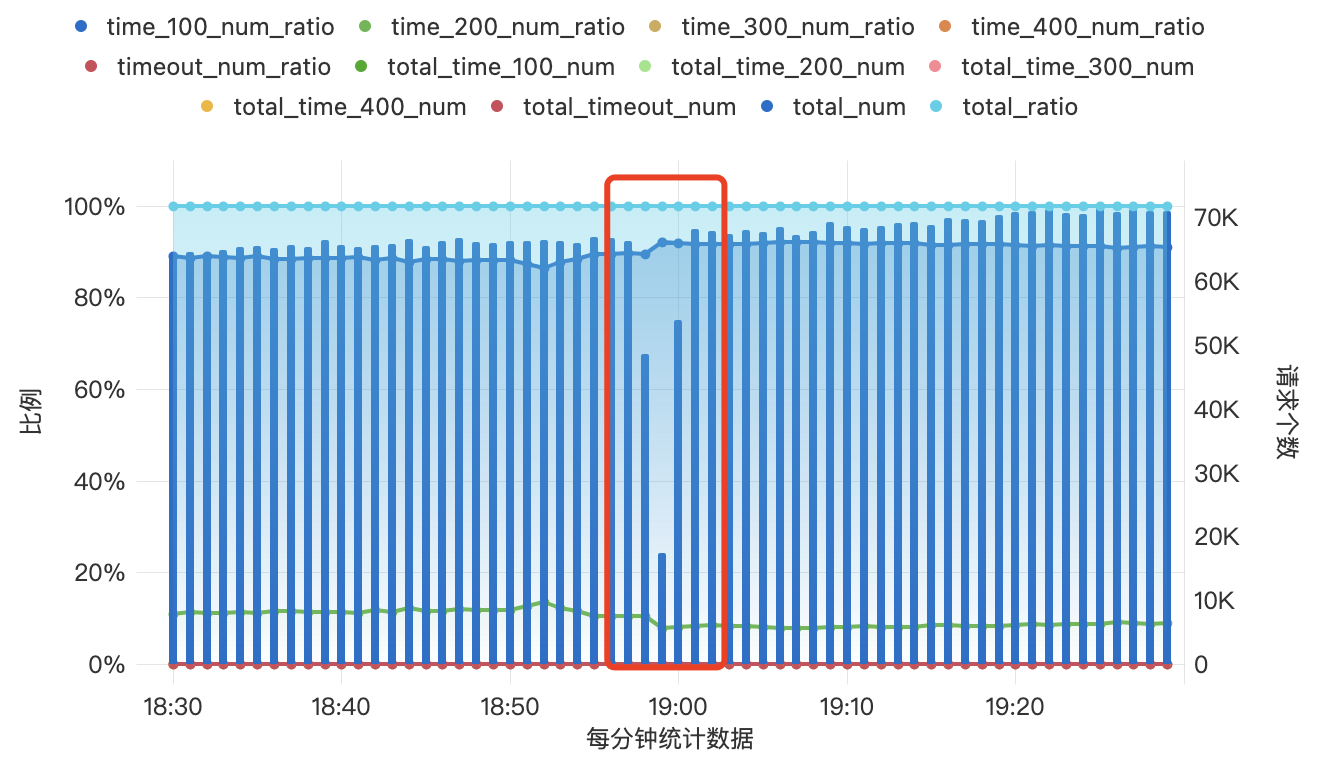
参数调整后
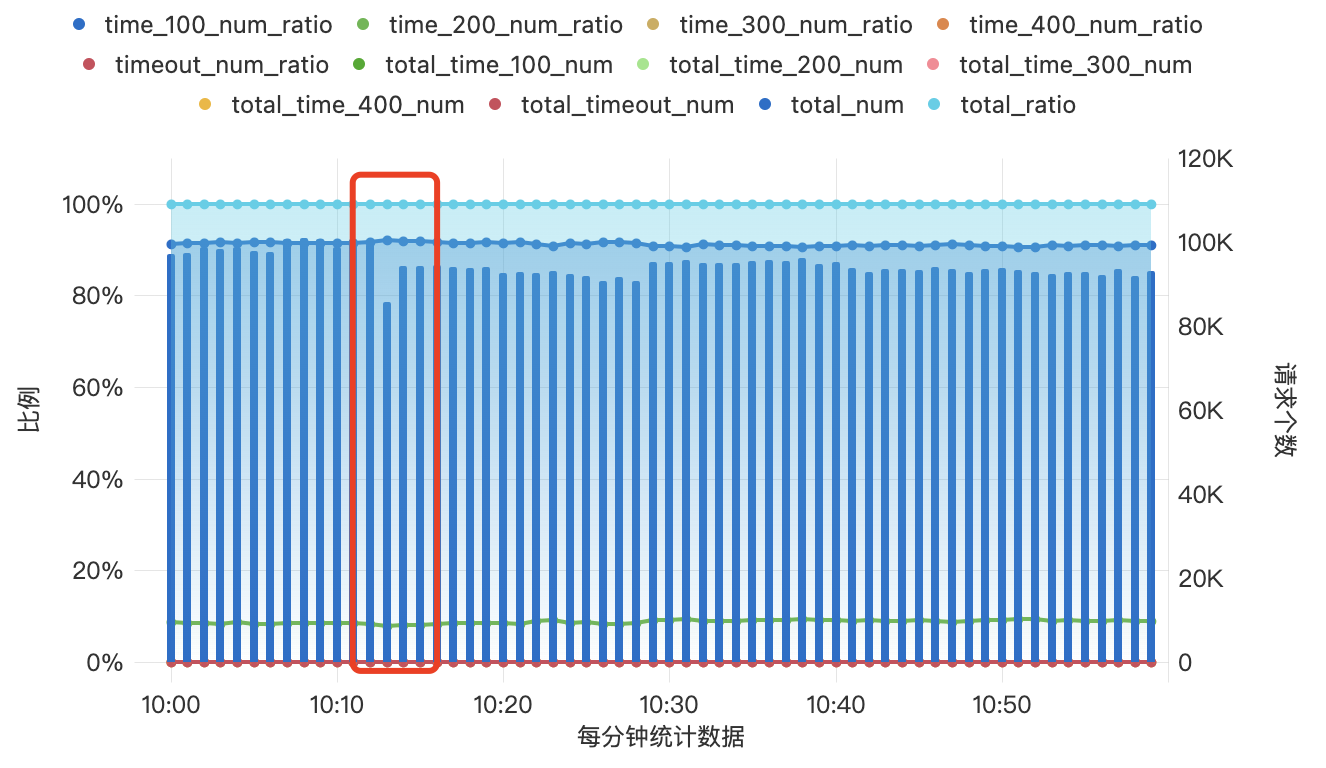
且线上未再产生超时告警.服务端同学这下就快乐了,服务端快乐,引擎端也快乐了,引擎端快乐,领导也快乐了,领导快乐,我就快乐(手动狗头)
滚动部署不再影响外部的请求响应,至此问题得到有效解决
而实验进行到这里,每日凌晨流量会有一分钟骤降的原因似乎也能找到了,因为从综合的数据来看,它跟每次发版时候的表现确实很像,怀疑可能是阿里的SLB每日定时重置导致的.果然,翌日之后,每日凌晨的流量问题也不再出现了
结论
gateway通过阿里的SLB接收外部请求,然后根据其自身的负载均衡策略进行请求的转发处理,每次滚动部署时由于未及时触发SLB的endpoints列表更新,导致新的请求一直阻塞或超时的情况出现,进而引发熔断报警以及服务不可用等问题。
我们无法控制SLB的网络策略,但是可以通过周期性ping的方式自我检测当前连接是否可用,从而及时止损,切换到其他可用的服务上去。
下面给出官方推荐的keepalive相关配置实例:
一些建议
- 在client发起grpc请求时,最好是通过ctx的withTimeout传入一个有效的超时过期时间,虽然server端在处理请求时一般都会给自己设置一个超时取消,但有些情况是避免不了的。就像我们遇到的这个坑里,明明我们已经配置了400ms超时,但是服务端还是会触发超时的告警,究其原因发现是请求卡在了tcp的阶段,一直在试图与server端建立连接,且没有超时退出的策略,故而导致请求一直阻塞。
- 建议所有客户端和服务端都添加下keeepalive的探测参数配置,默认的配置是2小时ping一次,这个时间对敏捷迭代的开发来说是有点长的
- preStop时间要根据实际情况来设置,不能太短,也不能太长,整体要以项目实际出发,一切脱离了项目实际的操作都是耍流氓