在2014年软件工程基础(FSE)大会上发表的一篇学术论文“A Large Scale Study of Programming Languages and Code Quality in Github”声称,函数式编程范式具有更低的代码错误率等四个结论。
编程语言对软件质量有什么影响?这个问题长期以来一直是人们争论的话题。在这项研究中,我们从 GitHub 收集了一个非常大的数据集(729 个项目、8000 万个 SLOC、29,000 位作者、150 万次提交、17 种语言),试图为这个问题提供一些实证依据。
Go 支持一等函数、高阶函数、用户定义的函数类型、函数文字、闭包和多个返回值。 这些丰富的功能正好支持一门强类型语言编写出函数式编程风格的代码。
一、什么是函数式编程
“函数式编程是一种编程范式,它将计算视为数学函数的评估,并避免状态和可变数据”。其有几个特点:
- 函数是“一等公民”,和其他数据类型一样,函数可以作为参数,返回值;
- 编写无“副作用”的函数,函数保持独立,不修改外部变量的值,这类成为
纯函数; - 使用不可变量;
- 柯里化;
- 惰性求值。
虽然 Go 不是天生的函数式编程语言,但我们可以做些尝试并以从中收益!
二、能解决什么问题?
先让我们回想一下,写过的“Bug”中或多或少出现过以下几种情况?
- 复杂的函数中一个变量被中间函数“篡改”,导致下游的错误调用
- 指针类型未进行必要的 nil 判断,导致 panic
2.1 使用纯函数避免“篡改”
纯函数是指函数的输出只由输入决定,没有任何副作用的函数。也就是说,纯函数不会改变任何外部的状态,也不会引起系统的任何变化。
爱因斯坦“可能”说过:“疯狂就是一遍又一遍地做同样的事情,却期待不同的结果。”
我们的目标是尽量使用纯函数来组合构建程序,使得程序更加可靠的,可维护和可复用。
一个栗子:
业务中经常会有类似下面的代码循环处理数据,这没什么问题,如果没有约定,在 doSomeThing(*Policy) 函数中,很可能把policy给修改掉。
var policyList []*Policy = GetListFromDb()
for _, policy := range policyList {
doSomeThing(policy)
}所以,我们约定可以适当减少指针的使用,或者避免在函数中直接对指针进行修改。
比如:商业化在DDD战术落地时的分层架构中,经常使用 Assembler(Factory) 来对 DTO、实体、持久化对象的相互转换,我们就约定这些通常都使用纯函数进行编写。
func AssemblePolicy(rep PolicyDTO) Policy {
return Policy{
}
}测试友好
既然函数有相同的就有相同的输出,那么单元测试编写起来是极轻松的,配合 Github Copilot,甚至可以自动生成单测。如果不是纯函数,单测就很难写,比如函数内有一个当前时间 time.Now(),第一时间就要想到提纯,把时间当做一个变量传入。
可复用
Assembler 处理单条数据和处理多条数据,以下是个简单示例:
policyList := lo.Map(policyDTOList, AssemblePolicy)项目业务中,经常使用 Map Reduce Filter 来处理数据,数据量虽然不像大数据那般多,但是业务场景也不少,比如商业化广告配置中就有大量策略,需要进行批量处理,过滤等操作。
但 Go 标准库并不支持 Map/Reduce,全世界范围内,有大量程序员都在问Go语音官网什么时候在标准库支持 Map/Reduce,Github issue 中也是大量的提案(proposal)。
幸运的是开源社区编写了大量的经过测试的库,其中 https://github.com/samber/lo,提供了 map/reduce/filter 等大量的工具,这个包在商业化服务端的代码中随处可见。
代码清晰
由于纯函数的特性,我们可以无需关注这些隐藏细节实现,在我们的“人脑编译器”看代码时,更高效。
通常来说,建立不可变量(Immutable) 才能真正意义上的避免被篡改,但Go未提供相应的库,可以参考社区实现,但通常会增加额外的CPU和内存,需要评估。 benbjohnson/immutable: Immutable collections for Go (github.com)
2.2 指针类型未进行必要的 nil 判断,导致panic
代码设计中,我们通常会用指针表示某个可能为空的字段,但往往忘记对该字段进行 nil 判断。比如:
type PolicySetting struct{
Name string
}
type Policy struct {
PolicySetting *PolicySetting
}
func XX() {
var policy Policy
// 编译不报错,运行时报错
if policy.PolicySetting.Name == "" {
}
}而在标准的函数式编程语言里,不存在类 nil 的值,而使用 Option 这个结构来表示可选值。我们借鉴过来设计一个 Option 类型。直接访问 Option 类型则编译报错。
type Option[T any] struct {
isPresent bool
value T
}
func (o Option[T]) OrEmpty() T {
return o.value
}现在我们把指针类型改为 Option,避免了经常出现的遗漏nil检查,编译和运行时都是安全的。
type Policy struct {
PolicySetting Option[PolicySetting]
}
func XX() {
var policy Policy
// policy.PolicySetting.Name 直接访问编译不通过
if policy.PolicySetting.OrEmpty().Name == "" {
}
}
不过,强大的 Goland IDE 是可以提示哪些 nil 未做判断,也可以辅助我们降低此类错误。设置如下图:
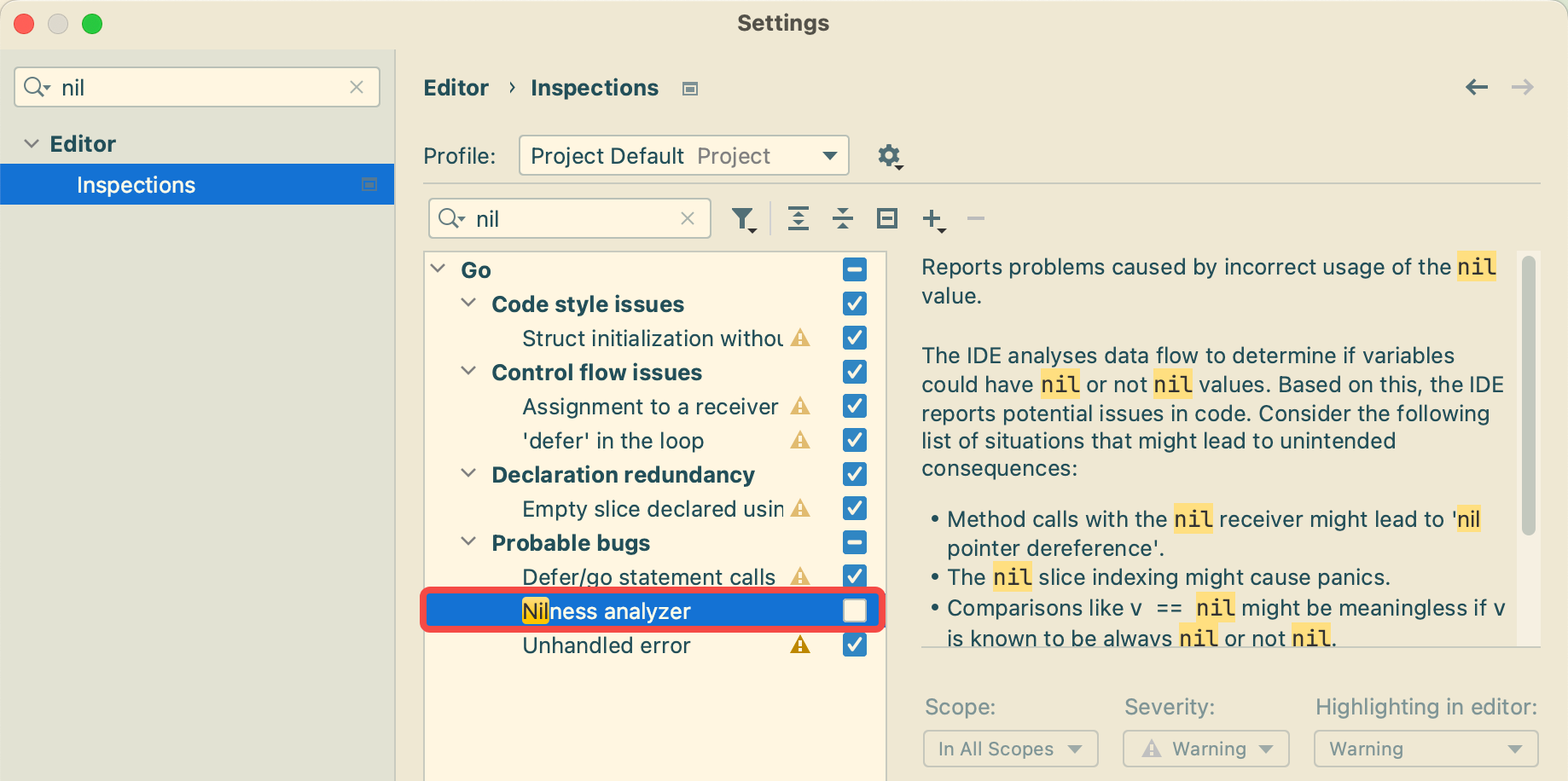
三、新的灵感
函数式编程除了能够规避一些问题,还能在代码设计上给我们提供思路。商业化广告运营总是有大量策略,每种策略有相同的基础数据结构,和较大差异的核心数据结构。
我们通常定义一个接口,再定其他 struct 隐式实现这个接口。示例:
type PolicySetting interface{
IsPolicySetting(int64) bool
}
type Policy struct{
Name string
Type int8
Setting PolicySetting
}
type PolicyForceStay struct{
FSField1 string
}
type PolicySplash struct{
SField1 string
}开发通常不会有什么问题,但代码中将会出现大量类型断言,虽然不用担心性能问题,看着确实很别扭。另外,一个接口有较多的实现,会影响我们查阅代码和排查问题的效率。
3.1 Either
这个时候就可以借用函数式编程中 Either。
type Either[T1 any, T2 any] struct {
argId int8
arg1 T1
arg2 T2
}
func (e Either[T1, T2]) ForEach(arg1Cb func(T1), arg2Cb func(T2)) {
switch e.argId {
case either3ArgId1:
arg1Cb(e.arg1)
case either3ArgId2:
arg2Cb(e.arg2)
}
}
type Policy struct{
Name string
Type int8
Setting Either[PolicyForceStay, PolicySplash]
}意思是 Policy.Setting 可能是 PolicyForceStay,也可能是 PolicySplash。当我们需要针对不同的类型做不同的处理,只需将不同的处理逻辑写在一个闭包传入 ForEach 执行即可。
Policy.Setting.Foreach(
func(p PolicyForceStay){
doSth()
},
func(p PolicyForceStay){
doSth2()
},
)我们可能会说这和 switch case 也没有差别,并且编写这些类型及其扩展函数会额外的代码和工作量,幸运的是这些通用类型均有社区支持 https://github.com/samber/mo
3.2 柯里化
柯里化是把接受多参数的函数变换成接受一个单一参数的函数,并且返回接受余下的参数而且返回结果的新函数的技术。这听起来有点别扭,看个示例:
foo1 := func(a int, b int) int {
return a*a + b*b
}
fmt.Println(foo1(2, 4))
fmt.Println(foo1(2, 8))
fmt.Println(foo1(2, 16))上面的示例,一个函数接受2个参数,并计算值。我们使用柯里化将上述代码转变成为如下接受单个函数,并返回一个单个参数的函数。
foo2 := func(a int) func(int) int {
aSquare := a * a
return func(b int) int {
aSquareCopy := aSquare
return aSquareCopy + b*b
}
}
foo2A2 := foo2(2)
fmt.Println(foo2A2(4))
fmt.Println(foo2A2(8))
fmt.Println(foo2A2(16))如上案例我们可以看到,实现了部分求值,foo2A2 函数如需多次执行,执行效率是有提升的。
数学家戈特洛布·弗雷格:为单一参数情况提供解决方案已经足够了,因为可以将具有多个参数的函数转换为一个单参数的函数链。
这种转变,就是“柯里化”,一般支持高阶函数的语言都支持柯里化。
3.3 惰性求值
如果说纯函数和 samber/lo 等库,已经打开一扇窗,惰性求值这个特性则顺带把门也打开了。惰性求职一般也称为延迟求值。在使用延迟求值的时候,表达式并不是在它被绑定到变量之后就立即求值,而是在该值被取用的时候求值。
var actions []string
in := seq.SliceOfArgs("hello", "my", "friend")
// 1. 过滤掉不包含 "e" 的元素,不会立即求值
filtered := in.Where(func(s string) bool {
actions = append(actions, "filter("+s+")")
return strings.Contains(s, "e")
})
// 2. 返回长度,不会立即求值
mapped := seq.MappingOf[string, int](filtered, func(s string) int {
actions = append(actions, "map("+s+")")
return len(s)
})
// 3. ForEach 求值
mapped.ForEach(func(i int) {
actions = append(actions, fmt.Sprintf("foreach(%v)", i))
})
// 打印执行的顺序
fmt.Printf("%v\n", actions)
// 输出
// [
// filter(hello) map(hello) foreach(5)
// filter(my)
// filter(friend) map(friend) foreach(6)
// ]
// 4. ToSlice 求值
result := mapped.ToSlice()
fmt.Printf("%v\n", result)
// 输出
// [5 6]有了这个特性,在处理复杂数据时,可以通过条件,避免一些计算,某些情况不需要返回结果时,甚至可以避免最终计算。这和 ORM 构造条件查询数据库的逻辑非常相似,只有最终明确查询动作时才去计算。
以上描述的这些特质在其他专门的函数式编程语言可以很容易获得,比如 Rust、Haskell。借助于 k8s 的 sidecar 模式,异构服务可以很容易部署,感兴趣的小伙伴可以多试试完全版函数式编程编程语言,了解和使用其带来的性能和内存安全的提升。
四、附录

图2:某些语言比其他语言产生的缺陷更少。
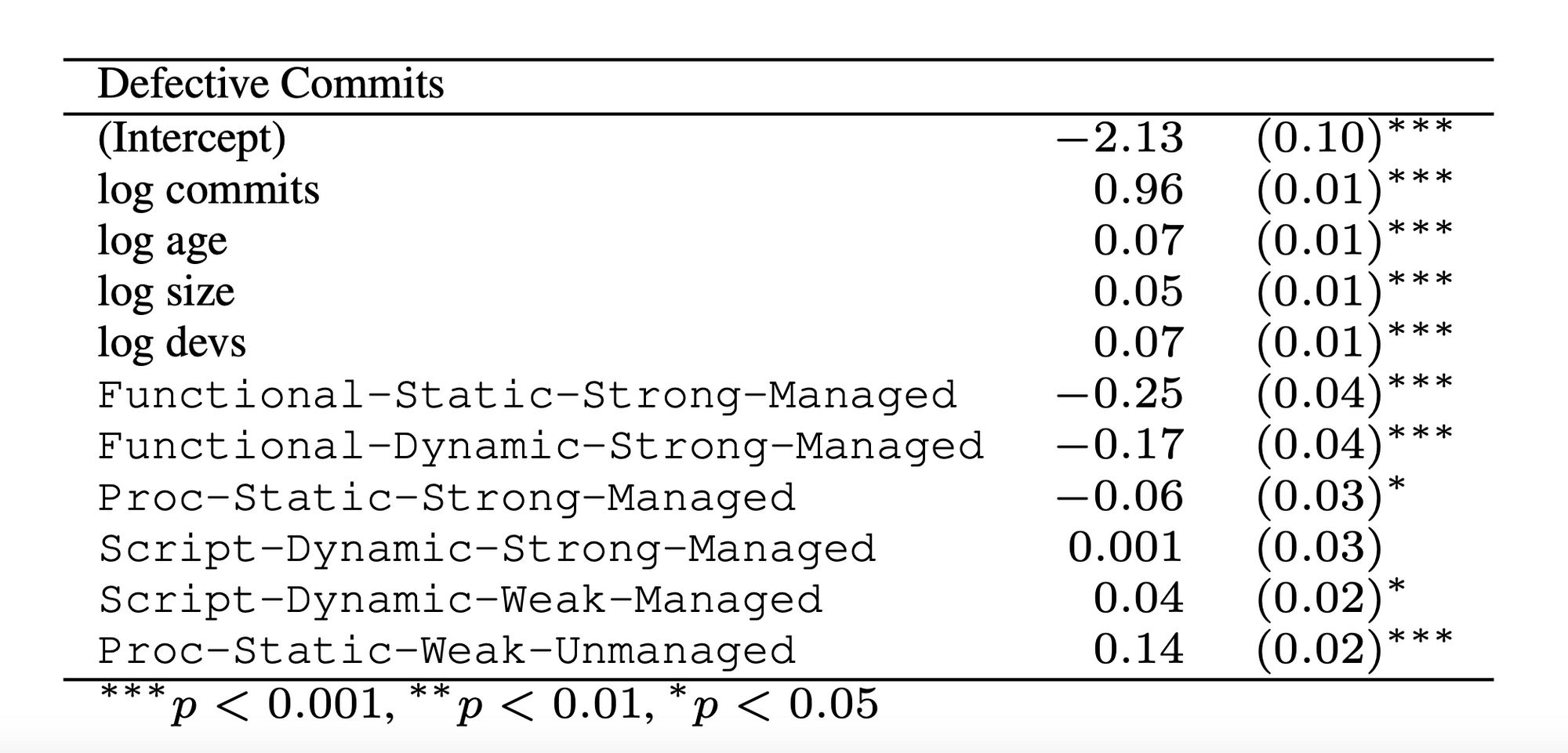
图3:函数式语言与缺陷的关系较小。