《命令行中的数据科学》是一本讲解如何使用命令行高效进行数据处理和分析的书。其作者在书中指出,尽管数据科学家拥有海量激动人心的技术和编程语言可供选择,如 Python、R、Hadoop、Julia、Pig、Hive、Spark 等等,但命令行工具因其灵活性、可增强性、可扩展性、可扩充性及易得性等诸多特点,许多问题使用命令行工具往往更加简单高效。
本文结合笔者在实际工作中的经历,通过三个案例介绍如何在实际工作中使用命令行工具进行数据处理。
案例一:群发短信
需求说明
根据运营同事提供的手机号信息和短信文案,分批次在同一时间段内按照对应关系群发短信。群发短信的接口每次只允许发送 500 个手机号码,为了尽可能快的将短信发出去,我们需要对这些手机号码进行处理。
原始数据格式
以两个文案为例,其中文案一:“请点击链接 https://xx.com/a 领取奖励!回T退订”,文案二:“请点击链接 https://xx.com/b 领取奖励!回T退订”,并给到 Excel 文件 phones.xlsx,文件中的 a 标签页中有 40000 个手机号,b 标签页中有 60000 个手机号,分别需要发送文案一和文案二。
约束条件
提供的短信发送工具为命令行工具(send),可通过参数 --input-file 指定手机号码列表文件,通过参数 --msg 传入发送的文案内容。
处理过程
数据预处理 原始数据往往不是我们期望的格式,预处理数据就是把数据转化成我们需要的格式。因为命令行无法直接操作 Excel 文件,我们要将手机号码信息从 Excel 文件中提取出来。csvkit 套件是一个非常强大的 CSV 命令行处理工具,使用 Python 实现,大家可以通过其官方文档进行了解学习:csvkit.readthedocs.io。我们使用 csvkit 套件中的 in2csv 命令将手机号码从 Excel 文件提取到 CSV 文件中:

经过这一步处理,我们就得到了文案一对应的手机号码的文件 a.csv 和文案二对应的手机号码的文件 b.csv。
数据处理 本案例的数据处理非常简单,我们只需要将手机号码按照 500 条一份的方式切割即可,使用以下命令进行数据切割:

切割之后,我们在 a 和 b 文件夹中得到了文件名为如下所示的数据文件,如下所示:

完整的数据处理脚本(clean.sh)如下所示:

数据使用 经过上述的数据处理,我们就可以发送短信了,我们得到了 200 份数据文件,手动一个个的发送是太过低效和繁琐,我们将使用神器 parallel 来进行批量操作。关于 parallel 的使用方法可以参考下文给出的参考资料,批量发送短信的脚本(send.sh)如下:

小结
经过上面一系列的处理,我们就完成了整个短信群发过程,使用经过预处理之后的数据,整个短信发送过程大概只需要几秒钟,简单且高效。上述的流程可以作为模版,每次发送不同短信文案和手机号时,只需要做简单调整即可。
案例二:广告点位信息统计
需求说明
一个广告点位的质量,可以通过这个广告点位带来的用户数及这些用户的次留情况进行判断,综合处理这些数据之后,我们就可以针对这些广告点位制定更加弹性的出价策略。本案例中,我们需要依据运营给到数据对广告点位的次留率进行计算。
原始数据格式
汇总周期内数据到一份 Excel 表中(名称为 info.xlsx),标签页名称 site_info,包含四列数据:点位 ID(site_id)、账号(account)、用户数(user_count)和次留数(retention_count),其中一个点位与账号是一对多的关系。
运营策略
基于点位 ID 对数据进行聚合,计算点位 ID 的次留率,且只计算点位 ID 对应用户总数大于给定值 X 的次留率,保留小数点 4 位。
处理过程
数据预处理 本案例中,数据以 Excel 表格格式给到,我们首先需要将其转化成更具可读性的 CSV 格式。我们依然使用 csvkit 套件处理,不过,在使用 csvkit 进行处理之前,我们还需要进行一个额外处理,对 Excel 中表头名称进行重命名(将列名由中文转换为英文),因为 csvkit 在中文处理上的能力少有欠缺,这一步需要打开 Excel 文件进行手动处理。手动处理好之后,我们就可以使用以下命令将 Excel 数据转化为 CSV 格式数据了:

接下来还需要对脏数据进行过滤,比如,对点位 ID 缺失的数据进行过滤,处理这种数据有很多方法,如使用 grep 对特殊文本进行过滤等。这里我们使用 csvkit 提供的查询方法进行过滤。所谓 csvkit 的查询语句,就是将 CSV 数据看作据库中的数据,使用 SQL (基于 sqlite3)进行数据查询。本案例中,我们的脏数据主要是点位 ID 为空或者为默认值(__DEFAULT_SITE_ID__)的数据,我们使用一下命令进行过滤:

经过上述步骤,我们就得到了我们想要的数据格式了,预处理后数据大概长这样:

数据处理 接下来进行数据处理,首先要做的是根据 site_id 进行数据聚合,同样使用 csvsql 命令进行操作:

total.csv 格式如下:

然后,根据另外一条业务规则对数据进行筛选,计算点位 ID 对应用户总数大于给定值 X(此处 X 以 80 为例) 的数据,再次使用 csvsql 进行处理:

result.csv 格式如下:

到这里,我们就基本将数据处理完毕了。不过,我们还有最后一个工作要做:数据展示。
数据展示 目前我们已经得到了一份 CSV 结果文件,可以直接发送给可爱的运营小姐姐了,但是这份数据还需要导入到配置系统中,我们得配置系统并可不认什么 CSV 文件,它有自己的格式要求,它想要一份 YAML 格式得数据,所以,我们还要对数据进行一次转化。
首先,创建一个 retention_rate.yaml 文件,并写入初始数据:

然后将 result.csv 中的点位次留率数按照指定格式写入 retention_rate.yaml 中:

至此,大功告成!
下面是完整得脚本(retention_rate.sh)。
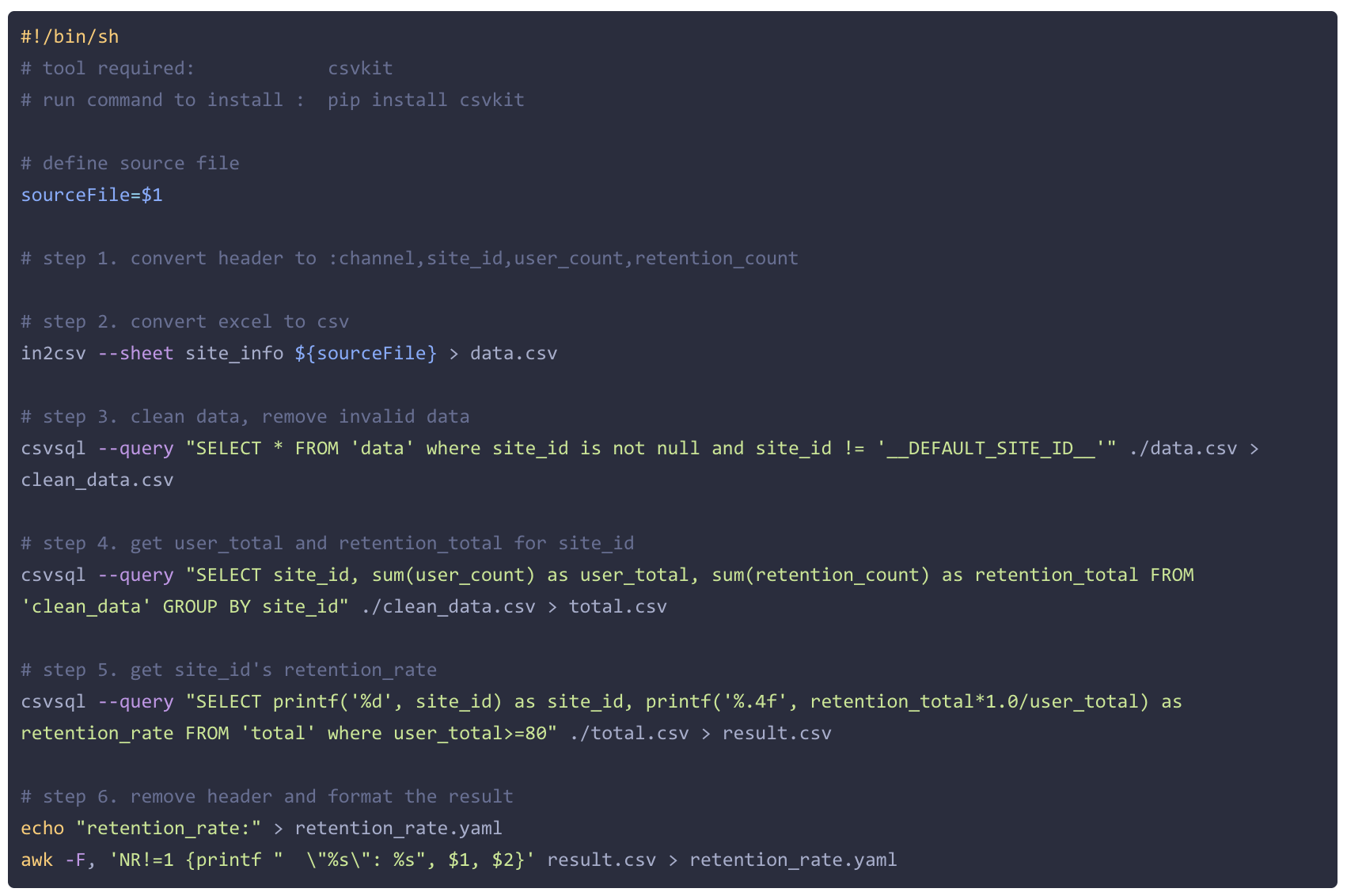
小结
有了这个脚本之后,每次只需要在拿到原始数据之后,将 Excel 文件中 info 表中的表头转化为英文之后,运行这个脚本,等待十几秒钟,就可以得到我们想要的结果,就是如此的简单高效。
案例三:批量数据查询
需求背景
为验证业务 A 中数据计算的逻辑正确性,需要对该业务入库数据(存储在 Clickhouse 中)进行人工分析。该业务数据量大概在每日 100 亿数据左右,无法且没必要进行全量的数据分析,我们使用抽样数据进行验证。怎样抽取数据?这依赖于另一项业务 B 的数据,两个业务的数据可通过某惟一 ID (unid)进行关联,在业务 B 中出现的数据,在业务 A 中必定能够找到,且某些字段的值必须存在且正确,所以先从 B 业务进行数据抽样,然后去匹配 A 业务的数据。
原始数据格式
抽样后的数据通过 CSV 格式(data.csv)给到,数据 100000 条,只有一个 unid 字段。
处理过程
数据预处理。我们需要的是从 Clickhouse 查询 100000 条数据,根据数据量,使用批量查询比较合理,但一次性查 100000 条数据,Clickhouse 无法支撑,经过实验,每批次查 2000 条数据比较合适。所以我们需要将数据进行切割,命令如下:

这样我们就在 data 目录下得到了 50 个数据文件。接下来我们需要构造查询 SQL 脚本。我们使用 Python 来生成 SQL 脚本并使用 Python 直接运行,脚本(run.py)如下:

运行:

脚本运行完之后,我们就得到了 50 个查询结果,我们将这些数据汇总到一个文件里面:

此后,便可以使用 csvkit 套件根据业务要求进行数据分析了。
小结
命令行工具能够很好的将 SQL、Python 和 R 等脚本串联起来,形成一个完整的工作流程,避免了在多个 GUI 工具中频繁地进行切换。通过简单的几行命令,我们就能快速的处理数据,而且能够重复多次运行,可以节约大量时间。
总结
本文通过三个例子简单介绍了如何在实际工作中使用命令行进行数据处理,希望能起到抛砖引玉的作用。《命令行中的数据科学》一书介绍了更多高效且实用的命令行工具,如用于解析 JSON 文件强大的 jq,JSON 与 CSV 转换工具 json2csv,以及更多 csvkit 套件中的命令,还有一整套数据科学分析的方法: OSEMN 模型,即(Obtain, Scrub, Explore, Model, and iNterpret)。该书的原著是一本开源书,目前第二版正在编写中,有感兴趣的小伙伴可以找来阅读一番,相信一定会有很多收获。