前言:
历时两个多月时间,广告ADX系统从立项、需求分析、设计方案、成本估算、开发对接再到不断优化升级。目前接口已经升级到第三版了,系统已经能够稳定的承受最高11.5万的QPS。当然,这还仅仅只是个开始。接下来就让我来写一点系统开发过程中的一些设计思路和问题排错的过程,希望对大家有所启发。
什么是广告ADX系统?
ADX(Ad Exchange) 指的是广告交易平台。简单理解,就是实时请求多家广告平台,根据平台实时出价,将出价最高平台的广告,在七猫app进行展示。
ADX系统的场景特点是什么?
- 海量的请求:接入N家平台,就要实时并发N家请求。假设全量一家平台请求目标50亿,那一天就要进行N*50亿的请求。
- 实时比价:因为每次都是平台的实时比价,所以无法利用缓存。
- 超时控制:不能无限等到所有平台都返回广告后再去比价,需要设置一个统一的超时时间。(就好像地铁,每次到站后按固定的时间发车)
- 海量的数据存储:涉及到和各家平台最终对账,所以请求、返回、比价、曝光、点击等该有的数据,都得记录,一点也不能少。
- 服务器的压力:超大的数据处理,对于服务器,流量带宽都是巨大的挑战。
v0.1版本的设计方案
了解了ADX系统的场景特点,我们就对系统设计进行了如下考虑:
- 通过设置http请求的timeout(设置超时时间为500ms),来控制多家平台的并发请求时间。
- 通过waitgroup来合并处理接到各家平台的返回值并进行比价处理。
- 通过提取公用字段,将不同平台的信息合并在一个events对象中(包含各平台的名称,出价等信息),统一发送一条上报请求给大数据,由大数据来进行拆分入库。(这样各类型的上报给大数据的都只要一次上报,避免了后续接入新平台就多一批上报的情况)
v0.1版本的接口,虽然进行了压测,但是只接入了一家平台,很多问题都没有暴露出来。当接入5家新平台后,很多并发问题也都接踵而来。
颠覆性的v0.2版本应运而生
一家平台的并发和多家平台的并发,程序的表现完全是不一样的。当同时接入多家平台后,就有很多新的问题暴露出来。下面我们来看看v0.1版本发现了哪些问题,v0.2版本中我们又是如何来进行问题排查和优化的。
问题1:观察下图可以发现,p99最高的达到9秒多,超时控制未生效。

已经设置了http的timeout,为什么还会有超时的情况呢?
通过在各个可能耗时的代码段前后加上了时间打印。日志分析后,我们发现仅仅设置http.Client.Timeout,并不能控制完整请求的超时时间。下面的这张图就能解释timeout并没有那么简单。
http.Client Timeouts:

http.Server Timeouts:

既然超时还有很多设置,那么我们就尝试加更多的超时设置:
client := &http.Client{
Timeout: 1000 * time.Millisecond,
Transport: &http.Transport{
Proxy: nil,
DialContext: (&net.Dialer{
Timeout: 1 * time.Second,
}).DialContext,
TLSHandshakeTimeout: time.Second,
ResponseHeaderTimeout: time.Second,
ExpectContinueTimeout: time.Second,
},
}修改后观察发现超时时间,确实在指定的时间返回了,但是整体的请求还是偏长。
问题2:为什么请求时间没问题,但是整体请求还有偏长的情况呢?
我们继续打印时间,分析日志发现,有一个流程是合作方竞败上报,仅仅只是异步发送请求,但是耗时就用了3秒多的时间。看来,高并发的情况下,不能轻视任何http请求,哪怕只是一个简单的上报。
发现了问题,那解决就容易多了。我们把需要上报的地址先异步写入kafka。再另起一个消费者来消费,并进行数据上报。在消费者中,我们就不用关心请求时间的长短了。
这样,广告的流程终于能及时返回,没有需要占用额外时间的请求情况了。
通过一段时间观察请求数据,我们发现大部分请求时间正常,但在高峰期还是有小部分请求时间超过5秒的情况。
问题3:肯定哪里还是有问题?
通过分析请求连接数,我们发现time_wait的数量较多,这种情况一般发生在长链接没有复用。
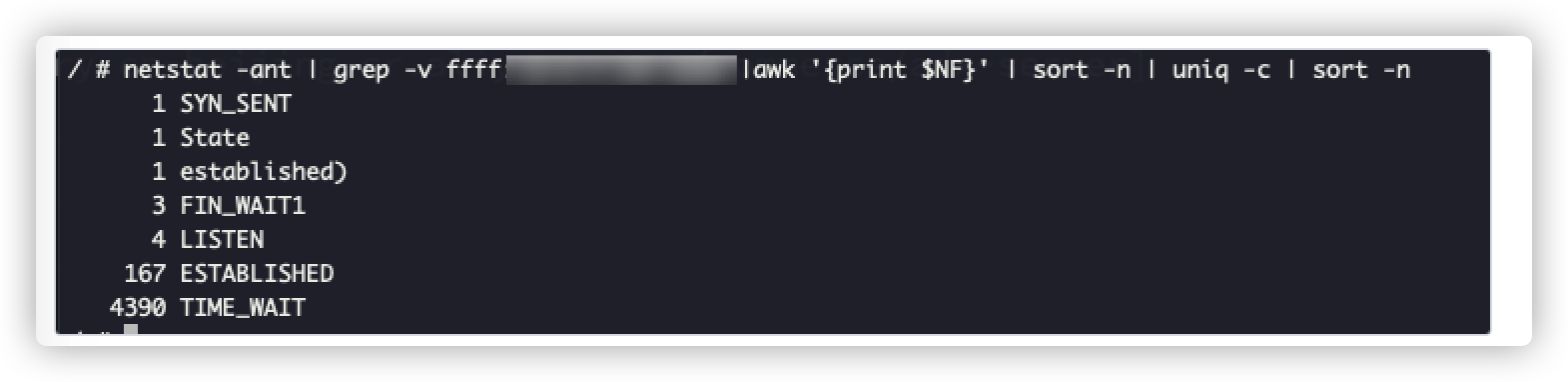
通过分析代码,我们发现问题的根源不在于超时时间的设置,在于长链接没有有效的复用。于是,我们就做了如下改动:
func NewHttpClient() (http.Client, error) {
t := http.DefaultTransport.(*http.Transport).Clone()
t.MaxIdleConns = 500 //所有host的连接池最大连接数量,默认无穷大
t.MaxIdleConnsPerHost = 20 //每个host的连接池最大空闲连接数,默认2
client := http.Client{
Timeout: 1500 * time.Millisecond,
Transport: t,
}
return client, nil
}改完后,我们再来观察time_wait的情况:
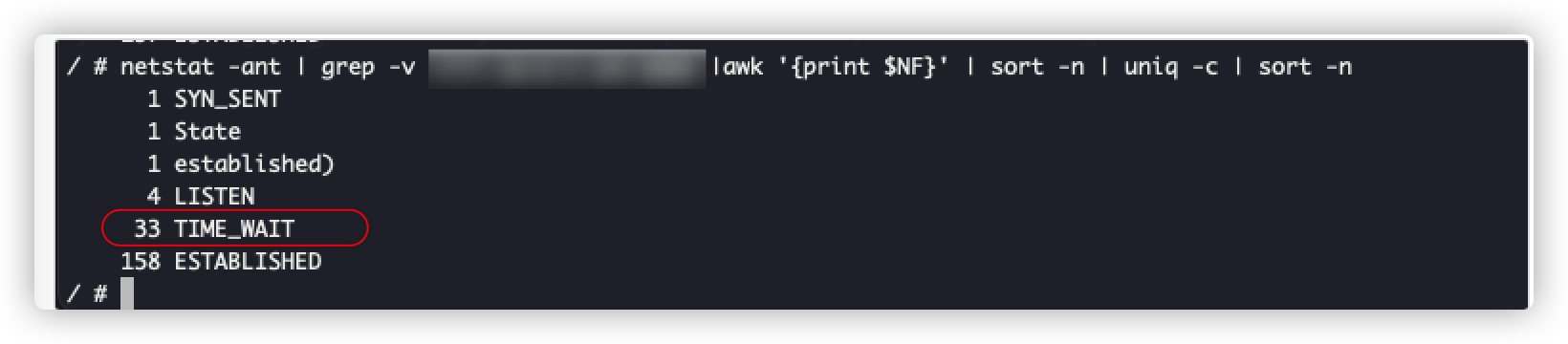
可以发现,修改后time_wait数量明显降低了很多。再来看看请求的具体情况,可以发现通过设置连接池,我们的请求超时情况就得到了极大的改善,如下图:
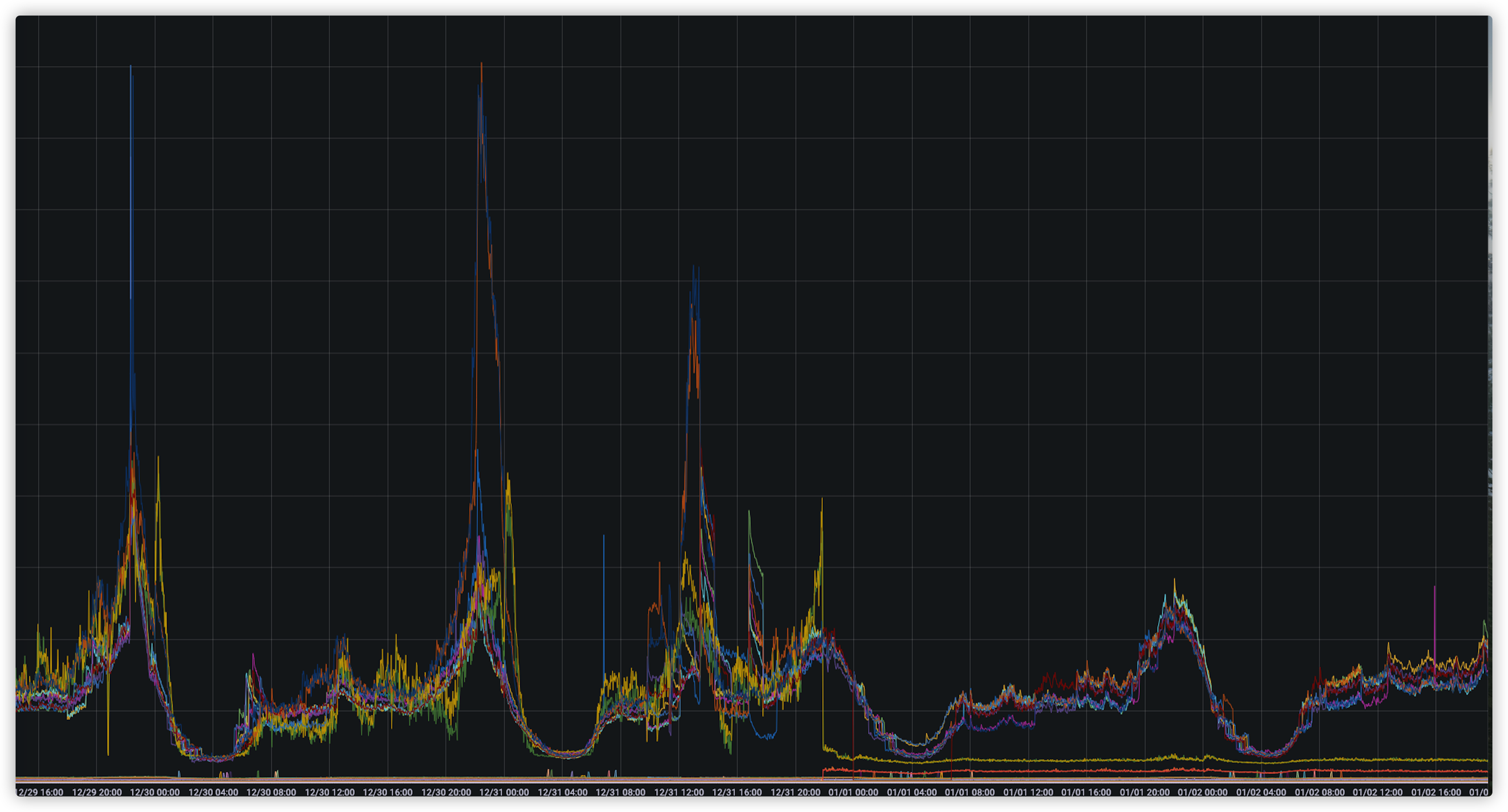
p99时间控制在了2.5秒的时间,当然,这还是因为部分合作方平台接口返回时间偏长,我们设置了3秒超时的缘故。至此,请求超时问题解决完毕。
http请求的问题解决完毕,我们又发现一个很奇怪的数据gap问题。客户端在广告曝光后,需要给大数据drs和合作方平台同时上报曝光统计。但是我们统计的数据比所有的合作方平台少了5%。既然是手机app同时上报,应该可以排除网络等特殊情况。而且我们比每家平台都少,排除了合作方平台出问题的可能性。
问题4:为什么简单的数据上报入库,我们这边会少数据呢?
数据上报问题,我们有两个排查方向。一个是数据处理过程到落库有没有报错,一个是服务器是否接收到请求。
先排查数据处理流程,因为没有特殊逻辑,从数据解析到落库,我们发现一共只有100多条的数据报错。那么问题就不在处理落库这边。再让运维查了下服务器接收到的总请求数,发现和落库的数据是吻合的,基本没有数据gap问题。那就很奇怪了,那5%的数据gap是怎么产生的呢?
会不会是阿里云ECS长链接的关系?当我们尝试的把阿里云ECS改为短链接后,第二天数据gap就明显下降了,第三天就几乎没有数据gap问题了。看来在并发请求量巨大的情况下,阿里云的ECS使用长链接会导致数据丢失问题。具体的原因是客户端在网络不稳定的情况下,使用长链接可能会导致发送请求失败。而短链接是每次发送都需要建立新的链接。相对而言,客户端网络不可控,需要频繁的发送请求的情况,使用短链接会更合适。
解决完了数据问题,我们终于可以来对项目做一些优化了。巨大的请求量带来的最直接的问题是成本问题。除了服务器的成本必不可少外,流量的成本是我们重点关注的点。但是一共就两个请求,一个是请求合作方平台,获取素材并比价获取出价最高的平台返回给客户端。一个是客户端瀑布流比价,告诉服务端比价结果并展示广告。还能怎么来节省流量的开销呢?我们的答案是方法永远比困难多。
且看v0.3版本如何实现节省流量的目的
在对接优量汇的过程中,我们发现优量汇一开始就返回价格和素材id。当优量汇最终竞胜的时候,客户端需要拿着素材id请求优量汇sdk获取最终素材。虽然请求比其他平台多了一次,但是他们的流量消耗比其他家少了10多倍。通过不断的和产品研究讨论,我们得到了一个可行的方案。
- 第一步客户端请求ADX获取最高出价的价格,将素材根据请求id缓存。
- 第二步客户端处再次比价,如果ADX胜出后,再次请求ADX获取素材。
这样就避免了原先第一步就返回素材,最后竞败没有展示的流量带宽浪费情况。预计这样修改后,可以极大的节省流量的成本。
当然,这样还不是最终的方案,后续我们还会推进合作方修改请求返回流程。在我们这最终获胜后,才返回给我们素材。等到那时就可以把请求时的带宽也降到最低。避免了无效的请求流量浪费,通过节省ADX的成本来提高收益。
成本节省了,代码质量也得跟上。最后来看看我们在代码上都做了哪些优化。
- 替换代码中的硬编码(将switch...case修改为合作方封装为独立的类,设计模式的合理运用)
- 合作方使用接口统一(通过接口封装共有方法。创建不同的类调用公有方法,减少代码的维护成本)
- 处理数据上报消费者(通过消费者来实现数据的异步处理。提高了主进程的效率)
- 加入熔断限流机制(避免了合作方出现异常情况下的无效请求)
- 优化了依赖注入的方式
- 其余很多细节的改动在此就不多赘述了,具体代码比较敏感,在此也就不展示了
至此,ADX系统就完成了从0到0.3的进化之路。
总结:
最后,让我们来对项目的历程做个回顾总结。
1、http.timeout并不完全是整个连接的超时控制。
2、不要小看简单的http请求,处理不好就会影响接口返回速度。
3、如果确定程序没问题,可以检查下服务器配置。
4、流量很贵,流量很贵,流量很贵。最容易被我们忽略,值得我们斤斤计较。
5、多看服务器监控情况,可以帮我们发现一些不易发现的问题。