前言
随着市场推广业务发展,为了更精准地投放,我们需要更多的报表字段进行分析。目前报表数据有以下特点:
- 单个报表字段多(目前付费渠道趋势分析数据表字段多达180+)
- 数据量大(渠道数据表单日数据量有300w+)
- 数据来源分散,数据产出时间分散(渠道数据来源包括大数据离线聚合表、媒体离线数据报表、市场业务逻辑相关中间表例如回传数据表等)
由此引来以下问题:
- 查询效率越来越低
- 更新字段困难
为了解决以上问题,在【Clickhouse实现主键(排序键)更新】一文中已经提出一种针对于Clickhouse的字段更新方式,有效解决了Clickhouse更新瓶颈的问题,然而在单表字段特别多,查询带有聚合、列间计算操作等场景下,查询效率仍然很低。因此本文主要分享一种利用Clickhouse预聚合方式,来提高查询效率。
什么是物化视图
我们都知道,视图是从一个或者多个基本表(或视图)导出的表(虚拟表),实质上是将底层结构隐藏封装起来,
使得我们只需要专注于上层的查询,简化了我们的查询条件,但数据仍然是从基础表中查询,并不会提高任何查询效率。
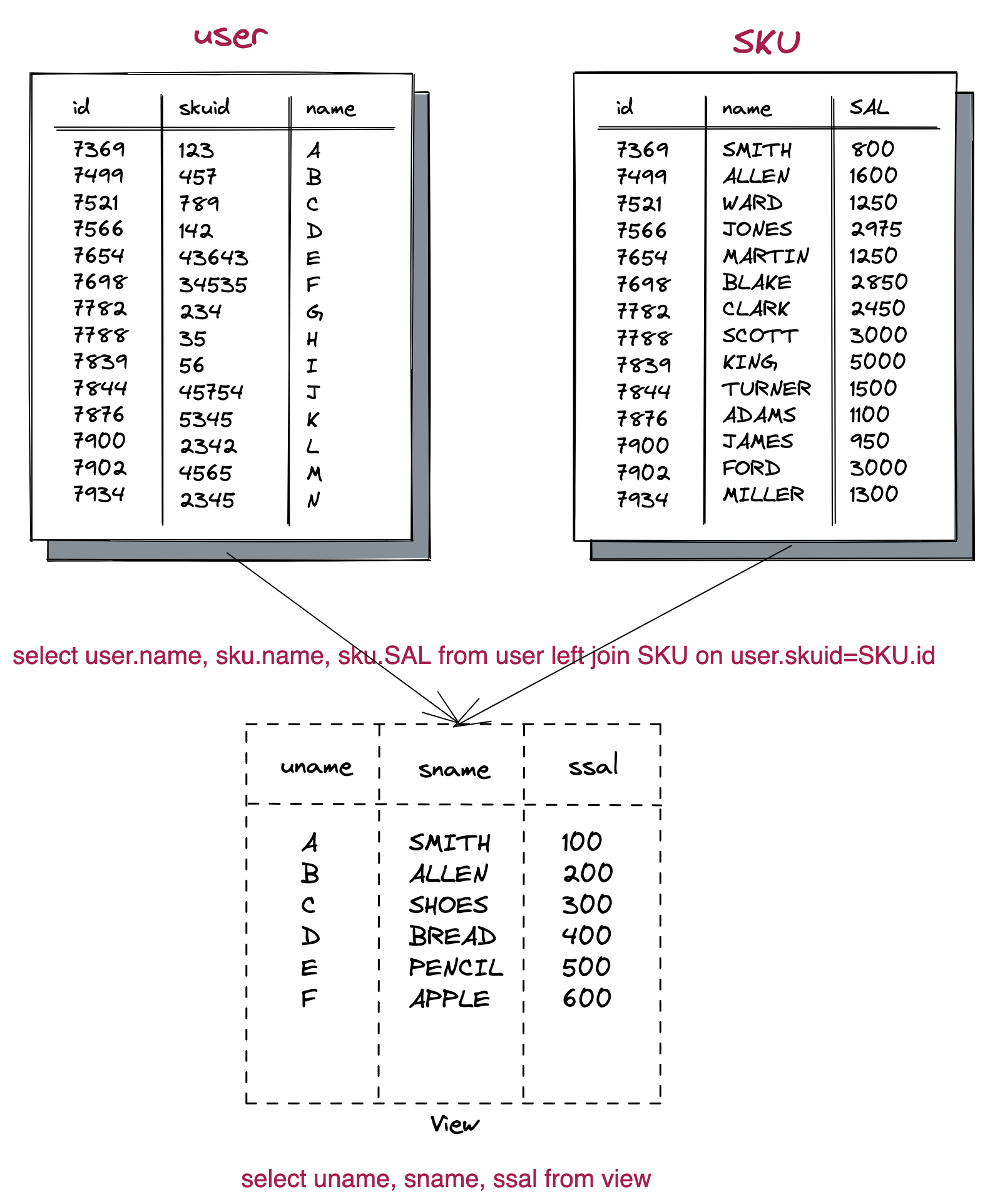
而物化视图是将上述的虚拟表变成一个真实的表,将多个表的数据通过预设的条件提前存储到这张表中,从而达到一个预聚合的目的。这个时候我们查询的数据就来源于预聚合好的表。
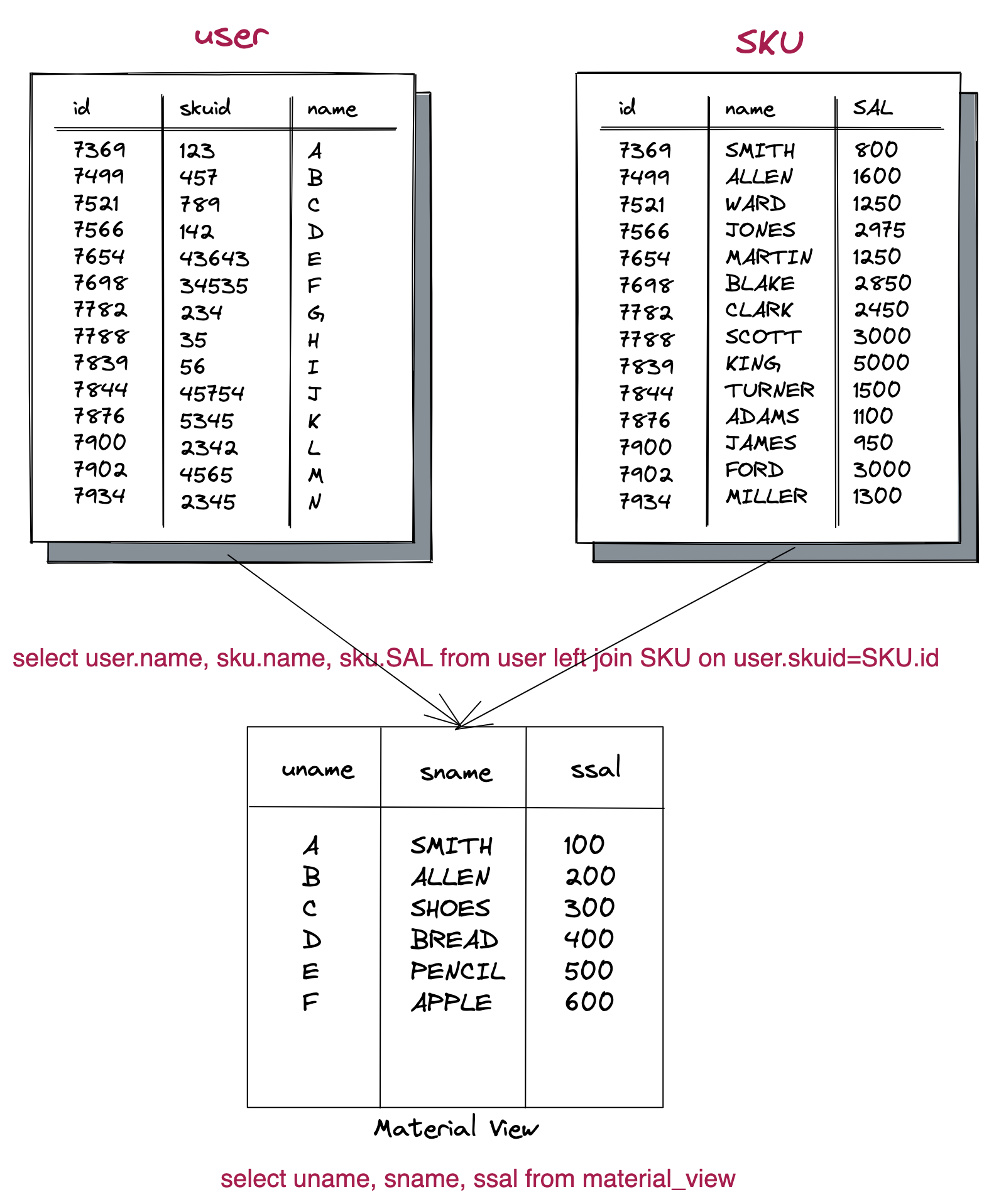
因此物化视图能通过预聚合的方式提高查询效率。
Clickhouse物化视图主要的优缺点
优点:
查询效率高
缺点:
1.牺牲空间换取时间
2.使用难度较大,需要合理设计表结构对历史数据做聚合分析
3.消耗更多机器资源
4.仅支持插入触发(严格来说不算缺点,因为Clickhouse本身不建议更新删除操作)
案例
场景
存储渠道维度下90天的累计充值用户数和累计充值金额(单表180个字段),每天更新一次有充值的渠道数据。
两种方案
1.【Clickhouse实现主键(排序键)更新】方案中提到的 AggregatingMergeTree+SimpleAggregateFunction+Nullable
这种方案已经顺利的帮我们解决了数据的更新问题,建表语句如下:
CREATE TABLE xx.trend_data
(
`date` String COMMENT '用户激活当天的渠道',
`channel_name` String COMMENT '渠道名',
`type` Int8 COMMENT '属性类型: 1.不含vip,2.含vip',
`book_id` SimpleAggregateFunction(anyLast, Nullable(Int64)) COMMENT '书籍ID',
`charge_fee_day1` SimpleAggregateFunction(anyLast, Nullable(Float64)) COMMENT '充值day1',
`charge_fee_day2` SimpleAggregateFunction(anyLast, Nullable(Float64)) COMMENT '充值day2',
......
`charge_fee_day89` SimpleAggregateFunction(anyLast, Nullable(Float64)) COMMENT '充值day89',
`charge_fee_day90` SimpleAggregateFunction(anyLast, Nullable(Float64)) COMMENT '充值day90',
`charge_users_day1` SimpleAggregateFunction(anyLast, Nullable(Float64)) COMMENT '充值用户day1',
`charge_users_day2` SimpleAggregateFunction(anyLast, Nullable(Float64)) COMMENT '充值用户day2',
......
`charge_users_day89` SimpleAggregateFunction(anyLast, Nullable(Float64)) COMMENT '充值用户day89',
`charge_users_day90` SimpleAggregateFunction(anyLast, Nullable(Float64)) COMMENT '充值用户day90',
`ver` SimpleAggregateFunction(max, DateTime64(3)) DEFAULT now() COMMENT '版本',
`after_discount` SimpleAggregateFunction(anyLast, Nullable(Float64)) COMMENT '推广费'
)
ENGINE = AggregatingMergeTree() PARTITION BY date ORDER BY (date, type, channel_name) SETTINGS index_granularity = 8192
表里每日插入产生的充值数据,我们如果要取出1~90天累计的充值数据,那么需要列与列之间相加才能得到每天的累计数据,幸运的是Clickhouse提供了这样的查询机制,这样我们就能顺利取出180个累计字段。
select charge_fee_day1 as ac_charge_fee_day1, ac_charge_fee_day1 + charge_fee_day2 as ac_charge_fee_day2, ...
from xx.trend_data
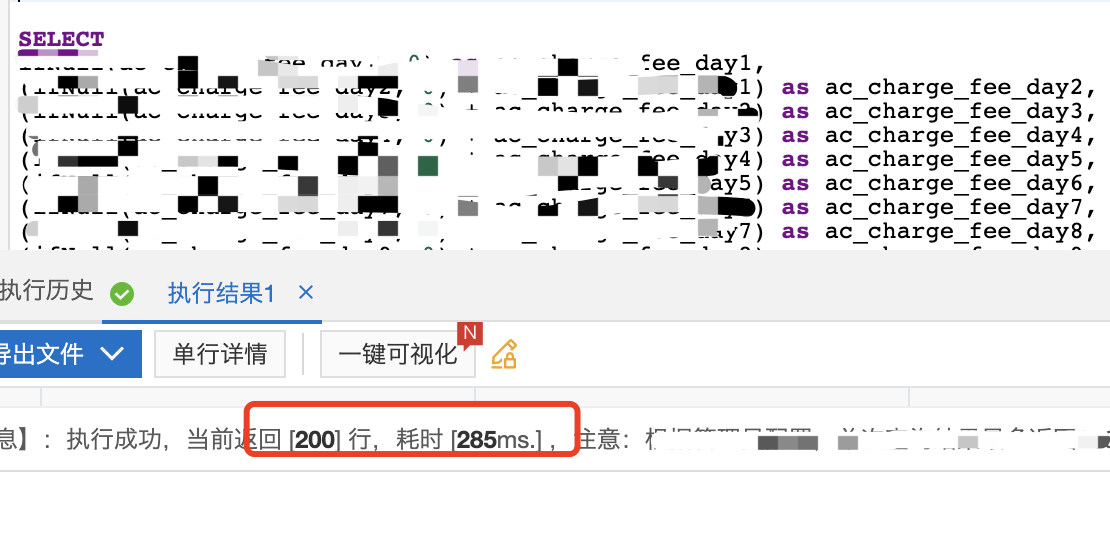
现在我们用线上数据以上述查询方式查200条数据,90个字段,看一下结果,耗时在300ms左右,显然这个结果是不那么令人满意的。
我们继续调研一下,如果不需要字段之间累加,按照下面查询方式直接取出每一列字段的数据,性能是否会好一些。
select ac_charge_fee_day1, ac_charge_fee_day2, ...
from xx.trend_data
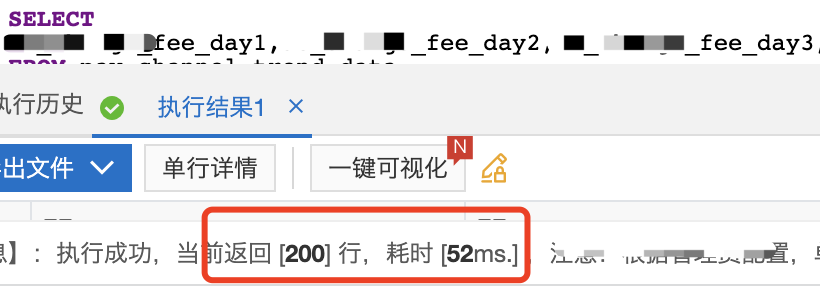
通过比对可以看出,即使Clickhouse支持select的字段之间的计算,但开销还是非常大的,因此我们需要尽可能找到一种开销小的查询方式。
我们可以通过将需要的累计字段预聚合提高查询效率,请看方案2。
2. Materialized View + AggregatingMergeTree,实现预聚合+更新
核心思想
- 我们建一张数据记录表,用于记录每日新增的充值数据;
- 建一张中间表,通过触发器从横向维度计算每日新增充值字段的累计值;
- 最后建一个聚合表,通过触发器从纵向维度聚合充值字段所有天数的累计值。
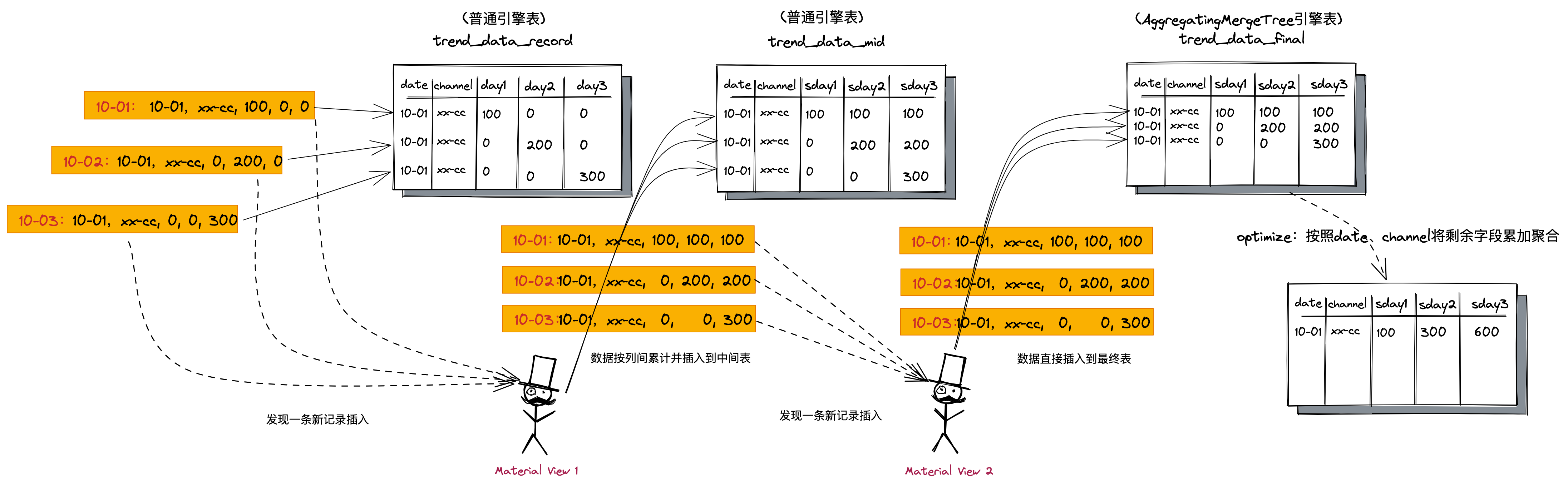
具体实现
首先建一个张记录表,用于插入每日的充值数据,用普通的存储引擎即可。
CREATE TABLE xx.trend_data_record
(
`date` String COMMENT '用户激活当天的渠道',
`channel_name` String COMMENT '渠道名',
`type` Int8 COMMENT '属性类型: 1.不含vip,2.含vip',
`book_id` Int64 COMMENT '书籍ID',
`after_discount` Float64 COMMENT '推广费',
`charge_fee_day1` Float64 COMMENT '充值day1',
`charge_fee_day2` Float64 COMMENT '充值day2',
......
`charge_fee_day89` Float64 COMMENT '充值day89',
`charge_fee_day90` Float64 COMMENT '充值day90',
`charge_users_day1` Float64 COMMENT '充值用户day1',
`charge_users_day2` Float64 COMMENT '充值用户day2',
......
`charge_users_day89` Float64 COMMENT '充值用户day89',
`charge_users_day90` Float64 COMMENT '充值用户day90'
)
ENGINE = MergeTree() PARTITION BY date ORDER BY (date, type, channel_name) SETTINGS index_granularity = 8192
接下来建一个物化视图监听 trend_data_record,做第一次横向预聚合,并将聚合结果导入到trend_data_mid,这样每一条充值数据进入到
trend_data_record时,都会通过物化视图聚合出这条数据的每日累计数据。
CREATE TABLE `xxx`.`trend_data_mid`
(
`date` String COMMENT '用户激活当天的渠道',
`channel_name` String COMMENT '渠道名',
`type` Int8 COMMENT '属性类型: 1.不含vip,2.含vip',
`book_id` Int64 COMMENT '书籍ID',
`after_discount` Float64 COMMENT '推广费',
`ac_charge_fee_day1` Float64 COMMENT '累计充值day1',
`ac_charge_fee_day2` Float64 COMMENT '累计充值day2',
...
`ac_charge_fee_day89` Float64 COMMENT '累计充值day89',
`ac_charge_fee_day90` Float64 COMMENT '累计充值day90',
`ac_charge_users_day1` Float64 COMMENT '累计充值用户day1',
`ac_charge_users_day2` Float64 COMMENT '累计充值用户day2',
...
`ac_charge_users_day89` Float64 COMMENT '累计充值用户day89',
`ac_charge_users_day90` Float64 COMMENT '累计充值用户day90'
)
ENGINE = MergeTree() PARTITION BY date ORDER BY (date, type, channel_name) SETTINGS index_granularity = 8192;
-- 通过物化视图将数据从记录表拿出,并计算今日累计字段的累计值,最后输出到中间表
CREATE MATERIALIZED VIEW xxx.trend_data_mv1
to `xxx`.`trend_data_mid`
AS
SELECT date,
channel_name,
type,
book_id,
after_discount,
ifNull(ac_charge_fee_day1, 0) as ac_charge_fee_day1,
(ifNull(ac_charge_fee_day2, 0) + ac_charge_fee_day1) as ac_charge_fee_day2,
(ifNull(ac_charge_fee_day3, 0) + ac_charge_fee_day2) as ac_charge_fee_day3,
...
FROM `xxx`.`trend_data_record`
最后再建一个物化视图监听 trend_data_mid,将数据直接插入到最终结果表trend_data_final,
AggregatingMergeTree引擎的 SimpleAggregateFunction(sum, Nullable(Float64)) 会自动帮我们按照排序键将数据汇总。
CREATE TABLE `xxx`.`trend_data_final`
(
`date` String COMMENT '用户激活当天的渠道',
`channel_name` String COMMENT '渠道名',
`type` Int8 COMMENT '属性类型: 1.不含vip,2.含vip',
`book_id` SimpleAggregateFunction(max, Nullable(Int64)) COMMENT '书籍ID',
`after_discount` SimpleAggregateFunction(max, Nullable(Float64)) COMMENT '推广费',
`ac_charge_fee_day1` SimpleAggregateFunction(sum, Nullable(Float64)) COMMENT '累计充值day1',
`ac_charge_fee_day2` SimpleAggregateFunction(sum, Nullable(Float64)) COMMENT '累计充值day2',
...
`ac_charge_fee_day89` SimpleAggregateFunction(sum, Nullable(Float64)) COMMENT '累计充值day89',
`ac_charge_fee_day90` SimpleAggregateFunction(sum, Nullable(Float64)) COMMENT '累计充值day90',
`ac_charge_users_day1` SimpleAggregateFunction(sum, Nullable(Float64)) COMMENT '累计充值用户day1',
`ac_charge_users_day2` SimpleAggregateFunction(sum, Nullable(Float64)) COMMENT '累计充值用户day2',
...
`ac_charge_users_day89` SimpleAggregateFunction(sum, Nullable(Float64)) COMMENT '累计充值用户day89',
`ac_charge_users_day90` SimpleAggregateFunction(sum, Nullable(Float64)) COMMENT '累计充值用户day90'
)
ENGINE = AggregatingMergeTree() PARTITION BY date ORDER BY (date, type, channel_name) SETTINGS index_granularity = 8192;
CREATE MATERIALIZED VIEW xxx.trend_data_mv2
to xxx.trend_data_final
AS
SELECT date,
type,
channel_name,
book_id,
after_discount,
ac_charge_fee_day1,
ac_charge_fee_day2,
ac_charge_fee_day3
FROM `xxx`.`trend_data_mid`
到这就结束了吗?no no no!我们还需要执行optimize触发数据合并,这样用户最终查到的数据才是正确的数据。
optimize table xxx.trend_data_final partition '2022-01-01' final
到此我们就可以把查询方法从方案一中的
select charge_fee_day1 as ac_charge_fee_day1, ac_charge_fee_day1 + charge_fee_day2 as ac_charge_fee_day2, ...
优化成
select ac_charge_fee_day1, ac_charge_fee_day2, ...
结论
通过物化视图+AggregatingMergeTree引擎,以空间换取时间的方式,可以显著提高数据库的查询效率。
ps: 我们常用的mysql这样的关系型数据库没有提供物化视图,但我们可以通过触发器自己实现一个物化视图,感兴趣的话可以自己研究或者以后业务上用到我们会再详细介绍。
参考文档
https://clickhouse.com/docs/en/sql-reference/data-types/simpleaggregatefunction
https://clickhouse.com/docs/en/sql-reference/statements/create/view/#materialized-view
https://tech.qimao.com/clickhouseshi-xian-shu-ju-de-you-xian-geng-xin/