背景
公司某项目为了精细化运营及提升运营日常数据分析效率,需要给数据做更精细的标注。首先运营会给渠道打上各种标签,标签由运营自定义,没有限制,例如:男频、都市、玄幻等。然后运营根据标签组合筛选某个周期内数据,大多数情况下,周期都会在1个月以内,我们单日数据50w左右,所以该功能需要支持2000w、数据的快速查询。综上所述,该功能主要具备以下特点
- 渠道标签多、标签丰富,条件组合多样化
- 数据量较大,单次查询数据量2000w
- 要求及时响应,过长的延时影响效率
- 标签更新及时
根据上述特点,mysql明显就不符合我们的需求了,因此我们探索了如何使用clickhouse bitmap实现该功能。以下是对实现过程以及性能测试的详细介绍。
核心逻辑
- 使用groupBitmapState函数生成bitmap
- 使用groupBitmapAndState/groupBitmapOrState查询标签交集、并集渠道ID(并集用And,交集用Or)
- 使用bitmapToArray将bitmap结果转为Array
- 使用arrayJoin将第3步的结果行转列
实现
数据库配置
阿里云s4规格单副本实例(4核16G)
表结构
首先我们创建一张渠道表做为基础表。并准备2000w的测试数据,id从0自增到2000w。
CREATE TABLE channel (
`id` UInt64,
`channel_name` String
) ENGINE = MergeTree() ORDER BY id SETTINGS index_granularity = 8192;
然后我们再创建一张渠道标签表,用与存放渠道标签数据。
CREATE TABLE channel_tag (
`tag_name` String,
`channel_id` UInt64
) ENGINE = MergeTree() PARTITION BY tag_name ORDER BY channel_id SETTINGS index_granularity = 8192;
然后为渠道分别打了五个标签用于测试,渠道标签数据总量3100w(搞笑100w+冒险200w+修仙300w+玄幻500w+男频1000w+女频1000w)。
| 标签 | 搞笑 | 冒险 | 修仙 | 玄幻 | 男频 | 女频 |
|---|---|---|---|---|---|---|
| 对应数据ID | id<=100w | id<=200w | id<=300w | id<=500w | id<=1000w | id >1000w |
准备好渠道以及渠道标签表后,我们还需要创建一张渠道标签bitmap表,用于存放渠道id bitmap。channel_ids使用AggregateFunction聚合函数,用于保证查询的实时性。
CREATE TABLE channel_tag_bitmap (
`tag_name` String,
`channel_ids` AggregateFunction(groupBitmap, UInt64) COMMENT '渠道ID'
) ENGINE = AggregatingMergeTree() PARTITION BY tag_name ORDER BY tag_name SETTINGS index_granularity = 8192;
现在渠道标签表、bitmap表都创建好了,生成bitmap数据则需要借助下面sql。(生成bitmap的两种方式:使用聚合函数groupBitmap构造、使用整形数组转换)。
INSERT INTO channel_tag_bitmap
SELECT
tag_name ,
groupBitmapState(channel_id) channel_ids
FROM channel_tag
GROUP BY tag_name;

我们一共拥有3100w的标签,生成bitmap仅需548ms,效率非常高。如果需要重新生成bitmap,只需重复执行上述sql即可。
如何查询
走到这一步基础数据都已经生成了,接下来要做的就是查询数据了。第一步我们要考虑的就是如何取bitmap的交集或者并集。这里需要使用groupBitmapAndState或者groupBitmapOrState函数(交集用And,并集用Or)。下面我们以取搞笑、冒险两个的交集做为示例
SELECT groupBitmapAndState(channel_ids) FROM channel_tag_bitmap WHERE tag_name in ('搞笑', '冒险')
上面SQL返回的是二进制数据乱码,并不能直接为我们所用,接下来我们需要使用bitmapToArray函数将二进制数据转换为数组
SELECT
bitmapToArray(
groupBitmapAndState(channel_ids)
)
FROM channel_tag_bitmap WHERE tag_name in ('搞笑', '冒险')
到这里数据库返回的内容我们已经能看懂了,为了能将id结果集做为子查询条件,我们还需要借助arrayJoin函数,将数据转换为行
SELECT
arrayJoin(
bitmapToArray(
groupBitmapAndState(channel_ids)
)
)
FROM channel_tag_bitmap WHERE tag_name in ('搞笑', '冒险')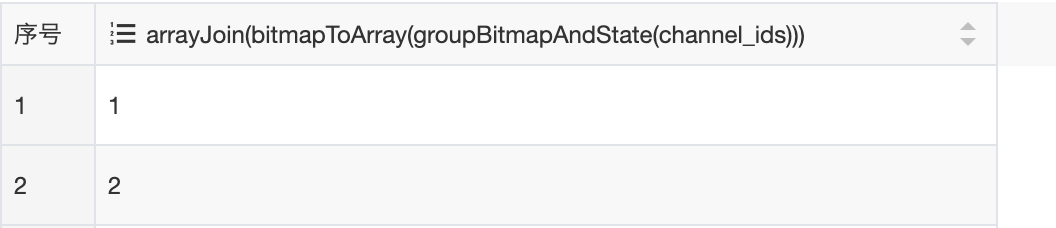
到这里我们的标签筛选工作就完成了,下面只需将上述结果带入查询即可(为了使sql看起来更清晰,我们使用WITH语法演示,效果与上述语句相同)
SELECT * FROM channel WHERE id IN (
WITH(
SELECT groupBitmapAndState(channel_ids) FROM channel_tag_bitmap WHERE tag_name in ('搞笑', '冒险')
) AS arr
SELECT arrayJoin(bitmapToArray(arr)) LIMIT 2000
)
性能测试
实验一:查询搞笑、冒险标签并集(300w标签并集,结果集:100w)。
SELECT * FROM channel WHERE id IN (
WITH(
SELECT groupBitmapAndState(channel_ids) FROM channel_tag_bitmap WHERE tag_name in ('搞笑', '冒险')
) AS arr
SELECT arrayJoin(bitmapToArray(arr)) LIMIT 2000
)
实验二:查询搞笑、冒险、修仙标签并集(600w标签并集,结果集:100w)。
SELECT * FROM channel WHERE id IN (
WITH(
SELECT groupBitmapAndState(channel_ids) FROM channel_tag_bitmap WHERE tag_name in ('搞笑', '冒险', '修仙')
) AS arr
SELECT arrayJoin(bitmapToArray(arr)) LIMIT 2000
)
实验三:查询搞笑、冒险、修仙标签并集(600w标签交集,结果集:600w)。
SELECT * FROM channel WHERE id IN (
WITH(
SELECT groupBitmapOrState(channel_ids) FROM channel_tag_bitmap WHERE tag_name in ('搞笑', '冒险', '修仙')
) AS arr
SELECT arrayJoin(bitmapToArray(arr)) LIMIT 2000
)
实验四:查询所有标签的并集(3100标签并集,结果集:0)。
SELECT * FROM channel WHERE id IN (
WITH(
SELECT groupBitmapAndState(channel_ids) FROM channel_tag_bitmap
) AS arr
SELECT arrayJoin(bitmapToArray(arr)) LIMIT 2000
)
实验五:查询所有标签的交集(3100w标签交集,结果集:3100w)。
SELECT * FROM channel WHERE id IN (
WITH(
SELECT groupBitmapOrState(channel_ids) FROM channel_tag_bitmap
) AS arr
SELECT arrayJoin(bitmapToArray(arr)) LIMIT 2000
)
结论
- 当前实例应对3000w量级的标签筛选完全没有压力。
- 查询速度与参与计算的标签量没有太大关系。实验一标签量300w、实验二标签量600w查询时间基本一致;实验四标签量3100w,执行时间比实验一、二还要快。
- 影响查询速度的是结果集的大小。实验二、实验三标签量相同,结果集不同,执行时间相差80%; 实验四、实验五标签量相同,结果集不同,执行时间更是天壤之别。