==============================================================================================================
1 背景信息
ClickHouse 是一款比较新型的列式分析型数据库。相比较传统的关系型数据库,ClickHouse能解决大数据量数据的查询场景。《ClickHouse在七猫业务中的应用和总结》一文站在开发人员的角度上,介绍了使用ClickHouse初期的应用过程和经验总结。
本文主要站在ClickHouse运维的角度上,结合业务实际运行中的具体场景,参考ClickHouse经典案例,总结故障实践经验,用于参考学习和对问题的分析。本文主要分三个模块对ClickHouse进行介绍:
1)ClickHouse在运维中的故障追踪。
2)ClickHouse在业务中的特性实践。
3)ClickHouse在学习中的基本操作。
==============================================================================================================
2 ClickHouse 故障追踪
2.1 ClickHouse Insert在批大小与并发数的抉择
ClickHouse 作为分析型数据库,主要功能是做数据分析使用。实际应用中我们常常需要将大批量的数据“快速”的写入ClickHouse的数据库存储中,“快速”的写入往往会给我们带来各种问题。
首先我们明确一个观念,分析型数据库对大批量执行单行insert操作通常是非常不友好的(1、ClickHouse因为单行插入会在操作系统层生成大量单个文件下,然后将大量文件夹进行合并操作,所以单行插入性能非常差;对比阿里云ADB分析型数据库,因为默认是全字段索引,单行插入,索引更新的成本太高,导致单行插入性能非常差),引出一个问题ClickHouse单行insert插入性能差,那么单个insert批量插入多大批次的时候性能达到最优(通俗的讲如何使用ClickHouse能满足我们业务的数据插入需求)。
实际生产过程中,没有人能明确的告诉你批次多大、并发多少的时候插入性能能到达最优,通常得到的信息是:“根据插入的‘字段大小’、‘类型’等实际场景来决定‘批大小’、‘并发量’ ”。我们通过案例来看看“批大小与并发如何进行抉择”。
案例1:
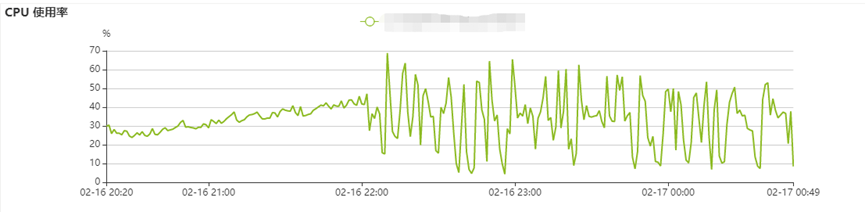
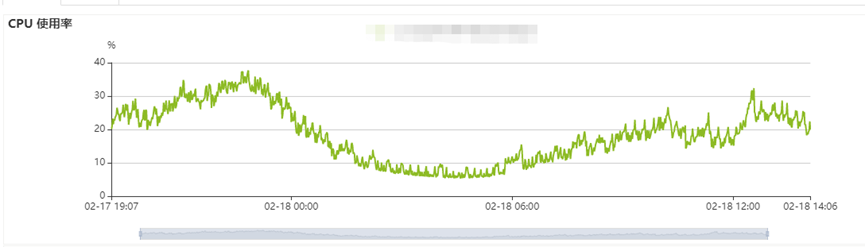
大数据部门通过脚本程序对kafka消息进行消费,按批次将数据写入到ClickHouse数据库,前期任务运行状态正常。突然一天早晨发现前一天数据库的CPU指标发生严重抖动,影响到运营同事前端查询。CPU抖动如下图:
>> 排查问题,先确定业务系统是否有过变化:
排查1:是否存在新增定时任务对当前实例查询导致CPU抖动--排除。
排查2:是否存在前端页面发起大量业务查询导致CPU抖动--排除。
排查3:是否存在数据插入量的变化:插入量存在激增--定位到可能原因。
排查完成后,确定消息数据有增量。正常思路分析,消息数据有增量(增量数据通常是缓慢增加),CPU资源使用率应该是逐步增加的,对比监控中CPU的指标“上下抖动”,明显有区别,可能是其他原因引起的。
>> 有了方向,验证问题定位是否准确:
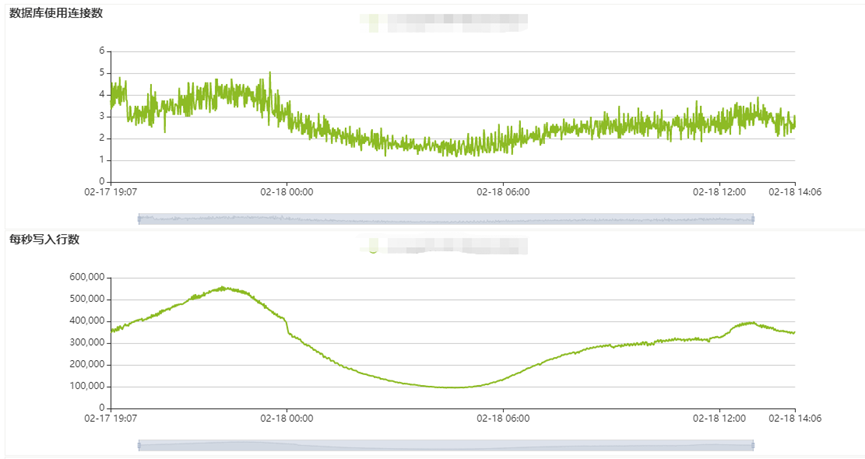
再次分析后发现程序连接数使用量和TPS均出现相同抖动,如下图所示:
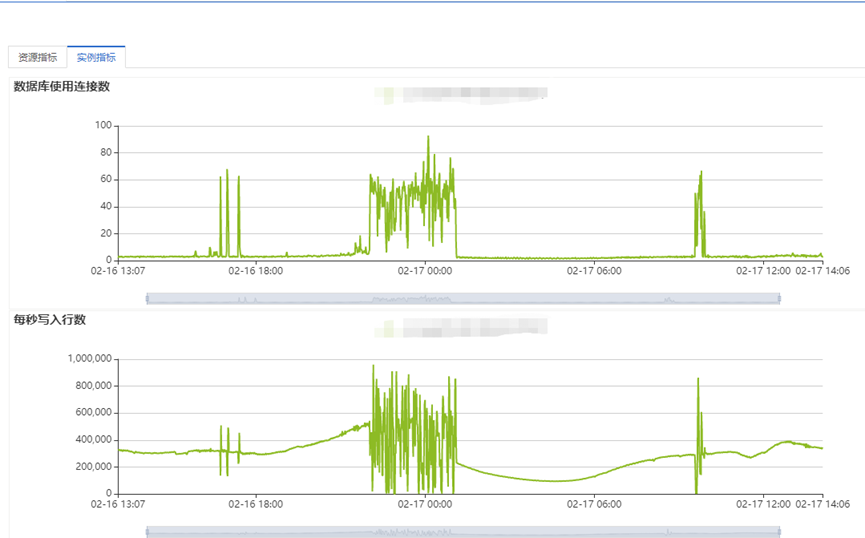
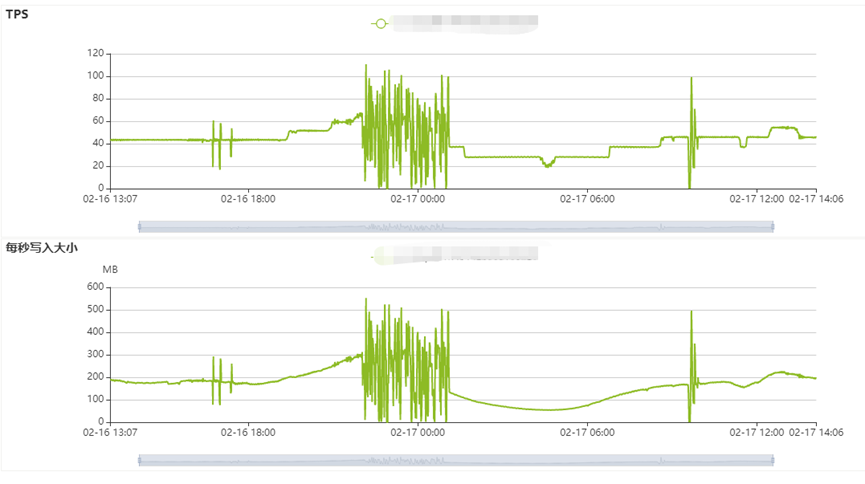
联系开发同事查看写入程序,发现程序设计是当kafka的消息量到达4W或每30S写入一次;最大并发控制在90。前一天业务进行了放量。根据以上条件判断,怀疑CPU抖动的原因是消息量在业务高峰期增长过快,导致写入程序并发数增多,对ClickHouse数据库进行了高并发数据写入。
>>我们先来了解下数据库系统写入速率与并发间的关系:
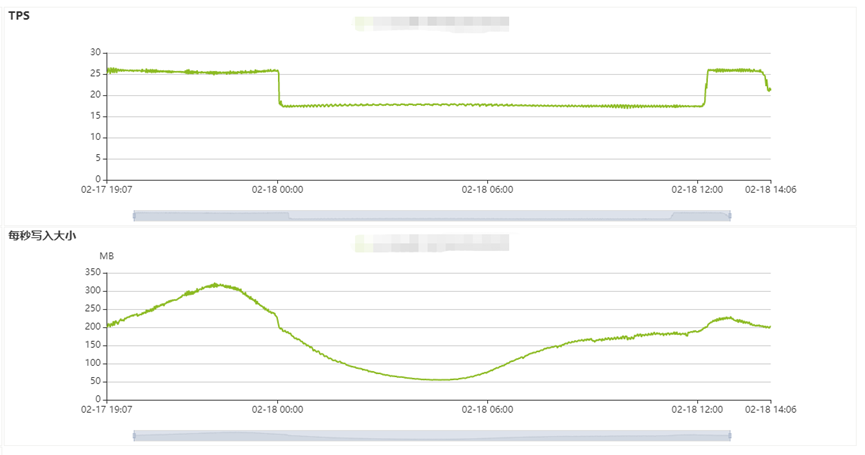
通常状况下ClickHouse写入速度与并发数并非正相关(特别是CK这种高耗CPU类型的数据库)。参考如下图所示:
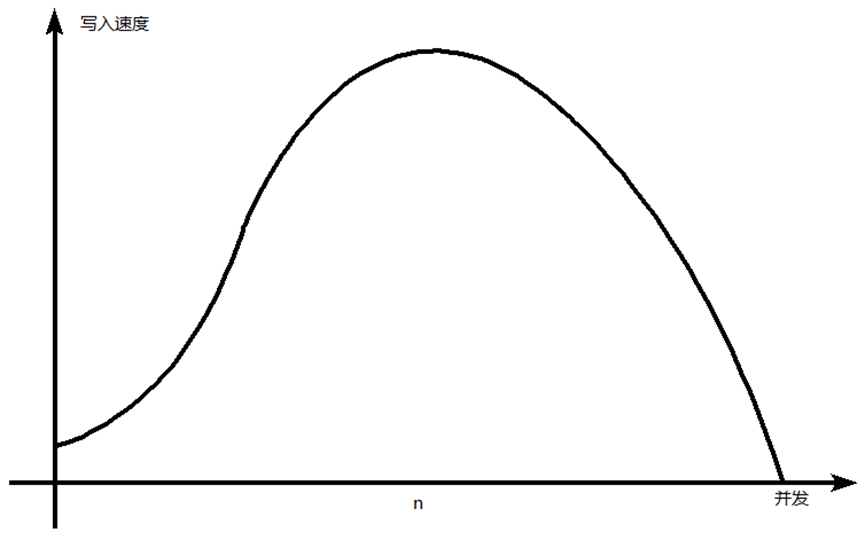
根据经验,在不触及ClickHouse IO瓶颈之前,影响写入的速度与单批次insert插入的数量有关,高并发往往会带来负效果。
a)监控可以看到,当前配置ClickHouse IO能力能到达500MB/s以上,瞬时写入速度能达到80W行/s以上。
b)根据kafka消息生成量,高峰期每秒60W左右,将单次写入的批大小调整成15W,最大并发数调整成10(多次实验得出数据)。
c)调整后观察监控CPU指标不在进行大幅度波动,数据插入状况稳定。
问题总结:当前场景下,单次批插入15W能够保证kafka消息及时的被消费,满足业务场景。ClickHouse作为OLAP类型的数据库,我们在将数据写入到ClickHouse的时候,往往需要多次的测试。通过控制并发数和单次insert的批次大小,去找到最适合自己场景的阈值。
2.2 ClickHouse 特定场景下TPS的天花板
TPS(每秒事务数)是衡量数据库运行的一个重要指标,关于ClickHouse最大支持多少TPS,或者说多少TPS以下才能保证业务的正常运行,没有统一的标准。我们从下述案例看看TPS激增引发的故障。
案例2:
运营反馈前台页面查询缓慢,并且存在报错信息。
>> 确定数据库信息,进行故障排查。
a)查看数据库发现:CPU指标存在波动,但是CPU并没有被打满。
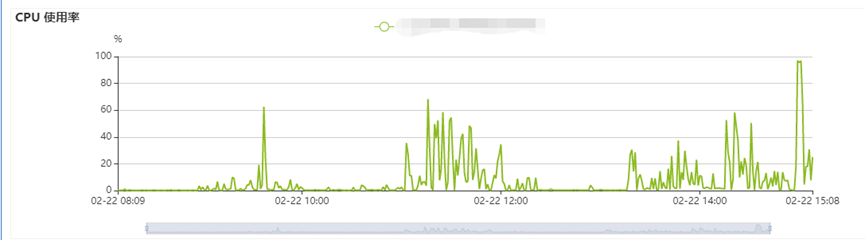
b)内存使用量也在百分之50以下,没有因为内存资源不足引发的报错。
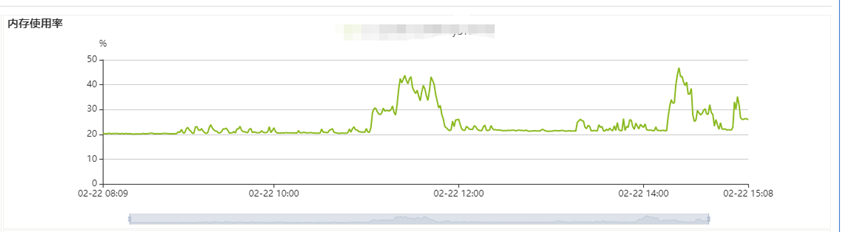
c)对接开发同事了解是否进行了业务变更,得到回复:“早11点30分左右,开发人员给表对象添加字段,alter table XXX.XXX add column real_expose_num Nullable(Int64) comment '真实曝光数' after income;并且更新了代码(数据写入程序)”。
d)对接运营同事业务人员前台页面查询ClickHouse报错,现象一会儿能查询,一会儿不能查询。显示连接超时,报错内容出现connect refuse。
e)通过客户端查询一会好 、一会坏,报错日志 reset connect。
f)数据库后台日志无报错,前台监控查看CPU、内存指标正常,数据写入正常。后台无报错。
>> 实际遇到的现象是:
a)前台查询不定期报错、客户端查询不定期报错,数据库无报错日志,监控有抖动,但是没有触发资源瓶颈。
b)表添加了字段、写入程序的代码进行了更新。
>> 因为已经影响到运营人员的使用,及时止损,进行代码回退,删除字段。回退完成后,一切正常。
问题暂时已经处理,但是需求还得继续,观察了数据库,尽管数据库的多个指标都有波动,但是资源使用情况都维持在中等的水平,这个时候不明确故障的原因。随后和运营商议维护窗口第二天下午13点50分左右,重新进行操作。
>> 二次验证,定位问题:
a)添加字段。
字段添加完成之后,20分钟,客户端查询正常、前端页面查询正常。
b)开发人员上新代码(数据写入程序)。
问题复现,客户端和前端页面查询同时出现问题。
现在知道问题是第二步开发人员上新代码引起的问题,并且是能够复现的。开发同事也提供了一个情况:“新代码写入速度非常慢”。
>> 问题分析:
a)字段添加应该没有问题,因为添加字段之后,20分钟之内一切正常。
b)观察监控,发现新代码启动之后数据库的cpu指标波动较小,数据库连接数从平均值5激增到25左右(可接受范围内,并非高并发)。tps从平均数1 激增到1500左右。
c)理论上新代码,业务侧只是新增了一个字段的写入,指标变化有波动正常,但是TPS的波动不应该这么大。
d)和开发同事检查insert批次和并发,发现insert 单次插入100,并发20。根据经验(参考2.1 ClickHouse Insert在批大小与并发数的抉择)单次100应该小了,怀疑是不是新代码进行了修改。发现原代码确实没有变化,原先就是100,但是业务运行正常,挺奇怪的。
e)根据经验,这个问题理论应该就是批次太小的问题,先调整单次插入15W,并发数降低到5,重新上新代码,跑跑看。 代码上线后客户端正常,前端页面查询正常。
>> 问题回顾
问题明确,ClickHouse insert 插入数量太少,导致数据库TPS激增,引起客户端和前端页面查询故障。返回头去确认问题。发现新增一个字段后(业务上需要一个字段,数据量大幅度增加),数据的插入量4W变成了1000W,超过了运营的预估,也超过了开发的预估。这也解释了老代码一直是好的,但是新代码会出现问题,因为数据量激增了200多倍。
分析后发现,CPU、内存、硬盘、QPS、每秒写入量、硬盘IO都没有触发瓶颈、数据库没有任何报错日志、网络均正常。只有TPS的指标发生了激增。数据库设计理论讲:资源有冗余的情况下,数据库应该不会连接失败。既然存在连接失败,那应该是某一指标触发了瓶颈,参数资源耗尽,导致后续无法连接。
问题总结:ClickHouse 数据库的配置是24C 96G,当数据库内存和CPU、硬盘等资源都充足的情况下,TPS激增会导致数据库的连接出现问题。因为TPS的指标量和业务SQL直接相关,所以无法直接评估数据库在多少TPS的时候会触发瓶颈,但是我们可以结合TPS正常运行指标,其他资源利用率是否达到阈值,来判断数据库到底是哪里出现了问题。
2.3 ClickHouse 并行的DDL的深坑
ClickHouse 作为OLAP数据库,OLAP分析型数据通常表现就是数据量非常大。当我们需要对表数据进行update或delete 的时候,ClickHouse并不是多么的友好,所以我们就需要换种方式来代替update和delete操作。通常我们使用的方式,就是删除需要变更数据所在的分区,然后重新进行数据的插入。
删除分区(DDL操作),在ClickHouse中是常常需要进行的变更操作。实际使用过程中ClickHouse集群架构和单实例架构之间总有一些差别,默认参数在使用的时候需要逐一衡量。下述案例描述因参数设置引起的DDL任务失败导致的大批量任务报错的故障。
案例3:
19日凌晨3点50分开始,多个关于ClickHouse数据库的定时任务脚本执行报错。查看发现,多个定时任务对于ClickHouse数据库都进行alter drop(ddl)操作。查询发现对adv_log的对象的DDL操作没有成功的情况下,后续存在ddl的任务都失败。
>> 问题分析:
发现定时任务对表对象adv_log同时删除20220218和20220217分区(DDL)(没有执行成功)。
>> 问题定位:
排查后发现,集群版的CK需要保障所有实例统一,所以集群版CK必须控制ddl任务是串行进行。我们购买的是单实例的CK,但是参数enforce_on_cluster_default_for_ddl默认是开启的,当前数据库处于ddl 串行执行模式。串行情况下,同时执行两个alter drop的ddl操作,会发生锁征用,且任务会多次发生重启。直至任务重试结束,报错也持续到了4点30左右。后续任务受影响失败(以前没有触发报错可能是因为条件没达到所以一直没报错,周六是触发了导致任务失败)。
>> 问题修复:
对于参数已经进行修复,后续并行执行DDL理论上是没有问题了。
>> 问题总结:
ClickHouse在使用过程中,我们需要对相关参数进行研究学习,这样在面对故障问题,我们能够根据特性去分析、定位、快速解决。
考虑ClickHouse归属分析型数据库,建议DDL的操作,任务设计以串行为主。
2.4 ClickHouse 常见缺陷
(1)ClickHouse资源监控,CPU使用率百分百的情况下,大多数造成的影响是查询缓慢,但内存使用率超过百分之八十左右就需要升配,因为随时都有可能发生OOM造成数据库重启。
(2)ClickHous alter delete在生产系统能不使用则不使用,因为不熟悉的操作,会消耗大量资源,会影响线上的使用。
(3) ClickHouse 因为底层都是文件,硬盘较小的时候,需要注意inode 资源可能会耗尽导致的宕机,特别是在小批量插入数据的时候。
(4)阿里云ClickHouse 删除分区参数为0表示不限制,但是实际删除的时候单个分区超过50会被限制,自己无法修改,阿里云后台进行了修改。
(5)阿里云RDS 的云分析型数据库ClickHouse。使用时需注意MaterializedMySQL DB engine不能在目标端数据库创建表对象,也不能在目标端创建物化视图,创建后数据将无法同步数据。但是可以在其他db创建这个关于db的物化视图。
(6)ClickHouse 物化视图可以优化与计算的复杂SQL,拥有丰富的函数可以满足各种场景,可参考文档:https://www.modb.pro/db/70716 。
(7)阿里云ClickHouse 单实例硬盘存在32T的限制,当使用冷热数据分层,冷盘的容量将没有容量限制。
==============================================================================================================
3 ClickHouse 特性实践
3.1 ReplacingMergeTree“应用”
ReplacingMergeTree首次实践主要是因为业务端存在sql的查询性能问题,分析后发现因为sql中包含对大量数据的distinct操作后,在进行统计计算 ,引起查询性能问题。
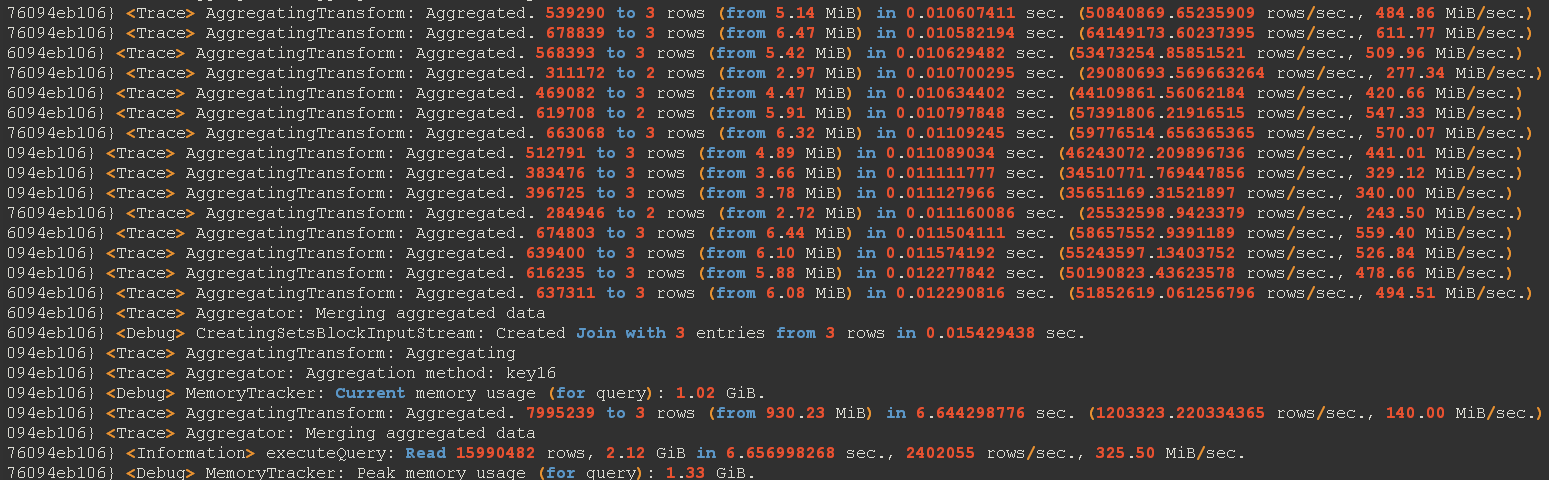
ClickHouse作为一款分析型数据库,当对8千万数据进行查询,SQL查询8秒,当前查询场景上,业务上不能接受。研究发现该表因为是实时消费写入数据,当写入任务失败就会重新写入,造成表对象中有重复数据。因为有重复数据,所以SQL在查询的时候需要对数据先行进行distinct ,在进行sum的聚合查询,性能就非常差。测试发现,当不需要进行distinct 的时候,查询的速度基本为0.2s,快的飞起。执行计划对比:
包含distinct的sql 的执行计划:
不包含distinct的sql 的执行计划:
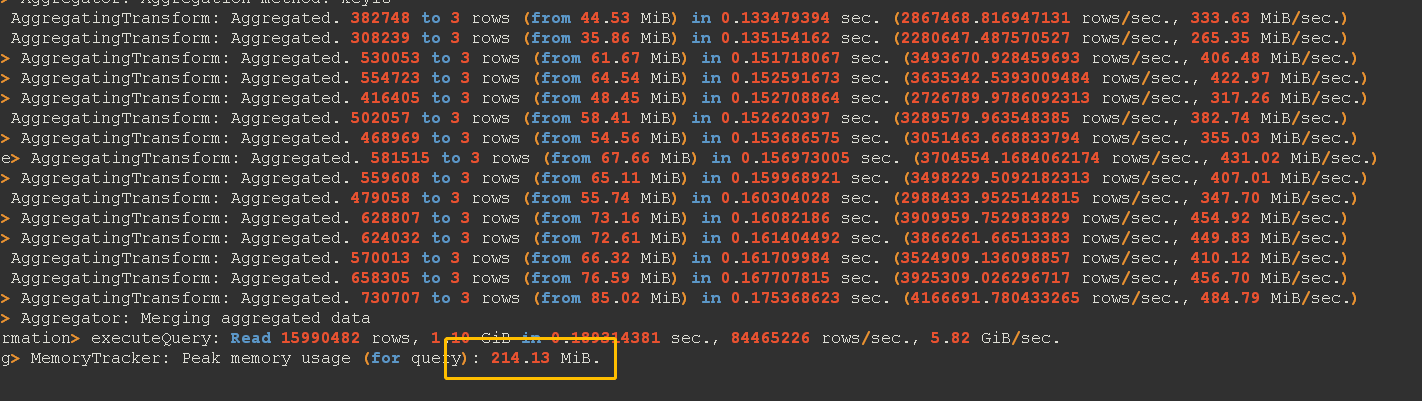
根据执行计划发现当sql中添加了distinct之后,发现内存的使用量,和数据获取的时间有很大的差别。基于此,需要去掉查询中的distinct操作,根据实际情况制定了三种解决方案,结合实际生产情况总结各方案之间的优缺点:
(1)创建雾化视图,雾化视图数据在每次插入的时候会进行数据的去重。
优缺点:
>> DB层:问题比较少,只需要创建雾化视图,成本上会增加磁盘的费用,因为雾化视图一定程度上讲是空间换时间的策略。
>> 数据写入层:程序不需要进行修改。
>> 业务代码层:需要对业务上进行比较大的改动。
(2)脚本介入,当数据发生重写,手工触发任务脚本 distinct 方式备份当天分区数据(根据分区键、和批次键),删除当天分区,然后插入distinct后的数据,然后重启插入任务。这样就能保证表中对象不存在重复值。
优缺点:
>> DB层:无需进行修改。
>> 数据写入层:需要对数据写入程序进行修改,数据写入流程复杂化,代码修改比较多。
>> 业务代码层:代码只需要去掉一个distinct。
(3)使用ReplaceingMergeTree存储引擎的特性进行数据的去重。
优缺点:
>> DB层:仅需要进行一次存储引擎的替换。
>> 数据写入层:仅需要添加表分析语句。
>> 业务代码层:代码只需要去掉一个distinct。
(4)根据优缺点开发人员最后决定选择方案(3)进行优化。
>> 优化完成后,前端查询从8s降低到0.2s。
实践总结:使用clickhouse,当表对象中存在重复数据,可以通过不同的方式对重复数据进行处理,我们 需要了解ClickHouse各个引擎之间的优缺点,选择合适的存储引擎应用到我们的业务中。
3.2 MaterializedMySQL “尝鲜”
关系型数据库MySQL能够满足日常的业务功能需求,可以应对OLTP类型场景,当实际业务需求中经常会出现对于大表的数据分析,当MySQL单表数量超过千万级别,随着数据量的增多,分析结果将会越来越慢。
我们业务侧MySQL存在这样一张MySQL分区表,数据量超过20亿,存储大小超过400G。业务上经常会有一些复杂的全局查询,MySQL数据库已经无法支撑实时业务查询。业务上已经有多处场景在使用ClickHouse数据库,根据场景尝试使用ClickHouse数据库来缓解MySQL数据库复杂查询的问题。
OLAP数据库ClickHouse提供了对于MySQL数据库的数据类订阅能力。ClickHouse数据库作为MySQL数据库副本,读取Binlog并执行DDL和DML请求,实现了基于MySQL Binlog机制的业务数据库实时同步功能。加强了对于MySQL实时查询的能力。
(1)阿里云RDS分析型数据库(MaterializedMySQL)特性总结如下:
>> 前端控制台支持MySQL库级别的数据同步,暂不支持表级别的。
>> MySQL 库映射到ClickHouse中自动创建为ReplacingMergeTree 引擎的表,需要添加final定期的进行表分析(final)结尾的表分析。
>> 支持全量和增量同步,首次创建数据库引擎时进行一次全量复制,之后通过监控binlog变化进行增量数据同步。
>> 支持的操作:insert,update,delete,alter,create,drop,truncate等大部分DDL操作。
>> 支持的MySQL复制为GTID复制。
(2)阿里云支持表级别的复制,通过参数include_tables控制所需的表对象,并且通过参数order_by_only_primary_key可以控制ClickHouse去重的依据(ClickHouse 去重依赖order by 后面的组合字段)。阿里云图形化界面操作会存在默认参数,不能进行选择参数,最好是在客户端直接执行创建命令,如下所示:
|
CREATE DATABASE promotion
ENGINE= MaterializeMySQL SETTINGS mysql_url= '****:3306', |
(3)使用ClickHouse MaterializedMySQL 存储引擎,测试MySQL需要分钟级别的查询,在ClickHouse数据库中都优化到了秒级别。
实践总结:
a)实际使用过程中ClickHouse目标端的数据库下不能创建雾化视图,否则将会影响数据的同步,如需创建,可重新创建数据库,跨库进行创建。
b)图形化创建不能选择目标对象。
c)图形化创建不能控制数据传输的速率。
d)400G大小20亿数据量数据同步到ClickHouse大概 需要4个小时。
4 ClickHouse 基础操作
4.1 常用命令
下述相关的操作内容,是日常运维过程对ClickHouse问题分析、状态查询的常用命令的总结,运维人员和开发人员都可进行参考,便于日常工作。
4.2 执行计划
ClickHouse没有提供方法(explain)来获取执行计划,借助后台的服务器日志,能够观察到相关执行计划。有胜于无,我们可以通过执行计划的获取查看数据的获取、分析索引和稀疏索引带来的优化效果、分析sql慢在了哪里,如何进行优化。下述为ClickHouse执行计划中获取的关键字及备注。
|
获取执行计划 |
|
|
ClickHouse-client
-h 127.0.0.1 --send_logs_level=trace <<< 'select * from table_name'
>> /dev/null |
|
|
关键字 |
备注 |
|
Union Expreesion X 2 Expreesion MergeTreeThread |
这条查询语句使用了2个线程执行,最后通过union合并了结果集。 |
|
Key condition:
unknown |
查询语句没有使用主键索引 |
|
MinMax index
condition:unknown |
查询语句没有使用分区索引 |
|
Selected 6 parts by
date, 6 parts by key, 1096 marks by primary key, 1096 marks to read from 6
ranges |
查询语句总共扫描了6个分区目录,攻击1096个markRange
|
|
Read 15990482 rows,
1.10 GiB in 0.189314381 sec., 84465226 rows/sec., 5.82 GiB/sec. |
查询语句纵沟读取了15990482行数据(部分数据表)大小8.5G, 是按,每秒行,每秒读取数据量 |
|
MemoryTracker: peak
memory usage (for query): 214.13 MiB. |
该查询语句消耗内存最大时为214.13 MiB. |
|
select xxx parts by
date |
分区过滤信息部分 |
4.3 参考文档
(1)https://ClickHouse.com/docs/en/engines/table-engines/mergetree-family/replacingmergetree
(2)https://help.aliyun.com/product/144466.html
(3)《ClickHouse原理解析与应用实践》