背景
对原始数据进行一个或多个标签的过滤,来获取数据子集,是很常规的步骤。但面对大规模数据集的检索过滤,常规的操作会存在查询性能的问题,本文就七猫推荐系统过滤服务所遇到的问题及解决方案进行探讨。
应用场景
对召回上万本书书籍进行快速过滤,获取偏好男生、已完结状态、字数范围在5万以上的书籍。过滤结构如图:
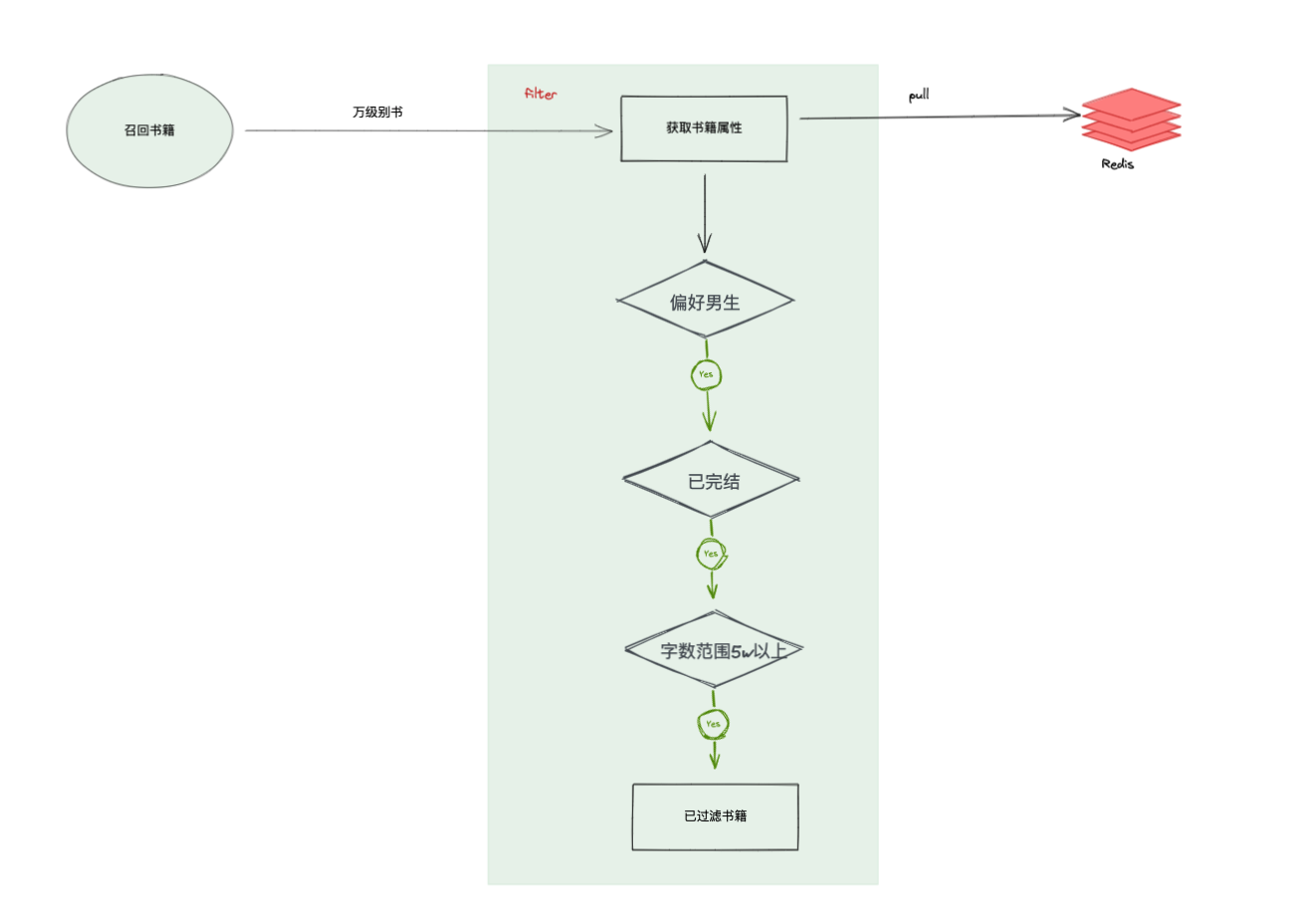
过滤服务书籍属性过滤主要的流程:
- 获取书籍属性
- 根据请求过来的召回书单,优先从本地缓存中获取;不存在的书单实时查询redis缓存获取书籍属性;
- 本地缓存存在过期时间,过期会重新从redis缓存中获取,因为书籍属性一天内会发生更新。
- 书籍进行属性过滤,如上图示根据过滤的条件进行过滤;
过滤目前的结构逻辑上没有任何问题,很常规的操作,那么在面对大规模召回书有什么问题呢?
问题
当召回过来上万本书到过滤服务,大部分的书本地缓存存在过期的情况,需要回溯到redis进行查询,尤其是业务流量高峰期,主要的压力都集中在redis,redis就会出现响应超时;过滤服务也会阻塞等待,这个过程会一直占用CPU资源,出现CPU受限的问题,正常的推荐也会受此影响。很长一段时间推荐系统受此困扰,一直有响应超时的问题。
所以问题的关键方向在如何提升大批量书籍查询的性能,怎么解决呢?redis升配,这能一定程度缓解目前的压力,但还不是最优的解决方案。
根据过滤阶段的特点,非常适合使用bitmap进行处理,下面进入正题。
什么是bitmap
bitmap是一种非常常见的结构,它使用每个二进制位(0或1)来存放一个值的状态,我们知道bit是数据的最小单位,正因为这个性质,这种数据结构往往是非常节省存储空间,利用这种思想可以处理大量数据的排序、查询以及去重。
为什么使用bitmap
利用bitmap的查重业务场景,可以实现书籍属性的过滤,进而提升过滤服务的性能,其优点:
- 占用内存少。比如N=10000000,只需占用内存为N/8=1250000Byte=1.25M;
- 运算效率高。能够快速进行属性判断,比如存储偏好男生的书ID,判断一批书是否男生偏好,位运算性能优越;
根据过滤阶段的特点,做了如下bitmap运算优化:
- 对书籍属性进行倒排,比如偏好男生对应有哪些书籍;
- 书籍属性倒排书籍集合使用bitmap进行存储;
- 过滤动作就是召回书对书籍属性进行bitmap位运算。比如获取偏好男生的书籍,就是召回书籍与偏好男生倒排bitmap取交集;
方案调研
对此调研对比几个bitmap技术实现:
| bitmap | 优点 | 缺点 |
|---|---|---|
| redis bitmap | 不占用本地内存空间 | 1. 简单使用getbit(get)、setbit方法,多个bitmap不能进行运算; 2.批量计算效率较差,占用网络传输时间,需要额外写运算代码; |
| Go集成bitmap(Roaring Bitmap) | 1. 比较丰富的运算函数,不同bitmap可进行与、或、差集运算; 2. 本地运算效率很高; 3. 压缩位图索引,性能、空间利用率更优 |
占用本地内存空间 |
| 其他数据库(ClickHouse) | 1. 比较丰富的位图函数,内部实现也是Roaring Bitmap 2. 不占用本地内存空间 |
1. 接入有一定复杂度,增加系统复杂性; 2.并发性能不太友好; |
结合推荐系统并发较高的特点,以及通过一些性能对比分析,最终决定使用Roaring Bitmap,它的优势很明显,而且相对于之前书籍缓存本地的方案,它的缺点可以忽略不计。
Roaring Bitmaps应用
Roaring Bitmaps 是一种十分优秀的压缩位图索引, 运算效率很高,支持golang、java等多语言,被多个主要系统使用,例如 Apache Lucene 、 Elasticsearch、Apache Druid (Incubating)、YouTube SQL 引擎 Google Procella 使用 Roaring 位图进行索引。
应用这么广泛,足见其成熟。(好用,bug几乎没有)
下面看下Roaring Bitmaps具体应用在过滤场景优化的步骤:
1. 生成书籍属性倒排bitmap
首先将所有书籍对应的属性,转换成属性倒排的书籍ID bitmap,如图所示:
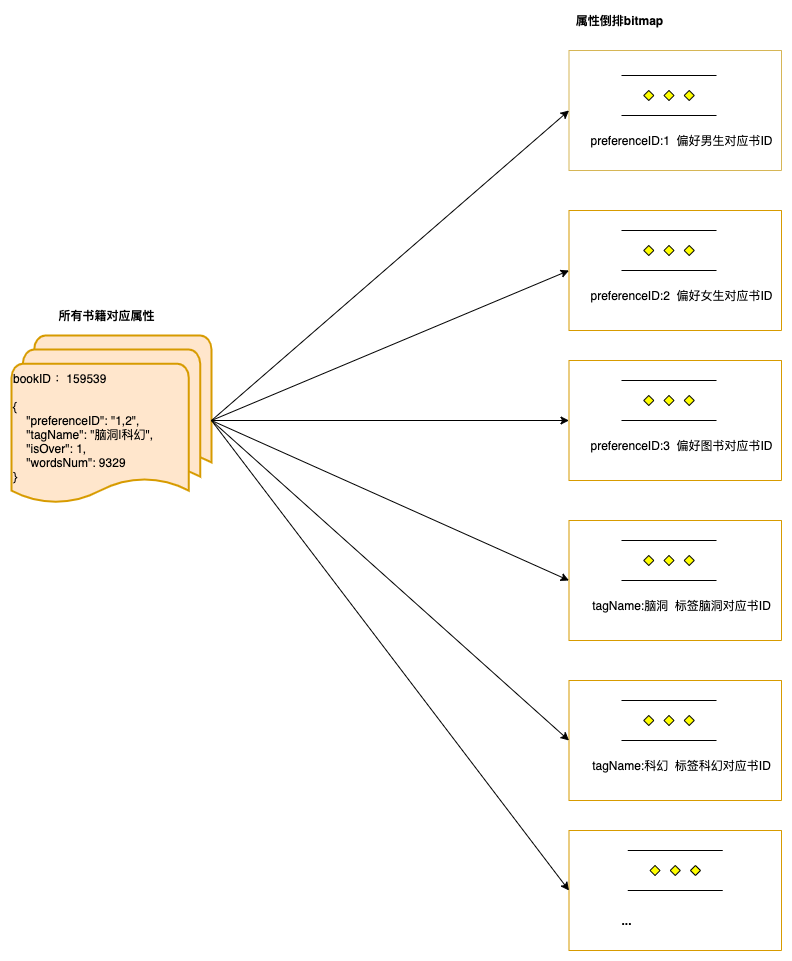
根据每个属性获取到倒排的全量书籍ID,然后通过Roaring Bitmap缓存在内存中。
2. bitmap运算过滤
接下来就是对召回过来的上万本书书籍,进行基于bitmap的快速过滤。我们看下伪代码:
// 伪代码
recallBooks := [159539, 159541, 159558 ... ] // 召回万本书籍
list := roaring.bitmap.Add(recallBooks...) // 召回书转roaring bitmap
// 获取男生偏好的书:男生偏好的书bitmap与之交集
if 偏好 == "男生" {
list = roaring.And(list,attrBit[preferenceID:1]) // 交集
}
// 获取非脑洞的书:脑洞书bitmap与之或集
if 标签 != "脑洞" {
list = roaring.Or(list,attrBit[preferenceID:3]) // 差(或)集
}
// 获取完结的书:完结书bitmap与之交集
if 完结 {
list = roaring.And(list,attrBit[isOver:1]) // 交集
}
...
// 最终过滤完的书
return list
通过Roaring Bitmap运算,可以很快速得到过滤的结果,避免了频繁对redis进行操作。
到这一步我们好像已经完成了过滤功能,也相应提升了过滤服务的性能。但是...
上述实现方案有个很大的缺点就是每次请求都需要重新进行bitmap的计算(roaring bitmap运算会有一定CPU损耗),这会限制优化的空间。
3. 过滤条件bitmap运算优化
我们来分析下几个过滤条件:
- 包含男生、女生偏好,等价于男生偏好bitmap与女生偏好bitmap取交集,最终与召回书取交集;
- 非脑洞标签,等价于脑洞标签bitmap取非,最终与召回书取交集;
- 男生或女生偏好,等价于男生偏好bitmap与女生偏好bitmap取并集,最终与召回书取交集;
故可以做进一步抽象优化,将过滤条件抽象出来作为一个单独的模块进行运算:
- 将召回书与过滤条件运算进行拆分,先算出过滤条件运算得到书的bitmap;
- 然后通过召回书与之交集就是需要的结果;
这样做的好处是首次请求把不变的过滤条件结果固定下来,缓存到内存里;后续请求就可以对变化的召回书籍与过滤条件的bitmap进行快速过滤运算,进一步提升CPU的性能和系统响应时间。
过滤条件bitmap运算关键代码:
// 书籍ID上下限
const (
bookIDLimit = 100000000
bookIDMin = 100781
)
....
// 获取过滤条件所需的属性bitmap
keyData, err := f.fetch(ctx, strategy, options)
// 每个过滤条件内部进行bitmap运算
for _, option := range options {
// 当前条件选项对应的bitmap
list = []*roaring.Bitmap{...}
// 根据条件选项的操作符进行bitmap运算
switch option.Operator {
// 获取集合
case OperatorGet:
bitmapList = append(bitmapList, list...)
continue
// 获取交集,如既包含男生,又包含女生的书
case OperatorIntersect:
bitmapOpt = roaring.ParAnd(0, list...)
// 获取差集,如非脑洞的书
case OperatorDiff:
bitmapOpt = roaring.ParOr(0, list...) // 先进行或运算获取并集
bitmapOpt.Flip(bookIDMin, bookIDLimit) // 在书籍ID上下限范围取非
// 获取并集,如男生或女生的书
case OperatorUnion:
bitmapOpt = roaring.ParOr(0, list...)
default:
continue
}
bitmapList = append(bitmapList, bitmapOpt)
}
// 对所有条件运算bitmap进行交集得到过滤后的书
result := roaring.ParAnd(0, bitmapList...)
....
注:roaring.ParAnd、ParOr运用的是roaring bitmap的并发处理,第一个参数设置0,默认使用当前进程可用的逻辑 CPU 数量。
最终bitmap过滤整体的结构,如图所示:
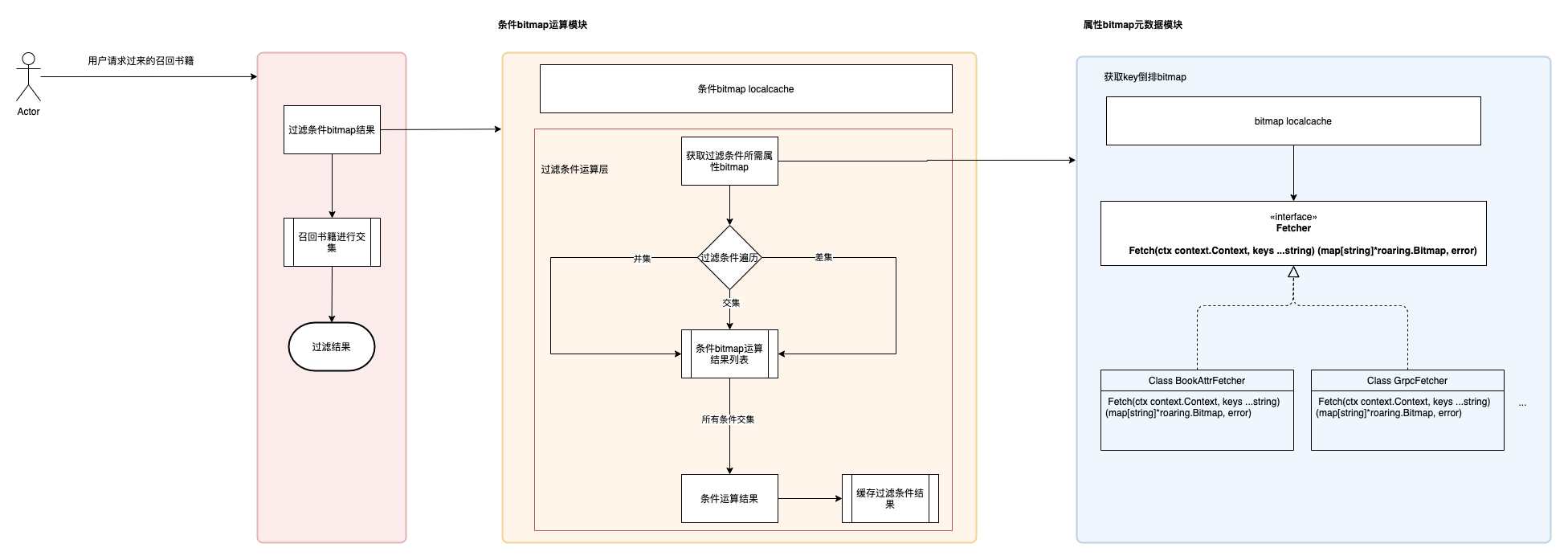
- 条件运算模块负责进行条件运算得到过滤的全量书bitmap;
- 属性bitmap元数据模块负责获取过滤条件选项所需要的bitmap元数据;
这样设计有什么优势呢?
- 与上层变化的业务计算解耦,模块划分清晰,职责明确。
- 进一步提升性能。对条件运算结果进行缓存,避免重复运算带来的CPU消耗,提升响应效率;
- 提升系统通用性、扩展性。属性bitmap元数据模块,新接业务仅需实现Fetcher接口和过滤条件选项对接,就可以完成bitmap方案接入。(目前在推荐系统重排阶段也有应用)
到此整体的优化已经完成,过滤服务的性能提升是否有效果?还需要做下压测对比。
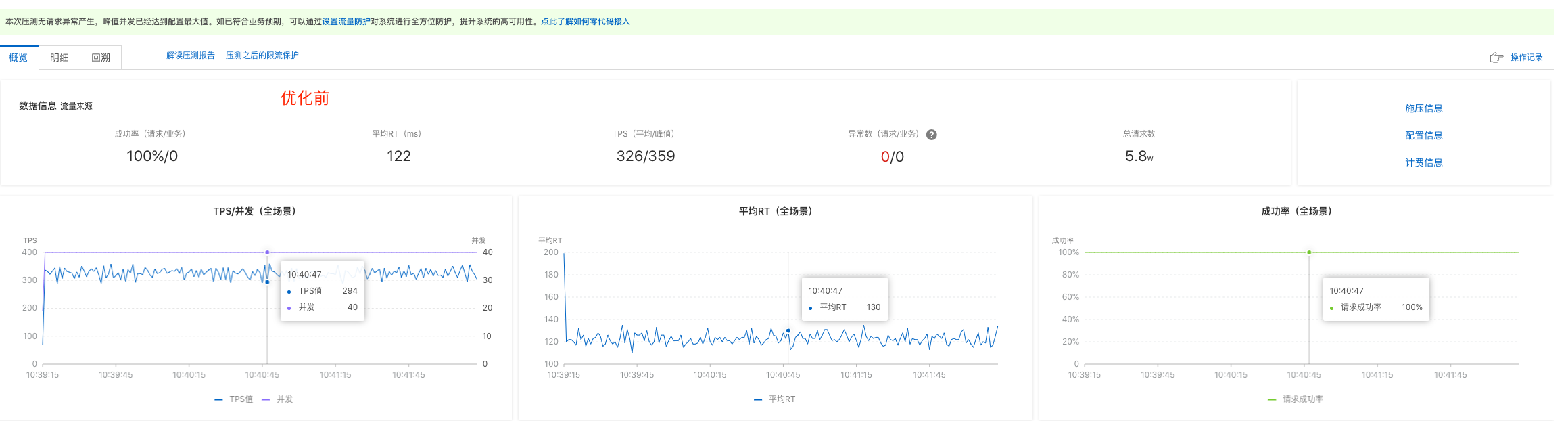
性能对比
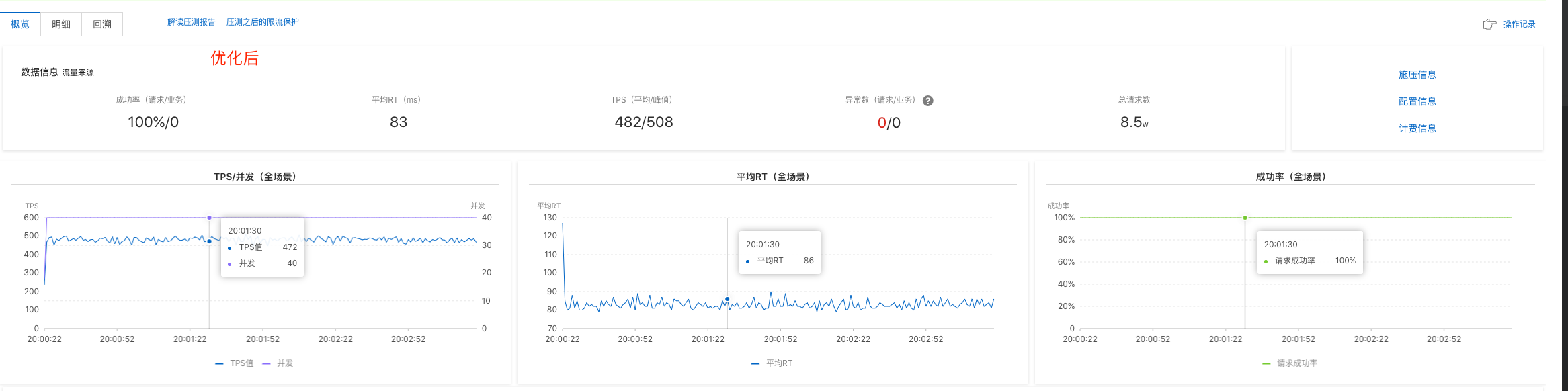
对过滤服务bitmap方案优化前后,cpu限制2core进行压测,性能对比如图(使用阿里云的性能测试服务PTS):
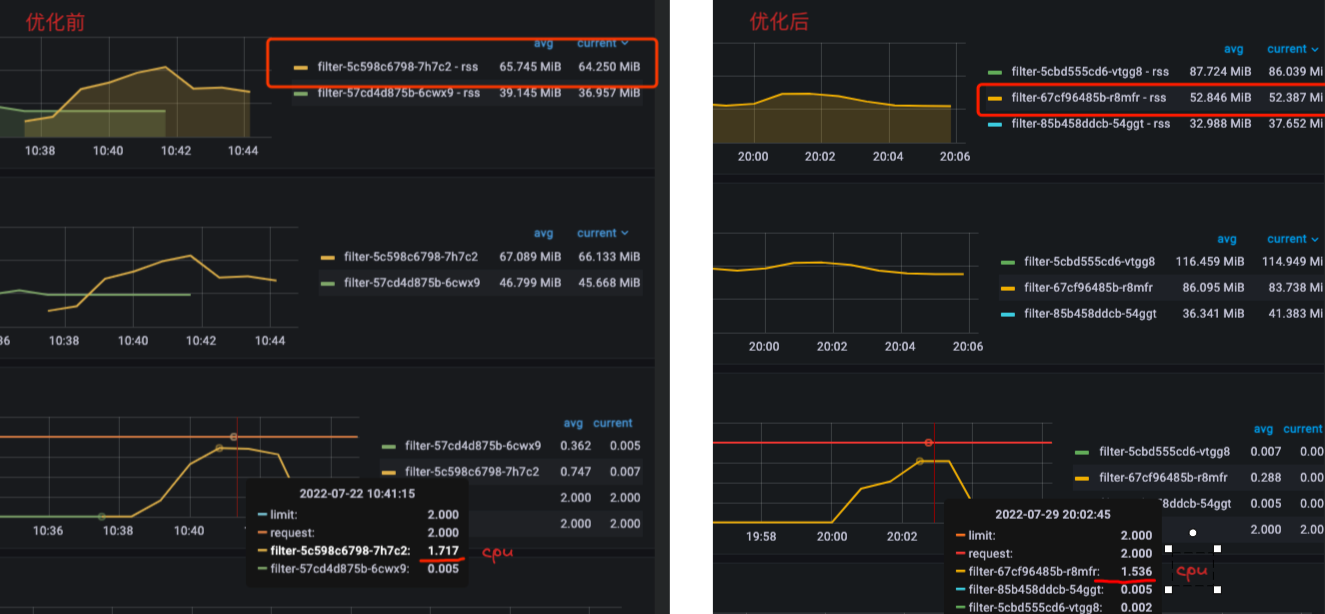
我们再来看下pod的内存和CPU使用情况:
整体我们可以看出效果是正向显著的:
- RT提升较为明显,相对提升30%;并且内存耗用也有显著下降,CPU耗用下降明显,之前过滤服务经常出现的CPU受限问题没有再复现;
- 服务运行稳定,没有再出现书籍属性redis请求超时的问题;
总结
Roaring Bitmap是应对大数据查询、去重业务场景,很成熟的解决方案,非常适合推荐系统过滤场景的应用,高效解决了大批量查询性能的问题。在技术方案的设计上,需要考虑方案的通用性,将变化与不变化的拆分开进行“动静分离”,降低业务耦合性,提升系统的扩展性,在类似的场景上能够复用,进行快速应用。