背景介绍
k8s是目前主流的部署模式,这项技术让应用封装变得简单了许多。优点有故障迁移、资源调度、资源隔离、安全等。古人云“工欲善其事,必先利其器”,用的好同样也需要维护的好,否则一旦出现故障就会悔之晚矣。所以平时的监控和巡检工作要时刻保持警惕,多观察多思考会有意想不到的收获。
一、事情起因
在一天的日常巡检中,我留意到业务的k8s各个node节点的负载情况差别有点大。这里要说明下我的巡检时间跨度为3-7天,当时间跨度短的时候我们看监控图形类似于这样:
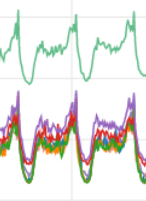
emmmmm......
这样看好像没什么问题,可能是pod负载不均匀,有多个pod分配到了同一个node上(常见的情况)。顺着这个思路想看看是哪一个更新导致了这种情况的产生,我拉长了监控的时间跨度看到如下情况:
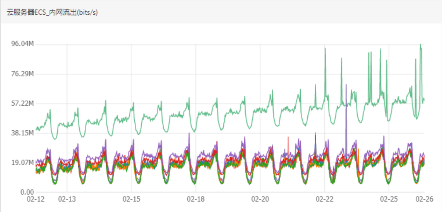
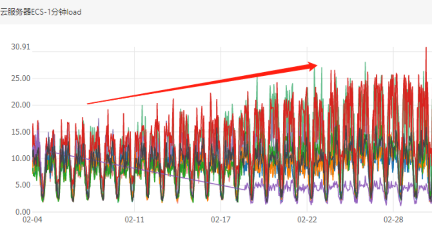
原来不仅是负载不均匀,而且负载每天都在不停的增长,但另外两个node负载却十分稳定。紧接着我查看了下其他的k8s集群也有类似的情况出现,会不会是业务量整体增长?
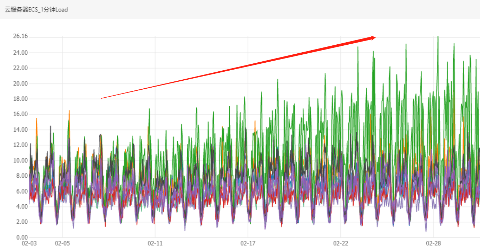
以上四个图表监控指标分别是内网流出流量最大值和CPU 1分钟load最大值,但是流量平均监控值看起来比较平稳,说明有瞬时指标异常。
按照如此趋势持续下去势必会影响节点的稳定性,影响到业务必需得赶紧找出原因并处理掉!
二、排查思路
猜想有几种情况:
1、业务量上升导致负载上升
2、高负载pod分配不均匀
3、内存泄漏
4、流量数据传输异常
既然两个k8s集群的node都存在流量异常的情况,那么肯定是有关联性。我们围绕上面的三个猜想去寻找答案,首先登录其中一个集群的问题节点。
1. 排查业务是否有更新
会不会是近期业务更新,新增了某些新的功能?
马上通过命令kubectl get pod -n $nameserver 观察状态,发现无重启且资源存活时间长,再次联系研发确认近期无业务更新。
2. 排查高负载pod分配不均匀
- 查看cpu负载
登录节点之后,执行top命令(因为cpu load异常情况比较频繁),当负载异常增高时观察运行的进程状态,发现cpu、内存、虚拟内存等资源占用比并无明显异常变化,那么应该不是业务进程引起的。 - 查看pod负载分布情况
那是不是负载分布不均匀导致的呢,k8s是通过调度器来调度pod的,在调度过程中,由于一些原因,会出现调度不均衡的问题,例如:节点故障、新节点刚加到集群中、节点资源利用不足。这些都会导致pod在调度过程中分配不均,例如会造成节点负载过高,引发pod触发OOM等操作造成服务不可用等。当设置的requests和limits不合理,或者没有设置requests/limits都会造成调度不均衡。
此刻我马上查看各个node节点的负载情况kubectl top nodes
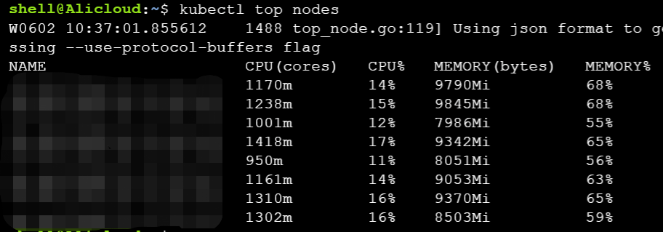
有个node的负载确实是有点高,再看看pod的request和limits都没有设置,目前看来确实是负载不均衡导致的。可是给每一个pod设置requests和limits后异常并没有恢复。
3. 排查是否内存泄漏
kubectl top pod -n $servername 和 kubectl get pod -n $servername 查看pod的cpu和memory使用情况,再确认pod的status都是Running且没有异常重启。
排查了业务增长和负载后,我们着手分析网络流量。
4. 排查流量数据
-
查看网卡流量
通过iftop -iany -P命令查看所有网卡流量情况,如下图

隔天发现次连接的流量比前一天瞬时流量有所增加,确认是此连接导致
那么这两个ip是什么pod的呢, 我们继续排查
使用命令kubectl get pod -n $nameserver -o wide一查,结果发现居然没有IP为172.29.1.13和172.29.1.128的pod,这是什么情况?随即看看nameserver如下:
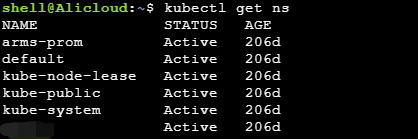
发现有一个arms-prom的nameserver,这是阿里云的创建k8s集群时自带的一个prometheus监控插件。会不会是这个nameserver里面的pod,一起搜索下看看。
kubectl get pod -A -o wide |grep arms

居然是arms-prom空间里面的容器造成的,瞬时流量这么高那是再上报什么数据吗?会不会是最近新增了什么监控项导致api调用频繁使流量升上去了? -
分析上报流量数据
现在我们已经知道是arms-prometheus 上报数据导致的,那么我们要分析
1、是不是由于业务量增高导致上报数据增多
2、是不是近期新增某个监控项
3、上报数据是否准确
再明确了业务近期没有更新和引流的情况下,排除第一个原因。接着上阿里云平台看看,查看下监控项和调用次数。

sum_apiserver_request_duration_seconds_bucket这个指标是集群apiserver的1分钟调用次数,要知道集群内的动作都会经过apiserver,它提供了k8s各类资源对象(pod,RC,Service等)的增删改查及watch等HTTP Rest接口,是整个系统的数据总线和数据中心。
可是对比其他指标占比大也比较正常。对比下其他集群这个值差几万,所以这个指标不能作为流量判断依据,它只是反应了集群内部接口调用的活跃度。
其他越靠后的指标占比和调用次数都非常小可以排除。
没什么办法那我们就从最基本的入手,分析流量。最直观的办法使用tcpdump抓包分析
tcpdump -vv -nn -iany port 9335 and host 172.29.1.218 -w dump.pcap
仅仅抓了几分钟文件大小就高达几百兆。使用WireShark对文件dump.pcap 分析后发现,上报数据当中存在非常多有规律性的内容且多达几百万行,如下图
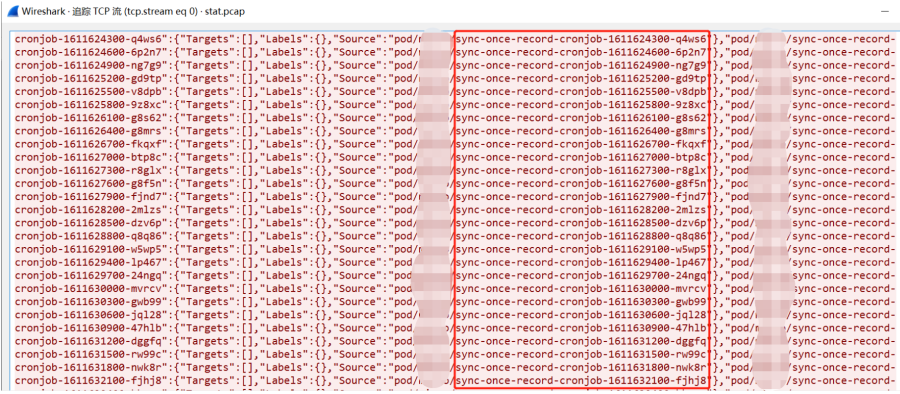
这个sync-once-record-cronjob名称的pod引起了我的注意,那么我们查看下k8s集群中的pod信息。
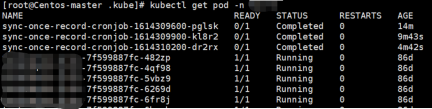
pod的名称中带有cronjob,应该是一个定时任务了,咱们再确认一下。kubectl get cronjobs -n $servername果然是定时任务。

这是每5分钟一次执行的周期性任务,按照时间表运行批处理job。我们发现线上cronjob 只有3个,而dump.pcap文件中却记录了许多cronjob信息。再对比一下dump.pcap文件中的内容不难发现,上报数据当中有相当多的cronjob名称。线上环境cronjob是周期性执行,而执行完毕后再次生成新的任务时,cronjob命名将会不相同。因为k8s中pod name名称是有规律的随机性命名的,这里就不展开讨论了。所以dump.pcap文件中的cronjob是历史信息(已经执行过的cronjob)。
三、结论
根据上面的排查得到,conrjob每次的任务名称都不相同,而arms-prometheus 每次上报信息中包括了cronjob的所有历史信息,每次上报时将执行过的定时任务cronjob信息都记录下来,由于缺少判断和清理机制,久而久之上报的信息量越来越大。累计上报数据量越大,每次网卡进行信息传输的量也越大,占用带宽增大从而影响到业务,节点cpu负载也因此出现异常波动。
其中一个业务集群的cronjob相比于另一个业务要多的多,所以其中一个节点网卡流量增长趋势比另一个业务更加陡。所以仅仅凭借接口调用次数是无法看出原因的,必须仔细分析。
那么它是什么时候开始的呢?我将时间跨度拉到30天(云监控时间范围最多30天),同样看不到异常发生的初始点。会不会这个问题开始就存在?看了其他一些新集群实例发现,没有cronjob的集群负载正常,而有cronjob的集群或多或少(根据cronjob数量)有这种异常的情况出现。cronjob越多的集群异常趋势越明显,越少的短期跨度负载平稳,需要将监控范围跨度拉大才能发现。
原则上只需要上报当前cronjob状态信息即可。agent收集cronjob信息上报后轮到下次再收集时删除历史信息重新收集目前状态的cronjob即可。由于监控容器内将arms-prometheus问题上报给阿里云,再更新image重新启动agent后,我进入了修复后的arms-prometheus容器内查看配置文件,发现arms-prom的调用动作action是replace,而配置文件底部注释掉的action是keep,看来逻辑是改变了。
将所有的集群的agent重启后异常现象恢复。
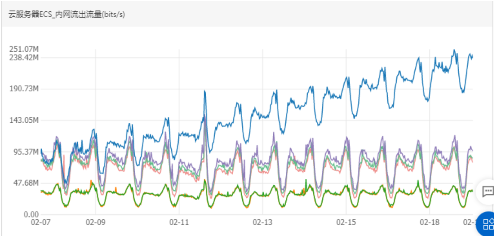
如图所示:
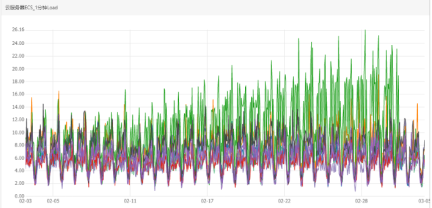
从这张图可以看到,cpu和流量都已经恢复,节点负载压力减小。使业务能够跑在健康的节点上,同时修正监控指标能让我们在以后的日常工作中对业务动态的掌控力更强。
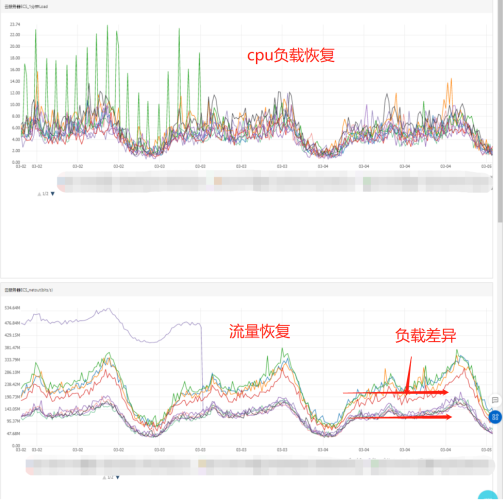
改进措施:可以看到集群节点间的负载不均衡,自身业务优化考虑设置pod的requests和limits以及nameserver的配额达到合理利用资源。另外日常工作中对第三方资源或者开源工具过于信任,需要加大运维监控力度和深度,要全方位的覆盖不遗漏不疏忽,使监控更加敏感当出现波动异常时能够早预警早发现早解决。
最后认真对待每一次巡检,做运维永远是预防比消防更重要!
扩展
另外补充一下,不仅仅是pod,svc也有流量策略的设置。
kubectl get svc $svcname -n $nameserver -o yaml
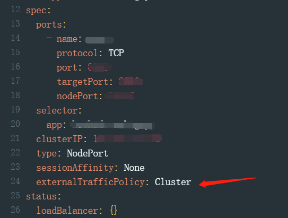
什么是external-traffic-policy
文档解释如下:
externalTrafficPolicy denotes if this Service desires to route external traffic to node-local or cluster-wide endpoints. "Local" preserves the client source IP and avoids a second hop for LoadBalancer and NodePort type services, but risks potentially imbalanced traffic spreading. "Cluster" obscures the client source IP and may cause a second hop to another node, but should have good overall load-spreading.
在k8s的Service对象(申明一条访问通道)中,有一个“externalTrafficPolicy”字段可以设置。有2个值可以设置:Cluster或者Local。
1)Cluster表示:流量可以转发到其他节点上的Pod。(默认)
2)Local表示:流量只发给本机的Pod。
注:只有nodeport和loadbalance两种模式的svc才有这个参数
如图所示:
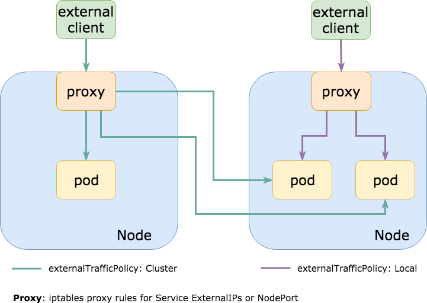
使用任何一种流量策略都有利有弊。
Cluster是默认模式,proxy不管容器实例在哪公平转发,转发时会替换掉报文的源IP。即:容器收的报文,源IP地址,已经被替换为上一个转发节点的了,这种模式好处是负载均衡会比较好,因为无论容器实例怎么分布在多个节点上,它都会转发过去。当然,由于多了一次转发,性能会损失一点。
Local只转发给本机的容器,绝不跨节点转发。缺点是负载均衡可能不是很好,因为一旦容器实例分布在多个节点上,它只转发给本机,不跨节点转发流量。性能会比Cluster好一点点,毕竟少了一次转发。不管可以再前端加一个Loadbalancer就能达到负载均衡
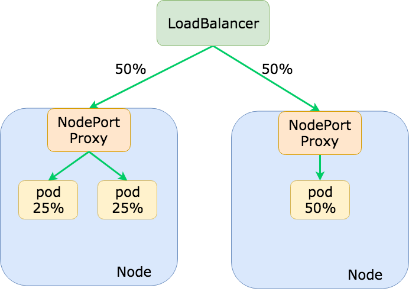
不过pod的流量并不均衡,因为负载均衡器通常不知道 Kubernetes 集群中的 pod 位置,所以它会假设每个后端(一个 Kubernetes 节点)都应该接收均等的流量分配。如上图所示,这可能会导致为应用程序选择 Pod 接收比其他 Pod 多得多的流量。为了避免流量分布不均,我们可以使用pod anti-affinity(针对节点的主机名标签),以便 pod 分布在尽可能多的节点上:
podAntiAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 100
podAffinityTerm:
labelSelector:
matchExpressions:
- key: k8s-app
operator: In
values:
- my-app
topologyKey: kubernetes.io/hostname
效果如下,每个node分配的流量都是25%包括pod所获得的总和流量也都是25%。
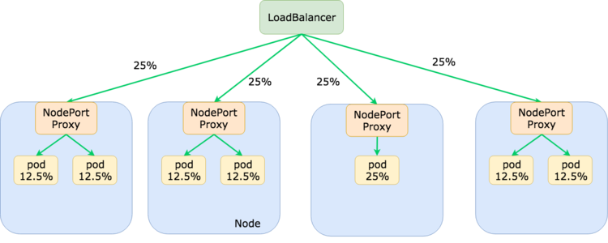
我观察了下阿里云的nginx-ingress的svc,发现他使用的策略是Local,看来性能还是王道啊。
参考:https://www.asykim.com/blog/deep-dive-into-kubernetes-external-traffic-policies