概述
提到协程池,不少使用过Java的同学会想到线程池,Java线程池以Runnable对象作为调度单位,Ants使用Golang闭包特性作为协程池调度单位。两种不同实现调度方法也有所不同。本文将展开讲解Ants调度原理,若想要对比两种实现区别,可浏览https://www.jianshu.com/p/87bff5cc8d8c
提出问题
问题
- 何时创建协程?
- 如何分发任务(Func)?
- 如何选择空闲协程,先进先出还是先进后出?
- 如何清理空闲协程?
读前想法
- 针对问题1,有两种不同思路,第一可使用惰性创建思路,有需要时创建协程;第二在协程池创建之初通过指定initializePoolSize参数来初始化部分协程,后期程序运行过程中使用惰性创建思路。
- 针对问题2,可使用channel进行任务分发,channel作为全局队列存放所有Func,各个协程获取任务并执行。
- 针对问题3,先进先出和先进后出的主要区别在于 GMP 的调度消耗。
- 针对问题4,可通过指定系数,对channel饱和度进行比较,低于系数则关闭部分协程。
读前实现
在阅读Ants源码前,自己试着实现了一个Pool。
package task_pool
import (
"fmt"
"sync"
)
// Pool 协程池
type Pool struct {
// maxPoolSize 最大协程池数量
maxPoolSize int
// stepLength 扩容和缩容跨度
stepLength int8
// expansionCoefficient 扩容系数 len(channel)/cap(channel)>expansionCoefficient 时扩容
expansionCoefficient float32
// reduceCoefficient 缩容系数 len(channel)/cap(channel)<expansionCoefficient 时缩容
reduceCoefficient float32
// taskChannelSize 任务管道长度
taskChannelSize int
stopChannels []chan struct{}
taskChannel chan func()
mutex sync.Mutex
}
func NewPool(maxPoolSize int, stepLength int8, expansionCoefficient float32, reduceCoefficient float32, taskChannelSize int) *Pool {
p := &Pool{
maxPoolSize: maxPoolSize,
stepLength: stepLength,
expansionCoefficient: expansionCoefficient,
reduceCoefficient: reduceCoefficient,
taskChannelSize: taskChannelSize,
taskChannel: make(chan func(), taskChannelSize),
mutex: sync.Mutex{},
}
p.mutex.Lock()
p.expand()
p.mutex.Unlock()
return p
}
// AddTask 添加任务
func (p *Pool) AddTask(t func()) {
p.mutex.Lock()
length := len(p.taskChannel) + 1
coefficient := float32(float64(length) / float64(p.taskChannelSize))
fmt.Println("add task, coefficient:",coefficient)
if coefficient > p.expansionCoefficient && length+int(p.stepLength) <= p.maxPoolSize {
// 大于扩容系数并且当前长度+步长小于等于最大poolSize 执行扩容
p.expand()
} else if coefficient < p.reduceCoefficient && len(p.stopChannels) > int(p.stepLength) {
// 小于缩容系数并且协程数量大于步长 执行缩容
p.reduce()
}
p.mutex.Unlock()
p.taskChannel <- t
}
func (p *Pool) expand() {
fmt.Println("expand called. ")
// 执行扩容
// 初始化stepLength个stopChannel 并go出协程 将stopChannels放入管理对象
stopFlags := make([]chan struct{}, p.stepLength)
for i := 0; i < int(p.stepLength); i++ {
stopFlags[i] = make(chan struct{})
p.doGo(stopFlags[i], len(p.stopChannels)+i)
}
p.stopChannels = append(p.stopChannels, stopFlags...)
fmt.Println("expand done, routine size: ", len(p.stopChannels))
}
func (p *Pool) reduce() {
fmt.Println("reduce called. ")
// 执行缩容 从stopChannels最后面选择关闭stepLength个channel
// 并将其从对象中删除
endIndex := len(p.stopChannels) - int(p.stepLength) - 1
for i := len(p.stopChannels) - 1; i > endIndex; i-- {
close(p.stopChannels[i])
}
p.stopChannels = p.stopChannels[:endIndex+1]
fmt.Println("reduce done, routine size: ", len(p.stopChannels))
}
func (p *Pool) doGo(stopChannel chan struct{}, routineIndex int) {
go func() {
LOOP:
for {
select {
case <-stopChannel:
// stopChannel不阻塞 说明关闭了 协程结束退出循环
break LOOP
case t := <-p.taskChannel:
// 拿到task 执行
t()
}
}
fmt.Println("routine: ", routineIndex, "has stopped. ")
}()
}后续的分析过程将通过对比两种实现来进一步分析Ants。
Ants分析
模型
Ants模型如下图所示:
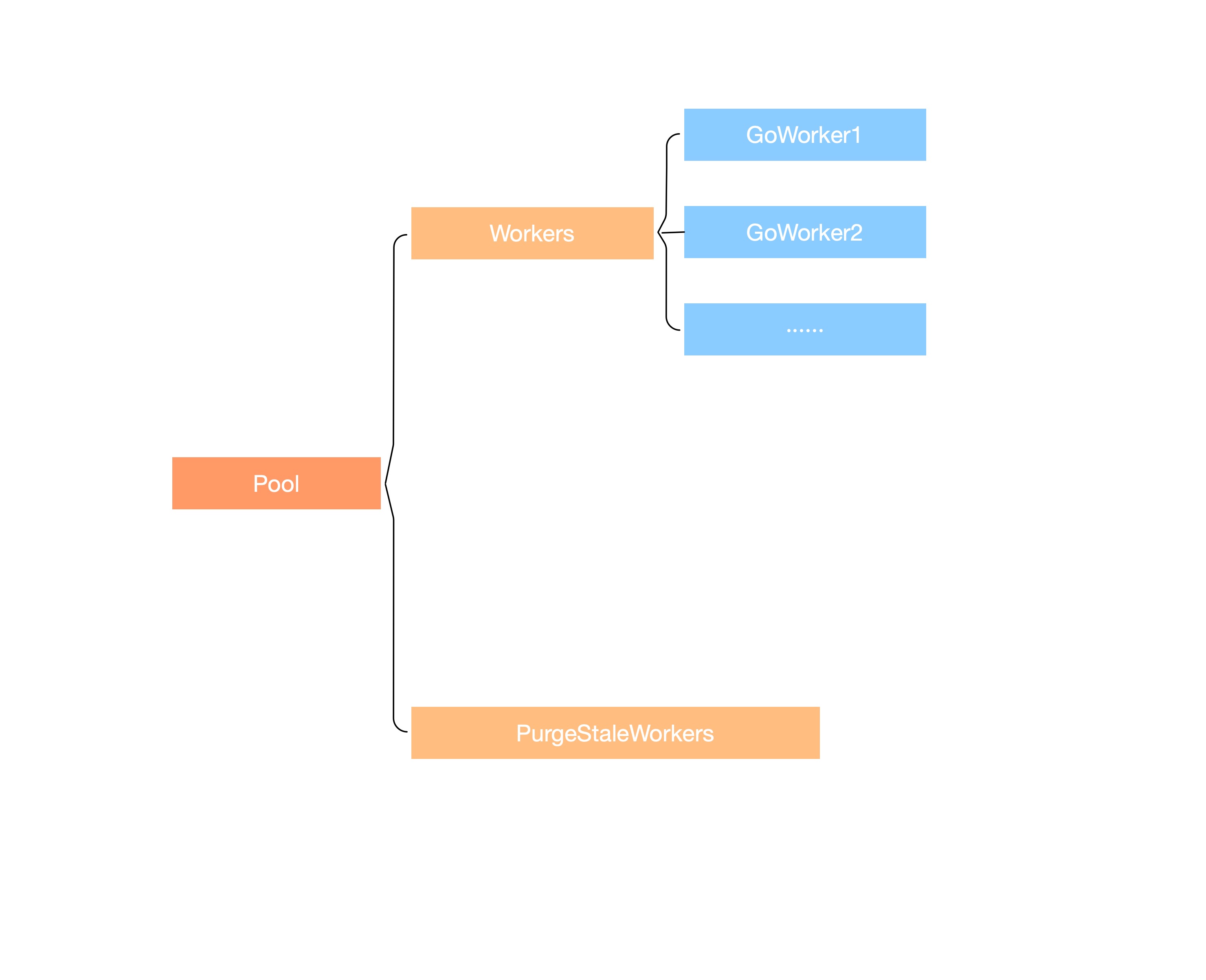
- Pool作为池对象,保存协程池状态属性、锁、协程、协程缓存等信息。
- Workers用于存储所有协程,在Ants中有循环队列和栈两种不同实现思路。
- GoWorker即协程对象,保存每个协程的任务队列(大小为0或1)及执行完上次任务的时间,是Ants中的协程单位。
- PurgeStaleWorkers作为守护协程,用于清理空闲协程。
协程池创建
协程池属性
在了解协程池创建之前,我们首先需要对Pool和Option各个属性进行分析并保留印象,在后续的分析中将离不开这些参数。
type poolCommon struct {
// 池容量, 负值为无限
capacity int32
// 正在运行的协程数量
running int32
// 用于保护协程容器 (workers) 的锁, 具体实现为 pkg/sync/spinlock.go
lock sync.Locker
// 协程容器, 具体实现有栈 (worker_stack.go) 和循环队列 (worker_loop_queue.go) 两种实现
workers workerQueue
// 协程池状态, 标记是否已经关闭
state int32
// 等待空闲协程的锁信号量
cond *sync.Cond
// 标记所有协程是否已经结束, 用于释放协程池时确保任务已经结束
allDone chan struct{}
// 确保协程池只会被关闭一次
once *sync.Once
// woker 缓冲池, 当一个协程结束后会放入此缓冲池, 减少频繁内存分配
workerCache sync.Pool
// 正在等待可用协程的任务数量
waiting int32
// 几个标记清理空闲协程结束状态的信号量
purgeDone int32
purgeCtx context.Context
stopPurge context.CancelFunc
// 几个时间更新协程结束状态的信号量
ticktockDone int32
ticktockCtx context.Context
stopTicktock context.CancelFunc
now atomic.Value
options *Options
}
type Options struct {
// 空闲过期时间, 当协程空闲时间超过此时间后将被回收, 默认为 1s
ExpiryDuration time.Duration
// 是否提前分配内存
PreAlloc bool
// 最大阻塞等待的任务数量, 0 代表无限制
MaxBlockingTasks int
// 标记提交任务时若无空闲协程是否阻塞, 设置为 false, 则直接报错, 设置为 true, 则阻塞等待
Nonblocking bool
// worker 协程 panic 处理函数
PanicHandler func(any)
// Logger is the customized logger for logging info, if it is not set,
// default standard logger from log package is used.
Logger Logger
// 是否禁用空闲协程回收
DisablePurge bool
}创建函数
接下来我们对NewPool函数参数及其处理过程进行简要分析,理解协程池初始状态。
func NewPool(size int, options ...Option) (*Pool, error) {
pc, err := newPool(size, options...)
if err != nil {
return nil, err
}
pool := &Pool{poolCommon: pc}
// 设置 worker 缓存初始化方法
pool.workerCache.New = func() any {
return &goWorker{
pool: pool,
task: make(chan func(), workerChanCap),
}
}
return pool, nil
}
func newPool(size int, options ...Option) (*poolCommon, error) {
// 如果size为0, 则置为-1, 标记其为无限容量
if size <= 0 {
size = -1
}
opts := loadOptions(options...)
if !opts.DisablePurge {
// 不禁用空闲协程检测, 校验空闲过期时间, 不合法则抛出异常, 若为0则置为默认值1s
if expiry := opts.ExpiryDuration; expiry < 0 {
return nil, ErrInvalidPoolExpiry
} else if expiry == 0 {
opts.ExpiryDuration = DefaultCleanIntervalTime
}
}
if opts.Logger == nil {
opts.Logger = defaultLogger
}
p := &poolCommon{
capacity: int32(size),
allDone: make(chan struct{}),
lock: syncx.NewSpinLock(),
once: &sync.Once{},
options: opts,
}
// 如果要提前进行 workers 内存分配, 则创建循环队列实例, 否则创建栈实例
if p.options.PreAlloc {
if size == -1 {
return nil, ErrInvalidPreAllocSize
}
p.workers = newWorkerQueue(queueTypeLoopQueue, size)
} else {
p.workers = newWorkerQueue(queueTypeStack, 0)
}
p.cond = sync.NewCond(p.lock)
p.goPurge()
p.goTicktock()
return p, nil
}通过阅读源码,我们可以看到NewPool函数主要做了以下几件事:
- 组装Options并设置默认值。
- 实例化Pool对象。
- 设置协程对象池实例化函数。
- 实例化 worker 容器。
- 启动空闲协程清理守护协程和时间更新协程。
在协程对象的实例化函数中,我们可以看到 worker 任务队列的容量是由 workerChanCap 函数返回的。
- 当运行时 P 的数量为1时,创建 channel 为0的阻塞队列。这里有一个关于 channel 特性的问题,在新版本实现中,即使非阻塞队列,若队列目前为空,发送协程推送消息后,则会立刻唤醒接收线程处理消息,以此来提高效率。但在 go1.5 及以下版本只有在阻塞队列中才有此特性,因此只有一个 P 时,需要将 channel 容量设置为0来提高效率。
- 当运行 P 的数量大于1时,channel 返回容量为 1,发送协程推送消息后继续执行后续任务。
workerChanCap = func() int {
// 如果 P 的个数为1, 则创建容量为0的阻塞式 channel
if runtime.GOMAXPROCS(0) == 1 {
return 0
}
// 否则返回1, 非阻塞式
return 1
}()在NewPool函数执行完成后,协程池初始化完毕,可接收任务,但此时并未创建协程,WorkerQueue 为空,即 Ants 协程创建策略为惰性创建。
WorkerQueue
WorkerQueue是一个抽象接口,实现该接口的结构体主要负责维护worker实例,提供插入、取出worker及扫描空闲实例等方法。在Ants中具体实现有两种,循环队列和栈。
type workerQueue interface {
len() int
isEmpty() bool
insert(worker) error
detach() worker
// 查询空闲过期协程
refresh(duration time.Duration) []worker
// 清理所有协程
reset()
}LoopQueue
LoopQueue是一个循环队列,在此不对循环队列做过多讲解,只针对几个重点操作分析。在Ants中,LoopQueue被用于预先根据Pool Size分配worker存储切片。
type loopQueue struct {
// 协程实例
items []worker
// 过期协程数组
expiry []worker
head int
tail int
size int
isFull bool
}
需要着重说明一下 expiry 这个过期协程数组,由于过期协程检测较为频繁,这个数组用于存储过期的 worker, 可以复用存储空间,不需要再重新分配内存,同时减小 GC 压力。
重点看一下空闲时间扫描,我们可知在items队列中每个协程最终执行任务的时间是有序递增的,因此在空闲超时扫描中只需要计算出阈值时间,使用二分查找即可找到空闲协程。
func (wq *loopQueue) refresh(duration time.Duration) []worker {
// 计算过期起始时间
expiryTime := time.Now().Add(-duration)
// 执行二分查找, 找到时间分割下标
index := wq.binarySearch(expiryTime)
if index == -1 {
return nil
}
wq.expiry = wq.expiry[:0]
if wq.head <= index {
// index 大于等于头标,直接将 head 到 index 部分加入到过期数组
wq.expiry = append(wq.expiry, wq.items[wq.head:index+1]...)
for i := wq.head; i < index+1; i++ {
// 将数组中过期的 worker 置为 nil, 解引用, 避免内存泄漏
wq.items[i] = nil
}
} else {
// index 小于头标, 组装首尾部分 worker 填充到过期数组
wq.expiry = append(wq.expiry, wq.items[0:index+1]...)
wq.expiry = append(wq.expiry, wq.items[wq.head:]...)
for i := 0; i < index+1; i++ {
wq.items[i] = nil
}
for i := wq.head; i < wq.size; i++ {
wq.items[i] = nil
}
}
// 更新 head 下标
head := (index + 1) % wq.size
wq.head = head
if len(wq.expiry) > 0 {
wq.isFull = false
}
return wq.expiry
}重点说明一下对items中被回收的worker实例置为nil,主要目的是为了解引用。系统在经历大流量洪峰后items中可能存在大量的worker实例,经过多次执行空闲回收后,假设items中实例未置为nil,回收后的worker将存储在workCache(sync.Pool)中,由于sync.Pool在获取实例速度变慢后的两个GC周期内会清理各个P缓存中的实例,此时被清理的实例应当被GC。但是由于items中仍然对该实例存在引用,不能对其回收,则产生了内存泄漏。同样的操作在detach方法中也有涉及。相关PR。
StackQueue
StackQueue维护了一个栈,栈中存放有worker实例,根据栈先入后出原则,每次Pop从切片最后一个元素取出,又由于golang slice特性,截取删除最后一个元素只是修改len属性,不会触发真正意义上的数组连续内存变更,故只有触发切片扩容时会导致底层内存的重新分配。
StackQueue在Ants中被用于不进行预先分配worker内存的情况下(PreAlloc为false),可通过切片扩容适应大量协程。同时请注意栈先入后出的原则可以帮助栈顶协程提高利用率,同时栈底协程可被尽快回收。
StackQueue操作大多与LoopQueue相同,此处不做过多展开,感兴趣的同学可查看源码。在此只分析一个小细节,前面我提到了slice特性,那么如果协程过期栈底元素需要弹出的时候怎么操作呢?
有同学会说可以直接找到index然后expiry[:index],这不符合栈的定义,但是却是最简单的实现。
然后我们再继续分析一下,如果这样做了slice的连续内存空间是否有所变动?是否会在一定程度上不利于内存的复用?
因此Ants在这里做了数据偏移,以确保内存复用,尽量在极端情况下不触发大量扩容。
func (ws *workerStack) refresh(duration time.Duration) []worker {
n := ws.len()
if n == 0 {
return nil
}
expiryTime := time.Now().Add(-duration)
index := ws.binarySearch(0, n-1, expiryTime)
ws.expiry = ws.expiry[:0]
if index != -1 {
ws.expiry = append(ws.expiry, ws.items[:index+1]...)
// 将 items 做偏移
m := copy(ws.items, ws.items[index+1:])
// 解引用
for i := m; i < n; i++ {
ws.items[i] = nil
}
ws.items = ws.items[:m]
}
return ws.expiry
}任务提交
Ants任务提交中涉及到自旋锁的实现及提交过程中的一些参数校验,接下来将一一详细展开。
自旋锁
Ants中实现了指数退避自旋锁,具体代码在sync/spinlock.go中, 可通过spinlock_test.go对其进行性能测试。值得一提的是,在Golang中实现指数退避只需要将当前P执行权交还给g0重新进行协程调度即可,具体实现如下。
type spinLock uint32
func (sl *spinLock) Lock() {
backoff := 1
// cas 成功则返回
for !atomic.CompareAndSwapUint32((*uint32)(sl), 0, 1) {
// 失败进入backoff
for i := 0; i < backoff; i++ {
runtime.Gosched()
}
if backoff < maxBackoff {
backoff <<= 1
}
}
}GoWorker
goWorker的实现并不复杂,它主要维护协程、一个 task channel 和回收时间,并不断接收任务并处理。
type goWorker struct {
worker
// 拥有该worker的协程池
pool *Pool
// 任务队列
task chan func()
// 上次执行完任务的时间
lastUsed time.Time
}
// run函数负责启动协程
func (w *goWorker) run() {
w.pool.addRunning(1)
go func() {
defer func() {
if w.pool.addRunning(-1) == 0 && w.pool.IsClosed() {
// 如果正在运行的协程为 0 且协程池已经关闭, 关闭 allDone channel
w.pool.once.Do(func() {
close(w.pool.allDone)
})
}
// 回收当前 worker 实例到缓存
w.pool.workerCache.Put(w)
if p := recover(); p != nil {
if ph := w.pool.options.PanicHandler; ph != nil {
ph(p)
} else {
w.pool.options.Logger.Printf("worker exits from panic: %v\n%s\n", p, debug.Stack())
}
}
// 唤醒一个正在等待的submit 因为当前 worker 结束意味着可以新建一个worker
w.pool.cond.Signal()
}()
for fn := range w.task {
// 收到 nil 时退出当前协程
if fn == nil {
return
}
fn()
// 将 worker 添加到可用队列
if ok := w.pool.revertWorker(w); !ok {
return
}
}
}()
}任务调度
在看源码之前,我们知道任务的提交就是寻找可用worker并将func添加到队列中。在前面分析 workers 时提到过可以通过调用 detach来弹出可用 worker。
那么如果没有可用 worker 会发生什么?如果为阻塞模式并达到了最大阻塞数量会发生什么?在任务执行完成后如何回收worker?
func (p *Pool) Submit(task func()) error {
// 校验协程池是否关闭
if p.IsClosed() {
return ErrPoolClosed
}
// 取可用 worker
w, err := p.retrieveWorker()
if w != nil {
w.inputFunc(task)
}
return err
}
func (p *poolCommon) retrieveWorker() (w worker, err error) {
p.lock.Lock()
retry:
// 尝试从 workers 容器中取一个可用的 worker
if w = p.workers.detach(); w != nil {
p.lock.Unlock()
return
}
// 协程数量没有达到最大容量,创建新的协程并执行
if capacity := p.Cap(); capacity == -1 || capacity > p.Running() {
p.lock.Unlock()
// 这里先解锁后创建协程,可能由于并发问题会导致创建多个 worker 出来,协程数量可能会大于容量,这类似于一种弹性策略
w = p.workerCache.Get().(worker)
w.run()
return
}
// 非阻塞式或者等待任务数量大于最大阻塞任务数量,直接报错
if p.options.Nonblocking || (p.options.MaxBlockingTasks != 0 && p.Waiting() >= p.options.MaxBlockingTasks) {
p.lock.Unlock()
return nil, ErrPoolOverload
}
p.addWaiting(1)
p.cond.Wait()
p.addWaiting(-1)
if p.IsClosed() {
p.lock.Unlock()
return nil, ErrPoolClosed
}
// 获取失败则重新从阻塞开始
goto retry
}调度流程并不复杂,使用cond的原因也是因为retry代码块被多次执行,会导致 cpu 占用率飙高,cond wait可将执行权交予其它协程,提高效率。
{kind=link}
任务完成后协程需要加入到 worker 容器中作为空闲协程供其它任务使用,我们在前面分析 worker 时知道回收过程由 worker 调用 Pool的 revertWorker 实现,那么接下来我们详细分析 revertWorker。
func (p *poolCommon) revertWorker(worker worker) bool {
// 首先校验当前正在运行协程数量是否大于容量
// 若是则直接返回 这个判断对应前面提到的先解锁后创建协程的弹性机制 此判断用于兜底并结束多余协程
if capacity := p.Cap(); (capacity > 0 && p.Running() > capacity) || p.IsClosed() {
p.cond.Broadcast()
return false
}
worker.setLastUsedTime(p.nowTime())
p.lock.Lock()
if p.IsClosed() {
p.lock.Unlock()
return false
}
// 插入空闲协程
if err := p.workers.insert(worker); err != nil {
p.lock.Unlock()
return false
}
p.cond.Signal()
p.lock.Unlock()
return true
}空闲协程清理
前面我们提到每个worker保存最后一个任务执行完成的时间,在pool初始化完成后启动了purge守护协程用于定时扫描workers中超过指定时间没有执行任务的协程并完成清理。接下来我们详细分析Pool purgeStaleWorkers方法来完善空闲协程清理的生命周期。
func (p *poolCommon) purgeStaleWorkers() {
ticker := time.NewTicker(p.options.ExpiryDuration)
defer func() {
ticker.Stop()
atomic.StoreInt32(&p.purgeDone, 1)
}()
purgeCtx := p.purgeCtx // copy to the local variable to avoid race from Reboot()
for {
select {
case <-purgeCtx.Done():
return
case <-ticker.C:
}
if p.IsClosed() {
break
}
var isDormant bool
p.lock.Lock()
// 加锁 从 workers 中获取空闲超时 worker
staleWorkers := p.workers.refresh(p.options.ExpiryDuration)
n := p.Running()
isDormant = n == 0 || n == len(staleWorkers)
p.lock.Unlock()
// 清理空闲 workers
for i := range staleWorkers {
staleWorkers[i].finish()
staleWorkers[i] = nil
}
if isDormant && p.Waiting() > 0 {
p.cond.Broadcast()
}
}
}其它操作
容量变更
Ants协程池容量变更通过调用Tune方法完成,但有几个特定条件是无法完成变更的:
- 容量原本就是无限。
- 变更后的容量为无限。
- PreAlloc为true, Ants已经分配好了loopQueue作为其workers,无法变更。
除以上条件外,还有两种情况:
- 扩容,需要唤醒一个或多个阻塞协程。
- 缩容,无需操作,等待worker被调用,在回收(revertWorker)时协程会被停止。
func (p *Pool) Tune(size int) {
// 取旧容量
capacity := p.Cap()
// 判断是否满足调整条件
if capacity == -1 || size <= 0 || size == capacity || p.options.PreAlloc {
return
}
// 更新容量大小
atomic.StoreInt32(&p.capacity, int32(size))
if size > capacity {
// 如果新容量大于旧容量
// 根据差值判断,只大1则只需要唤醒一个阻塞等待协程
// 否则唤醒所有等待协程
if size-capacity == 1 {
p.cond.Signal()
return
}
p.cond.Broadcast()
}
}预热协程
前面提到过,ants 的协程创建策略是惰性的,因此在冷启动情况下可能会存在一些性能问题。针对此问题,我们可以通过预热的方式刺激 ants 创建协程为即将到来的流量做出准备。
func TestPool(t *testing.T) {
initialSize := 20
p, _ := ants.NewPool(0)
// 提交空任务 预热
for i := 0; i < initialSize; i++ {
p.Submit(func() {})
}
// do something
}总结
至此,Ants源码分析已经结束,让我们重新回顾开篇提到的问题,看看Ants是怎么做的?
- 对于问题1,ants采用惰性创建策略,需要使用时才会创建协程。而在我的实现中采用了初始化创建+扩容的方式,具体两种方式的优劣需要考虑具体场景。如果需要解决冷启动问题,对ants pool进行预热也是个不错的选择。
- 对于问题2,ants维护了空闲工作队列,使用worker对象封装了协程,每个worker实例中channel的长度为0或1 。在我的实现中采用了全局channel,这种方式其实并不是太好,因为channel size很难确定,uber在golang编程规范中提到过,channel的size只能为0或1 。
- 对于问题3,先进先出可能会导致取出来的协程已经被放置到全局队列,调度过程可能会有更多消耗。
- 对于问题4,ants采用空闲时间计算的方式配合守护协程进行协程清理。个人实现中采用了被动提交任务时进行简单的负载计算并对协程组进行扩缩容,在缩容方面有一定的延时性。