供稿来自:@倪颖峰
零、AI 的思考
AI 时代的硬核技能
- 通过实践,了解 AI 能力的边界,逐步来明确 AI 擅长什么,不擅长什么。
- 基于实践,加强对自身能力的了解,对比 AI 的优劣势,更好的与 AI 协作,而非整体替代。
- 从 AI 探索实践中来发现双向的问题、分析原因,迭代个人能力与知识建设。
AI 擅长什么?
- 明确任务的技术方案设计、架构搭建、逻辑模块拆分,以及函数级别的编码能力;
- 极强的学习、参考与模仿能力,基于上下文进行代码预测、补全生成等,以及代码的检测和修复;
- 高质量地从 0 到 1 建设项目、独立模块建设,极强的代码分析、添加注释和撰写文档能力;
- 基于海量代码 + 大模型的自然语言能力的角度去理解,AI 能准确与高质量完成事情的范围;
AI 不擅长做什么?
- 复杂、特定领域的业务需求和逻辑的辅助支持;(本质:缺乏复杂、特定所需的上下文信息,难以内容化。)
- 创新性的架构设计或者创新的解决方案;(本质:预训练模型,AI 生成内容,基本算是高质量伪原创的形式。)
- 模糊、不确定性或者宽泛的任务需求;(本质:自身都不明确任务,那么就别为难 AI 了。)
- 用户体验、交互设计方面;(本质:优秀的体验与交互,难以以语言描述。)
💪🏻 当然随着大模型的加强,AI 不擅长的领域也在逐渐加强,下面文中提出的 “AI认知工程”的建设训练,也开始将 AI 从超强的知识库,进化到具有一定“认知”的状态。
《生成式AI进入第二幕:交大携手创智学院提出「认知工程」,AI新纪元开始了》
一、背景
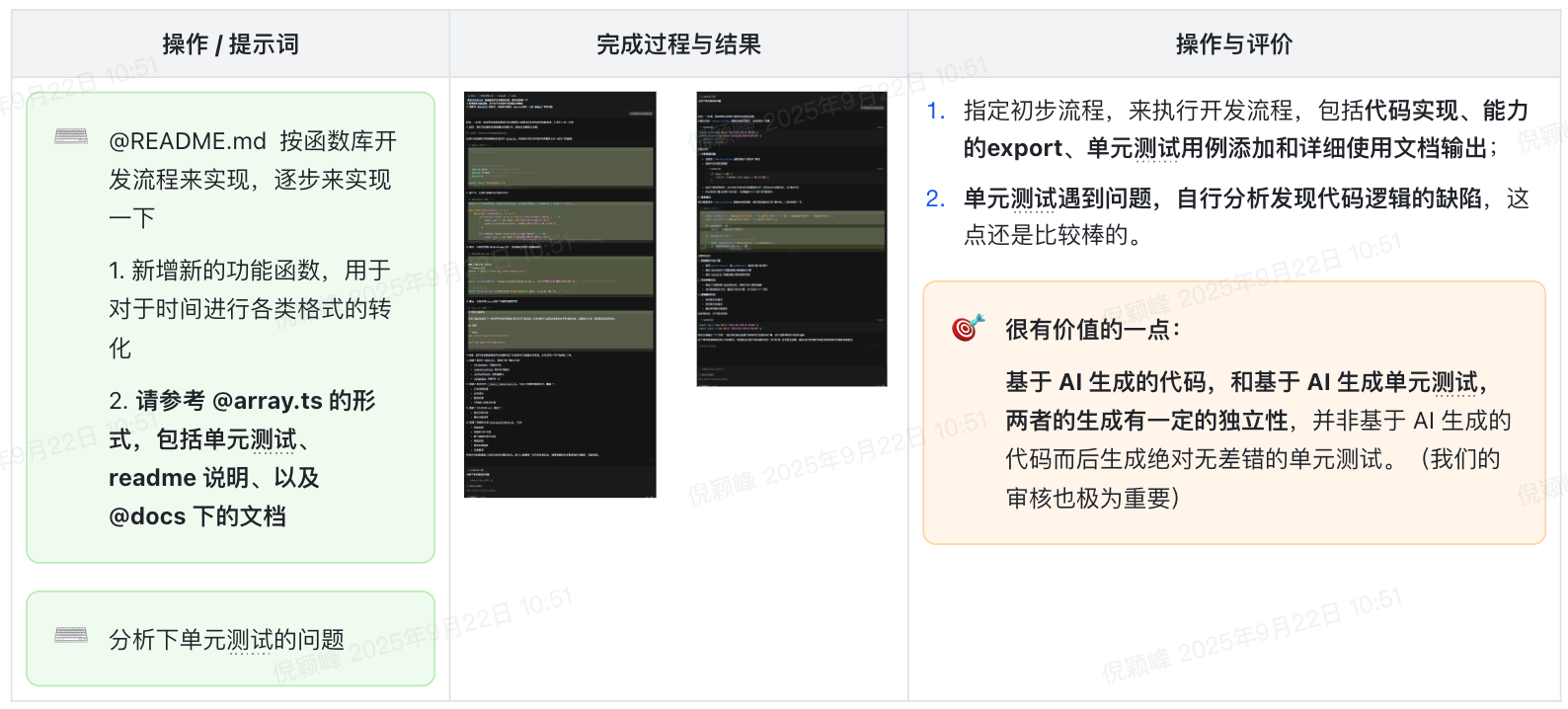
- 建设前端统一的工具函数库、完善工具库的测试用例与文档管理;
- 基于工具库实现定制 Rules,来用实现 AI 自动化工具库开发与 AI 自动化发版等系列操作;
注意:没有 AI 的时代,统一工具库建设成本与收益相比,性价比偏低,不易推进,有了 AI 其性价比直接飙升。而当前建设任务内容,均为 AI 强项:0-1项目、工具函数、测试用例、文档输出与管理。
二、日常操作:快速建设【熟练工可跳过】
1. 历史的 Monorepo 项目,先来总结个项目的概要介绍;

2. 按项目架构,新建 tools 子仓,并在 tools 上支持单元测试和基于 VitePress 的可视化文档。

3. 基础框架结构完成后,花个把小时来进行项目审核,确保当前架构满足目前的需要以及后续扩展。
熟练情况下,半小时内,绝对高质量的完成一个独立模块的搭建,包含单元测试与文档规范,整体大概小一天的工作量。但我们绝对不能省去项目审核的时间。(不熟练状态下,会遇到各类提示词的调试处理)
4. 而后基于 AI 辅助,开始对于各功能的填充,包括 代码 + 单测 + 文档 的系列操作。
5. 最后,大致项目架构如下
├── CHANGELOG.md
├── README.md
├── docs // 文档目录
│ ├── README.md // 文档目录下的说明文档
│ ├── array.md // 关于数组相关功能的详细文档
│ ├── cookie.md // 关于 cookie 相关功能的详细文档
│ └── ...
├── index.ts
├── jest.config.js // Jest 测试框架的配置文件
├── package.json // 项目配置文件
├── rollup.config.mjs // Rollup 打包工具的配置文件
├── src // 开发目录
│ ├── __tests__ // 单测目录
│ │ ├── array.test.ts
│ │ ├── cookie.test.ts
│ │ └── ...
│ ├── array.ts // 数组功能的实现代码文件
│ ├── cookie.ts // cookie 功能的实现代码文件
│ └── ...
└── tsconfig.json // TypeScript 的配置文件问题来了:
虽然整体流程都基于 AI 辅助高效完成,但是在处理功能新增或者修改时,我依旧需要 @ 一大堆文件、路径和信息,来确保 AI 处理范围的精确性。也还需要指定的在处理代码后,要求创建或修改单测文件和文档文件。但这些流程,原本就可以抽象出来!
三、重头戏:基于 AI 实现自然语言模式的自动化
本次期望解决的自动化模式任务:
- 在开发时,能自动化的进行相关资源关联参考,并且按流程进行单测、文档等创建与验证。
- 发包流程琐碎繁琐,按流程需要,AI 进行自动化运行处理。
那么开始吧:【具体自然语言脚本(或者说 Rule)见文章末尾】
1. 开发 tools 功能模块,自动化 AI 辅助开发流程:
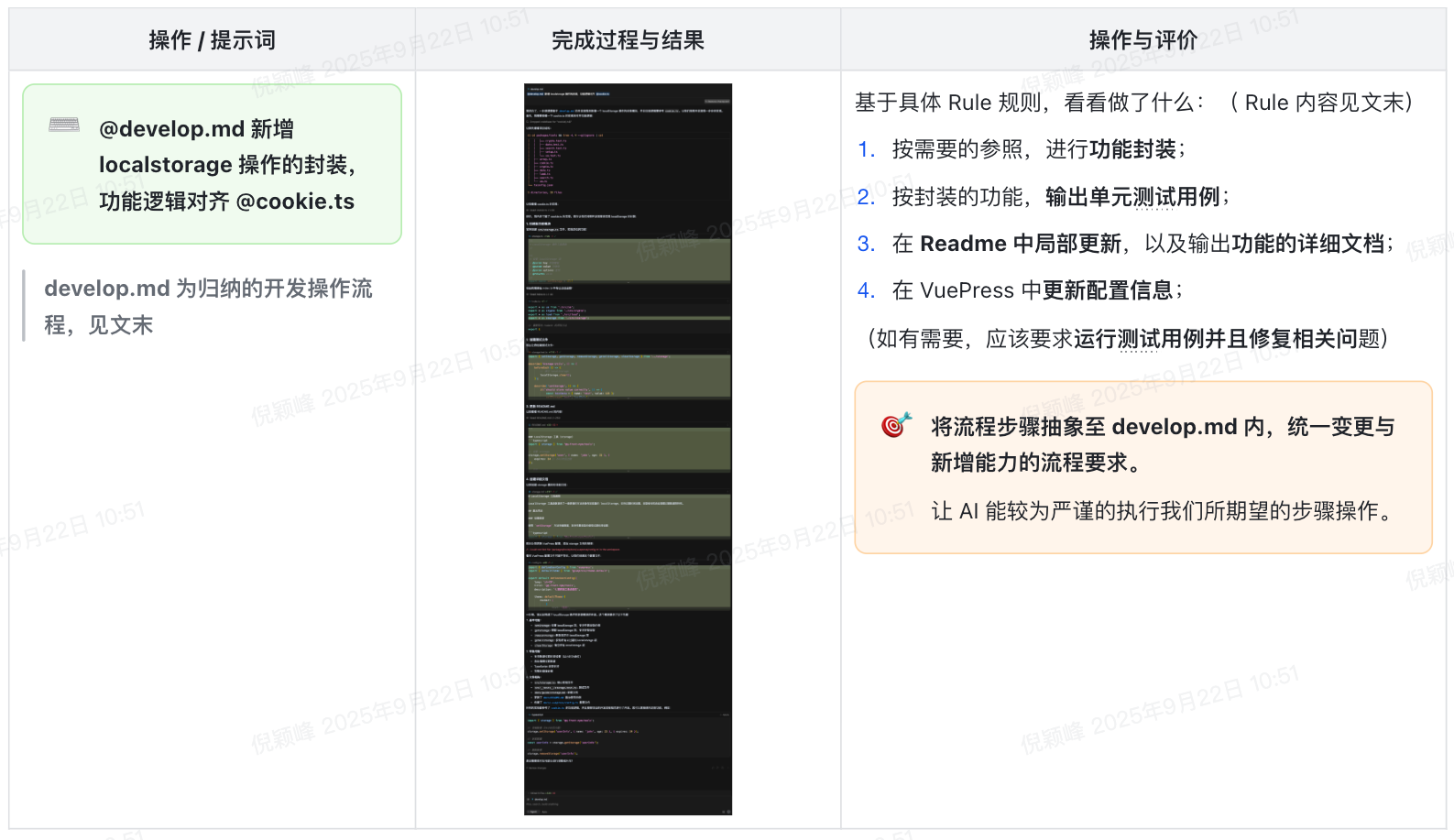
2. 实现自然语言的自动化脚本,避免较高成本的代码脚本开发,(见文末 publish.md Rule):

四、一些心得体会
- 高效和准确的使用 AI 是一门技能的学习,依赖我们不断实践,走些弯路,而后提升的熟悉度;
- 去让 AI 做明确的事,别让它猜你的想法,如果你自己都没计划好,那么先想清楚再说;
- 别把 AI 想得太聪明,降低做事的期望,结果往往会超出预期,期望太高时,我们的指令可能就会变形;
- 不要将 A、B、C 等一堆任务给 AI,试图让他来帮你来“思考”制定优秀的方案,拆分制定明确步骤,减少信息干扰,让 AI 更明白执行什么;(虽然有时可能超预期,有时又会走入 AI 的幻觉中)
- AI 在优秀项目里能发挥更大辅助价值,所以要做好历史项目里的规则、文档等建设工作;
- 和普通脚本模式相比,用自然语言写的 AI 脚本效率极高,但具有不确定性,需要调试打磨;
五、工具库特定 Rule
- Tools 功能开发自动化 Rules
# tools 开发流程
## 执行背景
- 执行要求:使用iTerm终端来执行流程命令
- 执行信息:了解下项目的 readme,位置 `./packages/tools/docs/README.md`
- 执行变量:
- 项目根目录: `./`
- tools目录: `./packages/tools`
- 需求能力:从上下文获取开发中所需要添加的能力
## 功能模块新增
### 1. 创建新功能模块
- 进入 `${tools目录}` 目录,在 src 下创建功能模块,并且在 `./index.ts` 中导出;类似参考 `./src/array.ts` 文件;
- 注意功能模块创建时,对于边缘场景case的考虑,比如参数类型,边界值,异常场景等;
### 2. 创建测试文件
- 进入 `${tools目录}` 目录,在 test 下创建功能模块的测试文件,类似参考 `./__test__/array.test.ts` 文件;
- 尽可能全面覆盖测试用例,包括但不限于正常场景,异常场景,边界场景等;
- 运行测试用例,确保功能模块的正确性;
### 3. 局部更新 README.md
- 进入 `${tools目录}` 目录,在 `./docs/README.md` 中,在 "使用方法" 中参考上下文新增功能模块的简单使用示例;
- 注意只处理新增内容的插入,不随便删除文档其他内容;
### 4. 创建文档
- 进入 `${tools目录}` 目录,在 `./docs` 目录下,创建功能模块的详细文档,类似参考 `./docs/array.md` 文件;
- 文档内容需要包含功能模块的详细说明,包括但不限于参数说明,返回值说明,使用示例等;
- 进入 `${tools目录}` 目录,处理 vuepress 的配置 `./docs/.vitepress/config.mts` 文件,新增功能模块的文档配置;
## 功能模块变更
- 按照 `执行步骤`,的操作流程,来变更代码以及相关联的内容。
- 变更代码时,需要考虑上下文,以及变更的影响范围。
## 执行规则
1. 严格按照步骤顺序执行,不随便执行其他理想化的shell指令,比如git commit和push等操作
2. 每个步骤必须等待上一步骤完成并获取其输出,输出必须被捕获并可用于后续步骤
3. 在条件分支点必须严格遵循定义的逻辑流程
4. 任何步骤失败都需要按照失败处理说明执行
## 输出要求
- 每个步骤执行前需要显示当前步骤信息
- 每个步骤完成后需要显示执行结果
- 错误和异常需要清晰记录
- 流程终止时需要提供终止原因
## 错误处理
- 记录所有错误信息
- 按照每个步骤定义的失败处理执行
- 提供错误发生时的上下文信息- Tools 自动化发包 Rules
# tools 包发布流程
## 执行背景
- 执行要求:使用iTerm终端来执行流程命令
- 执行变量:
- 项目根目录: `./`
- tools目录: `./packages/tools`
- 版本类型: 从上下文判定,是发布 `beta` 版本,还是 `正式` 版本
## 执行步骤
### 步骤 1: 运行测试用例
进入`${tools目录}`后执行:
```bash
pnpm test
```
- 成功条件: 所有测试用例通过,接入步骤 3
- 失败处理: 进入步骤 2
### 步骤 2: 用户确认(仅当测试失败时)
```bash
echo -n "测试未通过,是否继续?(y/n): " && read answer
```
- 条件判断:
- 如果 answer == "y": 继续执行步骤 3
- 如果 answer == "n": 终止流程
### 步骤 3: 执行 Changeset 环境判定
进入`${项目目录}`后执行:
如果 `${版本类型} === ’beta‘`, 则执行:
```bash
pnpm changeset pre enter beta
```
否则则执行:
```bash
pnpm changeset pre exit
```
- 成功条件: 用户输入完毕后,接入步骤 4
- 失败处理: 终止流程
### 步骤 4: 执行 Changeset 命令
```bash
pnpm changeset
```
- 成功条件: 用户输入完毕后,接入步骤 5
- 失败处理: 终止流程
### 步骤 5: 执行 Changeset version 命令
```bash
pnpm changeset version
```
- 成功条件: 执行完成
- 失败处理: 终止流程
- 输出要求: 捕获执行日志
### 步骤 6: 构建项目
进入`${tools目录}`后执行:
```bash
pnpm build
```
- 成功条件: 构建完成无错误
- 失败处理: 终止流程
- 输出要求: 捕获构建日志
### 步骤 7: 推送项目
```bash
npm publish
```
- 成功条件: 推送完成
- 输出要求: 记录推送结果
### 步骤 8: 确认是否提交代码
```bash
echo -n "是否提交变更与推送?(y/n): " && read isCommit
```
- 条件判断:
- 如果 isCommit == "y": 继续执行步骤 9
- 如果 isCommit == "n": 终止流程
### 步骤 9: 提交代码
进入`${项目目录}`后执行:
变量:
- 提交信息: 从上下文获取变更内容,生成 message 信息
```bash
git add .
git commit -m "${提交信息}"
git push
```
### 步骤结束
## 执行规则
1. 严格按照步骤顺序执行,不随便执行其他理想化的shell指令,比如git commit和push等操作
2. 每个步骤必须等待上一步骤完成并获取其输出,输出必须被捕获并可用于后续步骤
3. 在条件分支点必须严格遵循定义的逻辑流程
4. 任何步骤失败都需要按照失败处理说明执行
## 输出要求
- 每个步骤执行前需要显示当前步骤信息
- 每个步骤完成后需要显示执行结果
- 错误和异常需要清晰记录
- 流程终止时需要提供终止原因
## 错误处理
- 记录所有错误信息
- 按照每个步骤定义的失败处理执行
- 提供错误发生时的上下文信息