供稿来自:@李天鸣
写在前面
作为一个程序员,我们的工作本质上就是交付一行行的代码,那么对代码质量的把控始终都是重要的环节。本次 AI 代码评审的关键目标如下:
- 通过 AI 对代码的分析能力来辅助代码评审,提供不同视角来发现潜在的问题;
- 掌握 AI 应用工程化的核心开发流程与新技术的实践经验,为 AIOps 打下基础。
产品方案
经过讨论后,我们大致认为有以下几种方案:

在没有 AI 评审之前,我们就是通过云效来对问题的代码进行评论的。
最后我们采用了方案一。用户在无须任何额外配置的情况下,提交合并请求(MR)后会自动触发代码评审,流程如下:
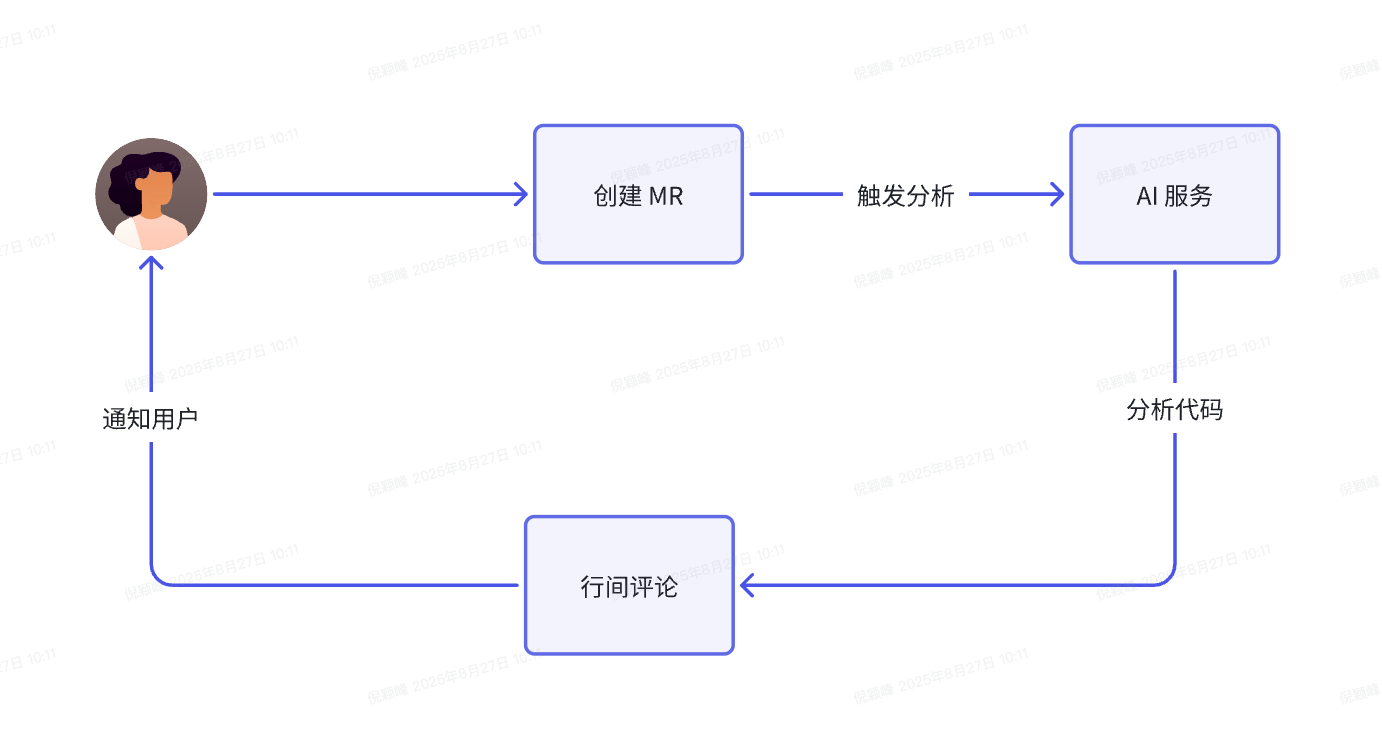
评论效果:
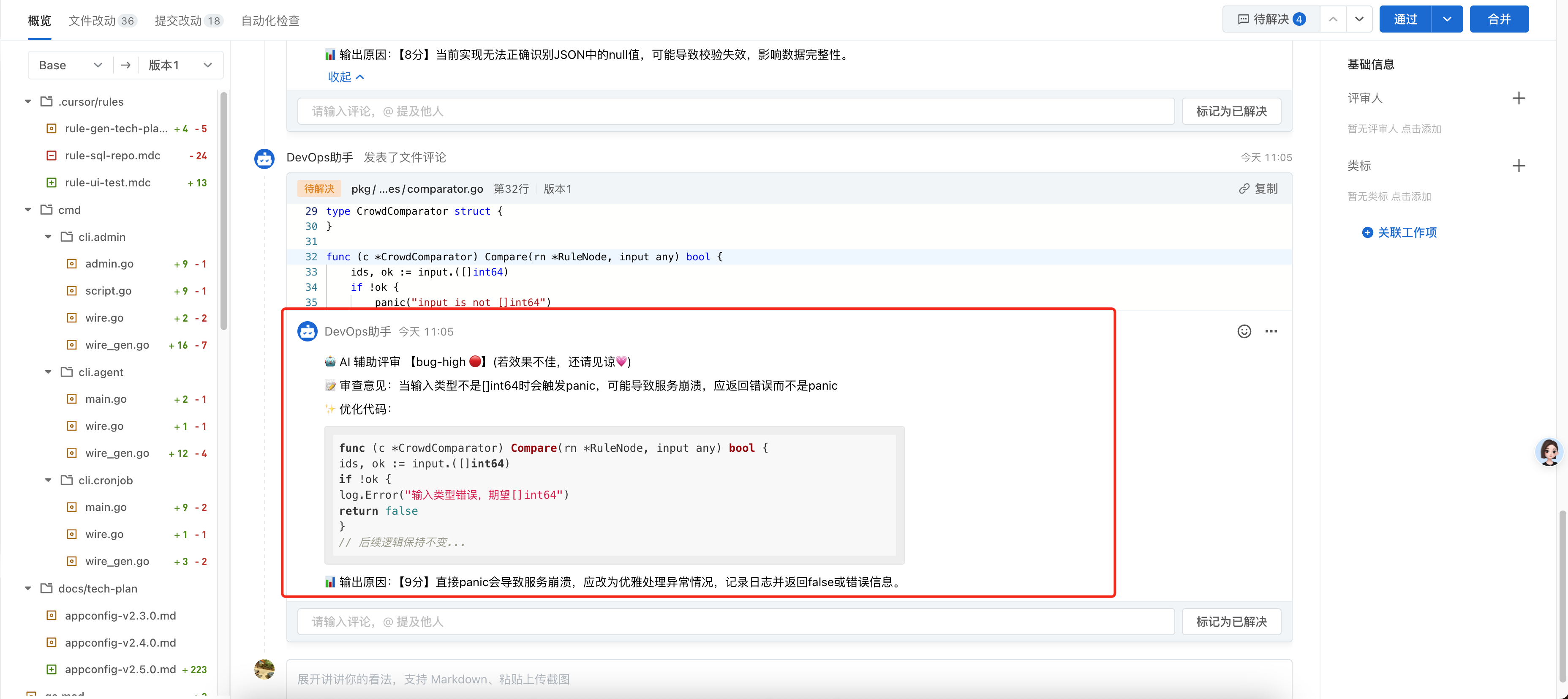
技术方案
技术选型
全代码 or 低代码 ?
👉 全代码。虽然目前各种低代码平台的功能也非常强大,但我们还是在可控性、稳定性、扩展性的角度来权衡,作为一个长期维护的项目,最后我们还是决定使用全代码来实现。
Python or Golang ?
👉 Golang。公司业务后端主要的语言为 golang,但是作为一个全新的项目我们并没有任何历史包袱,所以我们也认真考虑过是否要使用 AI 生态最为强大的 python ?不过最终我们认为项目的定位是为了解决企业内部的效率问题golang 已经足够用了。
手搓 or 框架?
👉 字节的 Eino 框架。经过技术调研,我们确定 AI Agent 开发模式具备一定的范式,比如“流程编排”必不可少,因为项目是以 LLM 为核心来进行开发的,而我们则是不断地对输入、输出进行调整。再比如“切面能力”业务逻辑中免不了对各个环节的调试。而这些能力框架都提供了,因此能够大幅提升开发效率。
业务流程
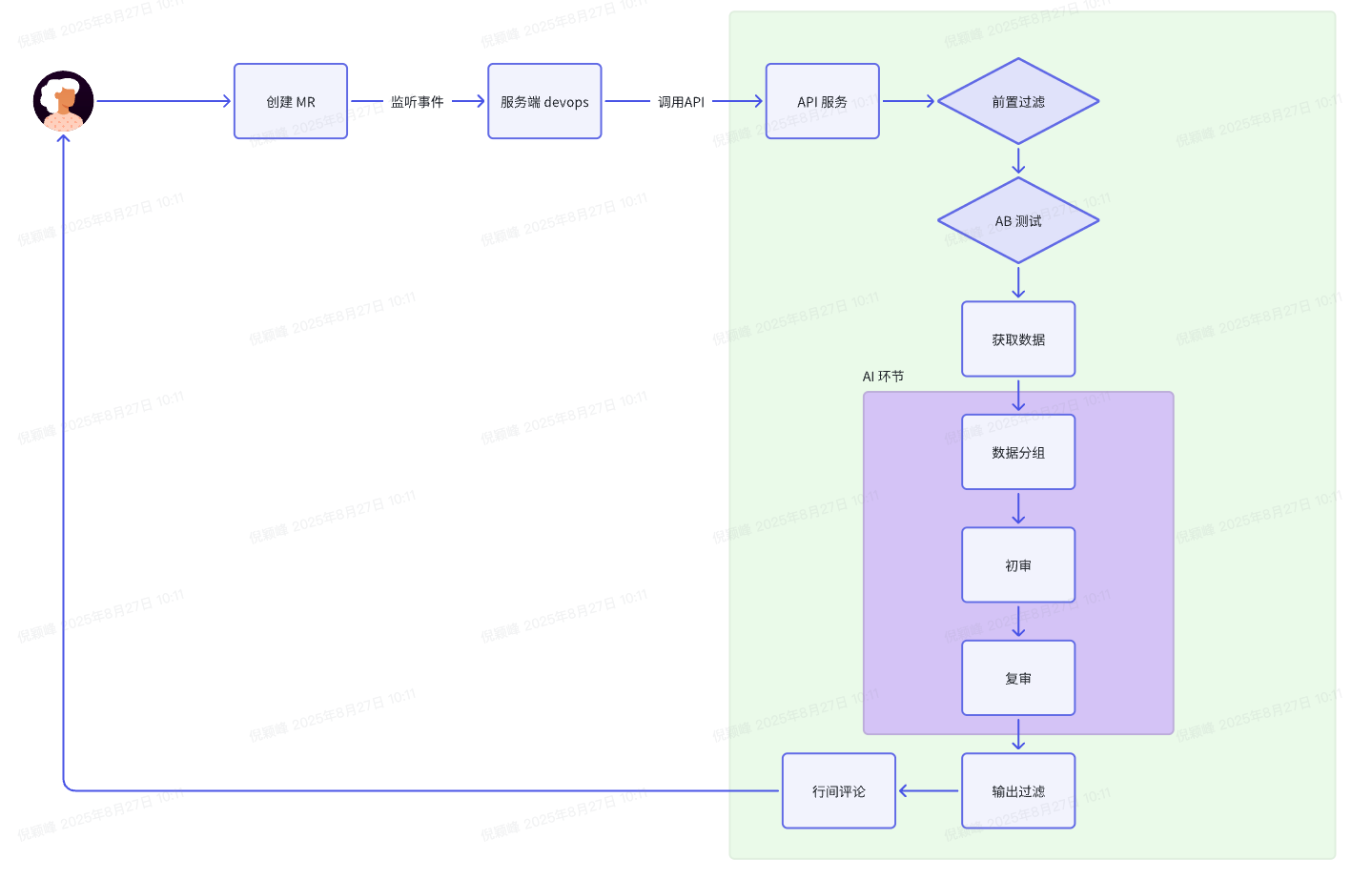
- 前置过滤:目前支持 <代码组> 和 <代码库> 两个级别的筛选设置。
- AB 测试:因为不同模型、不同提示词对输出结果的影响很大,所以在项目一开始设计了 AB 测试功能,方便后续的效果调优与功能迭代。
- 获取数据:目前会获取“增量”的 diff 数据、commit 数据、修改的代码文件等。
- 数据分组:分析给定的代码文件集合,基于代码的逻辑关系、功能相关性和依赖关系,将文件进行智能分组。
- 初审:对代码进行第一轮的评审,根据不同级别输出对应的内容:
- high: 高风险问题,影响核心功能或存在安全隐患,可能导致系统故障
- medium: 中等问题,影响用户体验或代码质量,可能影响业务流程
- info: 信息提示,代码规范或性能优化建议,不影响核心功能
- 复审:第二轮评审,根据第一轮的输出结果,以及相关数据来对问题打分。
- 输出过滤:根据打分由高到低排序,最终拿到 5 条评论(数量可配置)。
- 行间评论:调用云效 API 将结果反馈给用户。
项目排期
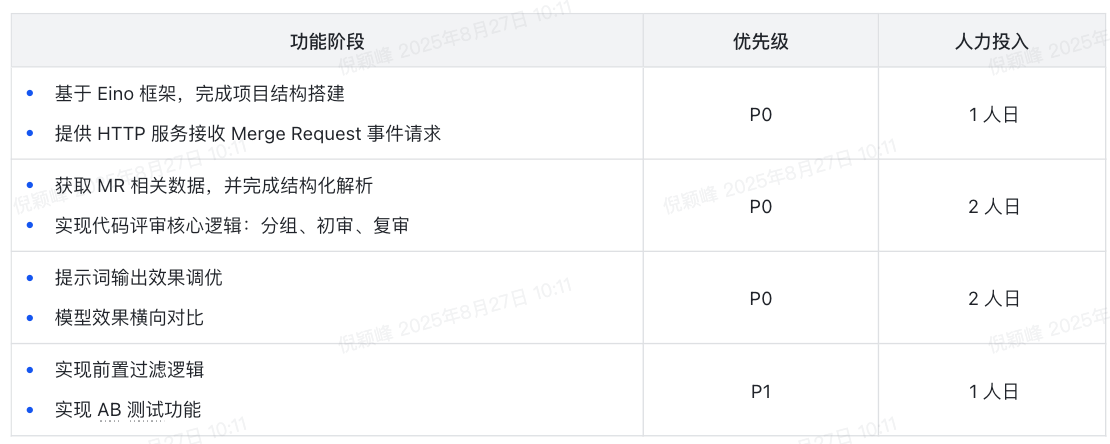
开发过程
流程编排
使用流程编排要求我们对步骤进行封装,定义好输入、输出的数据结构,然后进行组合:
func (f *Flow) compile() error {
chain := compose.NewChain[*CodeReviewRequest, string](compose.WithGenLocalState(func(ctx context.Context) *ReviewContext {
return &ReviewContext{}
}))
// 获取数据步骤
fetchLambda, fetchOpts := f.FetchLambda()
// 代码分组步骤
analysisLambda, analysisOpts := f.AnalysisLambda()
// 初审步骤
preReviewLambda, preReviewOpts := f.PreReviewLambda()
// 复审步骤
secondReviewLambda, secondReviewOpts := f.SecondReviewLambda()
// 流程是单向的链式编排
chain.AppendLambda(fetchLambda, fetchOpts...)
chain.AppendLambda(analysisLambda, analysisOpts...)
chain.AppendLambda(preReviewLambda, preReviewOpts...)
chain.AppendLambda(secondReviewLambda, secondReviewOpts...)
// 编译,对输入输出进行校验
runner, err := chain.Compile(context.Background())
if err != nil {
return err
}
f.runner = runner
return nil
}代码逻辑相对更清晰,可维护性强,根据业务需求的迭代只需要提供固定步骤,然后对编排逻辑进行改造即可。
数据结构
为了让大模型更好地理解代码评审的内容,我对 Diff 数据进行了结构化处理:

核心逻辑
是的,这里的核心逻辑已经不再是代码,而是由提示词构成的。

应用观测
与传统微服务一样 AI 应用同样需要进行观测,尤其是每次 token 消耗、API 调用 RT 等指标。感谢运维同学的大力支持 @郭子龙 目前已经提供 langfuse 平台。
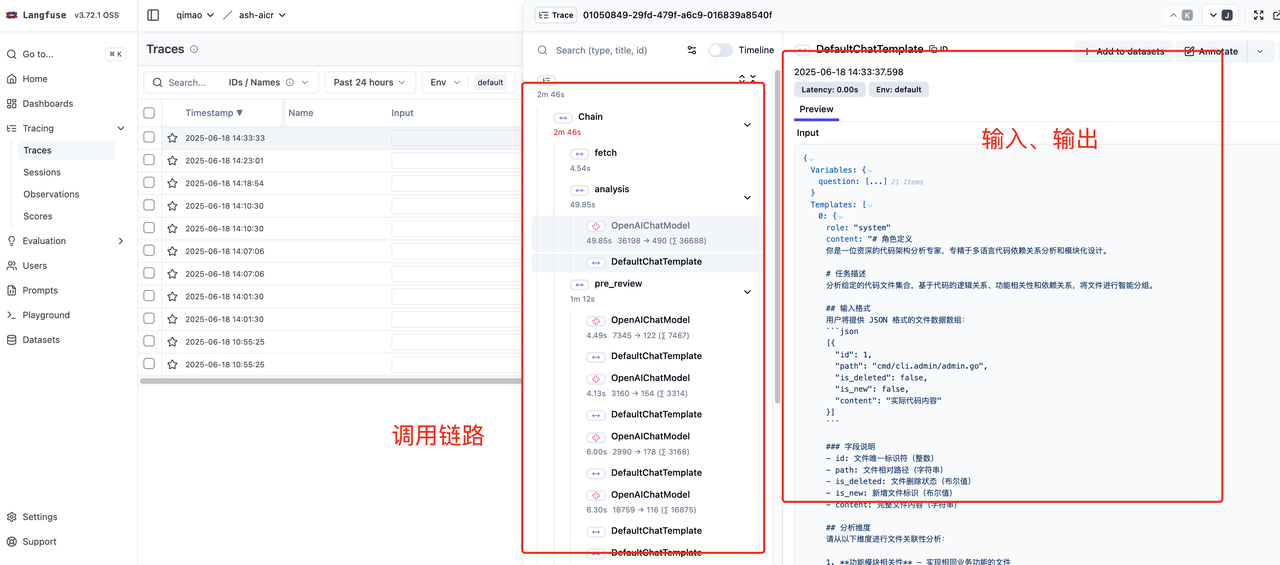
至此核心流程已经开发完成,能够监听 MR 事件 -> 获取数据 -> 分析代码 -> 行间评论。
效果调优
以下的测试内容,是针对一次真实的开发迭代来进行模拟的。代码变更行数 2000+,属于常规量级。
提示词优化
说是提示词优化,但是在实际过程中,我发现评审的最终效果始终达不到我的预期,所以在经过一天半的调整之后,我决定从数据结构开始重新设计。
由于篇幅的缘故,具体的过程就不做展开了,这里可以看到提示词的变更记录:
「初审阶段」最终线上版本传入给大模型的数据结构,可以看到这里我做了大量的减法:
[
{
"id": "文件编号",
"path": "文件路径",
"content": "文件完整内容",
"change_ranges": [
{
"start_line_number": "变更起始行号",
"end_line_number": "变更终止行号"
}
]
}
]理解大模型的能力边界
- 缺乏精确计算能力:在行间评论的业务需求中,需要精确定位到具体的问题行号,但是即便我把每一行 diff 的对应行号信息算好给到大模型,但是在评论的过程中依旧会出现大量的“行号漂移”。当然我们可以提供行号计算工具给大模型调用,但是在实际测试下来对 token 的消耗非常严重,出于对工程化的考量我最终放弃了使用大模型输出的行号数据。
- 多不等于好:当我把 diff 变更数据、diff 行号信息、对应的文件数据都给到大模型之后,我发现模型给出的答案很多都是断章取义,从结果反推来看大模型的回答似乎没有很好理解代码本身,再结合上述的行号问题,我在翻看它的审查结果时效率也非常低下。
工具推荐
AI 应用开发提示词优化的时间,可能才是占比最大的时间,所以一款趁手的工具十分必要。
这里推荐一个提示词优化工具 promptpilot ,可以很好地帮助我们提升效率。
模型选择
目前主要是基于三个维度来考量:效果、耗时、成本。
- 计费方式基于:阿里百炼平台。
- Token 数量:输入 100k 左右,输出 3k 左右。
数据分组阶段
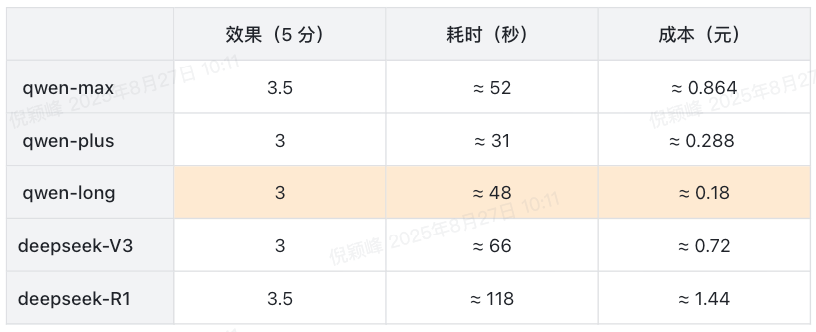
- 当前采用 qwen-long 因为需要考虑到新项目的极端情况,qwen-long 支持百万级的上下文。
代码分析阶段
这里理论上还可以分为初审和复审,因为时间关系还没来得及比较
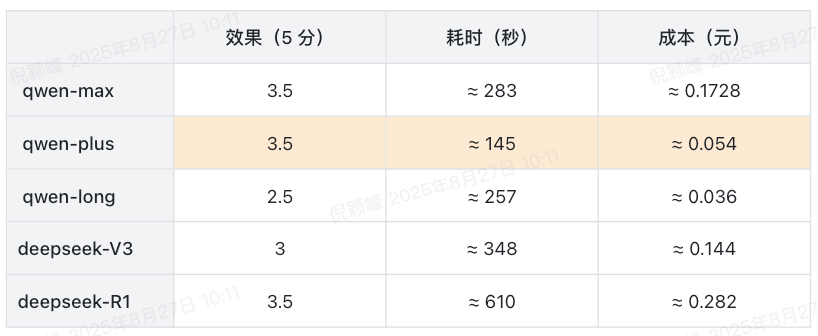
- 综合考量目前采用 qwen-plus 作为代码分析模型。
后续规划
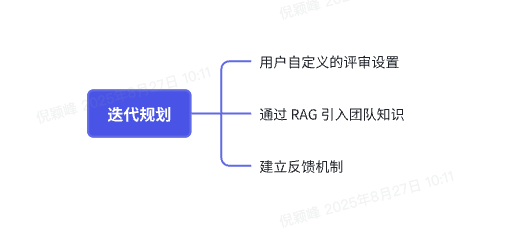
- 用户自定义的评审设置:通过自然语言描述代码评审的偏好
我只想要输出 high 级别的问题,数量不超过 3 条。对于支付流程的代码需要重点审查,是否有并发问题……- 通过 RAG 引入团队知识:目前各个业务方的业务模式是相对独立的,团队内部自治的规范,尤其是特定场景的业务知识,难以从公司层面做统一,但是又非常有实用价值,能够更好地辅助代码质量的评估。
- 建立反馈机制:不同用户对评审的结果也有不同的要求,通过收集用户反馈 + LLM 分析能力,来持续优化结果输出。
AI 应用的价值
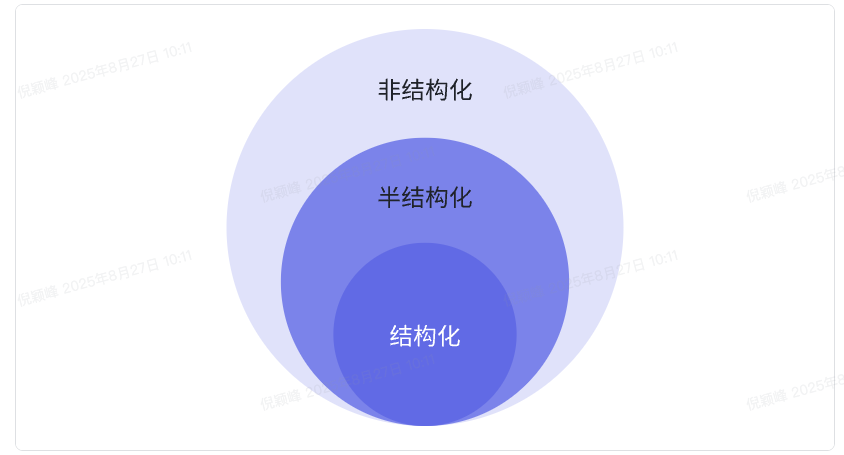
- 「结构化」数据:数据具有高度的规范性和规律性,就像是整齐排列在货架上的商品,每一项都有着明确的定义、固定的格式和清晰的逻辑关系。
- 「半结构化」数据:它的结构更为灵活和松散,例如 XML 文档,其中既有标签来表示一定的结构,又允许在标签内有相对自由的文本内容。
- 「非结构化」数据:几乎没有明显的结构,像大量的文本文件、图片、音频和视频等。在传统互联网的发展进程中,其处理的数据范围主要集中于“结构化”数据。对于“半结构化”和“非结构化”数据,传统互联网的处理能力则相对有限。然而,在大语言模型时代,情况发生了明显改变。 我们可以通过 AI 应用开发来挖掘、加工、分析这部分的数据,解决传统编程无法处理的问题,从而提升企业的生产效率。