PART1:背景介绍
当互联网产品的用户达到一定量级后,性能测试是必不可少的一个测试环节。
相比于传统的性能测试工具(loadrunner和jmeter),阿里云PTS(Performance Testing Service)是面向所有技术背景人员的云化测试工具,有别于传统工具的繁琐, PTS以互联网化的交互,提供性能测试、API调试和监测等多种能力。
很多测试人员虽然会使用性能测试工具,但是对于目标TPS的估算、压测场景的配置、压测结果的分析、压测指标的解读、瓶颈问题的分析等等方面还存在一些不足和误区。
因此,本篇以PTS工具为载体,讲解了一次性能测试的完整实践,旨在帮助测试人员在学会运用PTS工具的同时,对性能测试能有更深入的理解。
PART2:PTS简要介绍
打开PTS压测工具:https://pts.console.aliyun.com/#/overviewpage,工具首页如下:
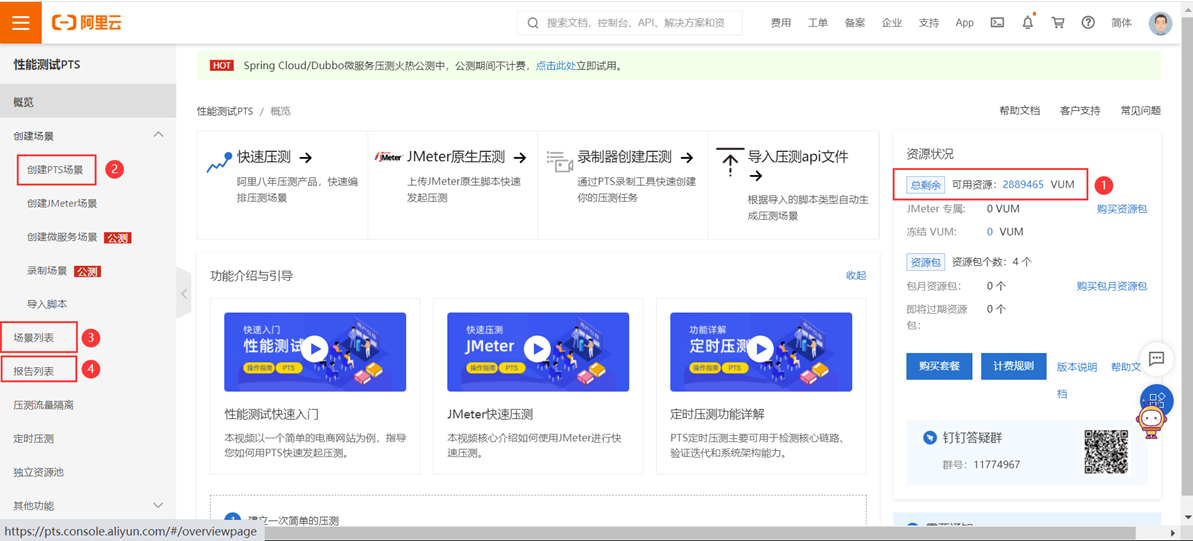
①可用资源VUM: 一次压测消耗的VUM=VU * Minute,即设置的最大并发数 * 运行的时长。如800并发运行1分钟,或者400并发运行2分钟,都是消耗800VUM,以此类推。VUM是需要钱购买的,因此需要节约着使用:比如在调试阶段,可以点击页面中的"调试场景"功能来调试,该功能不消耗VUM;即使设置较小的并发,但是设置较多的扩展ip,也会产生较大的VUM,这一点也需要注意,如下图:

②创建压测场景:可以参考:https://help.aliyun.com/document_detail/102753.html?spm=a2c4g.11186623.6.622.3bf84215jlykJr,写的很详细了;如果需要多串联链路,如何设置以及多串联链路的意义,可以参考https://help.aliyun.com/document_detail/95647.html?spm=a2c4g.11186623.6.621.48f72607UWdbIG
③压测场景:查看现有的压测场景,可以对场景进行:启动/编辑/删除/复制 操作
④压测报告:查看已生成的压测报告,可以参考:https://help.aliyun.com/document_detail/65304.html?spm=5176.11065259.1996646101.searchclickresult.19ba74119HzEnj&aly_as=crkUZKdV
几个重要指标的说明
(1)PTS中的并发数:对应jmeter中的虚拟线程数,即可以产生压力的线程数量。
该值越大,即对服务器施加的压力越大,但服务器每秒能处理的请求数(TPS),不完全与该值成正比,例如服务器性能出现下降的情况,响应时间也会随之增长,可能出现加大并发数,但是TPS不增长甚至下降的情况。
(2)TPS:服务器每秒处理的请求数
(3)平均响应时间:压测期间,请求的平均响应时间
(4)三个指标之间的计算关系: TPS = 并发(虚拟线程数) / 平均响应时间
假设对接口A压测,设置4个并发,请求平均响应时间是0.1秒,则效果如下图:
线程1:A---0.1s---A---0.1s---A---0.1s---A---0.1s---A---0.1s---A---0.1s---………………
线程2:A---0.1s---A---0.1s---A---0.1s---A---0.1s---A---0.1s---A---0.1s---………………
线程3:A---0.1s---A---0.1s---A---0.1s---A---0.1s---A---0.1s---A---0.1s---………………
线程4:A---0.1s---A---0.1s---A---0.1s---A---0.1s---A---0.1s---A---0.1s---………………
每个线程,当A请求完成(接收到服务器的响应),随即就会发起下一次A请求
因此以上场景中,TPS = 4/0.1s=40/s,即服务器每秒可以处理40个请求。
考虑一下:在4个并发数不变的情况下,如果服务器性能进行了优化,响应时间缩短为0.01秒,那TPS就上升到400/s。
因此,很小的并发量,也能测试到较大的TPS,这完全取决于服务器处理的速度(即响应时间)。
有的人只单纯的根据PTS工具的并发数(或jmeter中虚拟线程数、或loadrunner的虚拟用户数)来评估服务器的性能,这是不完全正确的,服务器的性能好坏主要关注的是TPS和RT。
再来分析一下,任何系统都是有瓶颈的,那么随着线程数(用户数)的增长,TPS和响应时间这两项指标的变化情况,如下图:
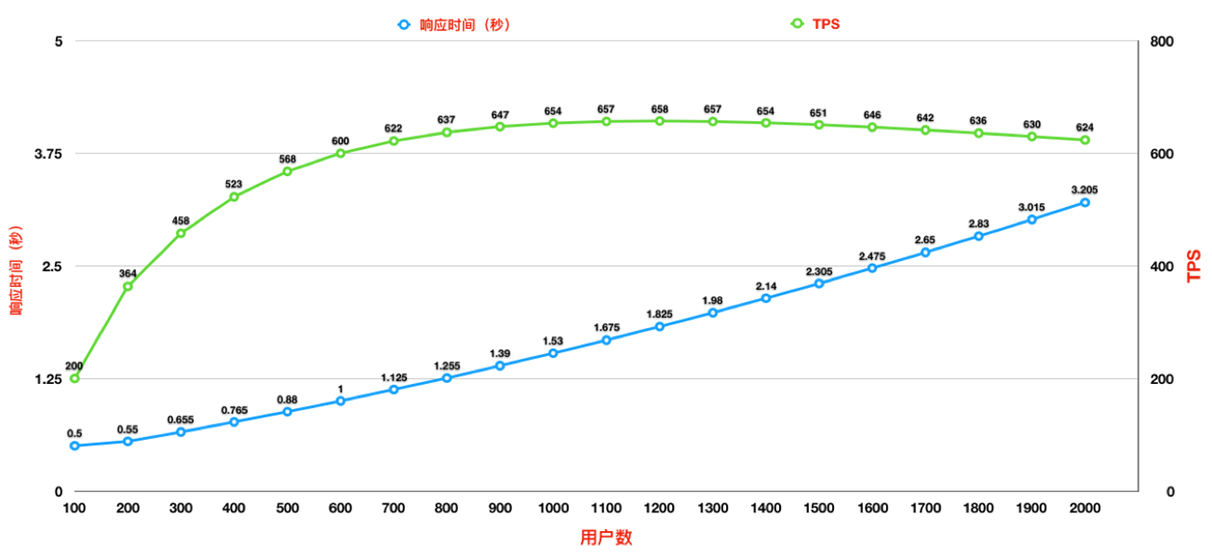
随着线程数(用户数)的增长(蓝色线),TPS稳步上升(绿色线),但是上升的速率是越来越慢的(TPS上升的速度,不及响应时间上升的速度,因此绿色线的斜率越来越小),这说明服务器性能出现了衰退。(如果随着线程数的增长,响应时间无变化,那么TPS的增长就是与线程数的增长成线性正比的关系,绿色线的斜率将会保持不变,这就是服务器性能未出现衰退的情况)。当TPS达到658时,响应时间的增长速度变得更快了,系统TPS出现了下降的情况,因此该系统最大TPS即658(当然,这也得参考性能需求要求的响应时间,如果此时对应的响应时间超出了预期的响应时间,则得出的这个最大TPS也是无意义的,需要优化)

PART3:具体实践
1.明确压测场景
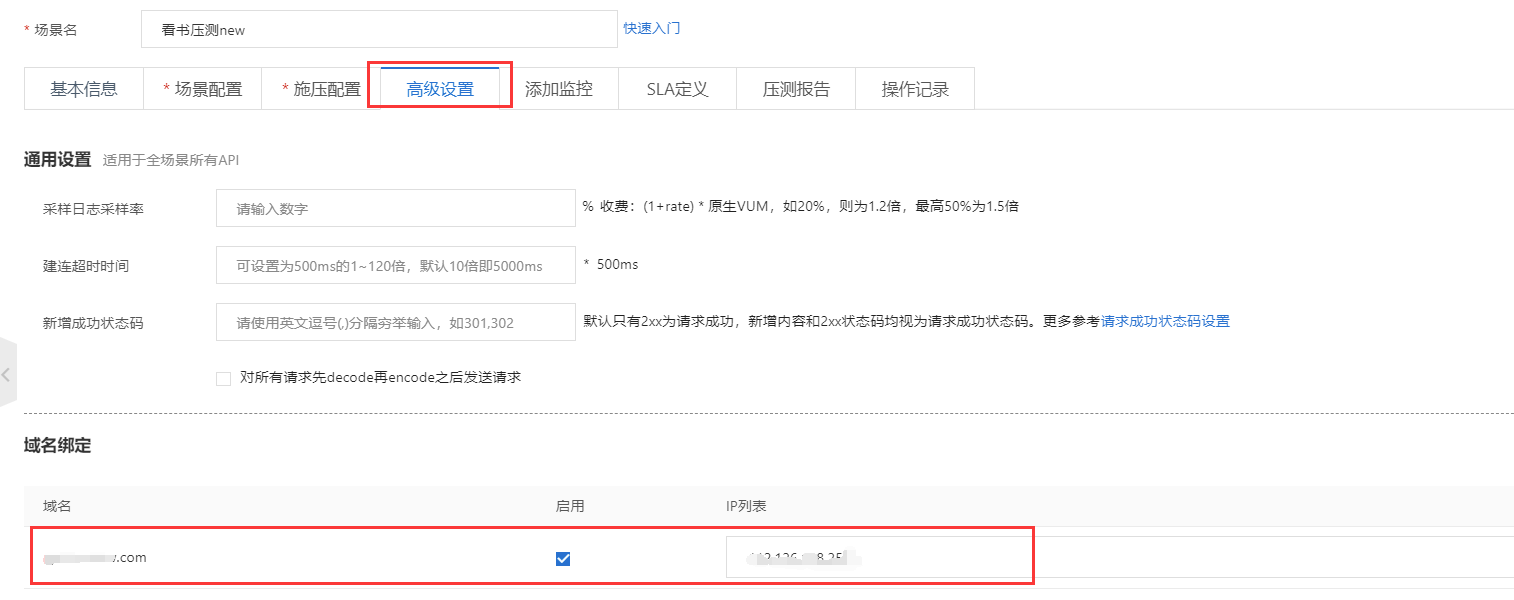
1.1明确待压测接口、待压测服务器IP
一般来说,压力测试都是在测试服务器进行的,因此一定要注意绑定host,否则就会压到线上环境,造成非常严重的后果。
先整理待测接口的地址与host关系:
|
功能点 |
接口地址 |
Host |
|
xxx |
xxx |
x.x.x.x |
|
xxx |
xxx |
x.x.x.x |
|
xxx |
xxx |
x.x.x.x |
在压测场景中进行host配置,配置方法如下:
1.2明确压测的TPS目标
1.1中已经把待测功能涉及到的接口都整理出来了,现在要评估每个接口的压测目标峰值tps,评估方法如下:
1)针对新的业务,需要和产品一起根据用户量,功能使用频率等角度去综合预估,本篇暂不讨论。
2)针对已有的业务,评估的依据是现有线上的数据,找运维要一下对应环境的接口在高峰时段访问量数据(高峰时段每秒请求数,一般可以取高峰时段10分钟的请求数,然后将请求数除以600秒,得出一个高峰TPS),需要注意询问运维提供的是一台web的数据,还是所有web的数据,如果是一台的,则还需要*web台数
以某接口压测为例,假设100万日活情况下,通过上述方法,已知目前线上接口的峰值tps=200
假设目标是中长期支持日活300万,那压测目标峰值tps=200/100*300=600
这里有一点要注意一下,不是所有接口都适合用日活来预估,需要看这个接口的特点,比如某个接口访问量和新增量密切相关,例如注册接口,那就需要去使用每天的新增量来预估目标TPS,例如目标是支持每天10万新增,目前每天是5万新增,则注册接口目标tps就是现在的两倍
按上述方法,可以依次把所有接口目标tps都评估出来:
|
功能点 |
接口地址 |
Host |
压测目标TPS |
|
xxx |
https://xxxxxx |
x.x.x.x |
xxx/s |
|
xxx |
https://xxxxxx |
x.x.x.x |
xxx/s |
|
xxx |
https://xxxxxx |
x.x.x.x |
xxx/s |
1.3明确压测连接方式
因为压测工具发起的压力是来源于少量机器,在重复请求接口时会建立长连接,从而减少的接口的响应时间RT值,因此要明确该接口在正式业务中使用时的场景是否是长连接,如果该接口是APP使用,相当于就是完全不同的机器在调用接口,这与压测的压力连接方式不一致,因此需要再header头中带上Connection:close,规避长连接的影响,如果实际业务场景是少数几台服务器在调用,则不需要加上该属性(如果是从合作方部分机器发起的请求,需要跟合作方确认,接口是不是没有做处理,接口默认带有connection:keep-alive 属性,保证真实场景是属于长链接)
对请求header和响应header中connection参数的情况做了测试,测试结果如下:
|
请求header |
响应header |
后续请求是否会保持连接 |
|
connection:close |
connection:close |
否 |
|
connection:close |
connection:keep-alive |
否 |
|
connection:keep-alive |
connection:close |
否 |
|
connection:keep-alive |
connection:keep-alive |
是 |
|
无connection参数 |
connection:close |
否 |
|
无connection参数 |
connection:keep-alive |
是 |
|
无connection参数 |
无connection参数 |
是(免费小说app测试结果) |
case1&2:请求header加上connection:close,无论响应header的connection值如何,每次请求都需要重新建立http/https连接,这样的话就是模拟用户端多点发起请求(用户都是需要建立至少一次连接的),平均响应时间相对会加长一些(建立连接、发送请求的时间),这样设置,也可以避免slb负载分配不均匀造成的性能问题。
case3:请求header加上connection:keep-alive,如果响应header的connection:close,则与情况1&2相同
case4:请求header加上connection:keep-alive,如果响应header的connection:keep-alive,那请求会保持长连接,在pts压测设置的ip数很少的情况下,可能造成负载不均衡的情况。但是如果业务是第三方服务端发起的请求(ip只有少数的几个),那可以压测时就使用keep-alive模式来压测,来模拟上线后的实际的情况,毕竟这样的话平均响应时间会短一些。
case5:请求header不加connection参数,如果服务端返回connection:close,则与上述情况1&2情况一致
case6:请求header不加connection参数,如果服务端返回connection:keep-alive,则与上述情况4情况一致
case7:请求和相应都不带connection参数,目前用免费小说app测试,是会保持长连接
总结:只要有一方close,就不使用长连接;两方都keep-alive,使用长连接;如果请求不带connection,则根据响应的connection来确定是否使用长连接
1.4明确业务路径的覆盖
如果同一个接口,接口是可以接受不同的参数,不同的参数,覆盖到的代码逻辑路径也不一样。那该接口也需要按实际业务,拆分成多个接口,按比例分配去压测,从而得出最真实的TPS上限,例如登录接口,可以分为微信登录和手机登录的参数,两种参数,走到的代码逻辑可能是不同的,那就需要作为两个接口去压测,一个接口是微信登录,一个接口是手机登录。
还有一种情况,同一个接口,不同的用户数据情况(例如新用户、老用户,走的逻辑不一样),覆盖到的代码逻辑路径也不一样,那我们就要考虑去准备不同比例的基础数据。
实际压测任务中,我们只知道有一个目标TPS和RT要完成,不一定很明确真实业务的参数比例或用户基础数据的比例,所以可以按照性能最差的业务场景来压测,该场景压测的TPS如果能完成任务,真实使用场景也必然没有问题。当然也可以是为了简化压测策略,快速完成压测任务,按此方法压测。判断性能最差的业务场景的基本原则:
- 覆盖到所有的中间件(如redis,队列)
- 同一中间件使用次数最多的,例如两条路径都操作redis,但是操作的次数不一样,则选择次数多的路径
- 如果现有的线上数据达不到路径覆盖,则需要开发改代码来实现相同的场景
- 如果一条路径并不能集齐最复杂的路径,例如不同的中间件在不同的路径中,可以分不同场景压测,每个场景达到目标TPS,则实际场景也可以达到目标TPS
- 准备的基础数据(例如用户账号),是按照保证能覆盖到最复杂的路径的数据来准备(例如同一个接口,新用户走的代码逻辑更为复杂,那准备数据可以都准备新用户数据)
当然如果能明确实际场景配比,并且场景配置也不复杂,还是以真实的场景来配置(即配置多个接口场景,根据实际情况分配不同的并发权重;基础数据也按真实情况准备)。例如:登录接口,按照手机登录占70%,微信登录占30%;老用户占80%,新用户占20%去压测
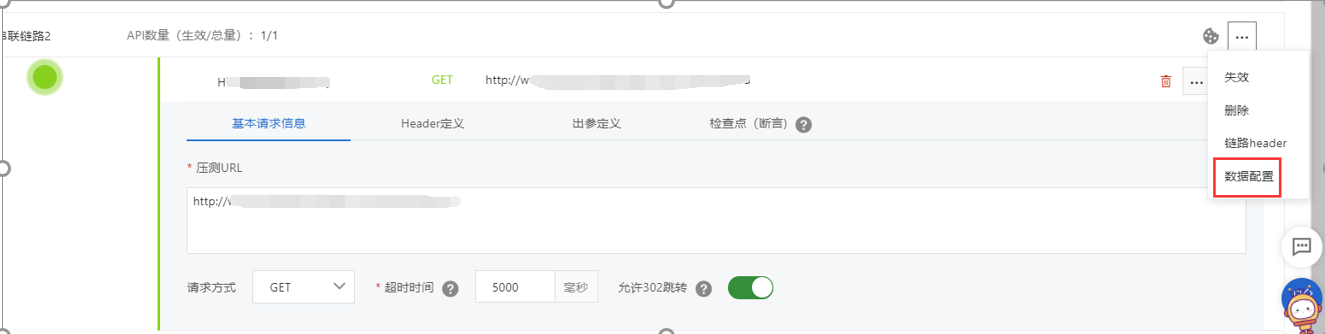
1.5设置参数化、关联
1)参数化:
a.添加参数配置,如下图
b.设置参数配置,并使用${}符号来调用,如下图

2)关联
a.先定义前一个接口的出参
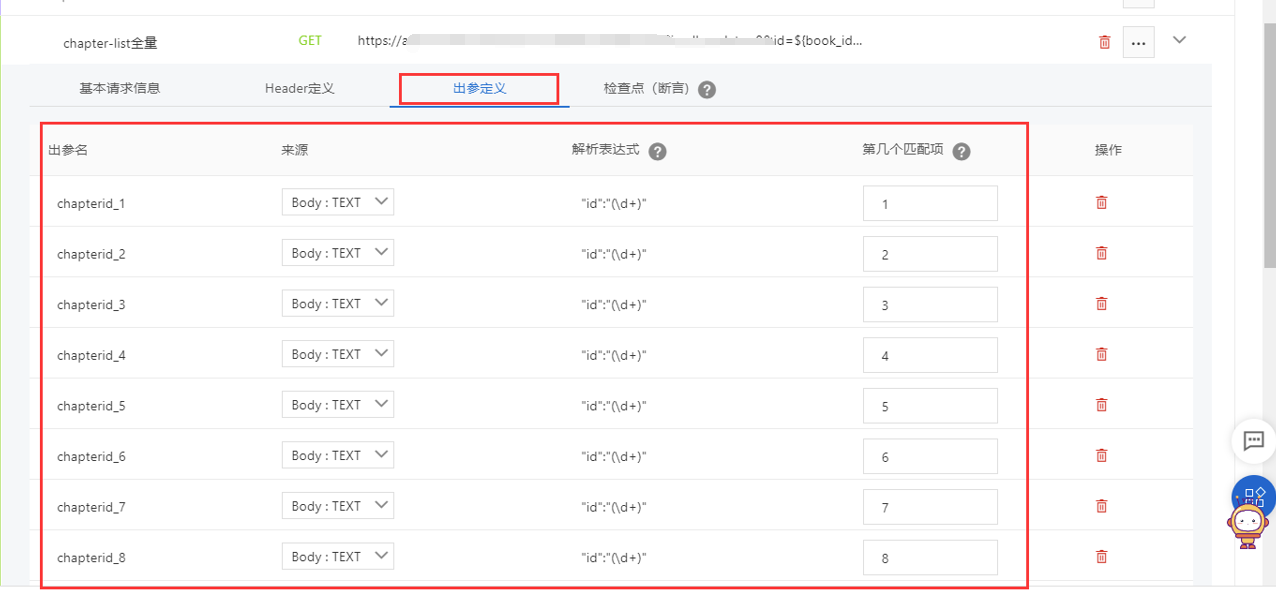
b.后续接口可以通过${}符号来调用
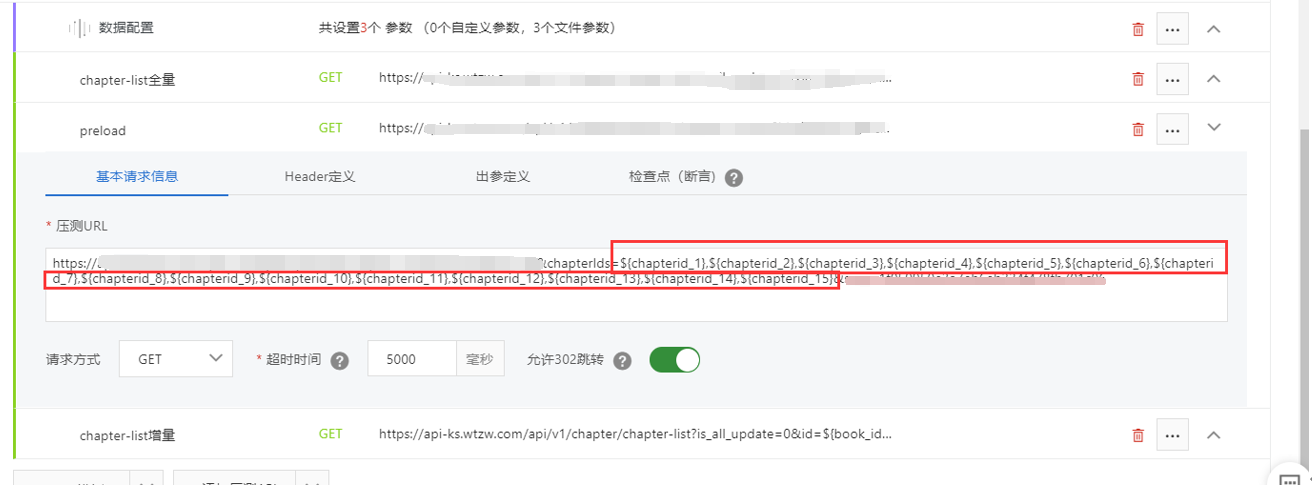
1.6预热数据情况考虑
如果某个功能是首次上线,那刚上线时,redis、golang缓存等缓存数据还未生成,并发量大的情况下,可能会造成数据库大量查询导致击穿现象。
那么我们在做性能测试时,就要重点考虑这点,跑压测脚本之前,先将各个已生成的缓存都删除,模拟刚上线时的服务器情况。
当然也可以在上线前提前生成好缓存,但业务稳定运行后,缓存也可能会出现大批量过期的情况,还是有可能会触发大量的数据库查询,因此最好的方法就是保证无缓存数据的情况下,性能测试也能够通过。
2. 施压配置策略
施压配置是为了达成目标TPS、RT的,需要知道配置参数对压测中的TPS的影响,另外压测也是需要花钱的,所以节省资源也是有必要的。
PTS中有两个压测模式(并发模式/RPS模式):
强烈推荐使用并发模式,慢慢使并发递增来压测。因为使用RPS模式容易造成服务器雪崩的情况。(如果响应稍慢,RPS(TPS)达不到设置的目标,工具就会自动创建很多并发,从而达到提高RPS(TPS)的目的,但并发提高,又可能会造成服务器出现瓶颈,导致TPS更下降,工具又会产生更多的并发,造成雪崩,达不到测试的目的,还浪费了压测资源)
2.1单次并发场景配置样例
目标TPS=80000,目标RT<50ms
计算可知最多需要并发用户数=80000/ (1000ms/50ms) = 4000
可以如图配置
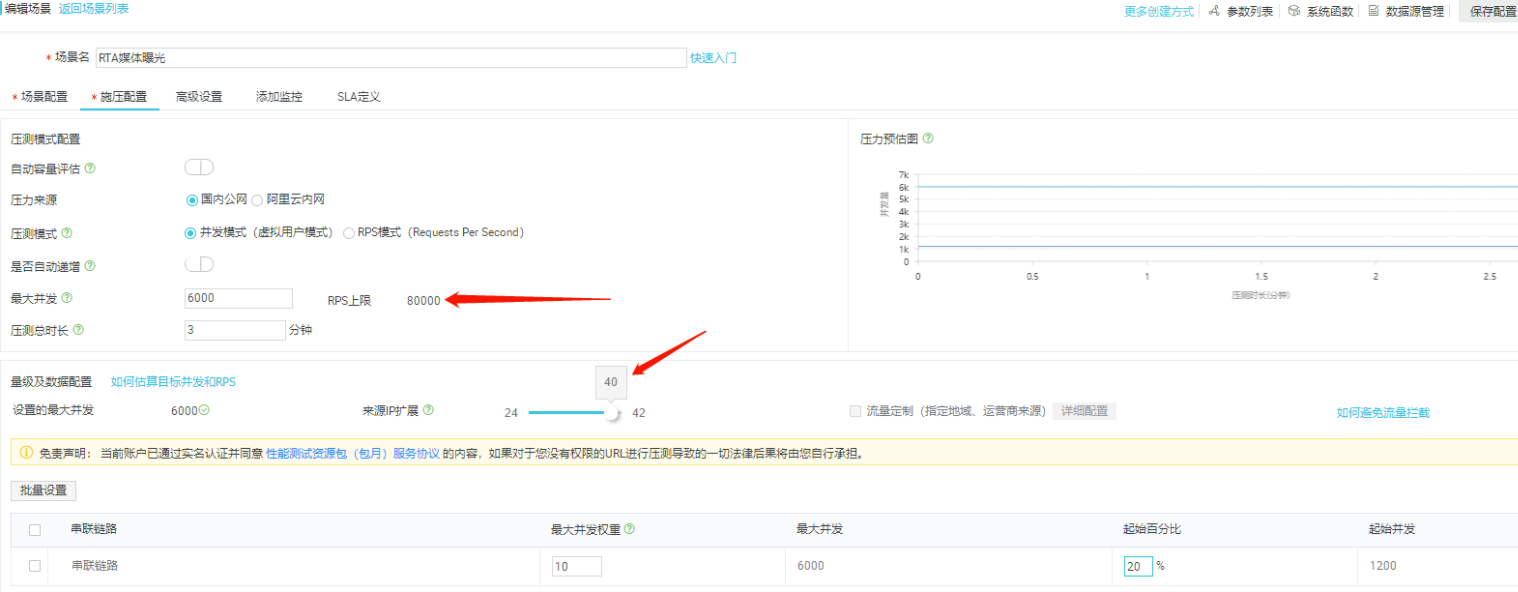
因为该压测工具会限制RPS上限(我们发现设置4000并发,28个ip,RPS只能达到56000,达不到目标80000),所以我们需要增加并发数和ip数(可设置的最大ip数,也会根据并发数的提升而提升),来提高RPS上限,让RPS达到我们的目标TPS,不然无论怎么压都不能完成目标,这里设置的并发数和ip能刚好达到目标TPS=80000即可。
因此并发数设置6000,ip数=40的时候,RPS上限=80000。
此外,串联链路中的起始百分比是调节起始并发数的,即压测开始时候压测的并发数,这个百分比可以设置小点,后面再慢慢手动增加,以防止一开始将服务器打挂掉
2.2自动递增并发场景配置样例
如果说并没有一个明确的TPS要求,只是想试探当前配置的最大TPS,可以用自动递增模式。

如上图所示的配置,就是开始固定以2000的并发压测,然后每分钟增加1000的并发,在第4-5分钟能测出当前接口RT<50ms的TPS峰值是80000,因为是试探TPS峰值,因此RPS上限得设置的比较大,而且爬坡运行的时间也很长,会消耗很多资源,不建议使用。
另一种场景,假如待测接口的TPS峰值是80000,但是接口程序会因为TPS由0突增至80000导致程序错误,接口程序限制只允许慢性递增,此时可以用自动递增并发场景匹配。(其实也可以使用上面2.1的方式,手动调整并发百分比,来增加并发)
2.3实际配置策略
虽说我们配置压测场景是为了验证接口是否满足压测任务目标,例如TPS=80000,RT<50ms,但是我们每次以这个目标去配置场景会浪费很多资源(接口调试次数越多,浪费越多;任务目标TPS越高,浪费越多),因为实际中目标接口会因为各种原因达不到任务目标TPS,因此实际应该先以一个小的TPS目标去配置,来保证目标接口能完成一个阶段性的任务,例如先以10000TPS为目标配置,达成目标后以40000TPS为目标配置,最后才配置80000TPS场景验证最终任务(首次目标尽可能小些,因为首次压测,一般都会因为服务器配置等原因出现瓶颈)。
3.压测结果分析
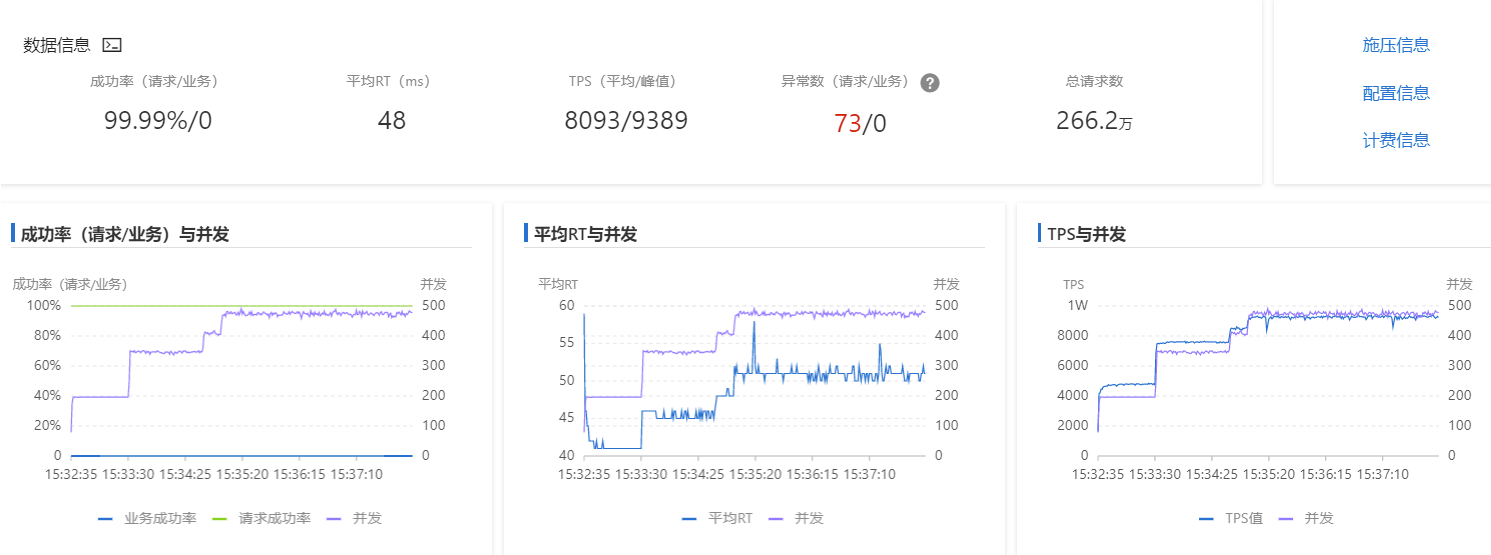
从以上三个图,就可以判断系统性能是否达到预期
图1:
TPS未达到目标TPS的情况下,成功率低于预期(一般预期成功率为100%),则视为性能不符合要求;
图2结合图3:
随着并发的上升,TPS未达到目标TPS的情况下,RT超过了预期RT,则视为性能不符合要求;
随着并发的上升,TPS未达到目标TPS的情况下,TPS无法再提高,或出现了下降,则视为性能不符合要求;
如果判断出性能不符合要求,可以提前停止压测任务,避免浪费资源(压测是按分钟计费,可以等到压到50秒后再关闭)
压测过程中,如果压测曲线正常,还需要联系开发、运维查看相关中间件、服务器等状态是否有异常,例如曲线TPS是80000,但是中间件队列的消费速度是70000/s,虽然曲线看似正常,但实际接口程序是存在某种问题,例如rabbitmq队列的写入速度是有软件瓶颈的(某次压测任务中的瓶颈是3台阿里云服务器单队列写入速度4.7万/秒),该类中间件异常会导致接口在压测持续n分钟后才出现问题,并不能通过压测曲线及时发现,因此在完成最终压测目标时需要保持一定的压测时长,保证接口程序能持续稳定的运行。
4.性能瓶颈问题案例
1、k8s的pod开太多反而导致性能问题
现象:接口短时间内压测正常,但是压测一会之后,会出现大量响应超时,服务器负载压力不大
原因:k8s的pod开多了,反而造成一些无谓的消耗,运维给的解释是,pod开太多,slb调度资源耗时导致的,适当减少之后压测正常
2、rabbitmq瓶颈问题
现象:TPS只要达到4.5万以上,运行一段时间就会挂掉,发现瓶颈在rabbitmq,消费速度最高只有4.5万/s,消息进来的速度大于这个,就会造成堆积,然后影响性能。原来配置是 3台12核24G,升级到24核48G,发现性能并未任何提升。
原因:rabbitmq存在一定瓶颈,处理速度级别是万/s级别,如果需要每秒处理更大量的数据,应该要用kafka。
3、流量带宽瓶颈
现象:某次接口压测时,TPS始终上不去,但运维观察服务器性能指标均没有压力。
原因:待测接口,响应体很大。因此需要从两个角度去查看带宽是否有瓶颈:
1) PTS施压机方面,如果施压机较少,单台施压机又有流量的瓶颈,因此需要增加施压机数量(增加IP数),来提高TPS;
2) 服务器配置方面:需要观察slb的带宽是否打满,如果打满了,需要升级SLB带宽配置。